はじめに
どうも。スクレイピング歴11日の初心者です。
本日学習したスクレイピングでは複雑な表記やif文、for文の集大成感があり、
上手く纏めて理解できると、スキルアップに繋がるのではと思いqiitaに書き残します。
環境
windows11
jupyterlab
本記事の目的
- キーワード検索した結果の中で、自動でそのページ内の情報を取得する事。
- 更に検索結果が複数のページにわたる場合でも対応できるようにすること。
例えばこのような場合。
この記事を通して
- 機械学習やAIアプリの開発、自動化のデータ取得の効率化の為にスクレイピングの技術を取得する。
- コードを書いてみて、内包表記やif文も多く見られたので復習も兼ねる。
このような狙いを達成できればと思います。
バックナンバー
- 初学者が勉強するSelenium。①
- 初学者が勉強するSelenium。②
- seleniumはCopy_full_xpathで少し楽になる
- 初学者が勉強するBeautiful Soup①
- 初学者が勉強するBeautiful Soup②
- Beautiful Soupで画像を取得
- BeautifulSoupでURLを一括取得
- 複数ページにわたる情報の取得。スクレイピング。
- 複数に渡るページでの画像収集スクレイピング
教材
基本的には上の動画を参考にして自分流に書き起こしました。
学習
まず初めに総まとめコードを添付します。最初にコードを読解し少しでもこれから行う処理のイメージをして頂ければと。
from bs4 import BeautifulSoup
import requests
import bs4
import time
import pandas as pd
keyword = 'Python'
url = 'https://kino-code.work/?s={}'.format(keyword)
r = requests.get(url)
time.sleep(3)
soup = BeautifulSoup(r.text, 'html.parser')
page_na = soup.find(class_ = 'pagination')
page_num = page_na.find_all(class_ = 'page-numbers')
pages = []
for i in page_num:
pages.append(i.text)
urls = []
if not pages:
urls = ['https://kino-code.com/?s={}'.format(keyword)]
else:
last_page = int(pages[-2])
for i in range(1, last_page + 1):
url = 'https://kino-code.work/?s={}'.format(keyword) + '&paged={}'.format(i)
urls.append(url)
links = []
titles = []
snippets = []
for i in range(len(urls)):
r = requests.get(urls[i])
time.sleep(3)
soup = BeautifulSoup(r.text, 'html.parser')
# find_allの引数に、HTMLタグが持つCSSのクラスで検索をかける。
get_list_info = soup.find_all('a', class_ = 'entry-card-wrap')
for n in range(len(get_list_info)):
# リンクを取得
get_list_link = get_list_info[n].attrs['href']
links.append(get_list_link)
# タイトルを取得
get_list_title = get_list_info[n].attrs['title']
titles.append(get_list_title)
# 説明文を取得
get_list_snippet = get_list_info[n].find(class_ = 'entry-card-snippet').text
snippets.append(get_list_snippet)
result = {
'title': titles,
'link': links,
'snippet': snippets
}
df = pd.DataFrame(result)
df
それでは次のセクションで基本的な流れや要点をまとめて行きます。
フロー
① モジュールのインポートとサイトの取得
モジュールのインポートと目的画像のあるページデータの取得
from bs4 import BeautifulSoup # HTMLの構造の解析と抽出
import requests # HTTP接続
import pandas as pd # pandasのインポート
import time # timeのインポート
この部分については特に語る事はありません。必要なスクレイピングのモジュールをインストールします。
keyword = 'Python' # 検索したい言葉
url = 'https://kino-code.work/?s={}'.format(keyword) # 今回スクレイピングを行うサイト
r = requests.get(url) # 指定したurlをリクエストで取得
time.sleep(3) # 3秒間待機
今回は変数 url にて検索されたkeyword(Python)にて表示された全ページに対してスクレイピングを行います。
- url
format構文を使用しておりますね。書き下すと
https://kino-code.work/?s=Pythonこのようになります。keywordが{}内に格納されます。
つまりurlの最後の部分には、検索されたkeywordが格納されるという仕組みです。例を挙げますと - https://kino-code.work/?s=Python
- https://kino-code.work/?s=Go
-
https://kino-code.work/?s=Javascript
等。
各々のサイトにも同様な法則がある場合も多いので是非探ってみてください。
② 検索結果が複数ページに渡る際の対処
先ほど取得したurlにはPythonの検索結果が複数あります。目的はその複数ページ全てから情報を取得する事です。
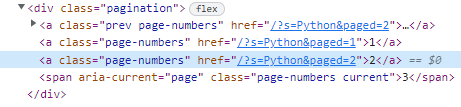
まず最初に、1,2,3ページ目のurlを比較してみましょう。
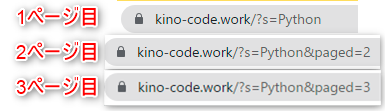
上記画像のように、ページ数とurlが呼応している事が確認できます。
更に検証で調べてみると、ページ数はclass_ = 'page-numbers'に属している事が確認できます。
検証での調べた結果
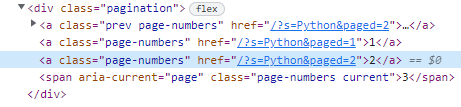
そうしますと下記のコードはイメージできますでしょうか。
soup = BeautifulSoup(r.text, 'html.parser') #html全体の情報を取得
page_num = page_na.find_all(class_ = 'page-numbers') #その全体からclass_ = 'page-numbers'を取得。
一旦まとめも兼ねてpage_numを確認してみましょう。
from bs4 import BeautifulSoup
import requests
import bs4
import time
import pandas as pd
keyword = 'Python'
url = 'https://kino-code.work/?s={}'.format(keyword)
r = requests.get(url)
time.sleep(3)
soup = BeautifulSoup(r.text, 'html.parser')
page_na = soup.find(class_ = 'pagination')
page_num = page_na.find_all(class_ = 'page-numbers')
print(page_num)
print(page_num[0].text)
print(page_num[1].text)
print(page_num[2].text)
実行結果化は以下の通りです。
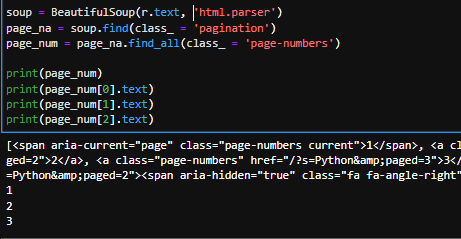
print(page_num)ではhtmlをそのまま抜き出す為、.textメソッドを用いてテキストのみ抽出します。そしてfind_allはリストを返すので各々はリストで表示させてあげる必要があります。
③ 各ページのurlを取得
pages = [] #空のリストを作成
for i in page_num: #page_numの回数文要素をforで回す。
pages.append(i.text) #空のリストに要素をテキスト化してappendで追加。
#結果
#['1', '2', '3', '']
3ページまである事が確認できました。 空白の''は「次へ」のボタンのことです。
同じような手段で別のKeywordでも試してはいかがでしょうか。
今度はそのページに呼応するurlを取得します。1Pのurl、2Pのurl等、検索結果のページの数だけurlを取得します。ここはポイントの一つです。(私的に)
urls = [] #空のリストを作成します。
last_page = int(pages[-2]) #最後のページ番号を変数に格納します。
for i in range(1, last_page + 1): # for文を用いてURLの検索結果の作成
url = 'https://kino-code.work/?s={}'.format(keyword) + '&paged={}'.format(i)
urls.append(url) #リストurlに作成したurlを格納。
-
last_page = int(pages[-2]) について
pagesの要素は['1', '2', '3', '']です。ここから最後から二番目[-2]と指定すれば最後のページを取得する事が出来ます。取得時にint型に直しておきましょう。 -
for i in range(1, last_page + 1)について
ページ数分のurlが必要なのでその分range関数で設定を行います。第一引数は[1]です。ページは1から始まりますので。最後のページはリストの性質上プラス1にしないと最後のページの一つ手前で終わってしまいます。最後まで取得するには+1してください。
これでページ数に呼応したurlを作成することができます。 -
.format(keyword) + '&paged={}'.format(i) について
このhtmlの構造を再現しましょう。keywordを{}の中に入れて、ページ数の番号(1,2,3)を変数 i で対応しています。
#結果
['https://kino-code.work/?s=Python&paged=1',
'https://kino-code.work/?s=Python&paged=2',
'https://kino-code.work/?s=Python&paged=3']
④ 例外処理
複数にページが渡る場合はこれで作動します。しかしページ数が1ページしかないjavascriptの場合はいかがでしょうか?
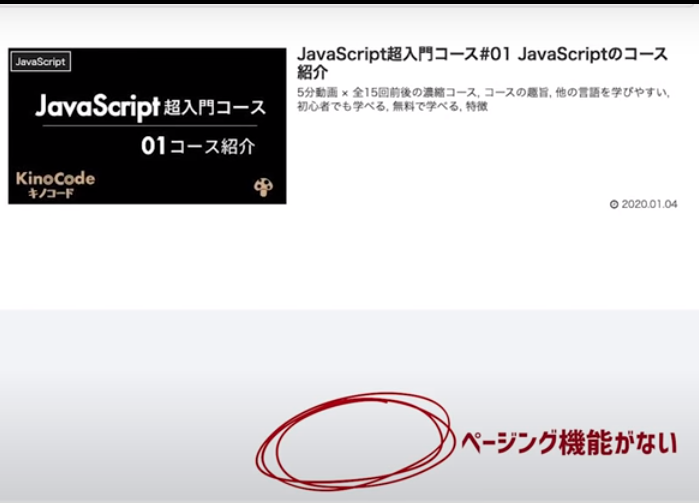
検索結果が複数ない場合はページングが無い為にエラーになってしまいます。
この場合はif文により条件分岐をして処理を分ける例外処理を行いましょう。
pagesの中身が空かどうかを判定。
if not pages: #リストpagesの中身が空かどうかを判定。
urls = ['https://kino-code.com/?s={}'.format(keyword)] #空ならばこの処理を行う。
else: # pagesの中身が格納されている場合はelseに移行。
このように書き換えも可能です。こちらの方が分かりやすいでしょうか。
if pages ==[]: #リストpagesの中身が空かどうかを判定。
urls = ['https://kino-code.com/?s={}'.format(keyword)]
else: # pagesの中身が格納されている場合はelseに移行。
上記を踏まえ一旦ここまで確認してみましょう。
from bs4 import BeautifulSoup
import requests
import bs4
import time
import pandas as pd
keyword = 'Python'
url = 'https://kino-code.work/?s={}'.format(keyword)
r = requests.get(url) #URLを取得できたかを確認。
time.sleep(3)
soup = BeautifulSoup(r.text, 'html.parser') #htmlを表示。
page_na = soup.find(class_ = 'pagination')
page_num = page_na.find_all(class_ = 'page-numbers') #1ページ2ページ3ページ。
pages = [] # pagesには1,2,3。
for i in page_num:
pages.append(i.text) #空のリストに要素をテキスト化して詰め込むのはappendを用いる。
urls = []
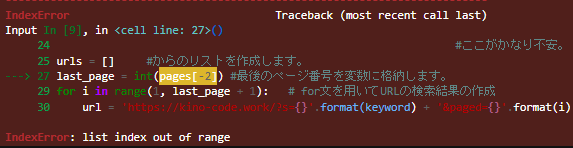
#ここがかなり不安。
if not pages: #データが何もない場合 #[ある条件を満たさない場合] に行う処理を書くときに使います。 不明
urls = ['https://kino-code.com/?s={}'.format(keyword)] #python で検索された検索結果。 を満たさない場合? 不明
else:
last_page = int(pages[-2])
for i in range(1, last_page + 1): # これはどこからどこまでというのが分からない。
url = 'https://kino-code.work/?s={}'.format(keyword) + '&paged={}'.format(i) #最後の数字で python ページが変化する。
urls.append(url) #これで全てのページの url (1,2,3) を取得することができた。
⑤ 各urlの情報を取得
まずは各々のデータを格納するリストを作成します。同じパターンですね。
links = []
titles = []
snippets = []
for i in range(len(urls)):
r = requests.get(urls[i]) #rangeの回数分urlが取得される。
同じようにリストから一つづつ行うという処理です。しかし私自身range(len(urls)):の解釈に苦戦したので一旦区切り説明させて頂きます。
-
rangeの引数はint型のみ。urlsはリストなのでlenを用いてint型に変換する必要がある。
-
何故rangeを使用するのか?リストの個数だけfor文を回したいから。rangeの回数(i回)だけurlの要素が取り出されforで回る。rangeの i とurlsの i がリンクされている。
-
for i in urls ではだめな理由。
シンプルにこれでいいのでは?と思いますよね?いつも通り。試しに
下記のコードを実装して結果をご確認ください。
for i in urls:
print(i)
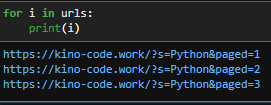
ご覧の通り,で区切られておらず、それぞれのurlが繋がっています。
これではエラーになるのも納得ですよね。なのでfor i in range(len(urls))を用います。
for i in range(len(urls)):
r = requests.get(urls[i]) #rangeの回数分urlが取得される。
time.sleep(3) # 3秒待つ。
soup = BeautifulSoup(r.text, 'html.parser') #読み込んだhtmlの解析
get_list_info = soup.find_all('a', class_ = 'entry-card-wrap') #解析したhtmlから欲しい情報を取得。
そこから欲しい情報がhtmlのどこに格納されているのか見極めて取得します。
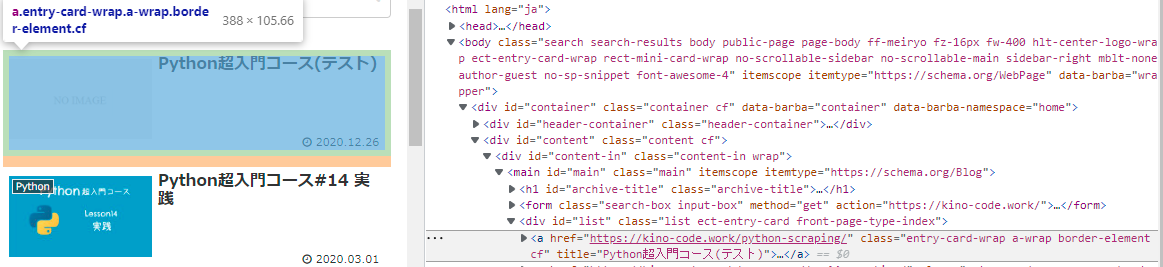
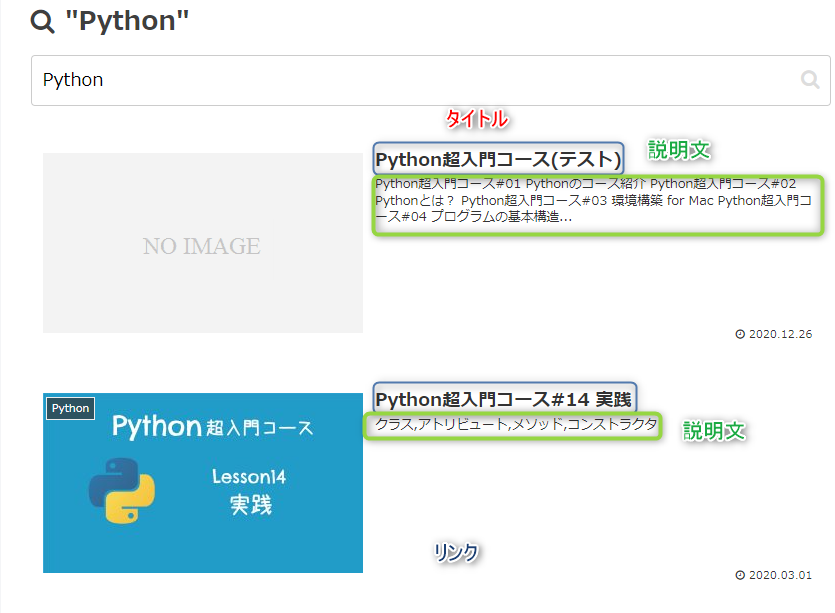
カーソルで合わせている部分class="entry-card-wrap a-wrap border-element cf"。
これは""で囲まれている1つのクラスではなくて、[entry-card-wrap][a-wrap][border-element][cf] というクラスが含まれているという事です。
今回は'entry-card-wrap' から抽出します。
一旦確認も挟みます。
a = soup.find_all('a', class_ = 'entry-card-wrap')
a[0]
クラス、「entry-card-wrap」 からaタグを全て取得します。
その抽出されたパートから、
- リンク、href="https://kino-code.work/python-scraping/"
- タイトル、"Python超入門コース(テスト)"
- 説明、Python超入門コース#01 Pythonのコース紹介 Python超入門コース#02 Pythonとは? Python超入門コース#03 環境構築 for Mac Python超入門コース#04 プログラムの基本構造...
がそれぞれ格納されていることをご確認下さい。
そしてその回数分forで回し、情報を各々取得します。
これらをまとめると下記のコードになります。
links = []
titles = []
snippets = []
for i in range(len(urls)):
r = requests.get(urls[i])
time.sleep(3)
soup = BeautifulSoup(r.text, 'html.parser')
# find_allの引数に、HTMLタグが持つCSSのクラスで検索をかける。
get_list_info = soup.find_all('a', class_ = 'entry-card-wrap')
for n in range(len(get_list_info)):#取得した get_list_info の回数分。
get_list_link = get_list_info[n].attrs['href'] #hrefを含むものを取得
links.append(get_list_link) #それをリストにappend
get_list_title = get_list_info[n].attrs['title'] # タイトルを取得。
titles.append(get_list_title) # リストに追加。
# 説明文を取得
get_list_snippet = get_list_info[n].find(class_ = 'entry-card-snippet').text
snippets.append(get_list_snippet)
#説明文はclass_ = 'entry-card-snippet'に格納されているので、テキスト化して抽出。リストに追加。
これで全ての要素をリストに追加する事が出来ました。それではこの3つのリストを
辞書化してdfに変換しましょう。
result = {
'title': titles, # key名に"title", value要素にtitles
'link': links, # key名に"title", value要素にtitles
'snippet': snippets # key名に"title", value要素にtitles
}
df = pd.DataFrame(result)
df
ここは難しくないはずです。 辞書化の基本通りで、
keyとvalueを指定しdfに変換してください。ここまででやっと当初の目的は達成されました。
終わりに
今回はかなりタフな内容でした。しかし、forの内包表記やif文、例外処理や辞書化等様々な基本動作を用いたので復習にはもってこいでした。
不安要素としては他のサイトから「検証」で要素を正しく持ってこれるかです。是非手ごろな練習サイトで同じような処理を試してみたいものですね。
今回urlと情報を取得したので次回は画像をまとめて取得したいと思います。
次の記事も是非ご覧ください。
質問やご意見いつでもお待ちしております。