
はじめに
生成AI活用の基礎技術である RAG(検索拡張生成)で多用されたことで認知度が増しつつある「ベクトル埋め込み」ですが、取っつきにくい名前と AI エージェントの華々しさの影に隠れて、ブラックボックスとして蓋を閉じたままにされることも多いようです。
しかし、埋め込みは RAG の検索精度を左右する心臓部 であるだけでなく、大規模言語モデル(LLM)そのものの基盤技術 であり、画像検索・画像分類・画像生成・動画レコメンデーションなど、生成AIのあらゆる応用を根底で支えています。その仕組みを理解することは、AIシステムの設計や精度改善において大きなアドバンテージとなります。
本記事では、「埋め込みとは結局何をしているのか?」という素朴な疑問から出発し、以下のテーマをコードや実験結果なども交えんがら概観していきます。
- トークンと埋め込みの基礎
- ベクトル検索の仕組み
- マルチモーダル埋め込み
- ベクトル検索や RAG の精度向上への活かし方
ブラックボックスの蓋を開けてみると、そこには意外とシンプルで美しい、そして、面白い世界が広がっています。
なお、このブログの内容は 2026/3/18 の Oracle AI Jam Session #34 にてご紹介させていただきました。
アーカイブ動画もありますのでお役に立てましたら。
第1章 そもそも「埋め込み」とは何か?
1.1 なぜ埋め込みが必要なのか
コンピュータは文章をそのままでは「理解」できません。テキストは人間にとっては意味のある記号列ですが、コンピュータにとっては単なるバイト列にすぎません。
そこで、テキストを 数値のベクトル(数値の配列) に変換し、「意味」を数学的に扱えるようにする技術が必要になります。これが 埋め込み(Embedding、エンベディング) です。
「猫はかわいい」 = [0.12, -0.34, 0.56, 0.78, -0.11, ...] (例:1024次元のベクトル)
埋め込みの最も重要な性質は、意味が似ているものは、ベクトル空間上で近くに配置される ということです。
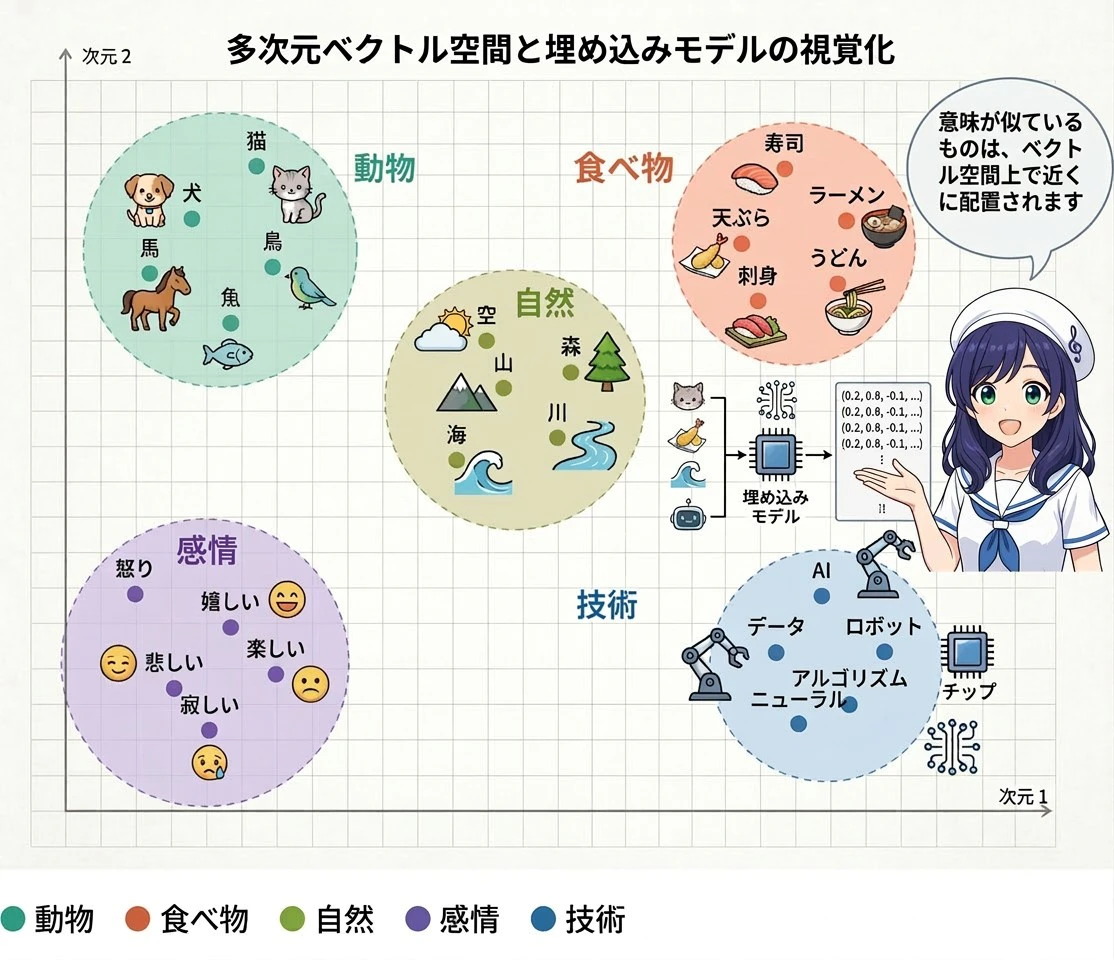
上の図は概念的なイメージですが、動物同士は近くに、乗り物同士は近くに配置されます。実際の埋め込みは数百〜数千次元の空間で、より細やかな意味の関係性を表現しています。
1.2 特徴ベクトルと埋め込みの違い
画像や文書などの特徴を数値ベクトルの形で表現したものを一般に 特徴ベクトル と呼びます。その中でも、特に 深層学習(ディープラーニング)の表現学習で得られたもの を「埋め込み」と呼びます。そして、埋め込みを生成する機械学習モデルを 埋め込みモデル といいます。
1.3 埋め込みが活躍する場面
埋め込みは生成AIのあらゆる場面で使われています。
| 活用場面 | 役割 |
|---|---|
| RAG(検索拡張生成) | ユーザーの質問と関連文書を意味的にマッチング |
| LLM の内部処理 | トークンを埋め込みベクトルに変換してから推論を開始 |
| 画像検索 | テキストや画像をクエリーにして類似画像を検索 |
| 画像分類 | 画像の埋め込みをもとにカテゴリを判定 |
| 画像生成 | DALL-E 2 や Stable Diffusion で CLIP 埋め込みがガイド役 |
| レコメンデーション | ユーザーやコンテンツの埋め込みから嗜好を予測 |
第2章 トークンと埋め込みの基礎
2.1 LLM の仕組みをざっくり理解する
埋め込みの役割を理解するために、まず LLM(大規模言語モデル) の基本的な仕組みを押さえておきましょう。
LLM は「入力された文字列の 次の単語(トークン)を予測する ように大量の公開テキストで訓練された機械学習モデル」です。
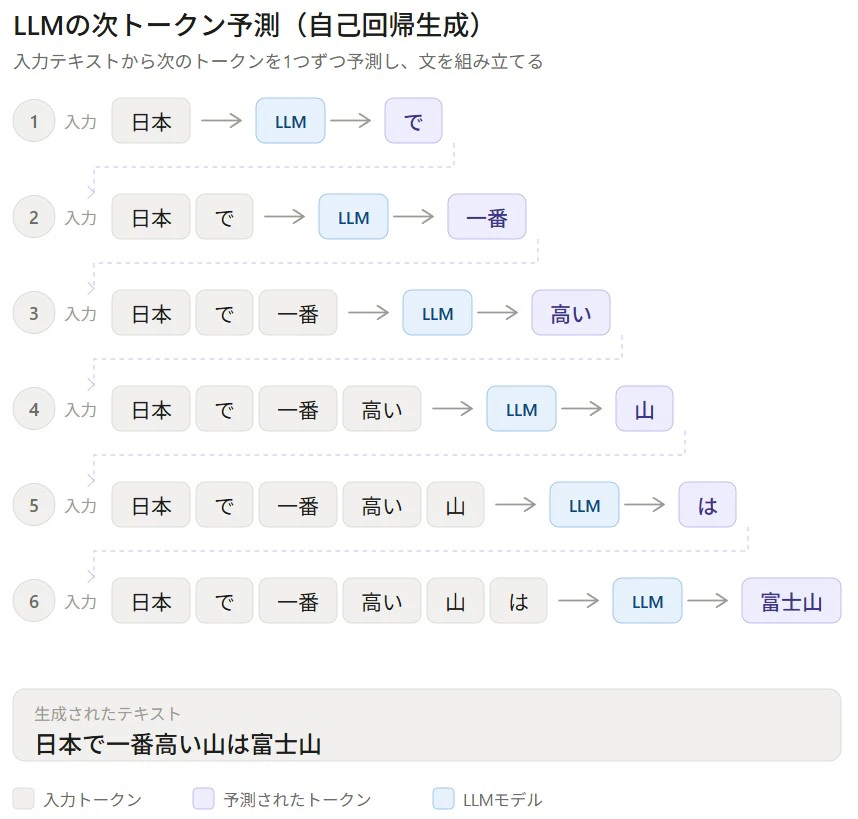
このとき LLM の内部では、入力テキストをまず トークン に分割し、各トークンを 埋め込みベクトル に変換してから処理を始めます。つまり埋め込みは LLM の入り口であり、LLM が「言葉の意味」を扱うための基盤技術です。
LLM の入口と出口 ― どちらも埋め込み
LLM は「次のトークンを予測する」モデルです。では、その予測の過程で埋め込みはどう関わっているのでしょうか。実は、LLM の 入口と出口の両方 に埋め込みが登場します。
入口 ー 言葉を数値に変える「翻訳者」
LLM がテキストを受け取ったとき、最初に行うのがトークン化と埋め込みへの変換です。トークンID(単なる通し番号)を、意味を反映したベクトルに変換する ― この「翻訳」を担当するのが 埋め込み層 です。

ここで重要なのは、埋め込み層が与える「意味の初期値」が貧弱であれば、LLM 本体の処理がどれだけ優秀でも十分な性能は得られないということです。料理に例えるなら、埋め込み層は素材の仕込みに相当します。素材の下ごしらえが雑であれば、どんなに腕の良いシェフでも最高の料理は作れません。
出口 ー 次のトークンを選ぶのもベクトルの「近さ比べ(最近傍検索)」
入口だけではありません。LLM が次のトークンを予測する 出口の部分 にも、埋め込みが関わっています。
LLM 本体が処理を経て、「次に来るべきトークンの意味」を表すベクトルを出力します。このベクトルを、LLM が知っているすべてのトークン(数万〜数十万個)のベクトルと比較して、最も近いもの(似ているもの)を次のトークンとして選び出します。
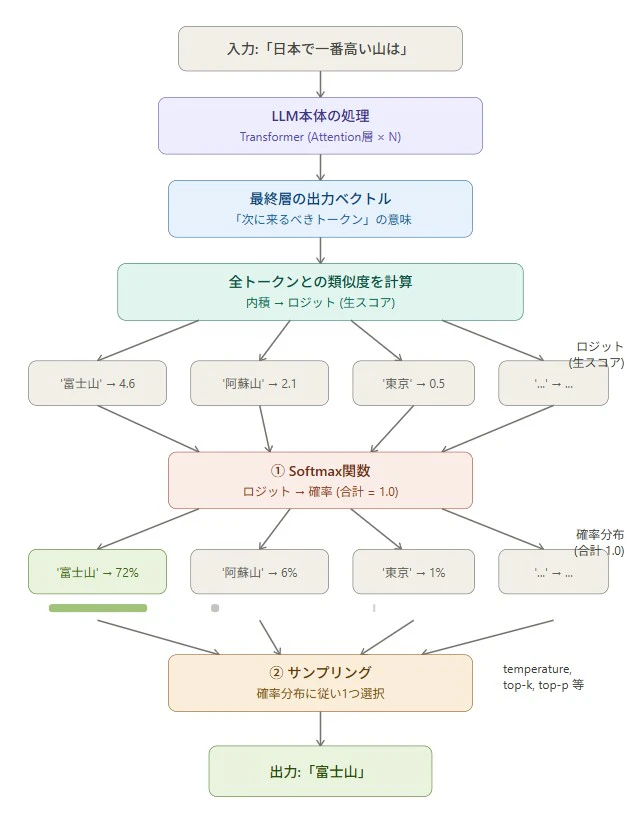
この処理は、本質的に ベクトルの「近さ比べ」 です。そして、この記事の後半で紹介するベクトル検索もまったく同じ原理で動いています。
| LLM が次の単語を選ぶとき | ベクトル検索で文書を探すとき | |
|---|---|---|
| 比較の起点 | LLM が出力した「次の単語の意味」ベクトル | ユーザーの質問の埋め込みベクトル |
| 比較の対象 | 語彙内の全トークンの埋め込み | データベース内の全文書の埋め込み |
| やっていること | 最も近いトークンを選ぶ | 最も近い文書を選ぶ |
つまり、この記事でベクトル検索の仕組みを理解すれば、LLM が言葉を紡ぐ仕組みの核心も同時に理解していることになります。
2.2 トークンとは
自然言語処理において、テキストはまず トークン という処理可能な最小単位に分割されます。このプロセスを トークン化(Tokenization) と呼び、実行するソフトウェアを トークナイザー と呼びます。
サブワードトークン化
現代の LLM ではサブワード(部分文字列)単位でトークン化する手法が主流です。頻出する単語には専用のトークンを割り当て、頻度の低い単語はより細かい単位に分解します。これにより語彙数を抑えつつ、すべてのテキストをカバーできます。
こちらは、OpenAI の o200k_base というトークナイザーでトークン化した例です。


代表的なアルゴリズムは以下の3つです。
| アルゴリズム | 採用モデル | 特徴 |
|---|---|---|
| BPE(Byte Pair Encoding) | GPT系(GPT-4, GPT-4oなど) | 頻出するバイトペアを繰り返し統合 |
| WordPiece | BERT | BPEに類似、尤度ベースで統合 |
| SentencePiece | T5, Gemma など | 言語非依存で、日本語にも効果的 |
Python で試すトークン化
OpenAI の tiktoken ライブラリを使うと、GPT系モデルのトークン化を手元で確認できます。
import tiktoken
encoding = tiktoken.get_encoding("o200k_base ") # GPT-4o で使われるエンコーディング
text = "ベクトル埋め込みと仲良くなりたい!"
tokens = encoding.encode(text)
print(f"テキスト: {text}")
print(f"トークンID: {tokens}")
print(f"トークン数: {len(tokens)}")
# 各トークンを確認
for token_id in tokens:
print(f" ID {token_id} → '{encoding.decode([token_id])}'")
面白いトークン
OpenAI の GPT-4o といっしょに登場した o200k_base というエンコーディングに含まれるトークンの中で、文字列長が長いものから上位10件を抽出したものがこちらです。
Token ID: 161518, String: abcdefghijklmnopqrstuvwxyz
Token ID: 184150, String: ABCDEFGHIJKLMNOPQRSTUVWXYZ
Token ID: 130756, String: verantwoordelijkheid
Token ID: 106123, String: telecommunications
Token ID: 133739, String: selbstverständlich
Token ID: 154976, String: .onreadystatechange
Token ID: 166459, String: significativamente
Token ID: 184611, String: Telecommunications
Token ID: 193348, String: Wahrscheinlichkeit
Token ID: 197767, String: disproportionately
a~z と A~Z にトークンが割り当てられているんですね!
ちなみに、その次の "verantwoordelijkheid" は、オランダ語で「責任」と言う意味の名詞のようです。
便利ツール: Hugging Face の Tokenizer Playground や Tokenizer Arena で、さまざまなモデルのトークン化を視覚的に比較できます。
2.3 トークンから埋め込みへ
トークン化でテキストが数値ID(トークンID)の列に変換されました。しかし、トークンIDは単なる辞書上の通し番号であり、意味的な情報は含まれていません。たとえば ID 123 が「猫」で ID 456 が「犬」だとしても、数値の差 456 - 123 = 333 に意味はありません。
そこで、各トークンIDを 意味を反映した高次元ベクトル に変換するのが「埋め込み」のステップです。
埋め込み関連用語の説明
| 用語 | 英語 | 指すもの | 説明 |
|---|---|---|---|
| トークン | token | テキストの分割単位 | テキストをモデルが処理できる最小単位に分割したもの。単語・サブワード・文字など粒度はモデルにより異なる |
| 埋め込み | embedding | 手法・操作・概念全般 | データを別の空間に写像する操作や手法そのもの。最も広い概念で、ベクトルに限らない |
| ベクトル埋め込み | vector embedding | ベクトル空間への写像手法 | 埋め込み先がベクトル空間であることを明示した表現。ML分野では「埋め込み」とほぼ同義 |
| 埋め込みベクトル | embedding vector | 生成されたベクトル(成果物) | 埋め込みの結果として得られる具体的な数値ベクトル。「300次元の埋め込みベクトル」のように使う |
| 埋め込み層 | embedding layer | モデル内部の変換層(部品) | ニューラルネットワーク内でトークンIDを密なベクトルに変換する層。ルックアップテーブルとして機能する |
| 埋め込みモデル | embedding model | ベクトルを生成するモデル(道具) | 入力データを埋め込みベクトルに変換する学習済みモデル。Cohere のCohere Embed 4等が例 |
関係を一言で表すと、トークン(入力)を埋め込みモデル(道具)に渡してベクトル埋め込み(操作)を行い、埋め込みベクトル(成果物)を得る、という流れになります。埋め込みはこのプロセス全体を包括する上位概念です。
ただし、埋め込み、ベクトル埋め込み、埋め込みベクトルの区別については、厳密な定義が存在するわけではなくニュアンスです。実際の会話や記事でも厳密に区別されないことが多く、文脈から判断する場面がほとんどです。
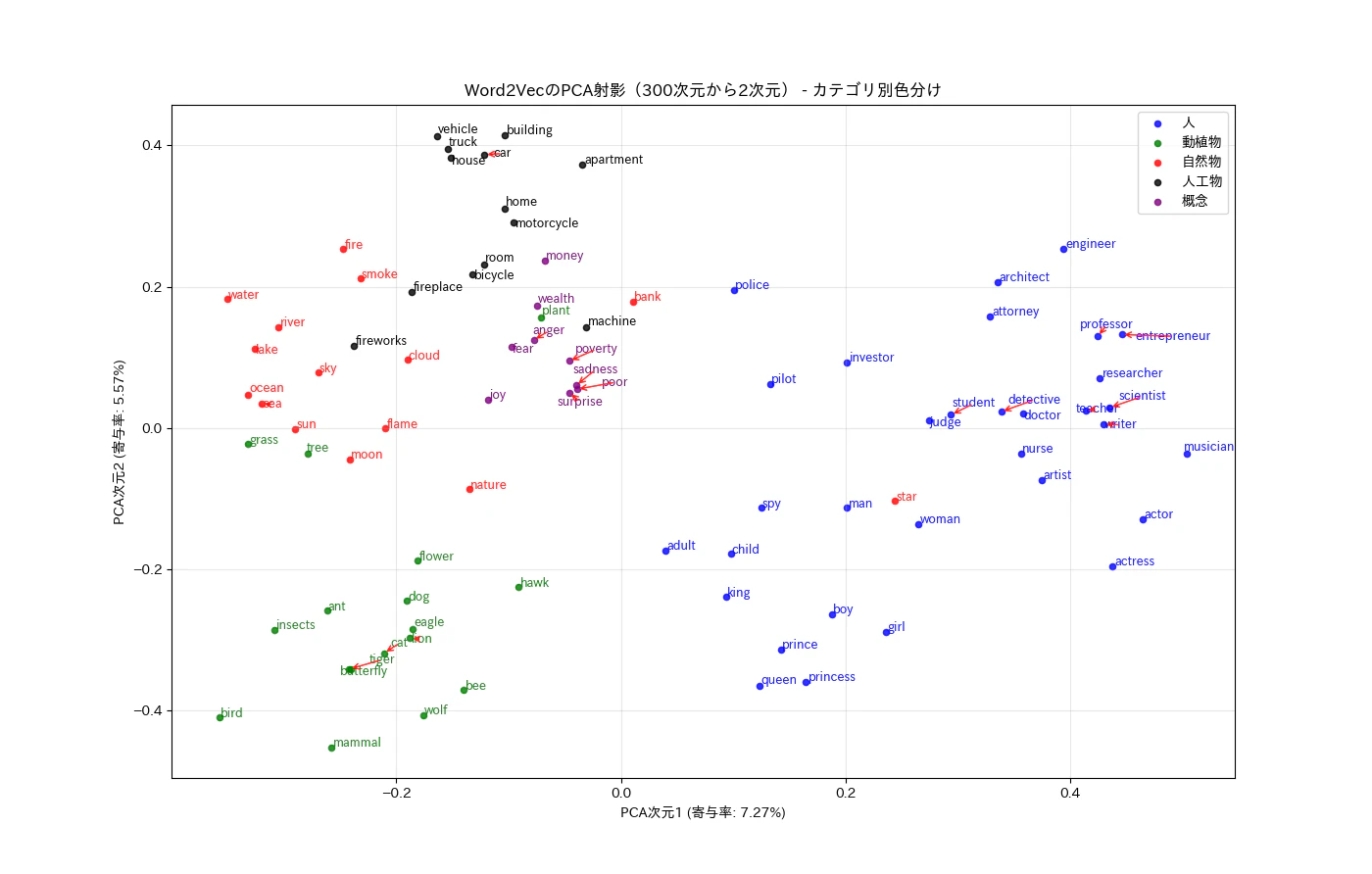
2.4 Static Embedding(静的埋め込み)
初期の埋め込み手法である Word2Vec や GloVe は、各単語に対して 固定されたベクトル を割り当てます。これを Static Embedding(静的埋め込み)と呼びます。
学習の仕組みはシンプルです。大量のテキストから 単語の共起関係(ある単語が別の単語と一緒に使われやすい傾向)を学習して、似た文脈で使われる単語には似たベクトルを割り当てます。
たとえば「コーヒー」という単語は「飲む」「カップ」「豆」「香り」などと共に出現しやすく、これらの共起パターンが「コーヒー」の埋め込みベクトルに反映されます。
Word2Vec の埋め込み空間
Static Embedding の限界
Static Embedding には大きな弱点があります。同じ単語には常に同じベクトルが割り当てられる ため、文脈によって意味が変わる多義語を区別できません。
日本語の「生物」という単語を例に考えてみましょう。
- 「猫は生物です」 → 「いきもの」
- 「刺身は生物です」 → 「なまもの」
Static Embedding では、この2つの「生物」は完全に同じベクトルになってしまいます。
英語だと、スポーツや芸能界で活躍している人も夜空に輝く星もどちらも "Star"で、同じベクトルになってしまいますね。
2.5 文脈考慮型埋め込み
この限界を克服するために考案されたのが文脈考慮型埋め込みです。主なアーキテクチャには以下のようなものがあります。
| アーキテクチャ | 代表モデル | 特徴 |
|---|---|---|
| Transformer | BERT, RoBERTa, SBERT | Self-Attention で全トークン間の関係を捉える。現在の主流 |
| RNN / LSTM | ELMo (biLSTM) | 前後方向のLSTMで文脈を逐次的に処理。Transformer 以前の代表格 |
| CNN ベース | TextCNN, ConvBERT | 局所的なn-gramパターンを畳み込みで捉える。高速だが長距離依存は苦手 |
| State Space Model (SSM) | Mamba | RNN的な逐次処理をSSMで効率化。長文処理でTransformerより効率的 |
| ハイブリッド | CNN + Transformer | 局所特徴とグローバル文脈を組み合わせる pub2.tokushima-u |
現在、主流となっているのは、Transformer アーキテクチャを基盤とする埋め込みモデルです。
Transformer モデルは Self-Attention(自己注意機構) を使って、入力テキスト内の全トークン間の関係性を計算します。
Self-Attention を直感的に言うと、「文中の各単語が、他のすべての単語をどれくらい気にかけるべきか」を自動的に学習する仕組み です。
「刺身は生物です」という文を例にすると、Self-Attention は「生物」というトークンを処理する際に、「刺身」「は」「です」のそれぞれに注意の重み(Attention Weight)を計算します。「刺身」への重みが大きければ、「生物」のベクトルは「なまもの」寄りの表現になります。一方、「猫は生物です」では「猫」への重みが大きくなり、「いきもの」寄りの表現になります。
このように、同じ「生物」でも周囲の単語との関係性に応じてベクトルが変わる のが、Self-Attention の威力です。これにより、同じ単語でも文脈によって異なるベクトル表現を生成 できます。
BERT で試す文脈考慮型埋め込み
以下のコードでは、日本語 BERT を使って「生物」という単語が文脈によってどのように異なるベクトルになるかを確認します。
import torch
from transformers import AutoModel, AutoTokenizer
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
model_name = "tohoku-nlp/bert-base-japanese-v3"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
sentences = [
"猫は生物です", # いきもの
"犬は生物です", # いきもの
"刺身は生物です", # なまもの
"生牡蠣は生物です", # なまもの
]
embeddings = []
for text in sentences:
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# "生物" トークンの埋め込みを取得
token_ids = inputs.input_ids[0]
for i, token_id in enumerate(token_ids):
if tokenizer.convert_ids_to_tokens(token_id.item()) == "生物":
embeddings.append(outputs.last_hidden_state[0][i].numpy())
# コサイン類似度を計算
sim_matrix = cosine_similarity(embeddings)
print("「生物」トークンのコサイン類似度:")
for i, s1 in enumerate(sentences):
for j, s2 in enumerate(sentences):
if i < j:
print(f" {s1} × {s2}: {sim_matrix[i][j]:.4f}")
実行すると、「いきもの」同士、「なまもの」同士の類似度が高く、「いきもの」と「なまもの」の類似度は低くなることが確認できます。Transformer が文脈を正しく捉えていることがわかります。
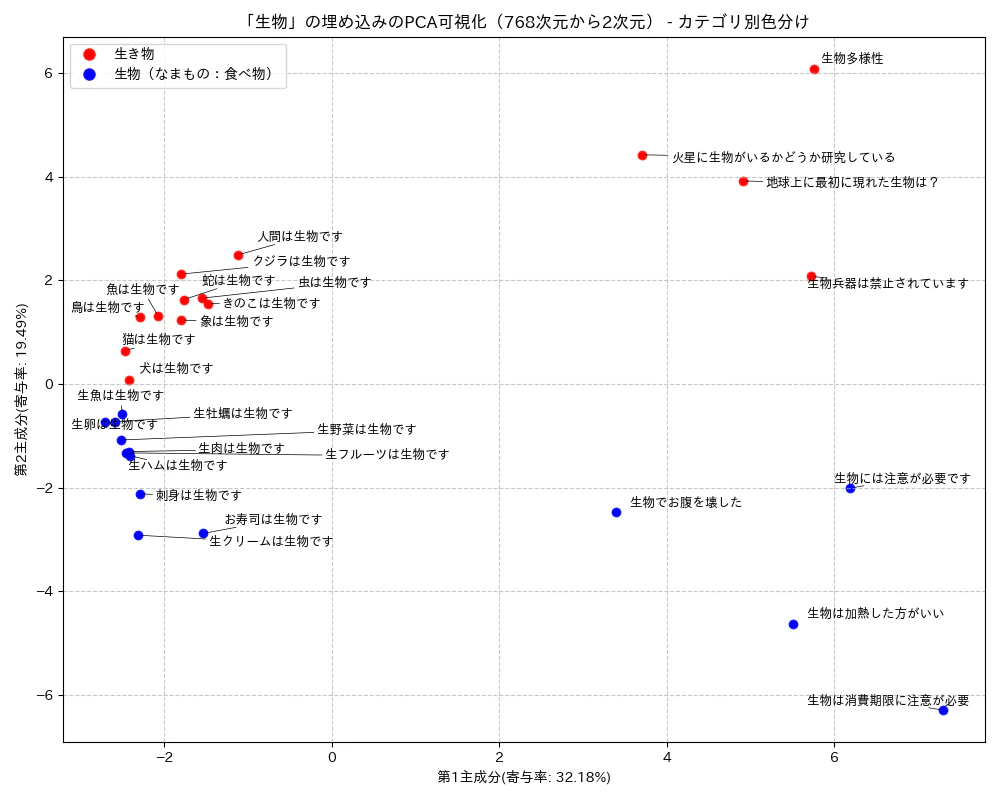
2.6 文の埋め込みとプーリング
トークン(単語)単位の埋め込みの作り方(共起関係を用いる例)をご紹介しましたが、まだ、文全体の埋め込みベクトルを生成する方法をご紹介していませんでした。RAG やベクトル検索では 文や文書全体を1つのベクトルで表現 する必要があります。
埋め込みモデルは入力テキストの各トークンに対して埋め込みベクトルを生成します。たとえば10トークンの文であれば、10個のベクトルが出力されます。これを1つのベクトルにまとめるのが プーリング(Pooling) です。
「猫はかわいい」という文埋め込みベクトル化の全体の流れは下記のようになります。
代表的なプーリング手法は以下の通りです。
| 手法 | 概要 | 特徴 |
|---|---|---|
| 平均プーリング Mean Pooling |
全トークンの埋め込みの平均 | 最も一般的。文全体の意味を均等に反映 |
| CLS Token Pooling | 先頭の [CLS] トークンの出力を使用 | BERT 系モデルで一般的 |
| Max Pooling | 各次元で最大値を取得 | 顕著な特徴を捉えやすい |
| Attention Pooling | 重要度で重み付けした平均 | 文脈に応じて適応的に重要トークンを強調 |
プーリングにより、元のトークン列の長さに依存しない 固定長のベクトル が得られます。これにより、長さの異なる文同士の類似度計算が可能になります。「三毛猫の毛色はどのように決まりますか?」のような短い質問文とドキュメントの類似度を計算して、三毛猫の毛色の決定メカニズムを詳細に説明したドキュメント(のチャンク)を見つけ出すようなことが可能となります。
| 質問文 | ドキュメント |
|---|---|
| 三毛猫の毛色はどのように決まりますか? | 三毛猫の毛色は、主にX染色体の遺伝とX染色体の不活性化という2つの仕組みで決まります。まず、猫の毛色を決める遺伝子のうち、オレンジ(茶色)と黒の色を決める遺伝子はX染色体上にあります。オレンジを作る対立遺伝子(O)と黒を作る対立遺伝子(o)があり、メス猫はX染色体を2本持つため、片方にO、もう片方にoを持つヘテロ接合体(Oo)になることができます。ここで重要なのが「X染色体の不活性化(ライオニゼーション)」です。メスの哺乳類では、発生の早い段階で各細胞のX染色体のうち1本がランダムに不活性化されます。その結果、ある細胞ではOを持つX染色体が活性化してオレンジの毛が生え、別の細胞ではoを持つX染色体が活性化して黒い毛が生えます。このランダムな不活性化によって、オレンジと黒がモザイク状に現れるわけです。白い部分は、別の常染色体上にある白斑遺伝子(S遺伝子)によるもので、メラノサイト(色素細胞)の移動を抑制することで白い領域を作ります。つまり三毛猫の3色は、オレンジ(X染色体のO)、黒(X染色体のo)、白(常染色体のS)という異なる遺伝的メカニズムの組み合わせで生まれています。この仕組みから、三毛猫がほぼメスに限られる理由も分かります。オスはX染色体を1本しか持たないため、通常はオレンジか黒のどちらか一方しか発現できません。ごくまれにXXYの染色体異常を持つオスが三毛になることがありますが、非常に珍しいケースです。 |
2.7 質問応答への埋め込みの最適化
質問文とドキュメントは、テキストの長さが異なるだけではなく文の形式そのものが著しく異なっています。ところが、埋め込みモデルが生成したベクトルを使ったベクトル検索が意味的に似ているドキュメントを見つけることができます。これは、埋め込みモデルが質問応答に最適化されているためです。
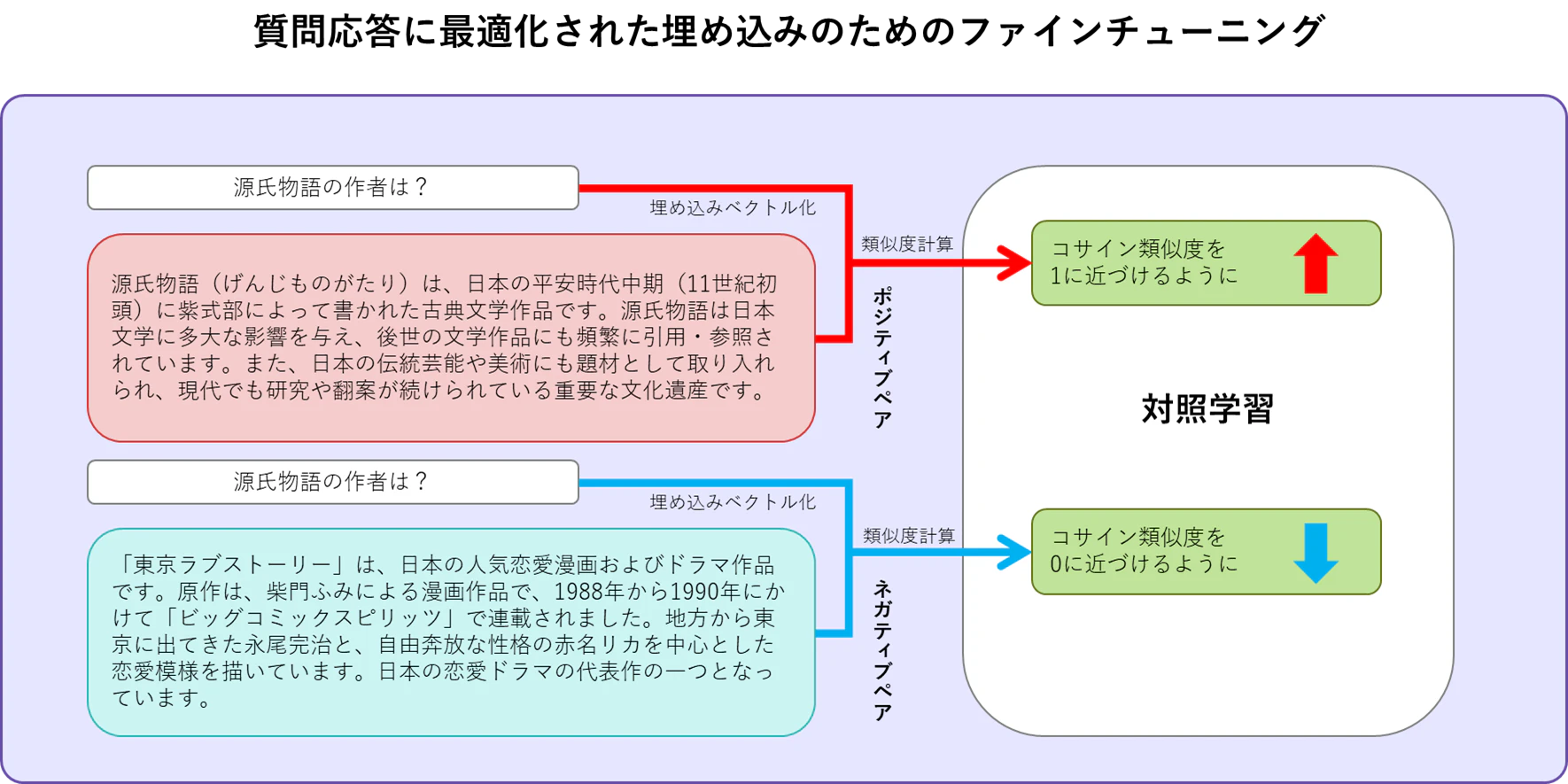
例えば、以下のようなテキストチャンク群をベクトル化してデータベースに登録してあるとします。
| テキストチャンク |
|---|
| COVID-19には多くの症状があります。 |
| COVID-19の症状は悪いです。 |
| COVID-19の症状は良くありません |
| COVID-19の症状はいろいろです |
| COVID-19の症状は悪いです。5Gの機能には、より広範なサービスカバレッジ、より多くの利用可能な接続数、および低電力消費が含まれます。 |
| COVID-19はウイルスによって引き起こされる病気です。最も一般的な症状は発熱、悪寒、および喉の痛みですが、他にもさまざまな症状があります。 |
| COVID-19の症状には、発熱や悪寒、新しい持続的な咳、嗅覚や味覚の喪失や変化など、さまざまな症状が含まれます。 |
| 認知症には以下の症状があります。記憶喪失、判断力の低下、および混乱を経験すること。 |
| COVID-19には以下の症状があります。記憶喪失、判断力の低下、および混乱を経験すること。 |
| COBIT 2019は政府のデジタル・ガバメント計画を支えるガバナンス態勢を整備する際の最適な枠組みです。 |
| 新型コロナ感染症の症状には、発熱や悪寒、新しい持続的な咳、嗅覚や味覚の喪失や変化など、さまざまな症状が含まれます。 |
| 鳥インフルエンザの症状には、高熱、咳、筋肉の痛み、倦怠感、頭痛、その他の症状が含まれます。 |
| COVID-19は、SARS-CoV-2(新型コロナウイルス)によって引き起こされる感染症です。2019年12月に最初に確認され、その後、世界的なパンデミックとなりました。症状としては、発熱、咳、息切れ、倦怠感、嗅覚や味覚の喪失などがあります。また、感染経路は、主に飛沫感染と接触感染ですが、空気感染の可能性もあります。高齢者や基礎疾患のある方は重症化リスクが高く、死亡率も高いとされています。COVID-19に対しては、ワクチン接種や手洗い、マスク着用、ソーシャルディスタンスなどの予防措置が推奨されています。パンデミックは世界中の医療システムや経済に大きな影響を与えました。 |
ここで、"COVID-19の症状は?" というクエリーを投げたらどうなるでしょうか?
単純にクエリーと字面が似ている文に高い類似度が与えられるとすると
| テキストチャンク |
|---|
| COVID-19には多くの症状があります。 |
| COVID-19の症状は悪いです。 |
| COVID-19の症状は良くありません |
| COVID-19の症状はいろいろです |
といったあたりがベクトル検索結果の上位を占めると推測できます。
しかし、実際にやってみるとこのような結果となりました。
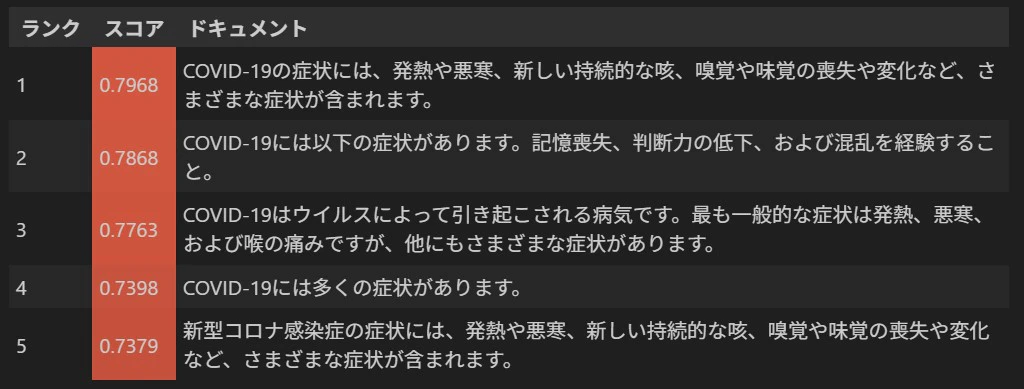
質問応答に最適化された埋め込みモデルが生成するベクトルは、単純に字面が似ているテキストに高い類似度を与えるわけではないことがわかります。
この検証は以下の記事で詳細をご紹介しています。
2.8 Transformer ベースの文脈考慮型埋め込みモデルの実用上のトレードオフ
Transformer ベースは精度が高い反面、推論コストが高く、文ごとにすべてのトークン間でAttention計算(すべてのトークンペア間でスコアを計算)が走るため、レイテンシやメモリが問題になるケースがあります 。そのため、低レイテンシやエッジ環境では、Static Embedding や 軽量CNNモデルが今も活躍しています。
ご参考
第3章 ベクトル検索の仕組み
3.1 RAG における埋め込みの役割
RAG(Retrieval-Augmented Generation)は、LLM の回答生成を外部データベースの検索で補強する手法です。RAG の検索には、ベクトルデータベース以外のデータベースや検索エンジンを活用することもできますが、
ここでは、埋め込みが果たす役割を全体像として見てみましょう。
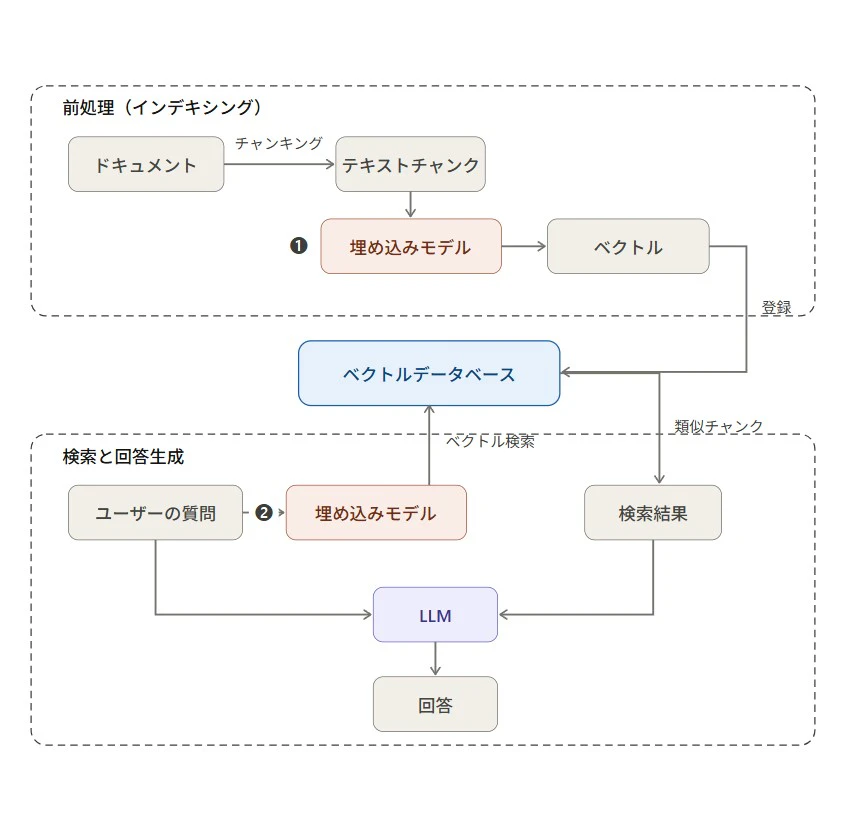
この全体フローの中で、埋め込みは以下の2箇所で登場します。
- 前処理(インデキシング) で、ドキュメントを分割したチャンクをベクトル化してデータベースに登録
- 検索時 に、ユーザーの質問をベクトル化して、データベース内の類似チャンクを探す
3.2 ベクトルデータベースとは
ベクトルデータベースは、埋め込みベクトルを格納し、ベクトル間の類似度に基づく検索を高速に実行するためのデータベースです。
ベクトルデータベースに格納されるデータのイメージは以下のようになります。
| ID | テキストのチャンク | 埋め込みベクトル | メタデータ |
|---|---|---|---|
| 1 | 遠い昔、はるか彼方の銀河系で… | [1.0, 1.2, 0.8, ...] | エピソード4.pdf |
| 2 | 時は内乱のさなか。凶悪な銀河帝国の… | [2.0, 0.3, 0.5, ...] | エピソード4.pdf |
| 3 | 反乱軍にとって試練の時だった… | [0.7, 1.5, 1.8, ...] | エピソード5.pdf |
3.3 ベクトル間の「近さ」の測り方
似たものを見つけるには、埋め込み間の距離(または類似度)を計算します。代表的な指標は3つあります。
| 指標 | 説明 | 特徴 |
|---|---|---|
| L2 距離(ユークリッド距離) | 空間上の直線的な距離 | 直感的だが、ベクトルの大きさの影響を受ける |
| コサイン距離 | ベクトル間の角度に基づく距離(1 − コサイン類似度) | 方向の類似性を測る。最も広く使われる |
| 内積(ドットプロダクト) | ベクトルの内積 | 正規化済みベクトルではコサイン類似度と同値。計算が高速 |
各指標のイメージ
埋め込みベクトルの「近さ」を測る方法を、2次元の簡単な例で見てみましょう。

コサイン類似度 は、2つのベクトルが原点から伸びる 矢印 だと考えたとき、その 矢印同士の角度で類似度を測る方法です。
- 同じ方向を向いている(角度が小さい)→ コサイン類似度 ≈ 1(とても似ている)
- 直角(90°)→ コサイン類似度 ≈ 0(関連が薄い)
- 正反対を向いている(180°)→ コサイン類似度 ≈ -1(意味が正反対)
重要なのは、矢印の 長さ(大きさ)は無視して、方向だけで比較する という点です。これにより、長い文と短い文のように埋め込みの大きさが異なる場合でも、意味の類似性を安定して評価できます。
コサイン距離 は、以下のように定義されます。
コサイン距離 = 1 − コサイン類似度
コサイン類似度は値が大きい程2つのベクトルが似ているわけですが、ベクトル間の距離と言った時には直観的に値が小さい方が近いというイメージになります。
そこで、この変換をすることで、値が小さい程近いという距離の概念に合わせているわけです。
内積(ドットプロダクト) は、2つのベクトルの各要素をかけ合わせて足し合わせた値です。
ベクトルA = [0.8, 0.3]
ベクトルB = [0.7, 0.4]
内積 = 0.8 × 0.7 + 0.3 × 0.4 = 0.56 + 0.12 = 0.68
内積は 方向が似ていて、かつ大きさが大きい ほど値が大きくなります。ベクトルが正規化済み(大きさが1に揃えてある)の場合は、内積とコサイン類似度は同じ値になります。
L2 距離(ユークリッド距離) は、日常で使う「2点間の直線距離」と同じ概念を高次元に拡張したものです。値が 小さいほど似ている ことを意味します(コサイン類似度や内積とは大小の向きが逆である点に注意してください)。
実務 TIPS: OpenAI や Cohere などの多くの埋め込みモデルは、モデルの訓練はコサイン類似度で行われていますが、ベクトルを正規化(大きさを1に調整)して出力します。この場合、内積とコサイン類似度は同じ値になるため、ベクトル検索時には、計算コストの低い内積を使うのが効率的です。
詳細補足
埋め込みモデル訓練時の指標と推論時の指標の関係
埋め込みモデルは訓練時の損失関数(contrastive loss、triplet lossなど)の中で特定の距離指標を前提に最適化されます。そのため、推論時にも同じ指標を使うのが原則です。モデルのドキュメントに「cosine similarity推奨」などと書かれているのはこのためです。
実用上の補足
ただし、よく使われるモデル(OpenAIのtext-embeddingシリーズやSentence-Transformersの多くなど)は出力ベクトルをL2正規化して単位ベクトルにしています。この場合、コサイン類似度とL2距離は単調な関係(ランキングが一致する)になり、コサイン類似度が高い なら L2距離が小さい、その逆も真という関係が常に成り立つため、どちらを使っても検索結果の順序は同じになります。
まとめ
原則: モデルが想定している指標を使う
実際: 多くの有名モデルは正規化済みなので、コサイン類似度とL2距離で結果が変わらないケースが多い
注意が必要なケース: 内積(dot product)を指標とするモデルでは、ベクトルのノルムに意味がある(例:検索の「重要度」を反映するなど)場合があり、この場合はコサイン類似度に置き換えると情報が失われます
モデルを選ぶ際は、ドキュメントで推奨されている距離指標を確認するのが一番確実です。
3.4 ベクトル検索の実行例
Oracle AI Database の AI Vector Search を使ったベクトル検索のコード例です。
CREATE TABLE doc_table (
id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
source VARCHAR2(500),
content CLOB,
embedding VECTOR
);
INSERT INTO doc_table (source, content, embedding)
VALUES (
'harry_potter_ch4.txt',
'ハグリッドは7月31日の深夜、嵐の中の小屋にやってきた。彼は…',
VECTOR_EMBEDDING(MULTILINGUAL_E5_LARGE USING
'ハグリッドは7月31日の深夜、嵐の中の小屋にやってきた。彼は…' AS data)
);
INSERT INTO doc_table (source, content, embedding)
VALUES (
'harry_potter_ch5.txt',
'ダイアゴン横丁でハグリッドはハリーをオリバンダーの杖の店に…',
VECTOR_EMBEDDING(MULTILINGUAL_E5_LARGE USING
'ダイアゴン横丁でハグリッドはハリーをオリバンダーの杖の店に…' AS data)
);
-- ... 残りのドキュメントも同様に INSERT ...
CREATE VECTOR INDEX doc_table_hnsw_idx
ON doc_table (embedding)
ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 95;
SELECT content, source,
VECTOR_DISTANCE(
embedding,
VECTOR_EMBEDDING(MULTILINGUAL_E5_LARGE USING
'ハグリッドがホグワーツへの入学案内書を持ってきたのはいつですか?' AS data),
COSINE
) AS score
FROM doc_table
ORDER BY score
FETCH APPROXIMATE FIRST 4 ROWS ONLY WITH TARGET ACCURACY 95;
「ハグリッドがホグワーツへの入学案内書を持ってきたのはいつですか?」というクエリーで検索すると、文書中に「入学案内書」というキーワードが直接含まれていなくても、意味的に関連する箇所 が検索結果の上位に現れます。これがキーワード検索にはないベクトル検索の強みです。
この例では、埋め込みモデルは、multilingual-e5-large という高性能な多言語モデル(オープンソース)をデータベースにロード(内臓)してベクトル生成をしています。埋め込みモデルをデータベースにロードする手順については、Oracle Autonomous AI Database に高性能な大規模埋め込みモデルをロードしてインデータベースでベクトルを生成するをご参照ください。
3.5 近似最近傍探索(ANN)
データベースに数百万件のベクトルがある場合、すべてのベクトルとの距離を計算していたのでは、計算コストが非常に高く実用的ではありません。そこで使われるのが 近似最近傍探索(ANN: Approximate Nearest Neighbor) です。
ANN は完全な精度をわずかに犠牲にする代わりに、数桁のオーダーで検索速度を向上させます。
HNSW アルゴリズム
代表的な ANN アルゴリズムが HNSW(Hierarchical Navigable Small World) です。ChromaDB や Oracle AI Database 26ai AI Vector Search でも採用されています。
Oracle AI Database 26ai のAI Vector Search は複数のインデックス・タイプをサポートしていますがインメモリ近傍グラフ・ベクトル索引を作成することによりHNSWアルゴリズムを利用可能となります。
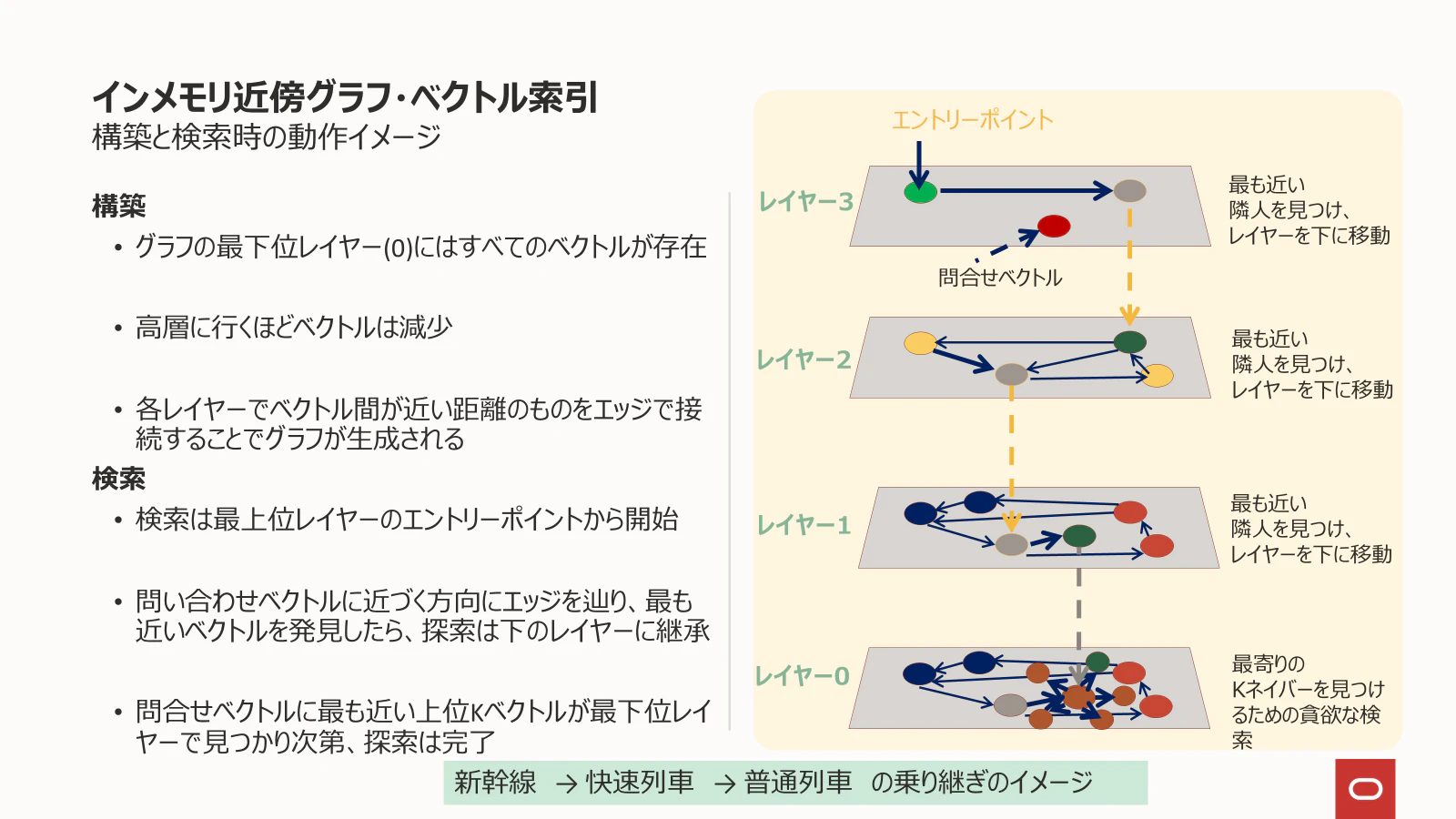
Oracle AI Vector Search 技術詳細より借用
HNSW は多層のグラフ構造を構築し、上位層から徐々に下位層へと探索範囲を絞り込むことで、効率的に類似する埋め込みを見つけ出します。イメージとしては、世界地図で大まかな位置を特定してから、詳細な地図で正確な場所を探すようなものです。
精度と速度のトレードオフ
ANN の検索精度は search recall@k というメトリックで表されます。これは「厳密な最近傍 k 件のうち、ANN が何件カバーしているか」を示す指標です。
興味深いことに、最近の研究 "Toward Optimal Search and Retrieval for RAG"(2025)では、RAG においては search recall@k を 70% 程度まで落としても RAG の最終的な性能にはあまり影響しないことが報告されています。つまり、検索精度を少し緩めることで、検索速度とメモリ効率を大きく向上できる余地があるということです。
3.6 埋め込みの可視化
高次元の埋め込みベクトルは人間が直接見ることはできませんが、次元削減手法を使って2次元に射影することで可視化できます。
以下は、総務省の共通相談チャットボット Govbot に搭載されている FAQ データの「問い」を、Cohere Embed Multilingual V3 で埋め込んでから UMAP で 2次元に射影したものです。
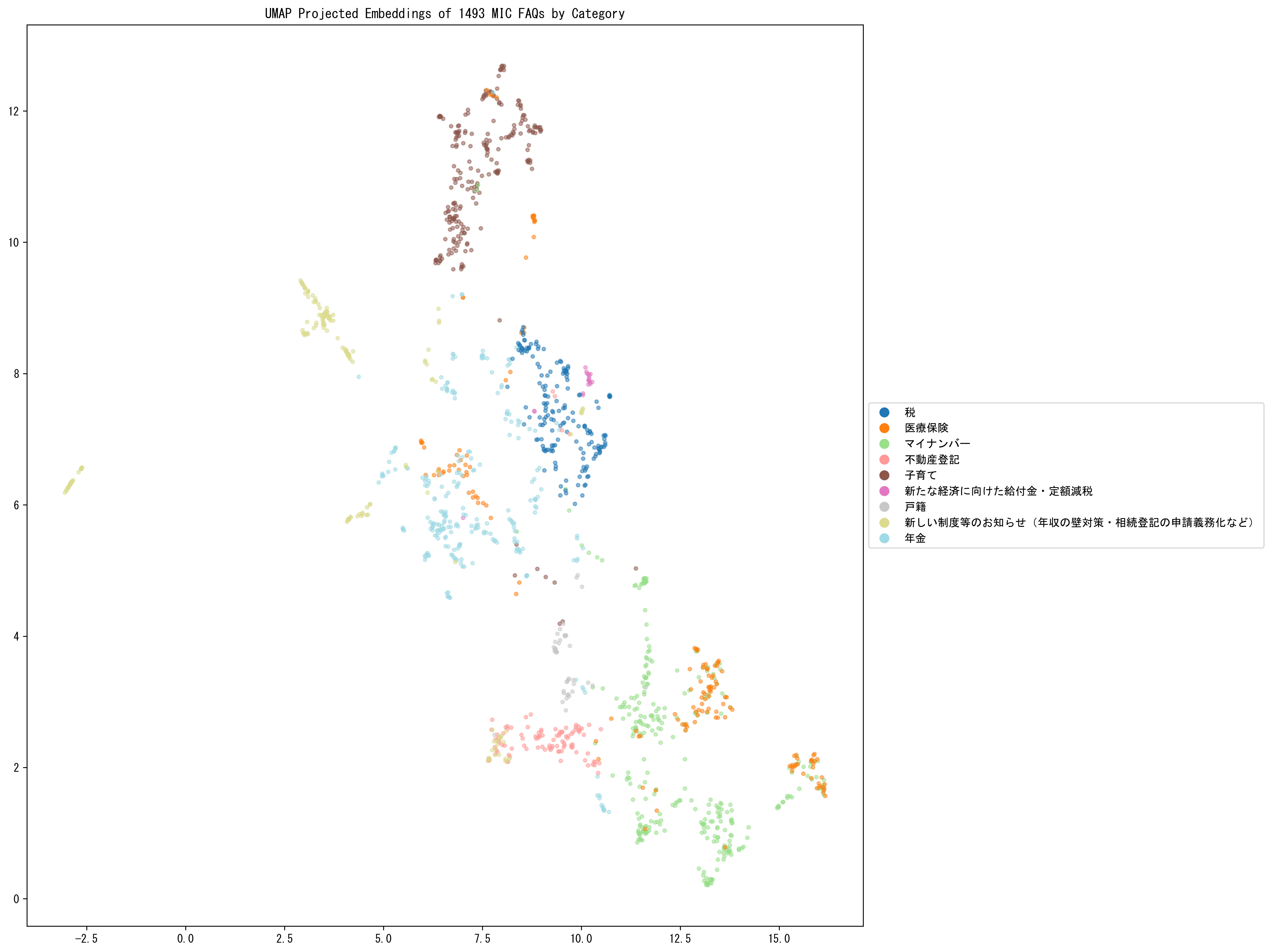
圧縮された2次元空間でも、「問い」が大分類ごとにクラスターを形成していることが確認できます。
次の画像は、「問い」と「回答」を連結して Cohere Embed 3 で埋め込みベクトル化したものを UMAP で次元削減(二次元へ射影)して可視化したもので、赤いデータポイントは103万円、150万円、106万円、130万円の壁に関するQAで、青はそれ以外を表しています。
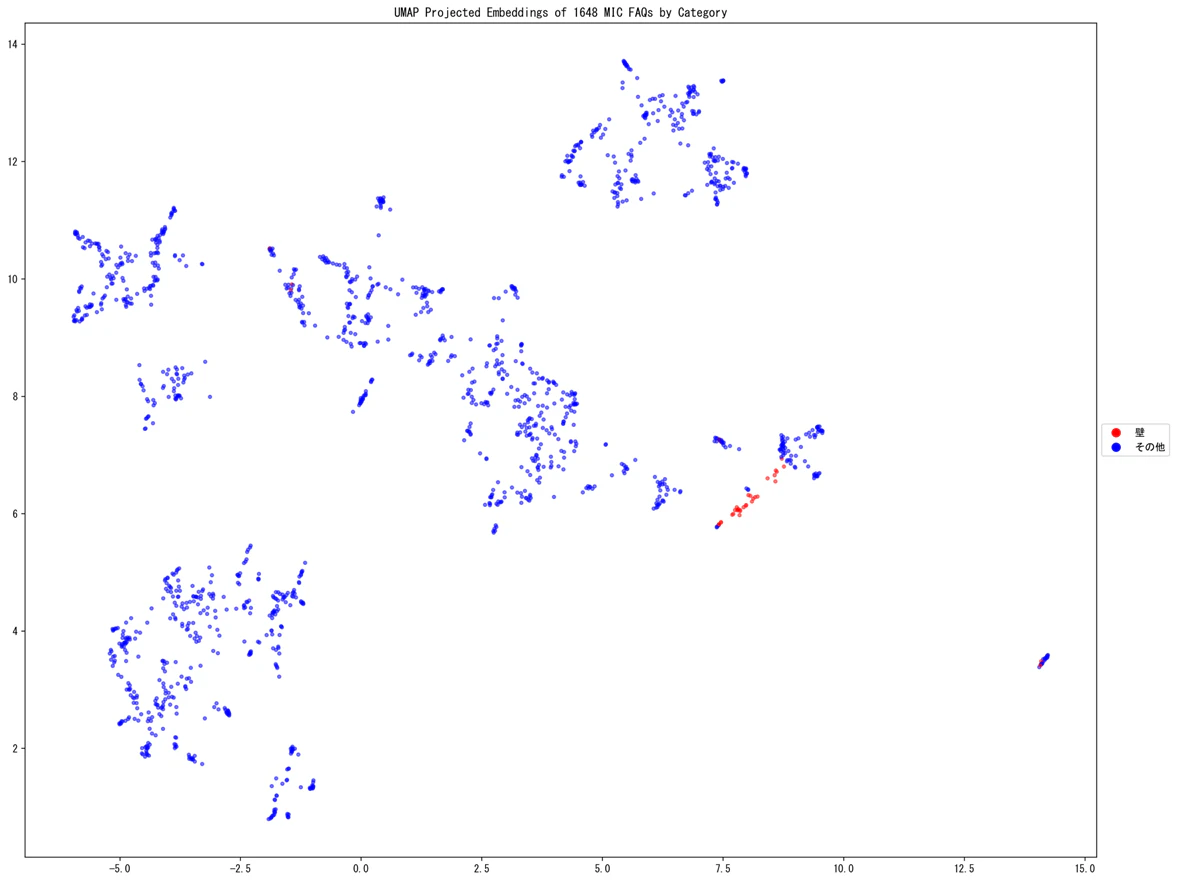
「103万円の壁」「106万円の壁」「130万円の壁」「150万円の壁」に関する QA は同じ領域に集まっています。
可視化ツール: WizMap や UMAP、PCA などを組み合わせて利用できます。UMAPは局所的な構造を強調するため、PCAなどの大局的構造に注目する手法との併用が推奨されます。
第4章 マルチモーダル埋め込み
4.1 テキストと画像を同じ空間に
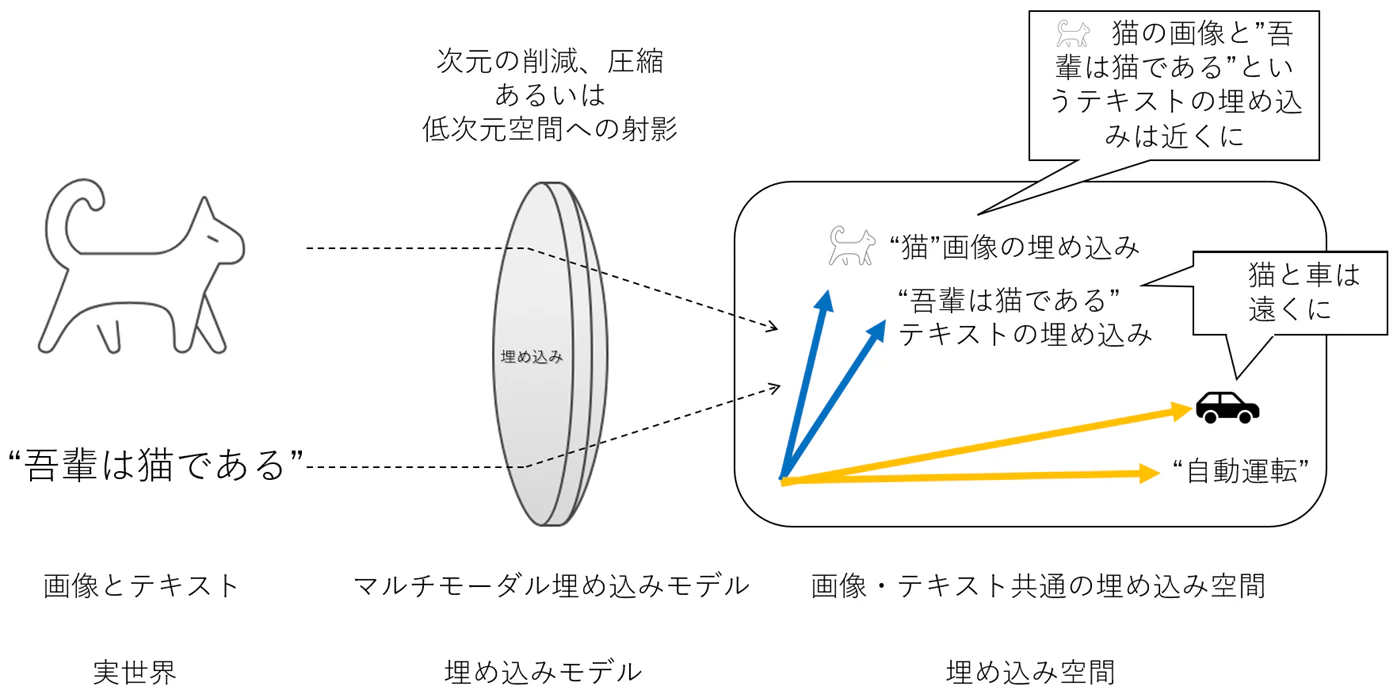
ここまではテキストの埋め込みを見てきましたが、埋め込みの威力が真に発揮されるのは マルチモーダル(複数の種類のデータ) を扱うときです。
マルチモーダル埋め込みモデルは、テキスト、画像、動画、音声など 異なる種類のデータを共通の埋め込み空間にマッピング します。これにより、テキストで画像を検索したり、画像で類似画像を検索したりすることが可能になります。
4.2 マルチモーダル埋め込みモデルの仕組み
マルチモーダル埋め込みの代表格が、2021年に OpenAI が公開した CLIP(Contrastive Language-Image Pre-training) です。
CLIP は 4億ペア の画像とテキストの組み合わせから学習されています。学習の仕組みを簡潔に説明すると以下の通りです。

Learning Transferable Visual Models From Natural Language Supervision
Figure 1. Summary of our approach.
- N個の画像-テキストペアを用意
- テキストエンコーダーと画像エンコーダーでそれぞれ埋め込みベクトルを生成
- 正しいペア(対応する画像とテキスト)の類似度が高く、正しくないペアの類似度が低くなるように学習
この学習方法を 対照学習(Contrastive Learning) と呼びます。「対照」という名前は、正しいペアと正しくないペアを 対照(コントラスト)させて区別する ことに由来しています。
具体的なイメージとしては、クラスの集合写真を思い浮かべてください。「田中さんの写真」というテキストと実際の田中さんの顔写真はペアとして近づけ、「田中さんの写真」と佐藤さんの顔写真は引き離す — これをクラス全員分繰り返すと、やがて名前(テキスト)を聞いただけで正しい顔写真(画像)を見つけられるようになります。CLIP はこの学習を 4億ペア という途方もない規模で行ったモデルです。
対照学習により、テキストと画像が同一の埋め込み空間上にマッピングされます。意味的に近い画像とテキストは近くに、異なるものは遠くに配置されます。
日本語に特化したモデルとして Japanese Stable CLIP もあり、GPU 環境がなくても動作する軽量なモデルです。
また、API 利用の形で提供されているマルチモーダル埋め込みモデルもあります。OCI Generative AI サービスでは、Cohere Embed 4 という多言語のマルチモーダル埋め込みモデルを利用できます。
4.3 マルチモーダル検索の実例
マルチモーダル埋め込みを使うと、以下のような検索が実現できます。
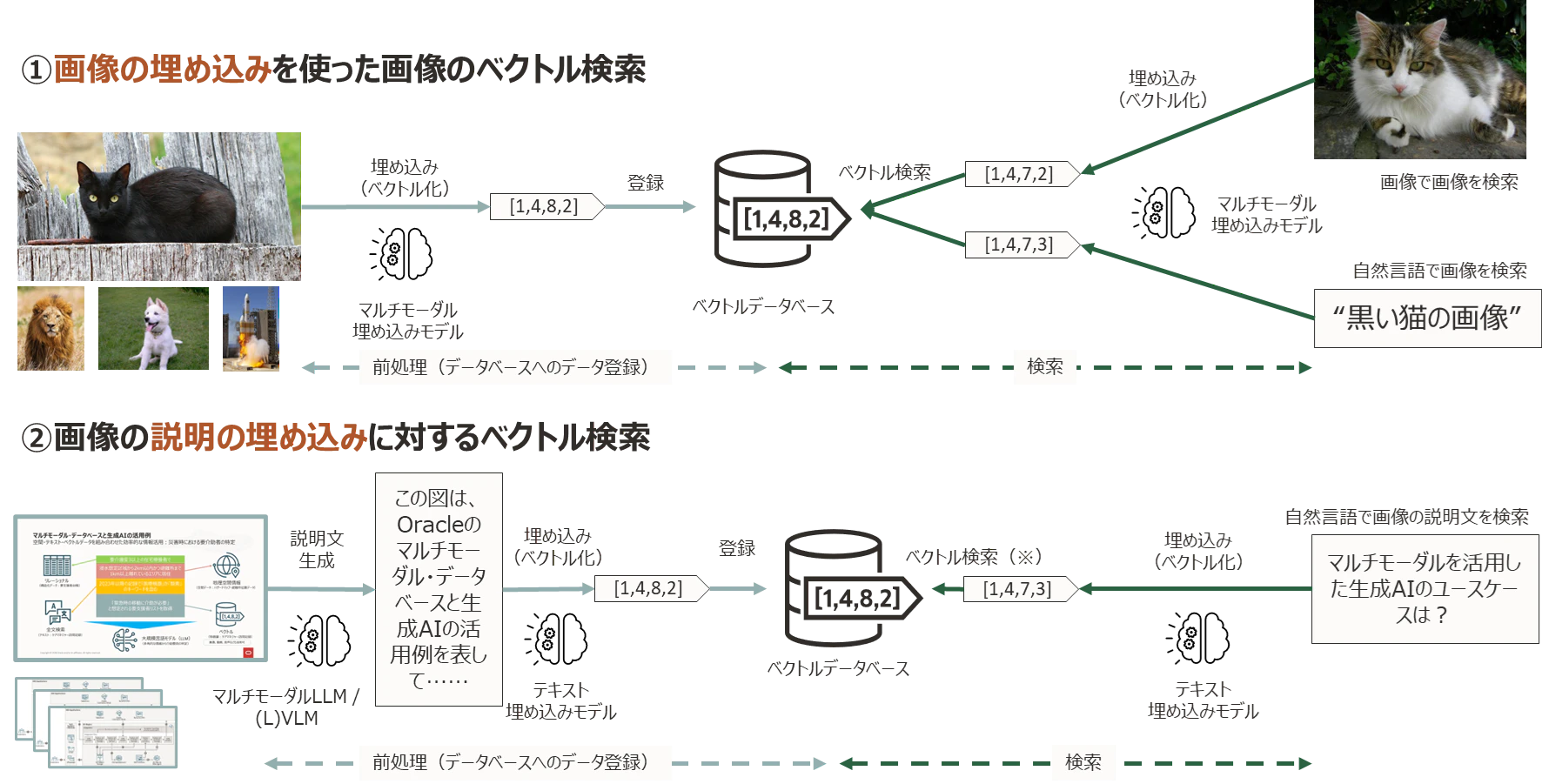
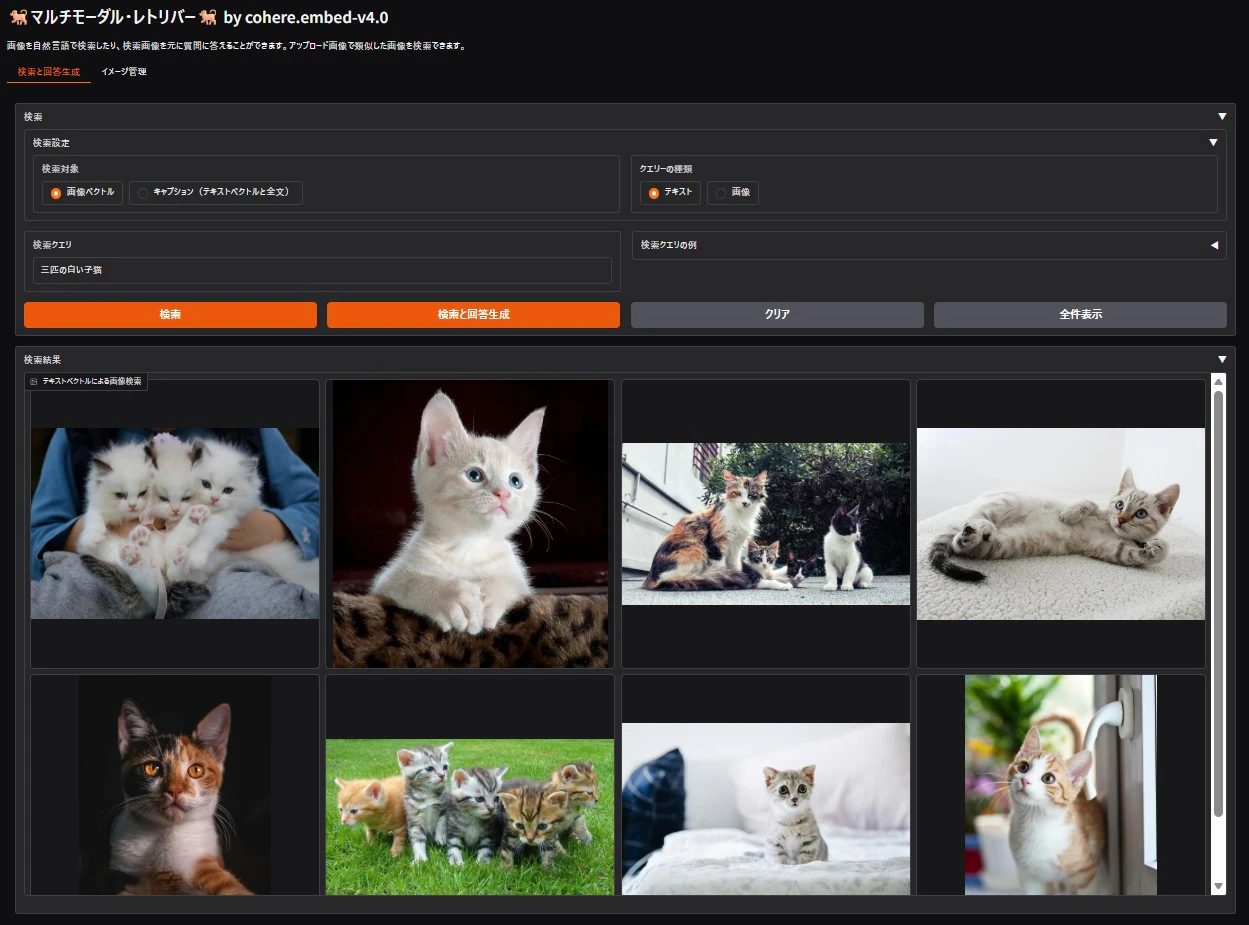
テキストで画像を検索
ユーザーが「三匹の白い子猫」というテキストを入力すると、埋め込みモデルがテキストをベクトル化し、データベース内の画像の埋め込みベクトルとの類似度を計算して、関連する猫の画像を返します。
なお、ベクトル検索ではクエリーのベクトルに近い順に検索結果を返しますので、順位の下位には猫以外の画像も含まれる可能性があります。
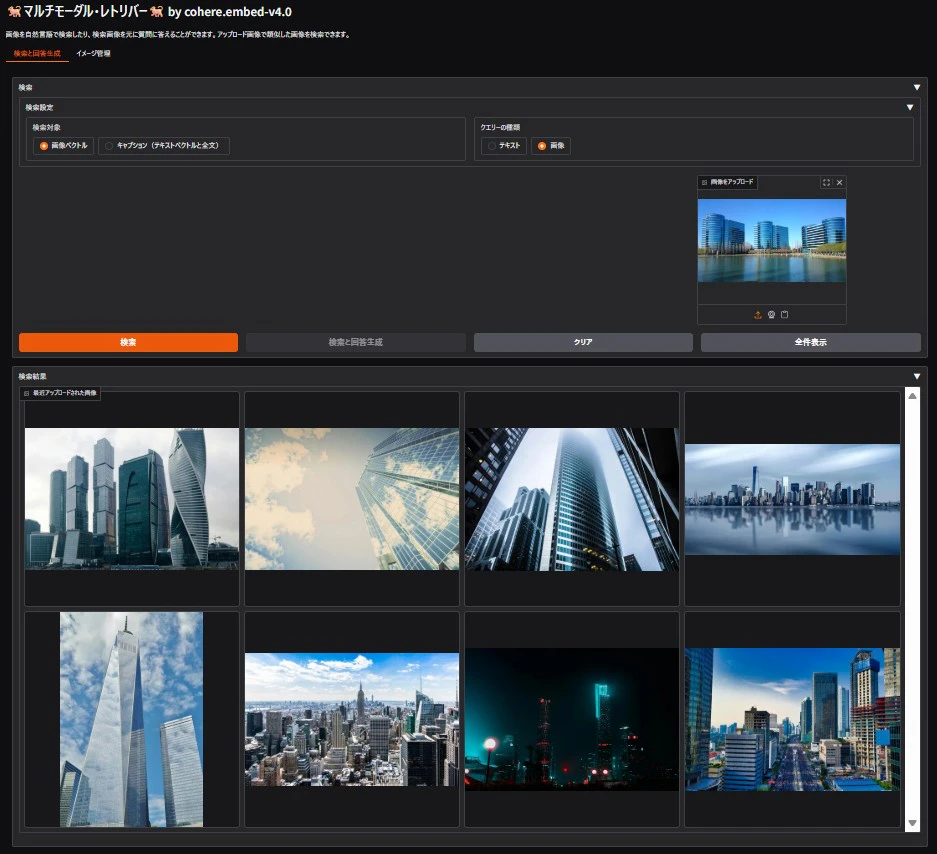
画像で画像を検索
アップロードした画像をクエリーとして、データベース内の類似画像を検索することもできます。
テキストで画像+テキストを横断検索
Cohere Embed V3 のような新しいマルチモーダル埋め込みモデルでは、画像とテキストの混合データストアに対する横断検索も可能です。従来のモデルでは「テキスト埋め込みと画像埋め込みが別のクラスターを形成する」という課題がありましたが、最新モデルではこの問題が克服されつつあります。
参考記事: Cohere のマルチモーダル埋め込みモデルを使い倒す!
4.4 マルチモーダル埋め込み(CLIP) の画像生成への応用
CLIP は画像検索だけでなく、画像生成 の基盤技術としても活躍しています。
OpenAI の DALL-E 2 で採用されている unCLIP のアーキテクチャでは、以下の流れで画像が生成されます。
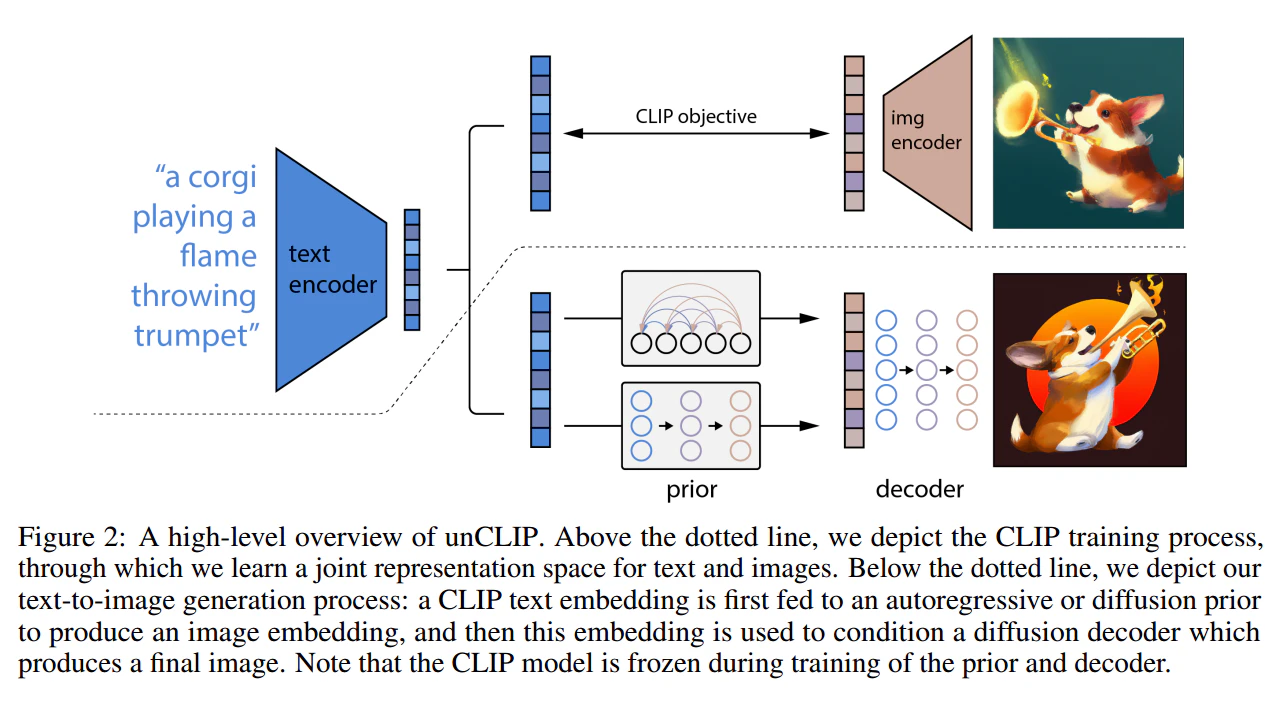
OpenAI の論文(Hierarchical Text-Conditional Image Generation with CLIP Latents)から引用
- CLIP のテキストエンコーダーでプロンプトを テキスト埋め込み に変換
- テキスト埋め込みを拡散モデル(Diffusion Model)で 画像埋め込み に変換
- 画像デコーダーが画像埋め込みから 画像を生成
CLIP の「テキストの埋め込みと画像の埋め込みが同じ空間にある」という性質が、テキストから画像を生成するという応用を可能にしているのです。
なお、初期のテキスト画像生成モデルでは 拡散モデル(Diffusion Model) が主流でしたが、近年では Transformer をベースにした画像生成モデル(Stable Diffusion 3 / FLUX、動画生成の OpenAI Sora)も登場しており、テキスト埋め込みから画像表現を生成する方法は多様化しています。CLIP のように テキストと画像を共通の表現空間で扱う技術は、これらのモデルにおいても重要な役割を果たしています。
4.5 マルチモーダル埋め込みによる画像のトランスフォーメーション

上の動画は、概略以下のような手順で作られています。
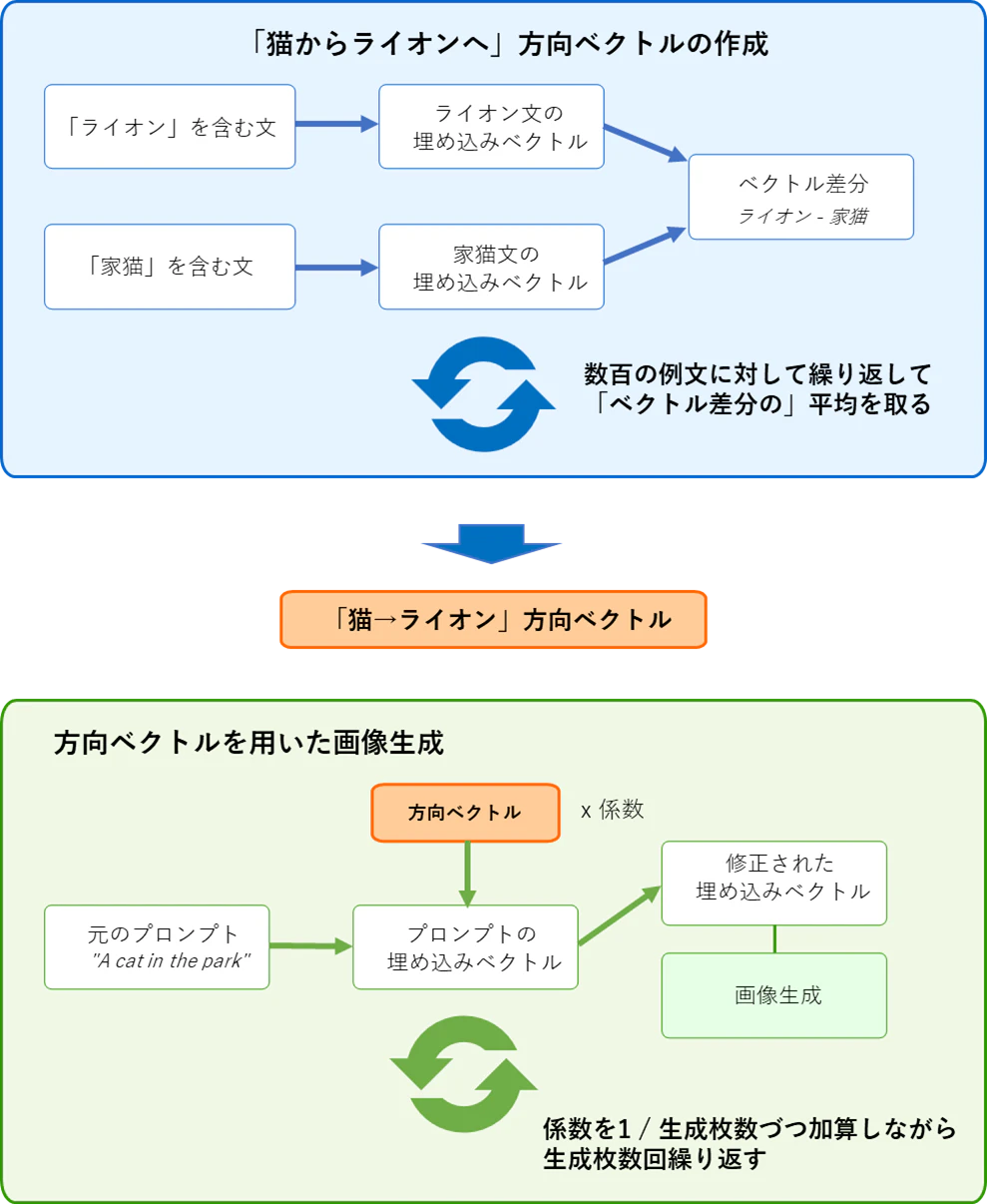
- 「猫からライオンへ」方向(埋め込み)ベクトルを作る
- "Lion"(ライオン) という単語を含んだ文をつくる
- "Domestic cat"(家猫)という単語を含んだ文をつくる
- 2つの文の埋め込みベクトルを生成する
- 2つの埋め込みベクトルの差分を取る(ライオン文 - 家猫文)
- ここまでの操作を数百回繰り返して平均を取り、これを「猫からライオンへ」方向ベクトルとする
- 画像群を生成する
- 画像生成プロンプト"A cat in the park"の埋め込みベクトルに「猫からライオンへ」方向ベクトルの、例えば1/10を加算する
- この加算された埋め込みベクトルで画像生成をガイドする
- この処理を繰り返す
下記のサイトで実際に試してみることができます。Prompt に "A cat in the park" のような動画の出発点となるプロンプトを、1st direction to steer Starting state に、「Domestic cat」のような変化の起点となるプロンプトを、2nd direction to steer Finishing state に「Lion」のような変化の終点となるプロンプトを設定して"Generate directions"をクリックすると動画が生成されます。うまく行かないことも多いですがいろいろ試して楽しんでみてください。上の GIF 画像もこのアプリケーションで作成したものです。
また、この Lattent Navigation は下記の2つを元にしています。
Semantic Sliders
Traversing through CLIP Space, PCA and Latent Directions
4.6 マルチモーダル埋め込みのその他の応用
マルチモーダル埋め込みモデルは、RAG や画像検索以外にも幅広い応用があります。
ゼロショット画像分類
埋め込みベクトルの類似度を使って、事前に学習していないカテゴリの画像分類が可能です。
ドローン空撮画像の洪水判定

Cohere Multimodal Embed 4 を使い、ドローン空撮画像が「洪水地域」か「非洪水地域」かを判定する実験を行ってみました。ゼロショットアプローチでは、再現率(洪水を見逃さずに見つけられた比率)が 81.4% でした。
セロショットアプローチとは、単純に空撮画像の埋め込みベクトルが "A satellite image of a non-flooded area of land." と "A satellite image of a flooded area of land." というテキストの埋め込みベクトルのどちらに近いか、つまり、どちらがコサイン類似度が高いかを判定するアプローチです。下のグラフで「コサイン類似度」と書かれている青い棒グラフです。
さらに、線形分類器を組み合わせることで、再現率を 89.8% まで高めることができました。下のグラフで「F2最適化線形分類器」と書かれている棒グラフです。
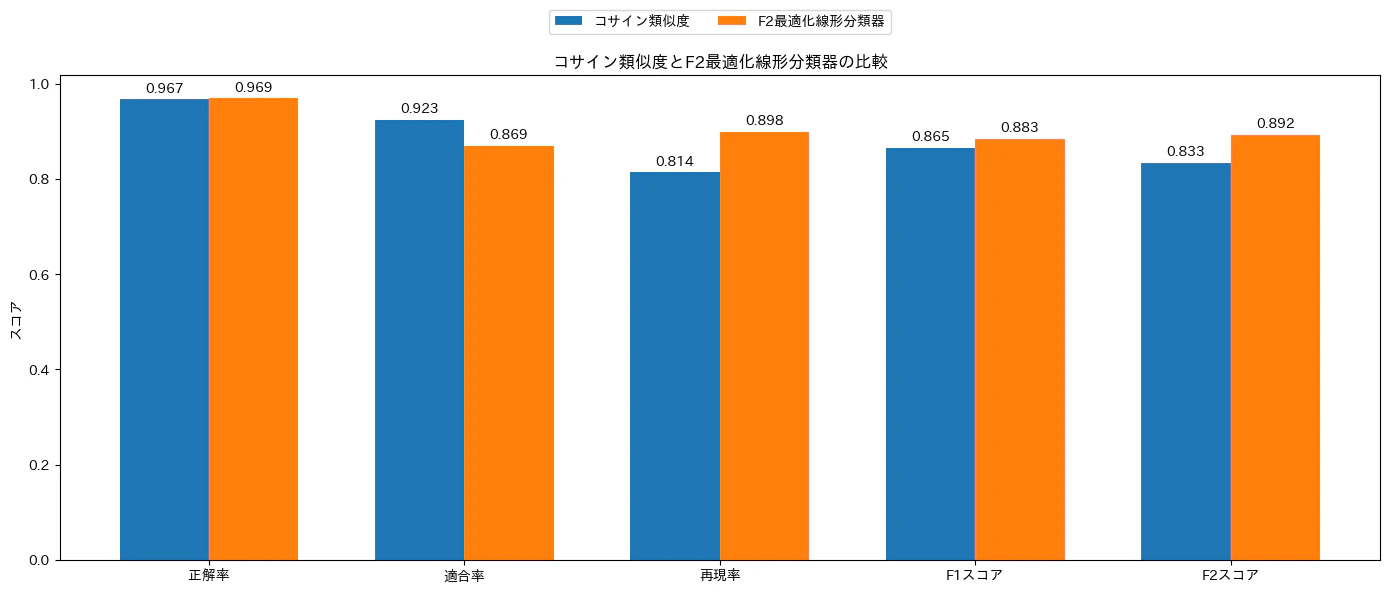
| 指標 | ゼロショット | 線形分類器(F2最適化) | 改善率 |
|---|---|---|---|
| 適合率(Precision) | 0.923 | 0.869 | -5.87% |
| 再現率(Recall) | 0.814 | 0.898 | +10.42% |
| F1スコア | 0.865 | 0.883 | +2.13% |
- 適合率(Precision) は、予測が「浸水」とされたもののうち、どれくらい実際に浸水だったかを表しています。適合率=真陽性(TP)/(真陽性(TP)+偽陽性(FP))。
- 再現率(Recall) は、実際に浸水であるデータのうち、どれくらい見逃さずに浸水と予測できたかを表しています。再現率=真陽性(TP)/(真陽性(TP)+偽陰性(FN))。
この結果は、埋め込みベクトルが画像の特徴を適切に捉えていることの証拠であり、少量の訓練データと簡素な分類器を組み合わせるだけで画像の特徴をかなり見極められることを表しています。
洪水判定のような用途では純分な精度を出すためには専用のモデルを訓練することが必要だと思いますが、用途によっては活用できそうです。
動画レコメンデーション
従来の動画レコメンデーション・アーキテクチャ
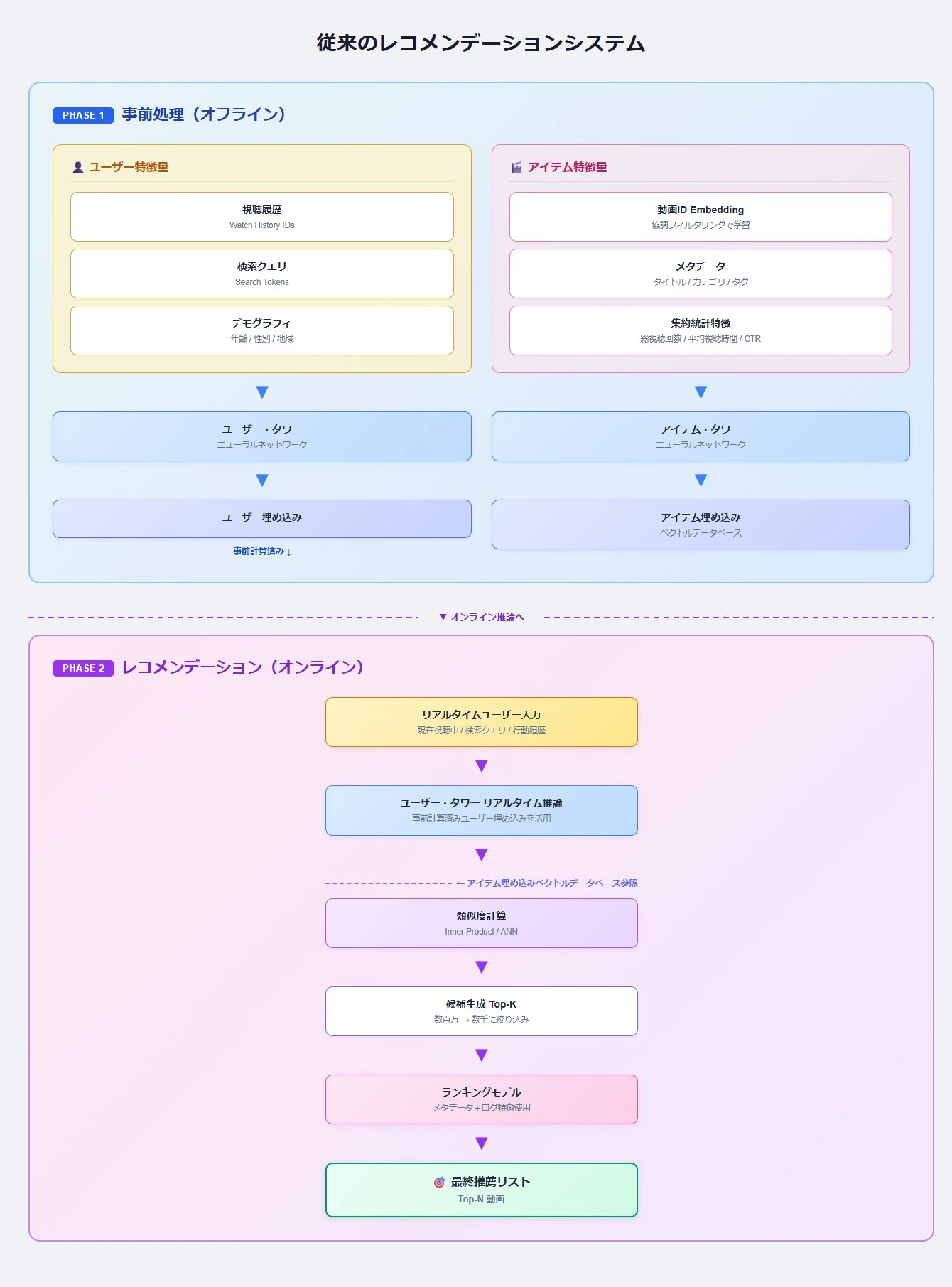
従来の動画レコメンデーションシステムでは、推薦の根拠となるアイテム(動画)の特徴やユーザーの特徴は、メタデータや行動履歴などを主な情報源としていました。つまり、動画自体や音声・音響データは活用できていないことが多かったのです。
近年のマルチモーダル化したレコメンデーション・アーキテクチャ
近年では、マルチモーダル技術の発展により動画の映像や音響の埋め込みベクトルも活用されるようになってきました。
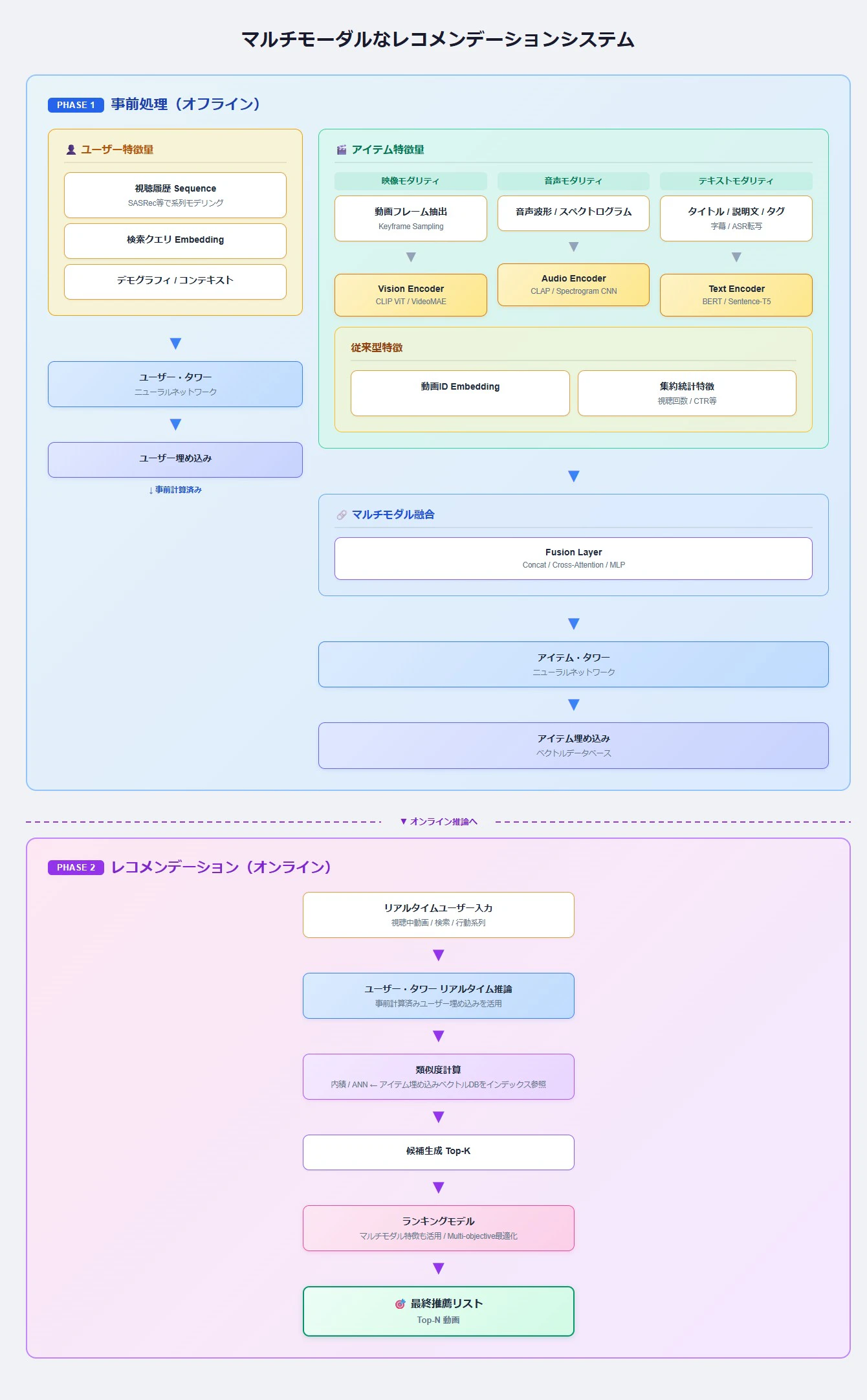
従来型では、新規動画は「動画ID Embedding が未学習」「視聴回数・CTR 等の集約統計がゼロ」という状態になります。アイテム特徴量の大部分がユーザーの行動ログに依存しているため、誰にも視聴されていない動画はまともな埋め込みベクトルを持てず、候補生成の段階でほぼ浮上しません。これはいわゆる コールドスタート問題(cold-start problem) と呼ばれるものです。
マルチモーダル型では、動画がアップロードされた時点で以下の特徴量を即座に計算できます。
映像:フレームを Vision Encoder(CLIP等)に通せば埋め込みが得られる
音声:Audio Encoder(CLAP等)で埋め込みが得られる
テキスト:タイトル・説明文・タグを Text Encoder で埋め込みにできる
つまり、視聴履歴がゼロでも「この動画はどんなコンテンツか」をベクトル空間上で表現でき、既存の類似動画の近くに配置されます。結果として、候補生成の段階で新規動画も浮上できるようになります。
ただし、完全に解消されるわけではないため様々な対策が講じられています。
ご参考:ショート動画投稿サイトの動画レコメンデーション
第5章 ベクトル検索と RAG の精度向上
5.1 RAG の精度を左右する4つの要因
RAG の検索精度(Context Recall)は、主に以下の4つの要因で決まります。
実際の PoC プロジェクトで成功するチームは、ベクトルデータベースの性能チューニングよりも、「データの質」に重点を置いている ことが多いようです。
- 元データに回答できる情報が含まれているか
- チャンク分割が適切か
- FAQなら質問+回答をセットで
- Excelなどの表が分断されてカラム名のないチャンクになっていないか
- ....
ベクトルデータベースの検索精度について、ANN(近似最近棒索引)を使わない場合は、ベクトル同士の総当たりとなりますのでデータベース製品による違いはありません。ANN を使う場合もアルゴリズムが同じでアルゴリズムを特徴づけるパラメータが同じにチューニングされていれば大きな違いはないはずです(実装上の多少の違いはあるかもしれません)。しかし、チューニングのしやすさ。難しさは製品毎の特長として表れてくるかもしれません。ちなみに、Oracle AI Database の AI Vector Search は、アルゴリズム固有のチューニングパラメータを調整する代わりにターゲットとなる精度を指定することができます。
CREATE VECTOR INDEX doc_table_hnsw_idx
ON doc_table (embedding)
ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE INNER_PRODUCT
WITH TARGET ACCURACY 95;
5.2 埋め込みモデルを正しく使う
入力タイプの使い分け
Cohere Embed のように、ドキュメント登録時とクエリー検索時で入力タイプを切り替えられる モデルがあります。
- ドキュメント登録時 →
input_type="search_document" - クエリー検索時 →
input_type="search_query"
この設定を正しく行うことで、検索精度が向上します。つまり、質問文に字面が似たドキュメントチャンクではなく、質問への回答に役立ちそうなドキュメントチャンクを検索できるようになります。
「2.7 質問応答への埋め込みの最適化」もご参照ください。
参考記事: OCI Generative AI サービスの埋め込みモデル Cohere Embed で類似性検索を試し倒す!
クロスリンガル検索
多言語対応の埋め込みモデルを使えば、日本語のクエリーで英語のドキュメントを検索するといった 言語を跨いだ検索 も可能です。Cohere Embed Multilingual V3 や V4 は100以上の言語をサポートしています。ただし、言語を跨いだ検索は同一言語内よりも精度が劣る可能性がありますので、ドキュメントを準備する手間と性能を天秤にかける必要があります。
モーダルの選択
画像を検索するという場合を例にすると以下のようなパターンが考えられます。
自然言語で検索する場合は、下記のように5つのパターンがありますがユースケース毎にそれぞれの得意不得意があります。

1. 自然言語のベクトルで画像ベクトルを検索する
- 言語・画像のマルチモーダル埋め込みモデルが必要
- 高性能モデルであれば、画像中のテキストも検索できるが精度が十分か要検証
2. 自然言語のベクトルで画像の説明文をベクトル検索する
- 言語・画像のマルチモーダル埋め込みモデルは必ずしも必要ではない
- 画像の説明文を生成するマルチモーダル LLM が必要
3. 自然言語のベクトルで画像ベクトルを検索すると同時に画像の説明文もベクトル検索する
- 言語・画像のマルチモーダル埋め込みモデルが必要
- 画像の説明文を生成するマルチモーダル LLM が必要
4. 自然言語のベクトルで、画像とその説明をまとめて埋め込んだベクトルを検索する
- mixed modal 機能を持つ言語・画像のマルチモーダル埋め込みモデルが必要(Cohere Embed 4 など)
5. 自然言語で画像の説明文を全文検索する
- 画像の説明文を生成するマルチモーダル LLM が必要
- 全文検索エンジンが必要(Oracle Text のようなもの)
- ベクトル検索が苦手とする珍しい固有名詞や IP アドレス、エラーコードなどの意味を持たない数列や文字列の検索で有利
ベクトル検索と全文検索を併用するハイブリッドもあります。
また、画像で画像を検索するという用途も考えられます。
- 画像のベクトルで画像ベクトルを検索する
- 画像の埋め込みモデル、もしくは、言語・画像のマルチモーダル埋め込みモデルが必要
5.3 チャンクサイズと取得件数(Top K)は重要
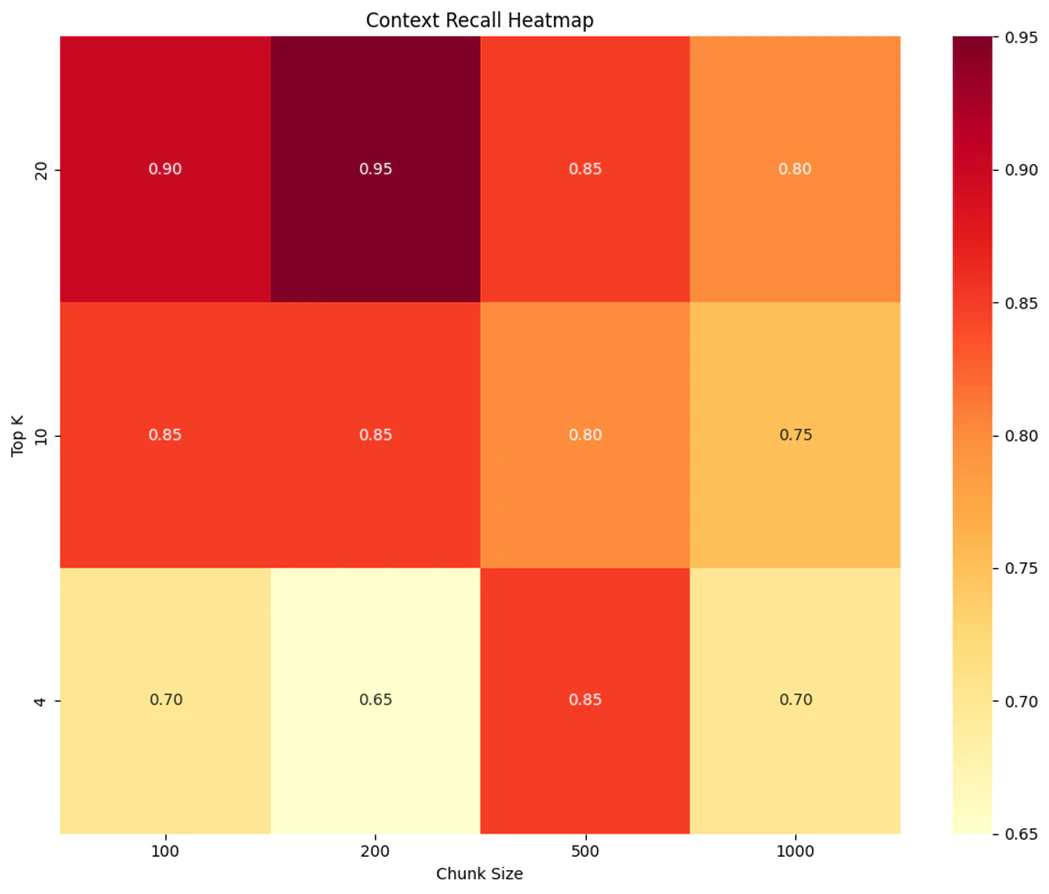
このヒートマップは、チャンクサイズと取得件数の組み合わせを変えて、Ragasの Context Recall を測定したものです。Ragas は、RAG(Retrieval-Augmented Generation)パイプラインの性能を評価するためのオープンソースフレームワークです。
- Context Recall とは、正解(Ground Truth)の文がどの程度コンテキスト(検索結果)に含まれていたかを表す指標です
- 回答に必要な情報の網羅率を表していて、正答率はこれを越えることはありません
- スコアは0~1の範囲で表され、高いほど良く、ヒートマップでは色が濃いほど良いことを表します
- Ragas の Context Recall は LLM を使って判定しているため、100%正確ではありません。Context Recall が “1” なのに、回答が間違っている場合や、逆に “0”なのに正解している場合はデータをよく確かめましょう。後者は、ハルシネーションが偶然正解していたり、事前学習した情報から回答が生成されています。
- ドキュメント、クエリーによって傾向は異なります。ユースケース毎に検証が必要です。
- 本検証は小規模(20問)であり、大きな誤差がある可能性があります。
- POC では、実際に使われるであろうものにできるだけ近いドキュメントと想定質問を多くそろえることが重要です。
5.4 遅延チャンキング ー 発想の転換
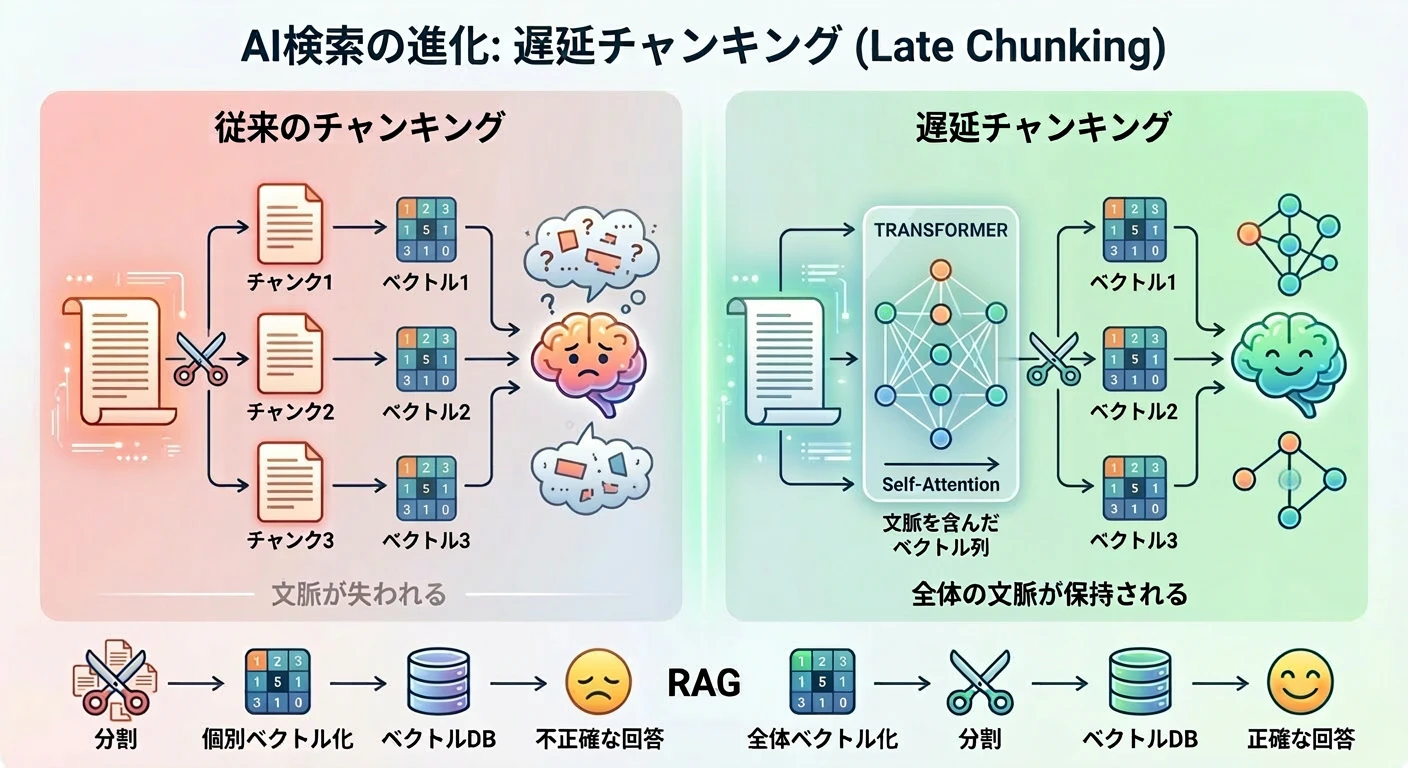
従来の RAG では「チャンキング → 埋め込み」の順に処理しますが、この順序を逆にする 遅延チャンキング(Late Chunking) という手法が注目されています。
従来手法の課題
従来手法では、文書を複数のチャンクに分割し、それぞれのチャンクをベクトル化します。
この手法では、チャンクに分割した時点で チャンク間の文脈が失われてしまう という問題があります。
上の図で言うと、チャンク1、2,3は自分自身のことしか知らず他のチャンクにどのような情報があるのか知らないということです。
この例では、「星風テクノロジーズの予測分析プラットフォームの特徴は?」というクエリーで検索されると、チャンク2、チャンク4の「同社」が「星風テクノロジーズ」を指すのか、「蒼月ロボティクス」を指すのかわからないので、検索結果の上位にチャンク4(蒼月ロボティクスの予測分析プラットフォームに関するチャンク)が現れる可能性が高くなります。
そして、チャンク1も会社名が一致していますので、検索結果の上位に現れることになります。もし、この2つのチャンクを LLM に渡して回答を生成したとしたらどうなるでしょうか?
星風テクノロジーズ株式会社に新しい予測分析プラットフォームが爆誕することになります。
遅延チャンキングの仕組み
遅延チャンキングでは、処理順序を逆にします。
Transformer の Self-Attention は文書全体のトークン間の関係を計算するため、先に文書全体を処理すると、各トークンのベクトルに「文書全体の文脈」が埋め込まれます。その後にチャンク分割しても文脈情報は保持されるため、「同社 = ○○社」という情報がベクトルに反映された状態で検索に使えます。
Perplexity の pplx-embed ファミリー
Perplexity が提供する pplx-embed は、遅延チャンキングを実装した埋め込みモデルファミリーです。Perplexity AI の APIサービスで利用することもできますし、モデル自体が MIT ライセンスで公開されていますのでオンプレミスやクラウドの閉域環境にセルフホストして利用することもできます。
| モデル | 用途 |
|---|---|
| pplx-embed-v1 | クエリーの埋め込み、通常のチャンク埋め込み |
| pplx-embed-context-v1 | 文書文脈を考慮したチャンク埋め込み(遅延チャンキング) |
import requests
HEADERS = {
"Authorization": f"Bearer {PERPLEXITY_API_KEY}",
"Content-Type": "application/json",
}
# 遅延チャンキング(文書ごとにチャンクをグループ化して入力)
resp = requests.post(
"https://api.perplexity.ai/v1/contextualizedembeddings",
headers=HEADERS,
json={
"input": [
["文書Aのチャンク1", "文書Aのチャンク2"],
["文書Bのチャンク1", "文書Bのチャンク2"],
],
"model": "pplx-embed-context-v1-0.6b",
},
)
# 検索時は通常版を使用
resp = requests.post(
"https://api.perplexity.ai/v1/embeddings",
headers=HEADERS,
json={
"input": ["蒼月ロボティクスの予測分析サービスは?"],
"model": "pplx-embed-v1-0.6b",
},
)
実験では、代名詞や指示語の解決が必要なクエリーにおいて、従来手法で検索上位に入らなかった正解チャンクが遅延チャンキングにより1〜3位に浮上することが確認されています。
参考記事: チャンキングしてからベクトル化するか、ベクトル化してからチャンキングするか ー Perplexity の遅延チャンキングを試してみた
5.5 データベースへの埋め込みモデルの内蔵
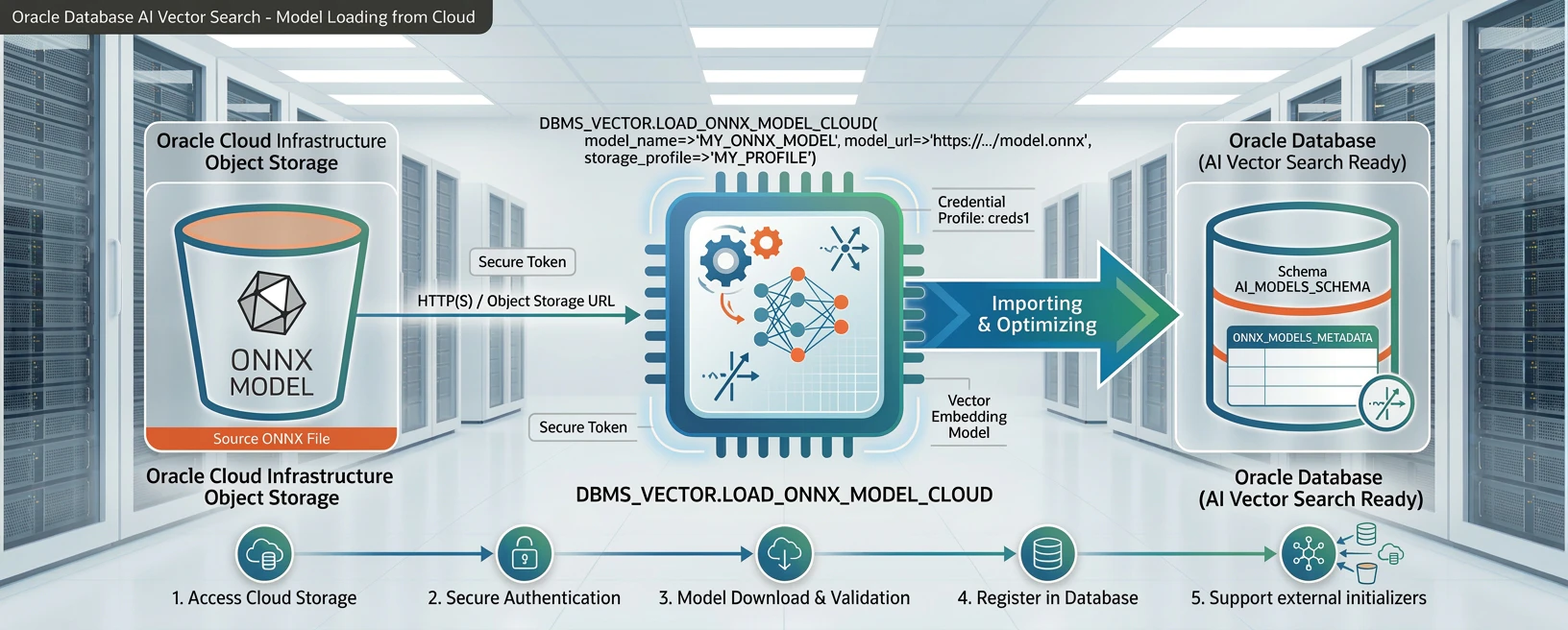
セキュリティや低遅延を重視したい用途では、ベクトルデータベースの中に埋め込みモデルを内蔵してしまいたいこともあります。
Oracle Database の場合、23ai から埋め込みモデルをデータベース内にロードして、データをデータベースの外へ出すことなくベクトル化できる機能があります。しかし、当初は、モデルのサイズが最大で1GB までという制限がありあまり高性能なモデルをロードすることはできず、実用上の課題でした。
Oracle AI Database 26ai(23.26.1)では、大規模な埋め込みモデル(1GB 超)をデータベース内に直接ロードして利用できるようになりました。
従来の 1GB の上限は、新しい External Initializer 機能により、モデルの重みパラメータを外部ファイルとして保持することで撤廃されました。
主な利点は以下の通りです。
- SQL 内で
VECTOR_EMBEDDING()関数を使って直接埋め込みを生成可能 - In-Memory Sharing 機能により、大規模モデルをグローバルメモリに一度ロードして全セッションで共有
- 外部 API 呼び出しが不要になるため、セキュリティを高めることができる上、レイテンシとコストを削減
-- データベース内の埋め込みモデルでベクトルを生成
SELECT VECTOR_EMBEDDING(multilingual_e5_large USING 'ベクトル埋め込みと仲良くなりたい!' as data)
FROM dual;
参考記事: Oracle Autonomous AI Database での高性能埋め込みモデルの活用
まとめ
本記事では、ベクトル埋め込みの基礎から応用まで、以下のポイントを解説しました。
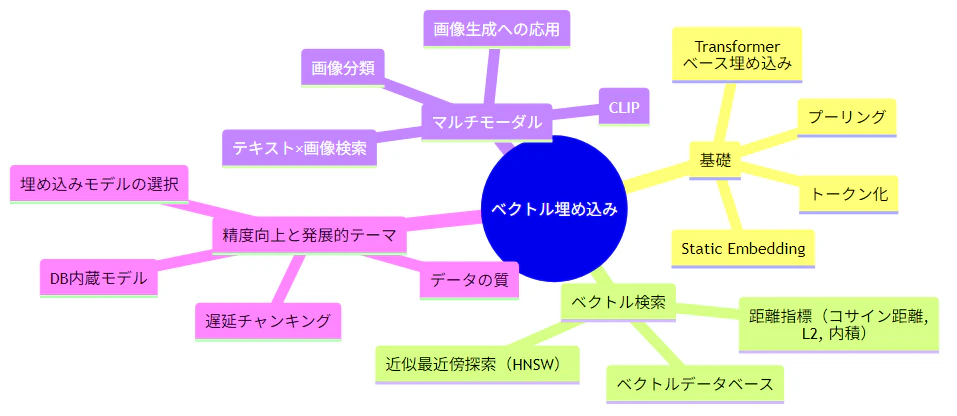
埋め込みは「テキストや画像の意味を数値ベクトルで表現する」というシンプルな概念ですが、その応用は RAG、画像検索、画像生成、分類、レコメンデーションなど広範にわたります。
ブラックボックスの蓋を開けてみると、そこにはシンプルで美しい仕組みがありました。この理解を土台にして、RAG の精度改善やマルチモーダルアプリケーションの設計に活かしていただければ幸いです。
参考資料
RAG と埋め込みの基礎
- 生成AIをより賢く ー エンジニアのための RAG入門 第1章 - RAG の基礎、LLM の仕組みと限界
- 生成AIをより賢く ー エンジニアのための RAG入門 第2章 - ベクトル検索の仕組み、埋め込みモデルの詳細
- 生成AIをより賢く エンジニアのためのRAG入門(Speaker Deck)
埋め込みモデルの実践
- 生成AIを活かすには埋め込みの理解から!RAGの心臓=埋め込みの基礎から応用まで! - 埋め込みの基礎からコード例まで
- OCI Generative AI サービスの埋め込みモデル Cohere Embed で類似性検索を試し倒す! - Cohere Embed の実践的な検証
マルチモーダル
- Oracle AI Vector Search と Japanese Stable CLIP によるマルチモーダル画像検索 - CLIP を使った画像検索の実装
- Cohere のマルチモーダル埋め込みモデルを使い倒す! - テキスト×画像の横断検索
- ドローン空撮画像を洪水判定してみる - OCI 生成AIサービス / Cohere Embed 4 編 - 埋め込みの画像分類への応用
- マルチモーダルレトリバー - マルチモーダル RAG アプリケーションの実装
精度向上と新技術
- チャンキングしてからベクトル化するか、ベクトル化してからチャンキングするか - 遅延チャンキングの検証
- Oracle Autonomous AI Database での高性能埋め込みモデルの活用 - DB 内蔵埋め込みモデル
外部参考文献
- Toward Optimal Search and Retrieval for RAG - RAG における検索精度と性能のトレードオフ
- Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts - LLM の外部知識と事前学習知識の優先度
- Hugging Face Tokenizer Playground - トークナイザーの可視化ツール