はじめに
Cohere 社の埋め込みモデル Cohere Embed V3.0 を使った画像とテキストのマルチモーダルのベクトル検索を様々なパターンで試してみました。
この記事の内容はウェビナー【Oracle AI JAM Session #23 生成AIを活かすには埋め込みの理解から!RAGの心臓:埋め込みの基礎から応用まで!】(2025年3月26日)にてご紹介させていただく内容の一部です。
コードは以下の GitHub Repo にて公開しています。
マルチモーダル検索のデモノートブック : 200_cohere_embed_multimodal_search_gradio.ipynb
Cohere 社の Embed 3 がマルチモーダルに対応した際のブログ によると、Cohere Embed 3 は、テキストと画像が同一のデータストア(ベクトルデータベース)にあるときのモーダリティ混合タスクで従来の CLIP を圧倒する精度を達成していることが書かれています。
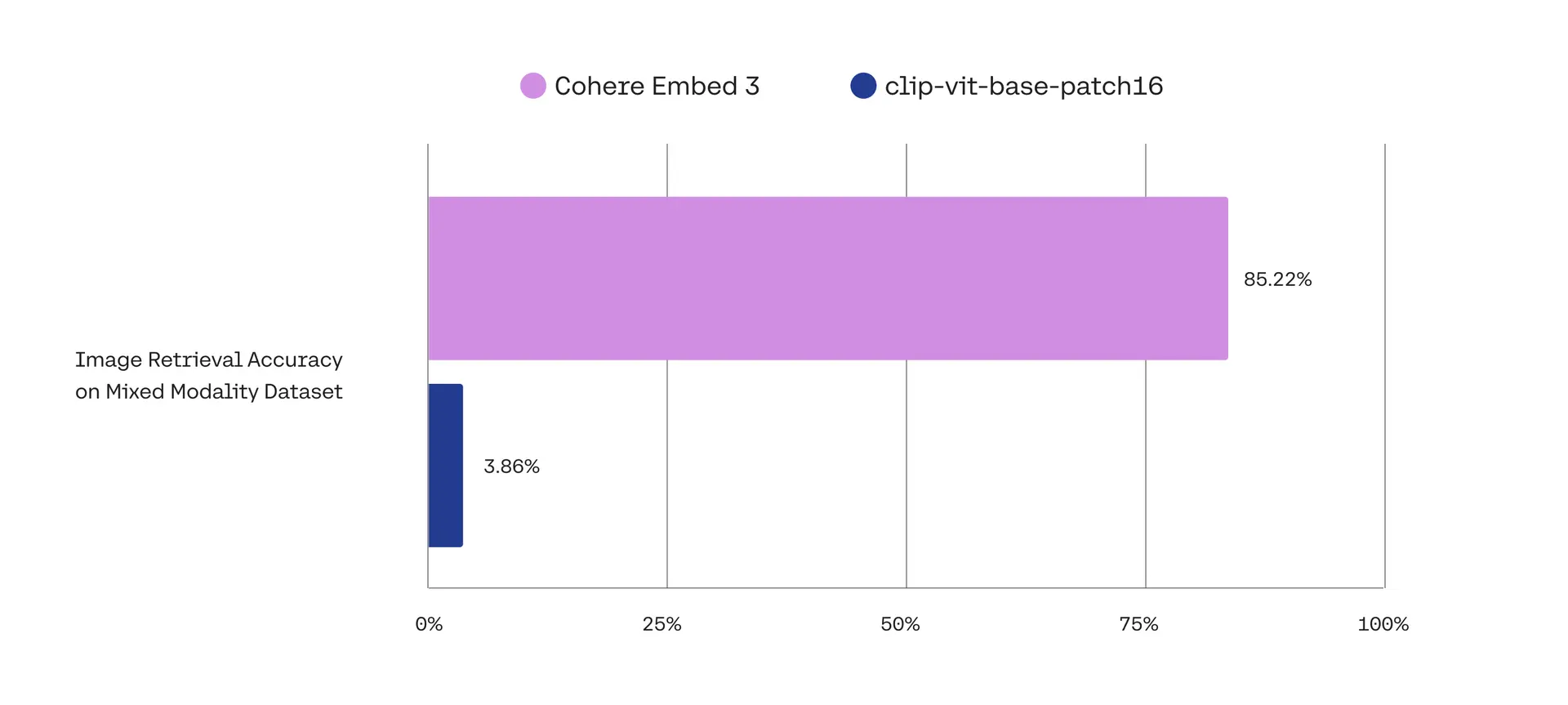
これって本当?という興味と、以前、X で見かけたこんなグラフとの関連にも関心があって試してみた記録です。
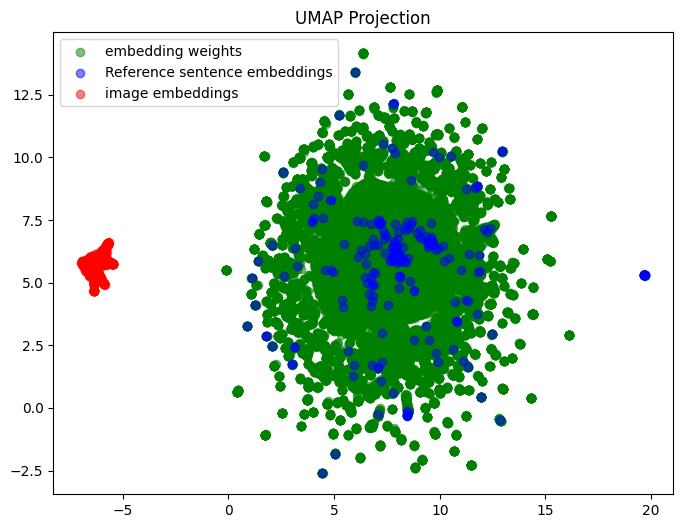
このグラフが意味しているのは、Vision-Language Model において、テキストの埋め込みと画像の埋め込みが別のクラスターを形成しているということです。埋め込みがこのような分布をしていると混合タスクで良い結果が得られるはずがありませんね。それでは、Cohere のマルチモーダル埋め込みモデルはこの問題を克服しているのでしょうか?
マルチモーダル埋め込みモデルとは何かや、その仕組み、CLIP(Japanese Stable CLIP)によるマルチモーダル検索のアプリケーションの作り方については別の記事を書いていますのでご興味のある方はぜひこちらにもお立ち寄りください。
それでは、「Cohere のマルチモーダル埋め込みモデルを使い倒す!」はじまります!
各テストケースに共通するコードの紹介
ライブラリのインポート
import cohere
from pathlib import Path
from PIL import Image
from io import BytesIO
import base64
import os
from dotenv import load_dotenv, find_dotenv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import gradio as gr
- cohere: Cohereの大規模言語モデルAPIを使用するためのクライアントライブラリ。テキストや画像の埋め込み生成や大規模言語モデル(Command R シリーズや A シリーズ)とのチャットに使われます
- pathlib.Path: ファイルパス操作のための便利なライブラリ
- PIL (Pillow): 画像処理ライブラリ。画像の読み込みや操作に使用
- BytesIO, base64: バイナリデータの処理とエンコーディングのためのモジュール。画像データの変換に役立つ
- dotenv: 環境変数を.envファイルから読み込むためのツール。今回は、Cohere 社の APIキーの管理に使用
- numpy (np): 数値計算ライブラリ。ベクトル演算や類似度計算に使用
- pandas (pd): データ分析のためのライブラリ。データフレームでデータを管理
- matplotlib.pyplot (plt): データ可視化ライブラリ。結果のグラフ化に使用
- japanize_matplotlib: matplotlib内の日本語表示をサポートするライブラリ(明示的に呼び出していませんが日本語を使用する際には必要)
- gradio (gr): 機械学習モデルのデモやプロトタイプ用のウェブインターフェースを簡単に作成できるライブラリ
ヘルパー関数
各サンプルコードで共通に使用するヘルパー関数をご紹介します。ここは、生成AIや埋め込みモデル、ベクトル検索の本質とは関係ありませんので、さらっと読み流していただいて大丈夫です。
類似度(コサイン)計算関数
今回使用するマルチモーダル埋め込みモデルの Cohere 社 embed-multilingual-v3.0 は、あるテキストと画像のペアが似ている(関連がある)とき、それらの埋め込みベクトル間のコサインが大きく(1に近く)なるように学習しています。そのため、実際にあるクエリー(テキストや画像)に似たテキストや画像を探す際には、クエリーと検索対象のコサイン類似度を計算して、その値が大きいものをより似ているものとします。
def calculate_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
- np.dot(a, b) - これは2つのベクトルの内積(ドット積)を計算します。dot() は、NumPyライブラリの基本関数
- np.linalg.norm(a) - ベクトル a のノルム(長さ)を計算します。linalg.norm()は、NumPyの線形代数モジュール(linalg)に含まれる関数
- np.linalg.norm(b) - ベクトル b のノルム(長さ)を計算します
- 最後に、内積を両方のベクトルのノルムの積で割り、コサインを求めています
Cohere 社 embed-multilingual-v3.0 をはじめ API サービスとして提供される埋め込みモデルのほとんどはベクトルの大きさ(長さ)が"1"に正規化されています。その場合、2つのベクトルのコサインと内積は一致しますので、内積を計算するだけでコサインを求めることができます。そのため、上記の計算式の分母は省略可能です。
画像をData URLに変換する関数
def image_to_base64_data_url(image_path):
with Image.open(image_path) as img:
buffered = BytesIO()
img.save(buffered, format="JPEG")
img_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8")
data_url = f"data:image/jpeg;base64,{img_base64}"
return data_url
embed-multilingual-v3.0 は、埋め込む(埋め込みベクトルに変換する)画像を Data URL フォーマットで受け取ります。対応する画像は、png, jpeg, webp, gif です。また、画像の最大サイズ(容量)は、 5MB です。今回のコードでは、画像のサイズのチェックは省略しています。PNG などは画像サイズが大きくなりがちですのでご注意ください。
結果表示用の Gradio インターフェースを生成する関数
def create_search_interface(query_type, query, max_images, results_df, max_image_width=None, max_image_height=None):
"""
検索結果を表示するためのGradioインターフェイスを作成する。
"""
# 表示する画像数を max_images に制限
results_df = results_df.head(max_images).reset_index(drop=True)
with gr.Blocks() as demo:
# 検索クエリを表示
if query_type == "画像":
gr.Markdown("### 検索クエリ(画像)")
gr.Image(value=query, width=max_image_width, height=max_image_height)
else:
gr.Markdown("### 検索クエリ(テキスト)")
gr.Textbox(value=query, label="")
gr.Markdown("### 検索結果")
for i, row in results_df.iterrows():
with gr.Group():
with gr.Row():
# 順位表示用左カラム
with gr.Column(scale=1, min_width=50):
#gr.Markdown(f"**#{i+1}**")
gr.Markdown(f"<h2 style='font-size: 24px; margin: 0;'>#{i+1}</h2>")
# コンテンツ(画像および/またはテキスト)用の中央カラム
with gr.Column(scale=5):
# パスが存在し、画像ファイルである場合に表示
path = row['パス']
if path is not None and os.path.exists(path) and path.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
gr.Image(value=path, width=max_image_width, height=max_image_height)
# テキストが存在する場合に表示
if row['テキスト']:
gr.Textbox(value=row['テキスト'], label="", lines=3)
# 右列は類似性とパス
with gr.Column(scale=4):
gr.Number(value=row['類似度'], label="類似度")
gr.Textbox(value=row['パス'], label="パス", lines=1)
# 結果の間にセパレータを追加
gr.Markdown("---")
return demo
-
呼び出しパラメータ
- query_type (str): "画像" or "テキスト"
- query: 画像ファイルへのパスまたはテキスト文字列
- max_images (int): 表示する結果の最大数
- results_df (pd.DataFrame): DataFrame 'テキスト', 'パス', '類似度' の3カラムが必要
- max_image_width (int, optional): 表示する画像の最大幅
- max_image_height (int, optional): 表示する画像の最大高さ
-
戻り値
- gr.Blocks: 検索結果を表示するGradioインターフェース
-
使い方例
- テキストによる画像などの検索の結果表示の場合
Gradioインターフェースの定義
result_display = create_search_interface(query_type="テキスト", query="Cohereって何ですか?", max_images=12, results_df=results_df, max_image_width=400, max_image_height=300) - 画像による画像などの検索の結果表示の場合
Gradioインターフェースの定義
result_display = create_search_interface(query_type="画像", query="images/something_greate.jpg", max_images=12, results_df=results_df, max_image_width=400, max_image_height=300) - Gradio サーバーを起動
result_display.launch() - Gradio サーバーの停止(Jupyter Notebook で使用する際には忘れずに!)
results_display.close()
- テキストによる画像などの検索の結果表示の場合
マルチモーダル検索
画像の埋め込み生成
カレントディレクトリ直下の images ディレクトリ内にある画像ファイルの埋め込みを生成して、doc_embeddings というリストに格納します。この記事では、このメモリ中に保持される Python のリストをベクトルデータベースに見立てます。
Cohere クライアントオブジェクトの生成
_= load_dotenv(find_dotenv())
api_key = os.getenv("COHERE_API_KEY")
co = cohere.Client(api_key=api_key)
カレントディレクトリにあらかじめ用意した .env ファイルに、COHERE_API_KEY=XXXXXXXXXXXX の書式で Cohere の API キーを設定しておきます。API キーには無料で利用できるトライアルキーもあります。ただし、トライアルキーは、1分間に埋め込みAPIリクエストを5回までしか発行できないレート制限があります。画像は、1リクエストで1ファイルとなりますので大量の画像を埋め込みたい場合は、有償のAPIキーを取得した方がよいかもしれません。
cohere.Client()で Cohere のクライアントオブジェクトを生成します。以降はこのオブジェクトを通して Cohere の API にアクセスします。
埋め込み処理対象の画像群を定義
image_dir = "images"
image_extensions = ['.jpg', '.jpeg', '.png', '.gif']
image_names = []
for filename in os.listdir(image_dir):
if any(filename.lower().endswith(ext.lower()) for ext in image_extensions):
image_names.append(filename)
image_paths = [os.path.join(image_dir, name) for name in image_names]
image_paths
カレントディレクトリ直下の images ディレクトリ内にある画像ファイルのリストを image_paths に保存しています。
['images\\DSC_0385-2.jpg',
'images\\sample02.jpg',
'images\\sample09.jpg',
'images\\00387-4109315140.png',
'images\\DSC_0046.JPG',
'images\\DSCF2958.JPG',
'images\\ComfyUI_00021_.png',
'images\\DSC_0060.JPG',
'images\\sample03.jpg',
'images\\DSC_5382.JPG',
'images\\DSC_5349.JPG',
'images\\1517975029190.jpg',
'images\\DSC_3430.JPG',
'images\\DSC_3476.JPG']
Windows Python 環境での出力例のためバックスラッシュがエスケープされて2回づつ現れています。
なお、imagesディレクトリには以下のような画像群が置かれています。
画像の埋め込み生成の実行
doc_embeddings = []
for i, image_path in enumerate(image_paths):
# 画像をData URLに変換
processed_image = image_to_base64_data_url(image_path)
# 埋め込みを取得
ret = co.embed(
images=[processed_image],
input_type="image",
model="embed-multilingual-v3.0",
embedding_types=["float"],
)
doc_embeddings.append({
"text": None,
"path": image_path,
"embedding": ret.embeddings.float[0]
})
print(f"画像 {i+1}/{len(doc_embeddings)} の処理が完了しました: {image_path}")
記事執筆時点(2025/3/23)では、Cohere の API は、1リクエストで1画像しか処理できないため、image_paths の1ファイルにつき1度、埋め込みのリクエストを投げています。
埋め込みのリクエストは、Cohere クライアントオブジェクトの embed() メソッドで発行します。
embed() メソッドの主要パラメータ
- model: 埋め込み処理に使う埋め込みモデル。今回は、多言語、マルチモーダル対応の"embed-multilingual-v3.0"
- input_type: 埋め込むデータのタイプ。画像の場合は、"image"
- images: Data URL フォーマット化した画像データのリスト。記事執筆時点(2025/3/23)では、1画像しか指定できませんが、リストになっていますので将来拡張されるのかもしれませんね。
- embedding_types: 圧縮レベルです。float、int8、unint8、binary、ubinary から選択できます。生成される埋め込みのサイズと精度にトレードオフがあります。今回は最も精度が良い
floatを使います
画像 1/1 の処理が完了しました: images\DSC_0385-2.jpg
画像 2/2 の処理が完了しました: images\sample02.jpg
画像 3/3 の処理が完了しました: images\sample09.jpg
画像 4/4 の処理が完了しました: images\00387-4109315140.png
画像 5/5 の処理が完了しました: images\DSC_0046.JPG
画像 6/6 の処理が完了しました: images\DSCF2958.JPG
画像 7/7 の処理が完了しました: images\ComfyUI_00021_.png
画像 8/8 の処理が完了しました: images\DSC_0060.JPG
画像 9/9 の処理が完了しました: images\sample03.jpg
画像 10/10 の処理が完了しました: images\DSC_5382.JPG
画像 11/11 の処理が完了しました: images\DSC_5349.JPG
画像 12/12 の処理が完了しました: images\1517975029190.jpg
画像 13/13 の処理が完了しました: images\DSC_3430.JPG
画像 14/14 の処理が完了しました: images\DSC_3476.JPG
画像検索(1) - テキストをクエリーとした画像の検索
テキストクエリーの埋め込み生成
クエリーとなるテキストの埋め込みを生成します。
クエリーテキストの定義
query = ["東京駅"]
クエリーテキストの埋め込み生成
ret = co.embed(
texts=query,
input_type="search_query",
model="embed-multilingual-v3.0",
embedding_types=["float"],
)
query_embedding = ret.embeddings.float
print(f"クエリーテキストの埋め込みの次元数: {len(query_embedding[0])}")
画像の埋め込み生成と異なるのは下記です。
- input_type: 検索テキストには、
search_queryを指定します - texts: 埋め込むテキストは、
textsリストに設定します。最大で96件のテキストを1度に埋め込みベクトルに変換することができます
クエリーテキストの埋め込みの次元数: 1024
Cohere embed-multilingual-v3.0 は、1024次元の埋め込みベクトルを生成します。
テキストクエリーによる画像検索の実行
# クエリと文書の埋め込みベクトル間の類似度を計算
similarities = []
for i in range(len(doc_embeddings)):
similarity = calculate_similarity(query_embedding[0], doc_embeddings[i]["embedding"])
similarities.append(similarity)
# 結果をデータフレームに格納
results_df = pd.DataFrame({
'テキスト':None,
'パス': [doc["path"] for doc in doc_embeddings],
'類似度': similarities
})
# 類似度の降順でソート
results_df = results_df.sort_values('類似度', ascending=False).reset_index(drop=True)
# 結果を整形して表示
pd.set_option('display.float_format', '{:.4f}'.format)
display(results_df.style.set_properties(**{'text-align': 'left'})
.set_table_styles([
{'selector': 'th', 'props': [('text-align', 'left'), ('font-weight', 'bold')]},
{'selector': '.row_heading, .blank', 'props': [('display', 'none')]},
{'selector': 'td', 'props': [('padding', '5px')]}
]))
類似度の計算には、上で定義したヘルパー関数の calculate_similarity() を使っています。
なお、Pandas Dataframe に変換して、類似度の降順にソートし結果を出力していますが、Pandas Dataframe を使うこと自体は本質的ではありません。Jupyter Notebook 上で綺麗な表にフォーマットしてくれるため使用しています。
出力例は下記スクリーンショットのとおりです。
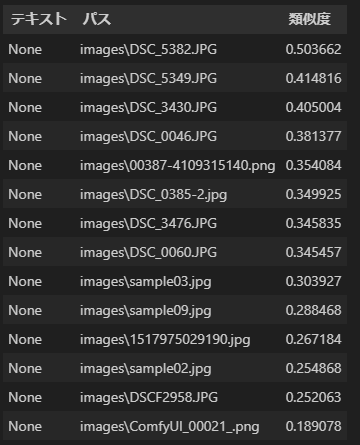
なお、この検索では検索対象は画像だけですので「テキスト」欄はすべてNoneとなっています。このサンプルの仕様です^^。
検索結果を画像付きで表示
results_display = create_search_interface(query_type = "テキスト", query = query[0], max_images = 12, results_df = results_df, max_image_width=400, max_image_height=300)
results_display.launch()
上で定義したヘルパー関数の create_search_interface() を使って結果を表示します。
* Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
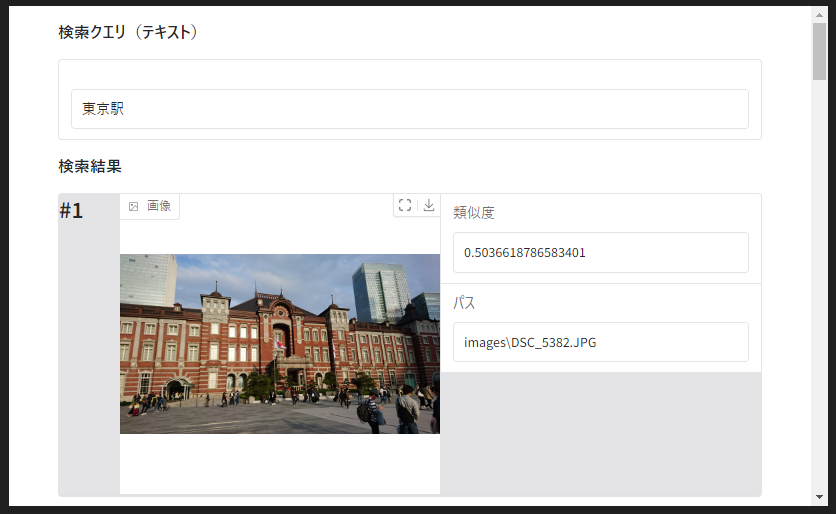
Jupytern Notebook のセルにも表示されますが、上の出力例に出ているような local URL の URL をクリックするとブラウザに結果が表示されます。
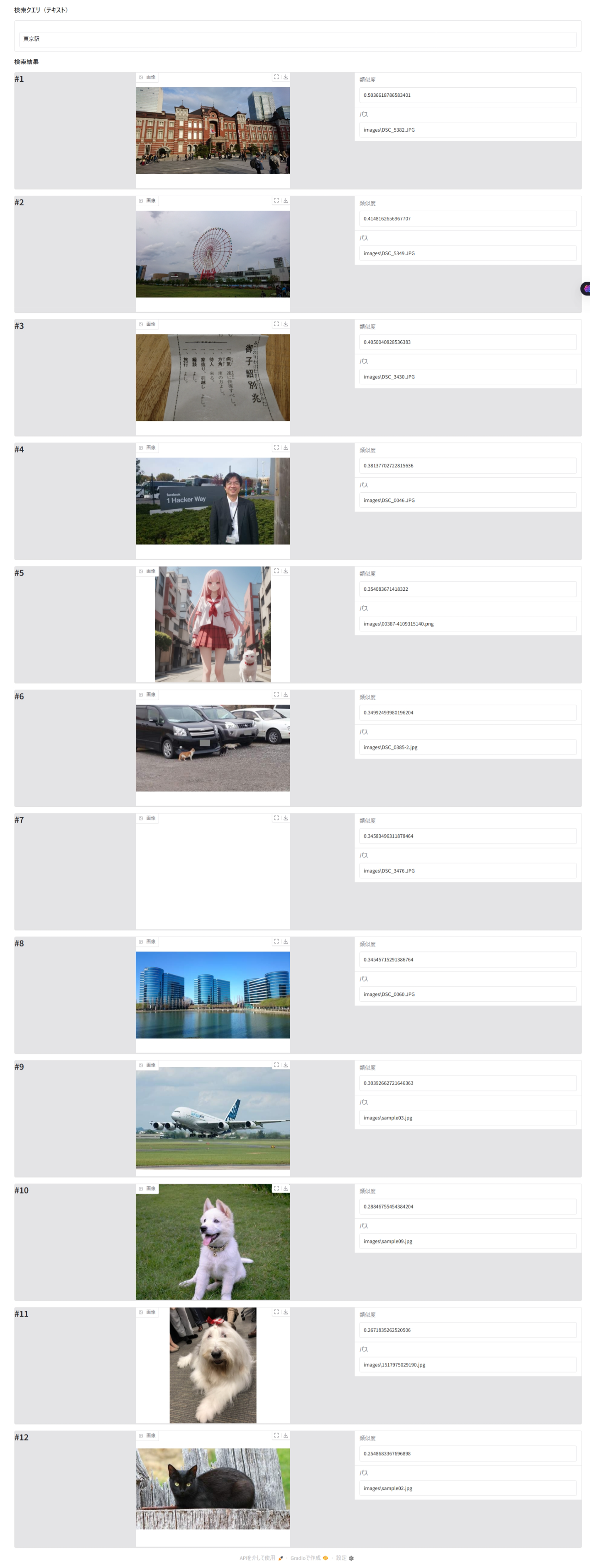
※ #7 の画像は、Edge のスクリーンショット機能では抜け落ちていますが、ブラウザのタブ上には見えています(なぞですが Edge の問題です)
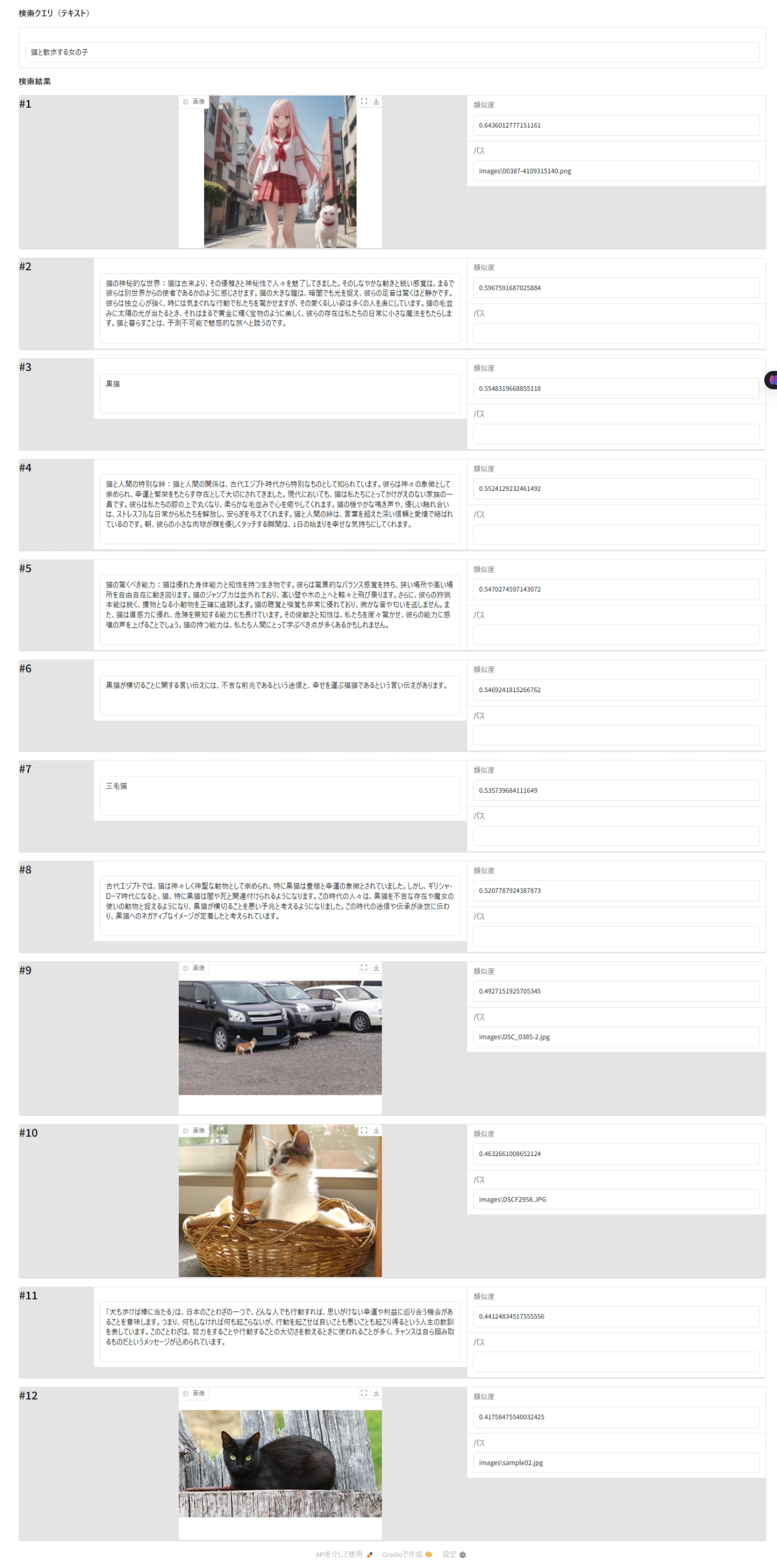
検索クエリー「東京駅」に対して、類似度1位の画像はまさに「東京駅」の画像が表示されています。
類似性検索は検索対象のデータ群の中で、似ている順にデータを並べ替えるものですので、「東京駅」の画像だけが表示されるわけではありません。
Gradio サーバーを停止(忘れずに!)
Gradio サーバーを起動するとバックグラウンドで Gradio サーバーが HTTP サーバーとして稼働しています。Jupyter Notebook のセルを移動してもこのサーバープロセスは停止しませんので、明示的に停止する必要があります。また、Gradio はデフォルトでリッスンしているポートが使用中の場合にはポート番号をインクリメントして別ポートでリッスンするサーバーを起動しますので、都度、停止が必要です。
results_display.close()
Closing server running on port: 7861
画像検索(2) - 画像をクエリーとした画像の検索
次は、クエリーをテキストではなく画像にしてみます。画像で画像を検索するパターンです。
クエリー画像の埋め込み生成
クエリー画像の定義
query_image_path = Path("images/sample02.jpg").as_posix()
img = Image.open(query_image_path)
plt.figure(figsize=(10, 8))
plt.imshow(img)
plt.title(f"クエリー画像", fontweight='bold', fontsize=14)
plt.axis('off')
plt.show()
出力例

クエリー画像の埋め込み処理
processed_image = image_to_base64_data_url(query_image_path)
ret = co.embed(
images=[processed_image],
input_type="image",
model="embed-multilingual-v3.0",
embedding_types=["float"],
)
query_embedding = ret.embeddings.float
print(f"クエリー画像の埋め込みの次元数: {len(query_embedding[0])}")
検索対象の画像の埋め込みベクトルを生成したとき基本的には同じです。
クエリー画像の埋め込みの次元数: 1024
画像の埋め込みベクトルもテキストのときと同じ 1024次元ベクトルとなります。
クエリー画像による画像検索の実行
# クエリと文書の埋め込みベクトル間の類似度を計算
similarities = []
for i in range(len(doc_embeddings)):
similarity = calculate_similarity(query_embedding[0], doc_embeddings[i]["embedding"])
similarities.append(similarity)
# 結果をデータフレームに格納
results_df = pd.DataFrame({
'テキスト': None,
'パス': [doc["path"] for doc in doc_embeddings],
'類似度': similarities
})
# 類似度の降順でソート
results_df = results_df.sort_values('類似度', ascending=False).reset_index(drop=True)
# 結果を整形して表示
pd.set_option('display.float_format', '{:.4f}'.format)
display(results_df.style.set_properties(**{'text-align': 'left'})
.set_table_styles([
{'selector': 'th', 'props': [('text-align', 'left'), ('font-weight', 'bold')]},
{'selector': '.row_heading, .blank', 'props': [('display', 'none')]},
{'selector': 'td', 'props': [('padding', '5px')]}
]))
類似度を計算して、降順にソートして表示しています。テキストをクエリーとしたときと全く同じです。
出力例は下記のスクリーンショットのとおりです。
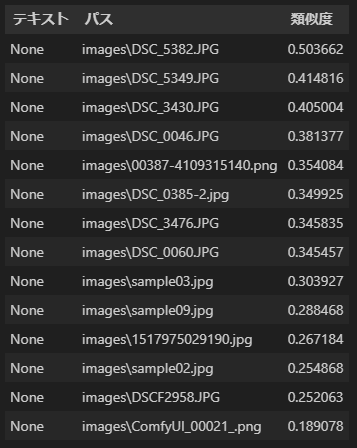
今回も検索対象は画像だけですので「テキスト」欄は None となります。
検索結果を画像付きで表示
results_display = create_search_interface(query_type = "画像", query = query_image_path, max_images = 5, results_df = results_df, max_image_width=400, max_image_height=300)
results_display.launch()
上で定義したヘルパー関数の create_search_interface() を使って結果を表示します。
テキストをクエリーとしたときと異なっているのは、query_type と query です。query には、クエリー画像のパスを指定します。今回は、表示する結果画像の件数を 5件にしています。
* Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
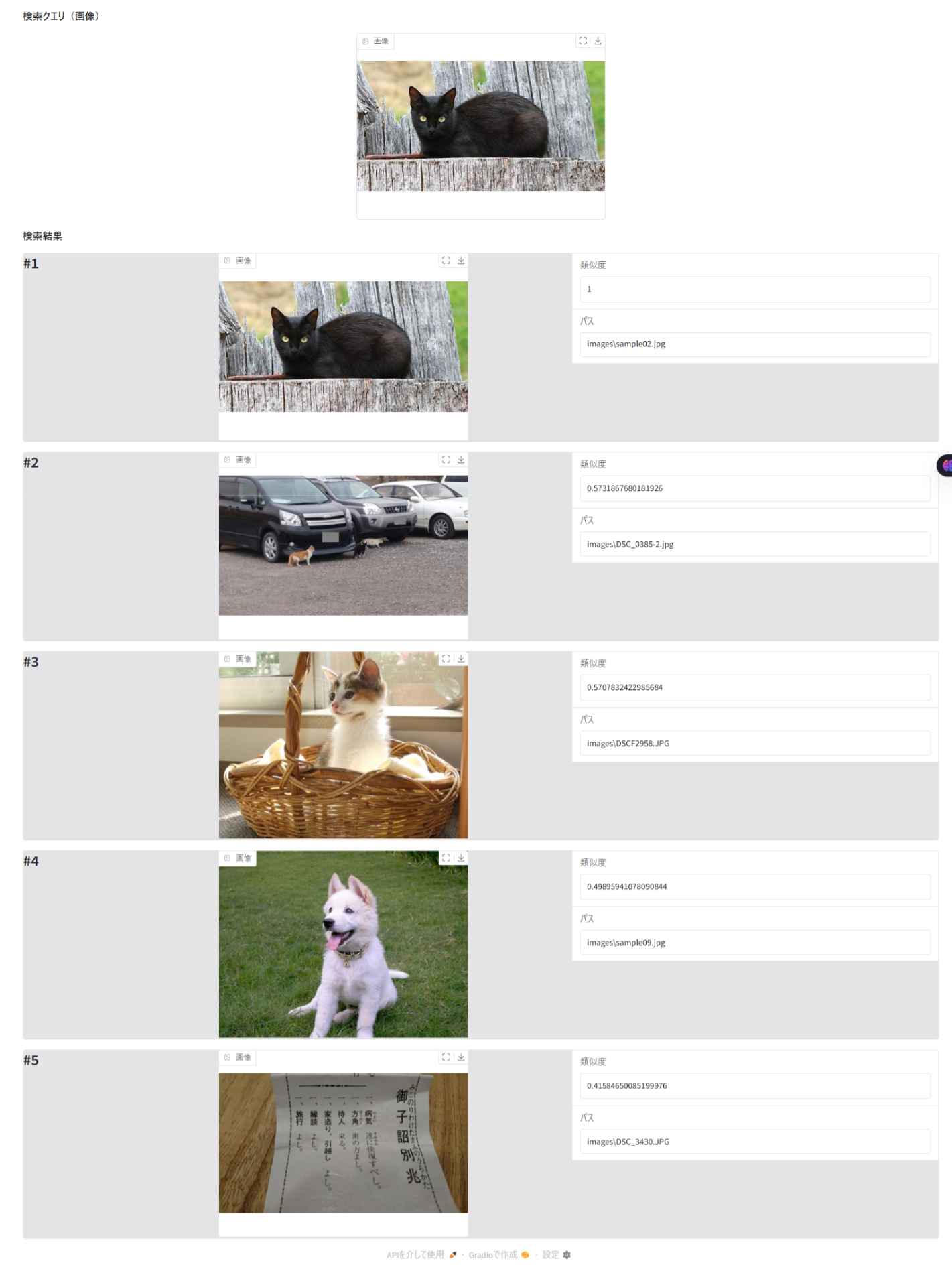
Gradio サーバーを停止(忘れずに!)
results_display.close()
Closing server running on port: 7861
画像検索(3) - テキストをクエリーとした画像とテキストのミックス検索
検索対象の画像群はこれまでと同じです。画像群に加えて、検索対象となるテキスト群を追加します。
検索対象のテキスト群を定義
以下のテキストドキュメントを検索対象に加えます。
| No | テキスト | 文字数 |
|---|---|---|
| 1 | 黒猫 | 2 |
| 2 | 三毛猫 | 3 |
| 3 | 猫の神秘的な世界:猫は古来より、その優雅さと神秘性で人々を魅了してきました。そのしなやかな動きと鋭い感覚は、まるで彼らは別世界からの使者であるかのように感じさせます。猫の大きな瞳は、暗闇でも光を捉え、彼らの足音は驚くほど静かです。彼らは独立心が強く、時には気まぐれな行動で私たちを驚かせますが、その愛くるしい姿は多くの人を虜にしています。猫の毛並みに太陽の光が当たるとき、それはまるで黄金に輝く宝物のように美しく、彼らの存在は私たちの日常に小さな魔法をもたらします。猫と暮らすことは、予測不可能で魅惑的な旅へと誘うのです。 | 262 |
| 4 | 猫と人間の特別な絆:猫と人間の関係は、古代エジプト時代から特別なものとして知られています。彼らは神々の象徴として崇められ、幸運と繁栄をもたらす存在として大切にされてきました。現代においても、猫は私たちにとってかけがえのない家族の一員です。彼らは私たちの膝の上で丸くなり、柔らかな毛並みで心を癒やしてくれます。猫の穏やかな鳴き声や、優しい触れ合いは、ストレスフルな日常から私たちを解放し、安らぎを与えてくれます。猫と人間の絆は、言葉を超えた深い信頼と愛情で結ばれているのです。朝、彼らの小さな肉球が顔を優しくタッチする瞬間は、1日の始まりを幸せな気持ちにしてくれます。 | 270 |
| 5 | 猫の驚くべき能力:猫は優れた身体能力と知性を持つ生き物です。彼らは驚異的なバランス感覚を持ち、狭い場所や高い場所を自由自在に動き回ります。猫のジャンプ力は並外れており、高い壁や木の上へと軽々と飛び乗ります。さらに、彼らの狩猟本能は鋭く、獲物となる小動物を正確に追跡します。猫の聴覚と嗅覚も非常に優れており、微かな音や匂いを逃しません。また、猫は直感力に優れ、危険を察知する能力にも長けています。その俊敏さと知性は、私たちを度々驚かせ、彼らの能力に感嘆の声を上げることでしょう。猫の持つ能力は、私たち人間にとって学ぶべき点が多くあるかもしれません。 | 270 |
| 6 | 黒猫が横切ることに関する言い伝えには、不吉な前兆であるという迷信と、幸せを運ぶ福猫であるという言い伝えがあります。 | 53 |
| 7 | 古代エジプトでは、猫は神々しく神聖な動物として崇められ、特に黒猫は豊穣と幸運の象徴とされていました。しかし、ギリシャ・ローマ時代になると、猫、特に黒猫は闇や死と関連付けられるようになります。この時代の人々は、黒猫を不吉な存在や魔女の使いの動物と捉えるようになり、黒猫が横切ることを悪い予兆と考えるようになりました。この時代の迷信や伝承が後世に伝わり、黒猫へのネガティブなイメージが定着したと考えられています。 | 193 |
| 8 | COVID-19は、SARS-CoV-2(新型コロナウイルス)によって引き起こされる感染症です。2019年12月に最初に確認され、その後、世界的なパンデミックとなりました。症状としては、発熱、咳、息切れ、倦怠感、嗅覚や味覚の喪失などがあります。また、感染経路は、主に飛沫感染と接触感染ですが、空気感染の可能性もあります。高齢者や基礎疾患のある方は重症化リスクが高く、死亡率も高いとされています。COVID-19に対しては、ワクチン接種や手洗い、マスク着用、ソーシャルディスタンスなどの予防措置が推奨されています。パンデミックは世界中の医療システムや経済に大きな影響を与えました。 | 269 |
| 9 | 近似最近傍検索は、高次元空間内で与えられたクエリポイントに最も近い(最も類似した)データポイントを効率的に見つけるアルゴリズムです。 | 58 |
| 10 | 「犬も歩けば棒に当たる」は、日本のことわざの一つで、どんな人でも行動すれば、思いがけない幸運や利益に巡り合う機会があることを意味します。つまり、何もしなければ何も起こらないが、行動を起こせば良いことも悪いことも起こり得るという人生の教訓を表しています。このことわざは、努力をすることや行動することの大切さを教えるときに使われることが多く、チャンスは自ら掴み取るものだというメッセージが込められています。 | 173 |
| 11 | 秋田犬は、日本原産の大型犬種で、忠誠心と勇敢さで知られる人気の犬種です。 | 35 |
| 12 | 自動車の発明はフランス、ドイツ、イギリス、アメリカなど、複数の国で並行して進められ、それぞれの発明家や技術者が独自のアイデアや技術を競い合いながら、現代の自動車へと繋がる発明を成し遂げました。自動車の歴史は、国境を越えた知恵と技術の集積によって織りなされてきたのです。 | 133 |
texts = [
'黒猫',
'三毛猫',
'猫の神秘的な世界:猫は古来より、その優雅さと神秘性で人々を魅了してきました。そのしなやかな動きと鋭い感覚は、まるで彼らは別世界からの使者であるかのように感じさせます。猫の大きな瞳は、暗闇でも光を捉え、彼らの足音は驚くほど静かです。彼らは独立心が強く、時には気まぐれな行動で私たちを驚かせますが、その愛くるしい姿は多くの人を虜にしています。猫の毛並みに太陽の光が当たるとき、それはまるで黄金に輝く宝物のように美しく、彼らの存在は私たちの日常に小さな魔法をもたらします。猫と暮らすことは、予測不可能で魅惑的な旅へと誘うのです。',
'猫と人間の特別な絆:猫と人間の関係は、古代エジプト時代から特別なものとして知られています。彼らは神々の象徴として崇められ、幸運と繁栄をもたらす存在として大切にされてきました。現代においても、猫は私たちにとってかけがえのない家族の一員です。彼らは私たちの膝の上で丸くなり、柔らかな毛並みで心を癒やしてくれます。猫の穏やかな鳴き声や、優しい触れ合いは、ストレスフルな日常から私たちを解放し、安らぎを与えてくれます。猫と人間の絆は、言葉を超えた深い信頼と愛情で結ばれているのです。朝、彼らの小さな肉球が顔を優しくタッチする瞬間は、1日の始まりを幸せな気持ちにしてくれます。',
'猫の驚くべき能力:猫は優れた身体能力と知性を持つ生き物です。彼らは驚異的なバランス感覚を持ち、狭い場所や高い場所を自由自在に動き回ります。猫のジャンプ力は並外れており、高い壁や木の上へと軽々と飛び乗ります。さらに、彼らの狩猟本能は鋭く、獲物となる小動物を正確に追跡します。猫の聴覚と嗅覚も非常に優れており、微かな音や匂いを逃しません。また、猫は直感力に優れ、危険を察知する能力にも長けています。その俊敏さと知性は、私たちを度々驚かせ、彼らの能力に感嘆の声を上げることでしょう。猫の持つ能力は、私たち人間にとって学ぶべき点が多くあるかもしれません。',
'黒猫が横切ることに関する言い伝えには、不吉な前兆であるという迷信と、幸せを運ぶ福猫であるという言い伝えがあります。',
'古代エジプトでは、猫は神々しく神聖な動物として崇められ、特に黒猫は豊穣と幸運の象徴とされていました。しかし、ギリシャ・ローマ時代になると、猫、特に黒猫は闇や死と関連付けられるようになります。この時代の人々は、黒猫を不吉な存在や魔女の使いの動物と捉えるようになり、黒猫が横切ることを悪い予兆と考えるようになりました。この時代の迷信や伝承が後世に伝わり、黒猫へのネガティブなイメージが定着したと考えられています。',
'COVID-19は、SARS-CoV-2(新型コロナウイルス)によって引き起こされる感染症です。2019年12月に最初に確認され、その後、世界的なパンデミックとなりました。症状としては、発熱、咳、息切れ、倦怠感、嗅覚や味覚の喪失などがあります。また、感染経路は、主に飛沫感染と接触感染ですが、空気感染の可能性もあります。高齢者や基礎疾患のある方は重症化リスクが高く、死亡率も高いとされています。COVID-19に対しては、ワクチン接種や手洗い、マスク着用、ソーシャルディスタンスなどの予防措置が推奨されています。パンデミックは世界中の医療システムや経済に大きな影響を与えました。',
'近似最近傍検索は、高次元空間内で与えられたクエリポイントに最も近い(最も類似した)データポイントを効率的に見つけるアルゴリズムです。',
'「犬も歩けば棒に当たる」は、日本のことわざの一つで、どんな人でも行動すれば、思いがけない幸運や利益に巡り合う機会があることを意味します。つまり、何もしなければ何も起こらないが、行動を起こせば良いことも悪いことも起こり得るという人生の教訓を表しています。このことわざは、努力をすることや行動することの大切さを教えるときに使われることが多く、チャンスは自ら掴み取るものだというメッセージが込められています。',
'秋田犬は、日本原産の大型犬種で、忠誠心と勇敢さで知られる人気の犬種です。',
'自動車の発明はフランス、ドイツ、イギリス、アメリカなど、複数の国で並行して進められ、それぞれの発明家や技術者が独自のアイデアや技術を競い合いながら、現代の自動車へと繋がる発明を成し遂げました。自動車の歴史は、国境を越えた知恵と技術の集積によって織りなされてきたのです。'
]
検索対象テキスト群の埋め込みの生成
# 埋め込みを取得
ret = co.embed(
texts=texts,
input_type="search_document", # 検索対象のテキストドキュメント
model="embed-multilingual-v3.0",
embedding_types=["float"],
)
# 各テキストとその埋め込みを対応付けてdoc_embeddingsに格納
for i, (text, embedding) in enumerate(zip(texts, ret.embeddings.float)):
doc_embeddings.append({
"text": text,
"path": None,
"embedding": embedding
})
print(f"テキスト {i+1}/{len(texts)} の処理が完了しました: {text[:50]}")
Cohere API は、最大で96件のテキストを1回のリクエストで埋め込みベクトルに変換できます。今回は件数が少ないため1回のAPI呼び出しで変換しています。件数が不明な場合は96件づつのバッチになるようにする必要があります。
テキスト 1/12 の処理が完了しました: 黒猫
テキスト 2/12 の処理が完了しました: 三毛猫
テキスト 3/12 の処理が完了しました: 猫の神秘的な世界:猫は古来より、その優雅さと神秘性で人々を魅了してきました。そのしなやかな動きと鋭い
テキスト 4/12 の処理が完了しました: 猫と人間の特別な絆:猫と人間の関係は、古代エジプト時代から特別なものとして知られています。彼らは神々
テキスト 5/12 の処理が完了しました: 猫の驚くべき能力:猫は優れた身体能力と知性を持つ生き物です。彼らは驚異的なバランス感覚を持ち、狭い場
テキスト 6/12 の処理が完了しました: 黒猫が横切ることに関する言い伝えには、不吉な前兆であるという迷信と、幸せを運ぶ福猫であるという言い伝
テキスト 7/12 の処理が完了しました: 古代エジプトでは、猫は神々しく神聖な動物として崇められ、特に黒猫は豊穣と幸運の象徴とされていました。
テキスト 8/12 の処理が完了しました: COVID-19は、SARS-CoV-2(新型コロナウイルス)によって引き起こされる感染症です。20
テキスト 9/12 の処理が完了しました: 近似最近傍検索は、高次元空間内で与えられたクエリポイントに最も近い(最も類似した)データポイントを効
テキスト 10/12 の処理が完了しました: 「犬も歩けば棒に当たる」は、日本のことわざの一つで、どんな人でも行動すれば、思いがけない幸運や利益に
テキスト 11/12 の処理が完了しました: 秋田犬は、日本原産の大型犬種で、忠誠心と勇敢さで知られる人気の犬種です。
テキスト 12/12 の処理が完了しました: 自動車の発明はフランス、ドイツ、イギリス、アメリカなど、複数の国で並行して進められ、それぞれの発明家
doc_embeddings の表示(ベクトルデータベースを模したリストの中身)
# doc_embeddingsをDataFrameに変換
df = pd.DataFrame(doc_embeddings)
df['embedding_length'] = df['embedding'].apply(len)
df_display = df[['text', 'path', 'embedding_length']].copy()
# DataFrameの表示
display(df_display)
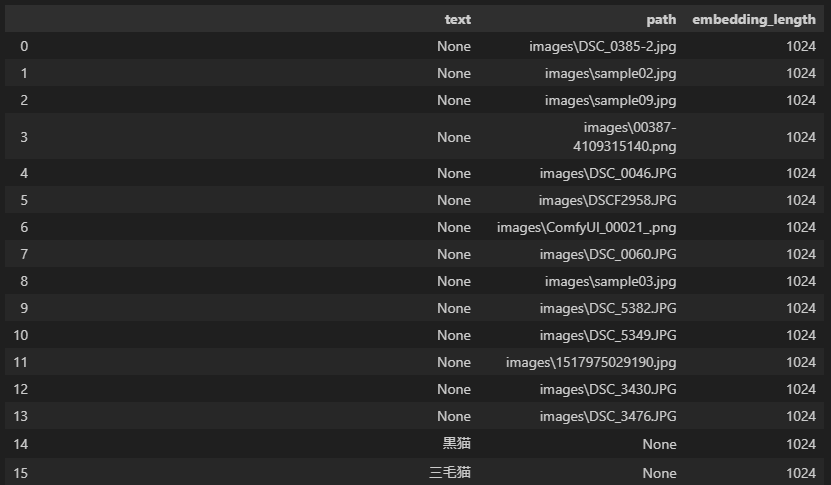
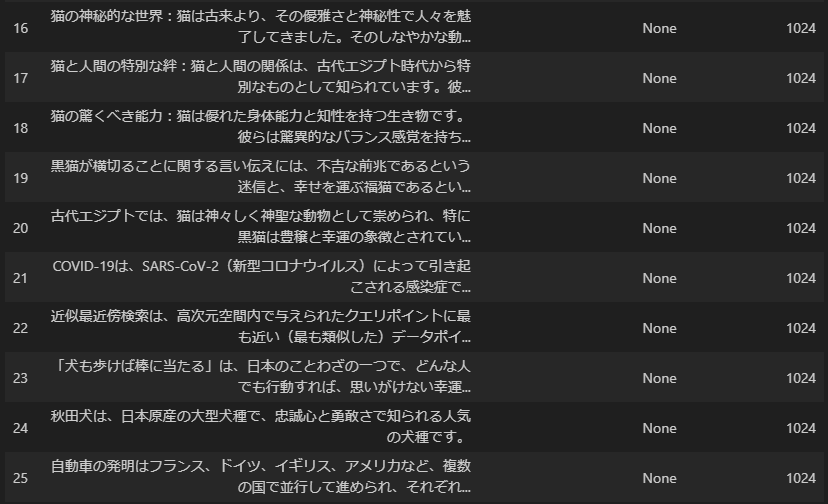
0 から 13 までは、これまでと同じ画像の埋め込みベクトルで、14以降が追加したテキストドキュメントの埋め込みベクトルです。
クエリーテキストの埋め込み生成
クエリーテキストの定義
query = ["猫と散歩する女の子"]
クエリーテキストの埋め込み処理
ret = co.embed(
texts=query,
input_type="search_query",
model="embed-multilingual-v3.0",
embedding_types=["float"],
)
query_embedding = ret.embeddings.float
print(f"クエリーテキストの埋め込みの次元数: {len(query_embedding[0])}")
クエリーテキストによる画像検索の実行
# クエリと文書の埋め込みベクトル間の類似度を計算
similarities = []
for i in range(len(doc_embeddings)):
similarity = calculate_similarity(query_embedding[0], doc_embeddings[i]["embedding"])
similarities.append(similarity)
# 結果をデータフレームに格納
results_df = pd.DataFrame({
'テキスト': [doc.get("text", "")[:300] + "..." if doc.get("text", "") and len(doc.get("text", "")) > 300 else doc.get("text", "") for doc in doc_embeddings],
'パス': [doc.get("path", "") for doc in doc_embeddings],
'類似度': similarities
})
# 類似度の降順でソート
results_df = results_df.sort_values('類似度', ascending=False).reset_index(drop=True)
# 結果を整形して表示
pd.set_option('display.float_format', '{:.4f}'.format)
display(results_df.style.set_properties(**{
'text-align': 'left',
#'white-space': 'nowrap',
'overflow': 'hidden',
'text-overflow': 'ellipsis',
'max-width': '500px' # テキスト列の最大幅を指定
})
.set_table_styles([
{'selector': 'th', 'props': [('text-align', 'left'), ('font-weight', 'bold')]},
{'selector': '.row_heading, .blank', 'props': [('display', 'none')]},
{'selector': 'td', 'props': [('padding', '5px')]},
{'selector': 'td:nth-child(1)', 'props': [('max-width', '400px'), ('overflow', 'hidden'), ('text-overflow', 'ellipsis')]} # テキスト列に特定のスタイルを適用
]))
検索結果を画像付きで表示
results_display = create_search_interface(query_type = "テキスト", query = query[0], max_images = 12, results_df = results_df, max_image_width=400, max_image_height=300)
gradio_server = results_display.launch()
出力例(ブラウザ表示のスクリーンショット)
Gradio サーバーを停止(忘れずに!)
results_display.close()
Closing server running on port: 7861
画像検索(4) - 画像をクエリーとした画像とテキストのミックス検索
クエリー画像の埋め込みベクトル生成
クエリー画像の定義
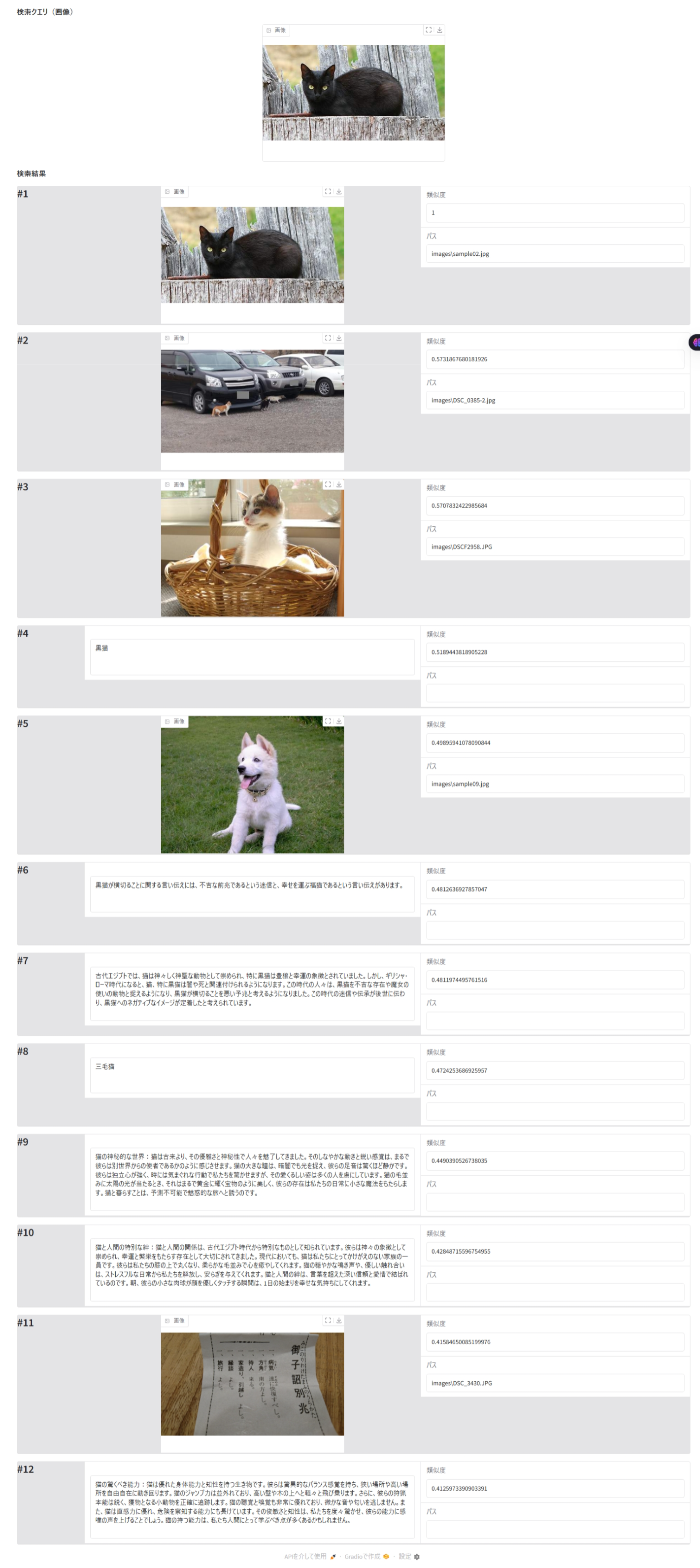
query_image_path = Path("images/sample02.jpg").as_posix()
img = Image.open(query_image_path)
plt.figure(figsize=(10, 8))
plt.imshow(img)
plt.title(f"クエリー画像", fontweight='bold', fontsize=14)
plt.axis('off')
plt.show()
出力例

クエリー画像の埋め込みベクトル生成処理
processed_image = image_to_base64_data_url(query_image_path)
ret = co.embed(
images=[processed_image],
input_type="image",
model="embed-multilingual-v3.0",
embedding_types=["float"],
)
query_embedding = ret.embeddings.float
print(f"クエリーの埋め込みの次元数: {len(query_embedding[0])}")
クエリー画像による画像検索の実行
# クエリと文書の埋め込みベクトル間の類似度を計算
similarities = []
for i in range(len(doc_embeddings)):
similarity = calculate_similarity(query_embedding[0], doc_embeddings[i]["embedding"])
similarities.append(similarity)
# 結果をデータフレームに格納
results_df = pd.DataFrame({
'テキスト': [doc.get("text", "")[:300] + "..." if doc.get("text", "") and len(doc.get("text", "")) > 300 else doc.get("text", "") for doc in doc_embeddings],
'パス': [doc.get("path", "") for doc in doc_embeddings],
'類似度': similarities
})
# 類似度の降順でソート
results_df = results_df.sort_values('類似度', ascending=False).reset_index(drop=True)
# 結果を整形して表示
pd.set_option('display.float_format', '{:.4f}'.format)
display(results_df.style.set_properties(**{
'text-align': 'left',
#'white-space': 'nowrap',
'overflow': 'hidden',
'text-overflow': 'ellipsis',
'max-width': '500px' # テキスト列の最大幅を指定
})
.set_table_styles([
{'selector': 'th', 'props': [('text-align', 'left'), ('font-weight', 'bold')]},
{'selector': '.row_heading, .blank', 'props': [('display', 'none')]},
{'selector': 'td', 'props': [('padding', '5px')]},
{'selector': 'td:nth-child(1)', 'props': [('max-width', '400px'), ('overflow', 'hidden'), ('text-overflow', 'ellipsis')]} # テキスト列に特定のスタイルを適用
]))
検索結果を画像付きで表示
results_display = create_search_interface(query_type = "画像", query = query_image_path, max_images = 12, results_df = results_df, max_image_width=400, max_image_height=300)
gradio_server = results_display.launch()
出力例
Gradio サーバーを停止(忘れずに!)
results_display.close()
Closing server running on port: 7861
画像検索(5) - ECサイトを想定した画像検索
こちらは、結果だけのご紹介ですが EC サイトを想定して商品画像から自然言語や画像で商品を検索してみました。結果の表示は Gradio ではなく matplotlib.pyplot と使っています。
商品画像のデータセットはE-commerce Product Imagesからお借りしています。
クエリー = "赤い靴の写真"

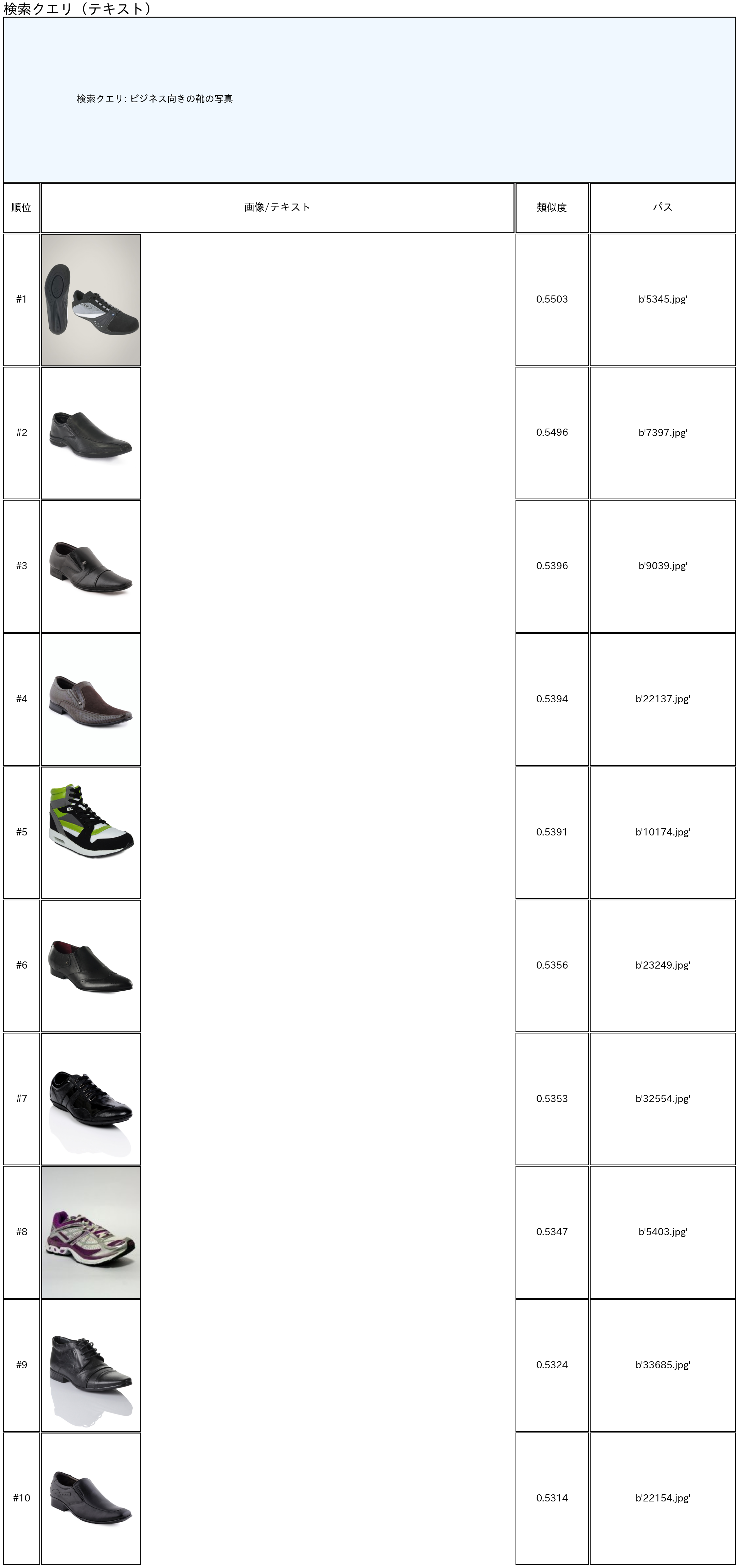
クエリー = "ビジネス向きの靴の写真"
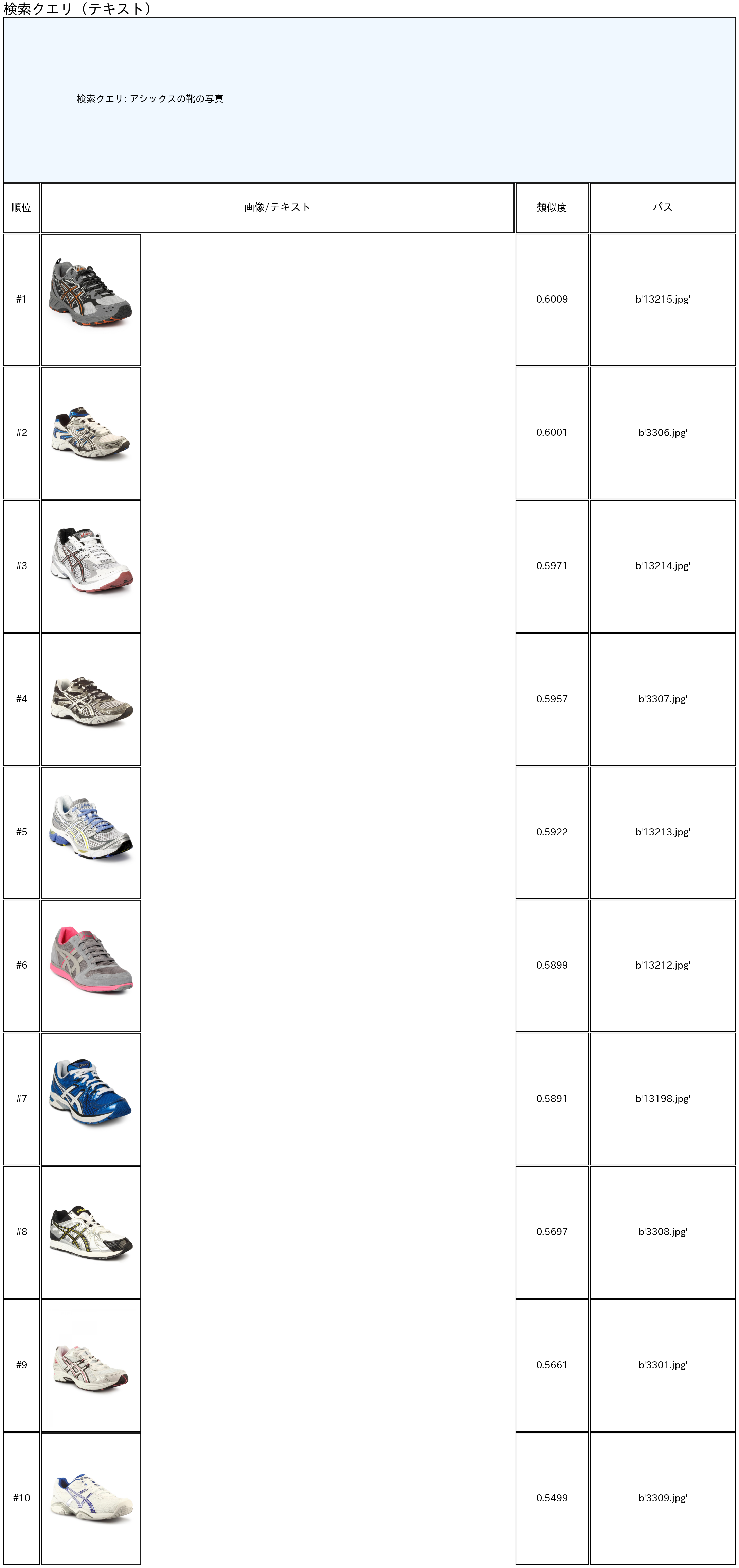
クエリー = "アシックスの靴の写真"
自分で用意した画像をクエリーとして

画像分類 - 航空写真を洪水被害を受けている地域のものか、そうでないか判定させる
FloodNet Datasetからお借りした画像10枚が洪水被害を受けている地域のものか、そうでないかを分類してみました。

この例では、10枚中8枚が正解しています。しかし、洪水の場合とそうでない場合のスコアの違いは非常にわずかです。実用的に使うためには後段の学習可能な分類器を置いて、ラベル付けされた大量の衛星画像で学習させる必要がありそうです。
あとがき
「はじめに」で触れたようにCohere 社の Embed 3 がマルチモーダルに対応した際のブログ によると、Cohere Embed 3 は、テキストと画像が同一のデータストア(ベクトルデータベース)にあるときのモーダリティ混合タスクで従来の CLIP を圧倒する精度を達成しているとのことでした。
今回の検証のうち次の2つのタスクが該当します。
- 画像検索(3) - テキストをクエリーとした画像とテキストのミックス検索
- 画像検索(4) - 画像をクエリーとした画像とテキストのミックス検索
CLIP などの従来の Vision-Language Model がこれらのタスクを苦手としているのは、従来の Vision-Language Model では、テキスト群の埋め込みと画像群の埋め込みが埋め込み空間の中で別のクラスターを形成しているためです。つまり、猫のテキスト埋め込みは犬の画像埋め込みよりは猫の画像埋め込みに近い、しかし、犬のテキスト埋め込みは、猫の画像埋め込みよりも猫のテキスト埋め込みに近いということが起きているためです。
先日、実際にこれを可視化したものが X に投稿されていました。
今回の画像検索(3)と画像検索(4)を見る限り、Cohere Embed 3 は、この問題をある程度克服しているようですね。
この問題は、テキストと画像を別々のベクトルストア(ベクトルデータベース、インデックス)に保存して、別々に検索することでも対処できますが、この場合はテキスト、画像のそれぞれの検索結果を統合して類似度で順位付けすることができないという問題があります。Cohere Embed 3 によってマルチモーダル埋め込みの用途がさらに広がりそうですね。