はじめに
「ChatGPTの回答、本当に正しいの?」「社内の機密情報は扱えないの?」「最新情報に対応できないの?」
生成AIの実用化に向けて、多くのエンジニアがこうした課題に直面しています。これらの課題に対する強力な解決策として注目を集めているのが、RAG(Retrieval-Augmented Generation:検索拡張生成)です。一方で、RAG はその基本的な考え方をダイレクトに実装しただけでは多くの応用において十分な精度を発揮できずプロジェクトが PoC から先へ進まないといった課題も目立っています。
本シリーズでは、RAGの基礎から実装の詳細まで、以下のような構成で解説していきます。
第1章(本記事)ー「RAGの基礎 ー LLMの限界とRAGによる解決への道」
第2章(公開済み)ー「RAGを支える技術 ー ベクトル検索の仕組み」(埋め込みモデルからベクトルデータベースまで)
第3章ー「ベクトル検索」(ChromaDB編)
第4章以降
- 基本的なRAGの仕組みと実装方法
- RAGの技術的課題と実践的な解決策
- RAGの最新動向と今後の展望
各章では、理論的な解説だけでなく、実際に動作する具体的なコード例を提供します。ChromaDBを使用した実装例、検索精度の向上のアプローチを紹介します。
この記事はウェビナー【Oracle AI JAM Session #20 生成AIをより賢く ー エンジニアのためのRAG入門】(2024年12月18日)の内容を、より詳細な解説とサンプルコードを加えて再構成したシリーズの第1章です。
セッション資料とデモプログラムを加筆修正して、丁寧に解説していきます。
それでは、生成AIをより賢く ー エンジニアのためのRAG入門(第1章)、始まります!
なぜ RAG が必要なのか?
大規模言語モデル(LLM)の基本的な仕組み
大規模言語モデル(Large Language Model:LLM)は、入力された文字列から次の単語(トークン:LLMが処理する最小単位となるテキストの断片で数値で表現されている)を予測するように訓練された機械学習モデルです。主に、インターネット上に公開されている大量の文章データを使って学習を行います。
詳細は、OraJAMでお馴染みの園田さんの QIITA の記事(ChatGPTのコア技術「GPT」をざっくり理解する)で分かりやすく解説されていますのでご一読を!(こちら↓)
2つの重要な仕組み ー 自己回帰とアテンション
現代の主要なLLMのアーキテクチャは、自己回帰(Auto-regression)とアテンション(Attention)の効果的な組み合わせにより実現されています。
自己回帰的生成
LLMは1つずつ単語を生成していく自己回帰的な方式を採用しています。
自己回帰的な生成では以下のような流れで文が生成されていきます。
- まず「日本」という単語が与えられると、次に来る可能性が高い単語「で」を予測
- 次にここまでに生成された「日本で」という文から、「一番」を予測
- さらに「日本で一番」から「高い」を予測
- このように、1つずつ順番に単語を生成していく
この自己回帰的な生成において重要なのは、『どのように過去の文脈を考慮するか』という点です。しかし、単純な自己回帰的生成だけでは離れた単語の影響は小さくなり、文全体の文脈を反映した生成ができません。そこで重要な役割を果たすのが、アテンション機構です。
アテンション機構
アテンション機構は、文章中の関連する情報を効果的に活用する仕組みとして開発されました。2017年にGoogleが論文"Attention Is All You Need"で提案したTransformerアーキテクチャは、このアテンション機構を中心に据えた革新的な設計を実現しました。
このアテンション機構により、生成時に以下のようなことが可能になりました。
- 全ての単語間の関係性を直接計算し、重要な情報を選択的に活用
- 離れた位置にある関連情報も、距離に関係なく効果的に参照
- 文脈に応じて各単語の重要度を動的に調整
例えば「日本で一番高い山は富士山です」という文を生成する場合を考えます。
従来の方式では、「日本で一番高い山は」から「富士」を予測する際、直前の数単語のみを主に参照していましたが、アテンション機構では、「富士」を予測する際に、冒頭の「日本」という情報を参照することも、「一番高い山」という文脈全体を考慮することも、これらの情報の重要度を状況に応じて調整することもできます。

ここでは、分かりやすく「単語」と表現しましたが、実際には LLM では入力された文章はまず「トークン」と呼ばれる単位に分割されます。
トークン化の仕組み
この自己回帰的生成とアテンション機構を効率的に機能させるため、入力テキストは適切な大きさのトークンに分割される必要があります。
トークン化においては、頻繁に使用される単語や文字パターンには専用のトークンが割り当てられます。一方で、めったに使用されない単語やパターンは、より小さな単位(文字やバイト)に分解されて処理されます。これにより、効率的なテキスト処理が可能になっています。
トークン化の方法は言語によって異なり、特に日本語の場合は英語のようにスペースで区切られていないため、独自の分割ルールが適用されます。
このようなトークン化を行う仕組みを トークナイザー と呼びます。
主なトークン化アルゴリズム
トークン化の具体的な実装方式として、以下のような手法が広く使用されています。
-
BPE(Byte Pair Encoding)
- 頻出する文字の組み合わせを繰り返し結合していく手法
- GPT系のモデルで採用されている手法の基礎
- 例)「low」「er」→「lower」のように頻出する部分を一つのトークンとして扱う
-
WordPiece
- BPEの変種で、結合時に頻度だけでなく尤度(あるパターンが実際に正しい単語の一部である確率)も考慮
- BERTなどのモデルで採用
- 学習データにない新しい単語でも適切に分割して処理できる特徴を持つ
-
SentencePiece
- 事前の単語分割や言語固有の規則に依存せず、前処理なしのテキストを直接学習して分割規則を自動的に獲得
- 言語に依存しない(言語非依存)な分割が可能
- 特に日本語や中国語などの分かち書きのない言語で効果的
トークン化の LLM への影響
トークン化の方式は以下のような面でLLMの性能に大きく影響します。
- 処理効率 ー 効率的なトークン化により、同じ文章でもより少ないトークン数で表現可能
- 学習データにない新しい単語への対応 ー 適切な分割により、学習データにない単語でも対応可能
- 文脈理解 ー 意味のある単位でのトークン化により、より正確な言語理解が可能
モデルごとの違い
異なるLLM 間(正確には、トークナイザー間)でトークン化の効率は異なります。例えば、GPT-4とCohere Command R などのモデルを比較すると、同じ日本語テキストでもトークンの割り当てや効率が異なることが分かります。
試しに、OpenAI GPT-4o と Cohere Command R で比較するため、次の文章をトークン化してみます。
| 日本国憲法前文の冒頭(149文字) |
|---|
| 日本国民は、正当に選挙された国会における代表者を通じて行動し、われらとわれらの子孫のために、諸国民との協和による成果と、わが国全土にわたって自由のもたらす恵沢を確保し、政府の行為によって再び戦争の惨禍が起ることのないやうにすることを決意し、ここに主権が国民に存することを宣言し、この憲法を確定する。 |
OpenAI GPT4-0

Tokenizer Arena でトークン化とトークン分割の可視化をしています。130トークンに分割されています。
Cohere Command R
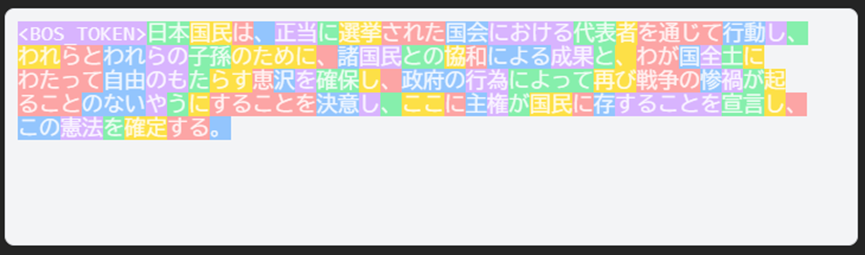
こちらは、The TokenizerPlaygroundでトークン化とトークン分割の可視化をしています。85トークンに分割されています。
分割されたトークン数が異なることに加えて、GPT-4o では、「?」と表示されているところがあります。例えば、「選挙」の「挙」が「?」となっています。これは、入力されたテキストにトークンが割り当てられていないことを意味しています。このような場合、トークナイザーは、Unicodeの各バイトに割り当てられたトークンを使用します。そのため、「挙」という一文字が「?」2つ、つまり、二つのトークンに分割されています。
Cohere Command R/R+ の日本語トークン化の効率については以下のブログで検証方法と結果をご紹介しています。
このように、LLMは自己回帰的な生成方式とアテンション機構による高度な文脈理解を組み合わせることで、人間のような自然な文章生成を実現しています。ただし、モデルの出力は常に確率的な予測に基づいているため、時として不正確な情報や誤った内容を生成する可能性があることにも注意が必要です。
LLM が得意なこと
大規模言語モデル(LLM)は、インターネット上の膨大な情報を学習することで、様々な能力を獲得しています。その主な強みは以下の分野で発揮されます。
テキスト生成
LLMは、与えられたプロンプトに基づいて一貫性のあるテキストを生成する能力を持っています。これは単なる文章作成に留まらず、創造的なストーリー作成、製品説明文の生成、ビジネスプレゼンテーションの原稿作成など、幅広い用途に活用できます。たとえば、Netflixのドラマの脚本第一稿を作成したり、商品レビューやSNSコンテンツを生成したりすることができます。
情報の理解と推論
複雑な情報を理解し、論理的な推論を行うことができます。与えられた情報から結論を導き出したり、因果関係を分析したり、新しいアイデアを提案したりすることが可能です。たとえば、市場動向の分析レポートの作成や、問題解決のためのアクションプランの提案などに活用できます。
タスクの計画立案
複雑なタスクを小さなステップに分解し、実行可能な計画を立案することができます。これはプロジェクト管理、イベント計画、学習カリキュラムの設計などに有用です。また、AIエージェントとして機能する際には、目標達成のための効率的な行動計画を立てることができます。
翻訳
多言語に対応し、文脈を理解した適切な翻訳が可能です。特筆すべきは、単なる逐語訳ではなく、文化的なニュアンスも考慮した翻訳ができることです。アニメの多言語字幕生成や、グローバルeコマースの商品説明、国際会議のリアルタイム通訳支援などに活用できます。
要約
長文の記事や文書を効率的に要約する能力を持っています。ビジネス会議の議事録作成、学術論文のダイジェスト化、ニュース記事のショート動画用原稿など、情報を簡潔にまとめることができます。
質問応答とインタラクション
自然言語による質問(問い合わせ)に対して人間のような自然な文章による回答を生成する能力があり、これはFAQの自動応答やカスタマーサポートのチャットボットとして活用できます。さらに、メタバース内のNPCキャラクター対話やオンライン教育の個別指導など、インタラクティブな対話にも応用可能です。また、質問の意図を理解し、状況に応じて適切な追加質問を行うことで、より深い理解と正確な回答を導き出すことができます。
データ分析と分類
テキストの内容を分析し、指定されたカテゴリーに分類することができます。これは、SNSトレンド分析、ESG投資のための企業活動評価、コンテンツモデレーションなどに活用できます。また、テキストの感情を分析し、ポジティブ、ネガティブ、ニュートラルなどの感情を分類することで、ブランドレピュテーション分析やユーザー感情の理解に役立ちます。
プログラミング支援
コードの生成や説明にも優れています。自然言語での指示に基づいてコードを生成したり、既存のコードを分かりやすく説明したりできます。これにより、開発効率の向上や、プログラミング学習支援に貢献できます。
マルチモーダル理解
最新のLLMは、テキストだけでなく画像も理解し、それらを統合的に処理する能力を持っています(マルチモーダルLLM(MLLM)、もしくは、Large Vision Language Model(LVLM) と呼ばれます)。画像付きの質問に対して文脈を理解した回答を生成したり、画像の詳細な説明を生成したりすることができます(Visual Question Answering(VQA))。例えば、製品の写真を見ながら仕様について質問に答えたり、医療画像に対して所見を記述したり、技術図面の説明を生成したりすることが可能です。これは、特に技術文書の理解、医療診断支援、Eコマースなどの分野で強力なツールとなっています。
画像理解の能力は日々進化しており、以下のようなタスクで特に効果を発揮します。
- 技術文書や図面の解説 ー 複雑な図表やダイアグラムの説明生成
- 医療画像分析 ー X線写真やMRI画像の初期評価支援
- Eコマース ー 商品画像からの自動タグ付けや詳細説明の生成
- 教育コンテンツ ー 視覚的な教材の解説や補足説明の生成
- 品質管理 ー 製造ラインでの製品外観検査の支援
| 得意なこと | 現代的な活用例 |
|---|---|
| テキスト生成 | • ビジネスプレゼンのストーリー作成 • ドラマのシナリオ第一稿 • 商品レビューやSNSコンテンツの作成 • マーケティングコピーの生成 • 研究論文やレポートの執筆支援 • パーソナライズされたメールの作成 |
| 情報の理解と推論 | • 市場動向の分析レポート作成 • 複雑な問題の解決策提案 • 科学的仮説の検証支援 • ビジネスケース分析 • 法的文書の解釈支援 • 医療診断支援のための情報分析 |
| タスクの計画立案 | • プロジェクト実行計画の策定 • イベント企画の詳細設計 • 学習カリキュラムの最適化 • AIエージェントの行動計画作成 • 災害対応シナリオの策定 • 効率的な業務フロー設計 |
| 翻訳 | • アニメの多言語字幕生成 • グローバルeコマースの商品説明 • 国際会議のリアルタイム通訳支援 • 技術文書のローカライゼーション • 多言語SNSマーケティング • クロスカルチャーコミュニケーション支援 |
| 要約 | • ビジネス会議の議事録作成 • 学術論文のダイジェスト化 • ニュース記事のショート動画用原稿 • 長文レポートのエグゼクティブサマリー • 法律文書の要点整理 • 市場調査データの簡略化 |
| 質問応答とインタラクション | • インテリジェントチャットボット • メタバース内のNPCキャラクター対話 • オンライン教育の個別指導 • カスタマーサポートの自動化 • ヘルスケアの初期診断支援 • 研究開発の質問応答システム |
| データ分析と分類 | • SNSトレンド分析 • ESG投資評価支援 • コンテンツモデレーション • 顧客フィードバックの感情分析 • 市場セグメンテーション • リスク評価と分類 |
| プログラミング支援 | • コード生成と最適化 • プログラミング教育コンテンツ作成 • レガシーコードの現代化支援 • APIドキュメント自動生成 • バグ修正提案 • コードレビュー支援 |
| マルチモーダル理解 | • 画像付きSNSの文脈理解 • 技術図面の説明生成 • 医療画像の所見作成支援 • プレゼン資料の分析と改善提案 • 製品カタログの自動タグ付け • ビジュアルコンテンツのナレーション生成 |
このように、LLMは言語処理に関連する幅広いタスクで高い能力を発揮します。ただし、これらの能力を最大限に活用するためには、適切なプロンプト(LLM への指示文)の設計やコンテキスト(プロンプトと共に LLM へ与えられる入力情報)の提供が重要です。特に、複雑なタスクや推論を必要とする場合は、明確な指示と十分な情報の提供が必要となります。
LLMが不得意なこと
LLMの限界と課題について、主に3つの重要な点があります。
ハルシネーション(幻覚)の発生
LLMは学習データに基づいて回答を生成するため、正確でない情報を生成してしまうことがあります。例えば「推しの子」の主人公について ChatGPT に聞いてみたところこのような答えが返ってきました。

(このスクリーンショットは、2024年6月に CHatGPT へ質問した際のものです。現在(2025年1月時点)では、事前学習データが増えたのか正しい回答が返ってくるようになっています)
外部データがない状態では「アクアリウス」という誤った名前を答えてしまいました。これは、主人公の通称「アクア」の本名を推測する際に、LLMが水がめ座を意味する「アクアリウス」という一般的な単語を予測してしまったためです。一方、Wikipediaの情報を外部データとして与えると、正しい情報である「アクア/星野愛久愛海(ほしの あくあまりん)」と回答できました。

(ChatGPTへアップロードしたPDFファイルは、Wikipedia の推しの子の記事です)
非公開情報への対応の限界
LLMは公開情報のみで学習しているため、企業の内部規定や手続きなど、非公開の情報(いわゆるドメイン・ナレッジ)については適切に回答することができません。例えば、雪道運転の一般的な注意事項については適切に回答できますが、特定の会社の海外出張の社内手続きについては回答することができません。

このように雪道での運転の一般的な注意事項のような公開データにある常識的なことはそれらしく答えられています(ただし、正しいとは限らずハルシネーションかもしれません)。
一方で、インターネット上に公開されていない自社の社内規定ではどうでしょうか?
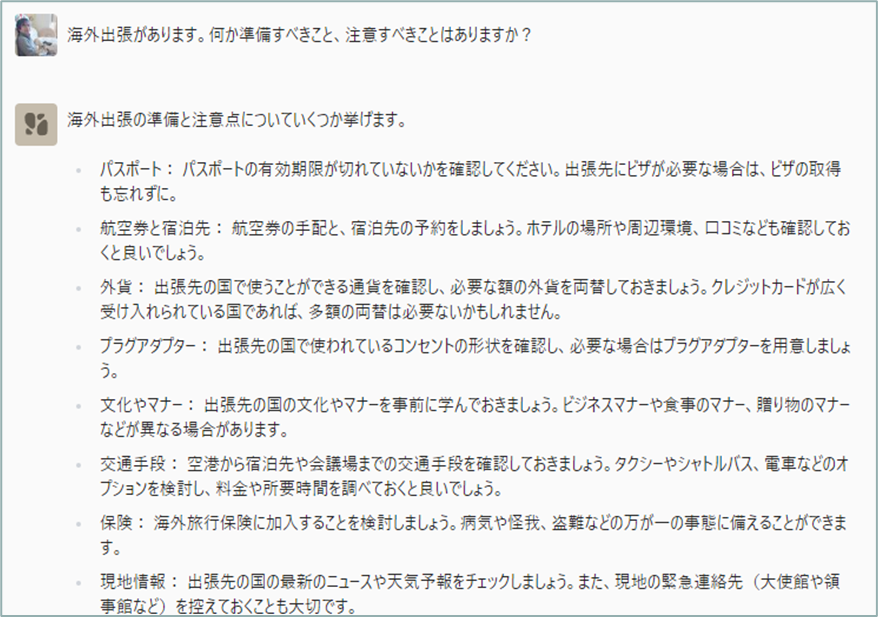
やはり、公開データにある常識的なことは答えてくれますが勤め先の社内手続きのことはアドバイスしてくれません。
最新情報の把握の制約
LLMは事前学習した時点(カットオフ)までの情報しか持っていないため、それ以降に発生した出来事や変更された情報については回答することができません。これは、常に変化するビジネス環境や最新のニュースなどへの対応において大きな制約となります。
このような限界に対処するためには、以下の点に注意する必要があります。
- 重要な事実確認が必要な場合は、必ず信頼できる外部データを参照する
- 企業固有の情報や手続きについては、適切な内部データベースと組み合わせて使用する
- 定期的に最新情報で更新された外部データを提供する
LLMを効果的に活用するには、これらの限界を理解した上で、適切な使用方法を選択することが重要です。特に企業での利用においては、RAG(検索拡張生成)などの手法を用いて、これらの限界を補完することが必要です。
Retrieval-Augmented Generation ー RAG(検索拡張生成)とは
LLMの限界を克服するための重要な技術として、RAG(Retrieval-Augmented Generation ー 検索拡張生成)があります。RAGは、LLMの生成能力を外部データベースからの情報検索で補強する手法です。
RAGのしくみ
RAGを実装していないAIチャットボットと実装しているものを比較すると、その違いは明確です。
RAGなしの場合

ユーザーからの質問(例 ー 「海外出張の準備は?」)に対して
- LLMは学習済みの一般的な知識のみに基づいて回答(例 ー 「パスポートを用意してください」)
- 企業特有の手続きや最新の規定を反映できない
RAGありの場合

ユーザーからの質問に対して
- システムは最初にデータベースを検索
- 社内規定集等のドキュメントから関連情報を取得
- 取得した情報とユーザーの質問を組み合わせてLLMに提供
- LLMは提供された具体的な情報に基づいて回答を生成(例 ー 「XXXで事前申請してください」)
RAGの基本アーキテクチャ
RAGのプロセスは、以下の3つの主要なステップで構成されています。
- データの準備と埋め込み処理
- 文書データベースから情報を取得
- テキストを適切な大きさのチャンク(断片)に分割
- 埋め込みモデルを使用してベクトル化
- ベクトルデータベースにインデックスを作成
- ベクトル検索プロセス
- ユーザーの質問をベクトル化
- ベクトルデータベースで類似度検索を実行
- 最も関連性の高い文書を抽出
- LLMによる回答生成
- 検索結果とユーザーの質問を組み合わせてプロンプトを生成
- LLMが提供された情報に基づいて回答を生成
RAGの目的と利点
RAGには主に3つの重要な目的・効果があります。
-
ハルシネーション(幻覚)の低減
- 外部データベースからの正確な情報を参照することで
- 誤った情報の生成を抑制(ゼロにはできないものの大幅に削減)
-
社内固有の知識への対応
- データベースに登録された社内文書や規定を検索
- 組織特有の情報に基づいた正確な回答が可能
-
最新情報への対応
- データベースを更新することで、常に最新の情報に基づいた回答が可能
- LLMの学習時点以降の新しい情報にも対応可能
RAGは、LLMの基本的な能力を活かしながら、その限界を補完する効果的な手法として、特に企業での実用化において重要な役割を果たしています。最新のガイドラインや規定に基づいた正確な情報提供が必要なビジネス環境において、RAGの活用は不可欠となっています。

LLMの外部知識の扱い方
RAGの効果をより深く理解するため、LLMが外部から提供された情報をどのように扱うのかについて、興味深い研究結果が報告されています。Xieらの研究(2024)によると、LLMは以下のような特徴的な行動を示します。
-
事前学習知識と外部知識が矛盾する場合
- LLMは外部から提供された検索結果などの情報を優先します
これはRAGが効果的に機能する重要な特性の一つです。LLMが自身の事前学習内容よりも、提供された最新かつ正確な情報を基に回答を生成することを示しています。
-
複数の外部知識が互いに矛盾する場合
- LLMは事前学習で得た知識と整合性のある外部知識を優先します
この研究結果は、RAGを実装する際の重要な知見を提供しています。具体的には、RAGシステムを通じて提供される外部情報の品質管理の重要性や、複数の情報源がある場合の取り扱いについての指針となります。
このような特性により、RAGは単なる情報の付加ではなく、LLMの回答品質を実質的に向上させる手法として機能していることが分かります。例えば、オラクル製品に関するQAシステムを考えると、LLMは、多くのオラクル製品について事前学習で知識を獲得している可能性が高いのですが RAG を使うことでハルシネーションを低減してより正確にオラクル製品に関する回答を生成できると期待できます。
RAG と In-Context Learning(文脈内学習)、プロンプトエンジニアリング
大規模言語モデル(LLM)には「In-Context Learning(文脈内学習)」という興味深い能力があります。これは、新しい情報を与えられたときに、追加の学習をしなくても、その場で理解して適切に対応できる能力です。
たとえば、特定の分野の専門用語や説明を文脈として与えると、LLMはその内容を理解し、関連する質問に答えることができます。
この能力を活かしているのが「RAG(検索拡張生成)」という技術です。RAGは、LLMが必要な情報を外部から探し出し、その情報を理解した上で回答を生成します。これにより、LLMの元々の知識だけでは答えられない質問にも対応できるようになります。
そして、これらの技術を効果的に使うための工夫が「プロンプトエンジニアリング」です。LLMへの指示の仕方を工夫することで、
- 検索された情報をより正確に理解させる
- 文脈に沿った適切な回答を生成させる
- 誤った回答を生成する(ハルシネーション ー 幻覚)を減らす
といった効果が期待できます。
これら3つの技術が組み合わさることで、LLMはより正確で信頼性の高い回答を提供できるようになります。
マルチモーダルRAGの可能性
RAGの応用は、テキストデータだけでなく、画像やビデオなどのマルチモーダルなコンテンツにも広がっています。マルチモーダルRAGでは、ビジョン・ランゲージ・モデル(MLLM/LVLM) を活用することで、以下のような高度な情報検索と生成が可能になります。
-
画像とテキストの統合的理解
- 技術文書や図面の説明生成
- 製品カタログからの視覚的情報抽出
- 医療画像の診断支援
-
表データの構造化抽出
- 財務諸表や帳票からの数値データ抽出
- 手書き文書のデジタル化
- ビジネス文書からの表形式データの取得
-
画像内のテキスト認識(OCR)との連携
- 手書き文字を含む文書の理解
- 複雑なレイアウトの文書からの情報抽出
- 多言語文書の処理
このようなマルチモーダルRAGの実現には、高性能なビジョン・ランゲージ・モデルが不可欠です。最近では、オープンソースのモデルも商用モデルに匹敵する性能を持つようになってきており、企業での実用的な導入の可能性が広がっています。
ただし、マルチモーダルRAGを実装する際には、以下の点に注意が必要です。
- 画像認識の精度と信頼性の確保
- ハルシネーション(幻覚)への対策
- 計算リソース(特にGPUメモリ)の要件
- 処理速度とレイテンシーの最適化
これらの課題に適切に対処することで、テキストと視覚情報を組み合わせた、より高度で実用的なRAGシステムを構築することが可能になります。
まとめ
本章では、RAGが注目される背景として、LLMの基本的な仕組みと、その得意分野・不得意分野について解説しました。
LLMは自己回帰的生成とアテンション機構を組み合わせることで、テキスト生成、情報理解、タスク計画、翻訳、要約など、多岐にわたる言語処理タスクで高い能力を発揮します。一方で、ハルシネーション(幻覚)の発生、非公開情報への対応の限界、最新情報の把握の制約という3つの重要な課題も抱えています。
これらの課題に対する解決策として注目されているのがRAG(Retrieval-Augmented Generation ー 検索拡張生成)です。RAGは外部データベースからの情報検索でLLMの生成能力を補強する手法で、以下の効果が期待できます。
- ハルシネーションの低減 ー 外部データベースからの正確な情報参照による誤情報生成の抑制
- 社内固有の知識への対応 ー 組織特有の情報に基づいた正確な回答の実現
- 最新情報への対応 ー データベース更新による最新情報の反映
特に企業での実用化において、RAGはLLMの基本的な能力を活かしながらその限界を補完する効果的な手法として、重要な役割を果たしています。次章以降では、このRAGを実現するための技術的な詳細と実装方法について解説していきます。
次章のご案内
【生成AIをより賢く ー エンジニアのためのRAG入門(第1章)「RAGの基礎 ー LLMの限界とRAGによる解決への道」】を最後までお読みいただきありがとうございます。
第2章「RAGを支える技術 ー ベクトル検索の仕組み」では、RAGの実装の核となるベクトル検索の技術的な詳細に踏み込んでいきます。埋め込みモデルの仕組みから、最新のベクトルデータベース技術まで、実装に必要な基礎知識を丁寧に解説します。特に、
- なぜRAGでベクトルデータベースが注目されているのか
- テキストをベクトル化する仕組み(Static EmbeddingとTransformerベースの比較)
- 効率的な検索を実現する技術(プーリング、近似最近傍探索など)
- 埋め込みの可視化
- 実際の検索結果の可視化例
といった内容を、具体例を交えながら分かりやすく説明していきます。
後続の章では、第3章で「ベクトル検索」(ChromaDB編)、そして、第4章以降では、「基本的なRAGの仕組みと実装方法」、「RAGの技術的課題と実践的な解決策」、「RAGの最新動向と今後の展望」について扱う予定です。
関連記事のご案内
