はじめに
「ChatGPTの回答、本当に正しいの?」「社内の機密情報は扱えないの?」「最新情報に対応できないの?」
生成AIの実用化に向けて、多くのエンジニアがこうした課題に直面しています。これらの課題に対する強力な解決策として注目を集めているのが、RAG(Retrieval-Augmented Generation ー 検索拡張生成)です。一方で、RAG はその基本的な考え方をダイレクトに実装しただけでは多くの応用において十分な精度を発揮できずプロジェクトが PoC から先へ進まないといった課題も目立っています。
本シリーズでは、RAGの基礎から実装の詳細まで、以下のような構成で解説していきます。
第1章(公開済) ー 「RAGの基礎 ー LLMの限界とRAGによる解決への道」
第2章(本記事) ー 「RAGを支える技術 ー ベクトル検索の仕組み」(埋め込みモデルからベクトルデータベースまで)
第3章 ー 「ベクトル検索」(ChromaDB編)
第4章以降
- 基本的なRAGの仕組みと実装方法
- RAGの技術的課題と実践的な解決策
- RAGの最新動向と今後の展望
本記事の第2章 ー 「RAGを支える技術 ー ベクトル検索の仕組み」(埋め込みモデルからベクトルデータベースまで)では、非構造化データを RAG で活用するために最もよく利用されるベクトルデータベースと、文章や画像などの意味を考慮した検索の要となる埋め込み に焦点を当てます。
後続の各章では、理論的な解説だけでなく、実際に動作する具体的なコード例を提供します。ChromaDBを使用した実装例、検索精度の向上のアプローチを紹介します。
この記事はウェビナー【Oracle AI JAM Session #20 生成AIをより賢く ー エンジニアのためのRAG入門】(2024年12月18日)の内容を、より詳細な解説とサンプルコードを加えて再構成したシリーズの第2章です。
セッション資料とデモプログラムを加筆修正して、丁寧に解説していきます。
それでは、生成AIをより賢く ー エンジニアのための RAG入門 第2章 「RAGを支える技術 ー ベクトル検索の仕組み」(埋め込みモデルからベクトルデータベースまで)、始まります!
ベクトルデータベースとは
なぜRAGでベクトルデータベースが注目されているのか

RAGシステムにおいて、ベクトルデータベースは非構造化データを効果的に活用するための重要な技術として注目されています。その主な理由は以下の通りです。
-
意味的な検索の実現
- 従来のキーワード検索と異なり、文章の意味を考慮した検索が可能
- 同義語や類似表現を含む文章も検索可能
- ユーザーの質問の意図に沿った情報の取得が可能
-
大規模データへの対応
- 企業内の大量の文書や非構造化データを効率的に検索可能
- スケーラブルな検索基盤の構築が可能
-
高速な検索性能
- 事前に計算された埋め込みベクトルを使用することで、高速な検索が可能
- 近似最近傍探索(Approximate Nearest Neighbor(ANN))により、大規模データでも実用的な応答時間を実現
データの格納形式
ChromaDB を例に、ベクトルデータベースに格納されているデータの構造を見てみましょう。

各レコードは以下の3つの要素で構成されています。
- テキストのチャンク ー 元のドキュメントを分割した文章の断片
- 埋め込み(エンベディング、ベクトル) ー テキストを数値化したベクトル表現
- メタデータ ー ソースドキュメントの名前などの付加情報
埋め込み(エンベディング)の仕組み
埋め込みは、テキストや画像などのデータをベクトル空間上の点として表現する方法です。

上図で示されているように、例えば猫、犬、車といった異なるオブジェクトは、それぞれの特徴を数値化することで多次元ベクトルとして表現されます。
このベクトル表現では、以下のような特徴を持ちます。
- 各次元が特定の特徴(ふさふさ度、ひげ度など)を表現
- 似た特徴を持つオブジェクトは、ベクトル空間上で近くに配置される
- 特徴の違いが大きいオブジェクトは、空間上で離れて配置される
画像や文書などの特徴を数値ベクトルの形で表現したものを特徴ベクトルと呼びます。特徴ベクトルの中でも、特に深層学習の表現学習で得られたものを埋め込み(エンベディング) と呼びます(厳密な用語の使い分けの定義があるわけではありません)。また、深層学習により埋め込みを生成する機械学習モデルを埋め込みモデルと呼びます。
この埋め込み(エンベディング)が織りなすベクトル空間を埋め込み空間と呼びます。似た事物は、似た特徴を持ち、この多次元の埋め込み空間(ベクトル空間)の中で近くに位置することとなります。
埋め込みモデルの仕組み
埋め込みモデルには、大きく分けて2つのアプローチがあります。Static Embedding(静的埋め込み)と Transformer ベースの文脈考慮型埋め込みです。
Static Embedding
Static Embeddingは、Word2VecやGloVeなどに代表される手法で、各単語に対して固定された埋め込みベクトルを割り当てます。
- まず、テキストはトークン(単語や部分文字列)に分割されます
- 各トークンは、事前に学習された固定のベクトルに変換されます
- このベクトルは、大規模なテキストコーパスから学習された単語の共起関係を反映しています
共起関係とは、ある単語が別の単語と一緒に使われやすい傾向のことを指します。
- 「コーヒー」という単語は「飲む」「カップ」「豆」「香り」などの単語と共に出現しやすい
- 「病院」は「医師」「看護師」「治療」「診察」などと共に出現する頻度が高い
- 「プログラミング」は「コード」「開発」「言語」「バグ」などと共によく使われる
Word2Vecなどの静的埋め込みモデルは、この共起関係を利用して単語の意味をベクトル化します。大量のテキストデータを分析し、単語同士の共起パターンを学習することで、意味的に近い単語は似たようなベクトル表現を持つようになります。
Static Embeddingの重要な特徴として、単語の文脈非依存性があります。例えば、"bank"という単語は、「銀行(bank)で口座を開設する」という文でも、「土手(bank)を散歩をする」という文でも、文脈に関係なく同一のベクトル表現に変換されます。このため、多義語の異なる意味を区別できないという制限があります。
また、各単語の埋め込みベクトルは、学習データ内での共起関係から計算された固定値となります。つまり、一度学習が完了すると、各単語に対応するベクトルは変化せず、固定された値として使用されます。
シンプルで効率的で軽量であるため、エッジデバイスやブラウザ環境での利用に適しています。
最近では、LLM 同様にアテンション機構による文脈を考慮したTransformerベースの埋め込みモデル(次項)が注目されてますが、Static Embedding は、現在でも発展を続けています。2025年1月 にも以下のような新しい研究/モデルも公開されています。
- Train 400x faster Static Embedding Models with Sentence Transformers
- 100倍速で実用的な文章ベクトルを作れる、日本語 StaticEmbedding モデルを公開
次に紹介するTransformerベースのモデルでは、多義語の文脈依存性を捉え、より柔軟な埋め込みを生成可能となっています。
Transformerベースの文脈考慮型埋め込み
より高度な埋め込みモデルは、BERTやGPTなどのTransformerアーキテクチャを基盤としています。これらのモデルは、入力テキストの文脈を考慮して動的に埋め込みを生成します。
処理の流れは以下のようになります。
- テキストは、まずStatic Embeddingと同様にトークンに分割されます
- 各トークンは、基本的なベクトル表現に変換されます。この段階では、Static Embeddingに似た形で単語の基本的な意味が表現されます
- ここからが重要な違いです。Transformerモデルは、周囲の単語との関係性(文脈)を計算します。これは、人間が文章を読むときに前後の文脈を考慮することに似ています
- この文脈の計算を何度も繰り返すことで、より深い理解に基づいた最終的な埋め込みが生成されます
このアプローチの特徴は、Static Embeddingとは異なり、同じ単語でも文脈によって異なる埋め込みが生成される点です。例えば、"bank"という単語は
- 「銀行に行く」という文では金融機関としての意味を反映した埋め込みに
- 「土手を散歩する」という文では河川敷としての意味を反映した埋め込みに
それぞれ変換されます。
下図は、同じ単語("bank")が異なる文脈において異なる埋め込みに変換される例です。

Wiedemann らのDoes BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized Embeddings より異なる文脈における"bank"のコンテキスト埋め込みの例
また、最近のTransformerベースのモデルは、入力テキストを効率的に処理するために、様々なトークン化戦略(BPE、WordPiece、SentencePieceなど)を採用しています。これにより、未知語や複合語も適切に処理することが可能になっています。
このように、Transformerベースのモデルは、より豊かな文脈情報を捉えることができる一方で、計算コストが高くなるというトレードオフがあります。
また、Static Embedding モデルでも、Transformerベースのモデルでも埋め込みモデルから得られる出力は各トークンに対応する埋め込みベクトルの系列となるため、これを効率的に利用するための工夫が必要となります。
Pooling(プーリング)の役割
埋め込みモデルは入力テキストの各トークンに対応する埋め込みの系列を生成します(トークンの数だけ埋め込みが生成される)。しかし、ベクトルデータベースのような実際のアプリケーションでは、文書やフレーズ全体を1つの埋め込みとして表現したほうが扱いやすく、効率的です。ここで重要となるのが、Pooling(プーリング)と呼ばれる操作です。
Poolingは、複数の埋め込みから単一の埋め込み表現を生成する手法です。主な手法として以下があります。
Mean Pooling(平均プーリング)
最も一般的なアプローチの1つで、全てのトークンの埋め込みの平均を取ります。文書全体の意味を均等に反映させる特徴があります。
Max Pooling(最大プーリング)
各次元で最大値を取る手法です。特に顕著な特徴を捉えるのに有効です。ただし、文書の一部の情報のみが強調される可能性があります。
CLS Token Pooling(CLSトークンプーリング)
BERTなどのTransformerモデルでよく使われる手法です。文頭に特別なトークン([CLS])を配置し、このトークンの最終層の出力を文書全体の表現として使用します。モデルは学習時に、このトークンが文書全体の意味を要約するように訓練されています。
Attention Pooling(アテンションプーリング)
トークンの重要度を学習可能なパラメータとして持ち、重み付き平均を計算する手法です。文脈に応じて適応的に重要なトークンを強調できます。
下図は、Mean Pooling(平均プーリング)のイメージです。

このようなプーリングにより埋め込みが持っていた特徴をある程度反映しつつ容量を劇的に小さくすることができ、ストレージ容量を抑えることができます。そして、後の検索の際の演算量を少なくすることができます。
埋め込みの可視化の例
埋め込みの可視化の例(人事部門/経理部門への質問文)

これは、人事・経理各部門への仮想的な質問文の埋め込みを OCI Generative AI サービスのプレイグラウンドで Cohere Embed Multilingual V3(Transformerベース) で生成した埋め込みを可視化したものです。1から20の人事部門への質問は右半分に、21から40の経理部門への質問は左半分に偏って分布していることがわかります。
確かに 意味的な何か (深層学習が見出した特徴)が埋め込みに反映されているようです。
埋め込みの可視化の例(総務省公開のFAQ)
WizMap による可視化

こちらは、総務省のサイトで公開されている国・地方共通相談チャットボット Govbot(ガボット)に搭載されている各分野のFAQデータ(全分野)の「問い」を WiZMap で次元削減(二次元へ射影)して可視化したものです。WiMapのデモサイト でインタラクティブに見ていただくことができます。圧縮された二次元空間の中でも似た「問い」が集まっていることを見ていただくことができます。
なお、WizMap に使い方は下記の記事でご紹介しています。
UMAP による可視化(1)

こちらは、先程と同じ総務省が公開している FAQ の「問い」を UMAP で可視化したものです。「問い」が「大分類」毎にクラスターを形成していることがわかります。
こちらの手順も上の記事でご紹介してます。
UMAP は、局所的な構造に注目して強調するため実際以上にクラスタの存在が強調されてしまうことがあります。つまり、本当は存在していないクラスタが見えてしまうことがあります。PCAなどの大局的な構造に注目する手法と併用することが必要です。
また、マルチモーダルな埋め込みの場合には、事物の意味的なクラスタの前にモーダル毎のクラスタが見えてしまい一見モーダルを越えた類似性が埋め込みに反映されていないように見えてしまうことがあります。例えば、テキストと画像のマルチモーダルな埋め込みを UMAP で可視化すると、テキストから生成した埋め込みのクラスタと、それとは別に画像から生成した埋込みのクラスタが見えてしまい「猫」というテキストと猫の画像が埋め込み空間上で近くに位置していないように見えてしまうことがあります。
X に投稿されていた例 ー https://x.com/yuji_amanogawa/status/1876186079629644032
UMAP による可視化(2)

こちらは、先程と同じ総務省が公開している FAQ の「問い」と「回答」を連結して を UMAP で可視化したものです。赤は「壁」が入っているQAで、青はその他を表しています。
103万円、150万円、106万円、130万円の壁に関するQA(赤)が集まっていることが見て取れます。
ベクトル検索の仕組み
埋め込み空間(ベクトル空間)の中で似たものを見つけるには、埋め込み間の距離を計算して、最も近くに位置する埋め込みを見つければよいこととなります。

そこで、ベクトルデータベースのベクトル検索は、上図に示されているように、クエリ(検索したい内容)の埋め込みと登録されているデータの埋め込みとの距離を計算することで行われます。主な距離の指標として以下があります。
- L2距離(ユークリッド距離) ー 空間上の直線的な距離(ユークリッド距離とも呼ばれる。3次元空間のおける直観的な距離に相当)
- コサイン距離 ー ベクトル間の角度に基づく距離(1 – コサイン類似度)
- 内積(ドットプロダクト) ー ベクトルとベクトルの内積。角度に加えて、ベクトルの大きさを反映した指標。大きさを1に正規化するとコサイン類似度と同等
近似最近傍探索(ANN ー Approximate Nearest Neighbor)とは
クエリの埋め込みと最も類似した検索対象の埋め込みを k 個見つけ出す際、クエリ文の埋め込みと、データベース内のすべての検索対象文の埋め込みとの距離を計算し、距離が近い順に k 個の埋め込みを選び出す k-最近傍(kNN ー k-Nearest Neighbors)では膨大な距離計算が必要となります。これは厳密解を求めることができますが計算コストが非常に高く、実用的ではありません。そこで、近似最近傍探索(ANN)という手法を使用します。
ANNは、完全な精度を少し犠牲にする代わりに、劇的に検索速度を向上させます。
ANNは、一般に以下のような特徴を持っています。
-
インデックス構築
- 検索前に埋め込みデータに対して特殊なインデックス構造を構築します。これにより、検索時の探索空間を大幅に削減できます
-
近似性
- 完全な探索と比べて、わずかな精度の低下は許容する代わりに、数桁のオーダーで検索速度を向上させます
-
メモリ効率
- インデックス構造により、メモリ使用量と検索速度のトレードオフを調整できます
代表的なアルゴリズムには、HNSW(Hierarchical Navigable Small World) があります。オープンソースで人気の Chromadb のインデックスは HNSW アルゴリズムを採用しています。また、Oracle Database 23ai のAI Vector Search は複数のインデックス・タイプをサポートしていますがインメモリ近傍グラフ・ベクトル索引を作成することによりHNSWアルゴリズムを利用可能となりなす。
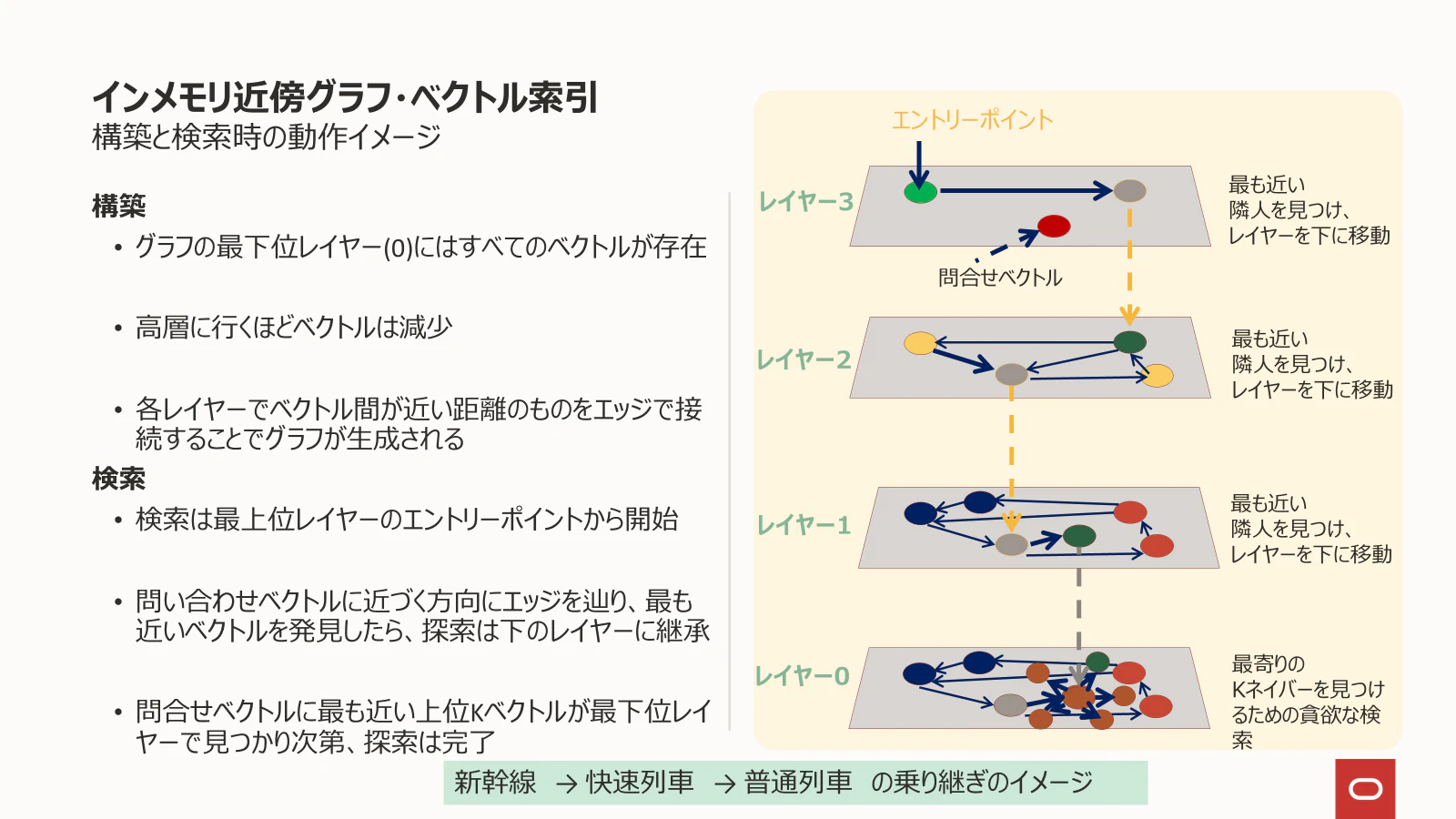
Oracle AI Vector Search 技術詳細 p.13より借用
HNSWは多層のグラフ構造を構築し、上位層から徐々に下位層へと探索範囲を絞り込むことで、効率的に類似する埋め込みを見つけ出すアルゴリズムです。
このHNSWアルゴリズムは、以下のようなちょっと変わった鉄道の旅に例えることができます。
福岡にいる人が鉄道に乗って移動しながら港区のオラクル青山センターに近い駅を近い順に3つ探しているとします。
ただし、探索にあたっては
- 新幹線に乗っているときは、各新幹線駅とオラクル青山センターの距離だけを知ることができる
- 在来線に乗っているときは、各在来線駅とオラクル青山センターの距離だけを知ることができる
- 地下鉄に乗っているときは、各地下鉄駅とオラクル青山センターの距離だけを知ることができる
という制約条件があるとします。
さて、最初に福岡で新幹線に乗車します
- 乗車したら新幹線の下車駅を考えます。使える情報は、各新幹線駅とオラクル青山センターの距離だけです。オラクル青山センターに近い新幹線の駅は、近い順に、例えば、東京駅、品川駅、新横浜駅、大宮駅となりそうです(東海道新幹線、東北新幹線の違いはこの際無視します)
- そこで、目的地に最も近い東京駅で新幹線を下車します
- 東京駅では山手線(在来線)に乗車します
- 次に山手線下車駅を考えます。使える情報は、各山手線駅とオラクル青山センターの距離だけです。オラクル青山センターに近い山手線の駅は、近い順に、例えば、新橋駅、有楽町駅、浜松町駅となるかもしれません(埼玉県民の感なのではずれても気にしないでください)
- そこで、目的地に最も近い新橋駅で下車します
- 新橋駅では銀座線(地下鉄)に乗車します
- 次に銀座線下車駅を考えます。使える情報は、各銀座線駅とオラクル青山センターの距離だけです。オラクル青山センターに近い銀座線の駅は、近い順に、例えば、外苑前、青山一丁目、表参道となります
以上の探索で、この福岡を出発した人は、オラクル青山センターに近い上位3駅は外苑前駅、青山一丁目駅、表参道駅であることを見つけました。HNSWによるベクトル検索であれば、オラクル青山センターはクエリーの埋め込み、外苑前駅は、クエリーに最も似ているドキュメントの埋め込みを表しています。
HNSWのパラメータ
外苑前周辺の地図を見ると直線距離でオラクル青山センターに近い駅として、千代田線乃木坂駅、大江戸線国立競技場駅、総武線信濃町駅もあることがわかります。上の例の探索では銀座線のみを探索しているためこれらの駅を見逃しています。もし、上位5駅を探していたとしたらこれらの候補駅を見逃してオラクル青山センターから遠い銀座線の駅をリストしてしまい正しい上位5駅を見つけることはできなかったはずです。実際の HNSW ではこのような状況を緩和するために探索する範囲を広く取るように実装されています。この広さを指定するパラメータは、exploration factor(探索係数)、もしくは単にefと呼ばれるもので、Oracle Database 23ai AI Vector Search であれば、EFSEARCH 、Chromadb であれば、search_ef パラメータです。
次回、第3章では、この探索係数が不適切な場合にHNSWが面白い(困った)振舞いを見せる例をご紹介します。
パラメータ調整をデータベースに任せる
HNSWには、この検索時の探索係数以外にも性能と精度のトレードオフを調整するいくつかのパラメータがあり、大規模なシステムではこれらのパラメータの調整が重要となります(ご参考 ー Hierarchical Navigable Small World索引の理解)。しかし、これらのパラメータは直観的に分かりやすいものではなく調整が難しいことがあります。Oracle Database 23ai AI Vector Search では、インデックス作成時や検索時にこれらのパラメータを直接指定する代わりに目標となる精度を指定して、パラメータの調整は Oracle Database に任せることができます。
HNSWなどの近似近傍検索が厳密解のうちどの程度をカバーしているかという search recall@k というメトリックがあります。ベクトルデータベースの検索精度といった場合にはこれを指しています。
RAG とベクトル検索の精度
(RAG の解説をする前ですがこの節には RAG に関する基本的な知識を前提とした記述が含まれます。)
ベクトルデータベースの技術的な側面から見た場合の"精度"はこのカバー率ですが、RAG の実務では、LLM が回答生成に必要なデータをベクトルデータベースがどれだけ取って来れるかが重要となります。これは、Context Recall と呼ばれます。ベクトルデータベースそのものの検索精度とは異なることに注意が必要です。Context Recall は、主に以下の4つの要因で決まります。
- データベースに登録されてるデータの質
- 元のデータの質 ー そもそも回答できる情報が含まれているか
- チャンクの質 ー 例えば、FAQをチャンク分割する際に、FAQを格納したCSVファイルを単純にチャンク分割するだけだと、「質問文+回答の先頭部分」が含まれるチャンク、「回答の一部」だけが含まれるチャンク、「回答の一部と次の質問文」が含まれるチャンクなどができてしまいます。これを検索対象とした場合、「回答の一部」だけを含むチャンクを見つけることは困難であるケースもありますし、「回答の一部と次の質問」を含むチャンクは回答生成にあたってはノイズとなる可能性があります。各チャンクに「質問文と回答の一部」がセットで含まれるような前処理が必要です
- 埋め込みの質
- 埋め込みモデルが生成する埋め込み(ベクトル)がどの程度元のデータの意味を反映できているか
- チャンクサイズと取得件数
- 大きなチャンクを1つの埋め込みに押し込めば必然的に情報は薄まります。チャンクが小さすぎたり、取得件数が少なければ情報の取りこぼしが増えます
- チャンクサイズと取得件数を変えたときの Context Recall については後続の章で具体例をご紹介します
- お急ぎの場合はこちらのアーカイブ動画 の 52分17秒から1時間42秒あたりを見てみてください
- ベクトルデータベースの検索精度
- 近似近傍検索が厳密解のどの程度をカバーしているか
つまり、ベクトルデータベースの検索精度は、Context Recall の精度の要因のひとつに過ぎません。
また、最近の Toward Optimal Search and Retrieval for RAG という論文では、RAG においては、この search recall@k を 70% 程度まで落としても RAG の性能にはあまり影響しないことが報告されています。また、検索精度を下げることでむしろ検索速度とメモリ効率を向上できるメリットがあることが示唆されています。
実際のPoCプロジェクトなどにおいて成功するプロジェクトは「データの質」に重点を置いています。手元のデータをとりあえず放り込んで何が起こるか見てみるといったPoCは「現時点では様子見」という結論で終わってしまうようです。将来的には、AIエージェント技術、マルチモーダルなどを駆使したRAG のマネージドサービスがこのあたりもすべて解決してくれることを期待したいところですが、今日時点では、エンジニアの皆様が活躍する場面ですね。
検索の実行例
自然言語 で 自然言語 を検索

上図は実際の検索の様子を示しています。
- 検索クエリ(例 ー 「戦争を描いた映画」)が埋め込みモデルによってベクトル化される
- このベクトルと、データベースに格納された各チャンクの埋め込みベクトルとの距離が計算される
- 最も近い(ベクトル間の距離が近い ≒ 事物の類似度が高い)上位k件の結果が返される
この例では、生成AIアプリケーションのフレームワークである LangChain の similarity_search_with_score()メソッドを使用して、距離のスコアと共に上位3件の検索結果を取得しています。スコアが小さいほど、クエリに近い(より類似している)ことを示しています。
自然言語 で 画像を検索

「壮大な宇宙のスペクタクル」というテキストで画像を検索した例です。
画像 で 画像を検索

右上でアップロードした画像の埋め込みでベクトルデータベース内の画像の埋め込みを検索したものです。
このように、ベクトルデータベースは、テキストや画像などのデータの意味的な類似性に基づく検索を可能にし、RAGシステムにおいて重要な役割を果たしています。
なお、この記事では、主にテキストの埋め込みを扱いました。上の画像検索のようなマルチモーダル(自然言語と画像)な検索や埋め込みについては、以下の記事とウェビナーのアーカイブ動画で解説しています。
まとめ
本章では、RAGを支える重要な技術要素であるベクトル検索の仕組みについて解説しました。特に以下の点について詳しく見てきました。
- ベクトルデータベースは、テキストの意味を考慮した検索を可能にし、大規模データに対する高速な検索を実現する技術です
- 埋め込み(エンベディング)には、固定的なStatic Embeddingと、文脈を考慮できるTransformerベースの2つのアプローチがあり、それぞれに特徴があります
- プーリング処理により、トークン単位の埋め込みから文書全体を表現する単一の埋め込みベクトルを生成し、効率的な検索を可能にしています
- 近似最近傍探索(ANN)を用いることで、若干の精度低下と引き換えに検索速度を大幅に向上させることができます
- 最近の研究では、RAGシステムにおいて検索精度(search recall@k)を70%程度まで下げても性能にあまり影響がないことが報告されており、検索速度とのバランスを取ることが可能です
このような技術的基盤の理解は、RAGシステムを実装・運用する上で重要となります。次章では、これらの知識を活かしながら、実際のベクトルデータベースであるChromaDBを使用した具体的な実装方法について解説していきます。
続きのご案内
【生成AIをより賢く ー エンジニアのためのRAG入門(第2章)「RAGを支える技術 ー ベクトル検索の仕組み」(埋め込みモデルからベクトルデータベースまで)】を最後までお読みいただきありがとうございます。
後日公開予定の後続の章では第3章で「ベクトル検索」(ChromaDB編)、そして、第4章以降では、「基本的なRAGの仕組みと実装方法」、「RAGの技術的課題と実践的な解決策」、「RAGの最新動向と今後の展望」について扱う予定です。
関連記事のご案内
