このブログは?
RAGを使った質問応答システムの継続的な回答品質の維持・改善にはユーザーの質問文を蓄積して分析することも重要です。そこで、その最初の一歩として蓄積した質問文を可視化してみようというのがこのブログの趣旨です。
ドキュメント(のチャンク)に対しても同じ手法が使えますので、ユーザーの質問をRAGに登録したドキュメントが網羅できているのかといった分析には役立つかもしれません。時間経過に伴う質問文ドリフトを定量的に評価していくためにはクラスタリングが有効ですが今回はそこまでは踏み込んでいませんので 0.1 歩 というタイトルにしています。
RAGそのものは、ウェビナー"生成AIをより賢く ー エンジニアのためのRAG入門" で取り上げています。
最初に、クラウドサービス(OCI Generative AI Searvice)のプレイグラウンドを使って可視化してみます。次に UMAP と WizMap を使ってより高度な可視化を試してみます。
クラウドサービスのプレイグランドで可視化してみよう
OCI Generative AI Searvie(生成AIサービス)には、質問文やドキュメントのベクトルデータを生成する埋め込みモデルのプレイグラウンドがあり、生成したベクトルをその場で可視化することもできます。
サンプルデータの準備
質問文のサンプルデータとして、「人事部門への典型的な質問」を20個、「経理部門への典型的な質問」を20個、LLMに生成してもらいます。ここでは、Claude 3.5 Sonnet を使用しました。
テキストデータはこちらで見ていただくことができます。
1から20は、人事部門への質問、21 から 40 は、経理部門への質問です。
OCI Generative AI Searvice (生成AIサービス)へアクセス
- OCI のコンソールの左上のハンバーガーメニューから アナリティクスとAI >> 生成AI と辿ります
- 左側のメニューの"プレイグラウンド"にある"埋込み"をクリックします
埋込みのプレイグラウンドでベクトル化と可視化
- モデルは、
cohere.embed-multilingual-v3.0を選択します - 文の入力の"ファイルのアップロード"から先程用意した質問文のテキストファイルをアップロードします

- "実行"をクリックするとこのようなグラフが表示されます。青丸の中の数字が上のスクリーンショットの質問文の番号となります

この番号をよく見てみると、1から20の人事部門への質問は右半分に、21から40の経理部門への質問は左半分に偏って分布していることがわかります(6と35は例外のようです)。

確かに 意味的な何か (DNNが見出した特徴)がベクトルに反映されているようです。 - "埋込みをJSONにエクスポート"をクリックして、生成したベクトルデータをファイルに保存しておきます
WizMap を使って可視化してみよう
OCI Generative AI Searvice のプレイグランドでは1度にベクトル化&可視化できるデータは96件までです。RAGのPoC や実運用では遥かに大量の質問文やドキュメントを可視化する必要があります。ここでは、大規模なベクトルデータの可視化とインタラクティブな探索が可能な WizMap を使用します。
WizMap を使った可視化のお試し
国・地方共通相談チャットボット Govbot(ガボット)に搭載されている各分野のFAQデータ(全分野)の「問い」を可視化してみます。
最初にベクトルデータを次元圧縮して散布図として可視化します。テキストデータをベクトル化する埋め込みモデルには Cohere Embed Multilingual V3 を使います。このモデルは1024次元のベクトルを生成しますので、UMAP(Uniform Manifold Approximation and Projection) で、1024次元から2次元への次元圧縮を行い散布図を作成します。次に、WizMap を使って散布図をインタラクティブに探索できるようにします。
WizMap のインストール
リポジトリのクローン
git clone git@github.com:poloclub/wizmap.git
cd wizmap
JavaScript 依存パッケージのインストール
npm install
WizMap を起動
npm run dev
localhost:3000 で Web サーバが起動します。このWeb サーバは、2つの役割があります。
- これから紹介するコードで生成する 2つの json ファイルに WizMap が http でアクセスできるようにホストする Web サーバ
- WizMap 自体をホストする Web サーバ(ブラウザからも http://localhost:3000 でアクセスできる)
以降の作業は別のターミナルで実行します。
本ブログのサンプルコードのクローン
テキストデータのベクトル化と可視化のサンプルコードを GitHub で公開しています。ベクトル化は Python スクリプト、可視化は Jupyter ノートブック形式です。
git clone https://github.com/kutsushitaneko/wizmap-mic-faq.git
cd wizmap-mic-faq
FAQ 問いのベクトル化
FAQ データ
全分野 のエクセルファイルから「大分類」だけを抜き出したテキストファイルと「問い」の列だけを抜き出したテキストファイルを用意します。作成したテキストファイルは、GitHubのレポジトリに置いてあります。
- 「大分類」 ー 大分類.txt
- 「問い」 ー 総務省FAQ.txt
「問い」のベクトル化
この記事では、OCI Generative AI Searvice の埋め込みモデル Cohere Embed V3 を使って次のコードでベクトル化を行います。
Python 依存パッケージのインストール
pip install oci python-dotenv
ベクトル化コード
本題から外れてしまいますので詳細説明は省きますが、96件づつのバッチにしてベクトル化していることだけ記しておきます(1件ずつベクトル化して降り積もった遅延で悩んでいる方へ)。
import oci
import os
import json
import time
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# OCI設定
CONFIG_PROFILE = "DEFAULT"
config = oci.config.from_file('~/.oci/config', CONFIG_PROFILE)
compartment_id = os.getenv("OCI_COMPARTMENT_ID")
model_id = "cohere.embed-multilingual-v3.0"
generative_ai_inference_client = oci.generative_ai_inference.GenerativeAiInferenceClient(config=config, retry_strategy=oci.retry.NoneRetryStrategy(), timeout=(10,240))
def generate_embeddings(batch):
embed_text_detail = oci.generative_ai_inference.models.EmbedTextDetails()
embed_text_detail.serving_mode = oci.generative_ai_inference.models.OnDemandServingMode(model_id=model_id)
embed_text_detail.inputs = batch
embed_text_detail.truncate = "NONE"
embed_text_detail.compartment_id = compartment_id
embed_text_detail.is_echo = False
embed_text_detail.input_type = "SEARCH_DOCUMENT"
embed_text_response = generative_ai_inference_client.embed_text(embed_text_detail)
return embed_text_response.data.embeddings
def process(batch_size=96):
total_processed = 0
total_time = 0
batch_count = 0
all_texts = []
all_embeddings = []
# ファイルを読み込む
with open('総務省FAQ.txt', 'r', encoding='utf-8') as f:
texts = f.readlines()
# バッチ処理
for i in range(0, len(texts), batch_size):
batch_start_time = time.time()
batch = texts[i:i + batch_size]
# 空行を除去し、テキストをクリーニング
batch = [text.strip() for text in batch if text.strip()]
# バッチサイズが0の場合はスキップ
if len(batch) == 0:
continue
# embeddingを生成
embeddings = generate_embeddings(batch)
# 結果を保存用リストに追加
all_texts.extend(batch)
all_embeddings.extend(embeddings)
batch_end_time = time.time()
batch_time = batch_end_time - batch_start_time
batch_count += 1
total_processed += len(batch)
total_time += batch_time
print(f"バッチ {batch_count}: {len(batch)} 件の embedding を生成しました。処理時間: {batch_time:.2f} 秒")
# 結果をJSONファイルに保存
result = {
"texts": all_texts,
"embeddings": all_embeddings
}
with open('総務省FAQ埋め込み.json', 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)
return total_processed, total_time
if __name__ == "__main__":
try:
start_time = time.time()
total_processed, processing_time = process()
end_time = time.time()
total_time = end_time - start_time
print(f"\n処理が完了しました。")
print(f"合計処理件数: {total_processed} 件")
print(f"embedding 生成時間: {processing_time:.2f} 秒")
print(f"総処理時間: {total_time:.2f} 秒")
except Exception as e:
print(f"予期せぬエラーが発生しました: {e}")
実行するためには、OCI の config ファイルを適切に設定しておく必要があります。また、コンパートメントIDを .envファイルに定義しておきます。
OCI_COMPARTMENT_ID=適切なコンパートメントID
実行例
$ python embed.py
バッチ 1: 96 件の embedding を生成しました。処理時間: 1.96 秒
バッチ 2: 96 件の embedding を生成しました。処理時間: 0.58 秒
バッチ 3: 96 件の embedding を生成しました。処理時間: 0.45 秒
バッチ 4: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 5: 96 件の embedding を生成しました。処理時間: 0.46 秒
バッチ 6: 96 件の embedding を生成しました。処理時間: 0.48 秒
バッチ 7: 96 件の embedding を生成しました。処理時間: 0.45 秒
バッチ 8: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 9: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 10: 96 件の embedding を生成しました。処理時間: 0.49 秒
バッチ 11: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 12: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 13: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 14: 96 件の embedding を生成しました。処理時間: 0.44 秒
バッチ 15: 96 件の embedding を生成しました。処理時間: 0.46 秒
バッチ 16: 53 件の embedding を生成しました。処理時間: 0.32 秒
処理が完了しました。
合計処理件数: 1493 件
embedding 生成時間: 8.74 秒
総処理時間: 10.28 秒
ベクトルデータの可視化
Python 依存パッケージのインストール
pip install --upgrade "numpy<2.0" wizmap umap-learn matplotlib ipywidgets
WizMap は、numpy 2.0 以上には未対応ですので "numpy<2.0" を忘れずに!
WizMap を表示するコード例
ライブラリのインポート
from json import load, dump
from matplotlib import pyplot as plt
import matplotlib as mpl
from umap import UMAP
import numpy as np
import wizmap
# 日本語フォントの設定
mpl.rcParams['font.family'] = 'MS Gothic'
# 乱数のシードを設定
SEED = 2024117
# 画像の解像度を設定
plt.rcParams['figure.dpi'] = 300
ファイルの読み込み
# JSONファイルからデータを読み込む
with open('総務省FAQ埋め込み.json', encoding='utf-8') as f:
data = load(f)
# textsとembeddingsを抽出
text = data['texts'] # テキストデータの配列を取得
embedding = np.array(data['embeddings']) # 埋め込みデータを numpy 配列に変換
print(f'読み込んだテキスト数: {len(text)}')
print(f'埋め込みの形状: {embedding.shape}')
次元削減(UMAP)と散布図の表示
# UMAPのパラメータを設定
reducer = UMAP(metric='cosine', n_neighbors=15, min_dist=0.1, random_state=SEED, transform_seed=SEED, init='spectral')
# 次元削減
embeddings_2d = reducer.fit_transform(embedding)
# 大分類ファイルを読み込む
with open('大分類.txt', 'r', encoding='utf-8') as f:
categories = [line.strip() for line in f.readlines()]
# ユニークな大分類を取得し、色をマッピング
unique_categories = list(set(categories))
colors = plt.cm.tab20(np.linspace(0, 1, len(unique_categories)))
color_map = dict(zip(unique_categories, colors))
# 各データポイントの色を設定
point_colors = [color_map[cat] for cat in categories]
# プロット
plt.figure(figsize=(16, 12))
plt.title(f'UMAP Projected Embeddings of {len(text)} MIC FAQs by Category')
scatter = plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1],
s=10.0, alpha=0.5, c=point_colors)
# 凡例を追加
legend_elements = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=color_map[cat],
label=cat, markersize=10)
for cat in unique_categories]
plt.legend(handles=legend_elements, loc='center left', bbox_to_anchor=(1, 0.5))
plt.tight_layout()
plt.show()
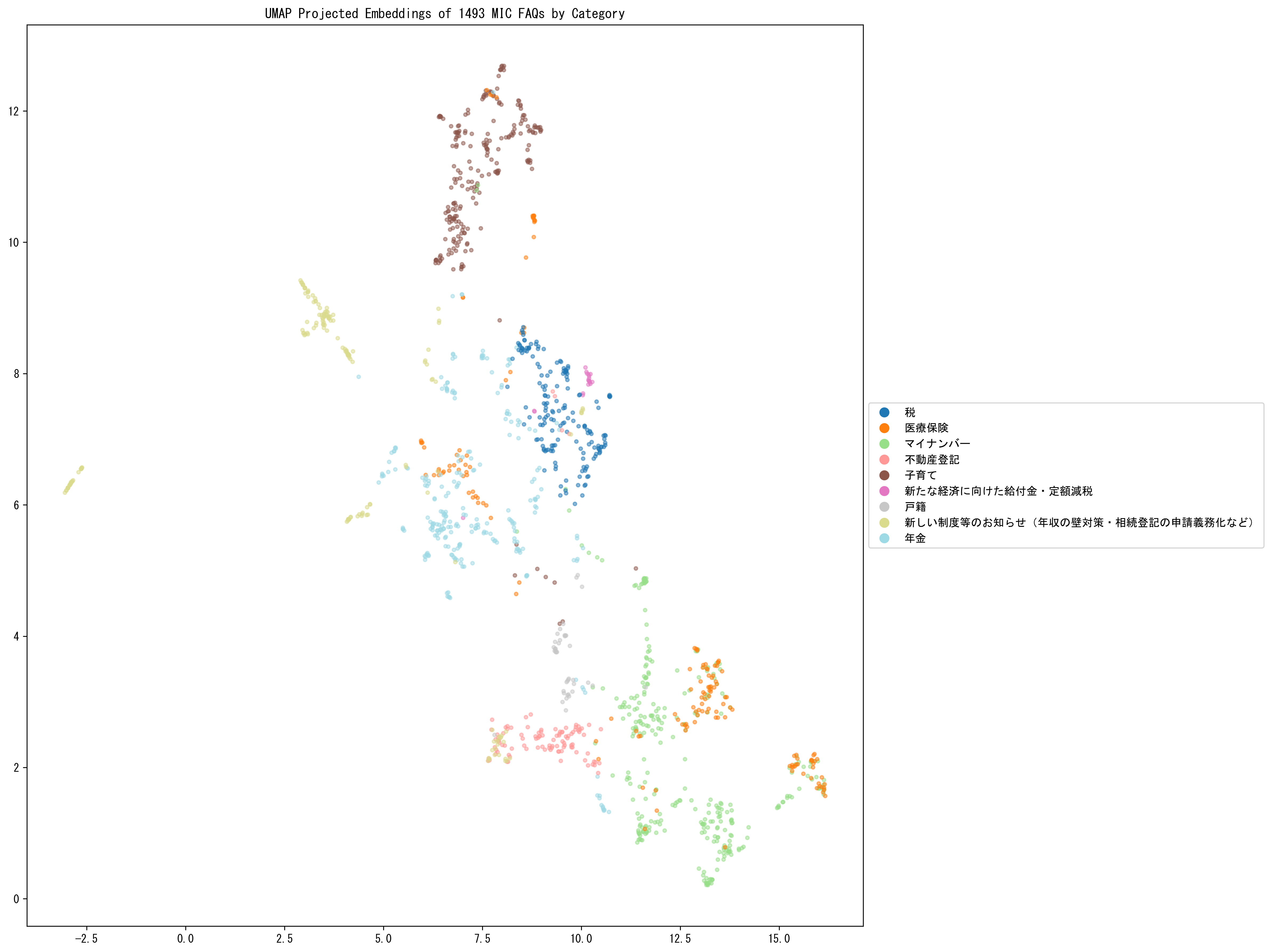
圧縮された二次元空間の中でも「問い」が「大分類」毎にクラスターを形成していることがわかります。
これだけでも有用ですが、個々のデータポイントがどの「問い」に対応しているのかを見ることができたり散布図のスケールを変えてより詳細な構造を見ることができると便利です。そのようなことができるのが WizMap です。
WizMap用データの生成
# データの座標を取得
xs = embeddings_2d[:, 0].astype(float).tolist()
ys = embeddings_2d[:, 1].astype(float).tolist()
texts = text
# データのリストを生成
data_list = wizmap.generate_data_list(xs, ys, texts)
# グリッドの辞書を生成
grid_dict = wizmap.generate_grid_dict(xs, ys, texts, '総務省FAQ', random_seed=SEED)
# JSONファイル(data.ndjsonとgrid.json)を保存
with open('data.ndjson', 'w', encoding='utf-8') as f:
for item in data_list:
dump(item, f, ensure_ascii=False)
f.write('\n')
with open('grid.json', 'w', encoding='utf-8') as f:
dump(grid_dict, f, ensure_ascii=False, indent=2)
WizMap を表示
# WizMap のdata.ndjsonのURLとgrid.jsonのURLを設定
data_url = 'http://localhost:3000/example/data.ndjson'
grid_url = 'http://localhost:3000/example/grid.json'
# wizmap を表示
wizmap.visualize(data_url, grid_url, height=700)

WizMap の操作
インタラクティブに探索するツールですので触ってみるのが一番です。
公式がデモサイトを公開しています。
このデモサイトを開いて、左下のフォルダーアイコンをクリックして、
Data JSON URL に
https://raw.githubusercontent.com/kutsushitaneko/wizmap-mic-faq/refs/heads/main/example-data.ndjson
Grid JSON URL に
https://raw.githubusercontent.com/kutsushitaneko/wizmap-mic-faq/refs/heads/main/example-grid.json
を入力して"Create"をクリックしてください。
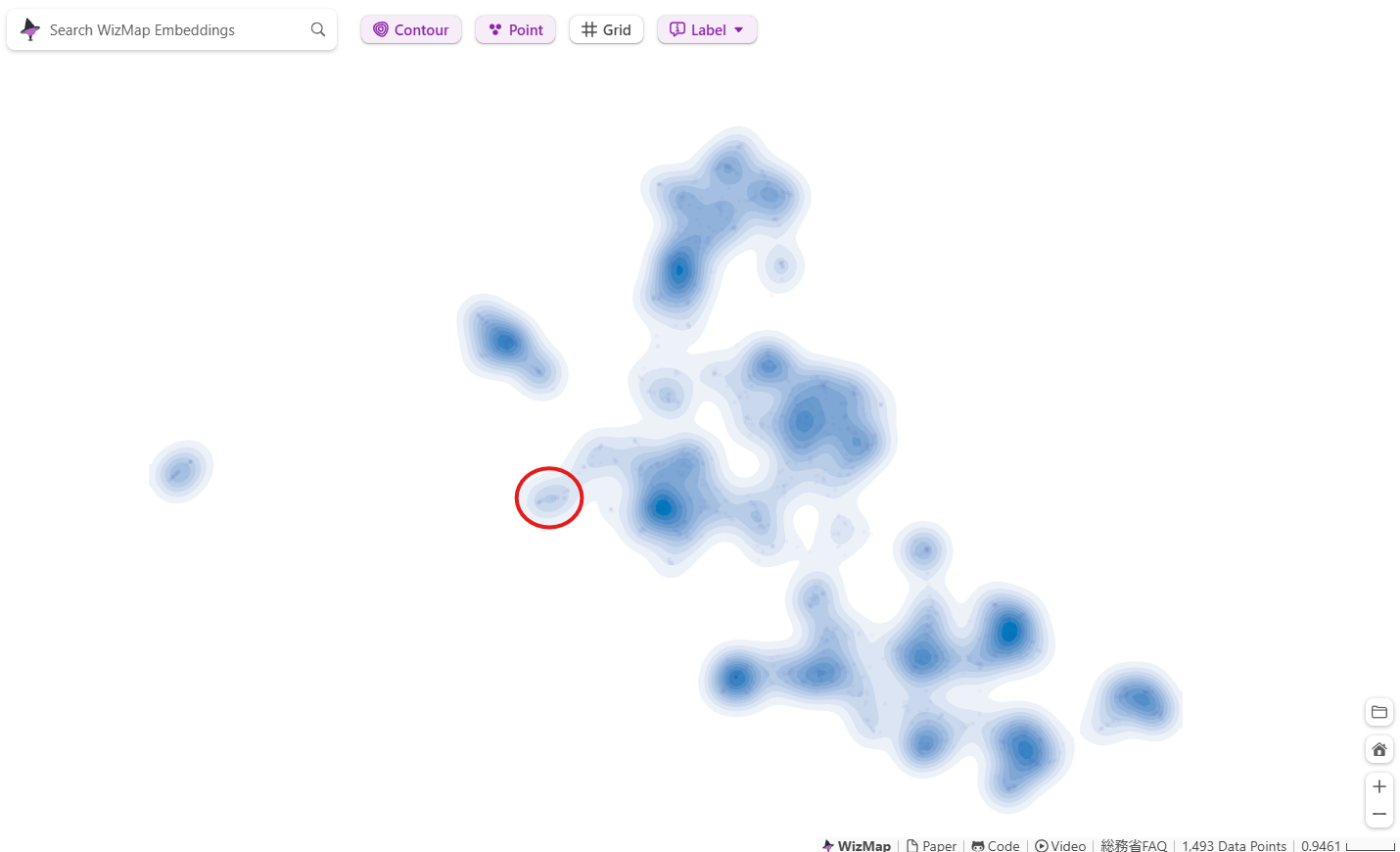
下記のように FQA の問いが可視化されます。

- ラベル(「問い」のテキスト)が多すぎて邪魔な場合には、画面上の"Label"で調整することができます
- "Contour"で等高線のようなものの表示をOn/OFFすることができます
- マウスのスクロールボタンでズームアップ/ズームアウト可能です
- "Search WizMap Embeddings"に「問い」を入力するとその「問い」のデータポイントへ移動できるようですが 日本語ではうまくいかないようです
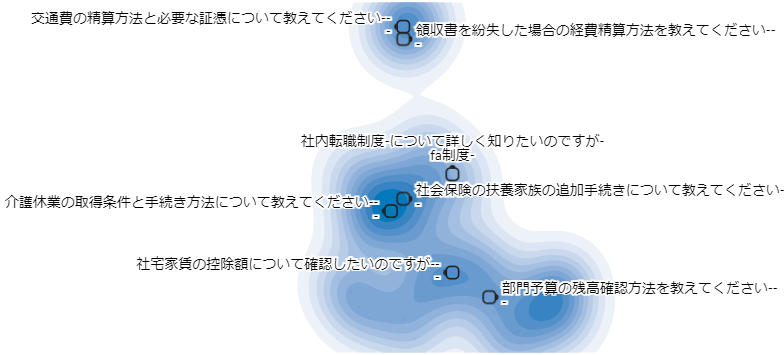
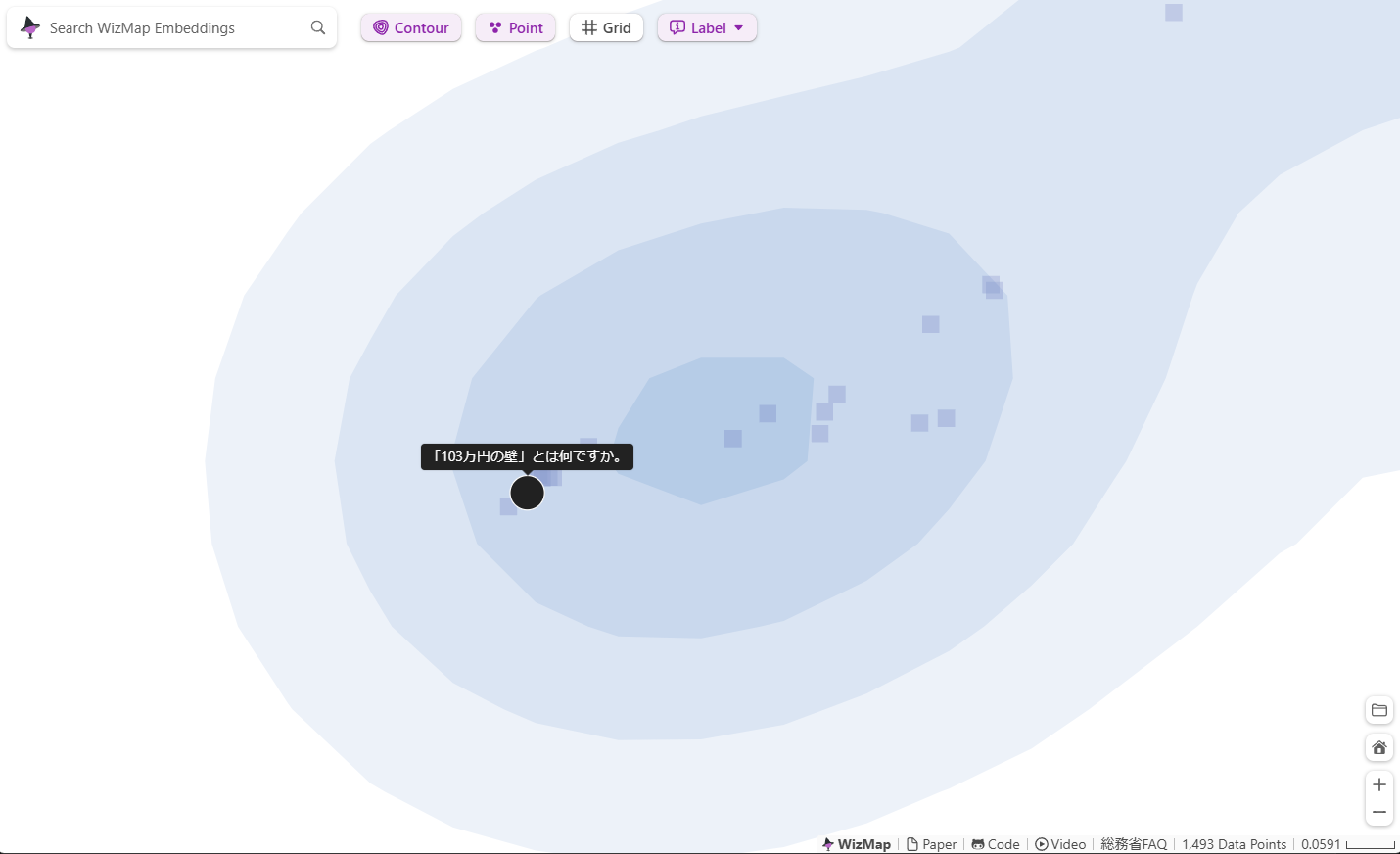
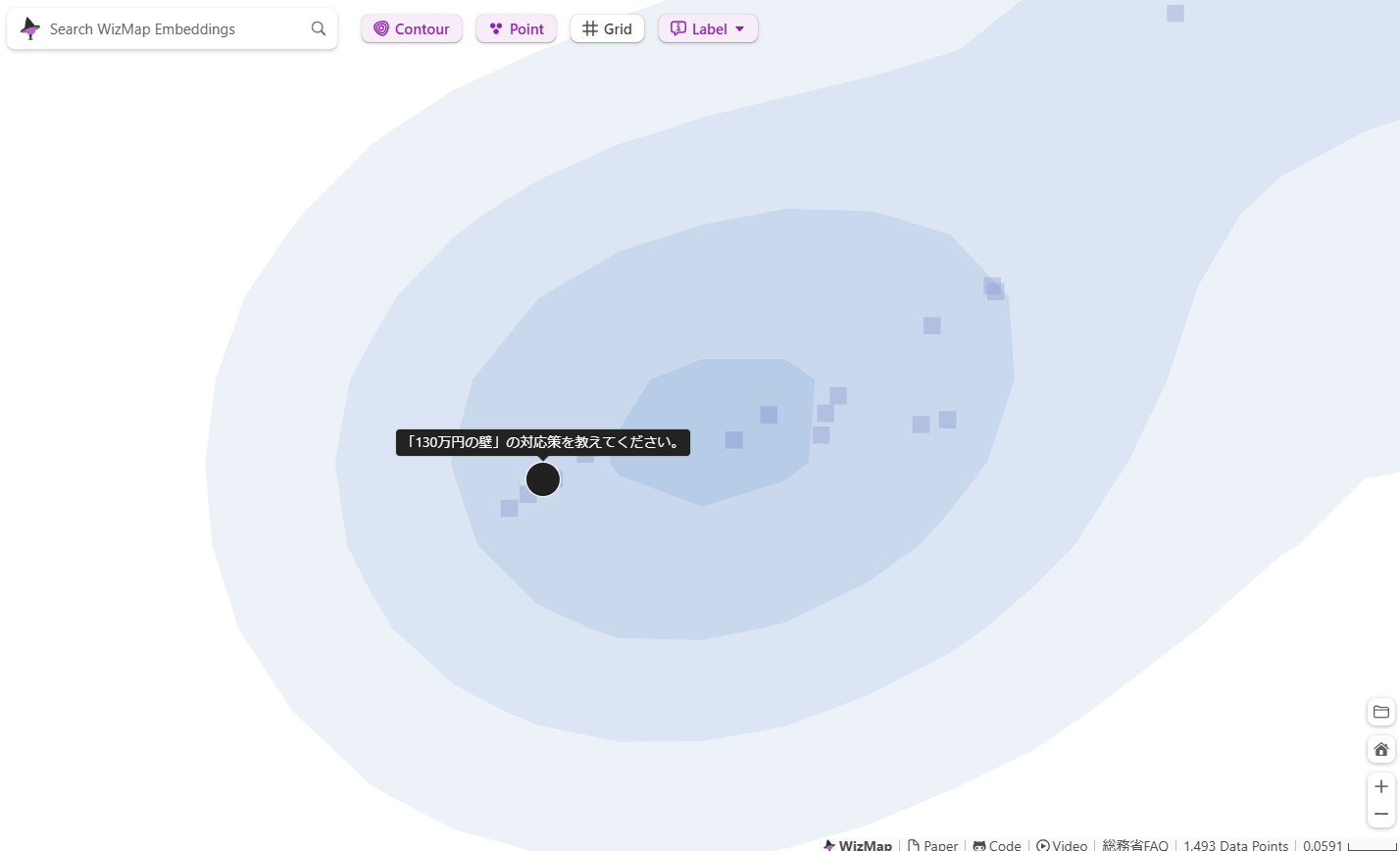
このあたり↓にはこのブログ執筆時点で国会で議論されている「103万円の壁」や「130万円の壁」に関する「問い」が集まっています。
上のスクリーンショットの赤丸で囲んだ領域をズームアップしてみます。

えっと、あとがきです
ちなみにこちら↓をクリックするとこのブログで題材にした総務省のFAQ(国・地方共通相談チャットボット Govbot(ガボット)に搭載されている各分野のFAQデータ(全分野))の「問い」を探索できます(先に言いなさい^^;)。
103万円の壁のあたりを探索(散策?)していると「106万円の壁」、「130万円の壁」、「150万円の壁」とか「月収が88,000円を超えてしまった」とかが周辺に見つかります。ちょっと違った使い方がありそうですね。情報検索の UI として考えてみても面白いかもしれません。