はじめに
ChatGPTなどの生成AIを企業で活用するには、独自のデータを組み合わせるRAG(検索拡張生成)が有益です。
しかし、RAGの中核を担う「埋め込み」の仕組みは意外と知られていません。
この記事では、埋め込みの基礎からベクトル検索やテキスト/画像の分類まで、実例を交えて解説します。
埋め込みの理解を深めることで、より効果的なRAGシステムの構築が可能になります。
初学者の方にも、生成AIを実用レベルで活用したいエンジニアの方にもお役に立てていただける内容を目指しています。
この記事の内容はウェビナー【Oracle AI JAM Session #23 生成AIを活かすには埋め込みの理解から!RAGの心臓=埋め込みの基礎から応用まで!】(2025年3月26日)にてご紹介させていただいたものです。
コードは、GitHub Repo にて公開しています。
この記事では、RAG とは何か? については簡単なご紹介に留めています。RAG の基本の詳細ついては 【Oracle AI JAM Session #20 生成AIをより賢く ー エンジニアのためのRAG入門】 (2024年12月18日)でご紹介していますので、下記のアーカイブやセッション資料、ブログにもぜひお立ち寄りください。
| アーカイブ | セッション資料 |
 |
それでは、「生成AIを活かすには埋め込みの理解から!RAGの心臓=埋め込みの基礎から応用まで!」はじまります!
RAG とは何か?
RAGの目的と利点

-
ハルシネーション(幻覚)の低減
- 外部データベースからの正確な情報を参照することで
- 誤った情報の生成を抑制(ゼロにはできないものの大幅に削減)
-
社内固有の知識への対応
- データベースに登録された社内文書や規定を検索
- 組織特有の情報に基づいた正確な回答が可能
-
最新情報への対応
- データベースを更新することで、常に最新の情報に基づいた回答が可能
- LLMの学習時点以降の新しい情報にも対応可能
RAGは、LLMの基本的な能力を活かしながら、その限界を補完する効果的な手法として、特に企業での実用化において重要な役割を果たしています。最新のガイドラインや規定に基づいた正確な情報提供が必要なビジネス環境において、RAGの活用は不可欠となっています。
RAGの基本アーキテクチャ
RAGのプロセスは、以下の3つの主要なステップで構成されています。

- データの準備と埋め込み処理
- 文書データベースから情報を取得
- テキストを適切な大きさのチャンク(断片)に分割
- 埋め込みモデルを使用してベクトル化
- ベクトルデータベースにインデックスを作成
- ベクトル検索プロセス("RAG" の "R"(Retrieval))
- ユーザーの質問をベクトル化
- ベクトルデータベースで類似度検索を実行
- 最も関連性の高い文書を抽出
- LLMによる回答生成("RAG" の "G"(Generation))
- 検索結果とユーザーの質問を組み合わせてプロンプトを生成
- LLMが提供された情報に基づいて回答を生成
埋め込み技術の基礎
トークンとは何か
自然言語処理におけるテキストの生データの問題点
自然言語はそのままでは、単に文字列や数値の列に過ぎず、意味や文法的な情報が直接的には表現されていません。コンピュータが理解するためには、テキストを意味のある最小単位(通常は単語やそれに類する単位)に分割して機械学習モデルによって単語間の関係などを学習する必要があります。この最小単位(通常は単語やそれに類する単位)をトークンと呼びます。

単語単位のトークン化の限界
すべての単語に固有のトークンを割り当てれば、意味を持つ最小単位として扱えますが、語彙数が膨大になり、特に未知語(頻出しない単語)への対応が難しくなります。これにより、学習モデルのサイズや処理効率にも悪影響を及ぼします。
サブワードトークン化の工夫
そこで、頻出する単語には専用のトークンを割り当て、頻度の低い単語はさらに細かい単位(サブワード、さらには文字レベル、またはシングルバイトレベル)に分解して対応します。これにより、語彙数を抑えつつ、すべてのテキスト情報をカバーするバランスの取れた方法となります。
例えば、BPE(Byte Pair Encoding)やWordPieceといったアルゴリズムは、このようなサブワード単位での分割を実現し、未知語問題を軽減しています。
サブワードトークン化(BPEアルゴリズム)の例
出現頻度の高い単語は、そのままトークン化されます。
例)computer - コンピュータ

出現頻度の低い単語は、複数のサブワードに分割されて複数のトークンに変換されます。
例)exhilarating - 爽快な

トークナイザーとは
トークナイザー(Tokenizer)は、トークン化を実行するソフトウェアです。各言語モデル/埋め込みモデルには専用のトークナイザーがあり、モデルの利用時には、モデルの訓練時に使用されたのと同じトークン化手法を使う必要があります。例えば、GPT系モデルにはGPT専用のトークナイザーがあり、Cohere社のモデルにはCohere用のトークナイザーがあります。
トークナイザーは通常、以下の機能を提供します。
-
エンコード
- テキストをトークンID列に変換
-
デコード
- トークンID列をテキストに戻す
-
トークン数のカウント
- テキストが何トークンになるかを計算
トークナイザーを使ってトークン化、トークン数のカウントなどを行うには、HuggingFaceのTokenizersライブラリやOpenAIのticktoken ライブラリなどが広く使われています。ticktoken は、サブワードの一種である BPEアルゴリズム の OpenAI による実装です。
Open AI tiktoken ライブラリを使ったトークン化の例
大規模言語モデルや埋め込みモデルはモデル毎に入力できるテキストの最大トークン長(コンテキスト長) が決まっています。この制限長を超えると、テキストの後ろが切り捨てられたり、APIリクエストがエラーとなります。そのため、あらかじめテキストがどの程度のトークンに変換されるかを知っておくことが必要です。また、大規模言語モデルや埋め込みモデルをAPIサービスで使う場合、料金がトークン単位である場合もあります。
トークン化とトークン数カウントの例("こんにちは!")
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
tokens = encoding.encode("こんにちは!")
print(f"tokens: {tokens}")
print(f"len(tokens): {len(tokens)}")
-
tiktoken.get_encoding()は、トークナイザーのインスタンスを生成します。引数は、エンコーディングの名前です - OpenAI の第三世代埋め込みモデル(text-embedding-3-small、text-embedding-3-large)では、トークン化には、
cl100k_baseというエンコーディングが使われています(OpenAIドキュメント)ので、その名前を指定しています。 -
encoding.encode()は、トークナイザのencode()メソッドを呼び出して、引数で与えたテキストをトークン化しています。戻り値は、トークンのリストです
tokens: [90115, 6447]
len(tokens): 2
トークン分割の色分け

トークン化とトークン数カウントの例("こんにちは、世界!")
次は、"こんにちは、世界!"をトークン化してみます。
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
tokens = encoding.encode("こんにちは、世界!")
print(f"tokens: {tokens}")
print(f"len(tokens): {len(tokens)}")
tokens: [90115, 5486, 3574, 244, 98220, 6447]
len(tokens): 6
トークン分割の色分け

"世"にはcl100k_base エンコーディングでは、トークンが割り当てられていなかったため、トークナイザーは、"世"(0xe4b896)をバイトペア"0xe4b8"とシングルバイト"0x96"に分割してエンコードしています。
(余談)面白いトークン
OpenAI の 第三世代の埋め込みモデル(text-embedding-3-small、text-embedding-3-large)や GPT-3.5 Turbo から GPT-4 Turbo with Vision までの大規模言語モデルで使われている cl100k_base というエンコーディングには下記のようなユニークなトークンが含まれています。
Token ID: 63570, String: .translatesAutoresizingMaskIntoConstraints
Token ID: 73303, String: .DataGridViewColumnHeadersHeightSizeMode
Token ID: 61207, String: latesAutoresizingMaskIntoConstraints
Token ID: 73905, String: dequeueReusableCellWithIdentifier
Token ID: 59591, String: AutoresizingMaskIntoConstraints
Token ID: 44078, String: UnsupportedOperationException
Token ID: 99867, String: NavigationItemSelectedListener
Token ID: 95656, String: .DataGridViewContentAlignment
Token ID: 58928, String: :UIControlEventTouchUpInside
Token ID: 73229, String: .ColumnHeadersHeightSizeMode
文字列長が長いものから上位10件を抽出したもの。
最長の translatesAutoresizingMaskIntoConstraints は、Apple の UIKit フレームワークのプロパティ。
Cohere のトークン化の例
埋め込み(エンベディング)とは?
埋め込みは、テキストや画像などのデータをベクトル空間上のベクトルとして表現する方法です。

上図で示されているように、例えば白猫、三毛猫、秋田犬、車といった異なるオブジェクトは、それぞれの特徴を数値化することで多次元ベクトルとして表現されます。
このベクトル表現は、以下のような特徴を持っています。
- 各次元が特定の特徴(ふさふさ度、ひげ度など)を表現している
- 似た特徴を持つオブジェクトは、ベクトル空間上で近くに配置されている
- 特徴の違いが大きいオブジェクトは、空間上で離れて配置されている
画像や文書などの特徴を数値ベクトルの形で表現したものを特徴ベクトルと呼びます。特徴ベクトルの中でも、特に機械学習の表現学習で得られたものを埋め込み(エンベディング) と呼びます(厳密な用語の使い分けの定義があるわけではありません)。また、機械学習により埋め込みを生成する機械学習モデルを埋め込みモデルと呼びます。
この埋め込み(エンベディング)が織りなすベクトル空間を埋め込み空間と呼びます。似た事物は、似た特徴を持ち、この多次元の埋め込み空間(ベクトル空間)の中で近くに位置することとなります。
埋め込みモデルの仕組み
単語の埋め込み
埋め込みモデルには、大きく分けて2つのアプローチがあります。Static Embedding(静的埋め込み)と Transformer ベースの文脈考慮型埋め込みです
Static Embedding
単語の静的埋め込み(Static Embedding)は、ある単語が別の単語と一緒に使われやすい傾向(共起関係)を学習して、単語に埋め込み(ベクトル)を割り当てる手法です。この手法では、意味的に似ている単語は、埋め込み空間内で近い位置に配置されます。

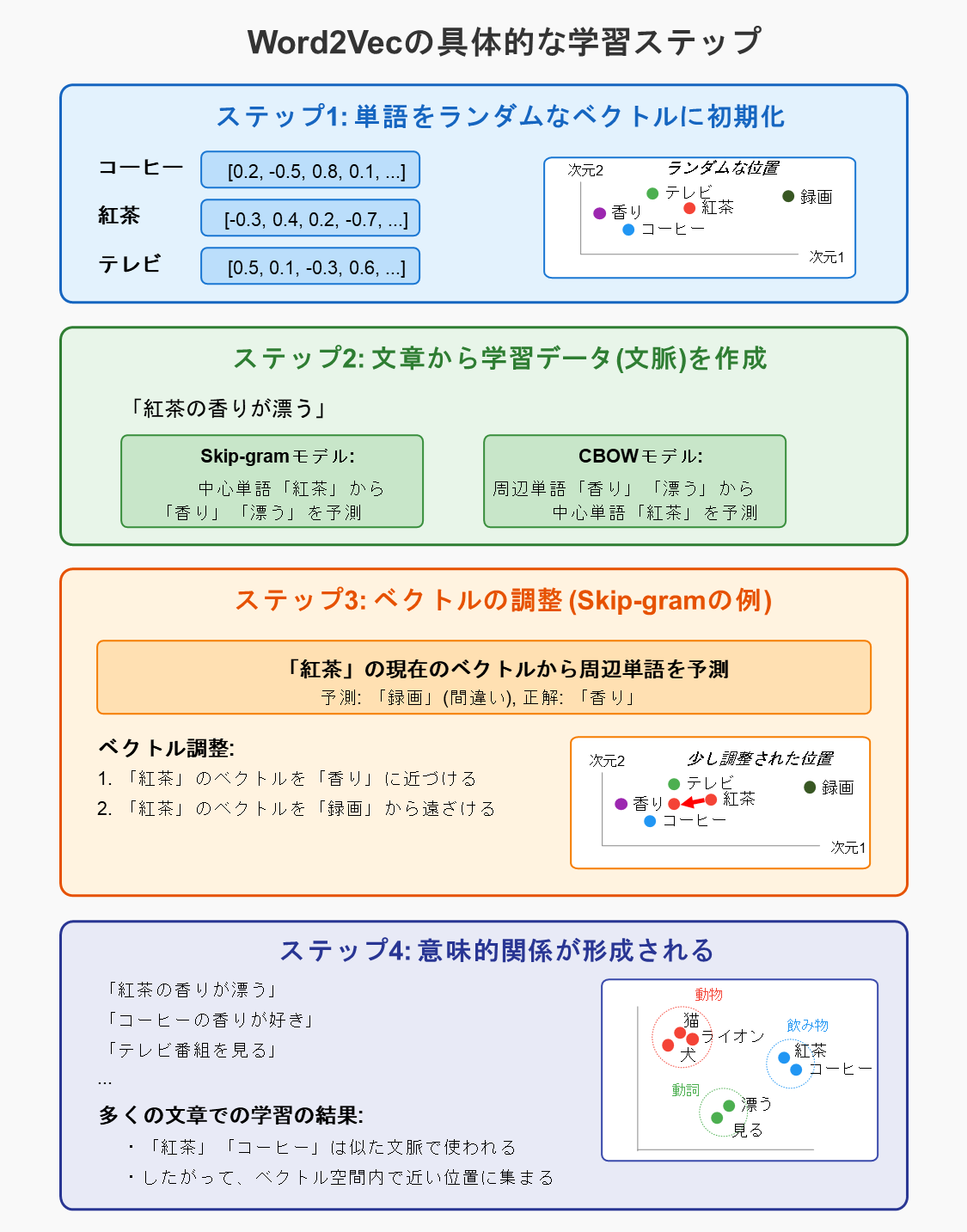
例えば、「コーヒー」「紅茶」「牛乳」「テレビ」という単語はそれぞれ以下のような単語と一緒に使われやすい傾向があります。
- 「コーヒー」という単語は「飲む」「カップ」「豆」「香り」などの単語と共に出現しやすい
- 「紅茶」という単語は「飲む」「カップ」「茶葉」「香り」などの単語と共に出現しやすい
- 「牛乳」という単語は「飲む」「カップ」「白い」「カルシウム」などの単語と共に出現しやすい
- 「テレビ」という単語は「見る」「録画」「チャンネル」「番組」などの単語と共に出現しやすい
「コーヒー」「紅茶」は、どちらも「飲む」「カップ」「香り」と同時に使われやすいため値が近い埋め込み(ベクトル)が割り当てられ埋め込み空間内で近い位置に配置されます。
「牛乳」は、「コーヒー」「紅茶」と「飲む」「カップ」の2つの単語が共通していますので、「コーヒー」「紅茶」の近くに配置されます。しかし、「牛乳」と「コーヒー」、「牛乳」と「紅茶」の距離は「コーヒー」と「紅茶」の距離よりは遠くなります。
「テレビ」は、「コーヒー」「紅茶」「牛乳」とは同時に使われやすい単語が異なるため、これらとは離れた位置に配置されます。
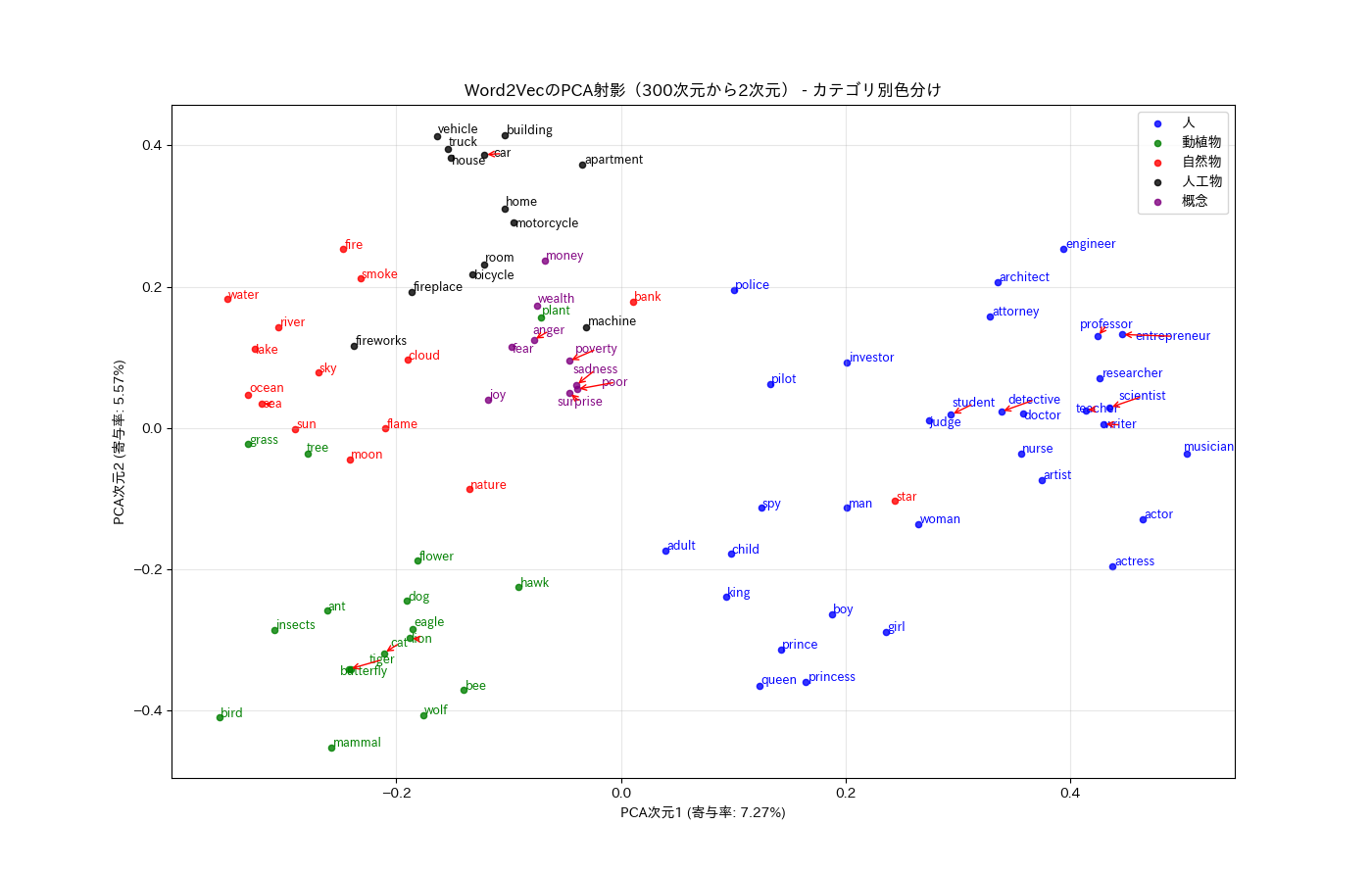
静的埋め込み(Static Embedding)による単語埋め込みのコード例(Word2Vec)
埋め込み生成と可視化のコードを表示/非表示
import gensim.downloader as api
from gensim.models import KeyedVectors
from sklearn.decomposition import PCA
from sklearn.preprocessing import normalize
import matplotlib.pyplot as plt
import japanize_matplotlib
from adjustText import adjust_text
import os
import warnings
warnings.filterwarnings('ignore')
# モデルのパス設定
ORIGINAL_MODEL_PATH = 'GoogleNews-vectors-negative300.bin'
LIGHT_MODEL_PATH = 'GoogleNews-vectors-negative300.kv'
# モデルのロード関数
def load_word2vec_model():
# 軽量フォーマットが存在する場合
if os.path.exists(LIGHT_MODEL_PATH):
print("軽量フォーマットのモデルを読み込んでいます...")
return KeyedVectors.load(LIGHT_MODEL_PATH)
# オリジナルのバイナリファイルが存在する場合
if os.path.exists(ORIGINAL_MODEL_PATH):
print("オリジナルのモデルを読み込み、軽量フォーマットに変換しています...")
model = KeyedVectors.load_word2vec_format(ORIGINAL_MODEL_PATH, binary=True)
model.save(LIGHT_MODEL_PATH)
return model
# どちらも存在しない場合、ダウンロードを試みる
print("モデルが見つかりません。word2vec-google-news-300をダウンロードします...")
try:
model = api.load('word2vec-google-news-300')
print("ダウンロードが完了しました。軽量フォーマットに変換して保存します...")
model.save(LIGHT_MODEL_PATH)
return model
except Exception as e:
raise Exception(f"モデルのダウンロードに失敗しました: {str(e)}")
# モデルのロード
model = load_word2vec_model()
# 単語ベクトルの次元数を表示
print(f"単語ベクトルの次元数: {model.vector_size}")
# カテゴリ分け
categories = {
'人': ['king', 'queen', 'prince', 'princess', 'man', 'woman', 'boy', 'girl', 'child', 'adult',
'engineer', 'architect', 'doctor', 'nurse', 'pilot', 'teacher', 'student', 'professor',
'researcher', 'scientist', 'artist', 'writer', 'musician', 'actor', 'actress',
'entrepreneur', 'investor', 'attorney', 'judge', 'police', 'detective', 'spy'],
'動植物': ['cat', 'lion', 'tiger', 'dog', 'wolf', 'mammal', 'hawk', 'eagle', 'bird',
'ant', 'bee', 'butterfly', 'insects', 'tree', 'plant', 'flower', 'grass'],
'自然物': ['nature', 'sky', 'cloud', 'sun', 'moon', 'star', 'water', 'river', 'sea', 'ocean',
'lake', 'fire', 'flame', 'smoke', 'bank'],
'人工物': ['car', 'truck', 'bicycle', 'motorcycle', 'vehicle', 'machine', 'house', 'building',
'apartment', 'home', 'room', 'fireplace', 'fireworks'],
'概念': ['joy', 'anger', 'sadness', 'fear', 'surprise', 'money', 'wealth', 'poverty', 'poor']
}
# 色の定義
category_colors = {
'人': 'blue',
'動植物': 'green',
'自然物': 'red',
'人工物': 'black',
'概念': 'purple'
}
# 単語ベクトルを辞書に格納
word_vectors = {}
# categoriesから全ての単語を取得し、重複を排除
words = []
for category, word_list in categories.items():
for word in word_list:
if word not in words: # 重複チェック
words.append(word)
for word in words:
try:
word_vectors[word] = model.get_vector(word)
except KeyError:
print(f"警告: '{word}' はモデル内に見つかりませんでした。")
# ベクトルリストの準備
vectors = list(word_vectors.values())
labels = list(word_vectors.keys())
# ベクトルの正規化
normalized_vectors = normalize(vectors)
# PCAで次元削減
pca = PCA(n_components=2, random_state=42)
reduced_vectors = pca.fit_transform(normalized_vectors)
# 寄与率の取得
explained_variance_ratio = pca.explained_variance_ratio_
# 可視化(カテゴリごとに色分け)
plt.figure(figsize=(14, 12))
# 各カテゴリごとに点をプロット
for category, color in category_colors.items():
# カテゴリに含まれる単語のインデックスを取得
indices = [i for i, label in enumerate(labels) if label in categories[category]]
# そのカテゴリの単語をプロット
if indices:
plt.scatter(
[reduced_vectors[i, 0] for i in indices],
[reduced_vectors[i, 1] for i in indices],
color=color,
label=category,
s=20,
alpha=0.8
)
# ラベルの追加
texts = []
for i, label in enumerate(labels):
# 単語が属するカテゴリの色を取得
category = next((cat for cat, words_list in categories.items() if label in words_list), None)
color = category_colors.get(category, 'black')
# テキストを追加
texts.append(plt.text(reduced_vectors[i, 0], reduced_vectors[i, 1], label, color=color, fontsize=9))
plt.title(f'Word2VecのPCA射影({model.vector_size}次元から2次元) - カテゴリ別色分け')
plt.xlabel(f'PCA次元1 (寄与率: {explained_variance_ratio[0]:.2%})')
plt.ylabel(f'PCA次元2 (寄与率: {explained_variance_ratio[1]:.2%})')
plt.grid(True, alpha=0.3)
plt.legend(loc='upper right')
# テキスト位置の調整
adjust_text(texts,
arrowprops=dict(arrowstyle='->', color='red', lw=1.0, alpha=1.0),
force_points=(0.1, 0.2),
force_text=(0.5, 1.0),
expand_points=(1.5, 1.5),
expand_text=(1.5, 1.5),
only_move={'points':'xy', 'text':'xy'})
plt.show()
静的埋め込み(Static Embedding)の特徴
-
一つの単語に対して常に同じベクトル表現(埋め込み)を割り当てる
-
文脈に依存しない固定された表現を生成する
- 例えば、人気者を表す star も、天体の star も同じ埋め込みベクトルが割り当てられる
- Shohei Ohtani is an MLB star.(大谷翔平さんはメジャーリーグのスターです)
- The sun is a star.(太陽はスター(星)です)
- 例えば、人気者を表す star も、天体の star も同じ埋め込みベクトルが割り当てられる
-
Word2Vec、GloVe、FastTextなどのアルゴリズムが代表的
静的埋め込み(Static Embedding)のまとめ
- モデルの学習時には、学習データの文の文脈(共起関係)から単語間の関連性を学習して、類似した単語、関連のある単語には近いベクトル値が与えられるように文脈から学習します
- モデルの利用時には、単語を学習時に割り当てた埋め込みベクトルに変換するだけで、利用時に単語が置かれた文脈は考慮されません
静的埋め込み(Static Embedding)の重要な特徴として、単語の文脈非依存性があります。例えば、"bank"という単語は、「銀行(bank)で口座を開設する」という文でも、「土手(bank)を散歩をする」という文でも、文脈に関係なく同一のベクトル表現に変換されます。このため、多義語の異なる意味を区別できないという制限があります。
また、各単語の埋め込みベクトルは、学習データ内での共起関係から計算された固定値となります。つまり、一度学習が完了すると、各単語に対応するベクトルは変化せず、固定された値として使用されます。
シンプルで効率的で軽量であるため、エッジデバイスやブラウザ環境での利用に適しています。
最近では、LLM 同様にアテンション機構による文脈を考慮したTransformerベースの埋め込みモデル(次項)が注目されてますが、Static Embedding は、現在でも発展を続けています。2025年1月 にも以下のような新しい研究/モデルも公開されています。
次に紹介するTransformerベースのモデルでは、多義語の文脈依存性を捉え、より柔軟な埋め込みを生成可能となっています。
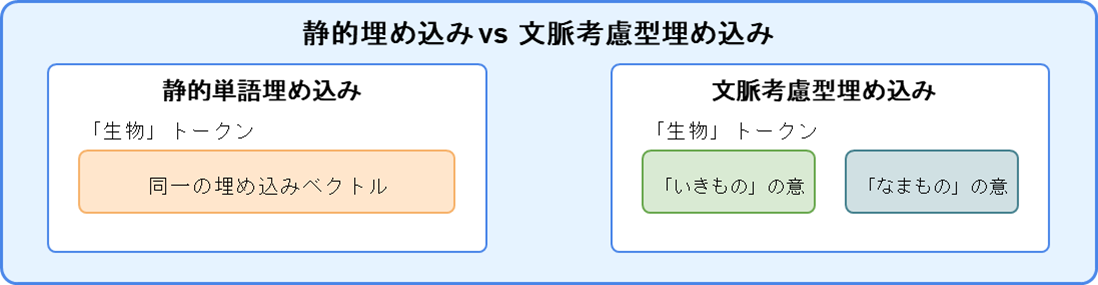
Transformerベースの文脈考慮型埋め込み
より高度な埋め込みモデルは、BERTやGPTなどのTransformerアーキテクチャを基盤としています。これらのモデルは、入力テキストの文脈を考慮して動的に(文脈を反映して)埋め込みを生成します。

例えば、「生物」という単語には、「いきもの」を表す場合と、「調理していない食品」を表す場合の2つの意味があります。読みを考慮しないトークナイザーはいずれの場合にも同じトークンIDを割り当てます。静的単語埋め込みモデルは、1つのトークンに対して1通りの埋め込みを生成するため、「生物("いきもの"の意)」も「生物("なまもの"の意)」も同じ埋め込みとなります。そのため、「生物("いきもの"の意)」も「生物("なまもの"の意)」という全く異なるものが区別されないことなります。
これに対して、Transformerベースの文脈考慮型埋め込みモデルでは、自己注意機構(Self Attention Mechnism)を使って文脈を埋め込むことができます。
自己注意機構によって生成される「猫は生物です」という文の中の「生物」の文脈考慮の埋め込みは次のようなイメージです。
["生物(いきものの意)"] = 0.3 x ["猫"] + 0.1 x ["は"] + 0.5 x ["生物"] + 0.1 x ["です"]
つまり、文脈考慮の["生物(いきものの意)"]には、「猫っぽさ」が3割混ざることとなります。
同様に「刺身は生物です」というの文の中の「生物」の文脈考慮の埋め込みは以下のようなイメージとなります。
["生物(なまものの意)"] = 0.2 x ["刺身"] + 0.1 x ["は"] + 0.6 x ["生物"] + 0.1 x ["です"]
今度は、["生物(なまものの意)"]に「刺身っぽさ」が2割混ざることとなりました。
文脈を考慮した単語埋め込み生成と可視化のコードの例
BERT base Japanese による埋め込み生成と可視化のコードを表示/非表示
import torch
from transformers import AutoModel, AutoTokenizer
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import japanize_matplotlib
from adjustText import adjust_text
# モデルとトークナイザーのロード
model_name = "tohoku-nlp/bert-base-japanese-v3"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# テキストの例
ikimono_sentences = ["猫は生物です", "犬は生物です", "鳥は生物です", "魚は生物です", "虫は生物です", "象は生物です", "蛇は生物です", "クジラは生物です", "きのこは生物です", "人間は生物です", "生物多様性", "生物兵器は禁止されています", "地球上に最初に現れた生物は?", "火星に生物がいるかどうか研究している"]
namamono_sentences = ["刺身は生物です", "お寿司は生物です", "生牡蠣は生物です", "生卵は生物です", "生ハムは生物です", "生肉は生物です", "生魚は生物です", "生野菜は生物です", "生フルーツは生物です", "生クリームは生物です", "生物には注意が必要です", "生物でお腹を壊した", "生物は加熱した方がいい", "生物は消費期限に注意が必要"]
texts = ikimono_sentences + namamono_sentences
seibutsu_embeddings = [] # 「生物」トークンの埋め込みを文と一緒に保存するリスト
# テキストリストから各テキストを処理
for i, text in enumerate(texts):
print(f"\n===== テキスト {i+1}: '{text}' =====")
# トークナイズ
inputs = tokenizer(text, return_tensors="pt")
# モデルに入力して埋め込みを取得
outputs = model(**inputs)
# 埋め込みの取得
embeddings = outputs.last_hidden_state
# トークンインデックスの取得
token_ids = inputs.input_ids[0]
token_embeddings = embeddings[0]
# トークンごとの埋め込みを取得
for token_id, embedding in zip(token_ids, token_embeddings):
token_text = tokenizer.convert_ids_to_tokens(token_id.item())
# トークンが「生物」の場合のみ処理して保存
if token_text == "生物":
print(f"Token ID: {token_id}, トークン: {token_text}, 埋め込み次元数: {embedding.size(0)}")
# 文と埋め込みをセットで保存
seibutsu_embeddings.append({
"text": text,
"embedding": embedding.detach().numpy() # テンソルをNumPy配列に変換して保存
})
# 保存したデータの確認
print(f"\n合計 {len(seibutsu_embeddings)} 個の「生物」埋め込みを保存しました")
# PCAの準備
embeddings_array = np.array([item["embedding"] for item in seibutsu_embeddings])
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(embeddings_array)
# 可視化の準備
plt.figure(figsize=(10, 8))
# 各点のカテゴリを判断し、色を設定
texts_objects = []
for i, item in enumerate(seibutsu_embeddings):
text = item["text"]
x, y = embeddings_2d[i]
# ikimono_sentencesの要素なら赤色、namamono_sentencesなら青色
if text in ikimono_sentences:
color = 'red'
category = '生き物'
else:
color = 'blue'
category = '生物(なまもの:食べ物)'
plt.scatter(x, y, c=color)
texts_objects.append(plt.text(x, y, text, fontsize=9))
# テキストの位置を自動調整
adjust_text(texts_objects, arrowprops=dict(arrowstyle='->', color='black', lw=0.5))
# グラフの設定
# 埋め込み次元数を動的に取得
embedding_dim = embeddings_array.shape[1]
plt.title(f'「生物」の埋め込みのPCA可視化({embedding_dim}次元から2次元) - カテゴリ別色分け')
explained_variance = pca.explained_variance_ratio_
plt.xlabel(f'第1主成分(寄与率: {explained_variance[0]:.2%})')
plt.ylabel(f'第2主成分(寄与率: {explained_variance[1]:.2%})')
# 凡例の追加
from matplotlib.lines import Line2D
legend_elements = [
Line2D([0], [0], marker='o', color='w', markerfacecolor='red', label='生き物', markersize=10),
Line2D([0], [0], marker='o', color='w', markerfacecolor='blue', label='生物(なまもの:食べ物)', markersize=10)
]
plt.legend(handles=legend_elements)
# グリッド表示
plt.grid(True, linestyle='--', alpha=0.7)
# グラフの表示
plt.tight_layout()
plt.savefig('seibutsu_pca.png')
plt.show()
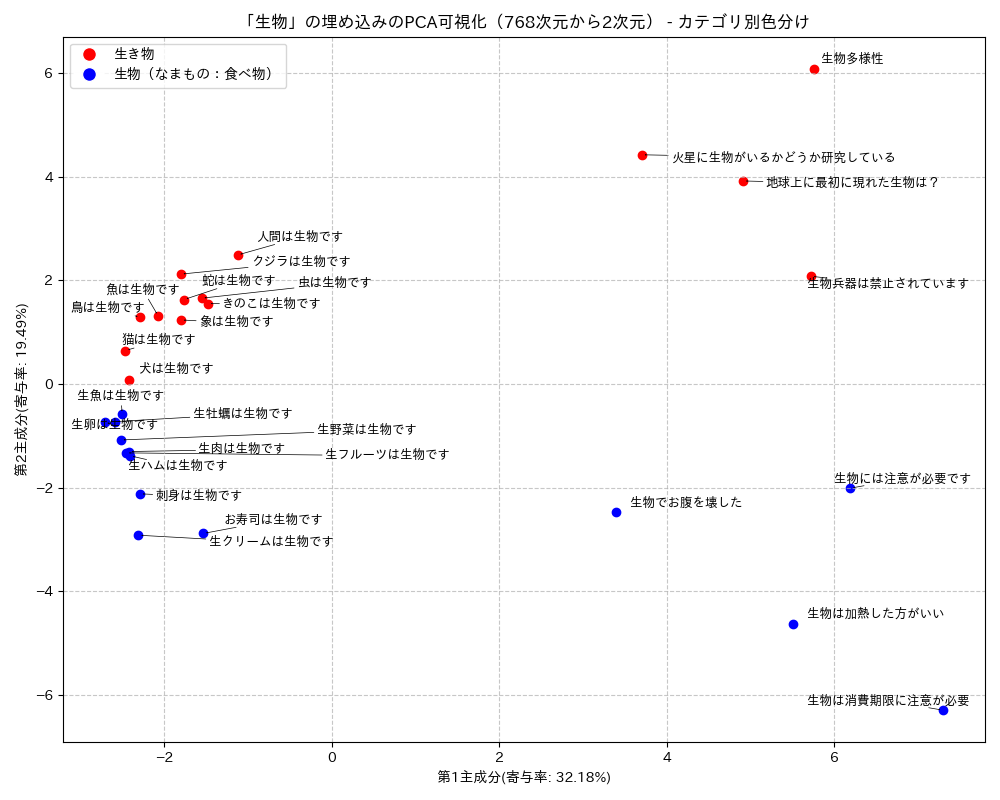
上図は、東北大学 BERT base Japanese v3の最終隠れ層から単語(トークン)= "生物"の埋め込みベクトルを取得して、PCA次元削減・可視化したものです。例えば、右上方の「火星に生物がいるかどうか研究している」のデータポイントは、「火星に生物がいるかどうか研究している」という 文の中の"生物"という単語のみの埋め込みベクトル を表しています。「生き物」の意味で使われている場合は、赤、「なまもの」の意味で使われている場合は「青」でプロットしています。
単語が含まれている文(文脈)が異なれば、同じ単語でも異なる埋め込みベクトルに変換されていること、文脈によりグループ(クラスター)を形成していることがわかります。
実際の Transfromer では、自己注意機構は階層的に多段階で適用されます。浅い層では単語間の直接的な関連性を捉え、深い層に行くにしたがって埋め込みに含まれている潜在的な概念の関連性が強化されます。
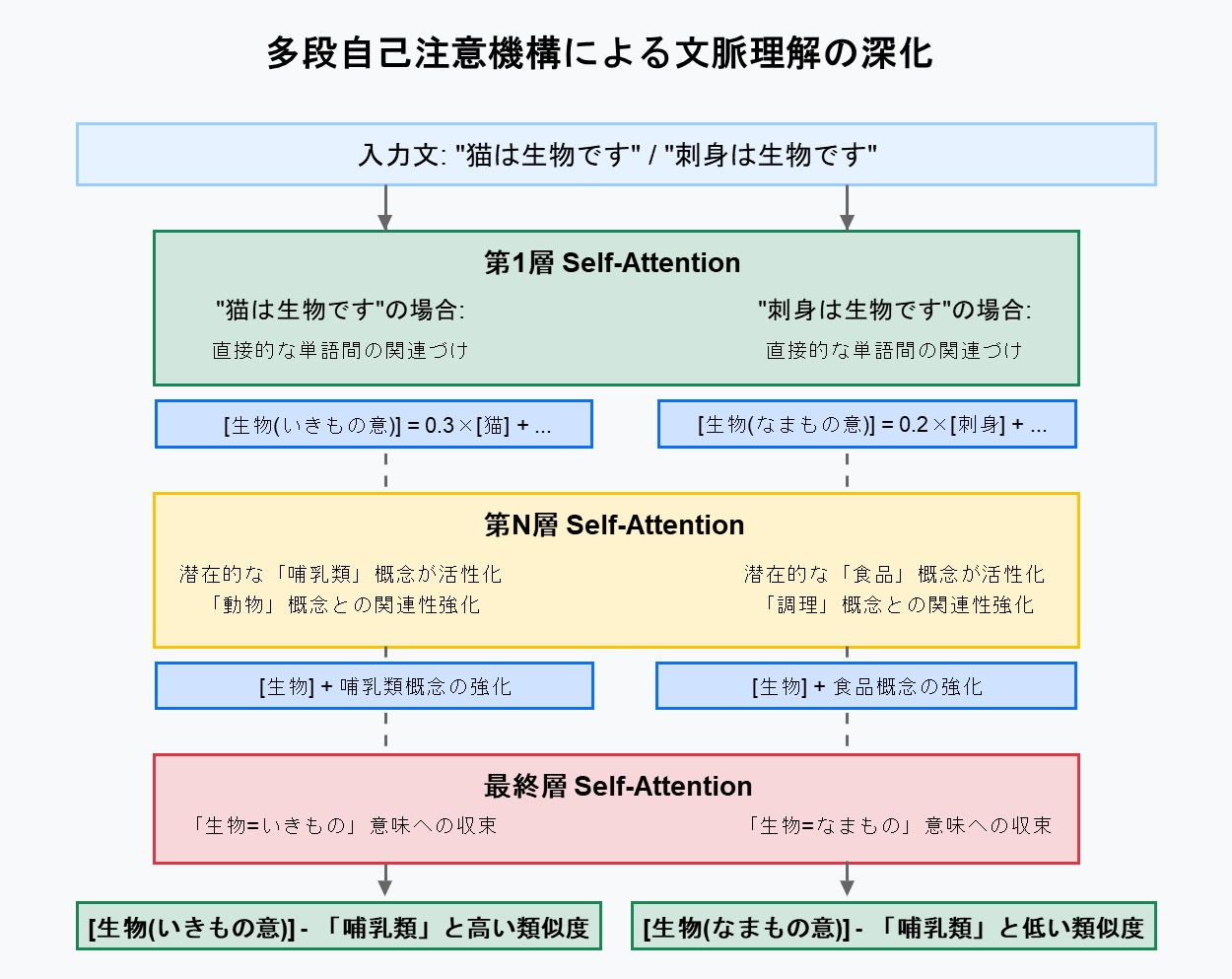
例えば、「猫」の埋め込みには「哺乳類」の概念との関連性が含まれていて、「生物」の埋め込みにも「哺乳類」の概念との関連性が含まれています。そのため、自己注意機構が繰り返し適用されることで生成される「生物(いきものの意)」の埋め込みでは「哺乳類」という概念との関連性が強化されていきます。
一方で、「生物(なまものの意)」の埋め込みでは「哺乳類」の概念が強化される度合いは低いと考えられます。
結果として、「生物(いきものの意)」の埋め込みは、「哺乳類」と高い類似度を持ちますが、「生物(なまものの意)」の埋め込みは「哺乳類」との類似度は相対的に低くなります。
文脈を考慮した単語埋め込み生成と類似度計算のコードの例
BERT base Japanese による埋め込み生成と類似度計算のコードを表示/非表示
import torch
from transformers import AutoModel, AutoTokenizer
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
import seaborn as sns
# モデルとトークナイザーのロード
model_name = "tohoku-nlp/bert-base-japanese-v3"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# テキストの例
ikimono_sentences = ["猫は生物です", "犬は生物です", "鳥は生物です", "魚は生物です", "虫は生物です", "象は生物です", "蛇は生物です", "クジラは生物です", "きのこは生物です", "人間は生物です", "生物多様性", "生物兵器は禁止されています", "地球上に最初に現れた生物は?", "火星に生物がいるかどうか研究している"]
namamono_sentences = ["刺身は生物です", "お寿司は生物です", "生牡蠣は生物です", "生卵は生物です", "生ハムは生物です", "生肉は生物です", "生魚は生物です", "生野菜は生物です", "生フルーツは生物です", "生クリームは生物です", "生物には注意が必要です", "生物でお腹を壊した", "生物は加熱した方がいい", "生物は消費期限に注意が必要"]
# ペット文を追加
pet_sentences = ["猫は世界中でペットとして飼われています"]
texts = ikimono_sentences + namamono_sentences + pet_sentences
seibutsu_embeddings = [] # 「生物」トークンの埋め込みを文と一緒に保存するリスト
pet_embeddings = [] # 「ペット」トークンの埋め込みを文と一緒に保存するリスト
# テキストリストから各テキストを処理
for i, text in enumerate(texts):
print(f"\n===== テキスト {i+1}: '{text}' =====")
# トークナイズ
inputs = tokenizer(text, return_tensors="pt")
# モデルに入力して埋め込みを取得
outputs = model(**inputs)
# 埋め込みの取得
embeddings = outputs.last_hidden_state
# トークンインデックスの取得
token_ids = inputs.input_ids[0]
token_embeddings = embeddings[0]
# トークンごとの埋め込みを取得
for token_id, embedding in zip(token_ids, token_embeddings):
token_text = tokenizer.convert_ids_to_tokens(token_id.item())
# トークンが「生物」の場合のみ処理して保存
if token_text == "生物":
print(f"Token ID: {token_id}, トークン: {token_text}, 埋め込み次元数: {embedding.size(0)}")
# 文と埋め込みをセットで保存
seibutsu_embeddings.append({
"text": text,
"embedding": embedding.detach().numpy(),
"category": "生物"
})
# トークンが「ペット」の場合も処理して保存
if token_text == "ペット":
print(f"Token ID: {token_id}, トークン: {token_text}, 埋め込み次元数: {embedding.size(0)}")
# 文と埋め込みをセットで保存
pet_embeddings.append({
"text": text,
"embedding": embedding.detach().numpy(),
"category": "ペット"
})
# 保存したデータの確認
print(f"\n合計 {len(seibutsu_embeddings)} 個の「生物」埋め込みを保存しました")
print(f"合計 {len(pet_embeddings)} 個の「ペット」埋め込みを保存しました")
# 類似度計算(コサイン類似度)
print("\n===== 埋め込みの類似度計算 =====")
# 埋め込みをnumpy配列に変換
seibutsu_embeddings_array = np.array([item["embedding"] for item in seibutsu_embeddings])
pet_embeddings_array = np.array([item["embedding"] for item in pet_embeddings])
# ペットと生物の間の類似度行列を計算
similarity_matrix = cosine_similarity(pet_embeddings_array, seibutsu_embeddings_array)
# テキストとカテゴリの表示用リスト
pet_texts = [item["text"] for item in pet_embeddings]
seibutsu_texts = [item["text"] for item in seibutsu_embeddings]
# 類似度の結果をデータフレームとして整形
similarity_df = pd.DataFrame(similarity_matrix,
index=[f"{text} (ペット)" for text in pet_texts],
columns=[f"{text} (生物)" for text in seibutsu_texts])
# 表形式でマークダウンとして保存
similarity_df.to_markdown('similarity_table.md')
print("ペットと生物間の類似度テーブルを similarity_table.md に保存しました")
# ヒートマップの描画
plt.figure(figsize=(15, 8))
sns.heatmap(similarity_matrix, annot=True, cmap='coolwarm',
xticklabels=seibutsu_texts,
yticklabels=pet_texts)
plt.title('ペットと生物の埋め込みのコサイン類似度')
plt.xlabel('生物トークンの埋め込み')
plt.ylabel('ペットトークンの埋め込み')
plt.tight_layout()
plt.savefig('pet_seibutsu_similarity_heatmap.png')
plt.show()
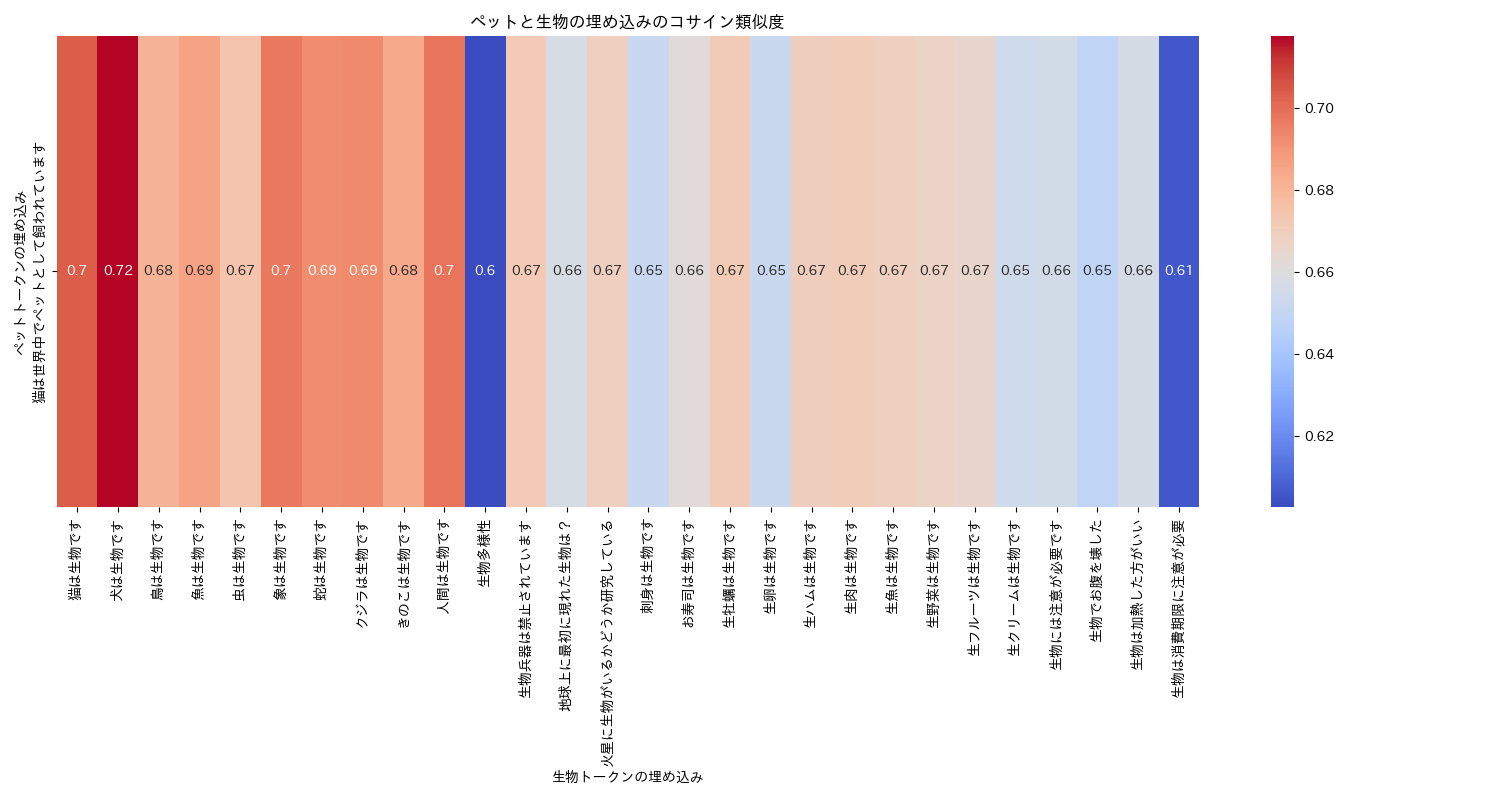
上図は、東北大学 BERT base Japanese v3の最終隠れ層から単語(トークン)= "生物"と"ペット"の埋め込みベクトルを取得してコサイン類似度を計算したものです。濃い赤程類似度が高いことを表しています。
文脈を考慮した単語埋め込み生成とUMAPによ次元削減のコードの例
BERT base Japanese による埋め込み生成とUMAPによ次元削減のコードを表示/非表示
import torch
from transformers import AutoModel, AutoTokenizer
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import japanize_matplotlib
from adjustText import adjust_text
# モデルとトークナイザーのロード
model_name = "tohoku-nlp/bert-base-japanese-v3"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# テキストの例
ikimono_sentences = ["猫は生物です", "犬は生物です", "鳥は生物です", "魚は生物です", "虫は生物です", "象は生物です", "蛇は生物です", "クジラは生物です", "きのこは生物です", "人間は生物です", "生物多様性", "生物兵器は禁止されています", "地球上に最初に現れた生物は?", "火星に生物がいるかどうか研究している"]
namamono_sentences = ["刺身は生物です", "お寿司は生物です", "生牡蠣は生物です", "生卵は生物です", "生ハムは生物です", "生肉は生物です", "生魚は生物です", "生野菜は生物です", "生フルーツは生物です", "生クリームは生物です", "生物には注意が必要です", "生物でお腹を壊した", "生物は加熱した方がいい", "生物は消費期限に注意が必要"]
# ペット文を追加
pet_sentences = ["犬はペットとして人気です", "猫は世界中でペットとして飼われています", "金魚もペットです", "ハムスターはかわいいペットです", "ペットの健康管理は大切です"]
texts = ikimono_sentences + namamono_sentences + pet_sentences
seibutsu_embeddings = [] # 「生物」トークンの埋め込みを文と一緒に保存するリスト
pet_embeddings = [] # 「ペット」トークンの埋め込みを文と一緒に保存するリスト
# テキストリストから各テキストを処理
for i, text in enumerate(texts):
print(f"\n===== テキスト {i+1}: '{text}' =====")
# トークナイズ
inputs = tokenizer(text, return_tensors="pt")
# モデルに入力して埋め込みを取得
outputs = model(**inputs)
# 埋め込みの取得
embeddings = outputs.last_hidden_state
# トークンインデックスの取得
token_ids = inputs.input_ids[0]
token_embeddings = embeddings[0]
# トークンごとの埋め込みを取得
for token_id, embedding in zip(token_ids, token_embeddings):
token_text = tokenizer.convert_ids_to_tokens(token_id.item())
# トークンが「生物」の場合のみ処理して保存
if token_text == "生物":
print(f"Token ID: {token_id}, トークン: {token_text}, 埋め込み次元数: {embedding.size(0)}")
# 文と埋め込みをセットで保存
seibutsu_embeddings.append({
"text": text,
"embedding": embedding.detach().numpy(),
"category": "生物"
})
# トークンが「ペット」の場合も処理して保存
if token_text == "ペット":
print(f"Token ID: {token_id}, トークン: {token_text}, 埋め込み次元数: {embedding.size(0)}")
# 文と埋め込みをセットで保存
pet_embeddings.append({
"text": text,
"embedding": embedding.detach().numpy(),
"category": "ペット"
})
# 保存したデータの確認
print(f"\n合計 {len(seibutsu_embeddings)} 個の「生物」埋め込みを保存しました")
print(f"合計 {len(pet_embeddings)} 個の「ペット」埋め込みを保存しました")
# すべての埋め込みを結合
all_embeddings = seibutsu_embeddings + pet_embeddings
embeddings_array = np.array([item["embedding"] for item in all_embeddings])
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(embeddings_array)
# 可視化の準備
plt.figure(figsize=(12, 10))
# 各点のカテゴリを判断し、色を設定
texts_objects = []
for i, item in enumerate(all_embeddings):
text = item["text"]
x, y = embeddings_2d[i]
if item["category"] == "ペット":
color = 'green'
category_name = 'ペット'
elif text in ikimono_sentences:
color = 'red'
category_name = '生き物'
else:
color = 'blue'
category_name = '生物(なまもの:食べ物)'
plt.scatter(x, y, c=color)
texts_objects.append(plt.text(x, y, text, fontsize=9))
# テキストの位置を自動調整
adjust_text(texts_objects, arrowprops=dict(arrowstyle='->', color='black', lw=0.5))
# グラフの設定
embedding_dim = embeddings_array.shape[1]
plt.title(f'「生物」と「ペット」の埋め込みのPCA可視化({embedding_dim}次元から2次元)')
explained_variance = pca.explained_variance_ratio_
plt.xlabel(f'第1主成分(寄与率: {explained_variance[0]:.2%})')
plt.ylabel(f'第2主成分(寄与率: {explained_variance[1]:.2%})')
# 凡例の追加
from matplotlib.lines import Line2D
legend_elements = [
Line2D([0], [0], marker='o', color='w', markerfacecolor='red', label='生き物', markersize=10),
Line2D([0], [0], marker='o', color='w', markerfacecolor='blue', label='生物(なまもの:食べ物)', markersize=10),
Line2D([0], [0], marker='o', color='w', markerfacecolor='green', label='ペット', markersize=10)
]
plt.legend(handles=legend_elements)
# グリッド表示
plt.grid(True, linestyle='--', alpha=0.7)
# グラフの表示
plt.tight_layout()
plt.savefig('seibutsu_pet_pca.png')
plt.show()

Transformerベースのモデルのまとめ
Transformerベースのモデルの特徴は、Static Embeddingとは異なり、同じ単語でも文脈によって異なる埋め込みが生成される点です。例えば、"bank"という英語の単語は
- 「銀行に行く」という文では金融機関としての意味を反映した埋め込みに
- 「土手を散歩する」という文では河川敷としての意味を反映した埋め込みに
それぞれ変換されます。
下図は、同じ単語("bank")が異なる文脈において異なる埋め込みに変換される例です。

Wiedemann らのDoes BERT Make Any Sense? Interpretable Word Sense Disambiguation with Contextualized Embeddings より異なる文脈における"bank"のコンテキスト埋め込みの例
このように、Transformerベースのモデルは、より豊かな文脈情報を捉えることができる一方で、計算コストが高くなるというトレードオフがあります。
文の埋め込み
Static Embedding モデルでも、Transformerベースのモデルでも埋め込みモデルから得られる出力は各トークンに対応する埋め込みベクトルの系列となるため、これを効率的に利用するための工夫が必要となります。
Pooling(プーリング)の役割
埋め込みモデルは入力テキストの各トークンに対応する埋め込みの系列を生成します(トークンの数だけ埋め込みが生成される)。しかし、ベクトルデータベースのような実際のアプリケーションでは、文書やフレーズ全体を1つの埋め込みとして表現したほうが扱いやすく、効率的です。ここで重要となるのが、Pooling(プーリング)と呼ばれる操作です。
Poolingは、複数の埋め込みから単一の埋め込み表現を生成する手法です。主な手法として以下があります。
Mean Pooling(平均プーリング)
最も一般的なアプローチの1つで、全てのトークンの埋め込みの平均を取ります。文書全体の意味を均等に反映させる特徴があります。
CLS Token Pooling(CLSトークンプーリング)
BERTなどのTransformerモデルでよく使われる手法です。文頭に特別なトークン([CLS])を配置し、このトークンの最終層の出力を文書全体の表現として使用します。モデルは学習時に、このトークンが文書全体の意味を要約するように訓練されています。
下図は、Mean Pooling(平均プーリング)のイメージです。

このようなプーリングにより個々の単語(トークン)の埋め込みが持っていた特徴を反映した文の埋め込みを作ることができます。また、多数の単語の埋め込みを1つの文埋め込みに集約することで、容量を劇的に小さくすることができ、ストレージ容量を抑えることができ、さらに、後の検索の際の演算量を少なくすることができます。

これは国・地方共通相談チャットボット Govbot(ガボット)に搭載されている各分野のFAQデータ(全分野)の「問い」と「回答」を連結して Cohere Embed 3 で埋め込みベクトル化したものを UMAP で次元削減(二次元へ射影)して可視化したもので、赤いデータポイントは103万円、150万円、106万円、130万円の壁に関するQAで、青はそれ以外を表しています。XXX万円の壁に関するQAが埋め込み空間上で近くに集まっていることが見て取れます。
文埋め込みの質問応答タスクへの最適化
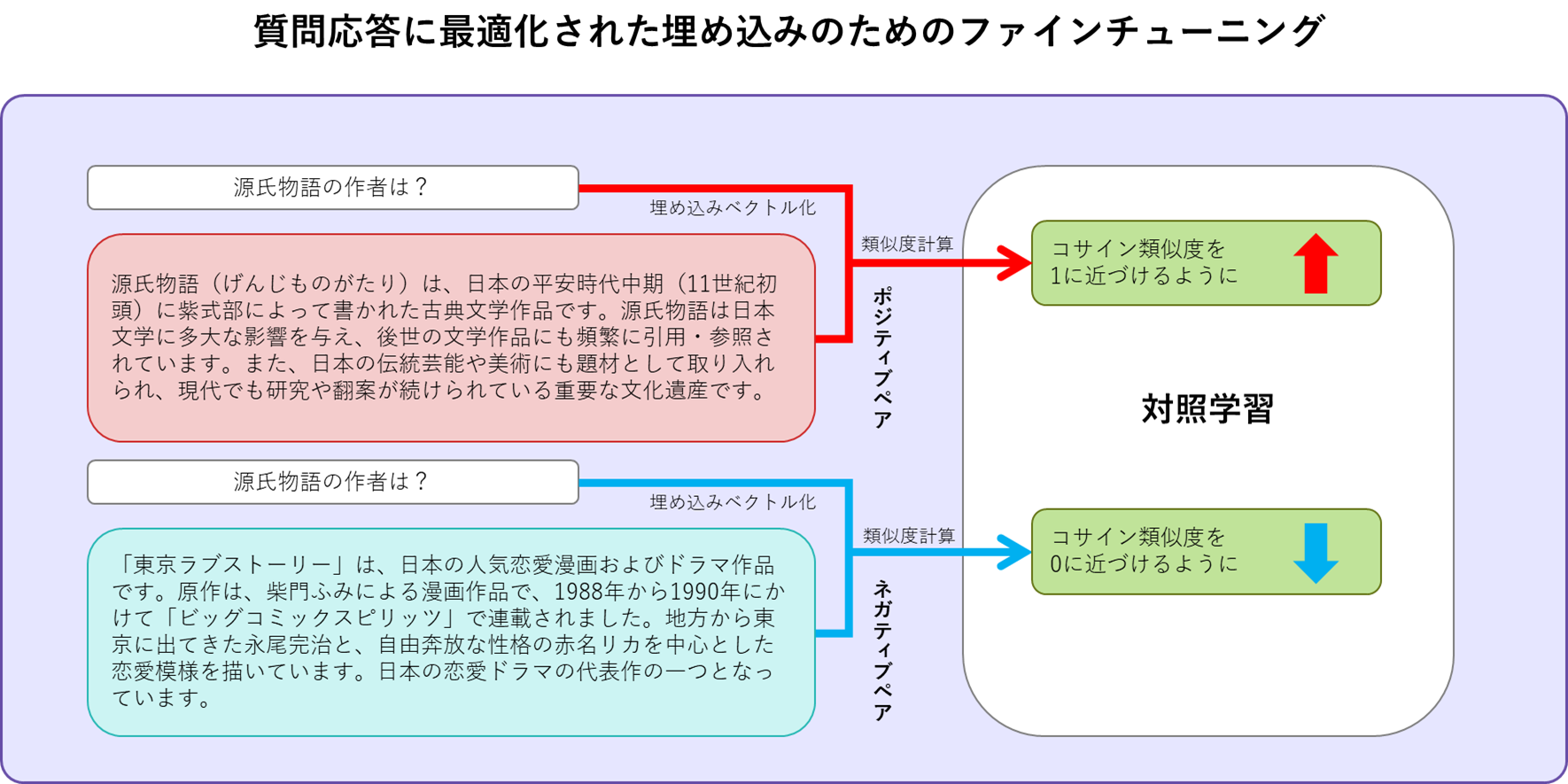
Cohere Embed 3 が単純に字面が似ている文に高い類似度を与えるわけではないことの検証記事はこちらです。
テキストの埋め込みを使った類似性検索
似た事物は、似た特徴を持ち、多次元の埋め込み空間(ベクトル空間)の中で近くに位置します。似たものを見つけるには、埋め込み間の距離を計算して、最も近くに位置する埋め込みを見つければよいこととなります。

埋め込みベクトルを使った類似性検索のイメージ
埋め込み空間(ベクトル空間)の中における"近さ"の指標
| 指標 | 意味 |
|---|---|
| L2距離 | ユークリッド距離とも呼ばれる。3次元空間のおける直観的な距離に相当 |
| コサイン距離 | ベクトル間の角度に基づく距離(1 – コサイン類似度) |
| 内積(ドットプロダクト) | ベクトルとベクトルの内積。角度に加えて、ベクトルの大きさを反映した指標。大きさを1に正規化するとコサイン類似度と同等。 |
テキストの埋め込みを使った類似性検索のデモ
この記事が長くなってしまいましたので、コード例、実行例は別の記事に分離しました。
以下のような6つのパターンで検証しています。
- その1)テキストの類似性検索(ベクトルデータベースとは?)
- その2)テキストの類似性検索(近似最近傍検索とは?)
- その3)複数クエリーの埋め込みベクトルの平均による類似性検索
- その4)テキストのクロスリンガル(言語跨りの)類似性検索
- その5)日本語英語混在ドキュメント群に対する類似性検索
- その6)ドキュメントの品質が考慮されている?単純に質問文に似ている?

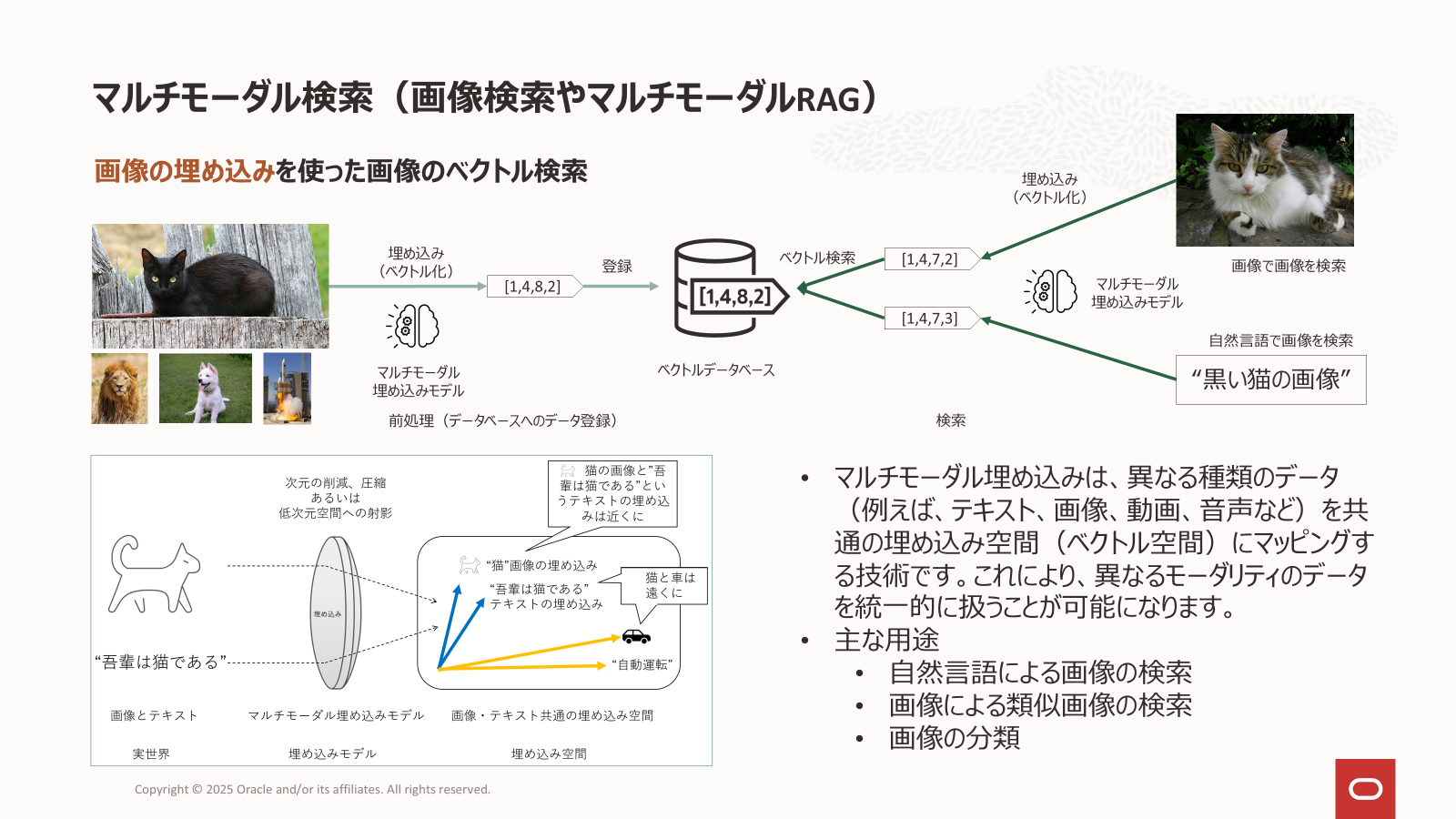
マルチモーダル埋め込み
マルチモーダル埋め込みモデルは、異なる種類のデータ(例えば、テキスト、画像、動画、音声など)を共通の埋め込み空間(ベクトル空間)にマッピングする技術です。これにより、異なるモーダリティのデータを統一的に扱うことが可能になります。マルチモーダル基盤モデルの一種です。
CLIP(Contrastive Language-Image Pre-training)
代表的なマルチモーダル埋め込みモデルには、CLIPがあります。2021年にOpenAIによって公開されました(OpenAIのブログ、実装)。CLIPは、インターネット等から収集された大規模な画像とテキストのペア(4億ペア)を用いて学習しています。学習は以下のように行われます。

Learning Transferable Visual Models From Natural Language Supervision
Figure 1. Summary of our approach.
- 収集したデータセットからN個の画像-テキストのペアをピックアップします(オリジナルの CLIP では、32768 のミニバッチ毎)
- N個の画像とN個のテキストそれぞれの特徴ベクトルを計算します(画像とテキストは同一の埋め込み空間にマッピングされます)
- N個の画像の特徴ベクトルとN個のテキストの特徴ベクトルのすべての組み合わせの類似度を計算します(N^2組)
- 画像とテキストの組み合わせが関連のあるペアである場合(上図の対角の水色のN組)に類似度が高くなり、無関係な組み合わせである場合(N^2 - N組)には類似度が低くなるように学習します
テキストの特徴ベクトルを生成するテキストエンコーダーには transformer を、画像の特徴ベクトルを生成する画像エンコーダーには、ResNet(CNNをベースにしたモデル)かVision Transformer (ViT)を利用することができます。
CLIPの学習の際には、類似度の指標にはコサイン類似度(2つのベクトルのなす角が小さい=コサインの値が大きい程似ているとみなす)が使われています。
このような学習により、テキストと画像を同一の埋め込み空間上にマッピングすることができます。そして、埋め込み空間上のテキストベクトルと画像ベクトルの位置は、テキストと画像が意味的に近いものは近く、意味的に異なるものは遠くへ位置することとなります。
このことから、テキストの意味に近い画像を検索する際には、テキストベクトルの近くにある画像ベクトルを見つければ良いこととなります。この近いベクトルを見つけるのはベクトルデータベースの役割となります。
なお、マルチモーダル埋め込みモデル(画像言語特徴抽出モデル)は、画像検索だけでなく、画像の分類にも利用できます(こちらが元々の使い方でもあります)。
画像検索とは検索の方向を逆にして、問い合わせとなる画像の画像ベクトルの近くにあるテキストベクトルを見つけることで、そのテキストが表すカテゴリ(分類クラス)への分類が実現できます。
従来の画像分類モデルは分類可能なカテゴリー(分類クラス)が学習に用いられたラベルだけに限定されていましたが、CLIPは大規模な画像・テキストのペアを学習していることからFine-tuningをすることなく任意の分類カテゴリーに対する分類が可能です。これはゼロショット画像分類と呼ばれています。
CLIPを利用した画像分類例

CLIPを利用した画像分類アプリケーション作成の記事
マルチモーダル埋め込みを使った画像の類似性検索と画像分類のデモ
こちらも、コード例、実行例は別の記事に分離しました。
- 画像検索(1) - テキストをクエリーとした画像の検索
- 画像検索(2) - 画像をクエリーとした画像の検索
- 画像検索(3) - テキストをクエリーとした画像とテキストのミックス検索
- 画像検索(4) - 画像をクエリーとした画像とテキストのミックス検索
- 画像検索(5) - ECサイトを想定した画像検索
- 画像分類 - 航空写真を洪水被害を受けている地域のものか、そうでないか判定させる

洪水画像の判定については、詳細を以下の記事にまとめています。
マルチモーダル埋め込みの応用
画像生成への応用(1)
CLIP の応用は、画像検索や分類だけに限定されるものではありません。画像生成AIとして有名な Open AI の DALL-E2、Stability AI の Stable Diffusion や Black Forest Labs の FLUX.1 等のプロンプトの言語理解と画像生成のガイドの機能を担うなど幅広い分野に応用されています。

OpenAI の論文(Hierarchical Text-Conditional Image Generation with CLIP Latents)から引用
この図は、OpenAI の画像生成モデル DALL-E2(ダリ2) で採用されているunCLIP(アンクリップ)です。
図の点線より上は、CLIPの学習過程を表していて、下半分がCLIPを活用した画像生成の仕組み(unCLIP)です。
unCLIPの画像生成処理は以下のように行われます。
- CLIP のテキストエンコーダーを使って、画像生成プロンプト(コーギーが炎を放つトランペットを吹いている)をCLIPのテキスト埋め込みへ変換する
- CLIPのテキスト埋め込み ≒ CLIPの画像埋め込み(ここが unCLIPのポイント)であることを利用して、 CLIPのテキスト埋め込みを prior(拡散モデルなど)で画像埋め込みに変換
- 画像デコーダーが画像埋め込みから「コーギーが炎を放つトランペットを吹いている」画像を生成する
2 の CLIP テキスト埋め込みから CLIP 画像埋め込みが unCLIP の肝となります。
unCLIP は、CLIP モデルの「テキストから画像への対応関係」を活用して画像生成を行う方式です。
CLIP は、画像とテキストをペアで学習することで、それぞれを同じ特徴空間(埋め込み空間)にマッピングできるマルチモーダルモデルです。これにより、たとえば「a cat」と入力すると、ネコの画像の特徴ベクトルに近い位置にマッピングされるようになっています。
一見すると、CLIP の「テキストの埋め込み」と「画像の埋め込み」は同じ空間にあるので、テキスト埋め込みをそのまま使って画像を再現できそうに思えます。
しかし、テキスト埋め込みはあくまでもテキストの特徴を捉えた埋め込みであって画像を生成するために十分な情報は持っていません。また、テキスト埋め込みと画像埋め込みは 同じ空間の中でも別の分布(領域) に偏って存在していることが知られています(Andi Marafioti さんの X 投稿)。そのため、テキスト埋め込みをそのまま使うと、画像生成モデルが想定している「画像的な特徴」に合わず、うまく画像を生成できません。
そこで unCLIP では、CLIP のテキスト埋め込みを、画像埋め込みの形式に変換する「prior(プライヤ)」と呼ばれる変換器を使います。この prior は、通常拡散モデルなどで構成され、テキストを画像的な表現へと変換してくれます。
CLIP がもともと画像とテキストの意味的な対応関係を学習しているため、この prior の学習も効率よく行え、高い精度で意味に合った画像生成が可能になります。
テキストによる画像生成の誘導方式には、unCLIP以外にも様々な方法があります。
-
Classifier Guidance
あらかじめ訓練した分類器を使って、生成途中の画像とテキストプロンプトの一致度を評価し、その情報から画像をテキストの意味に近づけるように調整する方式です。 -
Classifire-Free Guidance(CFG)
分類器を使わず、テキストあり・なしの両方の学習を通して得た情報を使い、生成をテキストの内容に沿うよう誘導する方式です。テキストと画像の関係は、交差注意機構(Cross-Attention)によって伝達されます。
また、CFG の交差注意機構による誘導に加えて、プロンプト中の特定の単語(たとえば「ball」や「dog」など)が画像内にきちんと反映されるよう、注意機構(Attention)がその語に十分に「集中」するように誘導する方式として Attend-and-Excite があり、特定単語への注意重みが高まるように制御することで、細かい要素の表現漏れ(プロンプト中に「ball」と「dog」があるのにボールが描かれないといったこと)を防ぐことができます。
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
画像生成の記事
FLUX.1 を使った画像生成アプリケーションや ComfyUI の使い方
画像生成への応用(2)

「テキストの埋め込みを使った類似性検索のデモ」の「その3)複数クエリーの埋め込みベクトルの平均による類似性検索」では、埋め込みベクトルに対して算術演算が可能であることを、画像生成への応用(1)では、CLIPなどの埋め込みベクトルが画像生成に応用されていることを見て来ました。この2つを組み合わせると上の猫からライオンへ変身するような動画を作ることができます。
上の動画は、概略以下のような手順で作られています。
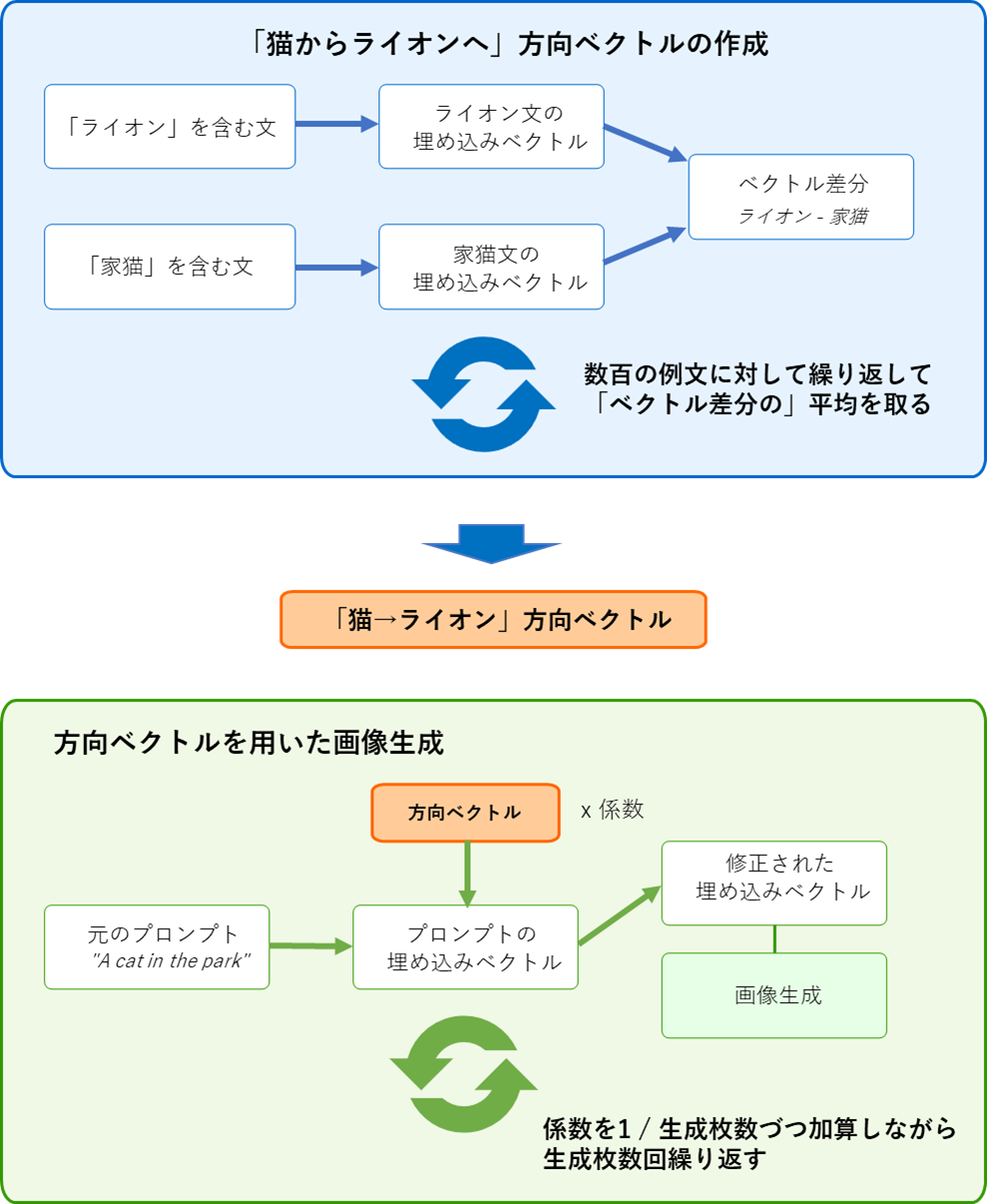
- 「猫からライオンへ」方向(埋め込み)ベクトルを作る
- "Lion"(ライオン) という単語を含んだ文をつくる
- "Domestic cat"(家猫)という単語を含んだ文をつくる
- 2つの文の埋め込みベクトルを生成する
- 2つの埋め込みベクトルの差分を取る(ライオン文 - 家猫文)
- ここまでの操作を数百回繰り返して平均を取り、これを「猫からライオンへ」方向ベクトルとする
- 画像群を生成する
- 画像生成プロンプト"A cat in the park"の埋め込みベクトルに「猫からライオンへ」方向ベクトルの、例えば1/10を加算する
- この加算された埋め込みベクトルで画像生成をガイドする
- この処理を繰り返す
下記のサイトで実際に試してみることができます。Prompt に "A cat in the park" のような動画の出発点となるプロンプトを、1st direction to steer Starting state に、「Domestic cat」のような変化の起点となるプロンプトを、2nd direction to steer Finishing state に「Lion」のような変化の終点となるプロンプトを設定して"Generate directions"をクリックすると動画が生成されます。うまく行かないことも多いですがいろいろ試して楽しんでみてください。上の GIF 画像もこのアプリケーションで作成したものです。
また、この Lattent Navigation は下記の2つを元にしています。
Semantic Sliders
Traversing through CLIP Space, PCA and Latent Directions
| プロンプト | 1st direction to steer Starting state | 2nd direction to steer Finishing state |
| a house | urban USA style | traditional Japanese style |
| 生成画像 |

|

|
なお、Semantic Sliders のコードを読んでみると生成される例文のテンプレートは、「Domestic cat」や「Lion」のような言葉が入力されることを意図していません。それでも、うまく行っているところが面白いですね。興味のある方は、clip_slider_pipeline.pyとconstants.py を読んでみてください。
超高解像度リモートイメージセンシング画像の解析:Image RAG
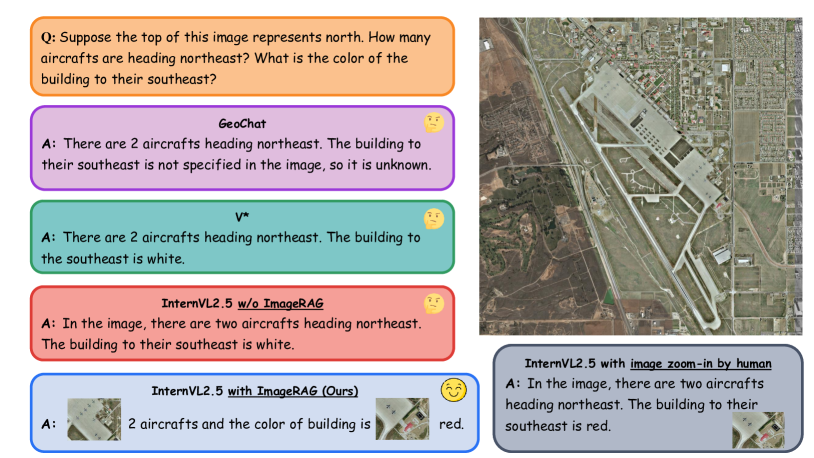
Enhancing Ultra High Resolution Remote Sensing Imagery Analysis with ImageRAG Figure 1 より
衛星画像などの超高解像度リモートセンシング画像や医療画像の中には、解像度が高すぎて現在利用できるRemote Sensing Vision Language Models (RSVLMs)では解析できなものがあります。このような用途に画像に対する RAG が提案されています。
通常のテキスト情報に対する RAG では、ドキュメントをチャンクに分割して、それを埋め込みベクトルへ変換して、ベクトルデータベースへ格納しますが、Image RAG では、超高解像度画像をパッチに分割して、このパッチの埋め込みベクトルをベクトルデータベースへ格納します。また、通常のテキスト情報に対する RAG では、ベクトルデータベースから取得したテキストチャンク群は、LLM にコンテキストとして入力されて、ユーザーの質問への回答が生成されますが、Image RAG では、LLM の代わりに VLM(マルチモーダルLLM)が使われます。

Enhancing Ultra High Resolution Remote Sensing Imagery Analysis with ImageRAG Figure 6 より
ショート動画投稿サイトの動画レコメンデーション

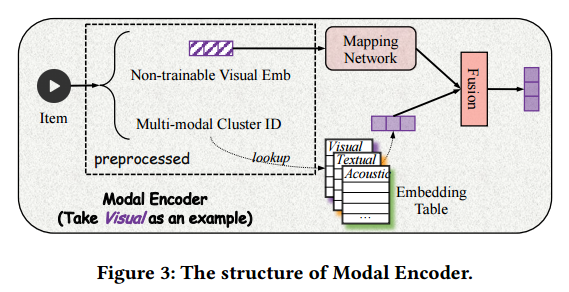
A Multi-modal Modeling Framework for Cold-start Short-video Recommendation より
この論文のショート動画投稿サイトでは、ユーザーの行動履歴と動画のマルチモーダル埋め込みをクエリーとして、動画の映像、音響、テキスト(タイトルや音声の書き起こし)の埋め込みベクトルに動画のクラスターごとの視聴傾向を統合したマルチモーダル埋め込みを検索対象とするベクトル検索によってサイト訪問者への推奨動画の提示を行っています(これは研究ではなくプロダクションで稼働しているものです)。
このようなレコメンデーションシステムでは、新規に投稿された動画のような視聴履歴の少ない動画のレコメンデーションをどうするかというコールドスタート問題が課題でした。このサイトでは、1,000万を超える動画のマルチモーダル埋め込みを k-means により約1,000のらクラスタに分類し、新規の動画をこの1,000のクラスタのいずれかに分類することにより、そのクラスタの視聴傾向を使って適切なユーザーへ推奨することを実現しています。
埋め込みを活用した RAG の精度向上策
ユーザーの質問文のクラスター分析によるドキュメントの改善
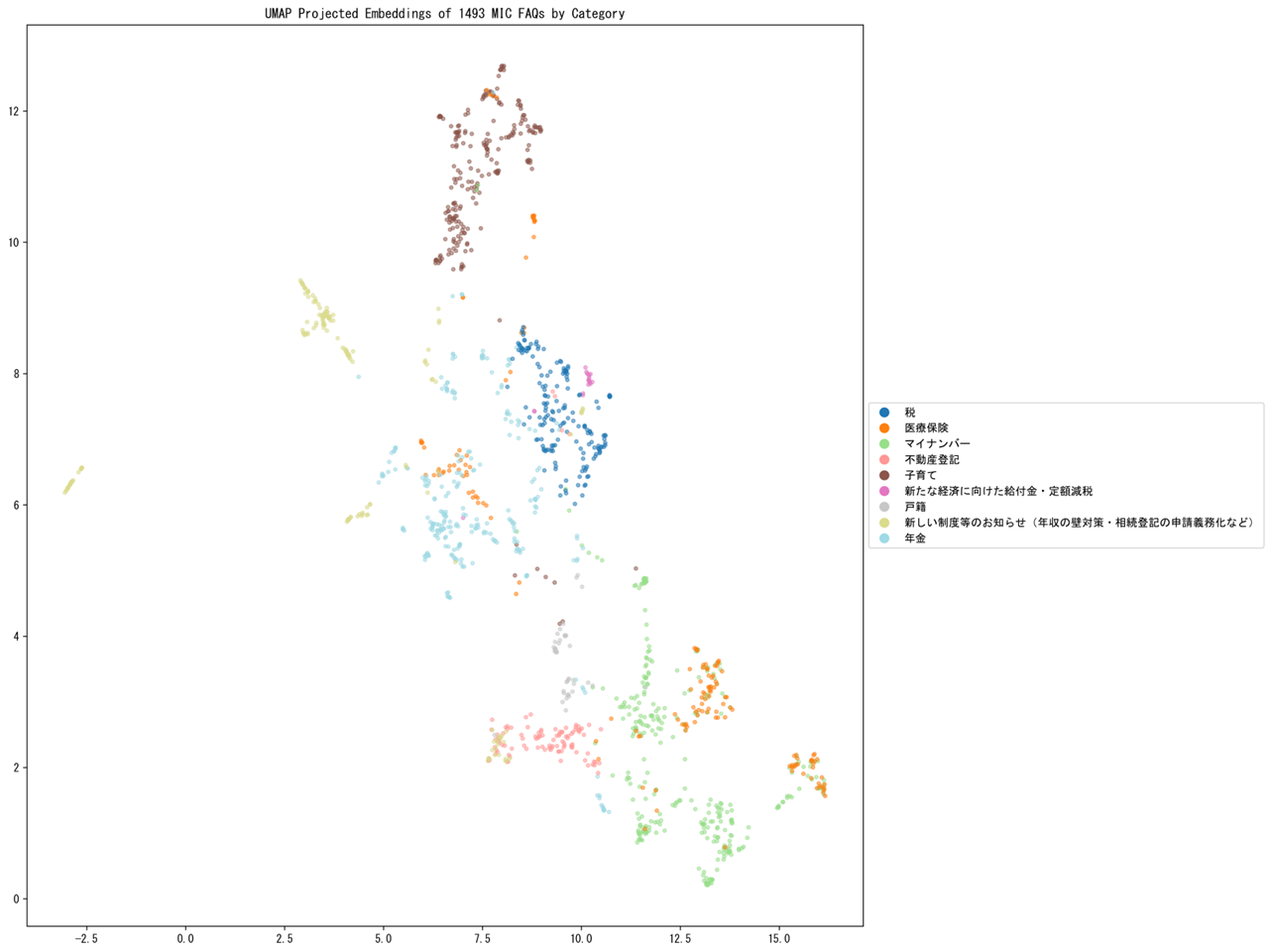
国・地方共通相談チャットボット Govbot(ガボット)に搭載されている各分野のFAQデータ(全分野)の「問い」を UMAP で次元削減(二次元へ射影)して可視化したもの
RAG を使っているかどうかに関わらず問い合わせ応答システムでは、開発者側が想定した質問と実際にユーザーが投入する質問を調べてみると当初想定していなかった質問群が含まれていることがあります。開発側は想定した質問に対する回答をLLMが生成できるようにドキュメントを用意しますが、このような乖離があると RAG システムは適切な回答を生成することができません。実際に投入された質問群をクラスター分析することでどのような質問が多く投入されているのかを知ることができ、ドキュメントの改善に関する洞察を得ることができます。
まとめ
本記事では、生成AIを企業で実用的に活用する上で重要となる埋め込み技術について、基礎から応用まで幅広く解説しました。以下に主なポイントをまとめます。
RAGと埋め込みの基礎
- RAG(検索拡張生成)は、ハルシネーション低減、社内固有知識への対応、最新情報への対応などの利点を持つ
- RAGのプロセスは「データの準備と埋め込み処理」→「ベクトル検索」→「LLMによる回答生成」の3ステップ
- 埋め込みはRAGの中核技術であり、テキストや画像などのデータをベクトル空間上の点として表現する
テキスト埋め込みの技術
- トークン化はテキストを意味のある最小単位に分割する前処理
- 静的埋め込み(Word2Vecなど)は文脈に依存しない固定された表現を生成
- Transformerベースの埋め込みは文脈を考慮した動的な表現を生成し、多義語の問題に対応
- プーリング(Mean Poolingなど)により、トークン単位の埋め込みから文書全体の埋め込みを生成
マルチモーダル埋め込み
- CLIPなどのマルチモーダル埋め込みモデルは、テキストと画像を同じベクトル空間にマッピング
- これにより、テキストによる画像検索や画像による画像検索など多様な検索が可能に
- 画像生成AI(DALL-E2など)でもCLIPの埋め込み技術が活用されている
埋め込みの応用例
- ベクトル検索による関連文書の効率的な検索
- 画像検索や画像分類
- 画像生成の制御や変化を与える操作
- 超高解像度画像の解析(Image RAG)
- 動画推薦システムにおけるコールドスタート問題の解決
埋め込み技術の理解を深めることで、より効果的なRAGシステムの構築が可能になります。静的埋め込みからTransformerベースの文脈考慮型埋め込み、そしてマルチモーダル埋め込みへと進化してきた技術は、今後も生成AIの実用化において中心的な役割を担っていくでしょう。
ぜひ、この記事で紹介した概念や技術を実際の業務に応用し、生成AIの可能性を最大限に引き出してください。
用語の整理
| 用語(英語) | 日本語 | 意味 |
|---|---|---|
| BPE | バイトペアエンコーディング | トークン化アルゴリズムの一種で、頻出する文字列のペアを繰り返し結合していくことで効率的な語彙を構築する手法(Byte Pair Encoding)。未知語や稀な単語に対応しながらも語彙サイズを抑えることができる。 |
| CLIP | クリップ | OpenAIによって開発されたマルチモーダル埋め込みモデルで、テキストと画像を同じ埋め込み空間にマッピングする(Contrastive Language-Image Pre-training)。大規模な画像-テキストペアを用いて学習され、画像検索や分類、画像生成のガイドなど幅広い用途に応用されている。 |
| Contrastive Learning | 対照学習 | 類似したデータポイントを近づけ、異なるデータポイントを遠ざけるように表現を学習する手法。マルチモーダル埋め込みモデルであるCLIPなどで使用され、異なるモダリティ間の対応関係を効果的に学習できる。関連するデータペア(正例)とそうでないペア(負例)の対比を通じて埋め込み空間の構造を形成する。 |
| Cosine Similarity | コサイン類似度 | 2つのベクトル間の類似度を測る指標で、ベクトル間のなす角のコサイン値を計算する。値が1に近いほど類似度が高く、-1に近いほど類似度が低いことを示す。埋め込みベクトル間の意味的類似性を評価するのによく使われる。 |
| Cross-Attention | 交差注意機構 | 異なる入力シーケンス間の関連性を計算する注意機構。例えば、テキスト-画像モデルにおいて、テキストの特徴が画像の特定部分にどの程度注目すべきかを決定する。画像生成モデルではテキストプロンプトと生成中の画像間の関連付けに使われる。自己注意機構が単一シーケンス内の関係性を捉えるのに対し、交差注意機構は異なるモダリティ間の関係性を捉える。 |
| Cross-lingual | クロスリンガル | 複数の言語にまたがるという意味。クロスリンガル埋め込みは、異なる言語のテキストを同じ埋め込み空間に変換し、言語間の意味的対応関係を捉えることができる技術。 |
| Embedding | 埋め込み |
1. 手法としての埋め込み 高次元データ(テキスト、画像など)を低次元の密なベクトル空間に変換したもの。意味的・概念的な関係性を保ちながら、データを効率的に表現する手法。 2. 表現としての埋め込み 上記の手法によって生成された低次元ベクトル自体も「埋め込み」と呼ばれる。深層学習によって得られた特徴ベクトルを特に「埋め込み」と呼ぶ。データの意味的・概念的関係性を保持している。また、わかりやすく埋め込みベクトル、もしくは、単にベクトルと表現されることも多い。 |
| Embedding Model | 埋め込みモデル | データを特定の次元の埋め込みベクトルに変換するために訓練された機械学習モデル。データの意味的関係を数学的空間に表現できるよう設計されている。画像、動画、音声などのテキスト以外のモーダルのデータを埋め込みベクトルへ変換するモデルもある。 |
| Embedding Space | 埋め込み空間 | 埋め込みベクトルが存在する数学的な空間。各データポイントが意味的な関係性を保ちながらマッピングされる多次元空間であり、類似したデータは空間内で近い位置に配置され、異なるデータは遠い位置に配置される。この空間内での距離や方向が意味を持ち、ベクトル演算(加算、減算、類似度計算など)を通じてデータの関係性を探索できる。 |
| Feature Vector | 特徴ベクトル | データの特徴を数値のベクトル形式で表現したもの。機械学習アルゴリズムが処理しやすいように、生データから抽出された特徴を数値化したベクトル。 |
| Hallucination | ハルシネーション | 大規模言語モデル(LLM)が事実に基づかない情報や存在しない情報を生成してしまう現象。RAGを活用することで、外部データベースからの正確な情報参照により、このような幻覚を低減することができる。 |
| Image RAG | イメージRAG | 超高解像度画像の解析に対応するため、画像をパッチに分割して埋め込みベクトル化し、ベクトルデータベースで検索してマルチモーダルLLM(VLM)に提供するRAGの画像版(Image Retrieval-Augmented Generation)。衛星画像や医療画像などの分析に活用される。 |
| Multimodal Embedding Model | マルチモーダル埋め込みモデル | 複数の種類のデータモダリティ(テキスト、画像、音声、動画など)を同一の埋め込み空間に変換できるモデル。異なるモダリティのデータ間の関係性を捉え、クロスモーダル検索や異種データ間の類似性計算などを可能にする。例えばテキストと画像を同じ埋め込み空間にマッピングすることで、テキストから関連画像を検索したり、画像の内容をテキストで説明したりすることができる。 |
| PCA | 主成分分析 | 高次元データの分散を最大化する方向(主成分)を特定し、重要な情報を保持しながらデータの次元を削減する手法(Principal Component Analysis)。埋め込みベクトルの可視化やノイズ除去などに使用される。UMAPなどと比較して線形変換であるため解釈がしやすいが、非線形な関係の保持は難しい。 |
| Pooling | プーリング | 複数の埋め込みから単一の埋め込み表現を生成する手法。Mean Pooling(平均プーリング)やCLS Token Pooling(CLSトークンプーリング)などがある。 |
| RAG | 検索拡張生成 | 外部知識源から関連情報を検索して言語モデルの生成プロセスを拡張する手法(Retrieval-Augmented Generation)。LLMの基本的な知識を活かしながら、外部データベースから検索した最新または特定領域の情報を組み合わせることで、より正確で具体的な回答を生成できる。ハルシネーション(幻覚)の低減や組織固有の知識への対応、最新情報への対応などの利点がある。 |
| Self-Attention Mechanism | 自己注意機構 | シーケンスの各要素が他のすべての要素との関連性を考慮できるようにする機構。入力シーケンス内の任意の位置の単語間の依存関係をモデル化することができ、文脈を考慮した表現の生成を可能にする。 |
| Static Embedding | 静的埋め込み | 文脈に依存せず、単語に常に同じベクトル表現を割り当てる埋め込み手法。Word2Vec、GloVe、FastTextなどの手法が該当する。計算効率が良く軽量だが、多義語の異なる意味を区別できないという制限がある。 |
| Token | トークン | テキストを処理する際の基本単位。言語モデルやNLPタスクにおいて、テキストはトークンの列として扱われる。トークンは単語、部分単語、文字、記号などの形態で表され、モデルやタスクによって定義が異なる。例えば、「富士山」は1トークンの場合もあれば、「富/士/山」のように複数のトークンに分割される場合もある。各トークンは通常、数値ID(整数)に変換されてモデルに入力される。 |
| Tokenizer | トークナイザー | テキスト(文字列)をトークンのシーケンスに変換するツールやアルゴリズム。トークナイザーはテキストを分割し、各トークンに一意のIDを割り当てる機能を持つ。また、特殊トークン(文の開始/終了、不明単語など)の追加や、トークン列の長さの調整(パディング、切り詰め)なども行う。言語モデルごとに専用のトークナイザーが設計されており、モデルの訓練と推論で同じトークナイザーを使用する必要がある。 |
| Transformer | トランスフォーマー | 自己注意機構(Self-Attention Mechanism)を中心としたニューラルネットワークアーキテクチャ。文脈を考慮した埋め込みを生成でき、BERTやGPTなどの基盤となっている。 |
| UMAP | ユーマップ | 高次元データを低次元(通常2次元か3次元)に縮約する次元削減アルゴリズム(Uniform Manifold Approximation and Projection)。データの局所的および大域的構造を保持しながら可視化するのに適している。埋め込みベクトルの可視化やクラスター分析などに使用される。 |
| unCLIP | アンクリップ | OpenAIのDALL-E2で採用されている画像生成方式で、CLIPの埋め込み空間における「テキストから画像への対応関係」を活用して画像生成を行う。CLIPのテキスト埋め込みをprior(拡散モデルなど)で画像埋め込みに変換し、その後画像デコーダーで実際の画像を生成する。 |
| Vector Database | ベクトルデータベース | 埋め込みベクトルを効率的に格納し、類似度に基づいた検索を可能にするデータベース。RAGシステムにおいて、クエリに関連する文書を高速に検索するために使用される。 |