はじめに
Oracle Database 26ai(23.26.1)から、ONNX 形式の埋め込みモデルのサイズ制限(従来は 1GB 上限)が撤廃され、multilingual-e5-large のような高性能な多言語対応モデルをデータベース内にロードできるようになりました。
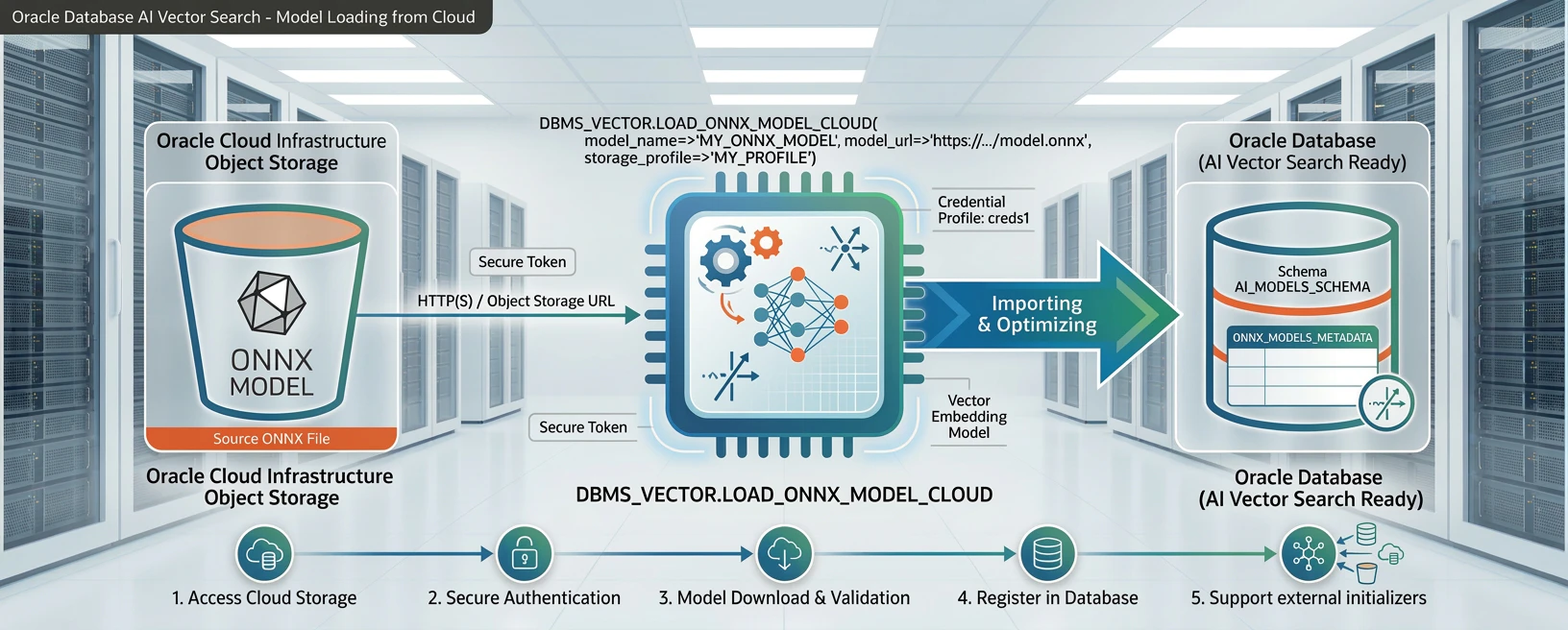
以前の記事「Oracle Autonomous Database で In-database 埋め込みモデルを使ってベクトルを生成する」では、当時の ADB(23ai)に対して LOAD_ONNX_MODEL を使う手順を紹介しました。当時は、1GB 制限のため multilingual-e5-base(約 400MB)のような比較的小さいモデルしかロードできませんでした。また、LOAD_ONNX_MODELを使っていたためモデルファイルをあらかじめ Autonomous AI Database のディレクトリへダウンロードしておく必要がありました。
今回は、従来モデルサイズが大きすぎてデータベースにロードできなかった 高性能モデル multilingual-e5-large がロードできるようになったことを確かめます。
また、 DBMS_VECTOR.LOAD_ONNX_MODEL_CLOUD プロシージャを使って、ディレクトリを経由せずにオブジェクトストレージから 直接ロード する手順を紹介します。
なお、オンプレミス版 Oracle Database 26ai での同様の検証(LOAD_ONNX_MODEL を使用)については、@ssfujita さんの記事「Oracle AI DB 26aiが高精度EmbeddingモデルのONNXインポートに対応したので試してみた」が詳しいです。本記事はその Autonomous AI Database 版+LOAD_ONNX_MODEL_CLOUD 版という位置づけです。
この記事の内容は私個人の経験・見解であり所属する企業・団体・組織を代表するものではありません。
26ai(23.26.1) で何が変わったのか
1GB 制限の撤廃(External Initializer 対応)
従来の Oracle Database では、ONNX モデルのインポートに 1GB のサイズ上限がありました。日本語など多言語に対応した高性能な埋め込みモデルは、量子化しても 1GB に収まらないことが多く、実用上課題となることがありました。
23.26.1では「External Initializer」の仕組みが導入され、モデルの重みパラメータを .onnx ファイルとは別の外部ファイルとして保持できるようになりました。これにより、従来の 1GB の上限が撤廃されると同時に Protocol Buffers の 2GB 制限を回避し、合計サイズが 2GB を超えるモデルでもロード可能になっています。
In-Memory Sharing によるメモリ効率の向上
大規模モデルではイニシャライザ(重みパラメータ)がモデルサイズの 95% 以上を占めることがあります。従来はセッションごとにイニシャライザのコピーを PGA にロードしていたため、同時利用するセッションが増えるほどメモリ消費が膨らんでいました。
23.26.1 では In-Memory Sharing 機能により、イニシャライザをグローバルメモリに一度だけロードして全セッションで共有できるようになりました。DBMS_VECTOR.INMEMORY_ONNX_MODEL(または DBMS_DATA_MINING.INMEMORY_ONNX_MODEL)で有効化できます。
LOAD_ONNX_MODEL_CLOUD
以前の記事でご紹介した LOAD_ONNX_MODEL では、ONNX モデルファイルをデータベースサーバー上のディレクトリに事前に配置する必要がありました。Autonomous AI Database の場合、これは以下のような手間を意味します。
-
CREATE ANY DIRECTORY権限の取得 - ディレクトリの作成
-
DBMS_CLOUD.GET_OBJECTによる全ファイルのダウンロード -
LOAD_ONNX_MODELの実行 - 後片付け(ディレクトリ上のファイル・ディレクトリの削除)
LOAD_ONNX_MODEL_CLOUD は、オブジェクトストレージ上の .onnx ファイルの URI を直接指定するだけでロードが完了します。ディレクトリの作成・管理が不要になり、手順が簡単になります。
環境
| 項目 | バージョン / 内容 |
|---|---|
| データベース | Oracle Autonomous AI Database (26ai) |
| OCI リージョン | ap-tokyo-1 |
| 埋め込みモデル |
intfloat/multilingual-e5-large(1024 次元) |
| 作業用サーバー OS | Oracle Linux 8(※) |
| Python | 3.13 |
| OML4Py | 2.1.1 |
※ OML4py 2.1.1 がサポートする Oracle Linux は、Ver.8 です。今回、間違って Ver 9 でテストしてしまいました。動作はしていますが、本番環境など重要な用途で利用される場合はサポートされている組み合わせを使ってください。
手順の全体像
本記事の手順は大きく以下の流れです。
| ステップ | 手順の内容 | |
|---|---|---|
| 1 | ONNX 変換 | Hugging Face のモデルを OML4Py で ONNX 形式にエクスポート |
| 2 | オブジェクトストレージへアップロード | 変換された ONNX ファイル群を OCI Object Storage へ配置 |
| 3 | ADB へのロード |
LOAD_ONNX_MODEL_CLOUD でオブジェクトストレージから直接ロード |
| 4 | ベクトル生成テスト |
VECTOR_EMBEDDING でベクトル化できることを確認 |
| 5 | In-Memory Sharing の有効化 | メモリ効率を改善 |
1. 埋め込みモデルの ONNX 変換
1.1 OML4Py 2.1.1 のセットアップ
OML4Py 2.1.1 は Oracle Machine Learning for Python Downloads からダウンロードできます。
Python 3.13 をビルドした上で、仮想環境に以下のようなパッケージをインストールしておきます。このブログでは、Python パッケージ管理と仮想環境作成には、uv を使用しています(必須ではありません)。
uv のインストール(オプション)
curl -LsSf https://astral.sh/uv/install.sh | sh
Python 仮想環境の作成(uv の場合)
mkdir -p oml4py
cd oml4py
uv venv --python 3.13
source .venv/bin/activate
Python 仮想環境の作成(uv を使わないの場合)
mkdir -p oml4py
cd oml4py
python3.13 -m venv .venv
依存パッケージのインストール
以下の内容で requirements.txt ファイルを作成します。
pandas==2.2.3
setuptools==80.8.0
scipy==1.14.1
matplotlib==3.10.0
oracledb==3.3.0
scikit-learn==1.6.1
numpy==2.1.0
pyarrow==19.0.0
protobuf<5
onnxruntime==1.20.0
onnxruntime-extensions==0.14.0
onnx==1.18.0
torch==2.9.0
transformers==4.56.1
sentencepiece==0.2.1
onnx が呼び出している protobuf は最新版(7.x 系)だとエラーが発生するため、onnx との組み合わせで実績が多い 4.x 系を指定しています。
uv pip install --upgrade -r requirements.txt --only-binary=:all:
OML4Py クライアントのインストール
OML4Py クライアントのパッケージは、Oracle Machine Learning for Python Downloads から入手できます。
unzip oml4py-client-linux-x86_64-2.1.1.zip
uv pip install client/oml-2.1.1-cp313-cp313-linux_x86_64.whl
1.2 ONNX エクスポート
この記事では埋め込みモデルとして multilingual-e5-large を使用します。
まずこのモデル用の作業ディレクトリを作成します。
mkdir -p multilingual-e5-large
cd multilingual-e5-large
OML4Py 2.1.1 では、ONNXPipeline / ONNXPipelineConfig を使って External Initializer 対応の ONNX ファイルを生成できます。
次の Python スクリプトを用意します。
from oml.utils import ONNXPipeline, ONNXPipelineConfig
config = ONNXPipelineConfig.from_template("text", max_seq_length=512, use_external_data=True)
pipeline = ONNXPipeline("intfloat/multilingual-e5-large", config)
pipeline.export2file("multilingual_e5_large", output_dir=".")
Pythonスクリプトを実行します。
uvの場合
uv run multilingual-e5-large.py
uvを使わない場合
python3.13 multilingual-e5-large.py
実行が成功すると zip ファイルが生成されます。
$ ls -al
total 2188488
drwxr-xr-x. 2 labuser oinstall 71 Mar 13 09:09 .
drwxr-xr-x. 6 labuser oinstall 4096 Mar 13 07:55 ..
-rw-r--r--. 1 labuser oinstall 275 Mar 13 07:15 multilingual-e5-large.py
-rw-r--r--. 1 labuser oinstall 2241000735 Mar 13 09:09 multilingual_e5_large.zip
zipファイルを解凍します。
$ unzip multilingual_e5_large.zip
Archive: multilingual_e5_large.zip
extracting: multilingual_e5_large_external_data.json
extracting: multilingual_e5_large_largeTensor_0.data
extracting: multilingual_e5_large_0.data
extracting: multilingual_e5_large_1.data
extracting: multilingual_e5_large.onnx
$ ls -al
total 4376972
drwxr-xr-x. 2 labuser oinstall 4096 Mar 13 09:11 .
drwxr-xr-x. 6 labuser oinstall 4096 Mar 13 07:55 ..
-rw-r--r--. 1 labuser oinstall 993251328 Mar 13 09:08 multilingual_e5_large_0.data
-rw-r--r--. 1 labuser oinstall 218103808 Mar 13 09:08 multilingual_e5_large_1.data
-rw-r--r--. 1 labuser oinstall 67234 Mar 13 09:08 multilingual_e5_large_external_data.json
-rw-r--r--. 1 labuser oinstall 1024008192 Mar 13 09:08 multilingual_e5_large_largeTensor_0.data
-rw-r--r--. 1 labuser oinstall 5569359 Mar 13 09:08 multilingual_e5_large.onnx
-rw-r--r--. 1 labuser oinstall 275 Mar 13 07:15 multilingual-e5-large.py
-rw-r--r--. 1 labuser oinstall 2241000735 Mar 13 09:09 multilingual_e5_large.zip
ONNX Pipeline API のモデルサイズ別の挙動
OML4Py の ONNX Pipeline API は、モデルサイズに応じて以下のように動作します(ドキュメント)。
| モデルサイズ | 挙動 |
|---|---|
| 1 GB 未満 | 最適なパフォーマンスでサポート |
| 1 GB 〜 2 GB(量子化あり) | 完全にサポート |
| 1 GB 〜 2 GB(量子化なし) | External Initializer を使用してエクスポート |
| 0.4 GB 〜 2 GB(量子化なし) | 量子化の使用を推奨する警告が表示される |
| 2 GB 超 | 量子化を無効にした状態でのみExternal Data を使用してサポート。量子化する場合の上限は 2 GB |
今回使用する intfloat/multilingual-e5-large は量子化前のサイズが 2 GB を超えるため、上記ルールに従い use_external_data=True(量子化なし・外部データ使用)を指定してエクスポートしています(明示的に指定しなくても自動的に使われますがドキュメンテーションも兼ねて明示しています)。1 GB 未満の小さなモデルであっても、use_external_data=True を明示的に指定すれば External Initializer 形式でエクスポートすることが可能です。
変換により multilingual_e5_large.zip(約 2.1 GB)が生成されます。展開すると以下のファイルが得られます。
| ファイル名 | サイズ | 説明 |
|---|---|---|
multilingual_e5_large.onnx |
約 5.3 MB | モデルグラフ定義 |
multilingual_e5_large_0.data |
約 947 MB | 外部イニシャライザ(重みパラメータ) |
multilingual_e5_large_1.data |
約 208 MB | 外部イニシャライザ(重みパラメータ) |
multilingual_e5_large_largeTensor_0.data |
約 976 MB | 大規模テンソルデータ |
multilingual_e5_large_external_data.json |
約 66 KB | 外部データメタデータ定義 |
.onnx ファイル自体はわずか 5.3 MB で、重みパラメータが外部ファイルに分離されていることがわかります。
2. オブジェクトストレージへの配置
ZIP ファイルと変換スクリプトを除いた ONNX 関連ファイルをオブジェクトストレージにアップロードします。ここでは、CLIを使った例をご紹介します。
# バケットの作成
oci os bucket create \
--name onnx-bucket \
--compartment-id <compartment-ocid> \
--namespace-name <namespace>
# ONNX ファイル群をアップロード
oci os object bulk-upload \
--bucket-name onnx-bucket \
--namespace-name <namespace> \
--src-dir . \
--object-prefix multilingual-e5-large/ \
--exclude "multilingual_e5_large.zip" \
--exclude "multilingual-e5-large.py"
アップロード後、以下の 5 ファイルが格納されていることを確認します。
multilingual-e5-large/multilingual_e5_large.onnx
multilingual-e5-large/multilingual_e5_large_0.data
multilingual-e5-large/multilingual_e5_large_1.data
multilingual-e5-large/multilingual_e5_large_external_data.json
multilingual-e5-large/multilingual_e5_large_largeTensor_0.data
3. Autonomous AI Database からオブジェクトストレージへのアクセス権限設定
3.1 リソースプリンシパルの設定
ADB からオブジェクトストレージにアクセスするため、ここでは、リソースプリンシパルを使用します。動的グループはあらかじめ作成されているものとします。
まず、ADB を含む動的グループに対して、バケットへの読み取り権限を付与する IAM ポリシーを作成します。
oci iam policy create \
--region us-ashburn-1 \
--compartment-id <compartment-ocid> \
--name dg-onnx-bucket-rw-policy \
--description "Grant <dynamic-group> RW access to onnx-bucket" \
--statements '[
"Allow dynamic-group <dynamic-group> to read buckets in compartment <compartment-name> where target.bucket.name='\''onnx-bucket'\''",
"Allow dynamic-group <dynamic-group> to manage objects in compartment <compartment-name> where target.bucket.name='\''onnx-bucket'\''"
]'
3.2 データベースユーザーに対するリソースプリンシパルの有効化
ADMIN ユーザーで接続し、対象ユーザーのリソースプリンシパルを有効化します。
BEGIN
DBMS_CLOUD_ADMIN.ENABLE_RESOURCE_PRINCIPAL(
username => '<db-username>'
);
END;
/
リソースプリンシパルが作成されたことを確認します。
SELECT credential_name
FROM user_credentials
WHERE credential_name = 'OCI$RESOURCE_PRINCIPAL';
4. LOAD_ONNX_MODEL_CLOUD で ONNX モデルをロード
ここが本記事の主題です。LOAD_ONNX_MODEL_CLOUD を使えば、ディレクトリの作成やファイルダウンロードといった中間手順を省略し、オブジェクトストレージ上の .onnx ファイルの URI を直接指定してロードできます(.onnx ファイルの URI を指定するだけで同じバケット/プレフィックスに配置されている他のファイルもロードされます)。
BEGIN
DBMS_VECTOR.LOAD_ONNX_MODEL_CLOUD(
model_name => 'multilingual_e5_large',
credential => 'OCI$RESOURCE_PRINCIPAL',
uri => 'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/<namespace>/b/onnx-bucket/o/multilingual-e5-large/multilingual_e5_large.onnx',
metadata => JSON('{"function":"embedding","embeddingOutput":"embedding","input":{"input":["DATA"]}}')
);
END;
/
| パラメータ | 説明 |
|---|---|
model_name |
データベース内でのモデル名 |
credential |
オブジェクトストレージへのアクセスに使うクレデンシャル名。リソースプリンシパルの場合は 'OCI$RESOURCE_PRINCIPAL'
|
uri |
.onnx ファイルのオブジェクトストレージ URI。外部イニシャライザファイル(.data、.json)は同じディレクトリに配置されていれば自動的に認識される |
metadata |
モデルの用途を指定する JSON メタデータ |
uri に指定するのは .onnx ファイルの URI のみです。_external_data.json やその他の .data ファイルは、同じオブジェクトストレージのパス上に存在していれば、LOAD_ONNX_MODEL_CLOUD が自動的に取得してくれます。
ドキュメントに記載されている 2GB 制限について
LOAD_ONNX_MODEL_CLOUD のドキュメントには "The model size is limited to 2 GB." と記載されていますが、これは 単一の .onnx ファイル(モデルグラフ定義)のサイズ上限を指しています。External Initializer を使用した場合の .data ファイルなどの外部データを含めたモデル全体の合計サイズの上限ではありません。実際、今回ロードした multilingual-e5-large は .onnx ファイル自体は約 5.3 MB ですが、外部データを含めた合計サイズは約 2.1 GB であり、問題なくロードできています(ロード後のデータベース内でのモデルサイズは約 3.3 GB)。
ロード結果の確認
SELECT MODEL_NAME, MINING_FUNCTION, ALGORITHM, ALGORITHM_TYPE,
ROUND(MODEL_SIZE/1024/1024) AS SIZE_MB
FROM user_mining_models;
MODEL_NAME MINING_FUNCTION ALGORITHM ALGORITHM_TYPE SIZE_MB
------------------------ ------------------ ------------ ----------------- -------
MULTILINGUAL_E5_LARGE EMBEDDING ONNX NATIVE 3289
約 3.3 GB のモデルがデータベース内にロードされました。
5. ベクトル生成テスト
5.1 ベクトルの生成
SELECT TO_VECTOR(
VECTOR_EMBEDDING(MULTILINGUAL_E5_LARGE USING '無詠唱魔法' AS data)
) AS embedding;
5.2 次元数と先頭要素の確認
WITH emb AS (
SELECT VECTOR_EMBEDDING(MULTILINGUAL_E5_LARGE USING '無詠唱魔法' AS data) AS vec
FROM dual
),
vals AS (
SELECT jt.idx, jt.val
FROM emb e,
JSON_TABLE(
VECTOR_SERIALIZE(e.vec RETURNING CLOB),
'$[*]'
COLUMNS (
idx FOR ORDINALITY,
val NUMBER PATH '$'
)
) jt
)
SELECT
(SELECT COUNT(*) FROM vals) AS dimension,
(SELECT JSON_ARRAYAGG(val ORDER BY idx RETURNING CLOB)
FROM vals
WHERE idx <= 5) AS first_5
FROM dual;
実行結果の例はこちらです。
DIMENSION FIRST_5
--------- -------------------------------------------------------------------
1024 [0.0379486009,0.0319504365,-0.0162661821,-0.0448859856,0.0147227719]
1024 次元のベクトルが正常に生成されることを確認できました。
6. In-Memory Sharing の有効化
大量のベクトル生成リクエストがある環境では、In-Memory Sharing を有効にすることで同時に複数のセッションで埋め込みモデルを利用する際のメモリー利用効率を向上させることができます。
6.1 External Data の確認
SELECT model_name, EXTERNAL_DATA FROM all_mining_models;
EXTERNAL_DATA が YES であることを確認します。In-Memory Sharing は External Initializer を持つモデルに対してのみ有効化できます。
6.2 有効化
EXECUTE DBMS_VECTOR.INMEMORY_ONNX_MODEL('MULTILINGUAL_E5_LARGE');
6.3 メモリ使用状況の確認
ADMIN ユーザーで確認します。
SELECT * FROM V$IM_ONNX_MODEL WHERE NAME = 'MULTILINGUAL_E5_LARGE';
OWNER NAME SLOT# POPULATE_STATUS METADATA_SIZE INITIALIZER_SIZE PREPACKED_SIZE
---------- ------------------------ ----- ---------------- ------------- ----------------- --------------
LABUSER MULTILINGUAL_E5_LARGE 0 ENABLED 227176 2235363328 1207992960
INITIALIZER_SIZE(約 2.1 GB)のイニシャライザがグローバルメモリ上に共有されています。PREPACKED_SIZE(約 1.2 GB)はランタイム用に最適化された形式のサイズです。
6.4 無効化(必要に応じて)
メモリを解放したい場合は以下を実行します。
EXECUTE DBMS_VECTOR.INMEMORY_ONNX_MODEL('MULTILINGUAL_E5_LARGE', enable => FALSE);
LOAD_ONNX_MODEL との比較
参考までに、LOAD_ONNX_MODEL を使った場合の手順を示します。Autonomous AI Database の場合、LOAD_ONNX_MODEL_CLOUD が手順を簡素化してくれることがわかります。
LOAD_ONNX_MODEL の場合に追加で必要な手順
LOAD_ONNX_MODEL を使う場合は、モデルのロード前に以下の準備が必要です。
1. ディレクトリ作成権限の付与(ADMIN で実行)
GRANT CREATE ANY DIRECTORY TO <db-username>;
2. ステージングディレクトリの作成
CREATE DIRECTORY staging AS 'stage';
3. オブジェクトストレージからファイルをダウンロード
DBMS_CLOUD.GET_OBJECT で 5 つのファイルをすべてステージングディレクトリにダウンロードする PL/SQL を書いて実行します。
4. LOAD_ONNX_MODEL の実行
BEGIN
DBMS_VECTOR.LOAD_ONNX_MODEL(
'staging',
'multilingual_e5_large.onnx',
'multilingual_e5_large',
json('{"function":"embedding","embeddingOutput":"embedding","input":{"input":["DATA"]}}')
);
END;
/
5. 後片付け
ステージングディレクトリ上のファイル削除、ディレクトリの削除、権限の後始末などが必要です。
このように、LOAD_ONNX_MODEL では権限付与 → ディレクトリ作成 → ファイルダウンロード → ロード → 後片付けという一連の手順が必要ですが、LOAD_ONNX_MODEL_CLOUD なら PL/SQL 1 ブロックで完結 します。
まとめ
| 観点 | 従来 | 現在(26ai) |
|---|---|---|
| モデルサイズ上限 | 1GB | 制限なし(External Initializer 対応) |
| ロード方法 |
LOAD_ONNX_MODEL(ステージングディレクトリ経由) |
LOAD_ONNX_MODEL_CLOUD(オブジェクトストレージから直接) |
| メモリ利用 | セッションごとに PGA にロード | In-Memory Sharing でグローバルメモリを共有 |
| 日本語対応モデル |
multilingual-e5-base 程度が限界 |
multilingual-e5-large など高性能モデルが利用可能 |
Oracle Autonomous AI Database 26ai で、モデルサイズの大きな高性能の多言語埋め込みモデルをデータベース内で手軽に利用できるようになりました。LOAD_ONNX_MODEL_CLOUD によるシンプルなロード手順と In-Memory Sharing によるメモリ効率の改善は、データの移動を極力少なくしたいセキュリティ要件の厳しい環境での RAG やベクトル検索の実用性を大きく高めるものと期待されます。
あとがき
LOAD_ONNX_MODEL_CLOUDの存在に気付いたときの私の妄想はこちらです。
お隣の天使様にLOAD_ONNX_MODEL_CLOUD を教えてもらった件
「……はぁ」
周(あまね)は深いため息をつきながら、ディスプレイに映るSQLclのコマンドラインを睨みつけていた。
Autonomous AI Databaseに埋め込みモデルをロードする。やることはわかっている。オブジェクトストレージにモデルファイルを置いて、データベース側にディレクトリオブジェクトを作って、クレデンシャルを設定して、ファイルを一つずつダウンロードして、それからLOAD_ONNX_MODELを叩く。わかっている。わかっているのだが——
「……地味にめんどくさい」
DBMS_CLOUD.GET_OBJECTでファイルを一個ずつ落としてくるのが、とにかく怠い。モデルのファイルが複数あると、その数だけ同じようなPL/SQLブロックを書くことになる。コピペして、ファイル名だけ変えて、実行して、次。コピペして、ファイル名だけ変えて、実行して、次——
「周くん、晩ごはんできましたよ。……何をそんなに難しい顔をしているのですか?」
隣の部屋からやってきた真昼(まひる)が、周の背後からディスプレイを覗き込む。ふわりと柔軟剤の良い香りがしたが、今の周にそれを意識する余裕はなかった。
「いや……Autonomous にONNXの埋め込みモデルをロードしてるんだけど、オブジェクトストレージからファイル一個ずつダウンロードして、ディレクトリに並べて、最後にLOAD_ONNX_MODELに渡すっていう手順がちまちましてて……」
「……それ、全部手動でやっているのですか?」
真昼の声のトーンが、わずかに変わった。それは周がカップ麺にお湯を入れようとしたときや、洗濯物を床に放置していたときに聞く、あの声だった。
「いや、手動っていうか、PL/SQLは書いてるけど……GET_OBJECTで一個ずつ落として、LOAD_ONNX_MODELで——」
「LOAD_ONNX_MODEL_CLOUD、使っていないんですか?」
「…………は?」
周の手がキーボードの上で止まった。
真昼は周の隣に腰を下ろすと、いつもの涼しい顔のまま淡々と説明を始めた。
「DBMS_VECTOR.LOAD_ONNX_MODEL_CLOUDです。オブジェクトストレージのURIとクレデンシャルを渡すだけで、ディレクトリの作成もファイルのダウンロードも全部すっ飛ばしてモデルをロードできます」
「…………」
「ディレクトリオブジェクトを作る必要もないですし、GET_OBJECTを何回も叩く必要もありません。クレデンシャルとオブジェクトストレージのパスを指定するだけです」
周は、自分がこの一時間ほどちまちまと書いていたPL/SQLブロックの群れを見た。ディレクトリ作成。クレデンシャル設定。GET_OBJECT、GET_OBJECT、GET_OBJECT。そしてようやくLOAD_ONNX_MODEL。
それが、一つのプロシージャで済む、と。
「…………先に言ってくれ」
「先にって、周くんが何をしているか知らなかったので言いようがないです。というか、ドキュメントに書いてありますよ?」
正論だった。あまりにも正論だったので、周は何も言い返せなかった。
「……ドキュメント、読んでなかった」
「知ってます」
真昼は小さくため息をつくと、立ち上がった。
「ごはん、冷めますよ。書き直すのは食べてからにしてください」
「……はい」
素直に従う周の背中に、真昼の声が降ってきた。
「それから、クレデンシャルはちゃんとリソースプリンシパルを使うのですよ——あと、Oracle Databaseのドキュメントは、ちゃんと読んだほうがいいですよ。周くん、いつも検索で最初に出て来た記事を鵜呑みにしてるでしょ」
図星だった。
※佐伯さん著「お隣の天使様にいつの間にか駄目人間にされていた件」(GA文庫)のキャラクターをお借りした二次創作です。
※この記事は、個人的な趣味で投稿しているもので所属する企業・組織・団体とは無関係です。
参考リンク
- Oracle AI Database New Features - ONNX Support
- DBMS_VECTOR - LOAD_ONNX_MODEL_CLOUD
- LOAD_ONNX_MODEL_CLOUD リファレンス(Oracle AI Vector Search User's Guide)
- About ONNX - External Initializers and In-Memory Sharing
- Support For Large ONNX Format Model(OML4Py)
- OML4Py 2.1.1 ダウンロード
- Oracle Autonomous Database で In-database 埋め込みモデルを使ってベクトルを生成する(前回記事)
- Oracle AI DB 26aiが高精度EmbeddingモデルのONNXインポートに対応したので試してみた(@ssfujita さんの記事)