本書では、無償で利用できるDatabricks Community Editionを使ってDatabricksの基本的な機能をウォークスルーします。GUIなどが更新されているので、2022/8/3時点のGUIで説明をしていきます。
後半で使用しているノートブックはこちらです。
Databricksとは
データブリックスは、学術界とオープンソースコミュニティをルーツとするデータ+AIの企業です。Apache Spark™、Delta Lake、MLflowの開発者グループによる2013年の創業以来、最新のレイクハウスアーキテクチャを基盤に、データウェアハウスとデータレイクの優れた機能を取り入れた、データとAIのためのクラウドベースのオープンな統合プラットフォームを提供しています。
このレイクハウスプラットフォームをご利用いただくことで、機械学習モデルのトレーニングはもちろん、機械学習モデルの運用管理、ETLパイプラインの開発・運用、データの蓄積、BIなど様々なワークロードを一つのプラットフォーム上で効率的に実施いただけるようになります。
Databricks Community Editionとは
Databricksではその機能を無償でお試しいただけるよう、2通りの方法を用意しております。
- 2週間の無償トライアル: Databricksのすべての機能を2週間無償でお試しいただけます。
- Community Edition: 利用できる機能が限定されますが、期限なし・無償でご利用いただけます。
本記事では、Community Editionを通じて、Databricksの基本的な機能を体験いただきます。
Databricks Community Editionへのサインアップ
以下のステップを実行することで、Databrikcs Community Editionのワークスペースを無料で利用できるようになります。
-
https://databricks.com/jp/try-databricks にアクセスします。

- フォームに必要情報を入力し、無料トライアルを開始をクリックします。
-
コミュニティ版を使ってみるのリンクをクリックします。

-
検証ダイアログが表示される場合には指示に従って検証を受けます。

- 確認メールが送信された旨の画面が表示されます。

- 最初に指定したメールアドレスに確認メールが届いていない確認します。場合によっては迷惑メールと判別されることがあるため、メーワクメールのフォルダも確認します。メールに記載されているGet started by visitingのリンクをクリックします。

- パスワードを設定する画面が表示されるので、パスワードを指定してパスワードをリセットをクリックします。以降、Databricks Community Editionにログインする際には、Community EditionのURL https://community.cloud.databricks.com/ とメールアドレス、パスワードが必要となります。

- これでDatabricks Community Editionへのログインが完了しました。

Databricksのウォークスルー
Databricks Community Editionの画面構成
Databricksでは、ノートブック上にロジックを記述してそれを実行することで様々な処理を行います。この観点ではJuypter notebookと非常に近いUIを持っていると言えます。しかし、様々な点で強化・拡張がなされているのがDatabricksです。
画面の左側のサイドメニューにマウスカーソルを移動するとメニューが展開されます。基本的な機能にはこちらからアクセスすることになります。

各項目については、以下の参考資料をご覧ください。ここでは、クラスターを作成するためにメニューからクラスターをクリックします。
クラスターの作成
クラスターとは、機械学習モデルのトレーニングやデータの加工を行う際に必要となる計算資源です。Databricksでは大量のデータを高速に処理できるように複数の仮想マシンをまとめてクラスターとして構成します。Databricksクラスターを用いることで、従来であれば手間のかかる環境構築(仮想マシンの設定、ソフトウェアのインストールなど)をGUIからの操作で手軽に行えるようになります。
-
クラスターの一覧が表示されます。この時点ではクラスターは存在していないため一覧は空の状態です。左上にあるクラスターの作成ボタンをクリックします。

-
この画面で作成するクラスターの設定を行います。ここでは、クラスター名とDatabricks Runtimeのバージョンを指定します。
- クラスター名: taka clusterなど人が見てわかりやすい名前を指定してください。
-
Databricks Runtimeのバージョン: Databricks Runtimeとはクラスターに自動でインストールされるソフトウェアのパッケージです。Pythonの実行環境やPythonライブラリなどが含まれています。ここでは、
Runtime 10.5 MLを選択します。

-
クラスターを作成をクリックするとクラスターが作成されます。クラスターが作成され、起動するまでに数分要しますのでお待ちください。作成が完了するとクラスター名の右側に緑のチェックマーク入りのアイコンが表示されます。

ノートブックの作成
次に、ロジックを記述するノートブックを作成します。
- サイドメニューのワークスペースをクリックします。ワークスペースは名前の通り、皆様の作業場でありノートブックを格納する場所となります。

- ワークスペース配下にはSharedとUsersというフォルダが存在しています。Sharedはワークスペース内で他のユーザーとノートブックを共有するための置き場所として使用します。Usersはそれぞれのユーザーごとのホームフォルダが格納されています。
- ホームフォルダにノートブックを作成するのでホームボタンをクリックして、自分のホームフォルダに移動します。

- ホームフォルダは自分のメールアドレスの名称となっています。ここにフォルダを作成したり、ノートブックを格納することになります。

- ホームフォルダ名(自分のメールアドレス)の右にある下向きの矢印をクリックします。

- メニューが表示されるので作成 > ノートブックを選択します。

- ダイアログが表示されます。以下の内容を指定して、作成をクリックします。
- 名前: わかりやすいノートブックの名前をつけます。
- デフォルト言語: Pythonのままとします。なお、SQL、Rなど他の言語を指定することもできます。
-
クラスター: 上のステップで作成、起動したクラスターを選択します。

- これでノートブックが作成されるのと同時に、ノートブックがクラスターに関連づけ(アタッチ)されます。アタッチされているクラスターは画面左上のリストで確認することができます。ノートブックの処理を実行するには稼働中のクラスターにアタッチする必要があります。編集のみを行う際にはクラスターは不要です。

ティップス
フルバージョンのDatabricksではフォルダやノートブックなどにアクセス権を設定できるので、ユーザー間でセキュアに資産のやり取りを行うことができます。
ノートブックの実行
すでにノートブックが表示されていますので、Juypter notebookを使うのと同様にPythonの処理を記述、実行することができます。
-
一つ目のセルにカーソルを移動し、以下の内容を記述します。
Pythonprint("test") -
セルを実行するにはいくつかの方法がありますが、ここではセルの右端に表示されているメニューから実行します。再生ボタンをクリックするとメニューが展開されます。

-
▶︎セルを実行をクリックすると当該セルが実行されます。

-
以下のように結果が表示されます。

ティップス
上に表示されているように、Shift+Enterキーを押してもセルを実行することができます。
新たにセルを追加するには、追加したい場所にカーソルを移動すると+マークが表示されるのでこれをクリックすることでセルの上下に追加することができます。


Databricksで機械学習を体験してみる
最後にDatabricksでの機械学習を体験してみます。
ノートブックのインポート
上ではノートブックを作成しましたが、インターネットで公開されているノートブックなどを簡単に取り込むこともできます。
-
サイドメニューのワークスペースをクリックします。
-
ホームボタンをクリックして、自分のホームフォルダに移動します。
-
ホームフォルダ名(自分のメールアドレス)の右にある下向きの矢印をクリックします。
-
メニューが表示されるのでインポートを選択します。

-
ダイアログが表示されます。以下を指定してインポートをクリックします。
インポート元:
URLを選択します。
テキストボックス: 以下のURLを貼り付けます。https://raw.githubusercontent.com/taka-yayoi/public_repo/main/mlflow_ce/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%82%AF%E3%82%A4%E3%83%83%E3%82%AF%E3%82%B9%E3%82%BF%E3%83%BC%E3%83%88%3A%20%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AE%E3%83%88%E3%83%AC%E3%83%BC%E3%83%8B%E3%83%B3%E3%82%B0(CE).py
-
以下のようにノートブックがインポートされます。
-
画面左上で上のステップで作成したクラスターを選択します。
ノートブックを実行
インポートしたノートブックに記載の指示に従ってノートブックを実行してください。
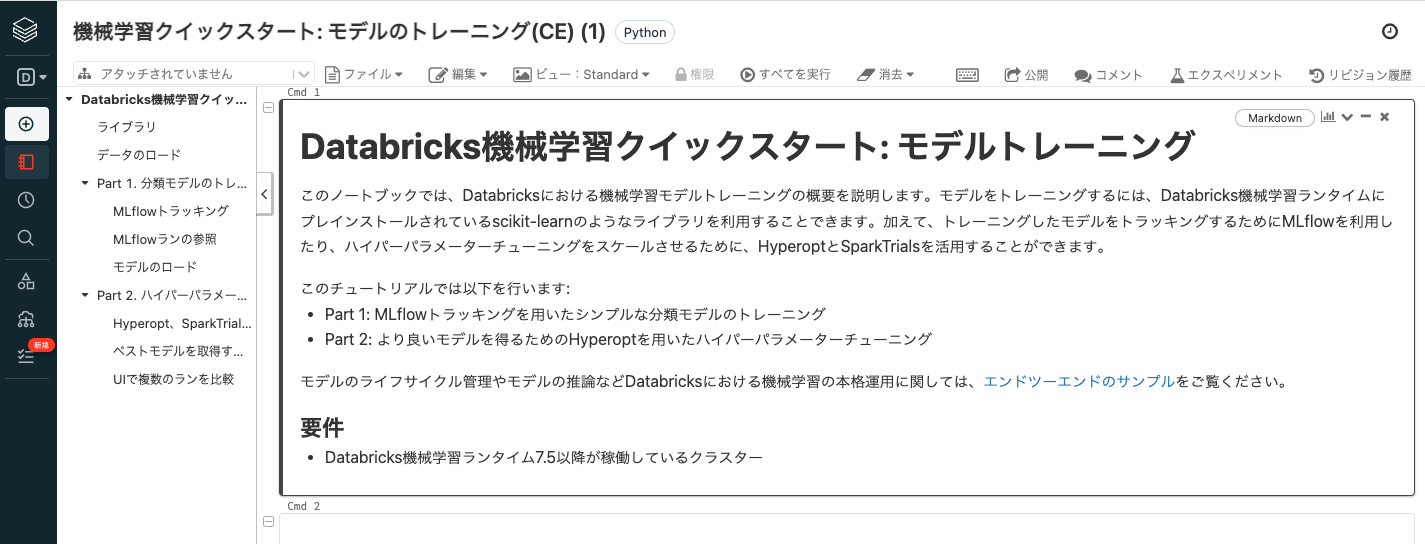
このノートブックでは、Databricksにおける機械学習モデルトレーニングの概要を説明します。モデルをトレーニングするには、Databricks機械学習ランタイムにプレインストールされているscikit-learnのようなライブラリを利用することできます。加えて、トレーニングしたモデルをトラッキングするためにMLflowを利用したり、ハイパーパラメーターチューニングをスケールさせるために、HyperoptとSparkTrialsを活用することができます。
このチュートリアルでは以下を行います:
- Part 1: MLflowトラッキングを用いたシンプルな分類モデルのトレーニング
- Part 2: より良いモデルを得るためのHyperoptを用いたハイパーパラメーターチューニング
モデルのライフサイクル管理やモデルの推論などDatabricksにおける機械学習の本格運用に関しては、エンドツーエンドのサンプルをご覧ください。
ライブラリのインポート
必要なライブラリをインポートします。これらのライブラリはDatabricks機械学習ランタイムにプレインストールされており、互換性とパフォーマンスに関してチューニングされています。
import mlflow
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
データのロード
このチュートリアルでは、異なるワインのサンプルからなるデータセットを使用します。このデータセットは、UCI Machine Learning Repositoryからのもので、DBFSに格納されています。ここでのゴールは、品質に基づいて赤ワイン・白ワインを分類するというものです。
他のデータソースからデータをアップロード、ロードする方法の詳細に関しては、データの取り扱いに関するドキュメント(AWS|Azure)をご覧ください。
以下のコマンドはCommunity Editionの制限に対応するためのものです。詳細はこちらのよくある質問を参照ください。
dbutils.fs.cp('dbfs:/databricks-datasets/wine-quality/winequality-white.csv', 'file:/tmp/winequality-white.csv')
dbutils.fs.cp('dbfs:/databricks-datasets/wine-quality/winequality-red.csv', 'file:/tmp/winequality-red.csv')
# データのロード、前処理
white_wine = pd.read_csv("/tmp/winequality-white.csv", sep=';')
red_wine = pd.read_csv("/tmp/winequality-red.csv", sep=';')
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# ワイン品質に基づく分類ラベルの定義
data_labels = data_df['quality'] >= 7
data_df = data_df.drop(['quality'], axis=1)
# 80/20でトレーニング、テストデータセットに分割
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
Part 1. 分類モデルのトレーニング
MLflowトラッキング
機械学習のライフサイクルを管理するソフトウェアであるMLflowのMLflowトラッキングを用いることで、お使いの機械学習トレーニングのコード、パラメーター、モデルを整理することができます。
autologgingを用いることで、自動MLflowトラッキングを有効化することができます。
# このノートブックにおけるMLflowオートロギングを有効化
mlflow.autolog()
次に、MLflowランのコンテキストで分類器をトレーニングし、トレーニングしたモデル、関連するメトリクス、パラメーターを自動で記録します。
モデルのAUCスコアやテストデータセットのような追加メトリクスを記録することもできます。
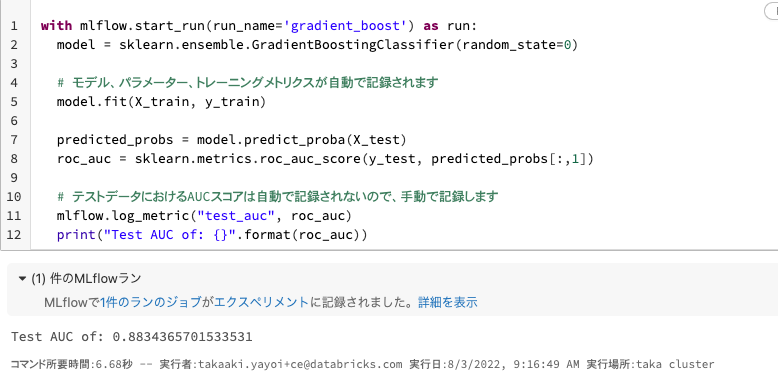
with mlflow.start_run(run_name='gradient_boost') as run:
model = sklearn.ensemble.GradientBoostingClassifier(random_state=0)
# モデル、パラメーター、トレーニングメトリクスが自動で記録されます
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
# テストデータにおけるAUCスコアは自動で記録されないので、手動で記録します
mlflow.log_metric("test_auc", roc_auc)
print("Test AUC of: {}".format(roc_auc))
上のセルを実行すると、モデルのトレーニングが行われるのと同時に機械学習モデルがMLflowによって記録されます。
画面右上のエクスペリメントに1というバッジが表示されているかと思います。こちらをクリックすることで記録されたモデルを確認することができます。
このモデルのパフォーマンスに満足できないのであれば、異なるハイパーパラメータを指定して別のモデルをトレーニングします。
# 後で参照できるようにrun_nameを指定して新たなランを実行します
with mlflow.start_run(run_name='gradient_boost') as run:
model_2 = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
# n_estimatorsに対して新たなパラメーターを指定してみます
n_estimators=200,
)
model_2.fit(X_train, y_train)
predicted_probs = model_2.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric("test_auc", roc_auc)
print("Test AUC of: {}".format(roc_auc))
記録されたモデルの数でバッジが更新されます。

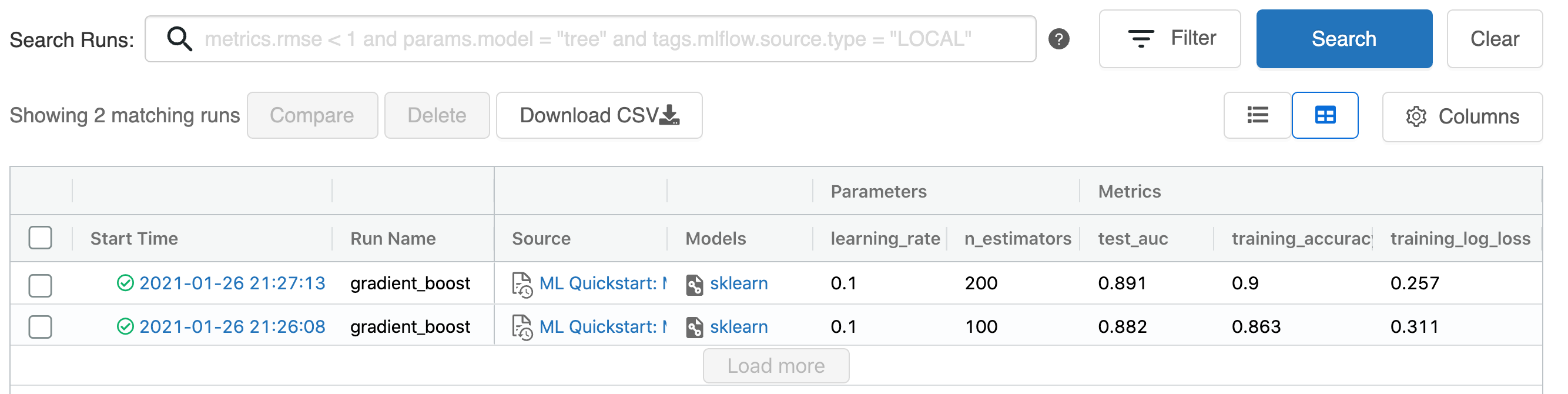
MLflowランの参照
記録されたトレーニングランを参照するには、エクスペリメントサイドバーを表示するために、ノートブックの右上のエクスペリメントアイコンをクリックします。必要であれば、最新の状態を表示するためにリフレッシュアイコンをクリックします。
より詳細なMLflowエクスペリメントページ(AWS|Azure)を表示するために、エクスペリメントページアイコン(右上矢印のアイコン)をクリックすることができます。このページでは、ランを比較したり、特定のランの詳細を参照できます。
モデルのロード
MLflow APIを用いて特定のランの結果にアクセスすることもできます。以下のセルのコードでは、特定のMLflowランにおいてトレーニングされたモデルをロードして予測を行う方法を示しています。MLflowランページで特定のモデルをロードするためのコードスニペットを参照することもできます。
# モデルが記録された後は、別のノートブックやジョブからロードすることができます
# mlflow.pyfunc.load_modelを用いることで一般的なAPIを用いたモデルの予測が可能になります
model_loaded = mlflow.pyfunc.load_model(
'runs:/{run_id}/model'.format(
run_id=run.info.run_id
)
)
predictions_loaded = model_loaded.predict(X_test)
predictions_original = model_2.predict(X_test)
# ロードしたモデルはオリジナルと一致しなくてはなりません
assert(np.array_equal(predictions_loaded, predictions_original))
Part 2. ハイパーパラメーターチューニング
ここまでで、あなたはシンプルなモデルをトレーニングし、あなたの作業を整理するためにMLflowサービスを使用しました。このセクションでは、Hyperoptを用いてどのように洗練されたチューニングを行うのかをカバーします。
Hyperopt、SparkTrialsによる並列トレーニング
HyperoptはハイパーパラメーターチューニングのためのPythonライブラリです。DatabricksにおけるHyperoptの詳細に関してはドキュメントを参照ください。
並列でハイパーパラメーターの探索、複数のモデルのトレーニングを実行するために、HyperoptとSparkTrialsを活用することができます。これにより、モデルのパフォーマンス最適化に必要な時間を短縮することができます。MLflowトラッキングはHyperoptとインテグレーションされているので、モデルとパラメーターを自動で記録します。
注意
Community Editionのクラスターで以下を実行すると約7分かかります。速度を上げるにはクラスター構成のノード数を増やし(フルバージョンのDatabricksでは可能です)、並列度を上げるといった対策が可能です。
# 探索する検索空間を定義
search_space = {
'n_estimators': scope.int(hp.quniform('n_estimators', 20, 1000, 1)),
'learning_rate': hp.loguniform('learning_rate', -3, 0),
'max_depth': scope.int(hp.quniform('max_depth', 2, 5, 1)),
}
def train_model(params):
# ワーカーごとにautologgingを有効化
mlflow.autolog()
with mlflow.start_run(nested=True):
model_hp = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
**params
)
model_hp.fit(X_train, y_train)
predicted_probs = model_hp.predict_proba(X_test)
# テストデータセットのAUCに基づくチューニング
# 実運用の環境においては、別に検証用データセットを用いることになるかもしれません
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric('test_auc', roc_auc)
# 損失関数を-1*auc_scoreに設定し、fminがauc_scoreを最大化するようにします
return {'status': STATUS_OK, 'loss': -1*roc_auc}
# SparkTrialsは、Sparkのワーカーを用いてチューニングを分散します
# 並列度を上げれば処理速度を向上しますが、それぞれのハイパーパラメーターのトライアルは他のトライアルから得られる情報が減ります
# 小規模クラスターやDatabricksコミュニティエディションではparallelism=2を設定するようにしてください
spark_trials = SparkTrials(
parallelism=8
)
with mlflow.start_run(run_name='gb_hyperopt') as run:
# 最大のAUCを達成するパラメーターを見つけるためにhyperoptを使用します
best_params = fmin(
fn=train_model,
space=search_space,
algo=tpe.suggest,
max_evals=32,
trials=spark_trials)
上を実行している時点で画面右上のエクスペリメントをクリックすると、大量のモデルが記録されていることがわかります。大量のモデルをトレーニングしたとしても、MLflowが自動で管理してくれるので、データサイエンティストの方はモデルのトレーニングに集中することができます。

ベストモデルを取得するためにランを検索
すべてのラン(MLflowにおいて1回の機械学習モデルトレーニングを指します)はMLflowによってトラッキングされているので、MLflowのsearch runs APIを用いて、最も高いAUCを出したベストのモデルのメトリクスとパラメーターを取得することができます。
チューニングされたモデルは、Part 1でトレーニングしたシンプルなモデルよりも高いパフォーマンスを示すべきです。
# テストデータセットにおけるAUCでランをソートします。同じ順位の場合には最新のランを採用します
best_run = mlflow.search_runs(
order_by=['metrics.test_auc DESC', 'start_time DESC'],
max_results=10,
).iloc[0]
print('Best Run')
print('AUC: {}'.format(best_run["metrics.test_auc"]))
print('Num Estimators: {}'.format(best_run["params.n_estimators"]))
print('Max Depth: {}'.format(best_run["params.max_depth"]))
print('Learning Rate: {}'.format(best_run["params.learning_rate"]))
best_model_pyfunc = mlflow.pyfunc.load_model(
'runs:/{run_id}/model'.format(
run_id=best_run.run_id
)
)
best_model_predictions = best_model_pyfunc.predict(X_test[:5])
print("Test Predictions: {}".format(best_model_predictions))

複数のランをUIで比較
Part 1と同じように、エクスペリメントサイドバーの上にある外部リンクアイコンからアクセスできるMLflowエクスペリメント詳細ページでランを参照、比較することができます。
エクスペリメント詳細ページで、親のランを展開するために"+"アイコンをクリックし、親以外の全てのランを選択、比較をクリックします。

下2行のランはハイパーパラメーターチューニングでトレーニングしたものではないので、チェックは外すようにしてください。

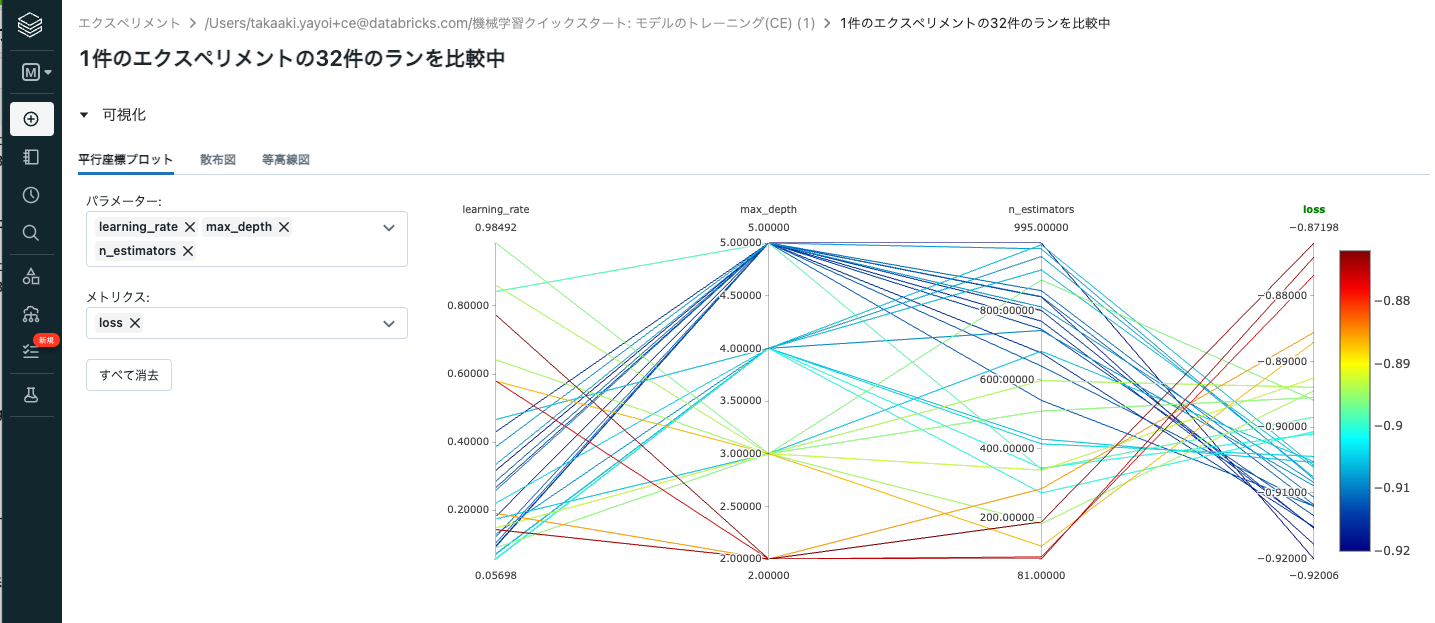
それぞれのパラメーターのメトリックに対するインパクトを表示するparallel coordinates plotを用いて、異なるランを可視化することができます。
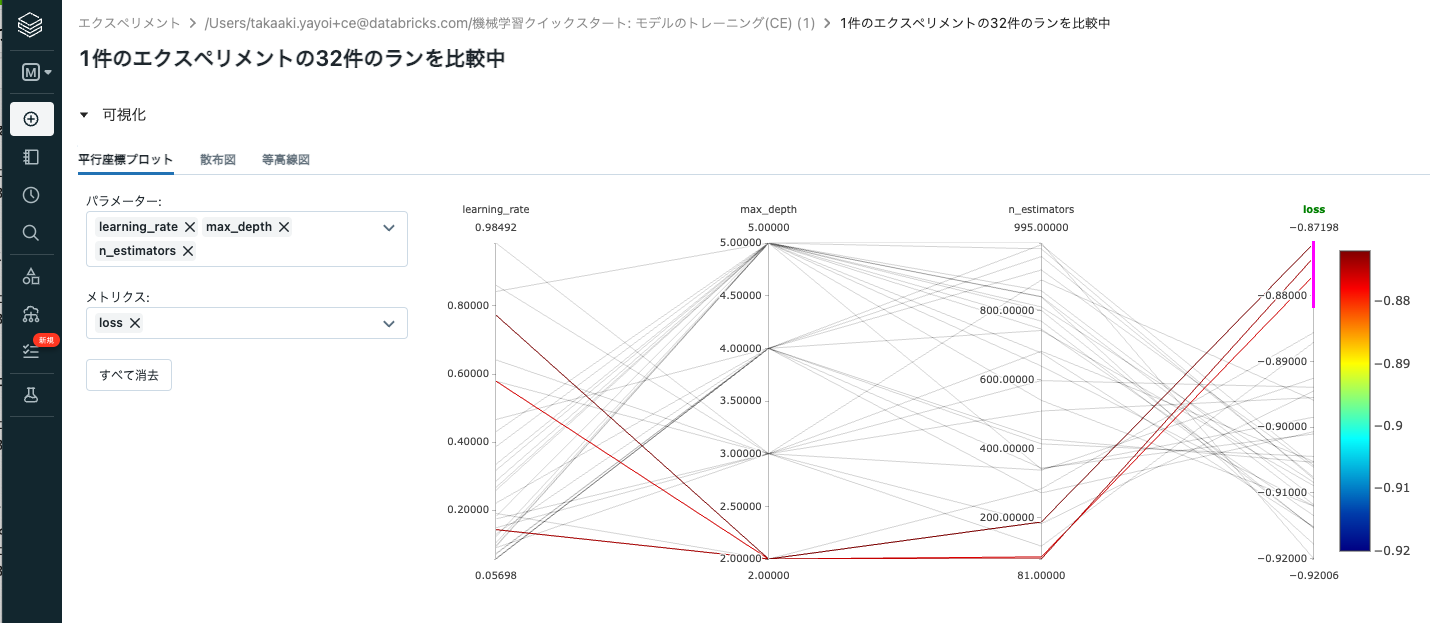
グラフの一番右のlossの軸で範囲を選択するとその部分のlossを導き出したハイパーパラメーターの組み合わせがハイライトされます。これによって、今後精度を高めていくためにはどのようなハイパーパラメーターを探索していったらいいのかの方向性を見極めることが可能となります。
まとめ
今回は、Databricks Community Edition上でscikit-learnを用いた機械学習モデルのトレーニングおよびトラッキング、ハイパーパラメータチューニングを体験いただきました。
もちろん、Databricksではこれ以外にも様々な機能を提供しています。興味のある方は以下の記事を参照してみてください。
参考資料
- Databricksチュートリアル
- Databricks Community Editionで画像データを分析してみる
- 無料のDatabricks Community EditionでSpark NLPを使って自然言語処理をやってみる
- Databricks Community EditionはDatabricksと何が違うのか?
- Databricksクイックスタートガイド
- Databricks記事のまとめページ