End-to-end example of building machine learning models on Databricks | Databricks on AWS [2021/6/28時点]の翻訳および、サンプルノートブックの説明を記載しています。
実世界における機械学習は複雑で扱いにくいものです。データソースには欠損値や重複した行が含まれ、あるいはメモリーにデータが乗り切らない場合もあります。特徴量エンジニアリングは多くのケースでドメイン知識を必要とし、手間がかかるものです。モデル構築は、データサイエンスとシステムエンジニアリングの組み合わせとなり、アルゴリズムの知識だけでなく、マシンのアーキテクチャや分散システムの知識も必要となります。
Databricksはこのプロセスをシンプルにします。以下の10分チュートリアルノートブックでは、表形式のデータに対する機械学習トレーニングのエンドツーエンドの例を示します。このノートブックをインポートして、必要に応じてコードを変更することができます。
紹介動画
要件
このノートブックには、Databricksランタイム 6.5 ML以降が必要です。
全体の流れ
- データのインポート
- Seabornとmatplotlibによるデータの可視化
- データセットに対して機械学習モデルをトレーニングする際、ハイパーパラメーター探索を並列実行
- MLflowによるハイパーパラメーター探索結果の確認
- ベストモデルをMLflowに登録
- Spark UDFを用いて登録済みモデルを別のデータセットに適用
- 低レーテンシーリクエストに対応するためのモデルサービング
この例では、ワインの物理化学的特性に基づいて、ポルトガルの"Vinho Verde"ワインの品質を予測するモデルを構築します。
この例では、UCI機械学習リポジトリのデータModeling wine preferences by data mining from physicochemical properties [Cortez et al., 2009]を活用します。
各ステップの説明
データのインポート
サンプルデータからpandasデータフレームにデータを読み込みます。
import pandas as pd
white_wine = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-white.csv", sep=";")
red_wine = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-red.csv", sep=";")
ワインが赤ワインか白ワインかを示すis_redカラムを追加して、二つのデータフレームを一つのデータセットにマージします。
red_wine['is_red'] = 1
white_wine['is_red'] = 0
data = pd.concat([red_wine, white_wine], axis=0)
# カラム名から空白を削除
data.rename(columns=lambda x: x.replace(' ', '_'), inplace=True)
データの可視化
モデルをトレーニングする前に、Seaborn、matplotlibを用いてデータを可視化します。いわゆる探索的データ分析(EDA)です。
目的変数のqualityのヒストグラムをプロットします。
import seaborn as sns
sns.distplot(data.quality, kde=False)
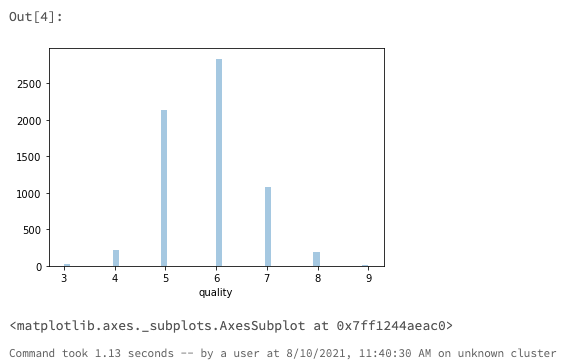
qualityは3から9に正規分布しているように見えます。ここでは、問題をシンプルにするためにquality >= 7のワインを高品質と定義し、2値分類問題にします。
high_quality = (data.quality >= 7).astype(int)
data.quality = high_quality
特徴量(説明変数)と2値ラベル(目的変数)の間の相関を見るにはボックスプロットが有用です。
import matplotlib.pyplot as plt
dims = (3, 4)
f, axes = plt.subplots(dims[0], dims[1], figsize=(25, 15))
axis_i, axis_j = 0, 0
for col in data.columns:
if col == 'is_red' or col == 'quality':
continue # カテゴリ変数にボックスプロットは使用できません
sns.boxplot(x=high_quality, y=data[col], ax=axes[axis_i, axis_j])
axis_j += 1
if axis_j == dims[1]:
axis_i += 1
axis_j = 0
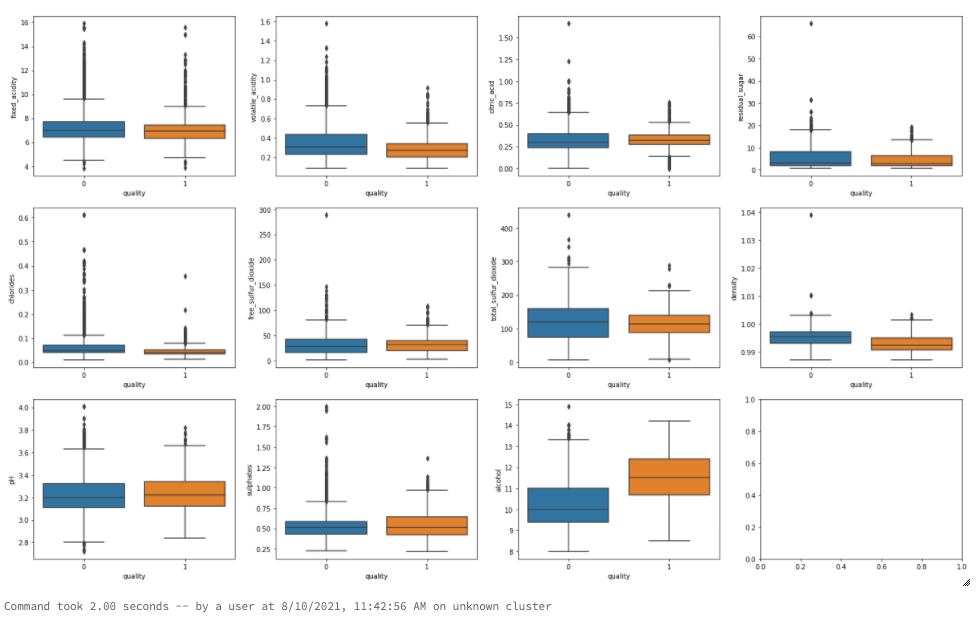
上のボックスプロットから、いくつかの変数がqualityに対する単変量予測子として優れていることがわかります。
- alcoholのボックスプロットにおいては、高品質ワインのアルコール含有量の中央値は、低品質のワインの75%パーセンタイルよりも大きな値となっています。
- densityのボックスプロットにおいては、低品質ワインの密度は高品質ワインよりも高い値を示しています。密度は品質と負の相関があります。
データの前処理
モデルのトレーニングの前に、欠損値のチェックを行い、データをトレーニングデータとバリデーションデータに分割します。
data.isna().any()
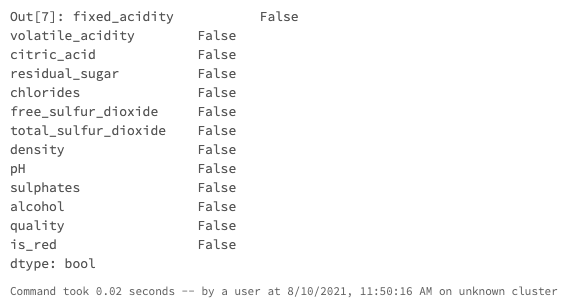
今回のケースでは欠損値はありませんでした。
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, random_state=123)
X_train = train.drop(["quality"], axis=1)
X_test = test.drop(["quality"], axis=1)
y_train = train.quality
y_test = test.quality
ベースラインモデルの構築
目的変数が2値であり、複数の変数間での相互関係がある可能性があることから、このタスクにはランダムフォレスト分類器が適しているように見えます。
以下のコードでは、scikit-learnを用いてシンプルな分類器を構築します。モデルの精度を追跡するためにMLflowを用い、後ほど利用するためにモデルを保存します。
import mlflow
import mlflow.pyfunc
import mlflow.sklearn
import numpy as np
import sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
import cloudpickle
import time
# sklearnのRandomForestClassifierのpredictメソッドは、2値の分類結果(0、1)を返却します。
# 以下のコードでは、それぞれのクラスに属する確率を返却するpredict_probaを用いる、ラッパー関数SklearnModelWrapperを構築します。
class SklearnModelWrapper(mlflow.pyfunc.PythonModel):
def __init__(self, model):
self.model = model
def predict(self, context, model_input):
return self.model.predict_proba(model_input)[:,1]
# mlflow.start_runは、このモデルのパフォーマンスを追跡するための新規MLflowランを生成します。
# コンテキスト内で、使用されたパラメーターを追跡するためにmlflow.log_param、精度のようなメトリクスを追跡するために
# mlflow.log_metricを呼び出します。
with mlflow.start_run(run_name='untuned_random_forest'):
n_estimators = 10
model = RandomForestClassifier(n_estimators=n_estimators, random_state=np.random.RandomState(123))
model.fit(X_train, y_train)
# predict_probaは[prob_negative, prob_positive]を返却するので、出力を[:, 1]でスライスします。
predictions_test = model.predict_proba(X_test)[:,1]
auc_score = roc_auc_score(y_test, predictions_test)
mlflow.log_param('n_estimators', n_estimators)
# メトリックとしてROC曲線のAUCを使用します。
mlflow.log_metric('auc', auc_score)
wrappedModel = SklearnModelWrapper(model)
# モデルの入出力スキーマを定義するシグネチャをモデルとともに記録します。
# モデルがデプロイされた際に、入力を検証するためにシグネチャが用いられます。
signature = infer_signature(X_train, wrappedModel.predict(None, X_train))
# MLflowにはモデルをサービングする際に用いられるconda環境を作成するユーティリティが含まれています。
# 必要な依存関係がconda.yamlに保存され、モデルとともに記録されます。
conda_env = _mlflow_conda_env(
additional_conda_deps=None,
additional_pip_deps=["cloudpickle=={}".format(cloudpickle.__version__), "scikit-learn=={}".format(sklearn.__version__)],
additional_conda_channels=None,
)
mlflow.pyfunc.log_model("random_forest_model", python_model=wrappedModel, conda_env=conda_env, signature=signature)
サ二ティチェックとして、モデルによって出力される特徴量の重要度を確認します。
feature_importances = pd.DataFrame(model.feature_importances_, index=X_train.columns.tolist(), columns=['importance'])
feature_importances.sort_values('importance', ascending=False)

先ほどボックスプロットで見たように、品質を予測するのにアルコールと密度が重要であることがわかります。ここまでのトレーニングには問題はないようです。
上のコードを実行することで、MLflowにモデルのROC曲線のAUCを記録しました。右上のExperimentをクリックして、エクスペリメントランのサイドバーを表示します。
このモデルはAUC0.89を達成しました。
ランダムな分類器のAUCは0.5となり、それよりAUCが高いほど優れていると言えます。詳細は、Receiver Operating Characteristic Curveを参照ください。
MLflowモデルレジストリにモデルを登録
モデルレジストリにモデルを登録することで、Databricksのどこからでもモデルを容易に参照できるようになります。
以下のセクションでは、どのようにプログラム上から操作をするのかを説明しますが、UIを用いてモデルを登録することもできます。"Create or register a model using the UI" (AWS|Azure)を参照ください。
MLflowのAPIを用いて、先ほどトレーニングしたモデルのIDを取得します。
run_id = mlflow.search_runs(filter_string='tags.mlflow.runName = "untuned_random_forest"').iloc[0].run_id
モデルのIDを用いて、モデルレジストリにモデルを登録します。
# モデルレジストリにモデルを登録します
model_name = "wine_quality_taka"
model_version = mlflow.register_model(f"runs:/{run_id}/random_forest_model", model_name)
# モデル登録に数秒を要するので、待ち時間を挿入します。
time.sleep(15)

Modelsページでモデルを確認できるはずです。Modelsページを表示するには、左のサイドバーでModelsアイコンをクリックします。
次に、このモデルをproduction(本格運用状態)に移行し、モデルレジストリからモデルをこのノートブックにロードします。
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Production",
)

Modelsページでは、モデルバージョンがProductionステージにあると表示されます。
これで、models:/wine_quality/productionのパスでモデルを参照することができます。
model = mlflow.pyfunc.load_model(f"models:/{model_name}/production")
# サニティチェック: この結果はMLflowで記録されたAUCと一致すべきです
print(f'AUC: {roc_auc_score(y_test, model.predict(X_test))}')
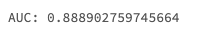
新たなモデルを用いたエクスペリメント
ハイパーパラメーターチューニングを行わなくても、このランダムフォレストモデルはうまく動きました。
以下のコードでは、より精度の高いモデルをトレーニングするためにxgboostライブラリを使用します。HyperoptとSparkTrialsを用いて、複数のモデルを並列にトレーニングするために、ハイパーパラメーター探索を並列で処理します。上のコードと同様に、パラメーター設定、パフォーマンスをMLflowでトラッキングします。
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
from math import exp
import mlflow.xgboost
import numpy as np
import xgboost as xgb
search_space = {
'max_depth': scope.int(hp.quniform('max_depth', 4, 100, 1)),
'learning_rate': hp.loguniform('learning_rate', -3, 0),
'reg_alpha': hp.loguniform('reg_alpha', -5, -1),
'reg_lambda': hp.loguniform('reg_lambda', -6, -1),
'min_child_weight': hp.loguniform('min_child_weight', -1, 3),
'objective': 'binary:logistic',
'seed': 123, # トレーニングの再現性を確保するためにシードを設定します。
}
def train_model(params):
# MLflowのオートロギングによって、ハイパーパラメーターとトレーニングしたモデルは自動的にMLflowに記録されます。
mlflow.xgboost.autolog()
with mlflow.start_run(nested=True):
train = xgb.DMatrix(data=X_train, label=y_train)
test = xgb.DMatrix(data=X_test, label=y_test)
# xgbが評価メトリクスを追跡できるようにテストセットを渡します。XGBoostは、評価メトリクスに改善が見られなくなった際にトレーニングを中止します。
booster = xgb.train(params=params, dtrain=train, num_boost_round=1000,\
evals=[(test, "test")], early_stopping_rounds=50)
predictions_test = booster.predict(test)
auc_score = roc_auc_score(y_test, predictions_test)
mlflow.log_metric('auc', auc_score)
signature = infer_signature(X_train, booster.predict(train))
mlflow.xgboost.log_model(booster, "model", signature=signature)
# fminがauc_scoreを最大化するようにlossに-1*auc_scoreを設定します。
return {'status': STATUS_OK, 'loss': -1*auc_score, 'booster': booster.attributes()}
# 並列度が高いほどスピードを改善できますが、ハイパーパラメータの探索において最適とは言えません。
# max_evalsの平方根が並列度の妥当な値と言えます。
spark_trials = SparkTrials(parallelism=10)
# "xgboost_models"という親のランの子ランとして、それぞれのハイパーパラメーターの設定が記録されるようにMLflowランのコンテキスト内でfminを実行します。
with mlflow.start_run(run_name='xgboost_models'):
best_params = fmin(
fn=train_model,
space=search_space,
algo=tpe.suggest,
max_evals=96,
trials=spark_trials,
rstate=np.random.RandomState(123)
)
この処理はクラスターのスペックに依存しますが数分かかります。

MLflowを用いて結果を確認
Experiment Runsサイドバーを開いて、ランを参照します。メニューを表示するために、下向き矢印の隣にあるDateをクリックしaucを選択し、aucメトリックの順でランを並び替えます。一番高いaucは0.92となっています。ベースラインモデルを上回りました!
MLflowはそれぞれのランのパフォーマンスメトリクスとパラメーターをトラッキングします。Experiment Runsサイドバーの一番上にある右上向きの矢印アイコン をクリックすることで、MLflowランの一覧に移動することができます。
をクリックすることで、MLflowランの一覧に移動することができます。
次に、どのようにハイパーパラメータの選択がAUCと相関しているのかを見てみましょう。"+"アイコンをクリックして、親のランを展開し、親以外の全てのランを選択し、"Compare"をクリックします。Parallel Coordinates Plotを選択します。
メトリックに対するパラメーターのインパクトを理解するために、Parallel Coordinates Plotは有用です。プロットの右上にあるピンクのスライダーをドラッグすることで、AUCの値のサブセット、対応するパラメーターの値をハイライトすることができます。以下のプロットでは、最も高いAUCの値をハイライトしています。
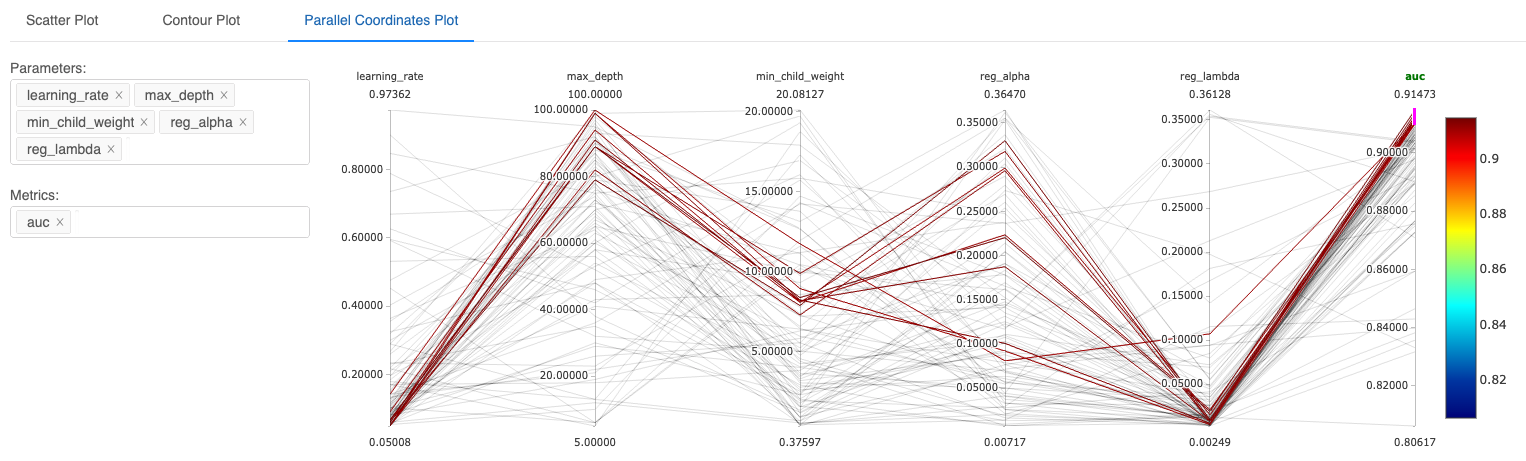
最もパフォーマンスの良かったランの全てが、reg_lambdaとlearning_rateにおいて低い値を示していることに注意してください。
これらのパラメーターに対してより低い値を探索するために、さらなるハイパーパラメーターチューニングを実行することもできますが、ここではシンプルにするために、そのステップをデモに含めていません。
それぞれのハイパーパラメーターの設定において生成されたモデルを記録するためにMLflowを用いました。以下のコードでは、最も高いパフォーマンスを示したランを検索し、モデルレジストリにモデルを登録します。
best_run = mlflow.search_runs(order_by=['metrics.auc DESC']).iloc[0]
print(f'AUC of Best Run: {best_run["metrics.auc"]}')
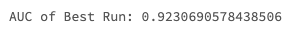
MLflowモデルレジストリのProductionステージにあるwine_quality_takaモデルを更新
はじめに、wine_quality_takaという名前でベースラインモデルをモデルレジストリに保存しました。さらに精度の高いモデルができましたので、wine_quality_takaを更新します。
new_model_version = mlflow.register_model(f"runs:/{best_run.run_id}/model", model_name)
# モデル登録に数秒を要するので、待ち時間を挿入します。
time.sleep(15)

左のサイドバーでModelsをクリックし、wine_quality_takaに二つのバージョンが存在することを確認します。
以下のコードで新バージョンをproductionに移行します。
# 古いモデルバージョンをアーカイブします。
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Archived"
)
# 新しいモデルバージョンをProductionに昇格します。
client.transition_model_version_stage(
name=model_name,
version=new_model_version.version,
stage="Production"
)

load_modelを呼び出すクライアントはURIを変更することなしに、新たなモデルを受け取ることができます。
# このコードは上の"ベースラインモデルの構築"と同じものです。新たなモデルを利用するためにクライアント側での変更は不要です!
model = mlflow.pyfunc.load_model(f"models:/{model_name}/production")
print(f'AUC: {roc_auc_score(y_test, model.predict(X_test))}')
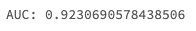
バッチ推論
新たなデータのコーパスに対してモデルを評価したいというシナリオは数多く存在します。例えば、新たなデータバッチを手に入れたり、同じデータコーパスに対して二つのモデルを比較することなどが考えられます。
以下のコードでは、並列に処理を行うためにSparkを用い、Deltaテーブルに格納されたデータに対してモデルの評価を行います。
# 新たなデータコーパスをシミュレートするために、既存のX_trainデータをDeltaテーブルに保存します。
# 実際の環境では、本当に新たなデータバッチとなります。
spark_df = spark.createDataFrame(X_train)
# Deltaテーブルの保存先(適宜変更してください)
table_path = "dbfs:/tmp/takaakiyayoidatabrickscom/delta/wine_data"
# すでにコンテンツが存在する場合には削除します
dbutils.fs.rm(table_path, True)
spark_df.write.format("delta").save(table_path)
モデルをSparkのUDF(ユーザー定義関数)としてロードし、Deltaテーブルに適用できるようにします。
import mlflow.pyfunc
apply_model_udf = mlflow.pyfunc.spark_udf(spark, f"models:/{model_name}/production")
# 新規データをDeltaから読み込みます
new_data = spark.read.format("delta").load(table_path)
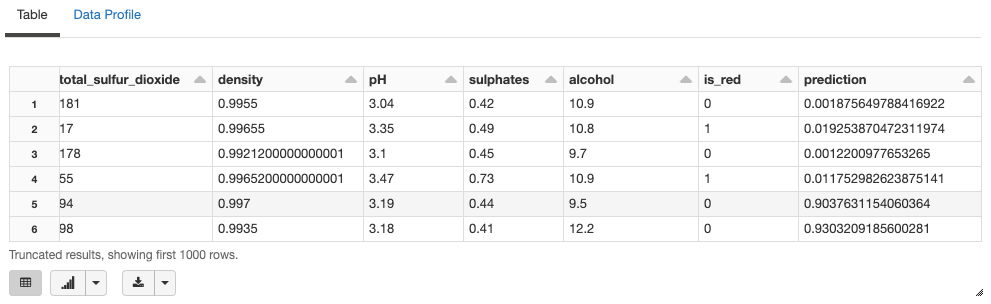
display(new_data)
from pyspark.sql.functions import struct
# 新規データにモデルを適用します
udf_inputs = struct(*(X_train.columns.tolist()))
new_data = new_data.withColumn(
"prediction",
apply_model_udf(udf_inputs)
)
# それぞれの行には予測結果が紐づけられています。
# xgboostの関数はデフォルトでは確率を出力せず、予測結果が[0, 1]に限定されないことに注意してください。
display(new_data)
モデルサービング
低レーテンシーでの予測を行うようにモデルを運用するためには、MLflowのモデルサービング(AWS|Azure)を利用して、モデルをエンドポイントにデプロイします。
以下のコードでは、どのようにREST APIを用いてデプロイしたモデルから予測結果を得るのかを説明します。
モデルのエンドポイントにリクエストするためには、Databricksのトークンが必要です。(右上のプロファイルアイコンの下の)User Settingページでトークンを生成することができます。
トークンなど機密性の高い情報はノートブックに記述すべきではありません。シークレットに保存するようにしてください。
Databricksにおけるシークレットの管理 - Qiita
import os
# 事前にCLIでシークレットにトークンを登録しておきます
token = dbutils.secrets.get("demo-token-takaaki.yayoi", "token")
os.environ["DATABRICKS_TOKEN"] = token
左のサイドバーでModelsをクリックし、登録されているワインモデルに移動します。servingタブをクリックし、Enable Servingをクリックします。
次に、Call The Modelで、リクエストを送信するためのPythonコードスニペットを表示するためにPythonボタンをクリックします。コードをこのノートブックにコピーします。次のセルと同じようなコードになるはずです。
Databricksの外からリクエストするために、このトークンを利用することもできます。
import os
import requests
import numpy as np
import pandas as pd
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(dataset):
url = 'https://e2-demo-west.cloud.databricks.com/model/wine_quality_taka/2/invocations'
headers = {'Authorization': f'Bearer {os.environ.get("DATABRICKS_TOKEN")}'}
data_json = dataset.to_dict(orient='split') if isinstance(dataset, pd.DataFrame) else create_tf_serving_json(dataset)
response = requests.request(method='POST', headers=headers, url=url, json=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()
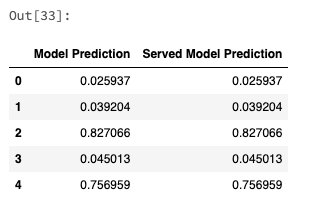
エンドポイントから得られるモデルの予測結果と、ローカルでモデルを評価した結果は一致すべきです。
# モデルサービングは、比較的小さいデータバッチにおいて低レーテンシーで予測するように設計されています。
num_predictions = 5
served_predictions = score_model(X_test[:num_predictions])
model_evaluations = model.predict(X_test[:num_predictions])
# トレーニングしたモデルとデプロイされたモデルの結果を比較します。
pd.DataFrame({
"Model Prediction": model_evaluations,
"Served Model Prediction": served_predictions,
})
ノートブック
MLflowによるエンドツーエンドのサンプルノートブック
サンプルノートブックはこちらからダウンロードできます。