Databricksクイックスタートガイドのコンテンツです。
Manage notebooks | Databricks on AWS [2022/8/11時点]の翻訳です。
UI、CLI、Workspace APIを用いてノートブックを管理することができます。本記事では主にUIを用いたノートブックに対する操作を説明します。他の方法に関しては、Databricks CLI、Workspace API 2.0を参照ください。
ノートブックの作成
作成ボタンを使う
あなたのデフォルトフォルダーで新規ノートブックを作成する最も簡単な方法はCreateボタンを使うことです。
- サイドバーの
 Createをクリックし、メニューからNotebookを選択します。ノートブック作成ダイアログが表示されます。
Createをクリックし、メニューからNotebookを選択します。ノートブック作成ダイアログが表示されます。 - 名前を入力し、ノートブックのデフォルト言語を選択します。
- 稼働中のクラスターがある場合は、Clusterドロップダウンが表示されます。ノートブックをアタッチしたいクラスターを選択します。
- Createをクリックします。
任意のフォルダーにノートブックを作成する
以下の手順を踏むことで、任意のフォルダー(Sharedフォルダーなど)に新規ノートブックを作成することができます。
- サイドバーの
 Workspaceをクリックします。以下のいずれかを行います。
Workspaceをクリックします。以下のいずれかを行います。
- 任意のフォルダーの右にある
 をクリックし、Create > Notebookを選択します。
をクリックし、Create > Notebookを選択します。

- ワークスペースかユーザーフォルダーで、をクリックし、Create > Notebookを選択します。
- 任意のフォルダーの右にある
- 作成ボタンを使うのステップ2からステップ4を行います。
ノートブックを開く
ワークスペースで、 をクリックします。ノートブックのタイトルにマウスカーソルを持っていくとノートブックのパスが表示されます。
をクリックします。ノートブックのタイトルにマウスカーソルを持っていくとノートブックのパスが表示されます。
ノートブックの削除
ワークスペースメニューにどのようにアクセスしてノートブックや他の項目を削除するのかに関しては、フォルダーとワークスペースオブジェクトの操作を参照ください。
ノートブックのパスのコピー
ノートブックのファイルパスをコピーするには、ノートブック名を右クリックするか、ノートブック名の右のをクリックして、Copy File Pathを選択します。

ノートブックの名前の変更
開いているノートブックのタイトルをクリックしてタイトルを変更するか、File > Renameをクリックします。
ノートブックのアクセス制御
DatabricksのPremium planを契約している場合には、ノートブックのアクセス権を設定できるワークスペースオブジェクトのアクセスコントロールを利用できます。
ノートブックの外部フォーマット
Databricksはいくつかの外部フォーマットをサポートしています:
- ソースファイル:
.scala、.py、.sql、.rの拡張子を持つソースコード - HTML:
.htmlの拡張子を持つDatabricksノートブック - DBCアーカイブ: Databricksアーカイブ
- IPythonノートブック:
.ipynbの拡張子を持つJupyter notebook - RMarkdown:
.Rmdの拡張子を持つR Markdown document
本章では以下を説明します:
ノートブックのインポート
URLかファイルから外部ノートブックをインポートできます。また、DatabricksワークスペースからバルクでエクスポートされたノートブックのZIPアーカイブをインポートすることができます。
-
サイドバーのWorkspaceボタン
をクリックします。以下のいずれかを行います。- フォルダーの右側にあるをクリックして、Importを選択します。
- ワークスペース、ユーザーフォルダーで
 をクリックし、Importを選択します。
をクリックし、Importを選択します。

- フォルダーの右側にある
-
URLを指定するか、サポートされている外部フォーマットのファイル、DatabricksのワークスペースからエクスポートされたZIPアーカイブを選択します。
-
Importをクリックします。
- 単一のノートブックを選択すると、現在のフォルダーにインポートされます。
- DBCかZIPアーカイブを選択すると、現在のフォルダーにフォルダー構造が再作成され、それぞれのノートブックがインポートされます。
ファイルをノートブックに変換する
ファイルの最初のセルにコメントを追加することで、既存のPython、SQL、Scala、Rスクリプトを単一セルのノートブックに変換することができます。
# Databricks notebook source
-- Databricks notebook source
// Databricks notebook source
# Databricks notebook source
Databricksノートブックは、セルを定義するために空白で囲まれた特殊なコメントを使用します。
# COMMAND ----------
-- COMMAND ----------
// COMMAND ----------
# COMMAND ----------
ノートブックのエクスポート
ノートブックツールバーで、File > Exportを選択し、フォーマットを指定します。
注意
HTML、IPythonノートブック、アーカイブ(DBC)としてノートブックをエクスポートする際に、実行結果をクリアしていない場合にはエクスポートしたものに実行結果も含まれます。
フォルダーのすべてのノートブックのエクスポート
注意
HTML、IPython、アーカイブ(DBC)としてノートブックをエクスポートする際、結果をクリアしていない場合には、ノートブックの実行結果が含まれます。
ファクスペースフォルダーのすべてのノートブックをZIPアーカイブとしてエクスポートするには、以下を行います。
- サイドバーのワークスペースをクリックします。以下のいずれを行います。
- 任意のフォルダーの隣にある右端のをクリックし、Exportをクリックします。
- ワークスペースあるいはユーザーフォルダーで、をクリックして、Exportを選択します。
- 任意のフォルダーの隣にある右端の
- エクスポートフォーマットを選択します。
- DBCアーカイブ: メタデータとノートブックコマンドの結果を含むバイナリーフォーマットであるDatabricksアーカイブをエクスポートします。
- ソースファイル: Databricksワークスペースにインポート可能なノートブックソースファイルのZIPアーカイブをエクスポートします。それぞれのノートブックのデフォルト言語のソースファイルとして参照したり、CI/CDパイプラインで使用できます。
- HTMLアーカイブ: HTMLファイルのZIPアーカイブをエクスポートします。それぞれのノートブックのHTMLファイルは、Databricksワークスペースにインポートでき、HTMLとして参照できます。ノートブックコマンド結果が含まれます。
ノートブックのパブリッシュ
Databricksコミュニティエディションを使用している場合には、ノートブックのURLを共有するために、ノートブックをパブリッシュすることができます。以降のパブリッシュアクションでノートブックのURLはパブリッシュ用のものに更新されます。
ノートブックとクラスター
ノートブックにおけるあらゆる作業を行う前に、まず最初にノートブックをクラスターにアタッチする必要があります。本章では、どのようにクラスターに対してノートブックをアタッチ、デタッチ(切り離し)するのか、その際に背後では何が起きているのかを説明します。
本章では以下を説明します。
実行コンテキスト
クラスターにノートブックをアタッチした際には、Databricksは実行コンテキストを生成します。実行コンテキストには、サポートされているプログラミング言語: Python、R、Scala、SQLそれぞれに対応するREPL環境の状態が含まれます。ノートブック上のセルが実行されると、コマンドは適切な言語のREPL環境にディスパッチされて実行されます。
また、REST 1.2 APIを用いて実行コンテキストを作成し、コマンドを実行コンテキストに送信して実行することもできます。同様に、コマンドは適切な言語のREPL環境にディスパッチされて実行されます。
クラスターには最大実行コンテキスト数(145)があります。実行コンテキストの数がこの最大値に達すると、ノートブックをクラスターにアタッチしたり、新たな実行コンテキストを作成することができなくなります。
アイドル状態の実行コンテキスト
最後のコマンドが実行された後、特定のアイドル期間を過ぎた時に実行コンテキストはアイドル状態にあると考えられます。アイドル期間とは、最後のコマンド実行時からノートブックを自動的にデタッチするまでの時間となります。デフォルトのアイドル期間は24時間です。
クラスターが最大実行コンテキスト数に達した場合には、必要に応じてDatabricksは、アイドル状態の実行コンテキストを(最も最後に利用されたものから)削除します。実行コンテキストが削除された場合には、該当コンテキストを利用していたノートブックは依然としてクラスターにアタッチされており、クラスターのノートブックリストに表示されます。実行中のストリーム処理があるノートブックの実行コンテキストは、ストリーム処理が終了するまで決して削除されません。アイドル状態のコンテキストが削除された際には、実行コンテキストを使用していたノートブックに対して、アイドル状態にあったため実行コンテキストを使っていたノートブックがデタッチされたことを知らせるメッセージが表示されます。

実行コンテキスト数が最大に達しているクラスターにノートブックをアタッチしようとした際、アイドルの実行コンテキストがない場合(あるいは自動削除が無効化されている場合)には、最大実行コンテキスト数に達していること、ノートブックはデタッチされたままであることが通知されます。

プロセスをフォークした際、フォークプロセスが終了しても、アイドル状態の実行コンテキストは依然としてアイドル状態と考えられます。なお、Sparkにおいて別プロセスのフォークは推奨されません。
実行コンテキスト自動削除の設定
実行コンテキスト自動削除はSparkプロパティのspark.databricks.chauffeur.enableIdleContextTracking falseで設定できます。
クラスターにノートブックをアタッチする
重要!
クラスターにノートブックがアタッチされている限り、ノートブックにCan Run権限を持つ任意のユーザーは、暗黙的にクラスターにアクセスする権限を持ちます。
ノートブックをクラスターにアタッチするには以下を行います。
- ノートブックノートブックツールバーで
 Detached
Detached をクリックします。
をクリックします。 - ドロップダウンから、クラスターを選択します。
重要!
アタッチされたノートブックでは、以下のApache Spark変数を利用できます。
| クラス | 変数名 |
|---|---|
| SparkContext | sc |
| SQLContext/HiveContext | sqlContext |
| SparkSession (Spark 2.x) | spark |
独自にSparkSession、SparkContext、SQLContextを作成しないでください。作成すると動作に一貫性がなくなります。
SparkとDatabricksランタイムバージョンを確認する
ノートブックをアタッチしたクラスターのSparkバージョンを確認するには、以下を実行します。
spark.version
ノートブックをアタッチしたクラスターのDatabricksランタイムのバージョンを確認するには、以下を実行します。
spark.conf.get("spark.databricks.clusterUsageTags.sparkVersion")
注意
Clusters API、Jobs APIのエンドポイントで必要となる sparkVersionタグとspark_versionプロパティに関しては、Databricks Runtime version(英語)を参照ください。これはSparkのバージョンとは異なります。
クラスターからノートブックをデタッチする
- ノートブックツールバーのAttached
<cluster-name>をクリックします。 - Detachを選択します。
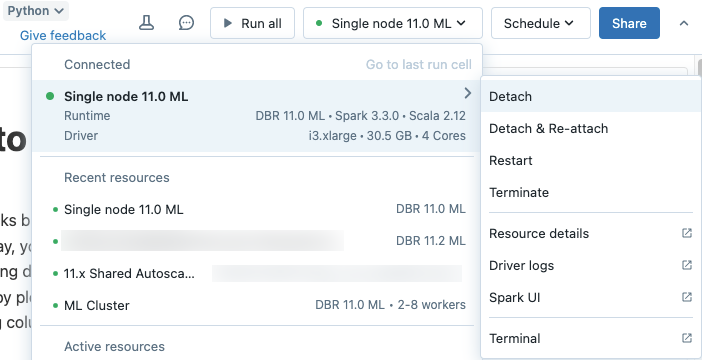
クラスター詳細ページのNotebooksタブで、クラスターからノートブックをデタッチすることもできます。
クラスターからノートブックをデタッチした際には、実行コンテキストが削除され、ノートブック上の全ての変数の値はクリアされます。
ティップス
使用していないノートブックはクラスターからデタッチすることをお勧めします。これによりドライバーノードのメモリーを解放できます。
クラスターにアタッチされているノートブックを参照する
クラスター詳細ページのNotebooksタブには、クラスターにアタッチされたノートブックが表示されます。また、それぞれのノートブックで、最後のコマンドが実行された時刻とノートブックの状態が表示されます。
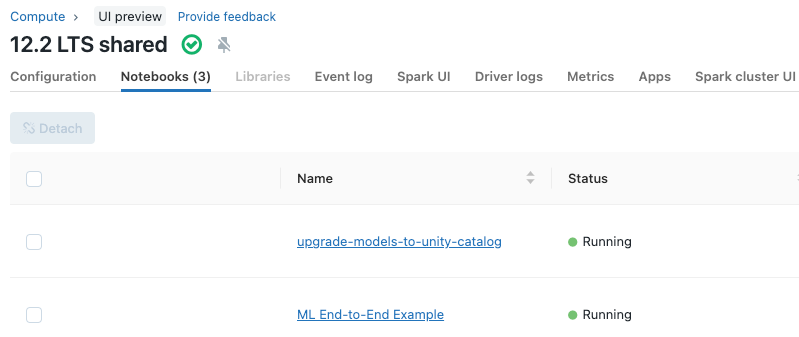
ノートブックのスケジュール
定期的にノートブックの実行をスケジュールするには:
-
ノートブックツールバーで、右上の
 ボタンをクリックします。このノートブックのジョブが存在しない場合、スケジュールダイアログが表示されます。
ボタンをクリックします。このノートブックのジョブが存在しない場合、スケジュールダイアログが表示されます。

すでに、ノートブックのジョブが存在している場合にはジョブ一覧が表示されます。スケジュールダイアログを表示するには、Add a scheduleをクリックします。
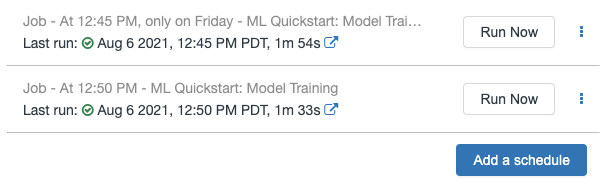
-
スケージュールダイアログでは、オプションとしてジョブの名前を入力します。デフォルト名はノートブック名となります。
-
マニュアルでのみジョブを実行するのであればManualを選択し、ジョブ実行のスケジュールを定義するにはScheduledを選択します。Scheduledを選択する場合、頻度、時刻、タイムゾーンを指定するためにドロップダウンを使用します。
-
Clusterドロップダウンで、タスクを実行するクラスターを選択します。
Allow Cluster Creation権限を持っているのであれば、デフォルトでジョブは新規ジョブクラスターで実行されます。デフォルトジョブクラスターの設定を行うには、クラスター設定ダイアログを表示するためにフィールドの右のEditをクリックします。
Allow Cluster Creation権限を持っていない場合は、デフォルトでジョブはノートブックがアタッチされているクラスターで実行されます。ノートブックがクラスターにアタッチされていない場合、Clusterドロップダウンからクラスターを選択する必要があります。
-
オプションで、ジョブに引き渡す任意のParameterを入力します。Addをクリックし、それぞれのパラメーターのキーと値を指定します。パラメーターは、パラメーターのキーによって指定されるノートブックウィジェットの値を設定します。パラメーターの値の一部として、動的な値の限定的なセットを引き渡すにはタスクパラメーター変数を使用します。
-
オプションで、ジョブイベントのAlertを受け取るメールアドレスを指定します。通知をご覧ください。
-
Submitをクリックします。
スケジュールされたノートブックジョブの管理
このノートブックに関連づけられているジョブを表示するには、Scheduleボタンをクリックします。ジョブ一覧ダイアゴルが表示され、このノートブックに現在定義されているすべてのジョブが表示されます。ジョブを管理するには、リストのジョブの右にある をクリックします。
をクリックします。
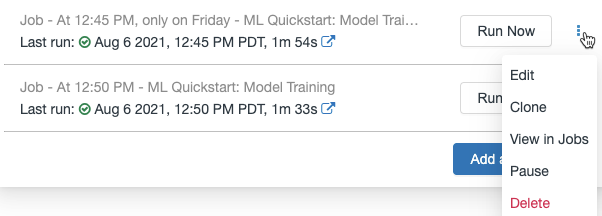
このメニューから、スケジュールされたジョブを編集、クローン、参照、停止、再開、削除することができます。
スケジュールされたジョブをクローンすると、オリジナルと同じパラメーターが設定された新規ジョブが作成されます。新規ジョブはリスト上に“Clone of <initial job name>”という名前で表示されます。
ジョブの編集方法は、ジョブのスケジュールの複雑度によります。スケジュールダイアログかジョブ詳細パネルが表示され、スケジュール、クラスター、パラメーターなどを編集することができます。
ノートブックの配布
容易にノートブックを配布できるように、Databricksは単体のノートブックや複数のノートブックを格納するフォルダーをパッケージできるDatabricksアーカイブ形式をサポートしています。Databricksアーカイブは、.dbcの拡張子を持った追加メタデータを含むJARファイルです。アーカイブに含まれるノートブックは、Databricksの内部フォーマットに変換されています。
アーカイブのインポート
- ノートブック、フォルダーの右にあるかをクリックし、Importを選択します。
- FileかURLを選択します。
- Databricksアーカイブをドラッグ&ドロップします。
- Importをクリックします。Databricksにアーカイブがインポートされます。アーカイブにフォルダーが含まれている場合には、Databricksでフォルダーが作成されます。
アーカイブのエクスポート
ノートブック、フォルダーの右にある![]() かをクリックし、Export > DBC Archiveを選択します。
かをクリックし、Export > DBC Archiveを選択します。<[folder|notebook]-name>.dbcという形式でファイルがダウンロードされます。