Configure clusters | Databricks on AWS [2022/10/11時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksクイックスタートガイドのコンテンツです。
注意
これらの手順はレガシーなクラスター作成UI向けのであり、正確な履歴を保つためだけのものです。すべての顧客は更新されたクラスター作成UIを使用すべきです。
本書では、Databricksクラスターを作成、変更する際に利用可能な設定オプションを説明します。UIを用いたクラスターの作成、変更にフォーカスしています。他の方法に関しては、Clusters CLI、Clusters API、Databricks Terraform providerを参照ください。
ご自身の要件に最も適した設定オプションをどの様に決めたら良いのかに関しては、Databricksクラスター設定のベストプラクティスを参照ください。

クラスターポリシー
クラスターポリシーを用いることで、一連のルールに基づきクラスターの設定を制限することができます。ポリシーのルールは、クラスター作成時に指定できる属性、属性の値に制限をかけます。クラスターポリシーには使用できるユーザー、グループを制限できるACLがあるので、クラスターを作成する際に選択できるポリシーを制限することができます。
クラスターポリシーを設定するには、Policyドロップダウンからクラスターポリシーを選択します。

注意
ワークスペースでクラスタポリシーが作成されていない場合には、Policyドロップダウンは表示されません。
- あなたがクラスター作成権限を持っている場合には、Unrestrictedポリシーを選択することで、任意の設定でクラスターを作成することができます。Unrestrictedポリシーはクラスターの属性、属性の値にいかなる制限を適用しません。
- クラスター作成権限およびクラスターポリシーへのアクセス権がある場合には、Unrestrictedポリシーあるいはアクセスできるポリシーを選択できます。
- クラスターポリシーへのアクセス権のみがある場合には、アクセスできるポリシーを選択できます。
クラスターモード
注意
本書ではレガシーなクラスターUIを説明しています。プレビューのUIの詳細に関しては、Create a clusterをご覧ください。これには、クラスターアクセスタイプとモードの用語の変更が含まれています。新規のクラスタータイプとレガシークラスタータイプの比較に関しては、Clusters UI changes and cluster access modesをご覧ください。プレビューUIにおいては、
- スタンダードモードクラスターは今では分離なし共有アクセスモードクラスターと呼ばれます。
- テーブルACLを使うハイコンカレンシークラスターは今では共有アクセスモードクラスターと呼ばれます。
Databricksでは、Standard、High Concurrency、Single Nodeの3つのクラスターモードをサポートしています。デフォルトはStandardとなっています。
重要!
- お使いのワークスペースがUnity Catalogのメタストアに割り当てられている場合、ハイコンカレンシークラスターを使用することはできません。代わりに、アクセスコントロールの一貫性を保証し、強力な分離保証を強制するためにはアクセスモードを使ってください。また、Create a cluster that can access Unity Catalogもご覧ください。
- クラスターを作成した後にクラスターモードを変更することはできません。異なるクラスターモードを使いたい場合には、新規クラスターを作成する必要があります。
クラスターの設定には、クラスターモードに応じた自動停止設定のデフォルト値が存在します。
- StandardおよびSingle Nodeクラスターはデフォルトで120分後に自動で停止します。
- High Concurrencyクラスターはデフォルトでは自動停止しません。
Standardクラスター
警告!
スタンダードモードのクラスター(分離なし共有クラスター)は複数のユーザーで共有することができますが、ユーザー間のアイソレーションはありません。テーブルACLやクレディンシャルパススルーの様な追加のセキュリティ設定を伴わないハイコンカレンシークラスターを使用している際にはスタンダードモードクラスターと同じ設定が使用されます。アカウント管理者はこれらのタイプのクラスターにおいてDatabricksワークスペース管理者の内部認証情報の自動生成を抑止することができます。よりセキュアな選択肢として、テーブルACLを使用するハイコンカレンシークラスターの様な代替案を使用することをお勧めします。
シングルユーザーのみの場合においては、Standardが推奨となります。Standardクラスターではあらゆる言語(Python、SQL、R、Scala)での開発を行えます。
High Concurrencyクラスター
High Concurrencyはマネージドのクラウドリソースとなります。High Concurrencyの大きなメリットは、リソースの使用率を最大化しつつもクエリーのレーテンシーを最小化するためのきめ細かいリソース共有機構です。
High ConcurrencyクラスターではSQL、Python、Rを用いた開発が可能です。High Concurrencyのパフォーマンスとセキュリティは、異なるプロセスでユーザーコードを実行することで実現され、Scalaではこれは不可能となります。
さらに、High Concurrencyクラスターのみ、テーブルアクセスコントロールをサポートしています。
High Concurrencyクラスターを作成するには、Cluster ModeでHigh Concurrencyを選択します。
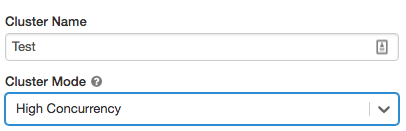
Cluster APIを用いてHigh Concurrencyクラスターを作成する方法に関しては、High Concurrency cluster exampleを参照ください。
Single Nodeクラスター
Single Nodeクラスターにはワーカーがないため、Sparkジョブはドライバーノードで実行されます。
一方、Standardクラスターにおいては、Sparkジョブを実行するためにドライバーノードに加えて、少なくとも1台のSparkワーカーノードが必要となります。
Single Nodeクラスターを作成するには、Cluster ModeでSingle Nodeを選択します。

Single Nodeクラスターについて詳細を知りたい場合には、Single Node clustersを参照ください。
データリネージュ
プレビュー
データリネージュはパブリックプレビューです。
データリネージュをキャプチャするクラスターを作成するには、クラスター設定ページに移動し、以下のステップを実行します。
注意
ジョブクラスターを用いたジョブ実行の一部としてリネージュをキャプチャするには、ジョブクラスターに以下の設定をすることを確認してください。
-
Access modeで、Single userかSharedを選択します。
- Single user: 複数言語をサポートしますが、割り当てられた単一のユーザーのみが使用できます。
- Shared: 複数ユーザーで共有できるクラスターです。SQLやPythonワークロードのみがサポートされています。
-
Databricks runtime versionでDatabricksランタイム11.1以降を選択します。
-
Advanced Optionsトグルをクリックします。
-
Sparkタブをクリックします。
-
Spark configテキストボックスに以下の設定を入力します。
inispark.databricks.dataLineage.enabled true -
Create Clusterをクリックします。
プール
クラスターの起動時間を削減するために、ドライバーノード、ワーカーノード向けにアイドル状態のインスタンスの事前定義済みのプールにクラスターをアタッチすることができます。プール内のインスタンスを用いてクラスターが作成されます。リクエストされたドライバー、ワーカーノードを作成するのに必要なアイドル状態のインスタンスが十分に無い場合には、プールはインスタンスプロバイダーから新たなインスタンスを割り当ててプールを拡張します。アタッチされたクラスターが停止されると、使用されたインスタンスはプールに返却され、異なるクラスターで再利用することができます。
ドライバーノードではなくワーカーノードにプールを選択した場合、ドライバーノードはワーカーノードの設定からプールを継承します。
重要!
ワーカーノードではなくドライバーノードにプールを選択しようとした場合、エラーが発生しクラスターは作成されません。この要件により、ドライバーノードがワーカーノードの作成を待たなくてはいけない、あるいは逆の状況を防ぐことができます。
Databricksにおけるプールの詳細については、プールを参照ください。
Databricksランタイム
Databricksランタイムは、お使いのクラスター上で稼働する一連のコアコンポーネントです。すべてのDatabricksランタイムにはApache Sparkが含まれており、ユーザビリティ、パフォーマンス、セキュリティを改善するためのコンポーネント、アップデートが追加されています。
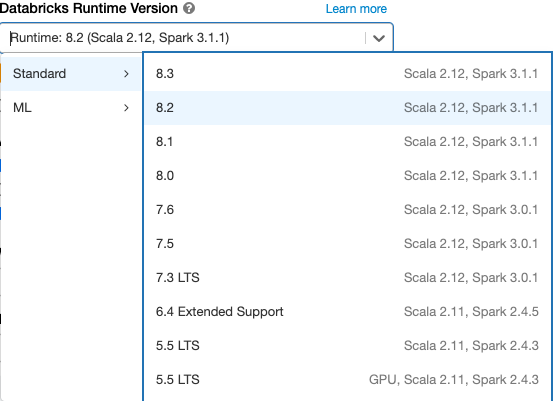
Databricksはいくつかの種類、バージョンのランタイムを提供しており、クラスターを作成、変更する際にDatabricks Runtime Versionドロップダウンから選択します。
Photonアクセラレーション
PhotonはDatabricksランタイム 9.1LTS以降で利用できます。
Photonアクセラレーションを有効化するには、Use Photon Accelerationチェックボックスを選択します。
必要に応じてワーカータイプとドライバータイプのインスタンスタイプを指定することができます。
Spark UIでPhotonのアクションを参照できます。以下のスクリーンショットではクエリー詳細のDAGを表示しています。DAGからPhotonに関する二つの示唆が得られます。まず、Photonのオペレーターは、例えば、PhotonGroupingAggのような「Photon」の文字列でスタートします。2つ目として、DAGにおいては、Photonオペレーターとステージは桃色で描画され、非Photonのオペレーターは青色となります。

Dockerイメージ
いくつかのDatabricksランタイムバージョンにおいては、クラスター作成時にDockerイメージを指定することができます。例となるユースケースには、ライブラリのカスタマイズ、変更がないゴールデン環境、DockerのCI/CDインテグレーションが含まれます。
GPUデバイスを持つクラスターによるディープラーニングのカスタム環境を作成するためにDockerイメージを使用することもできます。
使い方に関しては、Customize containers with Databricks Container ServicesとDatabricks Container Services on GPU clustersを参照ください。
クラスターノードタイプ
クラスターは1台のドライバーノード、0台以上のワーカーノードから構成されます。
ドライバーノードとワーカーノードに別々のインスタンスタイプを指定することができますが、デフォルトではドライバーノードはワーカーノードと同じインスタンスタイプを使用します。異なるインスタンスタイプファミリーは、メモリーを消費するワークロードや計算資源を消費するワークロードなど異なるユースケースにフィットします。
- ドライバーノード
- ワーカーノード
- GPUインスタンスタイプ
- [AWS Gravitonインスタンスタイプ]
ドライバーノード
ドライバーノードはクラスターにアタッチされている全てのノートブックの状態に関する情報を維持します。また、ドライバーノードはSparkContextを維持し、クラスター上のノートブックやライブラリから実行される全てのコマンドを解釈し、Sparkエグゼキューターと連携しす量にApache Sparkのマスターを実行します。
ドライバーノードタイプのデフォルトは、ワーカーノードと同じものが選択されます。ノートブック上で大量のデータをワーカーノードから取り出し分析を行うために、collect()を実行しようとする際には、より多くのメモリーを搭載したドライバーノードを選択することができます。
ティップス
ドライバーノードはアタッチされているノートブックの全ての状態に関する情報を保持するので、使用されていないノートブックはドライバーノードからデタッチする様にしてください。
ワーカーノード
Databricksのワーカーノードは、Sparkエグゼキューターやクラスターが適切に動作するために必要なサービスを実行します。ワークロードをSparkに分散させた場合、全ての分散処理はワーカーノードで実行されます。Databricksにおいては、1台のワーカーノードで1つのエグゼキューターを実行します。このため、Databricksのアーキテクチャの文脈においては、エグゼキューターとワーカーは同じ意味で使用されます。
ティップス
Sparkジョブを実行する際には、少なくとも1つのワーカーノードが必要となります。クラスターにワーカーがない場合、ドライバーノードで非Sparkのコマンドを実行することはできますが、Sparkコマンドは失敗します。
注意
Databricksがワーカーノードを起動する際、2つのプライベートIPアドレスを割り当てます。ノードのプライマリプライベートIPアドレスは、Databricks内部トラフィックをホストするために使用されます。セカンダリのプライベートIPアドレスはクラスター間通信のためのSparkコンテナによって使用されます。このモデルによって、Databricksは同じワークスペースにおける複数のクラスターの分離を実現します。
GPUインスタンスタイプ
ディープラーニングの様に高いパフォーマンスが求められる様なチャレンジングなタスクに対しては、Databricksではグラフィックプロセッシングユニット(GPU)を用いたクラスターをサポートしています。このサポートはベータバージョンです。詳細に関しては、GPU-enabled clustersを参照ください。
AWS Gravitonインスタンスタイプ
プレビュー
この機能はパブリックプレビューです。
DatabricksではAWS Gravitonプロセッサーを使用したクラスターをサポートしています。ArmベースのAWS GravitonインスタンスはAWSによってデザインされており、同等の現世代のx86ベースのインスタンスよりも優れたコストパフォーマンスを提供します。AWS Graviton-enabled clustersをご覧ください。
クラスターサイズ、オートスケーリング
Databricksクラスターを作成する際、クラスターにおけるワーカーの固定値、あるいは最小数、最大数を指定することができます。
固定サイズのクラスターを指定した場合、Databricksは指定された数のワーカーを保証します。ワーカーの数をレンジで指定した場合には、あなたのジョブを実行するのに必要なワーカーの最適な数を選択します。これはオートスケーリングと呼ばれるものです。
オートスケーリングを用いることで、Databricksはあなたのジョブの特性を考慮して動的にワーカーを再配置します。あなたのパイプラインの特定の部分では、他と比べてより多くの計算資源を必要とするかもしれません。この際、Databricksはジョブの実行過程で自動で追加のワーカーを追加します(そして、不要になればこれらを削除します)。
オートスケーリングを用いることで、ワークロードに適したクラスターを配備する必要がなくなるので、高いクラスターの利用率を実現することが容易になります。時間によってワークロードの要件が変化するケース(1日間のデータセットの探索など)でより効果を発揮しますが、クラスター配備要件が未知の短期間の一回限りのワークロードにも適用することができます。オートスケーリングは2つのメリットをもたらします。
- 固定サイズ、かつリソースが欠如しているクラスターと比較して、ワークロードが高速になります。
- 固定サイズのクラスターと比較して、オートスケーリングのクラスターは全体的なコストを削減できます。
クラスターとワークロードの固定サイズに依存しますが、オートスケーリングはこれら両方のメリットを同時に提供します。クラウドプロバイダーがインスタンスを停止した場合、選択されたワーカーの最小値よりもクラスターが小さくなる場合があります。この場合、Databricksはワーカーの最小値を維持する様に、継続的にインスタンスの再配備をリトライします。
注意
オートスケーリングはspark-submitジョブでは使用できません。
オートスケーリングの挙動
- 最小値から最大値にスケールアップするまでに2つのステップを踏みます。
- シャッフルファイルの状態を見ることで、クラスターがアイドル状態でなくても、スケールダウンすることがあります。
- 現在のノードのパーセンテージに応じてスケールダウンします。
- ジョブクラスターにおいては、過去40秒間の利用率が低かった場合にスケールダウンします。
- all-purposeクラスターにおいては、過去150秒間の利用率が低かった場合にスケールダウンします。
- Spark設定プロパティ
spark.databricks.aggressiveWindowDownSでどの程度の周期でクラスターのスケールダウンの決定を行うのかを、秒で指定できます。値を増加させることで、クラスターのスケールダウンがゆっくりとなります。最大値は600です。
オートスケーリングの有効化、設定
Databricksが自動でクラスターのサイズを調整できる様にするには、クラスターのオートスケーリングを有効化し、ワーカーの最小値、最大値を指定します。
-
オートスケーリングを有効化します。
- All-purposeクラスター: Create Clusterページで、Autopilot OptionsボックスのEnable autoscalingチェックボックスを選択します。

- ジョブクラスター: Configure Clusterページで、Autopilot OptionsボックスでEnable autoscalingを選択します。

- All-purposeクラスター: Create Clusterページで、Autopilot OptionsボックスのEnable autoscalingチェックボックスを選択します。
-
ワーカーの最小数、最大数を設定します。

クラスターを実行している際、クラスター詳細ページには割り当てられたワーカーの数が表示されます。割り当てられたワーカーの数とワーカー設定を比較することで、必要に応じて調整を行うことができます。
重要!
インスタンスプールを使っているのであれば:
- プールにおけるアイドルインスタンスの最小数以下のクラスターサイズになっていることを確認してください。これよりも大きい場合、クラスターの起動時間はプールを使用しないクラスターと同じものになります。
- クラスターの最大サイズはプールの最大キャパシティ以下になる様にしてください。
オートスケーリングの例
静的なクラスターをオートスケーリングクラスターに再設定した場合、Databricksは即時にクラスターを最小、最大の境界に収まるようにリサイズし、オートスケーリングをスタートします。例として、以下のテーブルでは特定の初期サイズのクラスターに対して、5ノード、10ノードの間にオートスケールさせるように再設定した際に何が起きるのかを示しています。
| 初期サイズ | 再設定後のサイズ |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
ローカルディスクの暗号化
プレビュー
この機能はパブリックプレビューです。
クラスターを実行する際に使用するいくつかのインスタンスタイプでは、ローカルにアタッチされたディスクが存在します。Databricksは、シャッフルデータや短期データをこれらのローカルにアタッチされたディスクに保存します。クラスターのローカルディスクに一時的に保存されるシャッフルデータを含む、全てのストレージタイプにおいて保存されている全てのデータが暗号化される様に、ローカルディスクの暗号化を有効化することができます。
重要!
ローカルボリュームとの暗号化データの読み書きによるパフォーマンスのインパクトによって、ワークロードが遅くなる可能性があります。
ローカルディスクの暗号化が有効化されると、Databricksはローカルにそれぞれのクラスターノードに固有の暗号化キーを生成し、ローカルディスクに保存される全てのデータの暗号化にキーを使用します。キーのスコープはそれぞれのクラスターノード固有で、クラスターノードとともに破棄されます。このライフタイムの期間において、暗号化、複合化のためにキーはメモリー上に保持され、ディスク上に暗号化された状態で格納されます。
ローカルディスクの暗号化を有効化するには、Clusters APIを使用する必要があります。クラスターの作成、編集の際に以下を設定します。
{
"enable_local_disk_encryption": true
}
これらのAPIの呼び出し方の例含めたCluster APIのリファレンスに関しては、Create、Editを参照ください。
以下がローカルディスク暗号化を有効化したcluster createの呼び出し例です。
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "r3.xlarge",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
セキュリティモード
ワークスペースがUnity Catalogに割り当てられている場合、アクセスコントロールの一貫性を保証し、強力なアイソレーション保証を強制するためには、ハイコンカレンシークラスターモードではなくセキュリティモードを使用します。
Advanced optionsで、以下のクラスターセキュリティモードを選択します。
- None: アイソレーションはありません。ワークスペースローカルのテーブルアクセスコントロールやクレディンシャルパススルーを強制しません。Unity Catalogデータにアクセスすることはできません。
- Single User: 単一のユーザーだけが使用できます(デフォルトではクラスターの作成者となります)。他のユーザーはクラスターにアタッチすることはできません。Single Userセキュリティモードのクラスターからビューにアクセスする際には、ビューはユーザーの権限で実行されます。シングルユーザークラスターは、Python、Scala、Rを用いたワークロードをサポートしています。シングルユーザークラスターではinitスクリプト、ライブラリのインストール、DBFSマウントがサポートされています。自動化ジョブではシングルユーザークラスターを使う必要があります。
- User Isolation: 複数のユーザーで共有できます。SQLワークロードのみがサポートされています。クラスターユーザー間における厳密な分離を強制するために、ライブラリのインストール、initスクリプト、DBFSマウントは無効化されています。
- Table ACL only (Legacy): ワークスペースレベルのテーブルアクセスコントロールを強制しますが、Unity Catalogのデータにはアクセスすることはできません。
- Passthrough only (Legacy): ワークスペースレベルのクレディンシャルパススルーを強制しますが、Unity Catalogのデータにアクセスすることはできません。
Unity CatalogワークロードをサポートしているセキュリティモードはSingle UserとUser Isolationのみとなります。
詳細に関しては、What is cluster access mode?をご覧ください。
AWSの設定
クラスターのAWSインスタンスを設定する際、アベイラビリティゾーン、最大のスポット価格、EBSボリュームタイプおよびサイズ、インスタンスプロファイルを選択することができます。これらの設定を行うには以下の手順を踏みます。
- クラスター設定ページで、Advanced Optionsトグルをクリックします。
- ページの下部で、Instanceタブをクリックします。

アベイラビリティゾーン
クラスターに対して特定のアベイラビリティゾーン(AZ)を選択することは、お客様の組織で特定のアベイラビリティゾーンでリザーブドインスタンスを購入している場合には特に有用となります。詳細に関してはAWS availability zonesを参照ください。
自動アベイラビリティゾーン(Auto-AZ)
ワークスペースのサブネットで利用できるIPアドレスに基づいて、クラスターが自動でアベイラビリティゾーンを選択する様に設定することができます、これは「Auto-AZ」と呼ばれる機能となります。Auto-AZを有効化するにはClusters APIを使用し、awsattributes.zone_id = "auto"を設定する必要があります。Auto-AZは、AWSがキャパシティ不足エラーを返した際に他のAZでリトライします。
スポットインスタンス
スポットインスタンスを使用し、オンデマンドインスタンスの価格に対するパーセンテージとしてスポットインスタンスを起動する際に使用するスポットインスタンスの最高価格を指定することができます。デフォルトでは、オンデマンド価格の100%が最高価格となります。詳細はAWS spot pricingを確認ください。
EBSボリューム
ここでは、ワーカーノードのデフォルトEBSボリューム設定、シャッフルボリュームの追加方法、Databtricksが自動でEBSボリュームを配置する様に設定する方法を説明します。
EBSボリュームを設定するには、クラスター設定のInstancesタブをクリックし、EBS Volume Typeドロップダウンリストからオプションを選択します。
デフォルトEBSボリューム
Databricksはすべてのワーカーノードに対して以下のEBSボリュームを配備します。
- ホストのオペレーティングシステムとDatabricksの内部サービスでのみ使用される30GBの暗号化EBSインスタンスルートボリューム。
- Sparkワーカーで使用される150GBの暗号化EBSコンテナルートボリューム。ここでSparkサービスとログがホストされます。
- (HIPAAのみ)Databricks内部サービス向けのログを格納する75GBの暗号化EBSワーカーログボリューム。
EBSシャッフルボリュームの追加
シャッフルボリュームを追加するには、EBSボリュームタイプドロップダウンリストでGeneral Purpose SSDを選択します。
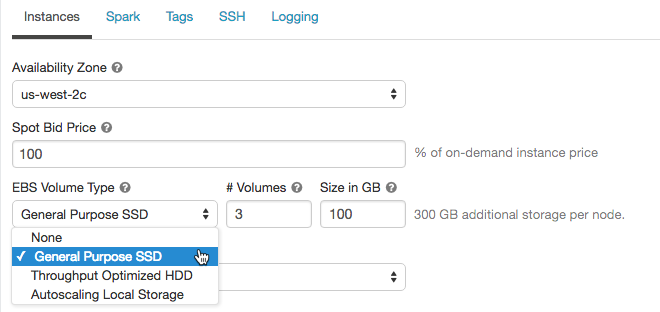
デフォルトでは、Sparkのシャッフルはインスタンスのローカルディスクに出力されます。ローカルディスクを持たないインスタンスタイプにおいて、あるいは、Sparkのシャッフルストレージスペースを拡張したい場合には、追加のEBSボリュームを指定することができます。これは特に、Sparkジョブが大容量のシャッフルアウトプットを生成する際に、ディスクスペースエラーを防ぐために有効です。
Databricksはオンデマンド、スポットインスタンスの両方でEBSボリュームを暗号化します。詳細は、AWS EBS volumesを参照ください。
顧客管理キーによるDatabricks EBSボリュームの暗号化(オプション)
オプションで、クラスターのEBSボリュームを顧客管理キーで暗号化することができます。
Customer-managed keys for workspace storageを参照ください。
AWS EBSのリミット
全てのクラスターにおける全てのワーカーに対するランタイムの要件を十分に満足できる様にAWS EBSのリミットが十分に高いものであることを確認してください。デフォルトのEBSリミットに関する情報、および、リミットの変更方法に関しては、Amazon Elastic Block Store (EBS) Limitsを参照ください。
AWS EBS SSDボリュームタイプ
AWS EBS SSDのボリュームタイプに対してgp2あるいはgp3を選択することができます。これを行うためには、Manage SSD storageを参照ください。gp2に比べてコストを削減できるのでgp3に切り替えることをお勧めします。gp2、gp3に関する技術情報については、Amazon EBS volume typesを参照ください。
ローカルストレージのオートスケーリング
クラスター作成時に固定数のEBSボリュームを割り当てたくない場合には、ローカルストレージのオートスケーリングを使用してください。ローカルストレージをオートスケーリングを活用することで、Databricksはお使いのクラスターのSparkワーカーにおけるディスク領域の空き容量をモニターします。ワーカーのディスクの空き容量が少なくなってくると、ディスク容量が枯渇する前に、Databricksは自動で新規EBSボリュームをアタッチします。EBSボリュームはインスタンスに対して最大5TB(インスタンスのローカルストレージを含む)までアタッチすることができます。
オートスケーリングのストレージを設定するには、Autopilot OptionボックスでEnable autoscaling local storageを選択します。

インスタンスにアタッチされたEBSボリュームは、AWSにインスタンスが返却される際にのみデタッチされます。すなわち、クラスターが稼働し続ける限りEBSボリュームはインスタンスから決してデタッチされません。EBS使用量を削減するには、GPUインスタンスタイプや自動停止が設定されたクラスターで本機能を使うことをお勧めします。
注意
Databricksは、インスタンスのローカルストレージを拡張する際にはスループット最適化HDD(st1)を使用します。これらのボリュームのデフォルトのAWSキャパシティリミットは20TBです。リミットを超過しないようにするには、使用量の要件に基づき、管理者はリミットを増加させるためのリクエストをする必要があります。
注意
Databricksアカウントをバージョン2.44以前(2017/4/27以前)に作成し、ローカルストレージのオートスケーリングを有効化したい場合(デフォルトではHigh Concurrencyクラスターでのみ有効になっています)には、IAMロールあるいはアカウントを作成時に使用したキーに対して、ボリュームのアクセス権を追加する必要があります。特に、ec2:AttachVolume、ec2:CreateVolume、ec2:DeleteVolume、ec2:DescribeVolumesを追加しなくてはなりません。既存のIAMロール、キーをアップデートする方法については、Create a cross-account IAM roleを参照ください。
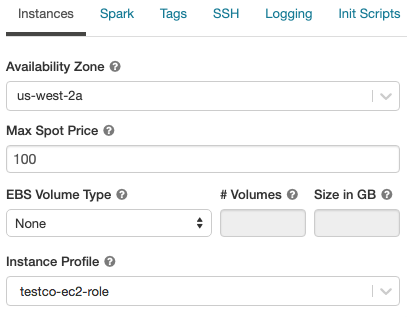
インスタンスプロファイル
AWSキーを使わずにセキュアにAWSのリソースにアクセスするためには、Databricksクラスターにインスタンスプロファイルを追加して起動します。どのようにインスタンスプロファイルを作成し設定するのかに関しては、Databricksにおけるインスタンスプロファイルを用いたS3バケットへのセキュアなアクセスを参照ください。インスタンスプロファイルを作成した後で、インスタンスプロファイルのドロップダウンリストから選択することができます。
注意
インスタンスプロファイルを追加してクラスターを起動すると、このクラスターに対するアタッチ権限を持つユーザーは誰でも、このロールを用いて背後のリソースにアクセスすることができます。望まれないアクセスを防御するには、クラスターへのアクセス権を制限するためにクラスターアクセスコントロールを使用してください。
Sparkの設定
Sparkジョブをファインチューニングするには、クラスター設定でSpark configuration propertiesをカスタマイズします。
- クラスター設定ページでAdvanced Optionsトグルをクリックします。
-
Sparkタブをクリックします。

Spark configで、一行ごとにキーバリューのペアとして設定プロパティを入力します。
Clusters APIを用いてクラスターを設定する際には、Create cluster requestあるいはEdit cluster requestにおけるspark_confフィールドにSparkプロパティを設定します。
全てのクラスターに対してSparkプロパティを設定するには、グローバルinitスクリプトを使用します。
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
シークレットからSpark設定プロパティを取得する
パスワードの様なセンシティブな情報は平文ではなくシークレットに保存することをお勧めします。Spark設定でシークレットを参照するには、以下の構文を使用します。
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
例えば、secrets/acme_app/passwordのシークレットに保存されている値を、passwordというSpark設定プロパティに設定するには以下の設定を行います。
spark.password {{secrets/acme-app/password}}
詳細については、Syntax for referencing secrets in a Spark configuration property or environment variableをご覧ください。
環境変数
クラスターで動作するinitスクリプトからアクセスできる環境変数を設定することができます。また、Databricksではinitスクリプトで使用できる定義済み環境変数を提供しています。定義済み環境変数を上書きすることはできません。
- クラスター設定ページで、Advanced Optionsトグルをクリックします。
- Sparkタブをクリックします。
-
Environment Variablesフィールドに環境変数を設定します。

Clusters APIエンドポイントのCreate cluster requestやEdit cluster requestのspark_env_varsフィールドを使って環境変数を設定することもできます。
クラスタータグ
クラスタータグを用いることで、企業内の様々なグループにおいて使用されるクラウドリソースのコストを容易にモニタリングできる様になります。クラスターを作成する際にキーバリューのペアでタグを指定でき、DatabricksはVMやディスクボリューム、DBU使用量レポートにタグを適用します。
プールから起動されるクラスターに関しては、DBU使用量レポートのみに適用されるカスタムクラスタータグのみが適用され、クラウドリソースには伝播しません。プールとクラスタータグのタイプがどの様に動作するかに関しては、Monitor usage using cluster and pool tags を参照ください。
Databricksはデフォルトで4つのタグ、Vendor、Creator、ClusterName、ClusterIdを適用します。
さらに、ジョブクラスターでは、DatabricksはRunNameとJobIdの2つのデフォルトタグを適用します。Databricks SQLで使用されるリソースに関しては、DatabricksはSqlEndpointIdのデフォルトタグを適用します。
警告!
キーがNameであるカスタムタグをクラスターに割り当てないでください。全てのクラウsターには、Databricksによって設定されるNameタグが存在します。キーNameを持つ値を変更すると、Databricksによってクラスターが追跡されなくなります。結果として、クラスターがアイドル状態になった後でも停止されず、使用量が発生し続けることになります。
クラスター作成時にカスタムタグを追加することができます。クラスタータグを設定するには以下の手順を踏みます。
- クラスター設定ページで、Advanced Optionsトグルをクリックします。
- ページ下部でTagタブをクリックします。

- それぞれのカスタムタグごとにキーバリューペアを追加します。カスタムタグは45個まで追加できます。
詳細については、Monitor usage using cluster and pool tagsをご覧ください。
必須タグの強制
クラスター作成時に常に特定のタグが追加される様にするために、お使いのアカウントのプライマリーIAMロール(アカウントセットアップに使用したもの。アクセスが必要な場合にはご自身のAWS管理者にコンタクトしてください)に特定のIAMポリシーを適用することができます。IAMポリシーには、必須のタグのキーおよびオプションの値に対する明示的なDeny文を含める必要があります。許可された必須タグが指定されていない場合、クラスターの作成は失敗します。
例えば、Department、Projectタグを強制したいケースで、前者では特定の値、後者ではフリーフォームで何かしらの入力を強制する場合、以下の様なIAMポリシーを適用することができます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "MandateLaunchWithTag1",
"Effect": "Deny",
"Action": [
"ec2:RunInstances",
"ec2:CreateTags"
],
"Resource": "arn:aws:ec2:region:accountId:instance/*",
"Condition": {
"StringNotEqualsIgnoreCase": {
"aws:RequestTag/Department": [
"Deptt1", "Deptt2", "Deptt3"
]
}
}
},
{
"Sid": "MandateLaunchWithTag2",
"Effect": "Deny",
"Action": [
"ec2:RunInstances",
"ec2:CreateTags"
],
"Resource": "arn:aws:ec2:region:accountId:instance/*",
"Condition": {
"StringNotLike": {
"aws:RequestTag/Project": "?*"
}
}
}
]
}
それぞれのタグが、オンデマンドインスタンスのみのクラスター、スポットインスタンスのみのクラスター、両方から構成されるクラスターがある際のシナリオに対してec2:RunInstancesとec2:CreateTagsアクションの両方が必要となります。
ティップス
タグごとに別のポリシー文を追加することをお勧めします。全体的なポリシーは若干読みにくいものになりますが、デバッグしやすいものとなります。ポリシーで使用できるオペレーターのリストについては、IAM Policy Condition Operators Referenceを参照ください。
注意
IAMポリシーのために、クラスター作成エラーがエンコードされたエラーメッセージとなります。
Cloud Provider Launch Failure: A cloud provider error was encountered while setting up the cluster.
アクションをリクエストしたユーザーが見るべきではない権限管理された情報から構成される認証ステータスの詳細である場合があるため、エンコードされたメッセージとなります。この様なメッセージをどの様にデコードするかについては、DecodeAuthorizationMessage API(あるいはCLI)を参照ください。
クラスターへのSSH接続
注意
セキュアクラスター接続が有効化されるクラスターにはSSHでログインすることができません。
SSHを用いることで、高度なトラブルシュートやカスタムソフトウェアをインストールするために、リモートからApache Sparkクラスターにログインすることができます。
関連する機能に関しては、Web terminalを参照ください。
ここでは、お使いの公開鍵を用いてどのようにAWSアカウントでイングレスアクセスを有効化するのか、どのようにクラスターノードに対してSSH接続をオープンするのかを説明します。
セキュリティグループの設定
SSH接続を行うIPアドレスからのイングレスアクセスを許可するために、お使いのAWSアカウントでDatabircksのセキュリティグループをアップデートする必要があります。ここでは、単一のIPアドレスあるいはオフィス全体のIPアドレスを表現するレンジを指定することができます。
- AWSコンソールで、Databricksのセキュリティグループを見つけます。
<databricks-instance>-worker-unmanagedといったラベルとなっています。(例:dbc-fb3asdddd3-worker-unmanaged) - セキュリティグループを編集し、ワーカーマシンに対するポート
2200を許可するインバウンドTCPルールを追加します。単一のIPアドレス、あるいはレンジを指定できます。

- お使いのコンピューターとオフィスが、ポート
2200に対してTCPトラフィックを送信できることを確認します。
SSHキーペアの作成
ターミナルセッションで以下のコマンドを実行しSSHのキーペアを作成します。
ssh-keygen -t rsa -b 4096 -C "email@example.com"
公開鍵、秘密鍵を保存するためのディレクトリへのパスを指定する必要があります。公開鍵は拡張子.pubで保存されます。
公開鍵を用いた新規クラスターの設定
- 公開鍵ファイルの全てのコンテンツをコピーします。
- クラスター設定ページで、Advanced Optionsトグルをクリックします。
- ページ下部で、SSHタブをクリックします。
- コピーした鍵をSSH Public Keyフィールドに貼り付けます。

公開鍵を用いた既存クラスターの設定
クラスターがすでにあり、クラスター作成時に公開鍵を指定しなかった場合には、クラスターにアタッチされたノートブックで以下のコードを実行することで、公開鍵を注入することができます。
val publicKey = " put your public key here "
def addAuthorizedPublicKey(key: String): Unit = {
val fw = new java.io.FileWriter("/home/ubuntu/.ssh/authorized_keys", /* append */ true)
fw.write("\n" + key)
fw.close()
}
val numExecutors = sc.getExecutorMemoryStatus.keys.size
sc.parallelize(0 until numExecutors, numExecutors).foreach { i =>
addAuthorizedPublicKey(publicKey)
}
addAuthorizedPublicKey(publicKey)
SparkドライバーノードへのSSH接続
-
クラスター設定ページで、Advanced Optionsトグルをクリックします。
-
SSHタブをクリックします。ドライバーノードのホスト名をコピーします。
-
以下のコマンドを実行します。ホスト名と秘密鍵のファイルパスは置換してください。
Bashssh ubuntu@<hostname> -p 2200 -i <private-key-file-path>
SparkワーカーノードへのSSH接続
ドライバーノードへのSSH接続と同じ方法でワーカーノードに接続することができます。
- クラスター詳細ページで、Spark Cluster UI - Masterタブをクリックします。
- Workers Tableで、SSH接続したいワーカーをクリックします。ホスト名フィールドをコピーします。

クラスターログデリバリー
クラスターを作成する際、Sparkドライバーノード、ワーカーノード、イベントに対するログを配信する場所を指定することができます。指定された場所に5分間隔でログが配信されます。クラスターが停止されると、Databricksはクラスターが停止されるまでに生成された全てのログが配信されることを保証します。
ログの格納場所はクラスターIDに依存します。指定された場所がdbfs:/cluster-log-deliveryの場合、0630-191345-leap375に対するクラスターログはdbfs:/cluster-log-delivery/0630-191345-leap375に配信されます。
クラスターログ配信の場所を設定するには、以下の手順を踏みます。
- クラスター設定ページで、Advanced Optionsトグルをクリックします。
-
Loggingタブをクリックします。

- destinationのタイプを選択します。
- クラスターログのパスを入力します。
S3バケットの格納場所
S3を格納場所に選択した際には、バケットにアクセスできる様に設定されたインスタンスプロファイルをクラスターに設定する必要があります。このインスタンスプロファイルにはPutObjectとPutObjectAclの両方が必要となります。サンプルのインスタンスプロファイルを以下に示します。どのようにインスタンスプロファイルを設定するのかについては、Databricksにおけるインスタンスプロファイルを用いたS3バケットへのセキュアなアクセスを参照ください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<my-s3-bucket>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<my-s3-bucket>/*"
]
}
]
}
注意
この機能はREST APIでも使用できます。Clusters APIとCluster log delivery examplesを参照ください。
initスクリプト
クラスターノードの初期化、あるいはinitスクリプトはSparkドライバー、ワーカーのJVMがスタートする前にそれぞれのクラスターノードのスタートアップ時に実行されるシェルスクリプトです。Databricksランタイムに含まれていないパッケージ、ライブラリをインストールしたり、JVMのシステムclasspathを変更したり、JVMで使用されるシステムプロパティ、環境変数を設定したり、Spark設定パラメータなどを変更するのにinitスクリプトを使用することができます。
Advanced Optionsセクションを展開し、Init Scriptsタブをクリックすることで、initスクリプトをアタッチすることができます。
詳細に関しては、Databricksクラスターノード初期化スクリプトを参照ください。