Databricksクイックスタートガイドのコンテンツです。
Secure access to S3 buckets using instance profiles | Databricks on AWS [2021/12/21時点]の翻訳です。
IAMロール(英語)はAWS上で何ができて、何ができないかを定義する許可ポリシーを伴うAWSのアイデンティティです。インスタンスプロファイル(英語)は、EC2インスタンスが起動する際にロール情報を引き渡すことができるIAMロールのコンテナです。
AWSのリソースにセキュアにアクセスするためには、ノートブックにAWSのキーを埋め込むのではなく、起動するDatabricksクラスターに対して、データへのアクセスを許可したインスタンスプロファイルを指定することができます。本書では、どのようにインスタンスプロファイルを設定し、S3にセキュアにアクセスするためにどのようにDatabricksで設定するのかを説明します。
注意
S3バケットにアクセスするための別の方法として、個々のユーザーのIAMロールをDatabricksに引き渡し、S3内のデータへのアクセスに個々のIAMロールを用いるIAMクレディンシャルパススルーが存在します。これにより、異なるユーザーに異なるデータアクセスポリシーを適用することができます。一方で、インスタンスプロファイルは単一のIAMロールを関連づけるため、Databricksクラスターのユーザーは同じロールとデータアクセスポリシーを共有することになります。詳細に関しては、Access S3 buckets using IAM credential passthrough with Databricks SCIM(英語)を参照ください。
前提
- Databricks環境を構築したAWSアカウントおよびS3バケットのAWSアカウントにおいて、IAMロールとポリシーにアクセスするためのAdministrator権限が必要です。
- 接続先のS3バケットはDatabricks環境のAWSアカウントと同一である必要があります。S3のAWSアカウントが異なる場合には、DatabricksがデプロイされたAWSアカウントからS3バケットへのアクセスを許可するクロスアカウントバケットポリシーの設定が必要です。
- S3バケットを暗号化している場合には、設定に用いたKMSキーのKey UserとしてIAMロールを追加する必要があります。詳細はs3a://パスに対するKMS暗号化の設定を参照ください。
ステップ1 S3バケットにアクセスするためのインスタンスプロファイルを作成する
-
AWSコンソールからIAMに移動します
-
ロールを開きます
-
ロールの作成をクリックします。
-
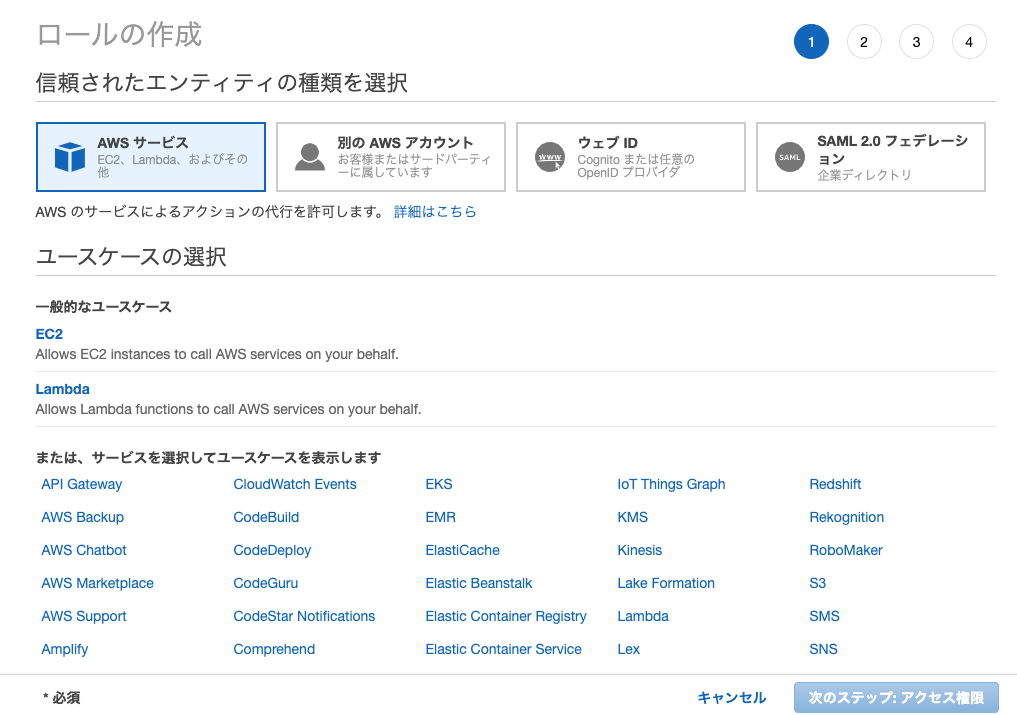
信頼されたエンティティの種類を選択からAWSサービスを選択します。
-
ユースケースの選択からEC2を選択します。
-
アクセス権限、タグ、確認の順にクリックします。
-
ロール名を入力します。
-
ロールの作成をクリックします。ロール一覧が表示されます。
-
-
ロール一覧から作成したロールを選択します。
-
ロールにインラインポリシーを追加します。このポリシーでS3バケットへのアクセスを許可します。
-
アクセス権限タブでインラインポリシーの追加をクリックします。
-
JSONタブをクリックします。
-
以下の内容を貼り付けます。
<s3-bucket-name>には接続先のS3バケット名を指定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::/*"
]
}
]
}
```- ポリシーの確認をクリックします。
- ポリシー名を入力します。
- ポリシーの作成をクリックします。
-
-
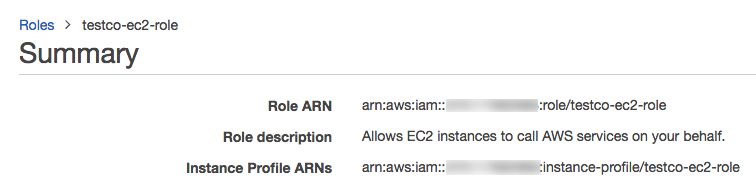
ロールの概要に進み、インスタンスプロファイルARNをコピーしておきます。
ステップ2 接続先S3バケットのパケットポリシーを作成する
接続先S3のポリシーには、最低限ListBucketとGetObjectのアクションを含める必要があります。
重要!
ステップ7 クロスアカウントS3 ACLの更新を実行する際には、バケットの全てのデータに対するバケットオーナーのアクセス権を設定するために、s3:PutObjectAclが必要となります。
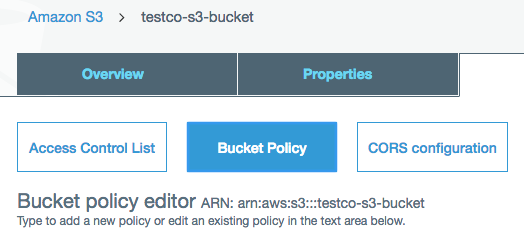
- 接続先S3バケットポリシーに以下の内容を貼り付けます。
<aws-account-id-databricks>にはDatabricks環境を構築したAWSのアカウントIDを指定します。<iam-role-for-s3-access>には、ステップ1で作成したIAMロールを指定します。<s3-bucket-name>には接続先S3バケット名を指定します。 - 貼り付け後、Saveをクリックします。
S3バケットポリシーに貼り付ける内容
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Example permissions",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>"
},
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::<s3-bucket-name>"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>"
},
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::<s3-bucket-name>/*"
}
]
}
ステップ3 Databricks環境構築に用いたIAMロールをメモする
ここでのIAMロールは、Databricksアカウントをセットアップした際のロールとなります。
あなたのアカウントがE2アカウント(英語)である場合は:
-
アカウントオーナーとして、Account Console(英語)にログインします。
-
Workspaceに移動し、ワークスペース名をクリックします。
-
Credentialsボックス内に記載されているRole ARNの最後にあるロール名をメモします。
例えば、Role ARNが
arn:aws:iam::123456789123:role/finance-prodであれば、finance-prodがロール名になります。
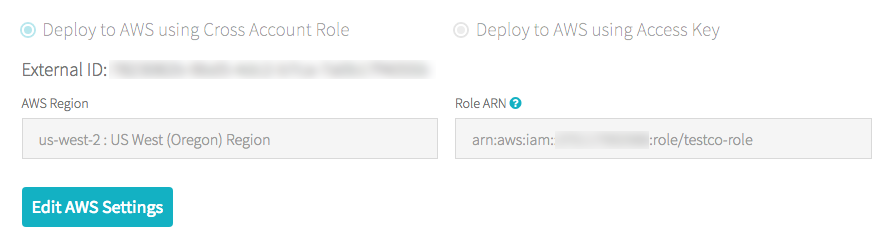
あなたのアカウントがE2アカウントでない場合は:
- アカウントオーナーとしてAccount Consoleにログインします。
- AWS Accountタブを開きます。
- ARNの最後にあるロール名をメモします。以下の例ではtesco-roleがロール名になります。
ステップ4 S3 IAMロールをEC2ポリシーに追加する
- AWSコンソールでIAMに移動します
- サイドバーからロールを開きます
- ステップ3で記録した(Databricks構築に用いた)ロールを開きます
- ステップ1で作成したIAMロールをSparkクラスターのEC2に引き渡せるように、アクセス権限のポリシーを編集します。以下の例では
<iam-role-for-s3-access>をステップ1で作成したロールで置換します。 - 編集後、確認の上、「変更を保存」をクリックします。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreateKeyPair",
"ec2:CreatePlacementGroup",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeleteKeyPair",
"ec2:DeletePlacementGroup",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePlacementGroups",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>"
},
{
"Effect": "Allow",
"Action": [
"iam:CreateServiceLinkedRole",
"iam:PutRolePolicy"
],
"Resource": "arn:aws:iam::*:role/aws-service-role/spot.amazonaws.com/AWSServiceRoleForEC2Spot",
"Condition": {
"StringLike": {
"iam:AWSServiceName": "spot.amazonaws.com"
}
}
}
]
}
上の例での追記箇所はこちらとなります。
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-access>"
},
注意
E2バージョンのDatabricksプラットフォームを使用している場合には、ec2:CreateKeyPairとec2:DeleteKeyPairを省略できます。アカウントのバージョンが不明の場合には、Databricks担当にお問い合わせください。
ステップ5 Databricksにインスタンスプロファイルを追加する
-
Admin Console(英語)に移動します。
-
Instance Profileタブを開きます。
-
Add Instance Profileをクリックするとダイアログが表示されます。
-
ステップ1で作成したインスタンスプロファイルARNを貼り付けます。

IAM credential passthrough(英語)をセットアップする際にのみMeta Instance Profileにチェックを付けます。DatabricksはインスタンスプロファイルARNが文法、内容的に正しいかを検証します。内容の正当性を確認するために、Databricksは指定されたインスタンスプロファイルを用いてクラスターのドライランを実行します。ドライランでのエラーは、validationエラーとしてUIに表示されます。インスタンスプロファイルが
tag-enforcementポリシーを含む場合、検証がエラーとなり正当なインスタンスプロファイルの追加ができないことになります。検証がエラーとなったとしても、インスタンスプロファイルを追加したい場合には、Skip Validationをチェックしてください。 -
Addをクリックします。
-
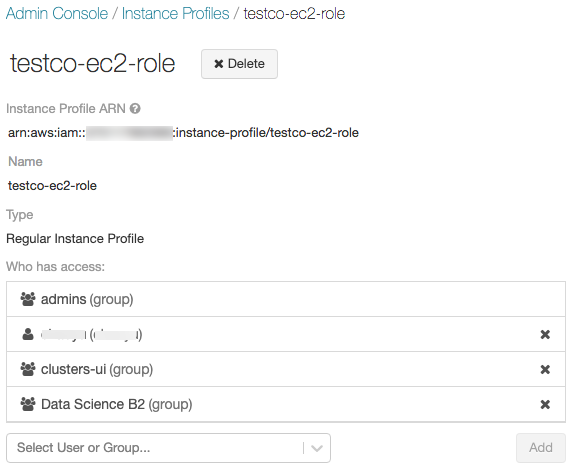
オプションとして、このインスタンスプロファイルを指定してクラスターを起動できるユーザーを指定できます。
ステップ6 インスタンスプロファイルを指定してクラスターを起動する
-
クラスターを選択、あるいは作成します。
-
Advanced Optionsを開きます。
-
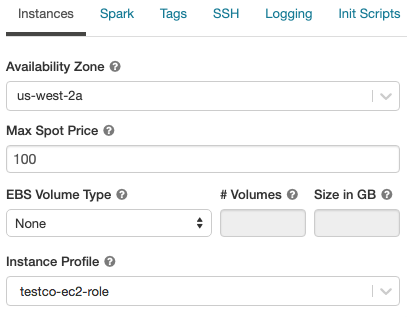
Instanceタブで、Instance Profileドロップダウンリストからインスタンスプロファイルを選択します。ドロップダウンにはクラスターで利用可能なインスタンスプロファイル全てが表示されます。
-
以下のコマンドを実行してS3バケットにアクセスできるか確認します。成功した場合には、ステップ7に進んでください。
dbutils.fs.ls("s3a://<s3-bucket-name>/")
警告!
インスタンスプロファイルを指定してクラスターが起動したあとは、クラスターに対してattach permission(英語)権限を持つ人は誰でも、ロールで許可されているリソースにアクセスすることができます。望まれないアクセスを制限するためには、クラスターのACLでattach permissionを制限できます。
ステップ7 クロスアカウントS3 ACLの更新
同じAWSアカウント内のS3バケットに書き込みを行なっている場合、この先に進む必要はありません。
クロスアカウントのS3バケットのファイルに書き込みを行う際には、デフォルトの設定では当該ファイルにのみアクセスを許可します。あなた自身のバケットにファイルを書き込むことを前提にしており、このデフォルト設定はあなたのデータを保護します。バケットオーナーに対してバケット内の全てのオブジェクトにアクセスを許可するためには、Databricksによって書き込みが行われるオブジェクトにBucketOwnerFullControlACLを追加する必要があります。
-
クラスター詳細ページのSparkタブで、以下のプロパティを設定します
ini
spark.hadoop.fs.s3a.acl.default BucketOwnerFullControl
```
- S3バケットに書き込みができていることを確認し、Databricksによって書き込まれたコンテンツに他のユーザーやツールがアクセスできるかアクセス権を確認します。
Terraformを用いた設定の自動化
AWSのIAMロールとクラスターへのアタッチメントの設定を自動化するために、Databricks Terraform providerを活用することができます。以下に、適切な設定サンプルを示します。ここではシンプルにするために他のリソースを省略しています。
resource "aws_iam_role" "data_role" {
name = "${var.prefix}-first-ec2s3"
description = "(${var.prefix}) EC2 Assume Role role for S3 access"
assume_role_policy = data.aws_iam_policy_document.assume_role_for_ec2.json
tags = var.tags
}
resource "aws_iam_instance_profile" "this" {
name = "${var.prefix}-first-profile"
role = aws_iam_role.data_role.name
}
resource "databricks_instance_profile" "ds" {
instance_profile_arn = aws_iam_instance_profile.this.arn
}
data "databricks_node_type" "smallest" {
local_disk = true
}
data "databricks_spark_version" "latest_lts" {
long_term_support = true
}
resource "databricks_cluster" "shared_autoscaling" {
cluster_name = "Shared Autoscaling"
spark_version = data.databricks_spark_version.latest_lts.id
node_type_id = data.databricks_node_type.smallest.id
autotermination_minutes = 20
autoscale {
min_workers = 1
max_workers = 50
}
aws_attributes {
instance_profile_arn = databricks_instance_profile.ds.id
}
}
FAQ
クラスターを作成する際にインスタンスプロファイルが表示されません
あなたが管理者であるならば、Admin Consoleに移動し、ステップ5 Databricksにインスタンスプロファイルを追加するを実施してください。そうでない場合には、管理者に問い合わせてください。
クレディンシャルを格納するのにマウントポイントを使っています。インスタンスプロファイルが設定されたクラスターでマウントポイントはどのように動作しますか?
インスタンスプロファイルを持たないクラスターと同じように既存のマウントポイントは動作します。インスタンスプロファイルを設定したクラスターを起動した際に、以下のコマンドを実行することで、クレディンシャルを引き渡すことなしにS3バケットをマウントすることも可能です。
dbutils.fs.mount("s3a://${pathtobucket}", "/mnt/${MountPointName}")