Databricksクイックスタートガイドのコンテンツです。
Databricks architecture overview | Databricks on AWS [2021/4/12時点]の翻訳です。
Apache Sparkの開発者が提供する、Databricksの統合分析プラットフォームは、世界中の困難な問題に取り組むデータチームのコラボレーションを実現します。
以下のようなユースケースにおいて、データサイエンティスト、データエンジニア、データアナリストがコラボレーションする際に、Databricksが効果を発揮します:
- スケーラビリティが求められる高度な機械学習、グラフ処理に取り組む
- ディープラーニングを活用して、非構造化データに対する画像解釈、自動翻訳、自然言語処理などを実現する
- データウェアハウスの高速化、簡素化、高スケーラビリティの確保
- データサイエンスとAIによる脅威の早期検知
- IoTデータのリアルタイム分析
- GDPR対応の円滑化
ハイレベルのアーキテクチャ
Databricksが大量のバックエンドサービスを管理しつつも、セキュアな機能横断チームのコラボラーションを実現するように構成されているので、あなたはデータサイエンス、データ分析、データエンジニアリングの作業に集中できます。
アーキテクチャは独自の設定に依存しますが、以下の図はAWS環境において最も一般的な構成と、データフローを示したものです。
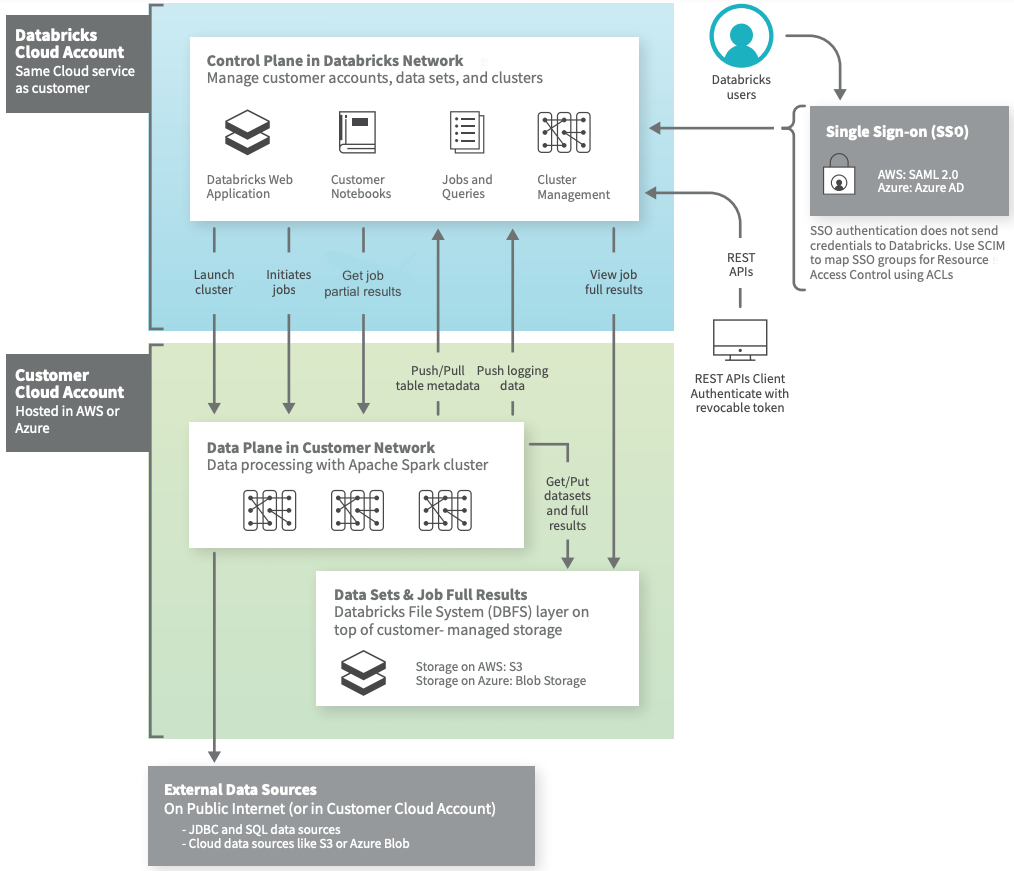
Databricksはコントロールプレーンとデータプレーンから構成されています。
コントロールプレーンには、DatabricksのAWSアカウント上でDatabricksが管理するバックエンドサービスが含まれます。あなたが実行する全てのコマンド(ノートブックのセル)は、完全に暗号化された状態でコントロールプレーンに存在することになります。保存されたコマンドはデータプレーンに格納されます。
データプレーンはあなたのAWSアカウントで管理され、あなたのデータが格納される場所になります。また、ここでデータが処理されます。この図では、既にデータがDatabricksに登録されていることを仮定していますが、イベントデータ、ストリーミングデータ、IoTデータなど外部のデータソースからデータを取り込むことが可能です。Databricksコネクターを用いることで、あなたのAWSアカウント外の外部データソースにも接続することができます。
あなたのデータは常に、データプレーンのあなたのAWSアカウントに存在します。このため、あなたのデータがロックインされることなく、常にフルコントロール、オーナーシップを維持することができます。
E2アーキテクチャ
2020年9月にDatabricksはE2バージョンのプラットフォームをリリースしました。E2プラットフォームには、以下の機能が含まれます:
- マルチワークスペースアカウント: Account APIを用いることで、一つのアカウントに対して複数のワークスペースを作成できます。
- 顧客管理のVPC: Databricksが作成するVPCでワークスペースを作成するのではなく、あなたが管理するVPCにワークスペースを作成することができます。
- セキュアなクラスター接続: "No Public IP"とも呼ばれる機能です。全てのノードがプライベートIPアドレスのみを持つ状態でクラスターを起動でき、より高いセキュリティを実現できます。
- ノートブックに対する顧客管理の鍵: (パブリックプレビュー)Databricksが管理するコントロールプレーンに独自のKMSキーを導入できます。
トークン管理、IPアクセスリスト、クラスターポリシー、IAMクレディンシャルパススルーの機能によって、E2アーキテクチャは、AWS上のDatabricksプラットフォームをよりセキュア、スケーラブルにし、管理を容易にします。
特定のお客様を除いて、新たなDatabricksアカウントはE2プラットフォーム上に作成されます。お持ちのアカウントがE2かどうか分からない場合には、Databricks担当までお問い合わせください。