Databricks File System (DBFS) | Databricks on AWS [2022/1/23時点]の翻訳です。
Databricksクイックスタートガイドのコンテンツです。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksファイルシステム(DBFS)は、Databricksワークスペースにマウントされる分散ファイルシステムであり、Databricksクラスターで利用することができます。DBFSはスケーラブルなオブジェクトストレージの抽象化レイヤーであり、以下のメリットを提供します。
- クレディンシャルなしにデータにシームレスにアクセスできるようにストレージをマウントすることができます。
- ストレージURLではなく、ディレクトリとファイルの文法を用いてオブジェクトストレージを操作することができます。
- オブジェクトストレージにファイルを永続化するので、クラスターを停止してもデータを失うことはありません。
DBFSのアクセス権に関する重要な情報
DBFSルートを除き、DBFSにマウントされたオブジェクトストレージのオブジェクトに対してすべてのユーザーが読み書きのアクセス権を持ちます。
しかし、インスタンスプロファイルを用いてマウントが作成されている場合、IAMロールが許可するユーザーのみがアクセス権を持ち、当該インスタンスプロファイルを使用するように設定されたクラスターのみがアクセスすることができます。このため、インスタンスプロファイルを用いて作成されたマウントにはDBFS CLIでアクセスすることはできません。
DBFSルート
DBFSのデフォルトストレージの場所をDBFSルートと呼びます。以下のDBFSルートのディレクトリにはいくつかの種類のデータが格納されます。
-
/FileStore: インポートされたデータファイル、生成されたプロット、アップロードされたライブラリが格納されます。特殊なDBFSルートのディレクトリを参照ください。 -
/databricks-datasets: パブリックなサンプルデータセットが格納されています。特殊なDBFSルートのディレクトリを参照ください。 -
/databricks-results: クエリーの完全な結果をダウンロードする際に生成されるファイルが格納されます。 -
/databricks/init: グローバルinitスクリプト、クラスター指定initスクリプト(非推奨)が格納されます。 -
/user/hive/warehouse: Hiveテーブルのデータとメタデータが格納されます。
新たに作成されたワークスペースにおいては、DBFSには以下のようなデフォルトフォルダが含まれています。

DBFSルートには、マウントポイントのメタデータ、クレデンシャル、そして特定のタイプのログを含むデータも格納されますが、これらは非表示となっており直接アクセスすることはできません。
推奨の設定と利用方法
Databriksのアカウント管理者は、アカウントコンソールあるいはAccount API 2.0を用いてワークスペースを作成する際に、DBFSルートストレージバケットをセットアップします。詳細はConfigure AWS storageを参照ください。
バケットとワークスペースを作成した後に行うことができる推奨設定が存在します。
- 問題の早期解決を行えるように、DBFSルートバケットのS3オブジェクトレベルロギングを有効化することをお勧めします。S3オブジェクトレベルロギングはAWSの利用量を増加させる場合があることに注意してください。
- DBFSマウントポイントに格納されていないデータを格納するために、一定の期間DBFSはDatabricksのアカウントのS3バケットを使用していました。お使いの環境のDatabricksワークスペースがこのS3バケットを使い続けている場合には、Databricksのサポートに連絡し、ご自身のアカウントのS3バケットにデータを移動することをお勧めします。
以下の利用法をお勧めしています。
-
マウントポイントのパス(
/mnt)に書き込まれるデータはDBFSルートの外になります。DBFSは書き込み可能ですが、DBFSルートではなくマウントされたオブジェクトストレージにデータを格納することをお勧めします。DBFSルートはプロダクションの顧客情報を格納することを目的とはしていません。
顧客管理キーによるDBFSルートのデータの暗号化(オプション)
パブリックプレビューとして利用できる機能として、顧客管理キーを用いたDBFSルートのデータの暗号化が可能です。
特殊なDBFSルートのディレクトリ
以下の文書では、特殊なDBFSルートのディレクトリを説明しています。
UIによるDBFSの参照
DBFSファイルブラウザを用いてDBFSの参照、検索が可能です。
注意
利用する前に、管理者がDBFSブラウザインタフェースを有効化する必要があります。Manage the DBFS file browserを参照ください。
- サイドバーの
 Dataをクリックします。
Dataをクリックします。 - ページの上部にあるDBFSボタンをクリックします。
ブラウザは階層上にDBFSオブジェクトを表示します。階層を展開するにはオブジェクトを選択します。DBFSオブジェクトを検索するにはPrefix searchを使用します。
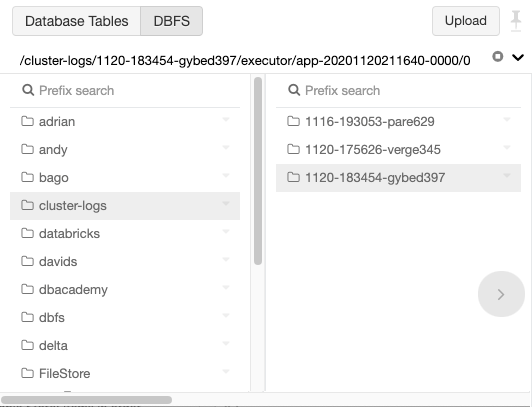
また、DBFS CLI、Databricksファイルシステムユーティリティ(dbutils.fs)、Spark API、ローカルファイルAPIを用いてDBFSオブジェクトの一覧を取得することができます。DBFSへのアクセスを参照ください。
DBFSへのオブジェクトストレージへのマウント
DBFSにオブジェクトストレージをマウントすることで、ローカルファイルシステムのようにオブジェクトストレージのオブジェクトにアクセスすることができるようになります。
マウントポイントは明示的にアンマウントしない限り永続化します。
AWS S3バケットのマウント、アンマウントの方法に関しては、DBFSを通じたS3バケットへのアクセスを参照ください。DBFSを通じてS3に書き込みを行う際の暗号化に関しては、s3a://パスに対するKMS暗号化の設定を参照ください。
Azure Blob Storageコンテナ、Azure Data Lake Storageアカウントのマウント、アンマウントに関しては、Mount Azure Blob storage containers to DBFS、Mount Azure Data Lake Storage Gen1 resource using a service principal and OAuth 2.0、Mount ADLS Gen2 storageを参照ください。
重要!
ネストされたマウントはサポートされていません。例えば、以下の構造はサポートされていません。
-
/mnt/storage1としてマウントされるstorage1 -
/mnt/storage1/storage2としてマウントされるstorage2
それぞれのストレージオブジェクトに対して別のマウントを作成することをお勧めします。
-
/mnt/storage1としてマウントされるstorage1 -
/mnt/storage2としてマウントされるstorage2
DBFSへのアクセス
重要!
DBFSルートを除き、DBFSにマウントされたオブジェクトストレージのオブジェクトに対してすべてのユーザーが読み書きのアクセス権を持ちます。DBFSのアクセス権に関する重要な情報を参照ください。
ファイルアップロードのインタフェースを用いてデータをDBFSにアップローできます。また、DBFS CLI、DBFS API 2.0、Databricksファイルシステムユーティリティ(dbutils.fs)、Spark API、ローカルファイルAPIを用いたアップロード、DBFSオブジェクトへのアクセスが可能です。
Databricksのクラスター上では、Databricksファイルシステムユーティリティ、Spark API、ローカルファイルAPIを用いてDBFSにアクセスすることができます。ローカルコンピューター上では、Databricks CLIあるいはDBFS APIを用いてDBFSオブジェクトにアクセスすることができます。
本セクションでは以下を説明します。
DBFSとローカルドライバーノードのパス
DBFS上のファイル、クラスターのローカルドライバーノードのファイルを操作することができます。%fsや%shといったマジックコマンドを使ってファイルシステムにアクセスすることができます。また、Databricksファイルシステムユーティリティ (dbutils.fs)を用いることもできます。
Databricksはクラウドに格納されているファイルへのローカルアクセスを提供するためにFUSEマウントを使用しています。FUSEマウントはセキュアかつ、バーチャルなファイルシステムです。
DBFSのファイルへのアクセス
デフォルトblobストレージ(root)へのパスはdbfs:/となります。
%fsとdbutils.fsのデフォルトロケーションはrootとなります。このため、rootや外部バケットに対する読み書きは以下のように行います。
%fs <command> /<path>
dbutils.fs.<command> ("/<path>/")
%shは、デフォルトではローカルファイルシステムから読み込みを行います。%shでrootやroot配下のマウントパスにアクセスするには、パスの先頭に/dbfs/を追加します。典型的なユースケースは、TensorFlow、scikit-learnのようなシングルノード向けのライブラリで作業をしており、クラウドストレージに対して読み書きを行いたいというものになります。
%sh <command> /dbfs/<path>/
シングルノードのファイルシステムAPIを使用することもできます。
import os
os.<command>('/dbfs/tmp')
サンプル
# Default location for %fs is root
%fs ls /tmp/
%fs mkdirs /tmp/my_cloud_dir
%fs cp /tmp/test_dbfs.txt /tmp/file_b.txt
# Default location for dbutils.fs is root
dbutils.fs.ls ("/tmp/")
dbutils.fs.put("/tmp/my_new_file", "This is a file in cloud storage.")
# Default location for %sh is the local filesystem
%sh ls /dbfs/tmp/
# Default location for os commands is the local filesystem
import os
os.listdir('/dbfs/tmp')
ローカルファイルシステムのファイルへのアクセス
%fsとdbutils.fsはデフォルトでroot(dbfs:/)から読み込みを行います。ローカルファイルシステムから読み込みを行うためには、file:/を使う必要があります。
%fs <command> file:/<path>
dbutils.fs.<command> ("file:/<path>/")
%shはデフォルトでローカルファイルシステムから読み込みを行いますので、file:/を使う必要はありません。
%sh <command> /<path>
サンプル
# With %fs and dbutils.fs, you must use file:/ to read from local filesystem
%fs ls file:/tmp
%fs mkdirs file:/tmp/my_local_dir
dbutils.fs.ls ("file:/tmp/")
dbutils.fs.put("file:/tmp/my_new_file", "This is a file on the local driver node.")
# %sh reads from the local filesystem by default
%sh ls /tmp
マウントされたオブジェクトストレージのファイルへのアクセス
DBFSにオブジェクトストレージをマウントすることで、ローカルファイルシステムのようにオブジェクトストレージのオブジェクトにアクセスすることができます。
サンプル
dbutils.fs.ls("/mnt/mymount")
df = spark.read.text("dbfs:/mymount/my_file.txt")
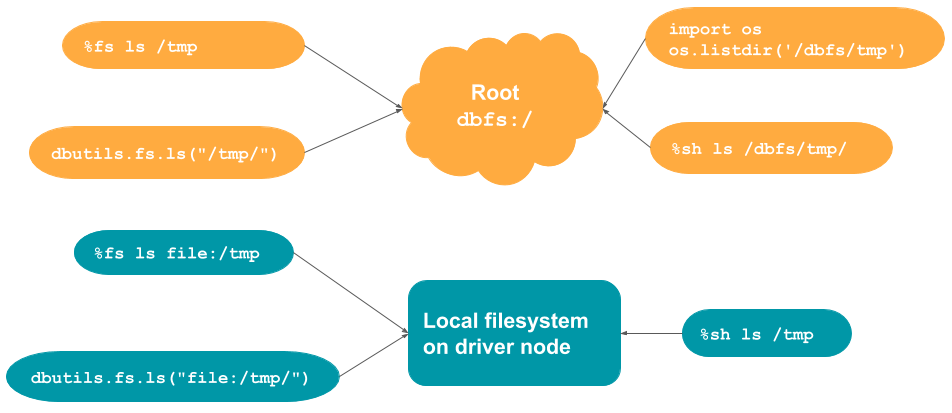
サマリーのテーブル及び図
このセクションで説明されたコマンド、および、いつそれぞれの文法を使うべきかを要約、説明するテーブル、図となります。
| コマンド | デフォルトロケーション | rootからの読み込み | ローカルファイルシステムからの読み込み |
|---|---|---|---|
%fs |
root | パスにfile:/を追加 |
|
%sh |
ローカルドライバーノード | パスに/dbfsを追加 |
|
dbutils.fs |
root | パスにfile:/を追加 |
|
os.<command> |
ローカルドライバーノード | パスに/dbfsを追加 |
ファイルアップロードのインタフェース
お使いのローカルマシンにDatabricksで分析したい小規模のデータファイルがある場合には、DBFSファイルブラウザー、あるいはノートブックのインタフェースを用いて簡単にDatabricksファイルシステム(DBFS)にインポートすることができます。
ファイルはFileStoreディレクトリにアップロードされます。
ファイルブラウザーからDBFSへのデータのアップロード
注意
この機能はデフォルトでは無効化されています。本機能を使用する前に管理者がDBFSブラウザーを有効化する必要があります。Manage the DBFS file browserを参照ください。
-
サイドバーの
Dataをクリックします。 -
ページの上部にあるDBFSボタンをクリックします。
-
ページの上部にあるUploadボタンをクリックします。
-
Upload Data to DBFSダイアログでは、オプションとしてターゲットのディレクトリを選択するか、新たなディレクトリを選択します。
-
Filesボックスに、アップロードするローカルファイルをドラッグアンドドロップするか、ファイルブラウザーで選択します。

アップロードされたファイルは、ワークスペースにアクセスできるすべてのユーザーがアクセスすることができます。
ノートブックからDBFSへのデータのアップロード
注意
この機能はデフォルトで有効化されています。管理者がこの機能を無効化した場合、ファイルをアップロードすることはできません。
UIを使ってテーブルを作成するためには、UIによるテーブルの作成を参照ください。
ノートブックで使うデータをアップロードするには、以下の手順を踏みます。
-
新規ノートブックを作成、あるいは既存のノートブックを開き、File > Upload Dataをクリックします。

-
アップロードするファイルを格納するターゲットのDBFSディレクトリを選択します。ターゲットディレクトリのデフォルトは
/shared_uploads/<your-email-address>/となります。アップロードされたファイルは、ワークスペースにアクセスできるすべてのユーザーがアクセスすることができます。
-
ファイルをドラッグ&ドロップするか、ローカルシステムのファイルを指定するためにBrowseをクリックします。

-
ファイルのアップロードが完了したらNextをクリックします。
CSV、TSV、JSONファイルをアップロードした場合、Databricksはデータをデータフレームにロードするためのコードを生成します。

テキストをクリップボードに保存するには、Copyをクリックします。
-
ノートブックに戻るにはDoneをクリックします。
Databricks CLI
DBFSコマンドラインインタフェース(CLI)は、DBFSに対する使いやすいコマンドラインインタフェースを提供するためにDBFS API 2.0を使用します。このクライアントを使うことで、Unixのコマンドラインと同じようなコマンドを使ってDBFSを操作することができます。
# List files in DBFS
dbfs ls
# Put local file ./apple.txt to dbfs:/apple.txt
dbfs cp ./apple.txt dbfs:/apple.txt
# Get dbfs:/apple.txt and save to local file ./apple.txt
dbfs cp dbfs:/apple.txt ./apple.txt
# Recursively put local dir ./banana to dbfs:/banana
dbfs cp -r ./banana dbfs:/banana
DBFSコマンドラインインタフェースの詳細については、Databricks CLIを参照ください。
dbutils
dbutils.fsは、DBFSのファイルにアクセするためのファイルシステムライクなコマンドを提供します。このセクションでは、dbutils.fsコマンドを使ってどのようにDBFSのファイルを読み書きするのかを説明します。
ティップス
DBFSのヘルプメニューを表示するには、dbutils.fs.help()コマンドを使用します。
ローカルファイルシステムのようにDBFSにファイルを読み書きする
dbutils.fs.mkdirs("/foobar/")
dbutils.fs.put("/foobar/baz.txt", "Hello, World!")
dbutils.fs.head("/foobar/baz.txt")
dbutils.fs.rm("/foobar/baz.txt")
DBFSのパスにアクセスするためにdbfs:を使う
display(dbutils.fs.ls("dbfs:/foobar"))
%fsマジックコマンドを使う
ノートブックでは、dbutilsファイルシステムモジュールにアクセするための、%fsマジックコマンドが提供されています。ほとんどのdbutils.fsコマンドを%fsマジックコマンドで使用することができます。
# List the DBFS root
%fs ls
# Recursively remove the files under foobar
%fs rm -r foobar
# Overwrite the file "/mnt/my-file" with the string "Hello world!"
%fs put -f "/mnt/my-file" "Hello world!"
DBFS API
DBFS API 2.0とUpload a big file into DBFSを参照ください。
Spark API
Spark APIを使用している際は、ファイルは"/mnt/training/file.csv"や"dbfs:/mnt/training/file.csv"で参照することになります。以下の例ではファイルfoo.textをDBFSの/tmpディレクトリに書き込んでいます。
df.write.text("/tmp/foo.txt")
DBFSにアクセスするためにSpark APIを使用している際(例えば、spark.readの呼び出し)には、ターゲットのDBFSの位置を完全な絶対パスで指定する必要があります。パスは/あるいはdbfs:/で始まるDBFSルートからスタートする必要があります。/とdbfs:/は同じ意味です。例えば、DBFSの/FileStoreにあるpeople.jsonを読み込むには以下のいずれかを実行します。
df = spark.read.json('dbfs:/FileStore/people.json')
df.show()
df = spark.read.json('/FileStore/people.json')
df.show()
以下の例は動作しません。
# This will not work. The path must be absolute. It
# must start with '/' or 'dbfs:/'.
df = spark.read.json('FileStore/people.json')
df.show()
ローカルファイルAPI
DBFSのパスに対して読み書きを行う際にローカルファイルAPIを使用することができます。Databricksは、クラスターノードで動作するプロセスが背後の分散ストレージレイヤーにローカルファイルAPIでアクセスできるように、それぞれのクラスターノードにFUSEマウント/dbfsを設定します。ローカルファイルAPIを使用する際には、以下のようにパスの先頭に/dbfsをつける必要があります。
#write a file to DBFS using Python file system APIs
with open("/dbfs/tmp/test_dbfs.txt", 'w') as f:
f.write("Apache Spark is awesome!\n")
f.write("End of example!")
# read the file
with open("/dbfs/tmp/test_dbfs.txt", "r") as f_read:
for line in f_read:
print(line)
import scala.io.Source
val filename = "/dbfs/tmp/test_dbfs.txt"
for (line <- Source.fromFile(filename).getLines()) {
println(line)
}
ローカルファイルAPIの制限
以下では、それぞれのFUSE、Databricksランタイムのバージョンに適用されるローカルファイルAPIの制限を列挙します。
-
すべて: クライアントサイド暗号化が有効化されたAmazon S3マウントをサポートしていません。
-
FUSE V2(Databricksランタイム6.x、7.xのデフォルト)
- ランダムの書き込みはサポートしていません。ランダムの書き込みが必要となるワークロードにおいては、以下のようにローカルディスクでオペレーションを行い、
/dbfsに結果をコピーするようにしてください。
Python# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/dbfs/tmp/excel.xlsx')- sparseファイルはサポートしていません。sparseファイルをコピーするには
cp --sparse=neverを使用してください。
Bash$ cp sparse.file /dbfs/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /dbfs/sparse.file - ランダムの書き込みはサポートしていません。ランダムの書き込みが必要となるワークロードにおいては、以下のようにローカルディスクでオペレーションを行い、
-
FUSE V1(Databricksランタイム5.5 LTSのデフォルト)
重要!
<DBR>5.5 LTSのFUSE V1で問題に遭遇した場合には、FUSE V2を使用することをお勧めします。<DBR>5.5 LTSのデフォルトFUSEバージョンは環境変数DBFS_FUSE_VERSION=2を設定することで上書きすることができます。-
2GB以下のサイズのファイルのみをサポートしています。2GB以上のサイズのファイルを読み書きしようとすると破損ファイルに直面することになります。2GB以上のサイズのファイルにアクセスするには、DBFS CLI、
dbutils.fs、Spark API、[#ディープラーニング用ローカルファイルapi]で説明されている/dbfs/mlフォルダーを使用してください。 - ローカルファイルシステムAPIを用いてファイルを書き込み、すぐにDBFS CLI、
dbutils.fs、Spark APIを持ちてアクセスしようとした場合、FileNotFoundExceptionやファイルサイズ0、古いファイルコンテンツに遭遇する場合があります。これは、オペレーティングシステムのキャッシュの書き込みがデフォルトとなっているため予期される挙動です。こられの書き込みが永続化ストレージ(ここではDBFS)でフラッシュされることを強制するには標準的なUnixシステムコールsyncを使用してください。
Scala// scala import scala.sys.process._ // Write a file using the local file API (over the FUSE mount). dbutils.fs.put("file:/dbfs/tmp/test", "test-contents") // Flush to persistent storage. "sync /dbfs/tmp/test" ! // Read the file using "dbfs:/" instead of the FUSE mount. dbutils.fs.head("dbfs:/tmp/test") -
2GB以下のサイズのファイルのみをサポートしています。2GB以上のサイズのファイルを読み書きしようとすると破損ファイルに直面することになります。2GB以上のサイズのファイルにアクセスするには、DBFS CLI、
ディープラーニング用ローカルファイルAPI
データのロード、チェックポイント、ロギングにDBFSへのアクセスを必要とする分散ディープラーニングアプリケーションにおいては、Databricksランタイム6.0以降では、ディープラーニングワークロードに最適化された高性能な/dbfsマウントポイントが提供されています。
Databricksランタイム5.5 LTSでは/dbfs/mlのみが最適化されています。このバージョンのDatabricksにおいては、dbfs:/mlにマッピングされる/dbfs/mlにデータを保存することをお勧めします。