無料のDatabricksコミュニティエディションでどこまで何ができるのかを模索中です。今回は画像編です。NLPはこちらです。
こちらで紹介しているノートブックは以下のリンク先からアクセスできます。
以下の記事をまとめた際に、画像データを保持したDeltaファイルがあることに気づきました。というか前に触っていました。
こちらのリファレンスソリューションで使っていました。なので、今回はこちらのデータをコミュニティエディションで分析してみます。コミュニティエディションの環境でもサンプルデータは利用できます。
コミュニティエディションにサインアップあるいはログインする
こちらのDatabricksコミュニティエディションにログイン、アカウントがない場合にはサインアップします。
正式版のDatabricksとの違いはこちらを参照ください。機能面、キャパシティ面で制限はありますが、基本的な機能は使用できます。
サインアップの方法はこちらを参照ください。
クラスターを作成する
Databricksで計算処理を行う際には、Databricksクラスターを作成し、起動する必要があります。GUIの操作でさまざまなスペックのクラスターを作成でき、自動停止、オートスケールなどの機能を活用することができるので、コスト効率高く機械学習の取り組みを行うことができます。
注意
以下の画面で言語が日本語になっていない場合には、こちらを参考に言語を変更してください。
- サイドバーでクラスターを選択します。
-
クラスターの作成ボタンをクリックします。

-
クラスター名にはわかりやすい名前を指定し、Databricks Runtimeのバージョンでは、10.5MLを選択し、クラスターを作成ボタンをクリックします。これでクラスターが起動します。ここでのランタイムのバージョンの
MLは機械学習ランタイムであることを意味し、tensorflow、pytorchなど著名な機械学習ライブラリが事前にインストールされているので、すぐに機械学習の作業に取り掛かることができます。 - クラスター名の右にグリーンのチェックマークが表示されるとクラスターの起動が完了したことを意味します。

ノートブックを作成する
Databricksではさまざまなロジックをノートブックに記述し、クラスター上で実行します。
- サイドバーのワークスペースをクリックします。
- 右上に表示されるホームをクリックすると、あなたのホームディレクトリが表示されます。

- ユーザー名(メールアドレス)の右の下向き矢印をクリックし、メニューを表示させます。
-
作成 > ノートブックをクリックします。

- わかりやすいノートブック名を入力し、クラスターには上のステップで作成したクラスターを選択します。

- これで空のノートブックが作成されました。

画像を分析してみる
サンプルデータセットの確認
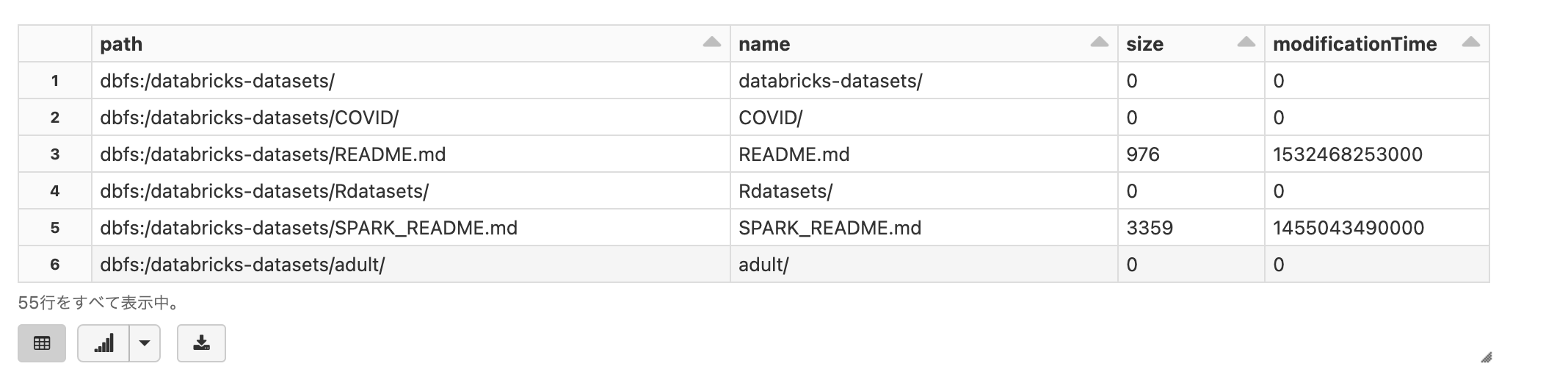
Databricksファイルシステム(DBFS)の/databricks-datasetsにはさまざまなサンプルデータが格納されています。
以下のセルではマジックコマンド%fsを指定しており、lsやheadなどを用いてファイルシステムにアクセスすることができます。
%fs
ls /databricks-datasets
データフレームにDeltaファイルをロード
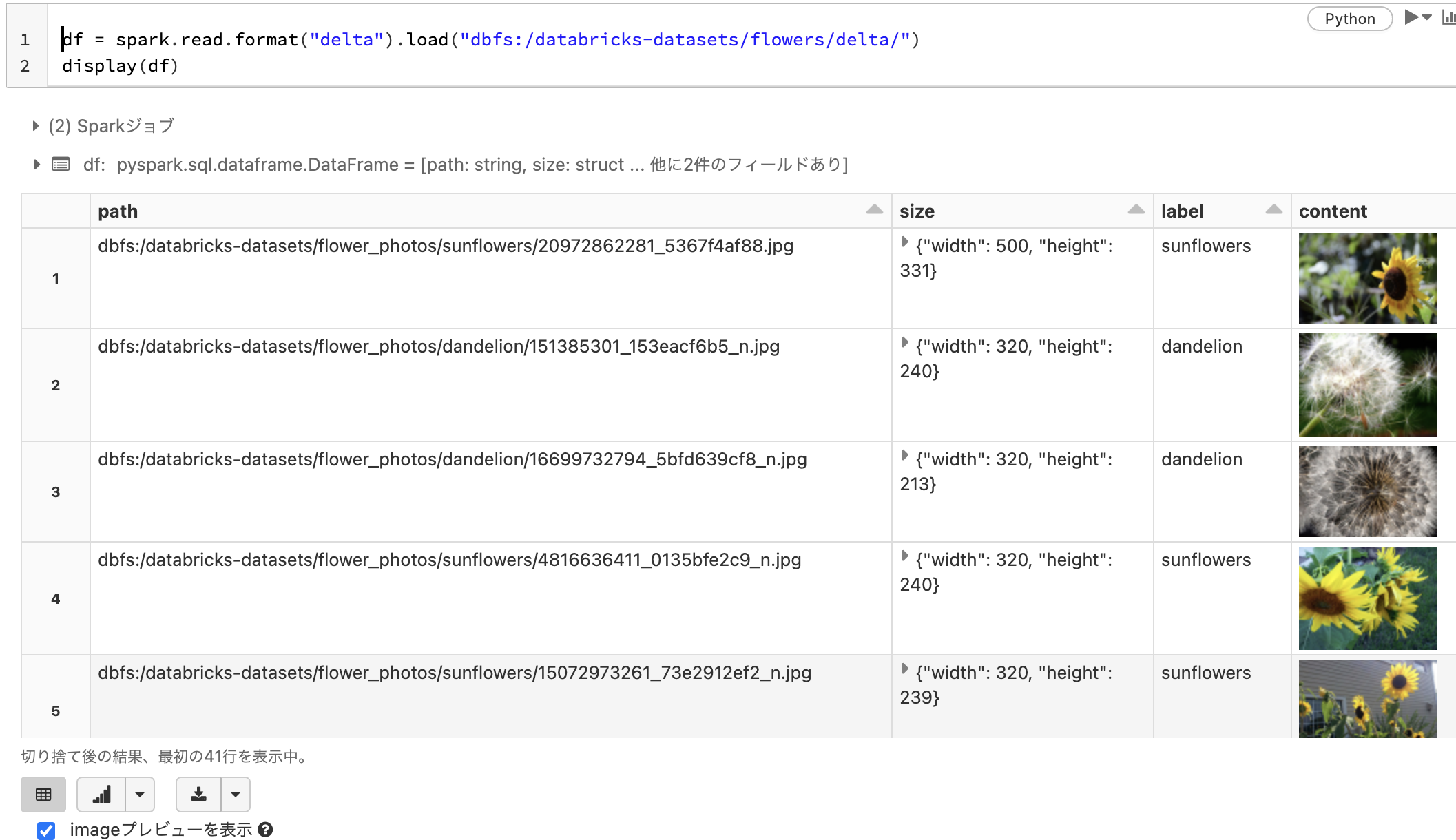
上のサンプルデータの中から花の画像を保存しているDelta形式のファイルをロードします。このデータには以下のカラムが含まれています。読み込んだデータフレームはSparkデータフレームとなります。Pythonの場合、PySparkというAPIを用いてこのデータフレームを操作します。
| カラム | 説明 |
|---|---|
| path | 画像ファイルのパス |
| size | 画像の幅と高さを持つ配列 |
| label | 画像のラベル |
| content | 画像のバイナリ |
また、Delta形式のファイルにはバイナリーをカラムとして含めることができるので、画像データを用いた分析を簡便に行うことができます。
以下のセルではデータフレームの表示にdisplay関数を使用しています。これにより、画像のサムネイル表示、グラフによる可視化などさまざまな機能を用いてデータを探索することができます。
df = spark.read.format("delta").load("dbfs:/databricks-datasets/flowers/delta/")
display(df)
printSchema()を用いることでSparkデータフレームのスキーマを確認することができます。
# 読み込んだデータフレームのスキーマを表示
df.printSchema()
root
|-- path: string (nullable = true)
|-- size: struct (nullable = true)
| |-- width: integer (nullable = true)
| |-- height: integer (nullable = true)
|-- label: string (nullable = true)
|-- content: binary (nullable = true)
このように、カラムの一つcontentはbinaryとなっていることがわかります。
PySparkによる簡単な集計
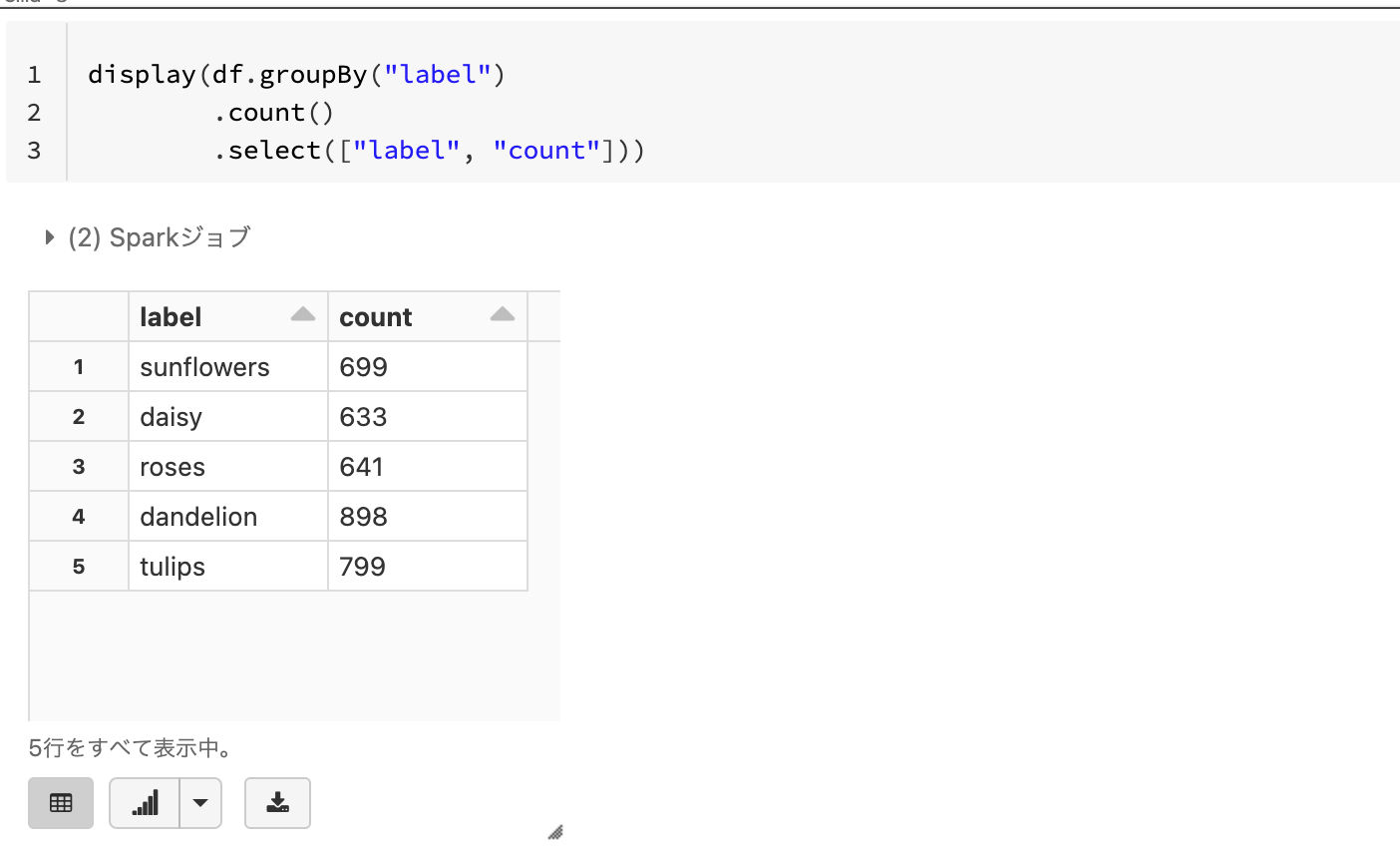
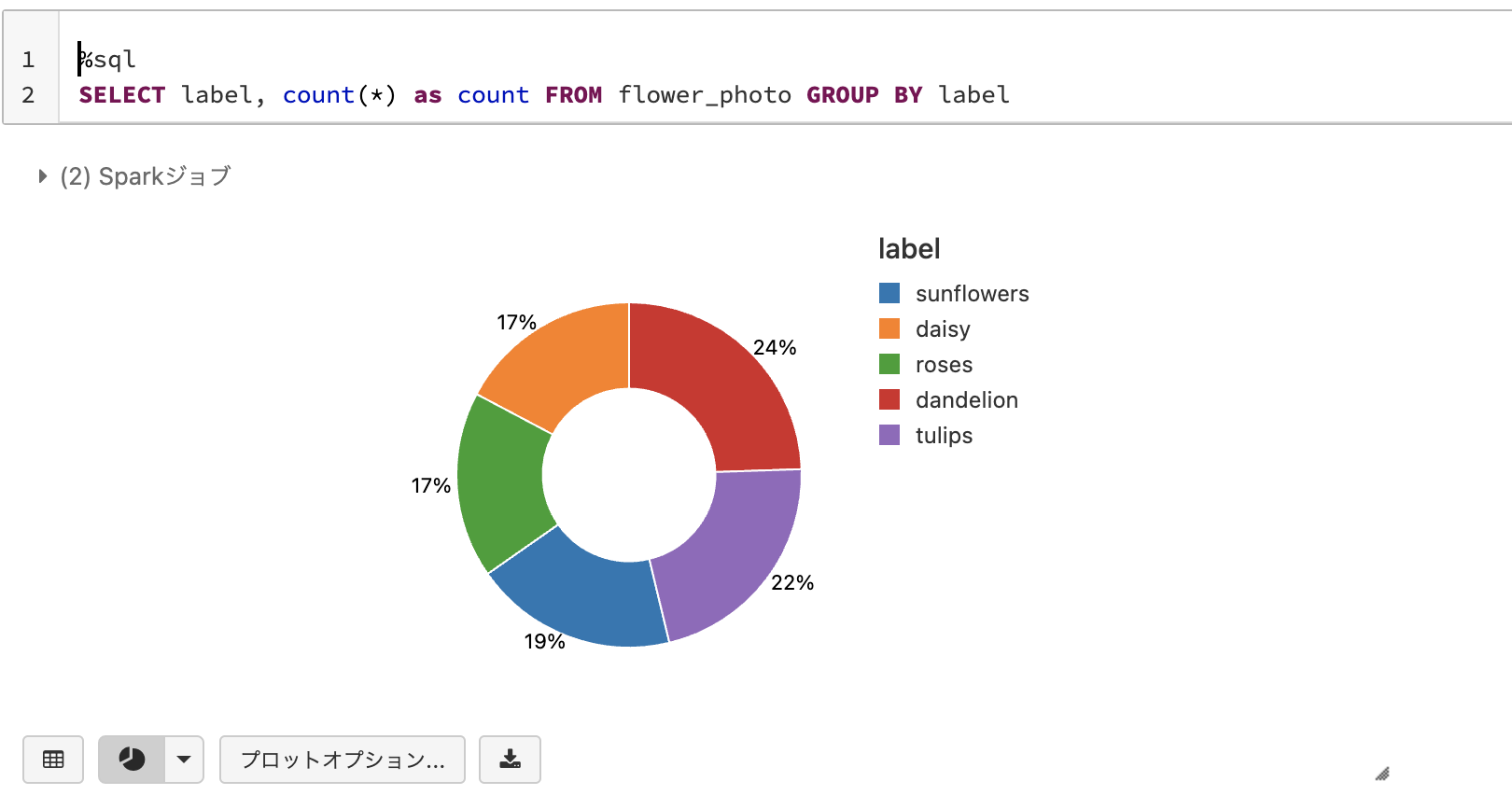
データフレームにさまざまなメソッドを用いることで、SQLライクな集計を行うことができます。以下の例ではlabelでグルーピングを行い、グループごとのカウントを集計しています。
display(df.groupBy("label")
.count()
.select(["label", "count"]))
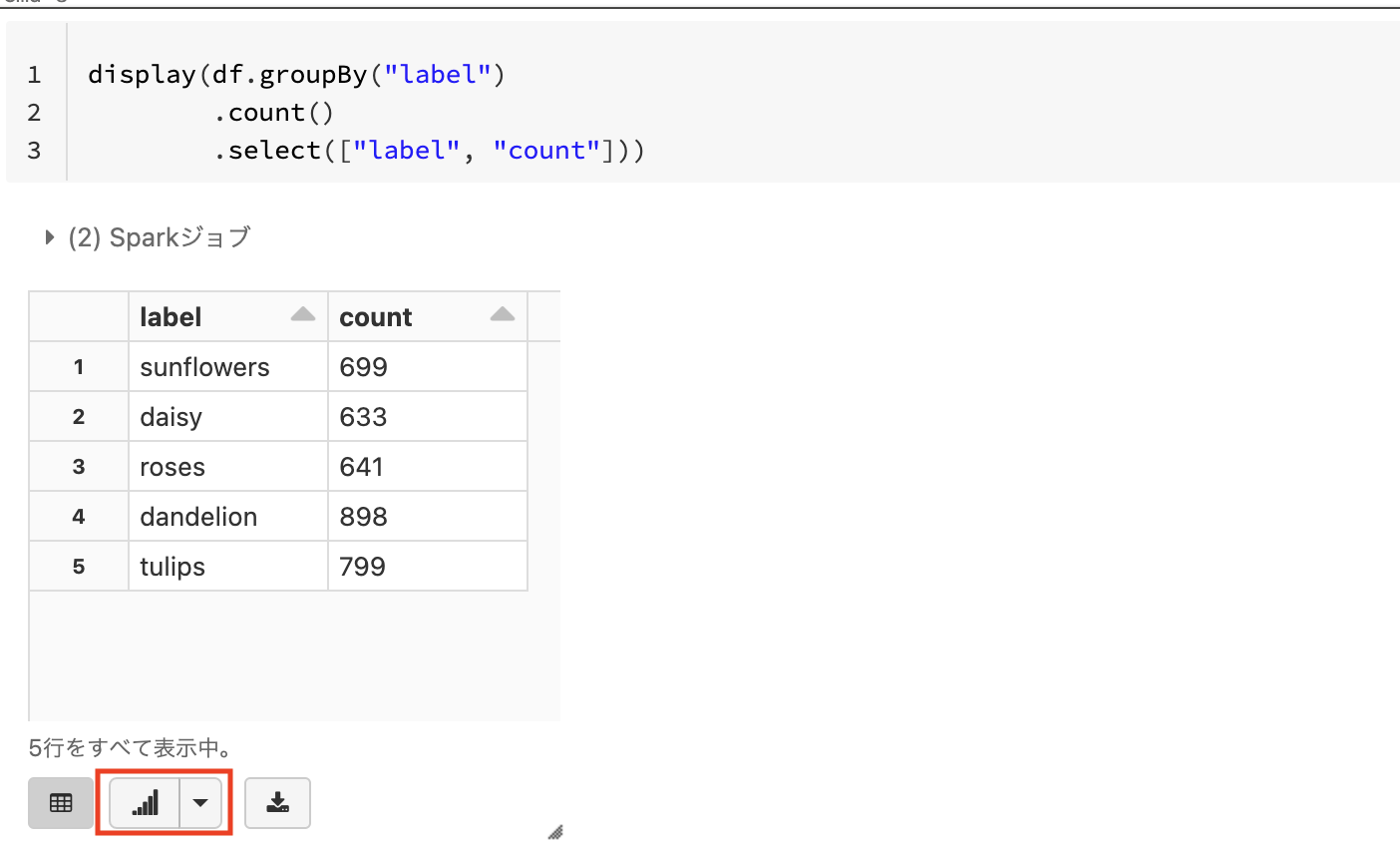
ここで、テーブルの下に表示されるグラフマークに注目してください。こちらをクリックするだけで、テーブルのデータを簡単に可視化することができます。
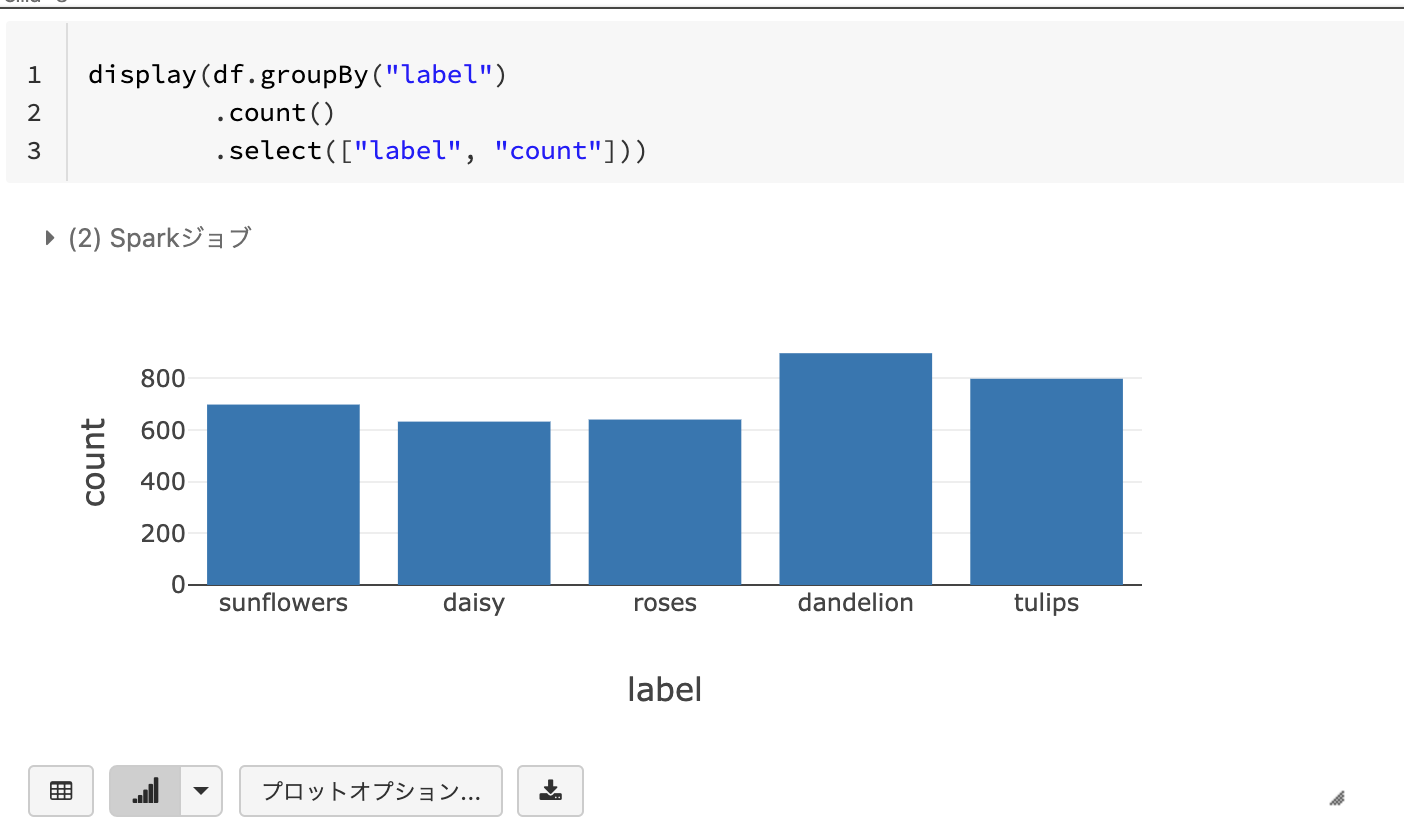
棒グラフでも傾向はわかりますが、ここでは円グラフに切り替えてみましょう。プロットオプションをクリックします。こちらの画面でプロットをカスタマイズすることができます。
ここではシンプルに表示タイプを円グラフに切り替えて、適用をクリックします。
これで、円グラフに表示を切り替えることができました。matplotlibやseabornを使わなくても簡単にデータを可視化することができます。もちろん、これらの可視化ライブラリを使うこともできます。
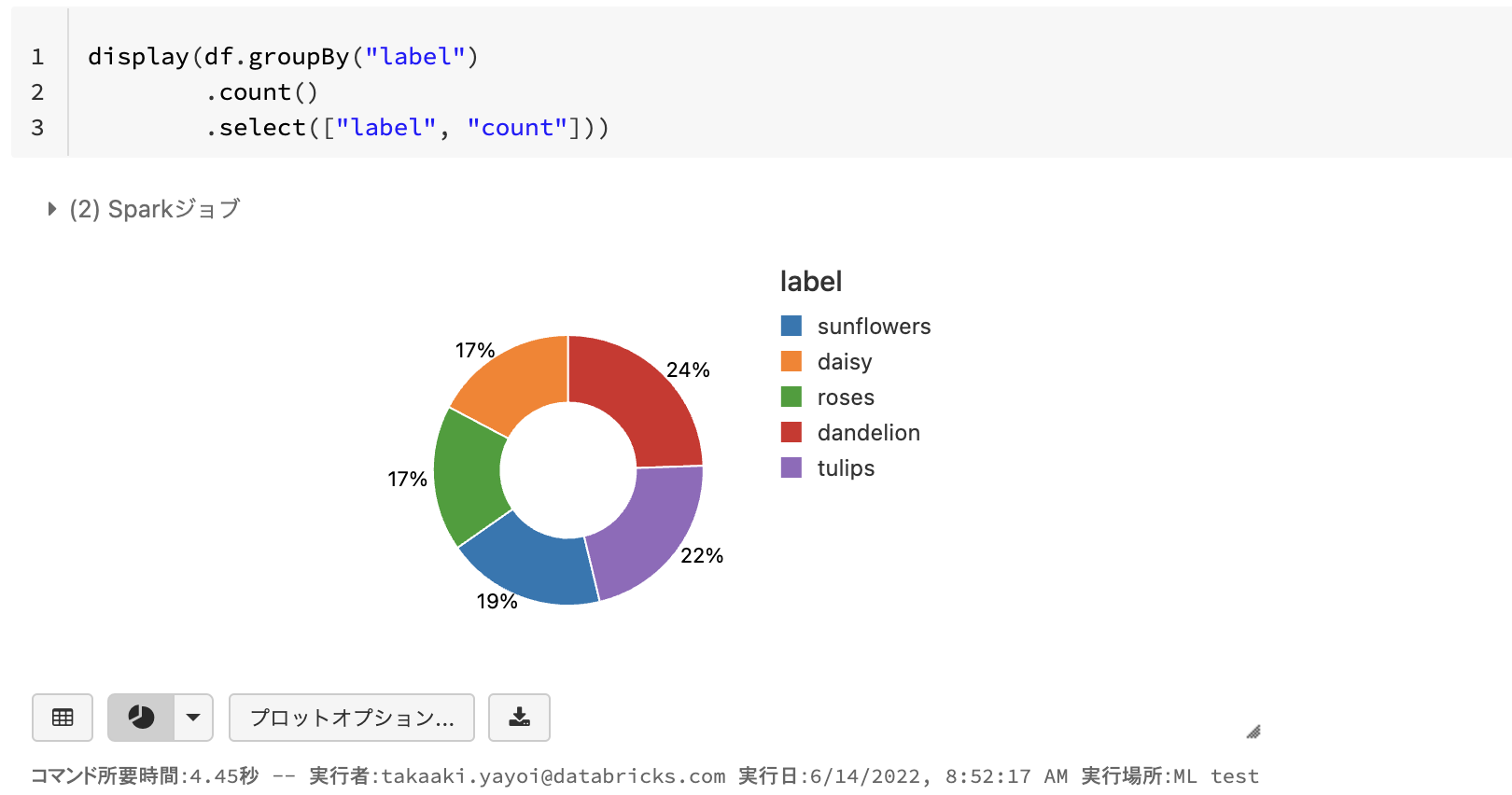
なお、一時ビューあるいはHiveメタストアにデータフレームを登録すると、直接SQLを実行することができます。以下の例では、データフレーム一時ビューを登録しています。マジックコマンド%sqlを用いることで、セルに直接SQLを記述することができます。
df.createOrReplaceTempView("flower_photo")
%sql
SELECT label, count(*) as count FROM flower_photo GROUP BY label
Delta Lakeを用いた分散モデル推論
大量データに対する推論を行う際に、Sparkの並列分散処理を活用することで処理に要する時間を短縮することができます。このために、ScalarイテレーターのPandasのUDF(ユーザー定義関数)を使用します。
必要なライブラリをimportします。Databricks機械学習ランタイムを使用しているので、tensorflow、PyTorchなど著名なライブラリが事前にインストールされています。
import io
from tensorflow.keras.applications.imagenet_utils import decode_predictions
import pandas as pd
from pyspark.sql.functions import col, pandas_udf, PandasUDFType
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import models, transforms
from PIL import Image
入力を処理するデータセットを定義
class ImageNetDataset(Dataset):
"""
標準的なImageNet前処理を用いて画像コンテンツをPyTorchデータセットへ変換
"""
def __init__(self, contents):
self.contents = contents
def __len__(self):
return len(self.contents)
def __getitem__(self, index):
return self._preprocess(self.contents[index])
def _preprocess(self, content):
"""
標準的なImageNet正規化を用いて入力画像コンテンツを前処理
詳細は https://pytorch.org/docs/stable/torchvision/models.html
"""
image = Image.open(io.BytesIO(content))
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
return transform(image)
推論タスクのためのPandas UDFの定義
1対1のマッピングセマンティックを提供するPySparkのUDFには3種類あります。
- PySpark UDF: レコード -> レコード、データのシリアライゼーションの性能に課題があるためお勧めしません。
- Scalar Pandas UDF: pandasのシリーズ/データフレーム -> pandasのシリーズ/データフレーム, バッチ間で状態が共有されません。
- ScalarイテレーターPandas UDF: いくつかの状態を初期化した後、バッチに進みます。
モデル推論にはスカラーイテレーターPandas UDFを用いることをお勧めします。
参考資料
- MobileNet(v1,v2,v3)を簡単に解説してみた - Qiita
- MobileNetV2(Tensorflow)を触ってみた。 | AI・人工知能、IoT、CPS、Mobile:システム開発・一括請負を行っております。
def imagenet_model_udf(model_fn):
"""
予測を行うImageNetモデルをPandasのUDFにラップします。
ご自身のユースケースに応じて以下のようなカスタマイゼーションが必要になるかもしれません。
- 性能を改善するためにDataLoaderのbatch_sizeとnum_workersをチューニング
- 高速化のためにGPUを使用
- 予測タイプを変更
"""
def predict(content_series_iter):
model = model_fn()
model.eval()
for content_series in content_series_iter:
dataset = ImageNetDataset(list(content_series))
loader = DataLoader(dataset, batch_size=64)
with torch.no_grad():
for image_batch in loader:
predictions = model(image_batch).numpy()
predicted_labels = [x[0] for x in decode_predictions(predictions, top=1)]
yield pd.DataFrame(predicted_labels)
return_type = "class: string, desc: string, score:float"
return pandas_udf(return_type, PandasUDFType.SCALAR_ITER)(predict)
# MobileNetV2をPandas UDFとしてラップします
mobilenet_v2_udf = imagenet_model_udf(lambda: models.mobilenet_v2(pretrained=True))
データフレームを用いた分散推論
- 必要となるカラムと、それぞれのカラムをどのように計算するのかを指定します。
- 上で定義したUDFを用いて、画像に対するラベルを推定します。
- 推論対象のデータが膨大になってもSparkがデータを分散しそれぞれにUDFを適用するので、大量データに対しても高速に推論を行えるアーキテクチャを維持することができます。
images = spark.read.format("delta") \
.load("/databricks-datasets/flowers/delta") \
.limit(100) # デモ目的のため実行時間を短縮するためにサブセットを使用します
# 上のUDFを呼び出して予測を行います
predictions = images.withColumn("prediction", mobilenet_v2_udf(col("content")))
# 結果を表示します
display(predictions.select(col("path"), col("prediction")).limit(5))
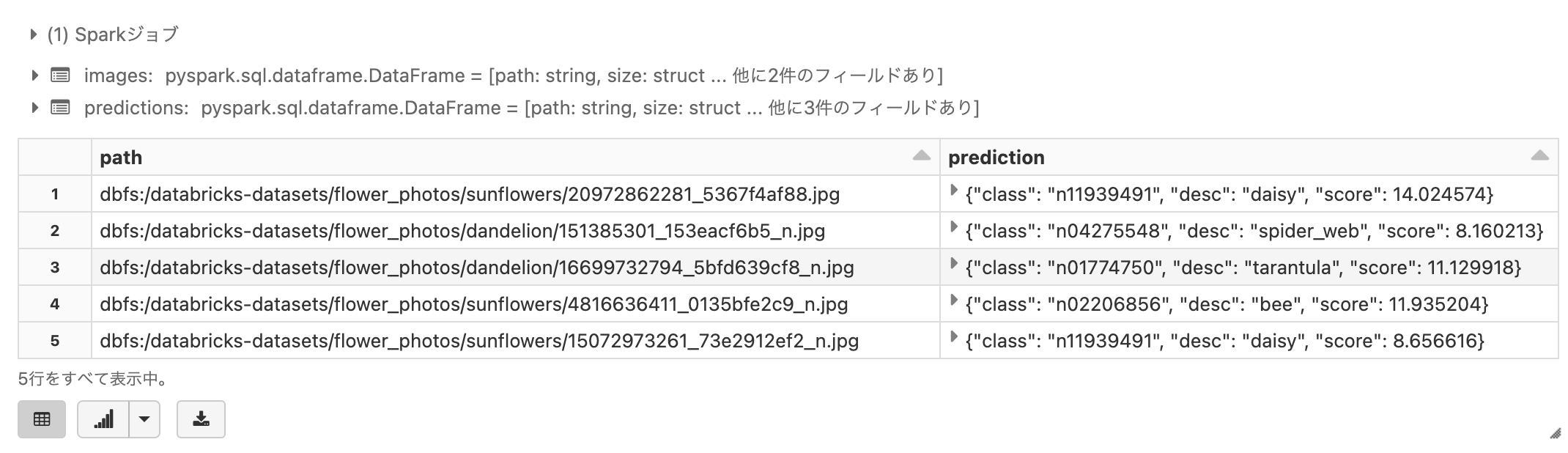
上の結果ではpredictionはネストされたデータとなっていますが、.記法を用いることで簡単に子要素にアクセスすることができます。
# 画像と予測結果のみに絞って表示します
display(predictions.select(col("content"), col("prediction.desc"), col("prediction.score")))
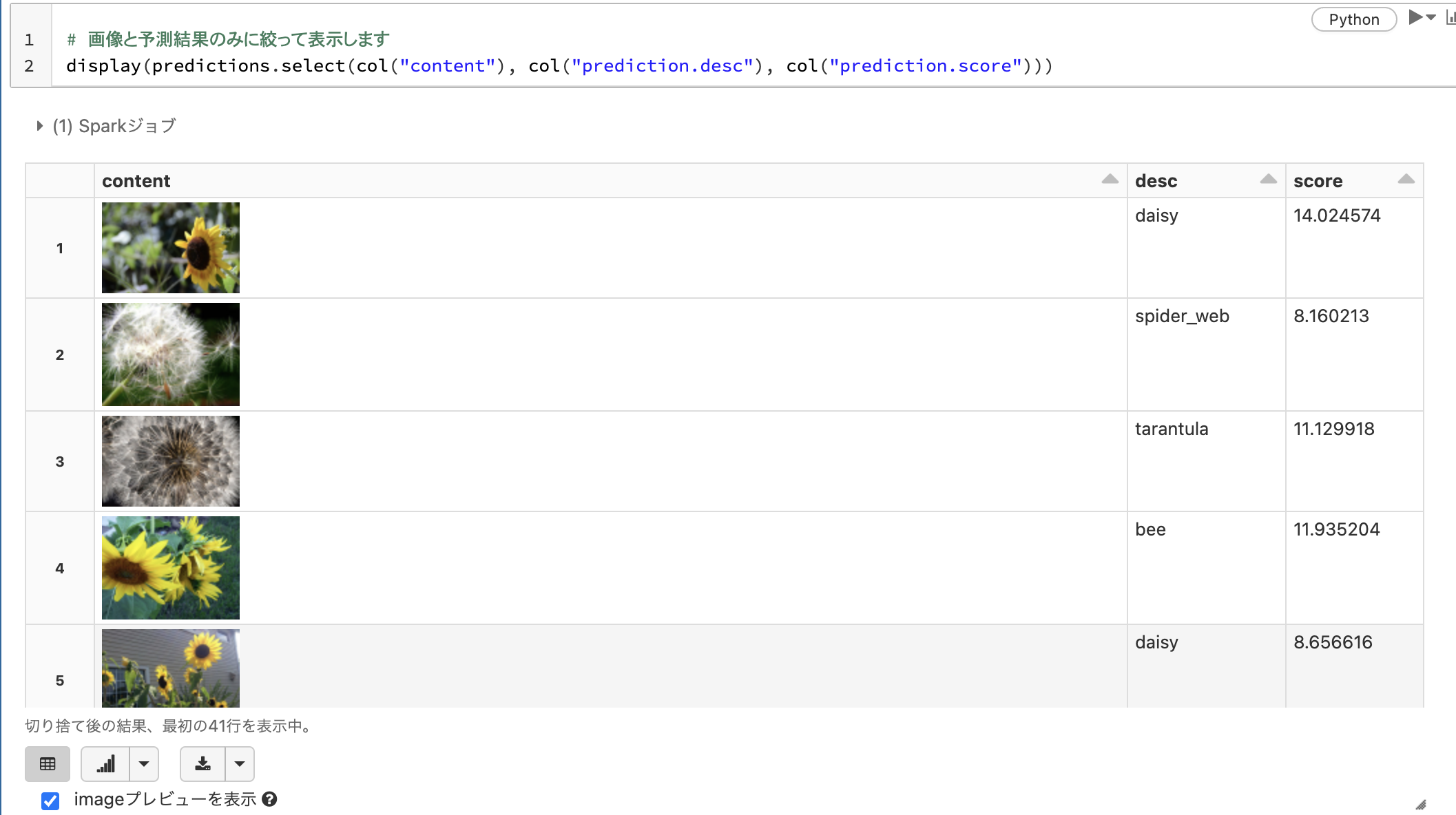
精度に関しては改善の余地がありますが、事前学習済みモデルを用いることで簡単に画像に対するラベルを推定することができます。以下のようなメリットを感じていただけたら幸いです。
- Delta Lakeによる画像管理の簡素化
- Databricksノートブックで柔軟なプログラミング言語の使い分け
- Databricks機械学習ランタイムを用いてライブラリ管理をシンプルに
- Sparkによる推論の並列実行