MobileNet
スマホなどの小型端末にも乗せられる高性能CNNを作りたいというモチベーションから生まれた軽量かつ(ある程度)高性能なCNN。MobileNetにはv1,v2,v3があり、それぞれの要所を調べたのでこの記事でまとめる。
原論文は
- Howard, Andrew G., et al. "Mobilenets: Efficient convolutional neural networks for mobile vision applications." arXiv preprint arXiv:1704.04861 (2017).
- Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
- Howard, Andrew, et al. "Searching for mobilenetv3." arXiv preprint arXiv:1905.02244 (2019).

1. MobileNet-v1(2017/04登場)
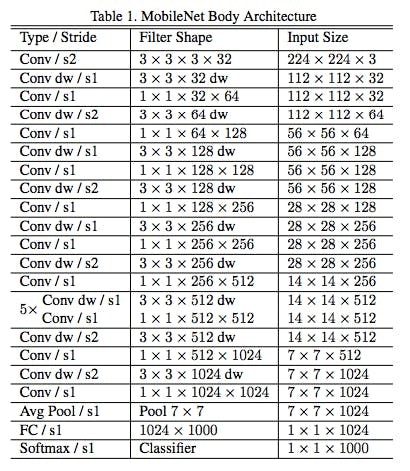
Howard, Andrew G., et al. "Mobilenets: Efficient convolutional neural networks for mobile vision applications." arXiv preprint arXiv:1704.04861 (2017).
Conv : 通常のConvolution
Conv dw : Depthwise Convolution
Conv/s1 : Pointwise Convolution
最初だけ通常のConvolutionで(線や角などの基本的な特徴を取るため。)、
あとはDepthwise Separable Convolution(= Depthwise Conv. + Pointwise Conv.)(後述)を13段積み上げて、全結合層をくっつけている構造。
要点は
- Depthwise Separable Convolution
1.1 Depthwise Separable Convolution
Depthwise Separable Convolutionとは、通常のConvolutionをDepthwise Conv.と Pointwise Conv.の2つに分けることで、パラメータ数を削減したもの。
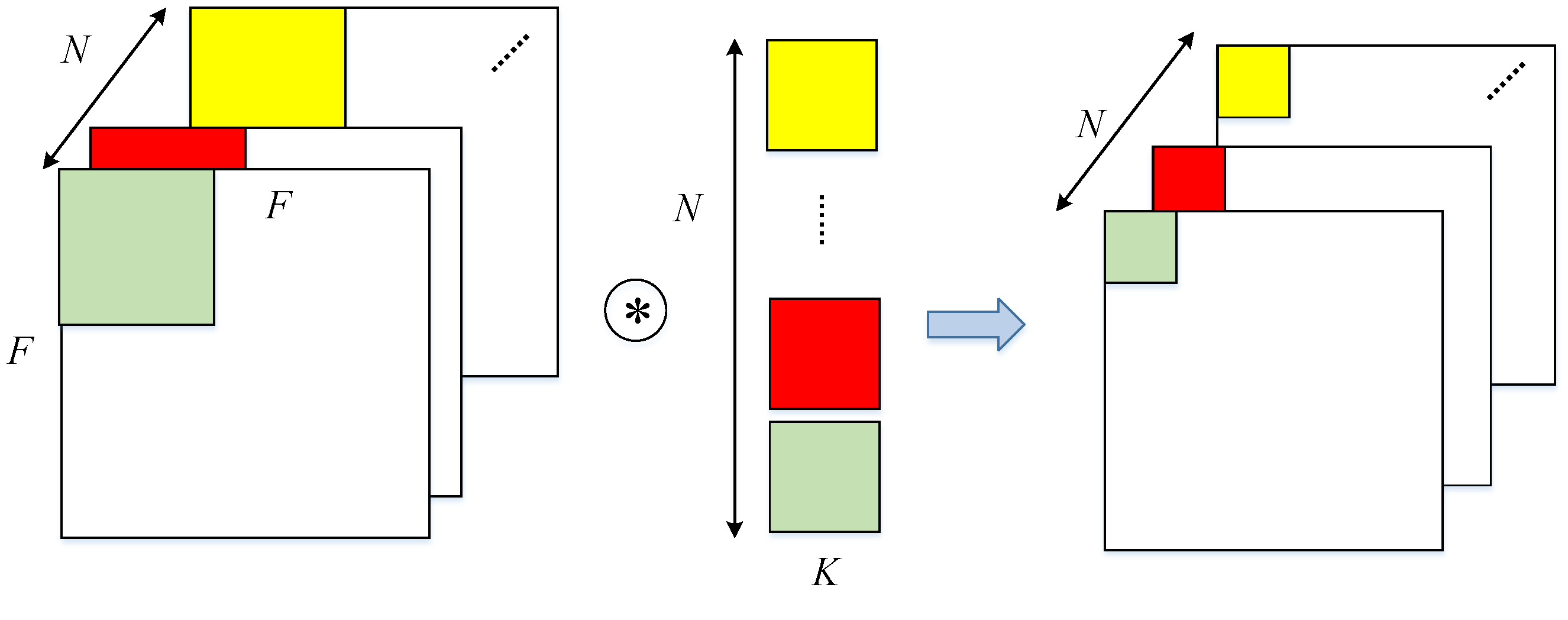
1.1.1 通常のConvolution

Liu, Bing, et al. "An FPGA-Based CNN Accelerator Integrating Depthwise Separable Convolution." Electronics 8.3 (2019): 281.
Nチャネル数の$F\times F$データ(e.g.画像)にM個の$K\times K\times N$フィルタを畳み込み演算することで、M個の特徴量データができあがる。
パラメータ数:
$$
M \times K \times K \times N
$$
1.1.2 Depthwise Separable Convolution
 >Ding, Wei, et al. "Designing efficient accelerator of depthwise separable convolutional neural network on FPGA." Journal of Systems Architecture 97 (2019): 278-286.
>Ding, Wei, et al. "Designing efficient accelerator of depthwise separable convolutional neural network on FPGA." Journal of Systems Architecture 97 (2019): 278-286.
通常の畳み込みが空間方向とチャネル方向の畳み込みを同時に行うのに対して、Depthwise(空間方向) を行なったのちにPointwise(チャネル方向) を行なうようにしているだけ。ポイントは空間方向とチャネル方向の畳み込みを同時に行うのではなく、順に行うという点。

左図:通常の3x3Conv., 右図:3x3Conv.を近似した3x3Depthwise Separable Conv.
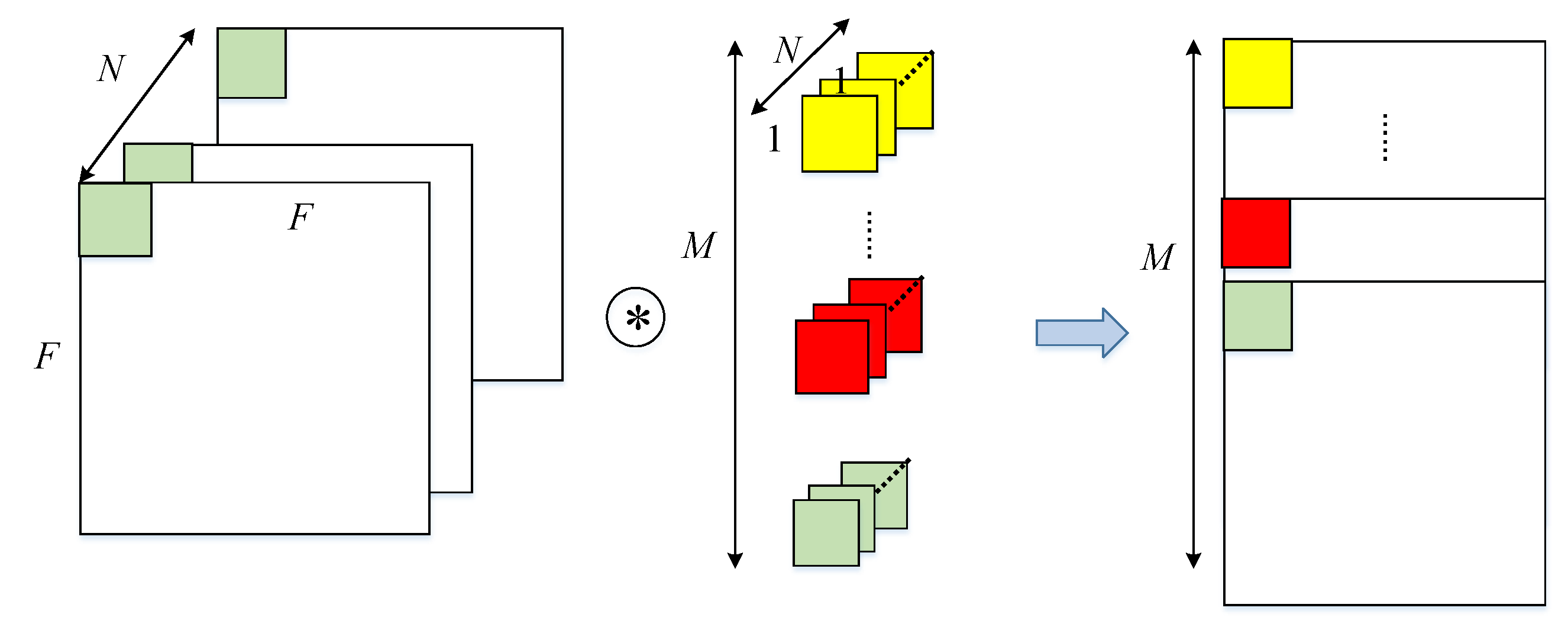
Depthwise Convolution
Liu, Bing, et al. "An FPGA-Based CNN Accelerator Integrating Depthwise Separable Convolution." Electronics 8.3 (2019): 281.
1チャネルに1つのフィルタが対応しており、各チャネルごとに対応したフィルタで畳み込みする。畳み込み処理はチャネルごとに独立しており、入力と出力のチャネル数は変わらない。
パラメータ数:
$$
K \times K \times N
$$
Pointwise Convolution (1x1 Convolution)
Liu, Bing, et al. "An FPGA-Based CNN Accelerator Integrating Depthwise Separable Convolution." Electronics 8.3 (2019): 281.
別名1x1 Convolutionと言われるように、単純にWindow Sizeが1x1の畳み込み。
1x1の畳み込みということは単純にピクセルごとのチャネル方向の圧縮だと考えるとわかりやすいかも。Window Sizeが1x1であること以外は通常の畳み込みと同じなので、出力のチャネル数はフィルタの数と等しい。
パラメータ数:
$$
M \times N
$$
1.2 どのくらいパラメータ数が小さくなった?
パラメーター数
通常のConv.: $M \times K \times K \times N = MK^2N$
Depthwise Separable Conv.: $K \times K \times N + M \times N = (M + K^2)N$
よって、
Depthwise Separable Conv.は $\frac{M+K^2}{MK^2} = \frac{1}{K^2} + \frac{1}{M}$ だけパラメータ数が減っている。
$M$はフィルタの数、$K$はフィルタの大きさでどちらも1より大きいため、かなり小さくなっていることがわかる。(通常$M>>K^2$, e.g. $M=32, K=3$)
MobileNet v1では通常のConvolutionをこのDepthiwise Separable Convolutionに変えて、13段重ねることで、約1/8 ~ 1/9に総演算量を削減 している。
2. MobileNet-v2(2018/01登場)
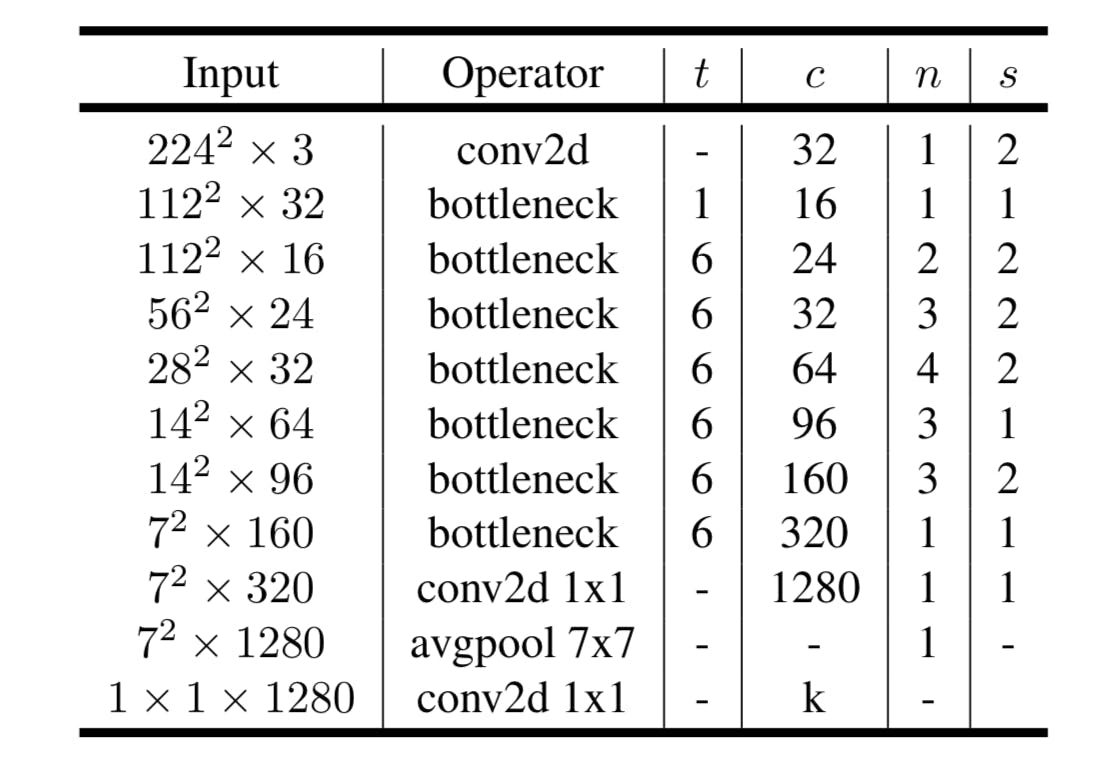
Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
新しくbottleneck(=Inverted Residual)を導入。
Depthwise Separable Convolutionにおいて、Pointwise Convolutionの計算量(パラメータ数)が大きいため、これを減らす為に、Depthwise Separable Convolutionに代わってInverted Residualを導入した。
要点は
- Inverted Residual
2.1 Inverted Residual
ResNetで使われるResidual Blockを応用したもの。
Residual Blockは入力からチャネル方向に注目すると、
広い(入力) -> 狭い -> 広い
という構造(Bottleneck構造)になっているが、Inverted Residualでは
狭い(入力) -> 広い -> 狭い
となっている。
Inverted Residualは途中でDepthwise Convolutionを入れているため、
オリジナルのResidual Blockよりもパラメータ数が少ない。
2.1.1 Original Residual Block (ResNet)
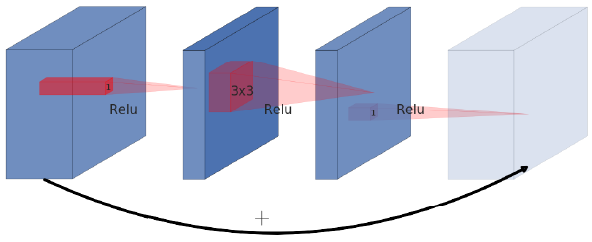
Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
そもそも元々のResNetにおけるResidual Blockが何のためにあったかというのは、
間にある3x3Conv.の計算量が大きいのでそれを減らすために3x3Conv.を1x1Conv.で挟むことによってチャネル方向を圧縮してから3x3Conv.を行うようにしている。
2.1.2 Inverted Residual Block (MobileNet-v2)
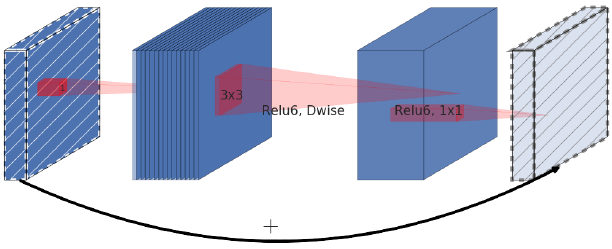
Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
3x3Depthwise Conv.を1x1Conv.(Pointwise Conv.)で挟む構造。
小さな1x1Conv.を2つ使うことで計算量ボトルネックであった1x1Conv.を小さな計算量で近似した。
拡張率$t$に従ってInverted Residual Blockに入ってきたデータのチャネル数を拡張する。
2.2 v1とv2の比較
Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
一般的に畳み込みでは層を重ねるごとにチャネル数が増加していきパラメータ量を圧迫していくが、v1は最終的に形が$7\times7\times1024$になるのに対してv2は$7\times7\times320$までしかならないためパラメータ数がv1よりも小さい。
ただし、チャネル数が小さいというのはその分情報量を十分に抽出できなく精度が出なくなってしまうため、Inverted Residual Blockの中でのみチャネル数を一旦増やすことで解決している。
v2は1x1Conv.の計算量を減らすために、1つの大きな1x1Conv.の代わりに小さな1x1Conv.を2つ使うことで近似した。
入出力チャネル$N$の1x1Conv.: $N^2$
入力$N$出力 $\frac{N}{t}$ の1x1Conv.と入力 $\frac{N}{t}$ 出力$N$の1x1Conv.: $\frac{2}{t}N^2$
よって 拡張率$t=6$(提案モデル標準)でパラメータ数が $\frac{1}{3}$ になることがわかる。
3. MobileNet-v3(2019/05登場)
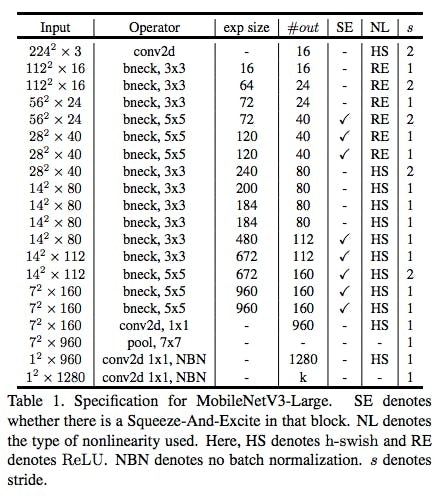
Howard, Andrew, et al. "Searching for mobilenetv3." arXiv preprint arXiv:1905.02244 (2019).
2019年5月に出た、出来立てホヤホヤのモデル
要点は
- BottleneckへのSqueeze-and-Exciteモジュールの導入
- h-swish
3.1 BottleneckへのSqueeze-and-Excitationモジュールの導入
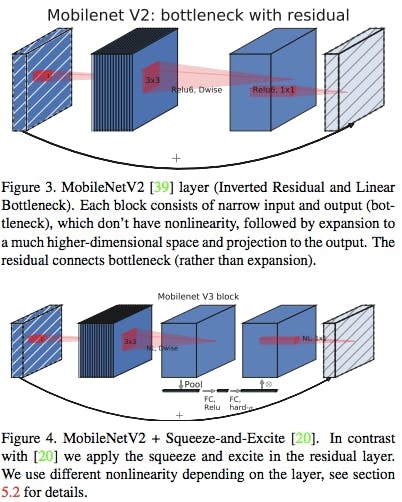
Howard, Andrew, et al. "Searching for mobilenetv3." arXiv preprint arXiv:1905.02244 (2019).
上図においてFigure4のようにInverted Residual Block内に3x3Conv.による特徴量抽出とSqueeze-and-Excitationモジュールなるもの(後述)を導入。
Squeeze-and-Excitationモジュール
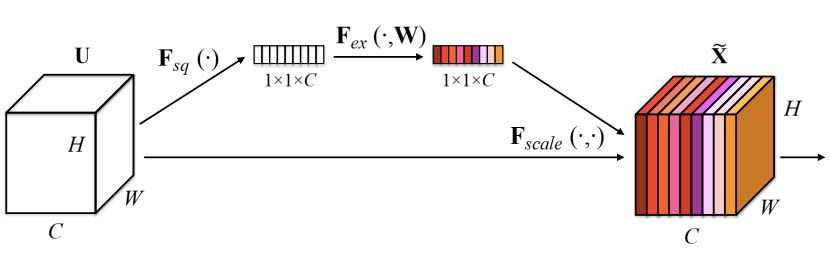
Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
SENetで初登場。上図において、左のInputデータからチャネルごとの重みを全結合層で算出して、それを掛け合わせたデータを新しいInputとして用いる。チャネルのSelf-Attentionとも言える。コードで書くと非常に簡単。
# Code: https://qiita.com/koshian2/items/6742c469e9775d672072
def se_block(input, channels, r=8):
# Squeeze
x = GlobalAveragePooling2D()(input)
# Excitation
x = Dense(channels//r, activation="relu")(x)
x = Dense(channels, activation="sigmoid")(x)
return Multiply()([input, x])
InputデータからGAPで各チャネルごとの代表値をとって(Squeeze)、それをinputとして全結合層(上図に置ける奥の経路)に入れて各チャネルの重みを計算したのち最終的には元々のInputデータとその重みを掛け算する(Excitation)だけ。
3.2 h-swish
ところどころh-swishと言われる関数を活性化関数としてReLUの代わりに使っている。(モデル構造を表す図におけるNLがHSになっている箇所がh-swish)
$$
h-swish[x] = x\frac{ReLU6(x+3)}{6}
$$
ここでReLU6とは
$$
ReLU6(x) = min(max(x,0),6)
$$
で、重みが最大でも6までにしかならないReLU。
4. 補足
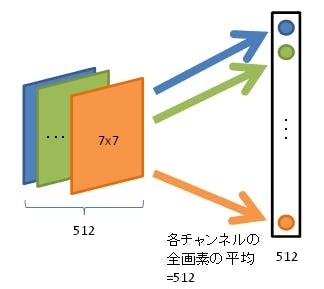
4.1 Global Average Pooling(GAP)
各チャネルごとに平均値をとり、それを最終のSoftmax層にぶちこむ。
GoogLeNetから使われ始めた。最後の全結合層を丸ごとGAPに取り替えることで全結合層によるパラメータの増加と過学習を抑えた。
Ex.) チャネルが512個(=フィルターが512枚)あった場合、GAPによりチャネルごと(フィルターごと)の平均を出し、出てきた512個を最終層に入力としてぶちこむ。
4.2 Convolutionの計算量に関する直感的な捉え方
Convolutionの計算量に関するおもしろい考え方をこちらのサイトで見つけた。
通常のConvolutionは空間方向とチャネル方向の計算を同時にしている。
フィルターは画像平面を移動しながら畳み込むが、このとき畳み込みはチャネル全体に同時に及ぶ。
つまり前者が空間方向、後者がチャネル方向の計算となる。InputとOutputの計算の関係を表した図が下図である。線の数が計算量となる。

図の例ではウィンドウサイズ3x3のConvolutionであるが、左図が空間方向(簡単のため一次元のみ)で右図がチャネル方向である。
左図(空間)について、Outputの1箇所にはInputの3箇所が影響していることがわかる。
右図(チャネル)について、Outputの1箇所にInputの全箇所(全チャネル)が影響していることがわかる。
この図からもわかるように、Convolutionにおいて空間方向の計算よりチャネル方向の計算の方が圧倒的に多い ことがわかる。
MobileNet-v2ではチャネル方向の膨大な計算量を変わらず持ってしまっている1x1 Convolution(=Pointwise Convolution)の計算量を減らしたいというモチベーション。
この考え方を用いたv1のDepthwise Spectral Convolutionやv2のInversed Residual Blockの計算量の考え方は元のサイトを参照。
5.まとめと所感
MobileNetはいろんな賢い方法でパラメータ数を減らしていっていることがわかった。こういったパラメータ削減のテクニックはCNNだけでなく他のモデルにも使えそうだと感じた。
いいねやコメントお待ちしております!!
【他の記事】
2019年最強の画像認識モデルEfficientNet解説
6. 参考
-
【論文まとめ】MobileNet V1, V2, V3の構造
MobileNetについてまとめたQiitaの記事。
概要がつかめた。 -
Depthwise Separable Convolution - A FASTER CONVOLUTION!
MobileNet-v1のDepthwise Separable Convolution解説のわかりやすい動画。なぜ計算量が小さいのかもわかった。 -
Deep Learning - プーリングについて
基本的なプーリング4種類の解説が簡潔かつわかりやすい。 -
MobileNet(v1/2)、ShuffleNet等の高速なモデルの構成要素と何故高速なのかの解説
Convolutionの計算量についての考え方がすごくわかりやすい。
上から飛ばさずに丁寧に読むと途中でつまづかない。
MobileNet-v2の仕組みがわかりやすかった。 -
MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNet-v2のInverted Residualの説明がコード付きでわかりやすい。 -
MobileNetV2: Inverted Residuals and Linear Bottlenecks_翻訳・要約
なぜv2がv1より優れているか書いてある。 -
Squeeze-and-Excitation Networksの効果を確かめる
Squeeze-and-Excitationモジュールの説明が書いてある。