単に精度だけを追求した重いモデルではなく、今後の深層学習のmobile化を目指し、オフラインでもエッジ端末で動くような「軽い」モデルの研究が盛んなよう。
製作中のRaspberry pi 戦車でも利用しているMobileNetがどんなものか気になったので、特に構造に関して、論文の記述をざっくりとまとめておきます。
MobileNet V1
Depthwise & Pointwise Convolution
- 通常の畳み込み層演算処理を空間方向とチャンネル方向の2段階に分けて行う
- まず各チャンネル毎に独立して空間方向(Depthwise, 3x3)にのみ畳み込み演算
- 次に1x1フィルターの畳み込みによりチャンネル方向(Pointwise, 1x1)にのみ畳み込み演算
- 1/8〜1/9に総演算量を削減
様々な高速モデルの仕組みをまとめているこちらの記事の通り、精度を保ちつつ高速演算できるように通常の畳み込み層を2分割している。1つの通常の畳み込み層を空間方向(Depthwise, 3x3)とチャンネル方向(Pointwise, 1x1)の2層に分け、個別に演算処理することで1/8〜1/9に全体の演算量を削減している。
Depthwise Convolutionの仕組み
- weight matrix Wをmask行列でmaskすることで、通常の畳み込み演算と同様の手法でDepthwise Convolutionを実現
空間方向に独立した畳み込み演算(Pointwise)は1x1フィルターを適用することで実現できる。しかし、チャンネル方向に独立(Depthwise)した演算に関しては、単純に考えれば各チャンネル毎に相当するカーネルを各々適用して演算を行うため、非常に時間がかかる。それを克服したのがこちらの論文。
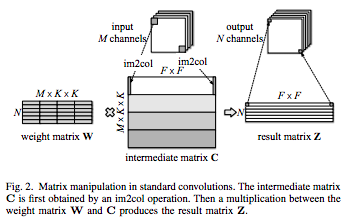
(図は論文より引用)
上図は通常の畳み込み演算の模式図であり、weight matrix Wと、im2colで演算データを抽出して2次元配列にしたintermediate matrix Cとで内積計算するが、どうしてもチャンネル方向も計算に絡む。
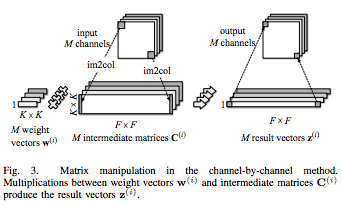
(図は論文より引用)
上図の通り、通常の3次元フィルターではなく、チャンネル方向をなくした2次元フィルター(カーネル)を入力チャンネル数分用意してそれぞれ演算させてもいいが、当然時間がかかる。
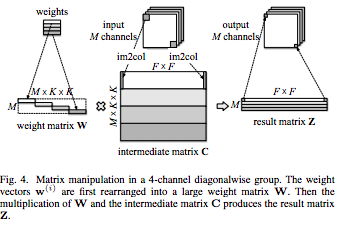
(図は論文より引用)
そこで上図のように、weight matrix Wをsparseにして、計算に絡ませたい該当チャンネルの部分だけ要素を格納し、他の要素はゼロにしておく。これで、通常の畳み込み演算と同様に内積計算させるだけでチャンネル方向に独立したDepthwise Convolutionを実現している。上図のweight matrix Wの行列中の一つ一つの横棒が各カーネル(shape:K,K)に相当する。
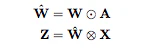
実際には、上式のようにmask行列Aを用意し、計算に絡ませたい要素のみを残した$\hat{W}$を作る。Backward Propagationで流れてきた勾配に関しても同様にmask行列Aを勾配行列にかける。
Depthwise Separable convolutions
Depthwise層とPointwise層をまとめたものをDepthwise Separable convolutionsとしてまとめてモジュール化している。下図の通り、それぞれの層にBatchNormalizationとReLUが付随している。

(図は論文より引用)
モデル構造
- 全体として28層
- 通常の畳み込み層の後、Depthwise Separable convolutionsを積層、最後はPoolingして全結合層
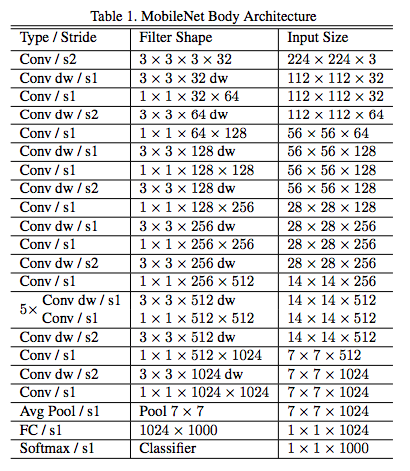
(表は論文より引用)
一番最初の入力層には通常の畳み込み層をエッジ検出用に配置。その後、Depthwise Separable convolutionsを13回(DepthwiseとPointwiseで26層)繰り返し、最後にAvg Poolingして全結合層となる。パラメータを持つ層として合計で28層からなるモデルを構成している。
Parameters
- モデル構築時のパラメータとして2つ
- Width Multiplier: 各層のチャンネル数を制御(Kerasでは"alpha"パラメータ)
- Resolution Multiplier: 各層の特徴量(解像度)を制御(Kerasでは"depth_multiplier"パラメータ)
Width Multiplierは各層のチャンネル数を制御(減らす)ためのパラメータ。0.25, 0.50. 0.75, 1.0から選択。1.0が論文通りの通常のモデルに相当し、値が減るごとに各層のチャンネル数が減る。チャンネル数が減る方が当然軽く速いモデルになる。
Resolution Multiplierは謎。解像度を調整するらしいが、入力画像サイズ(32〜224)によって通常は「暗黙的に」決まるパラメータらしく、それでは何故パラメータ化しているのかが私の頭では分からなかった。同じく混乱している様子がこちらにもあり。
MobileNet V2
Inverted residual block
V2ではthin-thick-thinの3層構造にさらに分解してモジュール化している。こちらの記事で紹介されているように、Pointwise(1x1 Conv)の計算量をさらに削減するために、DepthwiseをPointwiseで挟んだような構造になっている。従来のResidual blockのthick-thin-thickとは逆(Inverted)。
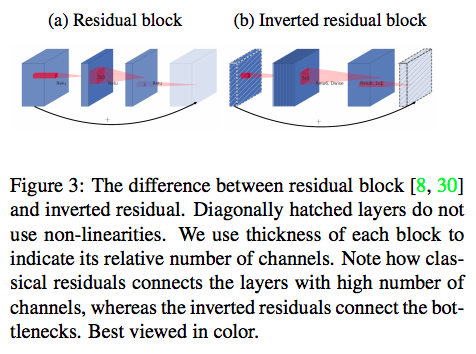
(図は論文より引用)
真ん中のDepthwiseでチャンネル方向の次元が増加し、その増加率が"t"(expansion factor)となっている。Expansion layerはテンソルの非線型変換を精密に実行するためだけの層で、必要な情報はbottleneck(thin)に詰まっていると解釈することで、従来のexpansion同士ではなくbottleneck同士をショートカットさせる今回の構造になったとのこと。
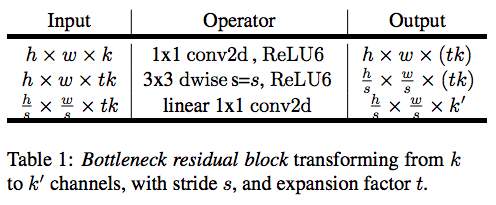
(図は論文より引用)
なお、出力の上限値を6に固定する"ReLU6"が採用されており、8ビット量子化による固定小数点演算でメモリ節約、軽量化を実現しているらしい。
モデル構造

(図は論文より引用)
上図の通り、最初の畳み込み層の後、19のresidual bottleneck layers(おそらく21層の前後をカウントから除いている)で構成されている。V1と比べ、だいぶスッキリした印象がある。
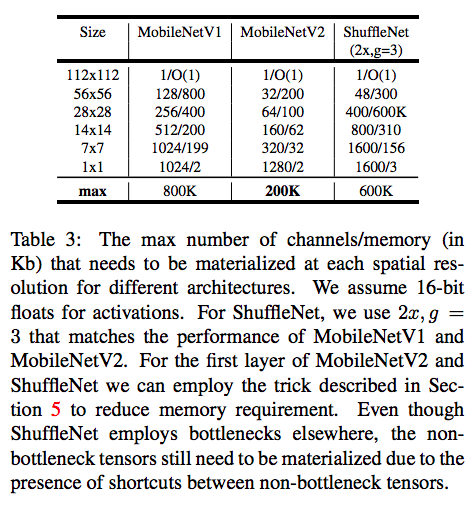
(図は論文より引用)
V2はだいぶ軽いですね。
Mobilenet V3
Squeeze-and-Excite
- MnasNetで導入されたSqueeze-and-Exciteをモジュールのbottleneckに適用
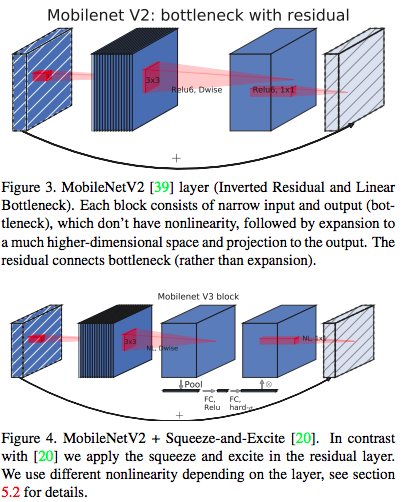
(図は論文より引用)
上図において、上がMobileNet V2のモジュール、下が今回のV3のもの。従来のショートカットの内側にさらにショートカットのように見えるものがある。これがSqueeze-and-Excite。

(図はこちらより引用)
通常の畳み込みフィルターでまずは畳み込み演算する。その各出力チャンネルには入力チャンネル方向の値の合算値が格納されているので、必然的にチャンネル依存的な性質を内包している。論文ではChannel relationships, channel interdependencies等と表現されている。ただ、畳み込みフィルターの演算結果であるテクスチャの各値は、当然フィルターサイズ分のlocalな情報(画像のある部分のspatial correlation)しか反映されておらず、その領域外のcontextual informationは反映されていない。そこで、Global Average Poolingで特徴マップのチャンネル毎の平均値をとり(空間方向を一つに"squeeze"する)、全結合-非線形変換-全結合-非線形変換の結果を元の特徴量に適用させる("Excitation"する)。これにより、フィルターサイズ限定のチャンネル依存的な特徴量から、画像(特徴量)全体のチャンネル依存性を反映した特徴量を生成することができる。論文では"self attention function on channels"と表現されている。上図のように、特徴量をチャンネル毎に「色をつける」ことで、特徴量全体としてどのチャンネルに着目するか(しないか)という視点を加えることで、モデルにより豊かな表現力を付与することができるらしい。
h-swish
非線形変換にはh-swishなるものを利用することで、より速く正確な推論が可能となったとのこと。活性化関数にはReLU6を利用。
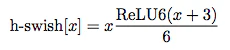
モデルの下流部分
Squeeze-and-Excite構造の追加で、より重いモデルになってしまったのかと思いきや、モデルの末端部分で工夫をしている。従来モデルでは、上流より下流でより計算コストがかかっていることが分かったため、下流の高次元特徴量生成層を最後のPooling層の後に配置。これにより、以前のbottleneckのショートカットやフィルター層が不要になり、結果として計算コストのかかる3層を精度を落とすことなく減らすことができている。

(図は論文より引用)
モデルの入口部分
モデルの入口部分にも手が加えられている。データ画像が一番最初にモデルに入るエッジ検出層には、従来通り、通常の畳み込み層(3x3)が配置されている。ただし、非線形変換にh-swishを使うことで、精度を落とすことなく従来の32フィルターから16フィルターに削減できている。
モデル構造
以上をまとめたモデル構造が以下。リソースに応じて重いLargeモデルと軽いSmallモデルの2種類が用意されている。
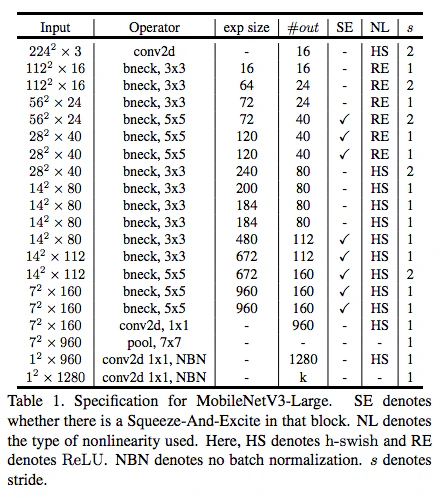
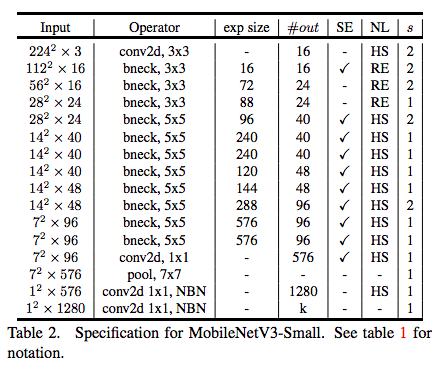
(図は論文より引用)
その他
こちらにMobileNet V3に対抗心剥き出しのモデルが早くも出ているみたいです。その名も"MoGA"。全然読めていませんが。論文読解が最近面白いです。