こちらの記事が面白かったので紹介されていた「Squeeze-and-Excitation」の効果をCIFAR-10を使って確かめてみました。転移学習についても検討してみました。
ILSVRC 2017 画像分類 Top の手法 Squeeze-and-Excitation Networks
https://qiita.com/agatan/items/8cf2566908228eaa5450
Squeeze-and-Excitationとは
紹介記事のほうで丁寧に解説されているので、こちらでは簡単にしますが、SkipConnectionにおいてGlobalPoolingを挟んでチャンネルをまたいだ演算をしてから乗算(Multipy)の演算で特徴量を重ねる構造。いろんなネットワークに対してつけられるのが売り。画像はSENetの論文より。
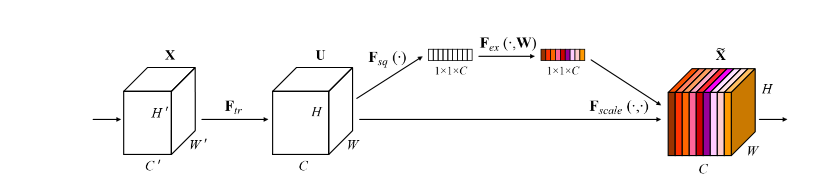
色がついているように、GlobalPooling+ボトルネックで特徴量を圧縮(Squeeze)し、それを乗算でかけることで元のネットワークを励起(Excitation)させるとのこと。確かに発想としては面白いです。
Kerasで書くとSENetの部分は一瞬でかけて、
# Squeeze and Excitation
def se_block(input, channels, r=8):
# Squeeze
x = GlobalAveragePooling2D()(input)
# Excitation
x = Dense(channels//r, activation="relu")(x)
x = Dense(channels, activation="sigmoid")(x)
return Multiply()([input, x])
となります。Excitationの最初のニューロン数を圧縮しているのは特徴量の集約もありますが、1x1畳み込みのボトルネックのような計算量の削減の効果も担っているのだと思います。summary()を見てみると、これがあることでパラメーター数の増加が抑えられています。
チャンネル間の演算をする発想としては既に「Depthwise Convolution(参考記事)」が有名で、これは広い意味でInceptionブロックの極端な場合と言われています。形は違えどもSENetでチャンネル間の演算をしているのは理解しやすいです。
実験
次のような実験をしてみました。CIFAR-10を分類し、精度を比較します。
1. SENetなしで新規に訓練する
2. SENetありで新規に訓練する
新規に訓練する場合のモデルはVGGライクな10層のモデルでやりました。また、SENetは既存のモデルにも転用できるのが売りなので、転移学習でも確かめてみます。
3. VGG16の転移学習
4. VGG16+BatchNormalizationを挿入した転移学習
5. VGG16+BatchNormalizationとSENetを挿入した転移学習
SENetのやっていることは結局「Depthwise Convolutionと同じではないか」という疑問があったので、既にDepthwise Convolutionが組み込まれているMobileNetでの転移学習もしてみました。
6. MobileNetの転移学習
7. MobileNet+SENetを挿入した転移学習
ちなみに1から訓練する場合は、ImageNetでの訓練結果が論文に載っていて、VGG16でもMobileNetでも精度が上がったそうです。
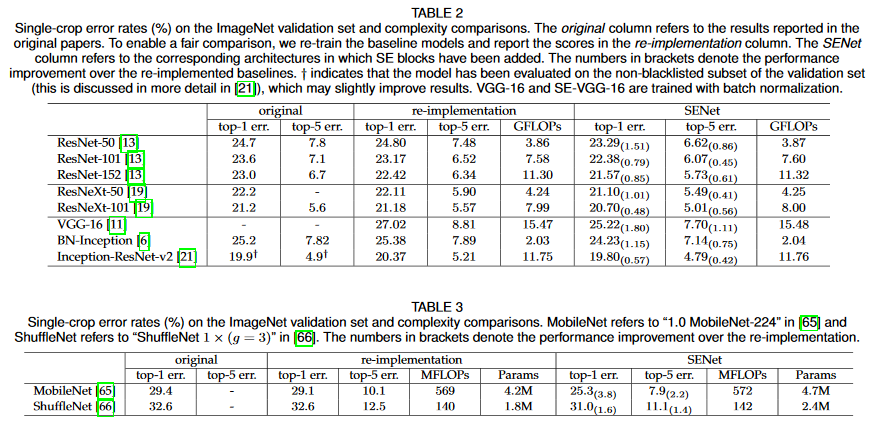
ただ1から入れる場合は、「正直Depthwise Convolutionに置き換えればよくない?」という気がしなくもないので、この記事ではConvレイヤーの置き換えが難しそうな転移学習を中心に見てみました。既存のモデルに対して新たにレイヤーを挿入するのはこちらに書いた方法でやってみます。
論文とはパラメーターが異なりますが、オプティマイザーは新規学習の場合は学習率1e-3のAdamを使い、転移学習の場合は学習率1e-5のRMSPropを使いました。バッチサイズは1024でColabのTPUで訓練させました。
SENetのReduction Ratio(ボトルネックの係数)は「8」を使いました。論文(ImageNet)では係数は8か16が良いそうでした。
コード
コードは以下のとおりです。
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, AveragePooling2D, GlobalAveragePooling2D, Dense, Multiply, Input
from tensorflow.keras.models import Model
from tensorflow.keras.applications import VGG16, MobileNet
import tensorflow.keras.backend as K
from tensorflow.keras.callbacks import History
from tensorflow.contrib.tpu.python.tpu import keras_support
from keras.activations import linear
from keras.datasets import cifar10
from keras.utils import to_categorical
import numpy as np
import os, pickle, zipfile, glob
def create_new_conv(input, chs):
x = Conv2D(chs, 3, padding="same")(input)
x = BatchNormalization()(x)
return Activation("relu")(x)
# Squeeze and Excitation
def se_block(input, channels, r=8):
# Squeeze
x = GlobalAveragePooling2D()(input)
# Excitation
x = Dense(channels//r, activation="relu")(x)
x = Dense(channels, activation="sigmoid")(x)
return Multiply()([input, x])
def create_new_network(use_se_block):
input = Input((32,32,3))
x = input
for i in range(3):
x = create_new_conv(x, 64)
if use_se_block: x = se_block(x, 64)
x = AveragePooling2D(2)(x)
for i in range(3):
x = create_new_conv(x, 128)
if use_se_block: x = se_block(x, 128)
x = AveragePooling2D(2)(x)
for i in range(3):
x = create_new_conv(x, 256)
if use_se_block: x = se_block(x, 256)
x = GlobalAveragePooling2D()(x)
x = Dense(10, activation="softmax")(x)
return Model(input, x)
def create_transfer_vgg(use_batch_norm, use_se_block):
vgg = VGG16(input_shape=(64,64,3), include_top=False, weights="imagenet")
x = vgg.layers[0].input
for i, layer in enumerate(vgg.layers):
if i == 0: continue
if "conv" in layer.name:
if use_batch_norm:
layer.activation = linear
x = layer(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
else:
x = layer(x)
if use_se_block:
x = se_block(x, layer.filters)
else:
x = layer(x)
x = GlobalAveragePooling2D()(x)
x = Dense(10, activation="softmax")(x)
return Model(vgg.inputs, x)
def create_transfer_mobilenet(use_se_block):
mobile = MobileNet(input_shape=(128,128,3), include_top=False, weights="imagenet")
# Squeeze and Excitationを入れるレイヤー
se_layers = ["conv1"]
se_layers += ["conv_pw_"+str(x) for x in range(1,14)] # DepthwiseConv2Dには入れない
x = mobile.layers[0].input
for i, layer in enumerate(mobile.layers):
if i == 0: continue
x = layer(x)
if layer.name in se_layers and use_se_block:
x = se_block(x, layer.filters)
x = GlobalAveragePooling2D()(x)
x = Dense(10, activation="softmax")(x)
return Model(mobile.inputs, x)
def generator(X, y, batch_size, upsampling_ratio):
while True:
indices = np.arange(X.shape[0])
np.random.shuffle(indices)
for i in range(X.shape[0]//batch_size):
current_batch = indices[i*batch_size:(i+1)*batch_size]
X_batch = X[current_batch].repeat(upsampling_ratio, axis=1).repeat(upsampling_ratio, axis=2)
X_batch = X_batch / 255.0
y_batch = to_categorical(y[current_batch], 10)
yield X_batch, y_batch
def train(case_no):
print("case ", case_no, "starts")
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# ネットワーク
if case_no == 0: model = create_new_network(False)
elif case_no == 1: model = create_new_network(True)
elif case_no == 2: model = create_transfer_vgg(False, False)
elif case_no == 3: model = create_transfer_vgg(True, False)
elif case_no == 4: model = create_transfer_vgg(True, True)
elif case_no == 5: model = create_transfer_mobilenet(False)
elif case_no == 6: model = create_transfer_mobilenet(True)
# アップサンプリング倍率
if case_no <= 1: upsampling_ratio = 1 # 新規
elif case_no <= 4: upsampling_ratio = 2 # VGG
else: upsampling_ratio = 4 # MobileNet
# ジェネレーター
batch_size = 1024
train_gen = generator(X_train, y_train, batch_size, upsampling_ratio)
test_gen = generator(X_test, y_test, batch_size, upsampling_ratio)
# オプティマイザー
if case_no <= 1: optimizer = tf.train.AdamOptimizer() # 新規学習
else: optimizer = tf.train.RMSPropOptimizer(1e-5) # 転移学習
model.summary()
model.compile(optimizer, "categorical_crossentropy", ["acc"])
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
hist = History()
model.fit_generator(train_gen, X_train.shape[0]//batch_size,
validation_data=test_gen, validation_steps=X_test.shape[0]//batch_size,
callbacks=[hist], epochs=100)
history = hist.history
if not os.path.exists("result"):
os.mkdir("result")
with open(f"result/case_{case_no}.dat", "wb") as fp:
pickle.dump(history, fp)
def main():
for i in range(7):
K.clear_session()
train(i)
with zipfile.ZipFile("senet_history.zip", "w") as zip:
for f in glob.glob("result/*.dat"):
zip.write(f)
if __name__ == "__main__":
main()
結果と議論
まずは条件を整理しておきます。
| ケース | モデル | 追加事項 | SENet | 学習方法 | 係数 |
|---|---|---|---|---|---|
| 1 | オリジナル10層 | - | ☓ | 新規学習 | 1,927,946 |
| 2 | オリジナル10層 | - | ○ | 新規学習 | 1,993,970 |
| 3 | VGG16 | - | ☓ | 転移学習 | 14,719,818 |
| 4 | VGG16 | BatchNorm | ☓ | 転移学習 | 14,736,714 |
| 5 | VGG16 | BatchNorm | ○ | 転移学習 | 15,194,074 |
| 6 | MobileNet | - | ☓ | 転移学習 | 3,239,114 |
| 7 | MobileNet | - | ○ | 転移学習 | 4,205,590 |
Squeeze and Excitation(SENet)を使っているのはケース2,5,7です。ケース4ではもともとBatchNormが入っていないVGGの係数に対しBatchNormを挿入し、精度の向上を確かめ、転移学習において新規のレイヤー挿入が必ずしも精度の悪化とならないことを確かめます。またここでの転移学習とは初期の重みのみの設定で、係数の固定はありません。
係数のサイズについて補足しまょう。SENetの係数の増分は主にチャンネルサイズに依存します。例えばチャンネルサイズが256で、Reduction Ratioが8なら、SENetのブロック1個あたり「256×(256÷8)×2=16,384」ですみますが、もしチャンネルサイズが1024になれば「1024×(1024÷8)×2=262,144」も必要になります。オリジナル10層モデルの最大チャンネル数は256、VGG16は512、MobileNetは1024なので、最大チャンネル数が特に多いMobileNetでは係数は増える傾向にあります(もちろんReduction Ratioを大きくすれば減らせます)。
前置きが長くなりましたが結果を見てみます。新規学習の場合は「学習率1e-3のAdam」、転移学習の場合は「学習率1e-4のRMSProp」で学習させた結果です。
| ケース | テスト精度 | ゲイン |
|---|---|---|
| 1 | 89.33% | |
| 2 | 89.51% | 0.17% |
| 3 | 90.34% | |
| 4 | 91.12% | 0.78% |
| 5 | 91.03% | 0.68% |
| 6 | 93.45% | |
| 7 | 92.38% | -1.06% |
新規学習の場合は、SENetの効果を確認することができました。しかし、転移学習の場合は、SENetを入れたほうが精度が悪くなるということが起こっています。これは学習済みの係数に対して新規のレイヤーを入れたから、学習にムラが起こって精度が下がるということだけではないようです。なぜならBatchNormがないVGG16にBatchNormを追加したケース4では精度が上がっているからです。VGG16の転移学習ではBatchNormを入れたら(ケース4)精度は上がりましたが、BatchNorm+SENet(ケース5)ではほぼ誤差レベルですが、ケース4を下回る結果となりました。
正直、オプティマイザーや学習率の差による感が否めないので、ケース3~ケース7について、「学習率1e-3、係数0.9のMomentum」のオプティマイザーを使ってもう一度試してみました。
| ケース | テスト精度 | ゲイン |
|---|---|---|
| 3 | 89.77% | |
| 4 | 90.83% | 1.06% |
| 5 | 91.05% | 1.28% |
| 6 | 93.53% | |
| 7 | 92.26% | -1.27% |
オプティマイザーと学習率を変えれば、転移学習でもVGGではSENetは精度の向上に寄与することがわかりました。ただ、MobileNetだけは明らかに精度が下がる結果となりました。
MobileNetで精度が下がったことについて、畳込みのフィルター数のプロパティが取得できなくてDenpthwiseConvlutionの層にはSENetを張らなかった、つまり通常のConv2Dの層だけSENetを張ったこともあるかもしれません。論文のImageNetの例では、MobileNetでも(新規学習ですが)「SENetの使用によりImageNetでのTop1エラーを3.8%減らした」とあるので、貼り方が悪かったのか、新規学習と転移学習の差なのか、ImageNetとCIFAR-10の差なのか、他のハイパラの選択が悪かったのか議論の余地があると思います。
MobileNetだけ悪いというのなら、あくまでこれは仮説の話ですが、SENetの役割とはチャンネル方向の特徴量の抽出と増強なので、MobileNetでは既にDepthwiseConvによってチャンネル方向の畳込みが行われているから、あえて似たような効果のSENetを追加しても効果が半減してしまうのではないかという疑問があります。もっとざっくり言うと「新規でモデル作るならそれDepthwiseConvでよくね?」という疑問です。しかし、先程の図ではImageNetで最もトップ1エラーが減ったのはMobileNetだったので、データが難しくなればちゃんと効果があるのかもしれません。
しかし、このようなアバウトな設定ではSENetの本来の効果を引き出すというのは難しいようです。現に新規学習やVGGでのSENetのゲインが0.2%程度とほぼ誤差レベルで、CIFARだけ見たら効果が出ているのか確認しづらいです。ImageNetのようにもっと大規模で難しいデータセットだったら効果があるので、これだけでSENetの効果を否定することはできませんが、少なくともCIFARではこのようなアバウトな設定で論文通りの精度出すのは厳しかったです。BatchNormみたいにどんなときもほぼわかりやすく効果が出せというのは無理難題でしょう。
論文にあったCIFAR-10、100の例です。
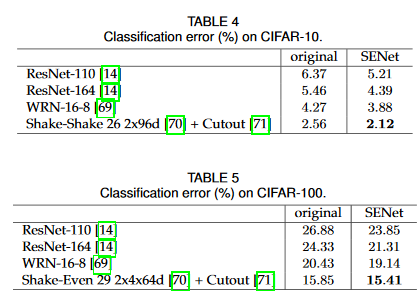
ほぼResNet系を中心に訓練していますね。確かにこれらのResNet系ではチャンネル方向への畳込みがないので、SENetのようにチャンネル方向への作用があるアーキテクチャでは、かなり補完する形で機能すると思います。論文でも議論されていますが、ResNetのSkipConnectionと、似たような分岐であるSENetを同時に作用させるという設計もあったので、おそらくResNet系ではこのSENetは使いやすいのではないかと思います。その点では「そういうアイディアもあるのか」ぐらいに頭の片隅においておく価値はあると思います。
SENetのあれこれ
最後に論文で議論されていたSENetの細かい設定について補足したいと思います。
Excitationの活性化関数
まず、SENetの最初のDense(再掲の下記コード参照)の活性化関数ですが、ここはReLUで設計しています。これは理解しやすいです。
# Squeeze and Excitation
def se_block(input, channels, r=8):
# Squeeze
x = GlobalAveragePooling2D()(input)
# Excitation
x = Dense(channels//r, activation="relu")(x)
x = Dense(channels, activation="sigmoid")(x)
return Multiply()([input, x])
しかし、不思議なのはその次のExcitationの活性化関数で、Sigmoidが一番よかったそうです。
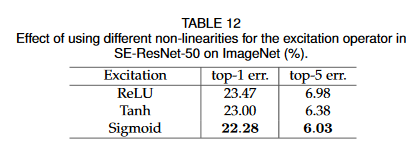
Excitationの活性化関数は「Sigmoidが良いというか、ReLUが明らかに悪い」とのことです。普通Sigmoidというと「勾配が消えやすいから出力層以外ではほぼ使わない」というのが第一印象ですが、ResNetのように勾配が消えないようにSkipConnectionでつないでいくアーキテクチャではまた別なのかもしれません。
ReLUが悪いのはなんとなく理解できて、ReLUのマイナス方向は全て0になってしまうから、Multipyの演算をすると結果的にニューロンの多くが0になります。もしReLUのマイナスとプラスの出方が50:50なら、この演算は50%のDropout入れているのとイメージ的には近くなります。それだと明らかに過剰なのでアンダーフィッティングしてしまい、精度が悪くなってしまうのでしょう。なので、ある程度線形性があって、ブーリアンマスクの要素があるtanhやsigmoidが良いというのはよく考えてみると理解できます。
Reduction Ratio
SENetのボトルネックとなっている($\frac{C}{r}$)のrの値です。
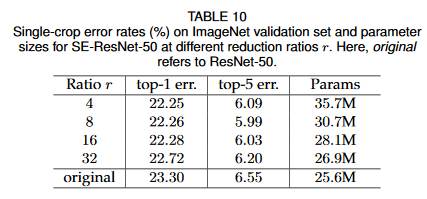
1×1畳み込みと全く同じ発想で、「チャンネルを一時的に減らすことで計算量を減らせるけど、ReLUの非線形性からよほどきつい圧縮をしなければ逆に精度が上がるよ」という理屈です。1×1畳み込みでもこのように圧縮率を横軸にすると、V字型の検証曲線が描けます。
ResNetのResBlockとの共存
ここがSENetのキモであり面白いところなのですが、ResNetのResBlockと共存できるような設計について論文で議論されています。
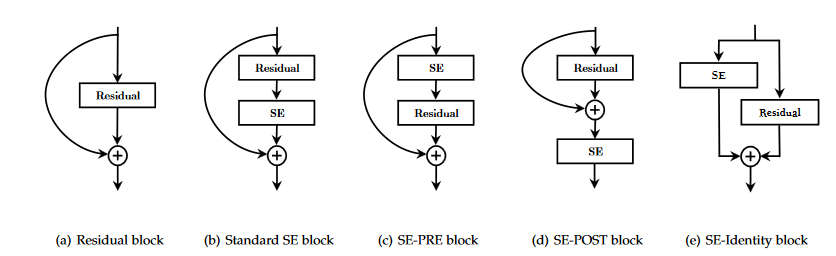
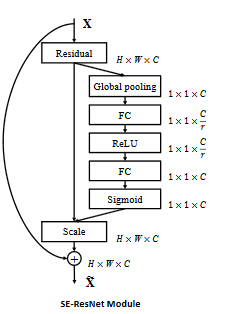
このようにいろいろなパターンについて試されているようです。最後のプラスのオペレーターは元をMultipyした後にAddの操作をします。これは先程の図のSE-ResNet Moduleにかかれています。
これらのResBlockとSEの配置の差による精度の差ですが、後ろに入れるの以外は正直どれでもいいんじゃないという感じです。
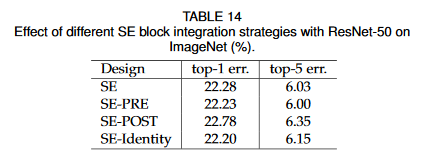
AddしたあとにSEブロック入れるSE-POSTは明確に悪くて、それ以外は似たり寄ったりという感じが。通常のSEブロックや、SE-PREなんかが感覚的にはわかりやすい気がします。作る人の好みで選べばいいのではないでしょうか。
ちなみにSENetを組み込んだResNet50(SE-ResNet-50)は次のようになります。これは通常のSEブロックの例です。

わかりやすいですね。ResNetのコードがあれば少し付け足すだけなので。
ここからは自分の意見ですが、SENetがDepthwiseConvと似たような機能を持っているので、ResNetにSEBlockを追加するだけで既存のResNetをXception化に近いようなことができるのだと思います。ResNetファミリーはいろいろとバリエーションがあるので、例えばWideResNetにSEBlock入れてチャンネル方向のオペレーションを入れるとかかなり面白そうな感じがします。
今回自分がやったCIFAR-10の実験では微妙な結果となってしまいましたが、よく見ていくとアイディア的に面白い、スルメみたいなモジュールではないかなと思います。なんでも入れられる(つまり転移学習で付け足す)というより、現在のCNNの主流であるResNet系に入れられて、直感的にはXception化できるというのが強みではないのかなと自分は思います。