ILSVRC 2017 の画像分類タスクでは Squeeze-and-Excitation という手法が 1 位を記録しました。
シンプルなアイディア・実装で、既存モデルの拡張にも利用できるうえ、精度も 2016 年の top 1 と比べてエラー率を約 25% 減らすという大きな成果をあげています。
Reference
- Jie Hu, et al., https://arxiv.org/pdf/1709.01507.pdf
文中の図表は論文から引用しています。
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
Squeeze and Excitation
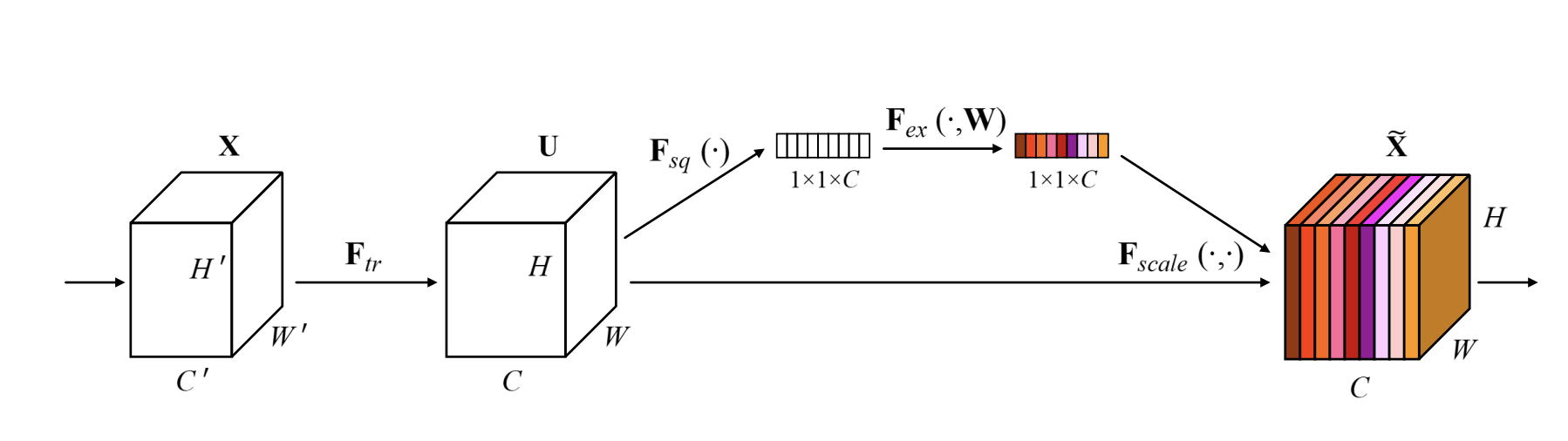
この論文では、SE block というブロックを提案しています。
SE block は特定のネットワーク全体の設計の提案ではなく、ネットワーク中の 1 component として振る舞うものです。
SE block を既存のいろいろなネットワークやモジュール(ResNet、Inception、...)に組み込むことで精度が向上することを実験で確かめています。
SE block は非常に実装が簡単なので先に実装を見てしまったほうがわかりやすいかもしれません。
def se_block(input, channels):
"""
Args:
input: (N, H, W, C)
channels: C
Returns:
tensor: (N, H, W, C)
"""
# Squeeze
x = GlobalAveragePooling2D()(input) # (N, C)
# Excitation
x = Dense(channels // 16, activation='relu')(x)
x = Dense(channels, activation='sigmoid')(x) # (N, C)
return Multiply()([input, x])
SE block は、通常の convolution の出力をそのまま使うのではなく、 各 channel の出力を重み付けして使う ようにすることで、チャンネル間の関係性の学習を可能にするブロックです。
Squeeze
既存のモデルは、convolution と activation を重ねることで、局所的な特徴を獲得していきます。
層が深くなったり pooling したりすると、局所的といいつつも広い視野を持っていくことになりますが、視野を一歩こえた先の情報などはまったく考慮できず、画像全体におけるチャンネル間の関係性を表すことはできません。
そこで、画像全体の特徴を活用するために、 global average pooling を利用します。(Spatial Squeeze)
Excitation
そうして得た「画像全体のチャンネルの状況」をいくつかの layer に通したのち、sigmoid に通します。
最後にブロックに入力されてきた値 input に、 sigmoid 関数を通して 0~1 の範囲に収めた「各チャンネルの重み」を掛けて出力しています。
この部分が Excitation とよばれる部分です。
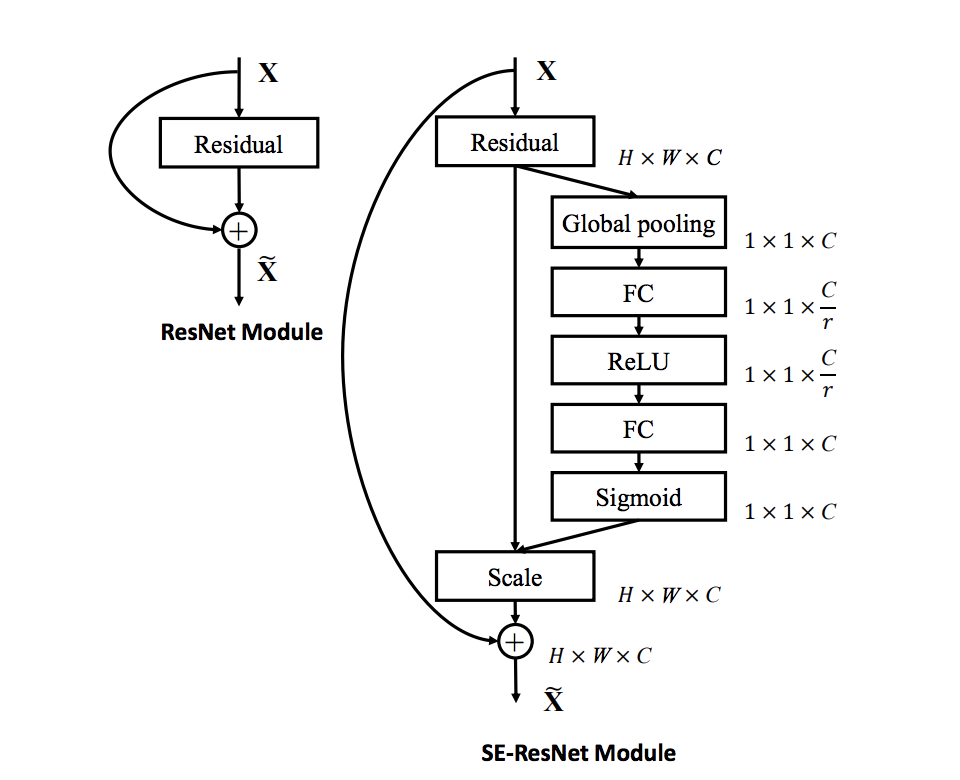
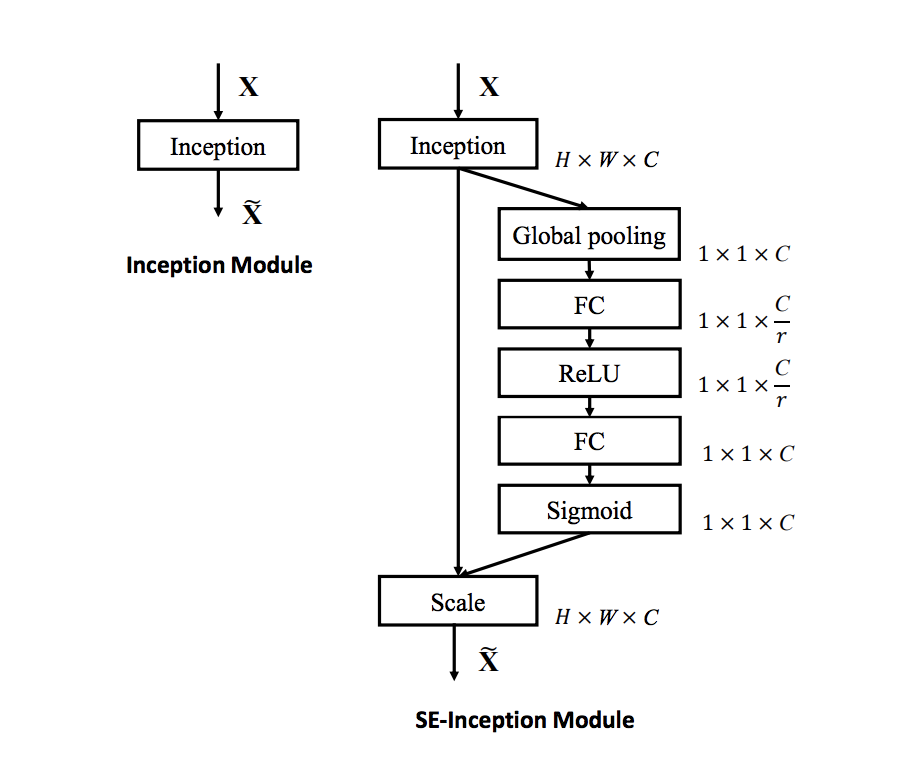
既存モデルへの組み込み
SE block は既存のモデルへの組み込みが容易であることも大きな強みです。
いくつかの組み込み方が提案・実験されています。
|
|
組み込み方もシンプルで簡単に試せるのですばらしいですね。
まとめと感想
かなりいろんなセットアップで実験をしているので、詳細は論文を参照ください。
Wantedly People で使われているモデルにも実験的に組みこんでみたところ、確かに数%の改善が確認できました。
この論文の続編的なものとして、segmentation タスクなどの fully convolutional networks 用の SE block 亜種が提案されています。
この advent calendar のどこかでそちらの紹介もできればと思います。