
MobileNetV1: 概要
MobileNetV1(以下V1)1 では、通常のconvolutionを、depthwise convolutionとpointwise convolutionの2つのサブタスクからなるdepthwise separable convolutionに置き換えることで計算コスト・パラメータ数を大きく削減した。ほぼ同じ精度で、計算コストを1/9ほどに削減ができた。
また、width multiplier / resolution multiplier というハイパーパラメータを導入することで、各層のチャネル数 / 解像度を小さくし、精度は下がってしまうものの、計算コスト・パラメータ数を大きく削減することができた。

図1: 通常のconvolution(a)とdepthwise separable convolution(b)のイメージ比較 1
MobileNetV2: 構造
MobileNetV2(以下V2)2 はV1同様に、基本的にdepthwise separable convolutionを用いている。V2では、さらに expand/projection layers と inverted residual block がポイントになる。
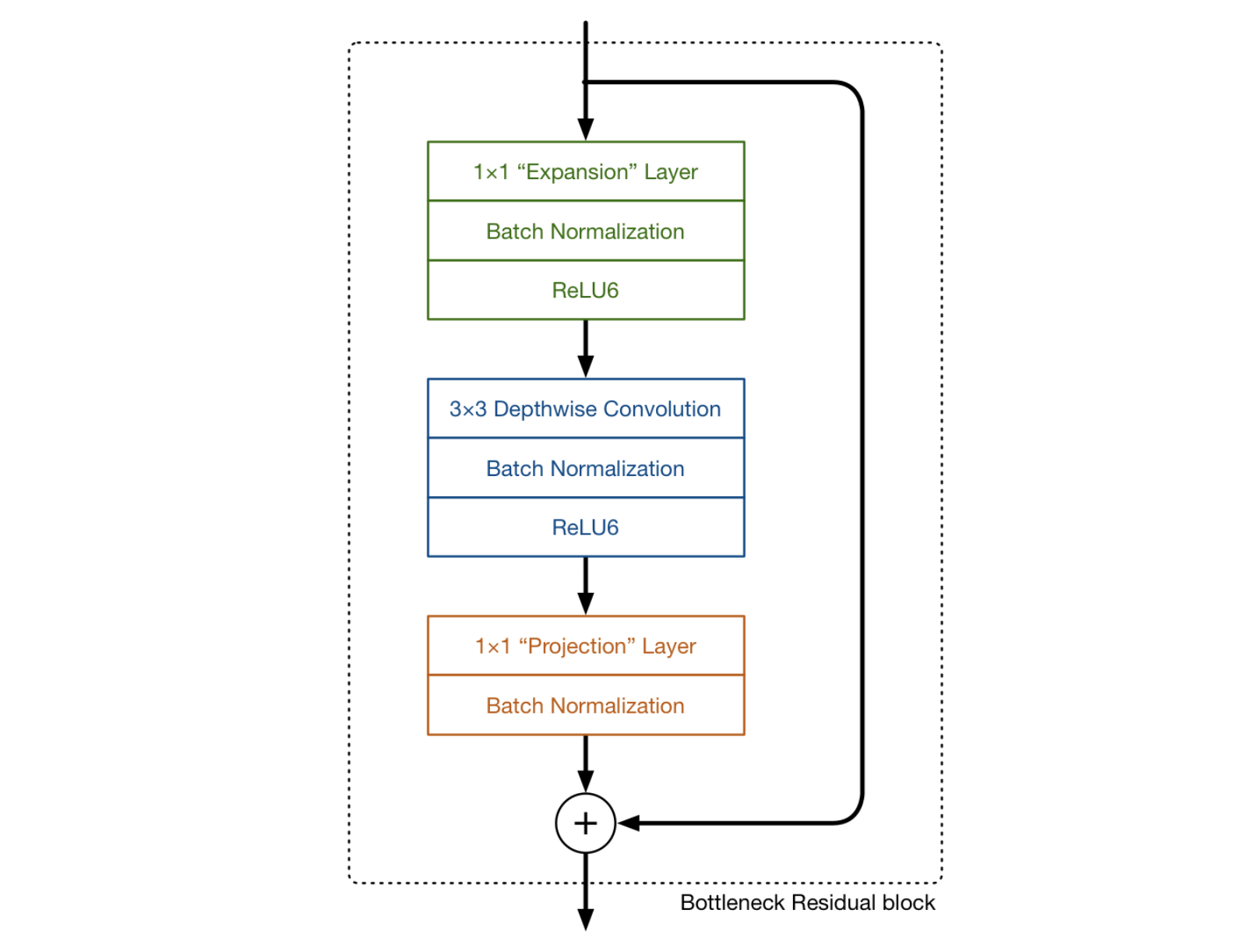 図2: MobileNetV2における畳み込みのイメージ [^3]
図2: MobileNetV2における畳み込みのイメージ [^3]
 図3: MobileNetV2における畳み込みのイメージその2 [^2]
図3: MobileNetV2における畳み込みのイメージその2 [^2]
expansion/projection layers
図2における2番目と3番目の層はそれぞれ、depthwise separable convolution の depthwise convolution と pointwise convolution である。 pointwise convolution に関しては、V1においてはチャネル数を1倍、もしくは2倍にする役割を持っていたが、V2では、チャネル数を小さくする役目をする。そのため、V2ではprojection layerとも呼ばれている。 projection layer は、高次元(チャネル)を大幅に低次元にするという点で、V2において重要な役割を持つ。
例えば、144チャネルのインプットデータに対して depthwise layer が畳み込みを行う場合、 projection layer はそれを24次元まで削減する。このような層を bottleneck layer とも呼ぶ。これは、出力されるブロックがボトルネックであり、 bottleneck layer はネットワークを流れるデータを大きく削減するから、こう命名されている。
図3における、1番目の層はV2で初めて出てきたものである。これも 1×1 convolution であり、depthwise convolution に入る前にチャネル数を大きくするという役割を持つ。このとき、チャネル数を大きくする割合を expansion factor と呼び、ハイパーパラメータとして扱う。通常6が使われる。
例えば図4では、24チャネルの tensor がブロックに入ってきたとき、 expansion layer が 24 * 6 = 144チャネルにする。次に、depthwise convolution がそのまま144チャネルの tensor として出力し、最後に projection layer が24チャネルにまで小さくする。
 図4: MobileNetV2における畳み込みのイメージ その3 [^3]
図4: MobileNetV2における畳み込みのイメージ その3 [^3]
インプットとアウトプットは低次元の tensor であり、途中経過は高次元の tensor であるというのが特徴である。
inverted residual block
2つめの特徴は、inverted residual blockである。これは、勾配の流れを調節するためにインプットtensorとアウトプットtensorを足し合わせる役割を持つ。
MobileNetV2: ネットワーク構造
表1は、V2のネットワーク構造である。tは expansion factor であり、expansion layerでの拡大率である、cは出力チャネル数、nはそのブロックの繰り返し数、sは stride である。
 表1: MobileNetV2のネットワーク構造 [^2]
表1: MobileNetV2のネットワーク構造 [^2]
V2とV1の比較: なぜV2はV1より優れているのか?
一般的に畳み込みでは、層を重ねるごとにチャネル数は大きくなっていき、空間方向の次元は半分になる。V1では、 7×7×1024 までサイズが大きくなるのに対して、V2では、7×7×324 と小さい。tensor が低次元である方が、計算量は小さくなるので、V2のほうが計算量が小さくなっているとわかる。
一方で、低次元の tensor では、情報量を十分に抽出できないという問題もあるため、より精度を出すためには、高次元な tensor を用いて学習したいと考えられる。V2では expansion layer でデータのチャネル数を大きくし、フィルタを適用し、projection layer でチャネル数に戻すというやり方をとっているからである。
conv1x1の計算量がボトルネックとなっているので、1つの計算量の大きなconv1x1を、計算量の小さなconv1x1を2つ利用することで近似しているということである。具体的には、入出力チャネル数が$N$のconv1x1の計算量は$HWN^2$である。これに対し、入力チャネル数が$N$、出力チャネル数が$N/t$のconv1x1と、入力チャネル数が$N/t$、出力チャネル数が$N$のconv1x1の計算量の合計は$2HWN^2/t$となる。ここで、$t$はチャネルの拡張率 (expansion factor) である。
$t=6$の場合、conv1x1の計算量が$1/3$になることが分かる。3
 図5: MobileNetV2における畳み込みのイメージ その4 [^3]
図5: MobileNetV2における畳み込みのイメージ その4 [^3]
V2とV1の比較: 実験結果より
Object detection
Object detection における、V2とV1の比較である。V2はV1よりも精度が高く、さらにParams/MAdds/CPUともに小さいという結果が出ている。また、width multiplier を1.4に設定すると、精度は大きく向上するが、Params/MAdds/CPUともにV1よりも大きくなってしまう。
 表2: Object detection におけるV2とV1の比較 [^2]
表2: Object detection におけるV2とV1の比較 [^2]
図6は、V2(resolution multiplier 0.35, 0.5, 0.75, 1.0, 1.4), V1, NasNet, ShuffleNetの精度比較である。
 図6: V2, NasNet, V1, ShuffleNetの計算量と精度の比較 [^2]
図6: V2, NasNet, V1, ShuffleNetの計算量と精度の比較 [^2]
図7は、non-linearities と residual connectionsのパフォーマンス比較である。(a)よりbottleneck layerで活性化関数として線形なRelu6を用いるより、非線形性の処理をした方が精度が上がることが示されている。(b)では、expansion layer 間のショートカットより、bottleneck間のショートカットのほうが精度が高いことがわかる。
 図7: non-linearities と residual connectionsのパフォーマンス比較 [^2]
図7: non-linearities と residual connectionsのパフォーマンス比較 [^2]
この論文では、Single Shot Detector (SSD)4をよりmobileフレンドリーにしたモデルを提案している。SSDのprediction layerを全てseparable convolutions (depthwise
followed by 1 × 1 projection)で置き換えたモデルをSSDLiteと定義した。表3にあるように、パラメータ・計算コスト共に、SSDと比較して大きく下がっていることがわかる。
また、COCOデータセットにおけるObject detectionにおいては、MobileNetV2 +
SSDLite という組み合わせが最も低いパラメータと計算コスト、かつ高い精度を出した。(表4)
 表3: SSDとSSDLiteのパラメータ・計算コストの比較 [^2]
表3: SSDとSSDLiteのパラメータ・計算コストの比較 [^2]
 表4: COCO dataset object detection task におけるMobileNetV2 +
SSDLiteと他の手法の比較 [^2]
表4: COCO dataset object detection task におけるMobileNetV2 +
SSDLiteと他の手法の比較 [^2]
参考文献
-
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications," in arXiv:1704.04861, 2017. ↩ ↩2
-
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen, "MobileNetV2: Inverted Residuals and Linear Bottlenecks" in arXiv:1801.04381, 2018 ↩
-
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu and Alexander C. Berg, "SSD: Single Shot MultiBox Detector," in arXiv: 1512.02325, 2016. ↩