Deep Learningのテクニックの一つであるGlobal Average Pooling(GAP)を、なるべくわかりやすいように(自分がw)解説してみます。
基本となるネットワークモデル
今回はVGG-16をベースに考えてみます。
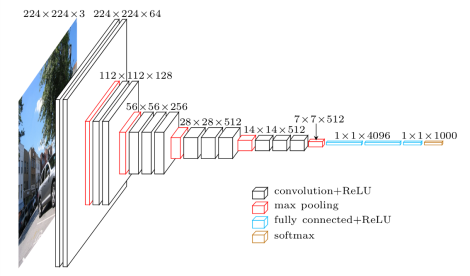
ポイントとなるのは、最後の全結合の部分です。
現状は、max poolingにより、7x7x512のデータができています。
これを1x1x4,096に全結合してますので、25,088×4,096=102,760,448の重みパラメータが存在しています。
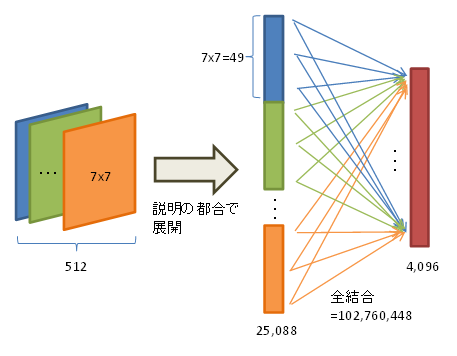
Global Average Poolingとは
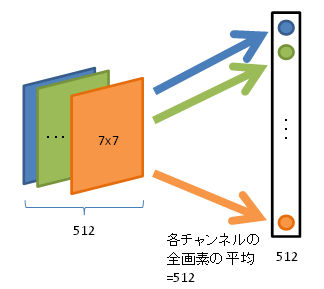
各チャンネル(面)の画素平均を求め、それをまとめます。
そうすると、重みパラメータは512で済みます。
評価
論文(pdf)によると、識別率に問題はない模様です。
(反対に良いぐらい!)

使用するメモリ量は少なく、識別率もよいなんて、いいことづくめですね!
おまけ
このGAPを利用した物体位置の検出がClass Activation Mapping(CAM)になります。
この辺りは
- Class Activation Mapping(CAM)の実装である「Weakly_detector」のソースを読み解く ~トレーニング編~
- Class Activation Mapping(CAM)の実装である「Weakly_detector」のソースを読み解く ~可視化編~
に書きましたので、参考にしていただければと思います。