無料で利用できるDatabricksコミュニティエディションがあることは意外と知られていないと思います。
コミュニティエディションについてはこちらの記事をご覧ください。機能制限はありますが、Databricksの使用感を体験していただくには好適な環境です。
Spark NLPがマイブームなのでコミュニティエディションで自然言語処理にトライしてみました。
画像編はこちらです。
Databricksコミュニティエディションへのサインアップ
以下のリンク先の手順に従ってアカウントを作成し、Databricksコミュニティエディションにログインします。
ランディングページが表示されます。
言語設定
GUIの言語設定が英語なので日本語に変更します。
-
画面左のサイドメニューの下にある歯車のマークをクリックしUser Settingsを選択します。
-
画面右上にあるLanguage settingsをクリックします。
-
Change your languageで日本語を選択します。
これでGUIが日本語になりました。
クラスターの作成
DatabricksでPythonを実行するなど計算処理を行うためには計算資源である「クラスター」が必要となります。
-
サイドメニューのクラスターをクリックします。
-
クラスターの作成ボタンをクリックします。
-
クラスター名にクラスターの名前を入力します。Databricks Runtimeとは、クラスター上にインストールされるソフトウェアパッケージです。ここでは、Runtime: 10.3 ML (Scala 2.12, Spark 3.2.1) を選択します。表示されている文字の意味は以下の通りです。
- Runtime: の後ろの数字はバージョンです。
- MLは機械学習ランタイムを意味し、scikit-learnやPyTorch、TensorFlowなど著名なライブラリも一緒にインストールされます。機械学習に関わる作業を行う際には機械学習ランタイムを選択すると環境構築の手間を省くことができます。
- LTSはLong Term Supportの略で現時点で最もサポート期間が長いランタイムであることを意味します。
- 括弧内の文字はScalaとSparkのバージョンです。
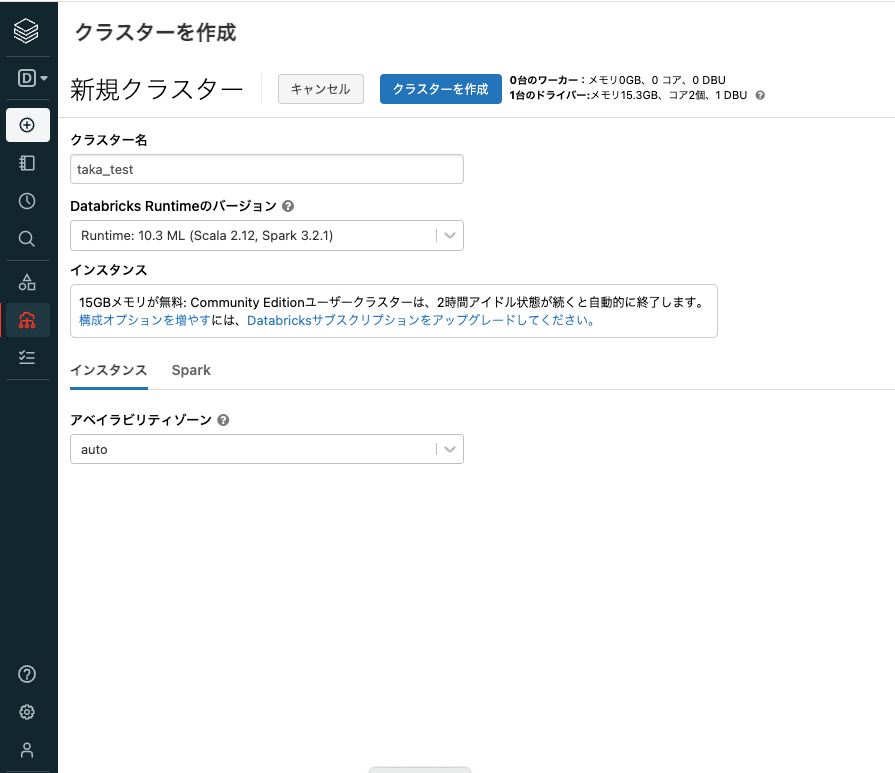
-
他はそのままでクラスターを作成ボタンを押すとクラスターの作成が始まります。
-
クラスターが起動すると、クラスター名の右にチェックマーク入りの緑の丸が表示されます。
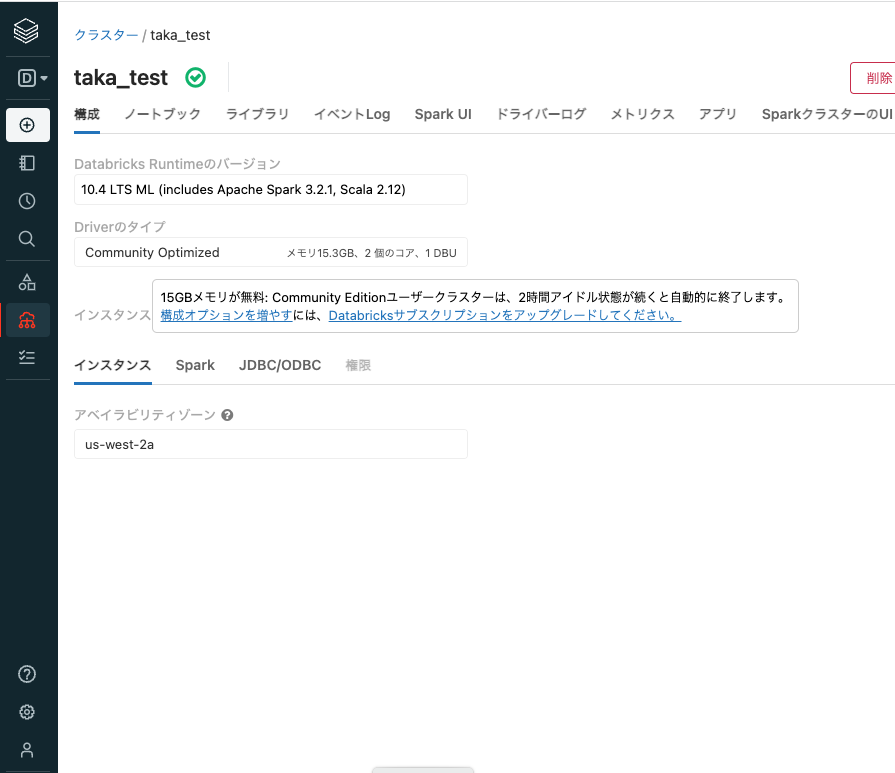
コミュニティエディションではクラスターのスペックを変更することはできませんが、フルバージョンであれば、GPUマシンを含む任意のスペックのインスタンスでクラスターを構成することができます。
ライブラリのインストール
クラスターの実態はクラウドサービスで提供されている仮想マシンです。クラスターを停止すると背後の仮想マシンは削除されます。このため、永続化したいデータは専用のファイルシステム(DBFS: Databricks File System)に保存する必要があります。
また、インストールしたライブラリも削除されるので、従来であればクラスターを再起動するたびにpipなどでライブラリをインストールする必要があります。これは手間なので、ライブラリをクラスターライブラリとしてインストールすると、クラスター起動時に自動でライブラリがインストールされるようになります。クラスターにアクセスするユーザーは誰でもこのライブラリを利用することができます。
注意
コミュニティエディションでは、一度停止したクラスターを再度起動することはできません。このため、コミュニティエディションではクラスターライブラリの意義は少ないですが、フルバージョンのDatabricksではクラスターライブラリ活用するのでこちらで紹介させていただいています。
以下の手順に従ってクラスターライブラリをインストールします。
マニュアルには追加のSpark設定が必要と記述がありますが、なくても動くので今回は割愛します。実際には以下の手順が追加となります。
-
作成したクラスターの画面右上の編集をクリックします。
-
画面下にあるSparkタブをクリックします。
-
Spark構成に以下の内容を追加します。
spark.serializer org.apache.spark.serializer.KryoSerializer spark.kryoserializer.buffer.max 2000M -
確認して再起動をクリックしてクラスターを再起動し設定を反映させます。
以下の2つのライブラリをインストールします。
- spark-nlp
- com.johnsnowlabs.nlp:spark-nlp-spark32_2.12:3.4.3
-
クラスターが起動していることを確認(クラスター名の右にチェックボックス入りの緑の丸が表示されます)して、ライブラリをクリックします。ここからクラスターライブラリをインストールすることができます。
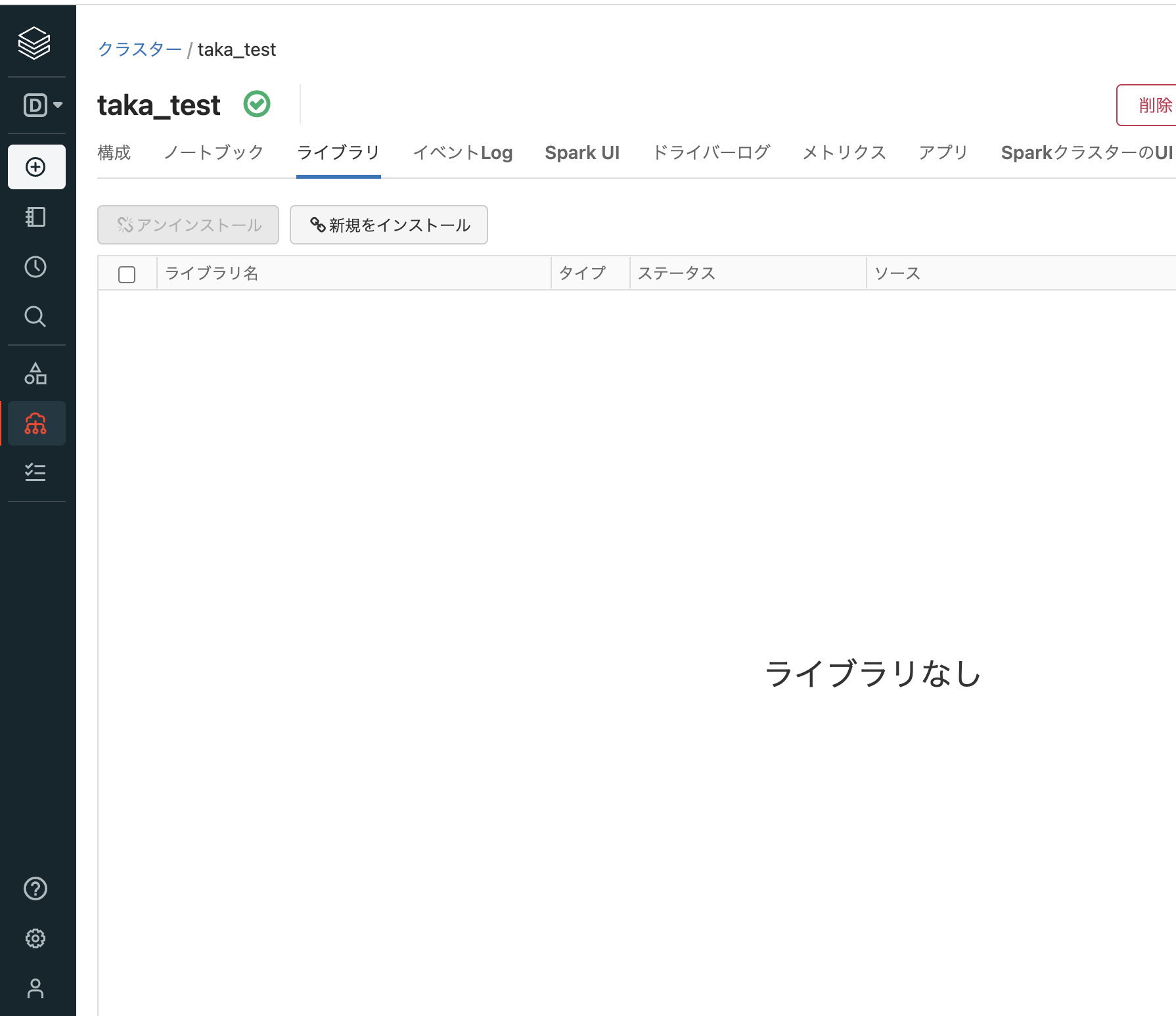
-
新規をインストールをクリックします。
-
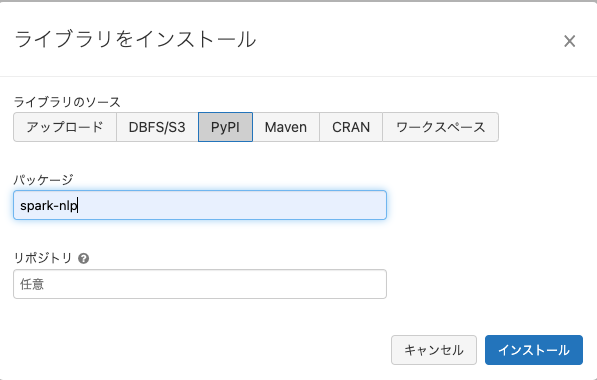
ライブラリのソースでPyPIを選択し、パッケージに
spark-nlpと入力し、インストールをクリックします。
-
新規をインストールをクリックします。
-
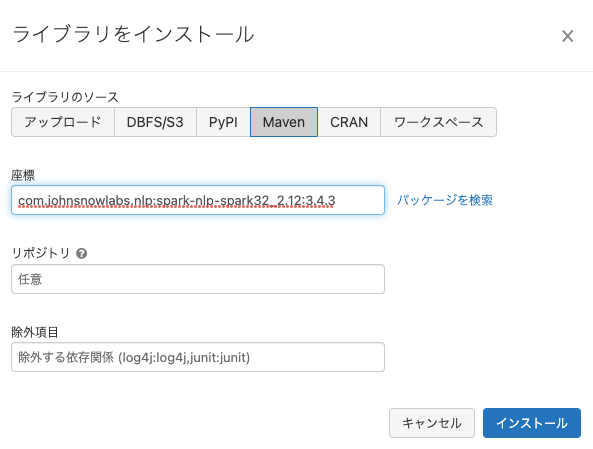
ライブラリのソースでMavenを選択し、座標に
com.johnsnowlabs.nlp:spark-nlp-spark32_2.12:3.4.3と入力し、インストールをクリックします。
-
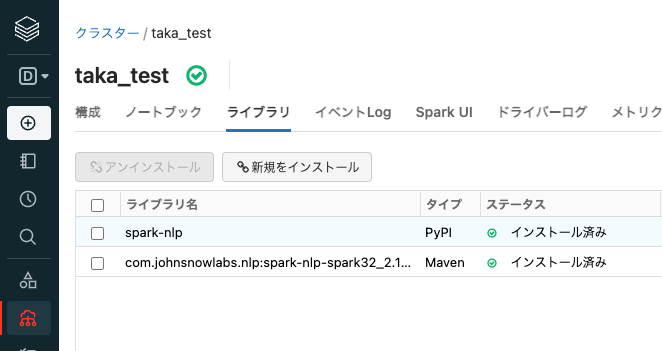
ライブラリのステータスが
保留中からインストール済みになったことを確認します。
ノートブックの作成
自然言語処理のコードをノートブックに記述します。
-
サイドメニューのワークスペースをクリックすると、ワークスペース上のフォルダーが表示されます。
-
右上のホームをクリックすると自分のホームディレクトリに移動します。
-
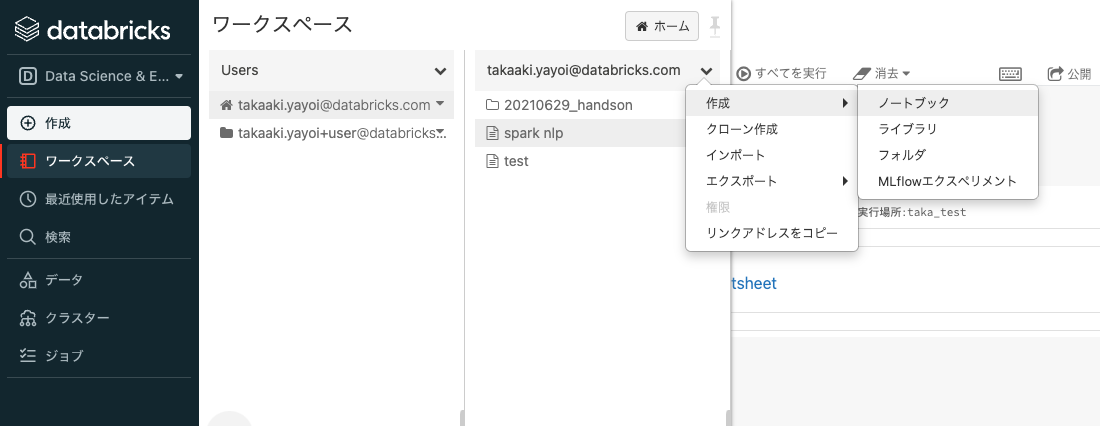
自分のユーザー名の右にある下向き矢印をクリックします。
-
作成 > ノートブックを選択します。
-
ダイアログが表示されます。
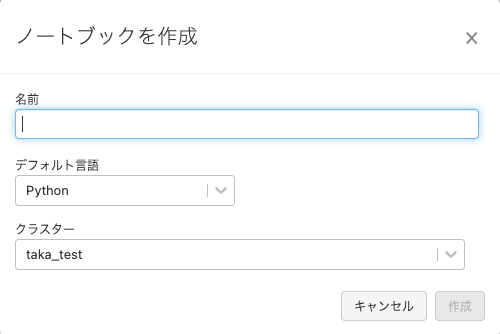
以下の内容を入力します。
- 名前: ノートブックの名前を入力します。例えば
DatabricksでNLP - デフォルト言語: Python
- クラスター: 上のステップで作成したクラスターを選択します。
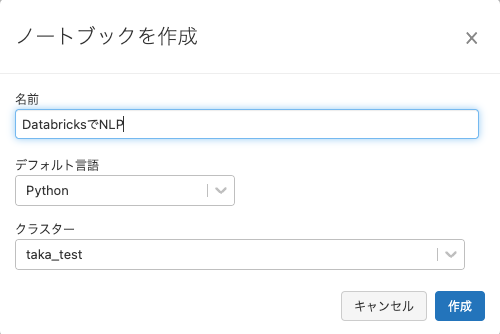
- 名前: ノートブックの名前を入力します。例えば
-
作成をクリックします。
-
ノートブックが表示されます。
自然言語処理(NLP)のコードの記述
-
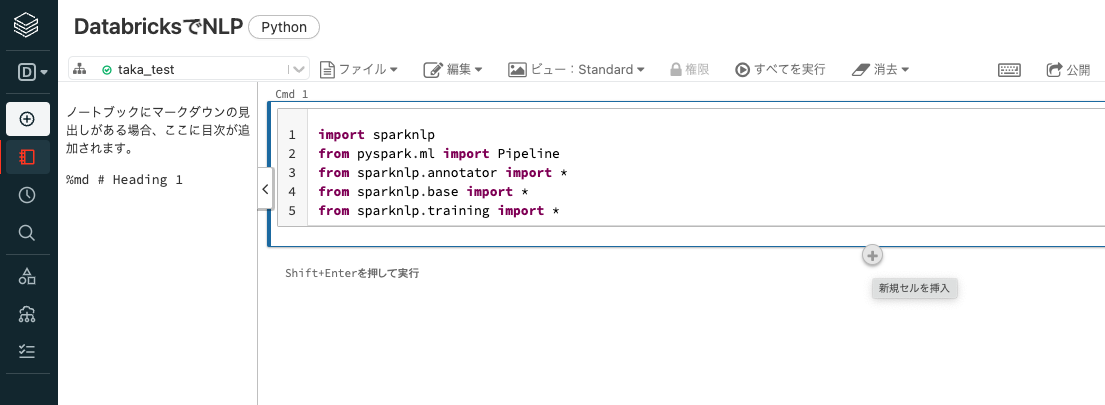
1つ目のセルにカーソルを移動し、以下の内容を入力します。必要なライブラリをインポートします。
Pythonimport sparknlp from pyspark.ml import Pipeline from sparknlp.annotator import * from sparknlp.base import * from sparknlp.training import * -
1つ目のセルの下にマウスカーソルを移動すると+マークが表示されるので、これをクリックします。新規セルが追加されます。
-
2つ目のセルに以下の内容を入力します。テキストの分かち書きを行うNLPのパイプラインを構築し、パイプラインを実行します。
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence_detector = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
word_segmenter = WordSegmenterModel.pretrained("wordseg_gsd_ud", "ja").setInputCols(["sentence"]).setOutputCol("token")
pipeline = Pipeline(stages=[document_assembler, sentence_detector, word_segmenter])
ws_model = pipeline.fit(spark.createDataFrame([[""]]).toDF("text"))
example = spark.createDataFrame([['データブリックスは、学術界とオープンソースコミュニティをルーツとするデータ+AIの企業です。']], ["text"])
result = ws_model.transform(example)
display(result)
コードの実行
画面右上にあるすべてを実行をクリックするとノートブックの全てのセルが実行されます。
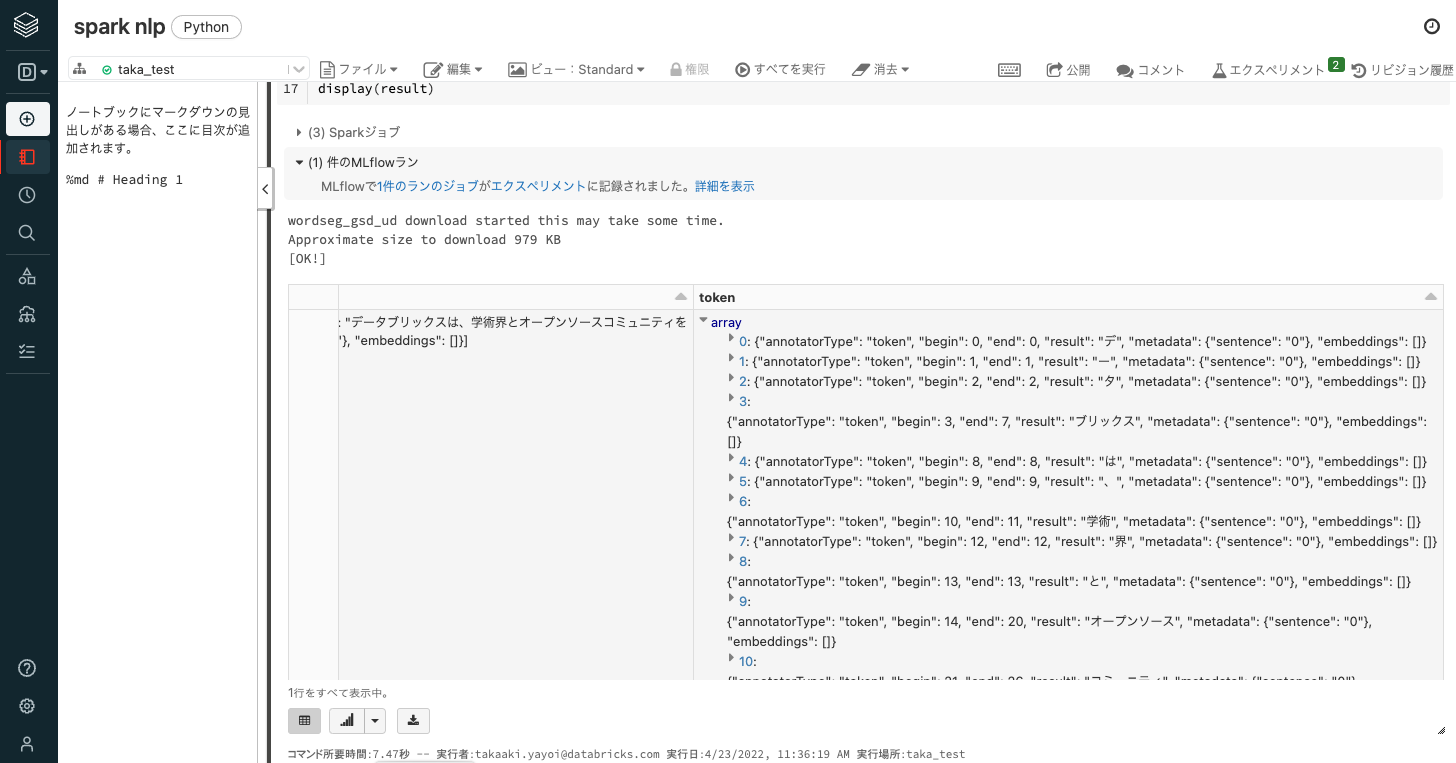
2つ目のセルの実行結果を右にスクロールするとtoken列に分かち書きされた結果が格納されています。
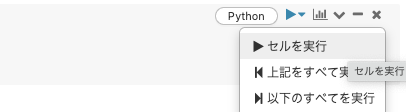
セルごとに実行する場合には、セルの右上の▶︎をクリックし、セルを実行を選択します。キーボードの<Ctrl> + <Enter>でショートカットできます。
例えば、上を実行した後で3つ目のセルに以下の内容を記述し、このセルだけを実行することでいろいろなテキストを対象に処理を行うことも可能です。
example = spark.createDataFrame([['お腹が空きました']], ["text"])
result = ws_model.transform(example)
display(result)
結果を見やすくするために一時ビューを活用
上の結果はネストされており一覧性に難があります。ここでは、Databricksのデータベース機能を活用してSQLで結果を整形します。
DatabricksにはHiveメタストアが同梱されているので、データベースの用途としても使用することができます。
以下のコマンドを実行してデータフレームを一時ビューとして登録します。なお、テーブルとして永続化することも可能です。
result.createOrReplaceTempView("result")
これでresultという一時ビューが作成されました。これに対してSQLのクエリーを実行することができます。ところで、ノートブックを作成する際にデフォルト言語をPythonにしたことを覚えていますでしょうか。このノートブックはPythonノートブックなので、SQLを実行するには専用の関数(spark.sql)を使わなくてはいけないのでしょうか...そんなことは不要です!
Databricksノートブックでは、セル単位で言語を切り替えることができます。以下のようにセルの先頭にマジックコマンド%sqlを記述するだけで、このセルでSQLを実行することができるようになります。他にも%r、%scala、%sh(シェル)、%md(マークダウン)などがサポートされています。
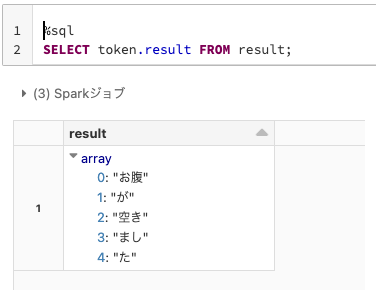
%sql
SELECT token.result FROM result;
このようなクエリーを実行することで、ネストされている中身のみを取り出すことができます。
さいごに
先日のウェビナー(近いうちにオンデマンド視聴できるようになります)でこちらのSpark NLPをご紹介させていただきましたが、大量テキストデータに対するスケーラビリティの確保にSparkの並列分散処理機能を活用でき、かつ、日本語にも対応しているので非常に使い勝手のいいライブラリだと思います。私もいろいろ試してみようと思っています。
自然言語処理の技術の進展によって以下のようなユースケースが実現されているのは、20年近くNLPに携わってきた人間からすると非常に興味深いです。
- ヘルスケアにおける大規模テキストデータへの自然言語処理の適用
- 自然言語処理によるリアルワールド診療データからのオンコロジー(腫瘍学)に関する洞察の抽出
- NLPを用いた薬害イベント検知による薬品安全性の改善
- ソリューションアクセラレータ:ゲームにおける有害行為の検知
- ESGに対するデータドリブンアプローチ
この他にもSpark NLPを紹介している記事を書いています。ほぼ翻訳ですが。