Applying Natural Language Processing to Healthcare Text at Scale - The Databricks Blogの翻訳です。
この記事はJohn Snow LabsのシニアソリューションアーキテクトMoritz Stellerとの共著となります。詳細を知りたい方は、7/15に予定されているバーチャルワークショップExtract Real-World Data with NLPをお見逃しなく。
2015年、HIMSS(医療情報管理システム協会)は、アメリカのヘルスケア業界において12億の医療ドキュメントが作成されたと推定しました。これは膨大な量の非構造化データです。これ以降、ヘルスケアにおけるデジタイゼーションによって毎年生成される医療テキストデータは増える一方です。電子フォーム、オンラインポータル、PDFのレポート、メール、テキストメッセージ、チャットボット、これら全てが現在のヘルスケアコミュニケーションのバックボーンとなっています。これらのチャネルで生成されるテキストの量があまりに多くて、人間が解釈、計測するには膨大なものとなっています。また、データセットは構造化されていないので、分析可能な状態でなく、多くの場合サイロ化します。
このことは、すべての医療機関にリスクをもたらすことになります。研究所のレポートに閉じ込められているプロバイダーノートやチャットログは価値のある情報です。患者の電子健康記録(EHR)と組み合わせることで、これらのデータポイントはより完全な患者の健康状態に対するビューを表現できるようになります。人口規模になれば、これらのデータセットを創薬、治療の道のり、現実世界の安全評価に活用できるようになります。
自然言語処理を用いて新たな健康上の洞察を得る
良いニュースがあります。コンピューターが書き文字、発声、テキスト画像を解釈できるようにする人工知能技術である自然言語処理(NLP)の発展によって、テキストから洞察を抽出することが可能となりました。NLPを用いることで、構造化されていない医療テキストを、後段の機械学習(ML)モデルに直接取り込めるように、構造化した形に変換して蓄積することができます。これらの技術は、研究、ケア領域で大きなイノベーションをもたらしています。
あるユースケースにおいては、アメリカ最大の非営利組織ヘルスプラン、ヘルスケアプロバイダーの一つであるKaiser PermanenteはNLPを活用して、エマージェンシールームの数百万のトリアージノートを分析することで、病床、看護師、医者の需要を予測し、最終的には患者のフローを改善しました。別の研究でも、構造化されていないテキストメッセージをNLPで分析し、HIV陽性の青年グループをサポートしています。この分析においては、グループに対するエンゲージメントと、治療への参画度合い、社会的サポートに対する感情との間に強い相関があることを明らかにしました。
ヘルスケアにおけるNLPの障壁は?
これらの信じられないイノベーションを目にして、一つの疑問が湧き上がります。なぜ、他の医療機関もこれらの医療テキストデータを活用しないのでしょうか?多くのヘルスケアにおける最大のペイヤー、プロバイダー、製薬企業と働いてきた我々の経験では、鍵となる三つの課題が存在していると言えます:
本来NLPシステムはヘルスケア向けに設計されていない: 医療テキストはそれ自身の言語となっています。広範なソースシステム(EHR、医療ノート、PDFレポートなど)のためデータに一貫性がありませんし、さらには、言語は医療専門分野によって大きく異なります。従来のNLP技術は、医療テキスト固有の語彙、文法、意図を理解するように設計されていません。例えば、以下のテキスト文字列では、NLPモデルはazithromycinが薬であること、500 mgは服用量、SOBは*pneumonia(肺炎)*の患者の状態に関連する"shortness of breath(呼吸困難)"の略語であることを理解する必要があります。また、処方を受けている段階なので、患者は"shortness of breath"ではないこと、まだ治療を受けていないことを推察することも重要です。

多くのNLPは適切に医療テキストを成文化できません。ヘルスケア向けSpark NLPはドメイン固有の言語を理解するために設計されたアルゴリズムとともに構築されています
柔軟性に欠けるレガシーなヘルスケアデータアーキテクチャ: テキストデータは情報の宝庫ですが、患者の健康状態に対して一つのレンズしか提供しません。包括的な患者のビューを作成するには、他の健康データと組み合わせて真の価値を生み出す必要があります。残念ながら、データウェアハウスに構築されたレガシーなデータアーキテクチャでは、スキャンされたレポート、生物医学画像、遺伝子シーケンス、医療機器のストリームなどの非構造化データをサポートできず、患者のデータを組み合わせることができません。さらに、これらのアーキテクチャは規模になるとコスト、複雑性が増加します。大規模なヘルスデータのコーパスに対するシンプルなアドホック分析ですら、処理に数時間、数日かかってしまいます。リアルタイムで患者の要求に応えるには遅すぎます。
最先端の分析機能の欠如: 多くの医療機関はデータウェアハウスやBIプラットフォーム上で分析を行っています。これは、先週使用された病床数の数を計算するような記述的な分析には向いていますが、将来使われる病床数を予測するようなAI/MLの機能には欠けています。AIに投資した組織は多くの場合、AIシステムをサイロ化された追加のソリューションとして取り扱います。このアプローチでは、異なるシステム間でのデータの複製が必要となり、結果、分析結果の不整合を引き起こし、洞察に至るまでの時間を遅らせます。
DatabricksとJohn Snow LabsがヘルスケアNLPのパワーを解放します
Databricksと、オープンソースのSpark NLPライブラリSpark NLP for Healthcare、Spark OCRのクリエーターであるJohn Snow Labsは、ヘルスケア、ライフサイエンス機関が、大規模なテキストデータを新たな患者に対する洞察に変換できるようにする新たなソリューションスイートを発表できることを嬉しく思います。我々のジョイントソリューションは、最先端のヘルスケアNLPツールと、全てのデータ、アナリティクス、AIに対してスケーラブルなプラットフォームを組み合わせたものとなっています。

DatabricksとJohn Snow LabsがヘルスケアNLPのパワーを解放します
基盤となるのは、データウェアハウスの優れた部分と、クラウドデータレイクのスケーラビリティ、柔軟性、低コストな部分を組み合わせたモダンデータアーキテクチャであるDatabricksレイクハウスプラットフォームです。このシンプルかつスケーラブルなアーキテクチャによって、ヘルスケアシステムは構造化データ、準構造化データ、非構造化データの全てを、従来型の分析とデータサイエンスで利用できる単一の高性能なプラットフォームに統合することができます。
DatabricksレイクハウスプラットフォームのコアはApache Sparkと、データレイクにパフォーマンス、信頼性、ガバナンスをもたらすオープンソースストレージレイヤーであるDelta Lakeです。医療機関は生のプロバイダーノート、PDFのラボレポートを含む全てのデータをDelta Lakeのブロンズ投入レイヤーに配置できます。これによって、あらゆるデータ変換を行う際に信頼できる唯一の情報源を確保できます。逆に、従来のデータウェアハウスにおいては、データを配置する前にデータ変換が行われます。すなわち、構造化されていないテキストから抽出された構造化変数は、本来のテキストと断絶されることを意味します。
この基盤の上に構築されるのが、ヘルスケア、ライフサイエンス業界で広く用いられているNLPライブラリであるJohn Snow Labs’ Spark NLP for Healthcareです。このソフトウェアは、芸術的とも言える精度で、医療、生物医学テキストデータに対してシームレスに抽出、分類、構造化を行います。これは、プロダクションレベル、スケーラブル、トレーニング可能な最新のヘルスケア特有のディープラーニングと転送学習技術の実装、200以上の定期的に更新される事前学習モデルによって実現されています。
特筆すべきJohn Snow Labsのソフトウェアライブラリの機能は以下のとおりです:
- 100以上の医療、生物医学エンティティ(症状・薬、解剖学、社会決定要因、研究、画像、遺伝子)の識別をアウトオブボックスで利用可能
- エンティティを意味的に近い用語コードに解決:SNOMED-CT、ICD-10-CM、ICD-10-PCS、RxNorm、LOICS、UMLS、MeSH、HPO
- 30以上のリレーションタイプを検知するための事前学習済みリレーション抽出モデル:医療イベント、トリートメント、薬、遺伝子、表現型など
- フリーテキスト、PDFドキュメント、スキャンされたレポート、DICOM画像に対してカスタマイズ可能な識別、ID除去、機微な情報の難読化
- 新たな用語、コンテンツで定期的に更新される、他では利用できないヘルスケア固有のワード、チャンク、センテンスのembedding(埋め込み)
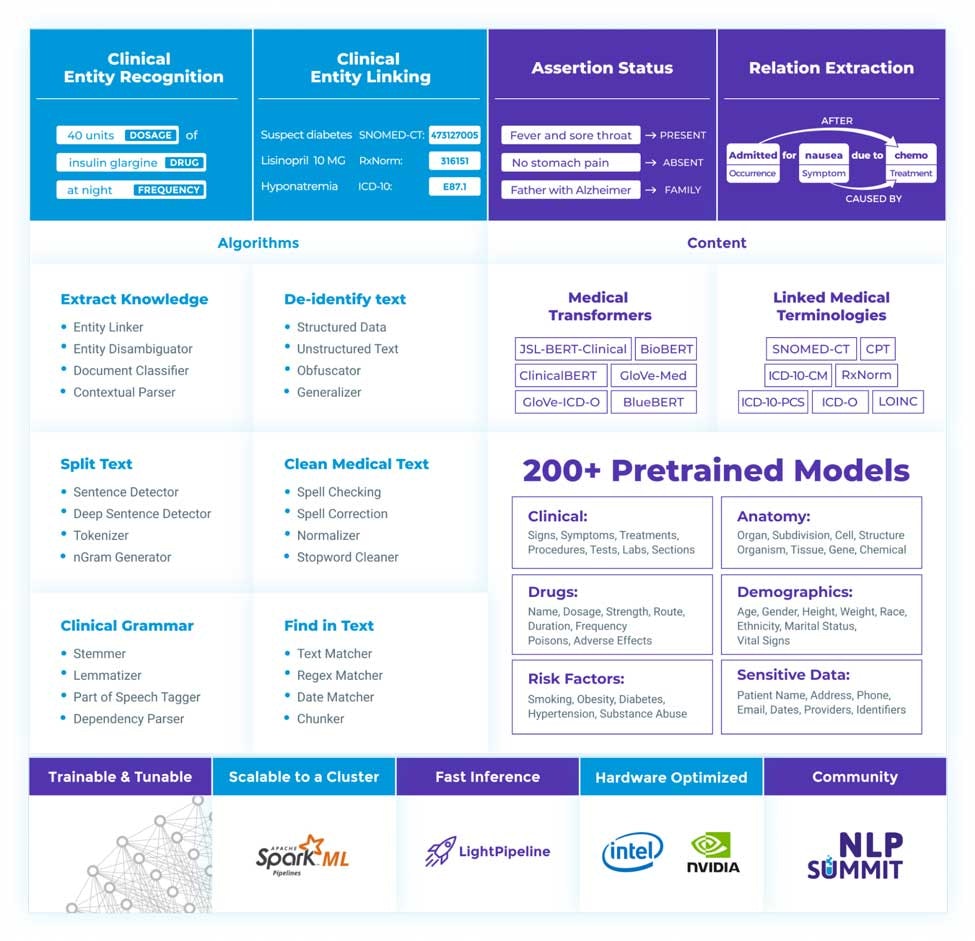
John Snow Labs’ Spark NLP for Healthcareライブラリは、医療業界における自然言語処理で使用できる最も頑健な機能、モデルを提供します
我々のジョイントソリューションは、Spark NLP for Healthcareと、Databricksのコラボレーティブな分析、AI能力を結合させたものです。インフォマティクスチームは生データを直接Databricksに投入し、Spark NLP for Healthcareを用いて大規模データを処理し、後段のSQLアナリティクスやMLで活用します。これらすべてを一つのプラットフォームで実行できます。トレーニング、推論の両方の処理は直接Databricksで実行されます。スピードとスケーラビリティのメリットに加え、これはデータが決して第三者に対して送信されないことを意味し、機微な医療データを処理する際の重要なプライバシー、コンプライアンス要件に応えられるというメリットもあります。そして、DatabricksはApache Spark™️の上に構築されており、Spark NLP for HealthcareのようなSparkアプリケーションが動作するには最適な場所と言えます。

医療テキストなどお持ちのデータに対する処理、分析、モデリングのエンドツーエンドのワークフローをDatabricksとJohn Snow Labsで実現
ヘルスケアにおける大規模テキストデータへの自然言語処理を始めるには
John Snow LabsとDatabricksによる自然言語処理ソリューションを用いて、どのように患者に対する新たな洞察を得るのかを知りたいのでしたら、7/15に予定されているバーチャルワークショップExtract Real-World Data with NLPに参加ください。