Databricksクイックスタートガイドのコンテンツです。
What is a Lakehouse? - The Databricks Blogの翻訳です。
3分間の紹介動画もご覧ください。
我々は、ここ数年で多くのお客様、ユースケースにおいて新たなデータマネジメントのアーキテクチャ:レイクハウスが生まれているのを目撃しています。この記事では、これまでのアプローチに対する優位性ともに新たをアーキテクチャを説明します。
データウェアハウスは意思決定サポートやBIアプリケーションにおいて長い歴史があります。1980年代後半の誕生から、データウェアハウス技術は進化を続けており、MPPアーキテクチャによって、大量データの取り扱いが可能なシステムとなっています。データウェアハウスは構造化データの取り扱いに長けていますが、多くの企業は現在、非構造化データ、準構造化データ、3V(variety、velocity、volume)の特性を持つデータを取り扱う必要性に迫られています。これらの多くのユースケースに、データウェアハウスは適していないことに加え、コストの面でも効率的とは言えません。
企業が異なる多くのデータソースから大量のデータを集め始めると、アーキテクトたちは、異なる多くの分析製品や、分析作業のために、データを格納する単一のシステムを思い描くようになりました。10年前頃から企業は、様々なフォーマットの生データを格納するデータレイクを構築し始めました。データレイクはデータの格納には長けていましたが、いくつかの重要な機能が欠けていました:トランザクション、データ品質の担保、一貫性、分離性の欠如は、バッチ処理、ストリーミング処理の統合、データ追加と読み取りの同時実行の実現を妨げていました。このため、データレイクに期待されていたことの多くは実現せず、多くの場合データウェアハウスのメリットすらも失うことになりました。
柔軟性があり、高性能なシステムへの欲求は止むことがありませんでした。多くの企業は、SQL分析、リアルタイムの監視、データサイエンス、機械学習など様々なデータアプリケーションのためのシステムを必要としました。近年のAIの進展は、主に非構造化データ(テキスト、画像、動画、音声)を処理するモデルにおけるものでした。しかし、これらはデータウェアハウスが不得意とするものでした。一般的なアプローチは複数のシステムを使うというものです。つまり、データレイクといくつかのデータウェアハウス、ストリーミング、時系列データ、グラフデータ、画像など向けのデータベースなどの特殊なシステムの組み合わせです。多数のシステムは、複雑性に加えて、異なるシステム間でのデータ移動・コピーに伴う処理の遅延をもたらしました。
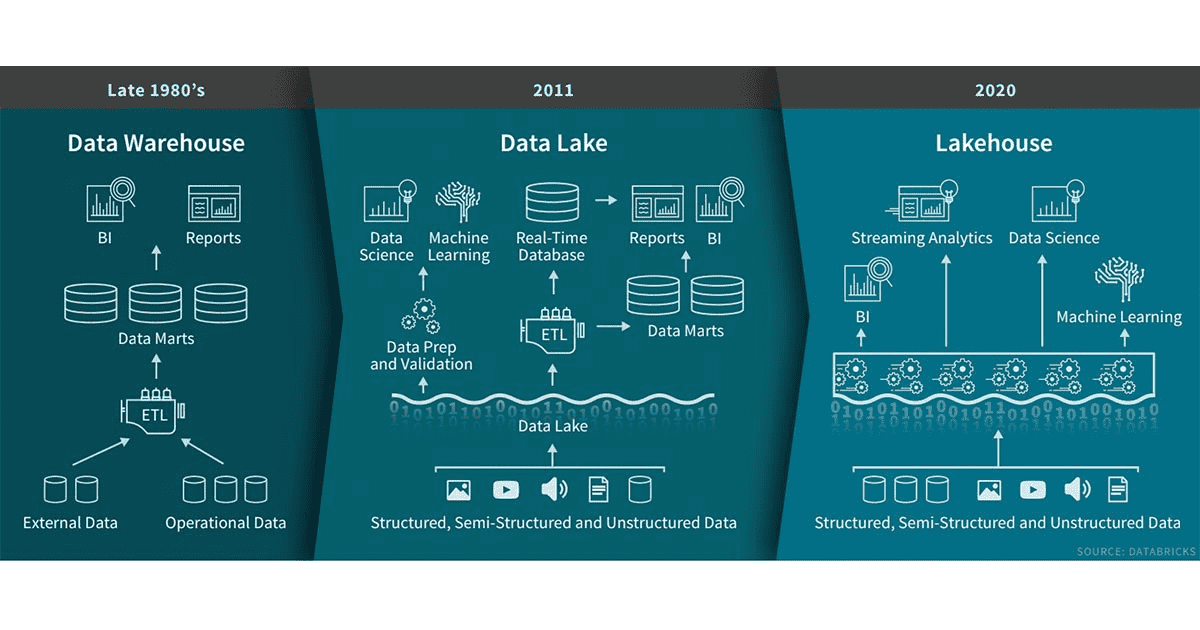
レイクハウスとは?
データレイクの制限を打破しようと、新たなシステムが出現しました。レイクハウスは、データレイクとデータウェアハウスの優れた部分を組み合わせた新しく、オープンなアーキテクチャです。レイクハウスは新たなオープンかつ標準化されたシステムによって実現されています:データウェアハウスと同様のデータ構造とデータマネジメント機構を備えており、データレイクのように安価なストレージに直接アクセスすることができます。今や安価で信頼性の高いオブジェクトストレージが存在しているので、あなたがもし近代的なデータウェアハウスを再設計しようとしたらこのようなものになるでしょう。
レイクハウスには以下の機能があります:
- トランザクションのサポート: 企業のレイクハウスにおいては、同時にデータの読み書きを行うデータパイプラインが存在するでしょう。ACIDトランザクションのサポートにより、特にSQLを用いたケースで、複数のデータの読み書きがあったとしても一貫性を維持できます。
- スキーマ適用及びガバナンス: スタースキーマ、スノーフレークスキーマのようにデータウェアハウスのスキーマアーキテクチャをサポートすることで、レイクハウスはスキーマの適用・進化をサポートすべきです。また、システムはデータの完全性を保証すべきであり、頑健性のあるガバナンス機能や監査機構が必要となります。
- BIのサポート: レイクハウスにおいては、ソースデータに直接アクセスしてBIを行うことができます。これにより、データの鮮度が保たれ、遅延が減ることに加え、データレイクとデータウェアハウスでデータの二重持ちする必要が無いため、コストを低減できます。
- 計算リソースとストレージの分離: これはストレージと計算リソースが異なるクラスターを用いることを意味します。すなわち、同時接続ユーザー数の増加やデータ量の増加に応じてシステムがスケールアウトできるということです。近代的なデータウェアハウスのいくつかはこの特性を有しています。
- オープン: 使用するストレージフォーマットは、Parquetのようにオープンかつ標準化されたものとなっています。また、機械学習、Python/Rライブラリのように多くのツールやエンジンに対するAPIを提供し、データに直接アクセスすることができます。
- 非構造化データから構造化データまで様々なデータタイプをサポート: レイクハウスは、画像、動画、音声、準構造化データ、テキストを含む新たなデータアプリケーションで必要となる様々なデータタイプの分析、精錬、格納に使うことができます。
- 様々なワークロードをサポート: データサイエンス、機械学習、SQLや分析に対応しています。これら全てのワークロードを実施するには複数のツールが必要になる場合がありますが、それらは全て同じデータリポジトリを使用します。
- エンドツーエンドのストリーミング: 今やリアルタイムのレポートは多くの企業で標準的なものになっています。ストリーミングのサポートにより、リアルタイムデータ処理専用のアプリケーションを別に持つ必要はありません。
これらがレイクハウスのキーとなる特徴です。企業レベルのシステムにおいては、さらに機能が必要となります。セキュリティ、アクセスコントロールは基本的な要件となります。昨今の個人情報に関する規制を受け、監査、保全、リネージュのようにデータガバナンスの機能も脚光を浴びています。データカタログのようにデータディスカバリーを実現するツールや、データ利用量に関するメトリクスも必要になります。レイクハウスでは、単一のシステムにおいて、これら企業が必要とする機能が実装、テスト、管理されます。
レイクハウスの内部動作に関する論文に関しては、こちらを参照ください。
初期段階における事例
Databricksプラットフォームはレイクハウスの機能を備えています。Azure Databricksと統合できるAzure Synapse Analyticsサービスもレイクハウスのパターンを有しています。BigQuery、Redshift Spectrumも上述のレイクハウスの一部の機能を有していますが、これらは主にBIやSQLのアプリケーションにフォーカスしています。オープンソースのファイルフォーマット(Delta Lake、Apache Iceberg、Apache Hudi)にアクセスする独自のシステムを必要とする企業は、レイクハウスを構築するのに適していると言えます。
データレイクとデータウェアハウスの単一システムへの統合は、複数のシステムにアクセスすることなしにデータを活用できるため、データチームがより迅速に行動できるようになることを意味します。レイクハウスの初期段階における、一定レベルのSQLサポートとBIツールとの統合は、一般的に多くのエンタープライズデータウェアハウスに対して十分と言えるものでした。マテリアライズドビューとストアドプロシージャは利用できましたが、ユーザーは従来のデータウェアハウスで利用できる他の機能を必要とするかもしれません。特に後者は、従来の商用データウェアハウスと同等のセマンティクスを実現するために、「リフトアンドシフトシナリオ」において重要です。
他のタイプのデータアプリケーションのサポートはどうでしょうか?レイクハウスのユーザーは、データサイエンスや機械学習などのBI以外の作業を行うために、様々な標準的ツール(Spark、Python、R、機械学習ライブラリ)にアクセスできます。データの探索とクレンジングは多くの分析、データサイエンスアプリケーションにおいては標準的なものです。Delta Lakeは、レイクハウスのデータを活用できるレベルまで品質を高められるように設計されています。
技術的な構成要素に関するメモです。分散ファイルシステムはストレージレイヤーに活用することはできますが、レイクハウスでは主にオブジェクトストレージが利用されます。オブジェクトストレージは、低コスト、高可用性であり、近代のデータウェアハウスにおける基本要件である大量の並列読み込みに優れています。
BIからAIへ
レイクハウスは、企業のデータインフラストラクチャを劇的に簡素化し、機械学習が全ての産業に改革をもたらしている時代において、イノベーションを加速します。これまでは、企業の意思決定、製品に活用されるデータの多くは、オペレーショナルシステムからの構造化データでした。一方、今日においては、多くの製品は、コンピュータビジョンやスピーチモデル、テキストマイニングと言った形でAIと連携しています。AIのためになぜデータレイクではなくレイクハウスを使うのでしょうか?レイクハウスは、非構造化データにおいても必要となる、データのバージョン管理、ガバナンス、セキュリテイやACID特性を提供するからです。
現在のレイクハウスはコストは削減できますが、性能に関しては長年の蓄積を持っている専用のシステム(データウェアハウスなど)に遅れをとっています。あるユーザーは、他の製品と比較した場合に、特定のツール(BIツール、IDE、ノートブックなど)を好みます。このため、レイクハウスにおいても、多くのペルソナに訴求するために、UXや人気ツールへのコネクターなどを改善する必要があります、これらの課題は、技術が進歩し、成熟、発展していく過程で解決されていきます。近いうちに、レイクハウスは、よりシンプルに、かつコスト効率を改善し、様々なデータアプリケーションに対応できるようになることに加え、これらのギャップを埋めることになるでしょう。
訳者追記
レイクハウスの概念を含め、Databricksの全体像を説明している書籍を発刊しました!