経済の未来は、社会的責任、環境への義務、企業の倫理と切っても切り離せない関係にあります。競争力を維持するために、金融サービス機関(FSI)は、積極的に自身の環境、社会、ガバナンス(ESG)に関するパフォーマンスの情報を公開しています。企業におけるあらゆる投資の社会的インパクト、持続性を理解し、定量化することで、FSIは風評リスクを軽減し、顧客、株主との信頼関係を維持することができます。Databricksにおいては、多くのお客様の経営層においてESGが優先事項になっていると聞いています。これは単に利他主義によるものではなく、経済的な動機によっても引き起こされているものです。ESGレーティングが高いほど、一般的には不安定性とは負の相関を維持しつつも、評価、利益とは正の相関があります。この記事では、キーとなる戦略的ESGイニシアチブを抽出し、グローバル市場における企業間の関係、マーケットリスクの計算に対するインパクトを理解するために、自然言語処理(NLP)技術とグラフ分析を組み合わせた、継続的な投資に対する新たなアプローチを提案します。
Databricksのレイクハウスプラットフォームを用いて、どのようにApache Spark、Delta Lake、MLflowが、アセットマネージャが投資の持続性を評価し、彼らの環境、社会、ガバナンス戦略に対する包括的かつデータドリブンのビューを用いて、自身のビジネスを強化できるのかをデモします。特に、年次レポート(PDF)からキーとなるESGの取り組みを抽出し、この抽出結果とニュースデータを分析することで得られる実際のメディアのカバレッジを比較します。
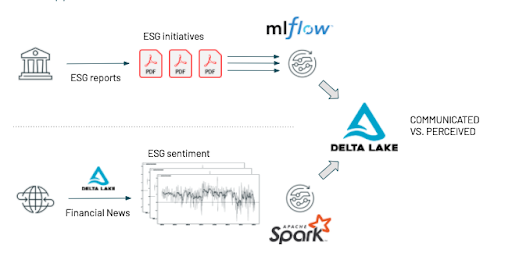
この記事の二つ目のパートでは、企業間のコネクションを学習し、ご自身のビジネスに対して、これらのコネクションがもたらすポジティブあるいはネガティブなインパクトをもたらすのかを理解します。この記事は、ESGと社会的責任を伴う投資に対するモダンなアプローチを説明するためにアセットマネージャにフォーカスしますが、このフレームワークは生活必需品、エネルギー、メディア、ヘルスケアなどあらゆる業界に容易に適用することができます。
キーとなるESG取り組みの抽出
金融サービス企業は、ESG戦略に関する情報をもっと公開しろという株主からのこれまで以上のプレッシャーにさらされています。多くの場合、複数のテーマにまたがるESGの取り組みを公開するために、年次ベースのPDFドキュメントのレポートという形でウェブサイトに公開されます。これには、自身の従業員、クライアント、顧客をどのように評価しているのか、どのように社会に還元しているのか、さらには二酸化炭素排出量を削減する(あるいは削減をコミット)ことで気候変化の影響を削減すると言ったものが含まれています。サードパーティのエージェンシー(msci、csrhubなど)によって、ESGメトリクスを作成するために、これらのレポートがまとめられ、業界横断でベンチマークが行われます。
ESGレポートからの文の抽出
この例では、トップレベルの金融サービス機関(いくつかを下の表に示しています)からの40以上のESGレポートをプログラムを用いてアクセスし、異なるトピックにまたがるキーのイニシアチブを学習したいと思います。しかし、標準的なスキーマや規制上のガイドラインなしには、これらのPDFドキュメントによるコミュニーケーションは変化するため、このアプローチは機械学習(ML)のユースケースにおいては完璧な候補となります。
ここでのデータセットは比較的小さいものですが、Spark環境で利用できるサードパーティライブラリのPyPDF2とユーザー定義関数(UDF)を用いて、どのようにスクレーピング処理を分散するのかをご説明します。
import requests
import PyPDF2
import io
@udf('string')
def extract_content(url):
# retrieve PDF binary stream
response = requests.get(url)
open_pdf_file = io.BytesIO(response.content)
pdf = PyPDF2.PdfFileReader(open_pdf_file)
# return concatenated content
text = [pdf.getPage(i).extractText() for i in range(0, pdf.getNumPages())]
return "\n".join(text)
正規表現とかなり複雑なデータクレンジング(添付ノートブックに記載されています)に加え、コンテンツからトークンを抽出し、文法上正しい文に変換するために先進的なNLP機能を活用したいと思います。トレーニングされたNLPパイプライン(以下のようなspacyライブラリ)をメモリーにロードするのにかかる時間を考慮して、以下のようなPandas UDF戦略を用いて、Sparkのエグゼキューターごとにモデルを一回のみロードするようにします。
import gensim
import spacy
from pyspark.sql.functions import pandas_udf, PandasUDFType
@pandas_udf('array', PandasUDFType.SCALAR_ITER)
def extract_statements(content_series_iter):
# load spacy model for english only once
spacy.cli.download("en_core_web_sm")
nlp = spacy.load("en_core_web_sm")
# provide process_text function with our loaded NLP model
# clean and tokenize a batch of PDF content
for content_series in content_series_iter:
yield content_series.map(lambda x: process_text(nlp, x))
このアプローチによって、40以上のESGレポートの生のPDFを適切に定義された文(いくつかを以下の表に示します)に変換することができます。このプロセスの一部として、過去形を現在形に、複数形を単数形にまとめるなど、コンテンツのlemmatise(派生形の除外)を行っています。モデリングのフェーズでトピックを学習する際の単語数を削減できるので、この追加プロセスを実行する価値はあります。
| 企業 | 文 |
|---|---|
| Goldman Sachs | we established a new policy to only take public those companies in the us and europe with at least one diverse board director (starting next year, we will increase our target to two) |
| Barclays | it is important to us that all of our stakeholders can clearly understand how we manage our business for good. |
| Morgan Stanley | in 2019, two of our financings helped create almost 80 affordable apartment units for low-and moderate-income families in sonoma county, at a time of extreme shortage. |
| Riverstone | in the last four years, the fund has conserved over 15,000 acres of bottomland hardwood forests, on track to meeting the 35,000-acre goal established at the start of the fund |
それぞれの文で述べられているテーマを人間の目で推定することは比較的容易(この場合はダイバーシティ、透明性、社会、環境)ですが、大規模データに対してプログラムで同様なことを行おうとする際は、別の複雑性が関係することになり、データサイエンスの高度な活用が求められます。
ESG文の分類
ここでは、40以上のESGレポートから抽出した8,000文のそれぞれを自動で分類したいと思います。Spark MLの分散バージョン、あるいは以下のようなインメモリsklearnを用いた、非行列因子分解とLatent Dirichlet Allocation(LDA)の組み合わせは、トピックモデリングにおける重要な武器となります。ここでは、単語の頻度を計算し、LDAモデルおよび、MLflowのトラッキング機能を用いてハイパーパラメーターをキャプチャします。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation as LDA
import mlflow
# compute word frequencies
# stop words are common english words + banking related buzzwords
word_tf_vectorizer = CountVectorizer(stop_words=stop_words, ngram_range=(1,1))
word_tf = word_tf_vectorizer.fit_transform(esg['lemma'])
# track experiment on ml-flow
with mlflow.start_run(run_name='topic_modeling'):
# Train a LDA model with 9 topics
lda = LDA(random_state = 42, n_components = 9, learning_decay = .3)
lda.fit(word_tf)
# Log model
mlflow.sklearn.log_model(lda, "model")
mlflow.log_param('n_components', '9')
mlflow.log_param('learning_decay', '.3')
mlflow.log_metric('perplexity', lda.perplexity(word_tf))
以下の複数の実験を通じて、コーパスを最も要約できる9つのトピックを発見しました。我々のモデルで学習したそれぞれのキーワードの重要度を深く見ていくことで、以下の表に示すように9つのトピックを9つの特定のカテゴリを説明してみようと思います。
| 名称 | LDAで特徴的なキーワード |
|---|---|
| 企業戦略 | board, company, corporate, governance, management, executive, director, shareholder, global, engagement, vote, term, responsibility, business, team |
| グリーンエネルギー | energy, emission, million, renewable, use, project, reduce, carbon, water, billion, power, green, total, gas, source |
| 顧客フォーカス | customer, provide, business, improve, financial, support, investment, service, year, sustainability, nancial, global, include, help, initiative |
| コミュニティのサポート | community, people, business, support, new, small, income, real, woman, launch, estate, access, customer, uk, include |
| 倫理的投資 | investment, climate, company, change, portfolio, risk, responsible, sector, transition, equity, investor, sustainable, business, opportunity, market |
| 持続的財政 | sustainable, impact, sustainability, asset, management, environmental, social, investing, company, billion, waste, client, datum, investment, provide |
| 行動規範 | include, policy, information, risk, review, management, investment, company, portfolio, process, environmental, governance, scope, conduct, datum |
| 強いガバナンス | risk, business, management, environmental, customer, manage, human, social, climate, approach, conduct, page, client, impact, strategic |
| 従業員を評価 | employee, work, people, support, value, client, company, help, include, provide, community, program, diverse, customer, service |
機械学習で得られた9つのトピックによって、それぞれのFSIのESGレポートを容易に比較でき、それぞれがフォーカスしている領域をより理解することができます。
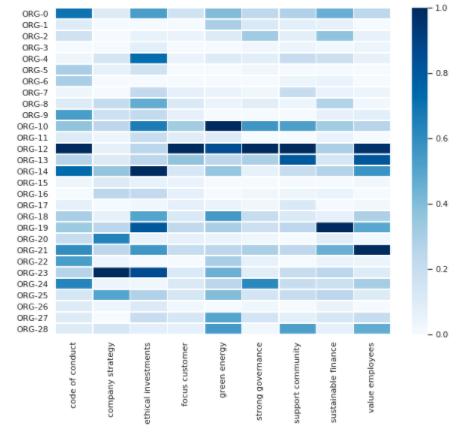
seabornで可視化することによって、容易に企業間の差異を把握することができます(企業名は匿名化しています)。いくつかの企業が「従業員を評価」、「ダイバーシティ、インクルージョン」にフォーカス(例:ORG-21)しているように見え、いくつかの企業は「倫理的投資」にフォーカス(ORG-14)しているようです。LDAのアウトプットは、特定のテーマではなく我々の9つのトピックに対する確率分布なので、シンプルなSQLとそれぞれのテーマで最も高い確率を捕捉するパーティション関数を用いることで、特定の企業における最も際立っているESGイニシアチブを容易に特定することができます。
WITH ranked (
SELECT
e.topic,
e.statement,
e.company,
dense_rank() OVER (
PARTITION BY e.company, e.topic ORDER BY e.probability DESC
) as rank
FROM esg_reports e
)
SELECT
t.topic,
t.statement
FROM ranked t
WHERE t.company = 'goldman sachs'
AND t.rank = 1
このSQLによって、NLPが70ページ以上のドキュメントを9つのESGイニシアチブ/アクションに要約することで生成したGoldman Sachs(オリジナルのレポート)に対するエグゼクティブサマリーを取得することができます。
| トピック | 文章 |
|---|---|
| コミュニティのサポート | Called the Women Entrepreneurs Opportunity Facility (WEOF), the program aims to address unmet financing needs of women-owned businesses in developing countries, recognizing the significant obstacles that women entrepreneurs face in accessing the capital needed to grow their businesses. |
| 強いガバナンス | The ERM framework employs a comprehensive, integrated approach to risk management, and it is designed to enable robust risk management processes through which we identify, assess, monitor and manage the risks we assume in conducting our business activities. |
| 持続的財政 | In addition to the Swedish primary facility, Northvolt also formed a joint venture with the Volkswagen Group to establish a 16 GWh battery cell gigafactory in Germany, which will bring Volkswagens total investment in Northvolt to around $1 billion. |
| グリーンエネルギー | Besides reducing JFKs greenhouse gas emissions by approximately 7,000 tons annually (equivalent to taking about 1,400 cars off the road), the project is expected to lower the Port Authority’s greenhouse gas emissions at the airport by around 10 percent The GSAM Renewable Power Group will hold the power purchase agreement for the project, while SunPower will develop and construct the infrastructure at JFK. |
| 顧客フォーカス | Program alumni can also join the 10KW Ambassadors Program, an advanced course launched in 2019 that enables the entrepreneurs to further scale their businesses.10,000 Women Measures Impacts in China In Beijing, 10,000 Women held a 10-year alumni summit at Tsinghua University School of Economics and Management. |
| 倫理的投資 | We were one of the first US companies to commit to the White House American Business Act on Climate Pledge in 2015; we signed an open letter alongside 29 other CEOs in 2017 to support the US staying in the Paris Agreement; and more recently, we were part of a group of 80+ CEOs and labour leaders reiterating our support that staying in the Paris Agreement will strengthen US competitiveness in global markets. |
| 従業員を評価 | Other key initiatives that enhance our diversity of perspectives include: Returnship Initiative, which helps professionals restart their careers after an extended absence from the workforce The strength of our culture, our ability to execute our strategy, and our relevance to clients all depend on a diverse workforce and an inclusive environment that encourages a wide range of perspectives. |
| 企業戦略 | Underscoring our conviction that diverse perspectives can have a strong impact on company performance, we have prioritized board diversity in our stewardship efforts. |
| 行動規範 | 13%Please see page 96 of our 2019 Form 10-K for further of approach to incorporation of environmental, social and governance (ESG) factors in credit analysisDiscussion and AnalysisFN-CB-410a.2Environmental Policy Framework |
いくつか誤った分類(主にトピックをどのように定義するのかに依存します)を観測し、さらにモデルをチューニングする必要があるかもしれませんが、複雑なPDFドキュメントから明確に定義されたイニシアチブを効率的に抽出するために、どのようにNLP技術を活用できるのかをデモしました。しかし、常に企業のコアとなる優先度を反映して、全てのテーマに対するすべてのイニシアチブをキャプチャするとは限りません。この場合、異常検知の考え方を拝借して、コーパスをクラスタリングし、標準から最も逸脱している文を抽出(企業固有の文章だがメインストリームではない)することで、この問題に対応することができます。この、K-Meansを用いたアプローチは添付のノートブックで議論されています。
データドリブンによるESGスコアの生成
前のセクションでカバーしたように、異なる9つのESGイニシアチブに基づいて、企業を横並びに比較することができました。ESGスコアを作り出すこと(多くのサードパーティが使用しています)にトライしてみますが、我々のスコアは主観的なものではなく完全にデータドリブンのものとなります。言い換えると、我々は単に企業の公式な公開情報を鵜呑みにせず、環境、ソーシャル、ガバナンスの観点での企業の評判はメディアでどのように受け止められているのかをベースにしたいと考えています。このために、イベントの場所とトーンのグローバルデータベースであるGDELTを活用します。
データの取得
GDELTで利用できるデータのボリューム(過去18ヶ月間の100万レコードのみ)の都合上、生データ(ブロンズ)からフィルタリングしたデータ(シルバー)、拡張されたデータ(ゴールド)から構成されるレイクハウスパラダイムを活用し、さらにこれをニアリアルタイムで処理(GDELTファイルは15分ごとに公開されます)できるように拡張します。このため、バッチモードでトリガーされる構造化ストリーミングアプローチを採用し、それぞれのバッチでは増分のみを処理するようにします。ストリーミングとバッチを統合することで、Sparkはモダンなデータレイクインフラストラチャにおけるデータ操作、ETLプロセスのデファクトとなっています。
gdelt_stream_df = spark \
.readStream \
.format("delta") \
.table("esg_gdelt_bronze") \
.withColumn("themes", filter_themes(F.col("themes"))) \
.withColumn("organisation", F.explode(F.col("organisations"))) \
.select(
F.col("publishDate"),
F.col("organisation"),
F.col("documentIdentifier").alias("url"),
F.col("themes"),
F.col("tone.tone")
)
gdelt_stream_df \
.writeStream \
.trigger(Trigger.Once) \
.option("checkpointLocation", "/tmp/gdelt_esg") \
.format("delta") \
.table("esg_gdelt_silver")
GDELTで利用できる様々なディメンジョンから、我々は経済ニュースに関係する記事のみを対象とした感情分析(トーン変数を活用)にフォーカスします。ここでは、ECON_で始まるというGDELTの命名規則に基づき、経済ニュースを適切に捕捉できると仮定します。さらに、全ての環境に関する記事はENV_、ソーシャルに関する記事はUNGP_*命名規則(国連の人権に関するガイドライン原則)に従うと仮定します。
ESGの代替としての感情分析
環境、ソーシャル、ガバナンスのメトリクスを定義するための業界の標準や既存モデル、あるいは我々の研究時点で利用できる正解ラベルない状況においては、経済ニュース記事から得られる全体的なトーンが企業のESGスコアの代替として活用できるとの前提を置きます。例えば、海岸の災害やオイル流出に関係する一連のプレス記事は、企業の環境面のパフォーマンスに強く影響するでしょう。逆に、発展途上国における女性によるビジネスへの経済的支援に関する好意的なニュース記事[ソース]は、企業のESGにポジティブな影響を与えることでしょう。我々のアプローチは、企業に対する感情と業界平均の差を見るというものです。金融サービスニュース全体で、どれだけ「ポジティブ」あるいは「ネガティブ」な企業として、受容されているのかの時系列変化を見ていきます。
以下の例では、我々の主要なFSIと業界平均との感情の差(15日間の移動平均)を示しています。COVID-19ウィルスの拡大があった2020/3前後のタイムウィンドウは別として、このFSIは、全体的に優れた環境をスコアを出しており、一貫して業界平均より優れたパフォーマンスを示しています。
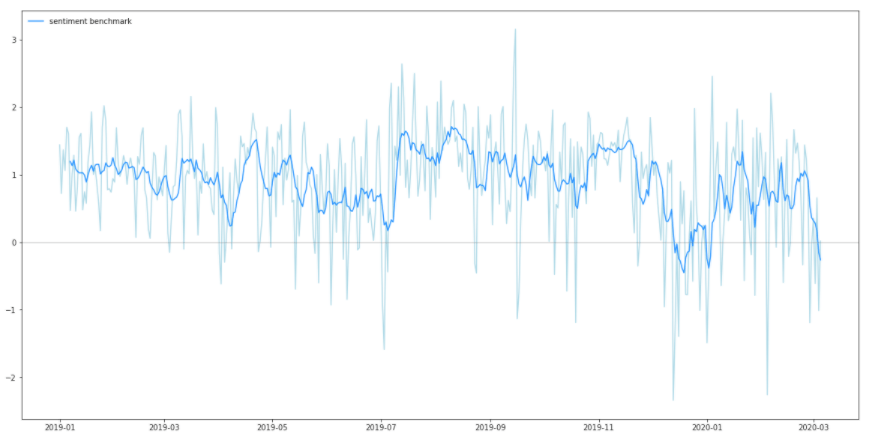
このアプローチをGDELTデータセットで言及されている全てのエンティティに一般化することで、正式なESGレポートを出しているわずかのFSIに限定されることなく、環境、ソーシャル、ガバナンスの次元であらゆる企業に対する内部的なスコアを作成することができます。言い換えれば、我々はESGのレンズを主観的なものからデータドリブンのものにシフトし始めたと言えます。
加重伝播ESGメトリクスのご紹介
グローバルマーケットにおいては、企業とビジネスは密接に絡まり合っており、そのうちの一つ(例:売り手)のESGパフォーマンスは他(例:買い手)の風評に影響を及ぼすかもしれません。例えば、あるファームが環境問題に直接的あるいは間接的に関係している企業に投資し続けた場合、リスクを定量化し、彼らの倫理的投資戦略の一部として企業のレポートに反映されるべきです。タールサンドプロジェクトに間接的に関わっていたことで、Barclaysの風評にインパクトがあった2018年後半の例を引用することができます[ソース]。
影響要因の特定
Googleによって民主化されたウェブのインデクシング、Page Rankは大規模ネットワークにおけるノードの影響力を特定するために使われる一般的なテクニックです。我々のアプローチでは、我々の主要なFSIに影響力がある組織を特定するために、Page Rankの派生形であるパーソナラナイズドPage Rankを使用します。これらのコネクションに影響力があるほど、その組織は我々のESGスコアに(ポジティブあるいはネガティブな)影響を与えることになります。タールサンド業界への間接的なコネクションは、パーソナライズされたページランクの影響力に応じて企業にネガティブな影響を与えるという、このアプローチのイラストを以下に示します。
Graphframesを用いることで、共通するメディアのカバレッジを共有する企業のネットワークを容易に作成することができます。ここでは、ニュース記事で一緒に言及される企業ほど、彼らのリンク(エッジの重み)は強くなるという仮定を置きます。この仮定では、ニュース記事でたまたま共起した場合に誤った推論を行う可能性はありますが、この非有向加重グラフは、我々が評価したいと考える主要なFSIに対する企業の重要度を発見する手助けをしてくれます。
val buildTuples = udf((organisations: Seq[String]) => {
// as undirected, we create both IN and OUT connections
organisations.flatMap(x1 => {
organisations.map(x2 => {
(x1, x2)
})
}).toSeq.filter({ case (x1, x2) =>
x1 != x2 // remove self edges
})
})
val edges = spark.read.table("esg_gdelt")
.groupBy("url")
.agg(collect_list(col("organisation")).as("organisations"))
.withColumn("tuples", buildTuples(col("organisations")))
.withColumn("tuple", explode(col("tuples")))
.withColumn("src", col("tuple._1"))
.withColumn("dst", col("tuple._2"))
.groupBy("src", "dst")
.count()
import org.graphframes.GraphFrame
val esgGraph = GraphFrame(nodes, edges)
このグラフをさらに調べることで、エッジの重みのべき乗分布を観測しました:コネクションのあるビジネスの90%は非常に少ないコネクションを共有していました。エッジの重みを200以上(実験を通じて得られた閾値)に限定することで、グラフのサイズを51,679,930から61,143コネクションに劇的に削減することができました。Page Rankを実行する間に、我々は最短パスアルゴリズムを用いてコネクション数を削減することで最適化を行い、(landmarks配列としてキャプチャされる)我々の主要FSIのノードに到達するまでに必要な最大ホップ数を計算しました。グラフの深さは、すべての最短パスの最大値、あるいはランダムなノードが他のノードに到達するために必要なコネクション数(深さが小さいほどネットワークの密度は高くなります)となります。
val shortestPaths = esgGraph.shortestPaths.landmarks(landmarks).run()
val filterDepth = udf((distances: Map[String, Int]) => {
distances.values.exists(_ < 5)
})
最大の深さが4でグラフをフィルタリングしました。このプロセスによって、さらにグラフのサイズを2,300ビジネス、54,000コネクションにまで削減し、業界の影響度をよりキャプチャできるように、多くのイテレーションを通じてPage Rankアルゴリズムを実行できるようにしました。
val prNodes = esgDenseGraph
.parallelPersonalizedPageRank
.maxIter(100)
.sourceIds(landmarks)
.run()
ここでは、特定のビジネス(この場合はBarclays PLC)に対して影響力のあるトップ100のノードを以下のように直接可視化することができます。驚くことではありませんが、Barclaysは我々の主要FSI(JP Morgan Chase、Goldman Sachs、Credit Suisse)とコネクションがあることがわかりますが、さらにはSEC(Security Exchange Commission)、Federal Reserve、国際通貨基金ともコネクションがあります。
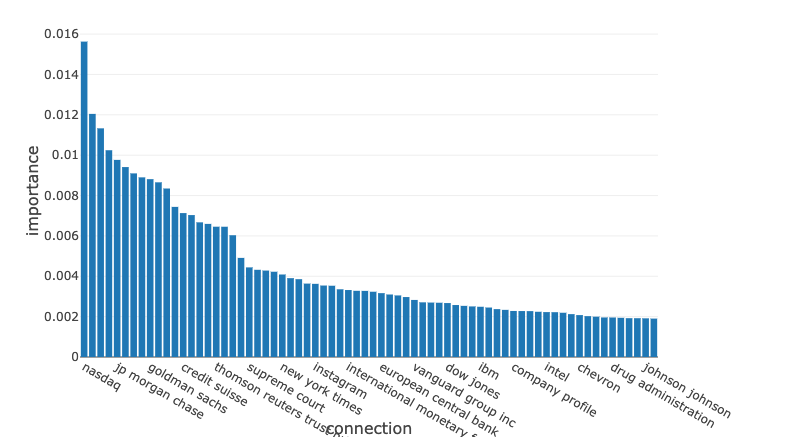
この分布をさらに調べることで、Chevron、Starbucks、Johnson and Johnsonのようなパブリック、プライベートカンパニーともつながりがあることがわかりました。強い、弱い、直接的、間接的なコネクションであっても、これら全てのビジネスは理論上BarclaysのESGパフォーマンス、すなわち、Barclaysの評判に対して、ポジティブ、あるいはネガティブな影響を与える可能性があります。
伝播メトリクスとしてのESG
先ほどキャプチャしたESGスコアと、これらのエンティティの重要度を組み合わせることで、相対的な重要度に基づきBarclaysのESGスコアに影響を及ぼす「Barclaysネットワーク」に対して、容易に加重平均を適用することができます。我々はこのアプローチを加重伝播ESGスコア(PW-ESG)と呼びます。
ワードクラウドによる可視化によって、企業ネットワークに対するネガティブ、ポジティブな影響度を観測します。以下の図においては、特定の企業(名前は伏せます)に対するネガティブな影響度(ESGにネガティブな影響を与えるエンティティ)を可視化しました。

ニュース記事の性質上、ニュース発行会社(Thomson Reuters、Bloomberg)、ソーシャルネットワーク(Facebook、Twitter)に強い関係性があることは驚くべきことではありません。特定のビジネスに対する真のコネクションを反映せず、ニュース記事におけるシンプルな共起に基づくものであるため、Page Rankプロセスの前にコネクションの度合いが高いノードを除外することで除外することを検討すべきです。しかし、この追加のノイズは我々のFSI全体で一貫性があるものであり、このため、ある企業特定の欠点には見えません。あるいは、生のテキストに対して高度なNLPを適用することで得られる、確立されたコネクションを用いてグラフを構築するというアプローチも考えられます。しかし、これは新たなスクレーピングプロセスを必要とし、このプロジェクトの複雑性とコストを増加させることになるでしょう。
最後に、前のセクションで計算したオリジナルのESGスコア、そして、それと比較して、PW-ESGアプローチを用いて計算した環境、ソーシャル、ガバナンスのスコアがどれだけ減少(増加)したのかを示します。以下の例では、特定の企業においては、初期スコアは69、62、67でしたが、57、53、60に減少し、もっとも減少幅が大きかったのは環境のカバレッジ(-20%)でした。
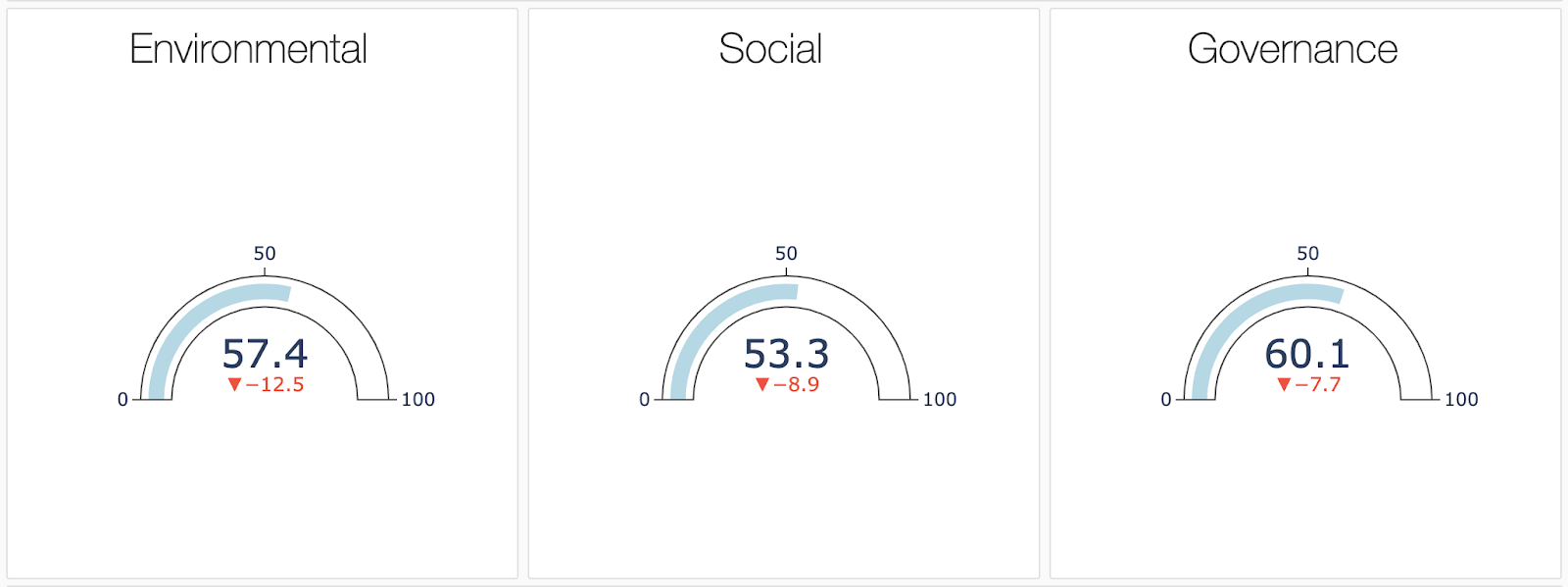
Databricksランタイムの効率性と組み合わされたRedash(現Databricks SQL)の機能を活用することで、この一連の洞察を迅速にBI/MIレポートとしてまとめることができ、みなさまの企業のアセットマネージャが持続的かつ責任を持ってより良い投資ができるように、ESG as-a-serviceを提供することができます。
この新しいフレームワークは、複数のユースケースに合わせられるように一般化されています。主要FSIは、風評リスクをより良く評価するために彼ら自身の企業がPage Rankのランドマークと考えるかもしれませんが、アセットマネージャはそれぞれの投資判断の持続可能性を評価するために、彼らをランドマークとして位置付けるかもしれません。
マーケットリスクへのESGの適用
高いESGスコアは一般的に企業評価額と利益に正の相関を示し、不安定性に対しては負の相関を示すという初期仮説を検証するために、我々のPW-ESGフレームワークを実行するためのランダムな金融資産から構成される合成ポートフォリオを作成し、Yahooファイナンスから得られる実際の株価情報と結合しました。以下のグラフで示されているように、科学的な結論を導き出すためにはデータが明らかに不足しているものの、我々のESGスコアの最大値と最小値を示した企業(上のグラフにはESGの代替として感情分析結果を示しています)は、過去18ヶ月において、それぞれ最高、最低の利益を示しています。
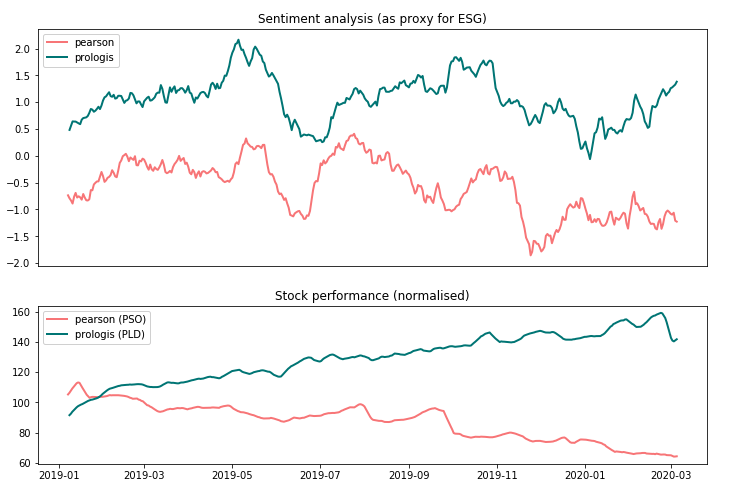
興味深いことに、CSRHubは全く逆のことを報告しており、ESGスコアにおいてはPearson(メディア)はPrologis(資産リース)より10ポイント高く、ESGスコアの主観性を強調しており、どのように発表されたのかと、実際にどのように観測されたのかにおける一貫性の欠如を示しています。
リスク管理の近代化に関する我々のブログ記事にならい、より良いリスク計算を行うために利用できる新たな情報を活用することもできます。我々のポートフォリオを、ESGスコアのトップ、ワースト10%それぞれから構成される二つの異なるブロックに分割することで、以下のようなグラフで過去のリターンと対応する95%リスク値を示します(historical VaR)。
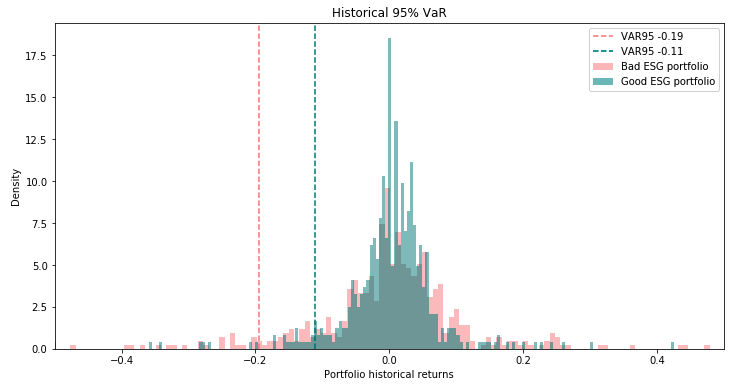
我々のフレームワークを用いて抽出したメトリクス以外に、企業に対する事前知識なしで、ESGのパフォーマンスが低い企業で構成されるポートフォリオにおいては、2倍のリスクがあることを観測しました。このことは初期仮説をサポートしています。
以前の記事でカバーした通り、リスク管理の未来は迅速性とインタラクティブ性にかかっています。リスクアナリストは、自身のビジネスが直面しているリスクを特定、定量化できる新たな方法を見つけ出すために、従来のデータを別のデータ、別の洞察で拡張すべきです。クラウドの柔軟性とスケーラビリティ、Databricksランタイムを通じて実現されるデータに対するインタラクティブ性によって、異なる業界、国、セグメント、そして新たにESGのレーティングに応じたマーケットリスクの計算を通じて、リスクアナリストはビジネスが直面しているリスクをより良く理解できるようになります。このデータドリブンのESGフレームワークによって、ビジネスは新たな質問を行えるようになります:会社の環境スコアを10ポイント上げれば、リスクをどのくらい減らせるのか?低いPW-ESGスコアを示している企業に投資することでどれだけのリスクに晒されるのか?
ESG戦略の変換
この記事では、それぞれの投資を持続性の観点でより理解できるように、どのように複雑なドキュメントをキーとなるESG取り組みに要約するのかをデモしました。グラフ分析を用いて、企業戦略と風評リスクの両方における、グローバルマーケットへの影響を特定するための新たなESGアプローチを紹介しました。最後に、マーケットリスク計算におけるESG要因の経済的インパクトを説明しました。データドリブンESGジャーニーのスタート地点として、より持続性のある財務、利益のある投資を実現し続けるために、様々な投資に関する内部データ、サードパーティデータから得られる追加のメトリクスを取り込み、リスクをPW-ESGフレームワークに伝播させることでこのアプローチをさらに改善することができます。
ESG戦略を加速するために、以下のノートブックをDatabricksで試してみてください。また、同様のユースケースにおいてサポートが必要な場合には、是非お問い合わせください。
- Using NLP to extract key ESG initiatives from PDF reports
- Introducing a novel approach to ESG scoring using graph analytics
- Applying ESG framework to market risk calculations