以前からSpark NLPの存在は知っていたのですが、恥ずかしながら日本語に対応していることを最近まで知りませんでした。
なので、早速日本語を対象にDatabricks上でSpark NLPを使ってみました。
Spark NLPとは
John Snow Labsが開発したSpark上での動作を前提とした、NLP(自然言語処理)ライブラリです。Spark MLを拡張する形で実装されているので、パイプラインの概念を使ってNLPパイプラインを容易に構築でき、さらにSparkの並列分散処理のメリットを享受することができます。Spark NLPの成り立ち、特徴については以下の記事をご覧ください。
インストール
クラスターライブラリでもノートブックスコープライブラリでも構わないので、ライブラリをインストールします。以下の例ではノートブックスコープライブラリとしてインストールしています。
# Install PySpark and Spark NLP
%pip install -q pyspark==3.1.2 spark-nlp
# Install Spark NLP Display lib
%pip install --upgrade -q spark-nlp-display
import sparknlp
from pyspark.ml import Pipeline
from sparknlp.annotator import *
from sparknlp.base import *
from sparknlp.training import *
分かち書き
Spark NLPにおいては、トークナイズ、ストップワード除去などの処理を組み合わせてパイプラインを構築します。
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence_detector = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
word_segmenter = WordSegmenterModel.pretrained("wordseg_gsd_ud", "ja").setInputCols(["sentence"]).setOutputCol("token")
pipeline = Pipeline(stages=[document_assembler, sentence_detector, word_segmenter])
ws_model = pipeline.fit(spark.createDataFrame([[""]]).toDF("text"))
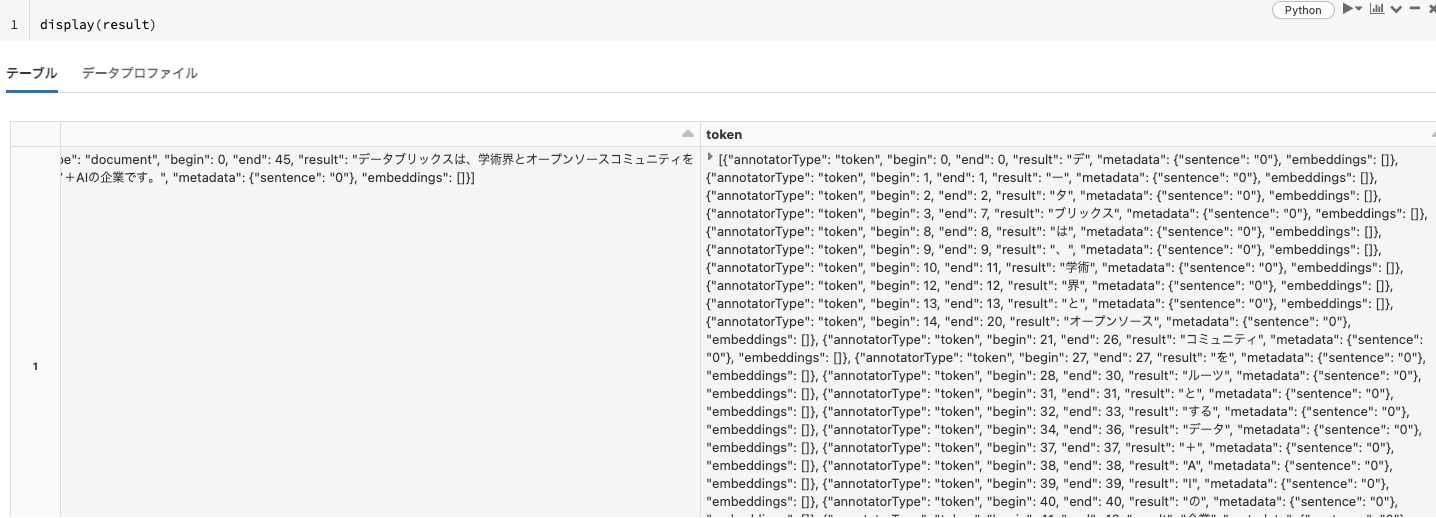
example = spark.createDataFrame([['データブリックスは、学術界とオープンソースコミュニティをルーツとするデータ+AIの企業です。']], ["text"])
result = ws_model.transform(example)
display(result)
以下のように文が分割されていますが、結果がわかりにくいのでひと手間加えます。
結果を一時テーブルに格納します。
result.createOrReplaceTempView("word_segmentation_result")
こうすることで、SQLクエリーを簡単に実行できるようになります。上の結果は配列、ネストされているので、以下のようなクエリーを発行して一部のみを抽出します。
%sql
SELECT token.result FROM word_segmentation_result;
先ほどより結果がわかりやすくなりました。

品詞抽出
名詞、動詞などの品詞を特定することもできます。以下ではパイプラインにpos_taggerを追加しています。
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence_detector = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
word_segmenter = WordSegmenterModel.pretrained("wordseg_gsd_ud", "ja")\
.setInputCols(["sentence"])\
.setOutputCol("token")
pos_tagger = PerceptronModel.pretrained("pos_ud_gsd", "ja") \
.setInputCols(["document", "token"]) \
.setOutputCol("pos")
pipeline = Pipeline(stages=[
document_assembler,
sentence_detector,
word_segmenter,
pos_tagger
])
example = spark.createDataFrame([['データブリックスは、学術界とオープンソースコミュニティをルーツとするデータ+AIの企業です。']], ["text"])
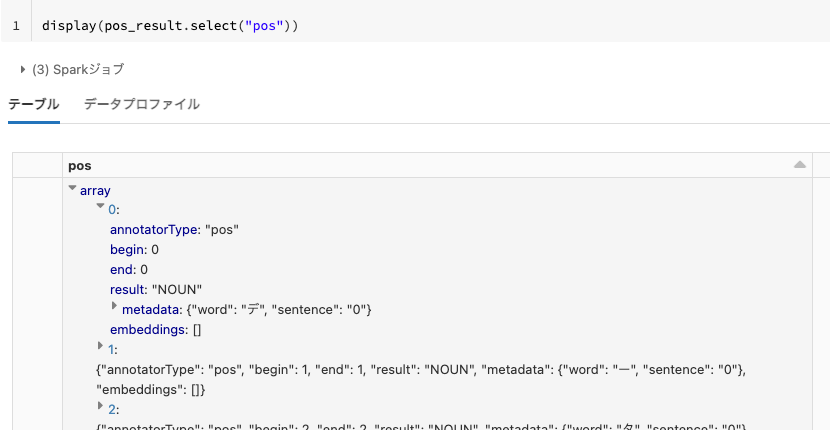
pos_result = pipeline.fit(example).transform(example)
NOUN(名詞)などの品詞が抽出されていますが、こちらも結果がわかりにくいものになっていますので、上と同じアプローチを取ります。
pos_result.createOrReplaceTempView("pos_result")
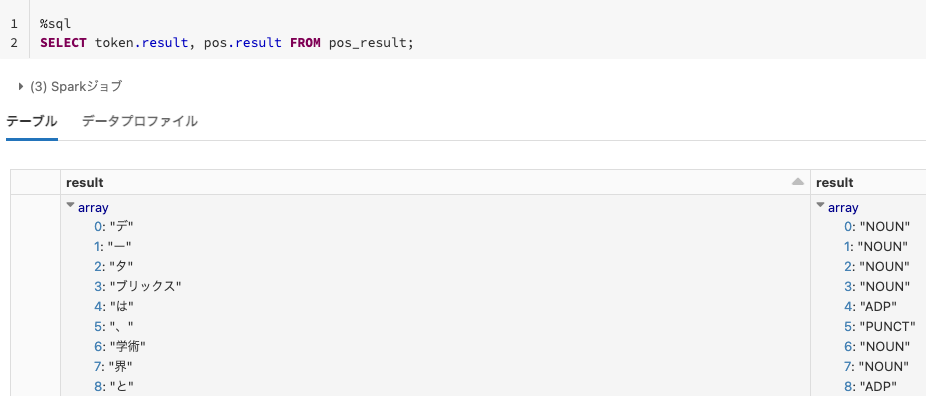
%sql
SELECT token.result, pos.result FROM pos_result;
以下のように品詞が抽出されていることがわかります。
NER(Named Entity Recognition)
日本語に対する固有表現抽出(固有名詞や数値の抽出)も可能です。
documentAssembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
sentence = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")
word_segmenter = WordSegmenterModel.pretrained("wordseg_gsd_ud", "ja") \
.setInputCols(["sentence"]) \
.setOutputCol("token")
embeddings = WordEmbeddingsModel.pretrained("japanese_cc_300d", "ja") \
.setInputCols(["sentence", "token"]) \
.setOutputCol("embeddings")
nerTagger = NerDLModel.pretrained("ner_ud_gsd_cc_300d", "ja") \
.setInputCols(["sentence", "token", "embeddings"]) \
.setOutputCol("ner")
ner_converter = NerConverter() \
.setInputCols(['sentence', 'token', 'ner']) \
.setOutputCol('ner_chunk')
pipeline = Pipeline().setStages([
documentAssembler,
sentence,
word_segmenter,
embeddings,
nerTagger,
ner_converter
])
抽出した結果を可視化する関数を準備します。
from sparknlp_display import NerVisualizer
def display_ner(text):
example = spark.createDataFrame([[text]], ["text"])
result = pipeline.fit(example).transform(example)
ner_vis = NerVisualizer().display(
result = result.collect()[0],
label_col = 'ner_chunk',
document_col = 'document',
return_html=True
)
displayHTML(ner_vis)
徳川家康 - Wikipediaの文を入力してみます。
display_ner("徳川 家康(とくがわ いえやす、旧字体:德川 家康、1542年 - 1616年)は、戦国時代から江戸時代初期の日本の武将、戦国大名。松平広忠の長子。江戸幕府初代将軍。安祥松平家第9代当主で徳川家の始祖。幼名は竹千代(たけちよ)、諱は元信(もとのぶ)、元康(もとやす)、家康と改称。")
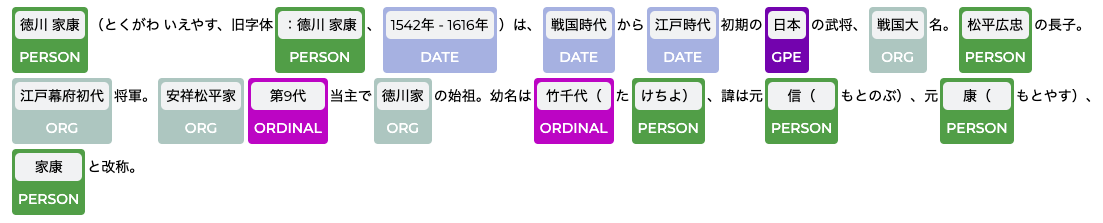
表示結果のラベルが途切れているのはご愛嬌ということで。データ自体はきちんと抽出されています。Githubにissueとして報告しておきました。
上記は私の認識違いで、NerConverterに対応しているNERモデルを使う必要がありました。
これらのSpark NLPの機能は全て無料で利用できます。大量テキストデータに対する処理を高速化するためにSpark NLPを活用してみてはどうでしょうか。
サンプルノートブック