本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
注意
2017年の記事です。
これは、オープンソースのApache Spark Natural Language Processing (NLP)ライブラリへの貢献を説明するコミュニティによるブログ記事であり、John Snow Labsのエンジニアリングチームの力によって作成されたものです。このブログ記事では、このライブラリの3つのトップレベルの技術的要件と検討を詳細に説明します。
Apache Sparkは、分散SQL、ストリーミング、グラフ処理、機械学習をネイティブでサポートする汎用クラスターコンピューティングフレームワークです。今では、Sparkのエコシステムには、Spark Natural Language Processing libraryも含まれています。
GitHubから取得できます。
John Snow Labs NLP LibraryはApache 2.0ライセンスで提供され、他のNLP、MLライブラリに依存せず、Scalaで記述されています。これはネイティブでSpark ML Pipeline APIを拡張しています。このフレームワークは、アノテーターのコンセプトを提供しており、以下の機能をすぐに利用することができます。
- Tokenizer
- Normalizer
- Stemmer
- Lemmatizer
- Entity Extractor
- Date Extractor
- Part of Speech Tagger
- Named Entity Recognition
- Sentence boundary detection
- Sentiment analysis
- Spell checker
さらに、Spark MLと密にインテグレーションすることで、ご自身のNLPパイプラインを構築する際に多くのことをすぐに実現することができます。これには、単語エンべディング、トピックモデリング、ストップワード除去、数多くの特徴量エンジニアリングの機能(tf-idf、n-gram、類似性メトリクスなど)、機械学習ワークフローにおける特徴量としてNLPアノテーションの使用が含まれます。これらの単語に馴染みがないのであれば、guide to understanding NLP tasksが良いスタート地点となることでしょう。

我々のバーチャルチームは数年に渡って、自然言語の理解に非常に重きを置く商法ソフトウェアを開発してきました。このため、我々はspaCy、CoreNLP、OpenNLP、Mallet、GATE、Weka、UIMA、nltk、gensim、Negex、word2vec、GloVeなどに対する実践の経験を持っています。我々はこれらに対する熱心なファンであり、これらのライブラリがこれらのライブラリを模範とするようなケースは非常に多くありました。しかし、現実世界のプロダクションとしての利用において、スケーラブル、高性能、高精度のソフトウェアを提供しようとした際、これらの制限に対して頭を悩ませるケースがあったのも事実です。
この記事では、John Snow Labs NLPライブラリの利点と、皆様ご自身のプロジェクトでの利用を検討すべきユースケースを説明します。
パフォーマンス
我々が取り組んだ3つのトップレベルの要件の1つ目は、実行時の性能です。もしかしたら、あなたはspaCyと熟考され職人技的に実装されたトレードオフをよく反映した公式のベンチマークの出現によって、問題の大部分は解決されたと考えているかもしれません。しかし、その上にSparkアプリケーションを構築しようとすると、依然として合理的はない標準以下のスループットに直面することになります。
なぜかを理解するために、NLPのパイプラインは常に、より大規模なデータ処理パイプラインの一部であることを考えます。例えば、質問回答には、ロード、トレーニング、データ、変換、NLPアノテーターの適用、特徴量の構築、値抽出モデルのトレーニング、結果の評価、ハイパーパラメーターの推定が含まれます。
NLPフレームワークからデータ処理フレームワーク(Spark)を分離することは、あなたの処理時間の多くがシリアライズと文字列のコピーに費やされることを意味します。
多大なる並列性は、Sparkデータフレームに対してTensorFlowワークフローを実行することで劇的に性能を改善するTensorFramesによってもたらされます。以下の画像はTim Hunter’s excellent TensorFrames overviewによるものです。

SparkとTensorFlowの両方はパフォーマンスとスケールを最大化するために最適化されています。しかし、データフレームはJVM内に存在し、TensorFlowはPythonプロセスで実行されるため、これら2つのフレームワーク間のインテグレーションでは、全てのオブジェクトはシリアライズされる必要があり、お互いにプロセス間コミュニケーションを通じてやりとりしなくてはなりません(!)し、少なくとも2回メモリーにコピーされなくてはなりません。TensorFramesの公開ベンチマークでは、データをJVMプロセスにコピーするだけで4倍の速度改善(GPUを使用した際にはさらに改善)をレポートしています。
SparkでspaCyを使用している際に同様の問題に直面します。Sparkはデータのロードと変換に最適化されていますが、NLPパイプラインの実行には、全てのデータをTungsten最適化フォーマットの外にコピーし、シリアライズし、Pythonプロセスにプッシュし、NLPパイプラインを実行し(これは非常に高速です)、結果を再度シリアライズし、JVMプロセスに戻さなくてはなりません。これは当然ながら、Sparkのキャッシングや実行プランナーによるパフォーマンスのメリットを相殺し、少なくとも2倍のメモリーを必要とし、スケーリングによる改善ができません。CoreNLPを使うことで、別のプロセスへコピーする必要はなくなりますが、依然としてデータフレームから全てのテキストをコピーし、結果を戻す必要があります。
このため、我々の最初のビジネスオーダーは、すでにSpark MLが行っているように、最適化されたデータフレーム上で直接分析を実行することでした(クレジット:ML Pipelines introduction post by Databricks)。
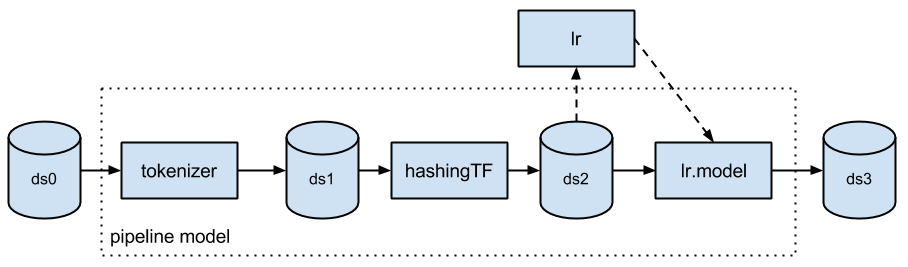
エコシステム
我々の2つ目の要件は、既存のSparkライブラリを摩擦なしに再利用できるようにすることでした。このパートは我々のお気に入りです。なぜ、世の中のNLPライブラリは、自身でトピックモデリングと単語エンべディング実装を構築しなくてはいけないのでしょうか?別のパートは実利的なものです。我々はタイトな締め切りに追われている小規模なチームであり、既に存在しているものを活用して物事を達成する必要がありました。
Spark NLPライブラリを考え始めた際に、我々は最初にDatabricksで誰が既に構築しているのかを尋ねました。回答は誰もやっていないということでしたので、次のお願いはライブラリの設計とAPIが完全にSpark ML APIのガイドラインに完全に準拠できるように支援してもらえないかということでした。このコラボレーションの結果は、例えば以下のようなパイプラインを構築できるSpark MLのシームレスな拡張となりました。
val pipeline = new mllib.Pipeline().setStages(Array(
docAssembler,
tokenizer,
stemmer,
stopWordRemover,
hasher,
idf,
dtree,
labelDeIndex))
このコードでは、document assembler、tokenizer、stemmerはSpark NLPライブラリcom.jsl.nlp.*パッケージから提供されます。TF hasher、IDF、labelDeIndexは全てMLlibのorg.apache.spark.ml.feature.*パッケージから提供されます。dtreeステージはspark.ml.classification.DecisionTreeClassifierです。一つのパイプラインで実行されるこれら全てのステージは、全く同じ方法で設定可能、シリアライズ可能、テスト可能です。また、これらは(spark-corenlpとは異なり)データのコピーなしにデータフレームに対して実行することができ、Spark特有のインメモリー最適化、並列性、分散スケールアウトのメリットを享受することができます。
これが意味することは、John Snow Labs NLPライブラリは完全に分散化され、強力にテストされ、最適化されたトピックモデリング、単語エンべディング、n-gram生成、コサイン類似度をすぐに利用できるということです。これらを開発する必要はなく、Sparkとともに提供されます。
さらに重要なこととして、お使いのNLPとMLパイプラインが統合されることを意味します。上記のコードサンプルは、単なるNLPパイプラインではなく、決定木のトレーニング使われる特徴量を生成するためにNLPが使用されるという意味で典型的なものです。これは質問回答タスクでは典型的なものです。より複雑なサンプルでは、名前付きエンティティ識別、POSタグによるフィルタリング、会話の解決、ランダムフォレストのトレーニングを適用し、NLPベースの特徴量と別のソースからの構造化された特徴量の両方を考慮し、ハイパーパラメーターチューニングのためにグリッドサーチを実行するというものがあります。統合されたAPIを使用できるようになることで、パフォーマンスや再利用のメリットに加え、このようなパイプラインのテスト、再現、シリアライズ、公開を行う必要がある際に助けとなります。
エンタープライズグレード
我々の3つ目の要件は、ミッションクリティカル、エンタープライズグレードのNLPライブラリをデリバリーすることです。我々は、プロダクションのソフトウェアを開発をすることで生計を立てています。現在人気のNLPパッケージのほとんどは、アカデミックを起源としており、性能よりもプロトタイピングの容易性、シンプルかつ最小限のAPIよりも幅広のオプション、スケーラビリティ、エラーハンドリング、消費メモリーの節約、コードの再利用の過少評価といった設計上のトレードオフが認められます。
John Snow LabsのNLPライブラリはScalaで記述されています。Sparkで使用するためにScalaとPythonのAPIが提供されています。他のNLPやMLライブラリに依存しません。いかなるタイプのアノテーターに対して、最先端のものを見つけ出すために論文調査を行い、どのアルゴリズムを実装すべきかに関して議論しました。実装は3つの評価指標に基づいて評価されました。
- 精度 – 標準以下のアルゴリズムやモデルであったら優れたフレームワークとは言えません。
- 性能 – 実行性能はいかなる公開ベンチマークと同等以上であるべきです。ストリーミングユースケースを取り扱うのに十分な性能でアノテーターが動作しない、あるいはクラスターの設定でうまくスケールしないがために精度を諦めるべきはありません。
- トレーニング可能性、設定可能性 – NLPは本来ドメイン固有の問題です。ソーシャルメディアの投稿、決算資料、電子医療記録、ニュース記事では異なる文法、語彙が使用されます。
このライブラリは既にエンタープライズのプロジェクトで使用されており、これは、最初のレベルのバグ、リファクタリング、予期しないボトルネック、シリアライゼーションの問題が解決されていることを意味します。ユニットテストのカバレッジとリファレンスドキュメントは、このコードをオープンソースにするのに十分なレベルとなっています。
John Snow Labsは、Spark NLPライブラリの開発、スポンサー、推進を行なっている企業です。この企業は商用サポート、補償、コンサルティングを提供しています。彼らは、長期利用時のファイナンシャル支援、ファンドされたアクティブな開発チーム、堅牢性とロードマップの優先づけを行うリアルワールドのプロジェクトの成長の流れを生み出しています。
使ってみる
あなたのプロジェクトでNLPが必要なのであれば、John Snow Labs NLP for Apache Spark homepageかクイックスタートガイドを参照し、トライしてみてください。ビルド済みのmaven(Scala)、pip(Python)も利用可能です。質問やフィードバックはnlp@johnsnowlabs.com、あるいは、Twitter、LinkedIn、GitHub経由でお願いします。
次に必要とする機能を教えてください。我々がいただいているリクエストを以下に示します。更なるフィードバックをお待ちしています。
- SparkRクライアントの提供
- 「Sparkフリー」なJava、Scalaバージョンの提供
- coreference resolutionに対する最先端技術の追加
- polarity detectionに対する最先端技術の追加
- temporal reasoningに対する最先端技術の追加
- 質問回答、テキスト要約、情報収集などの一般的なユースケース向けのサンプルアプリケーションの公開
- 新たなドメイン、言語に対するモデルのトレーニング、公開
- 再現可能かつレビュー済みの精度、性能ベンチマークの公開
ライブラリに貢献したいのであれば、John Snow Labs NLP for Spark GitHubをクローンするところからスタートしてください。コードの変更、バグ、機能の管理はプルリクエストとGitHubのイシューを使用しています。このライブラリはまだ出来上がったばかりであり、あらゆる貢献、フィードバックは大歓迎です。
謝辞
原文を参照ください。