Extracting Oncology Insights from Real-World Clinical Data with NLP - The Databricks Blogの翻訳です。
半構造化、非構造化データ:オンコロジー(腫瘍学)のエビデンスの生成における課題
このブログで参照しているソリューションアクセラレータのノートブックをオンラインで確認するか、ノートブックをダウンロードしてお使いのDatabricksアカウントにインポートして試してみてください。
アメリカにおいて癌は主要な死因、病因となっており、驚くべきことに今年においても200万もの新たな癌のケースが診断されています。また、癌はアメリカにおける診療費の大部分を占めており、2020年で2000億ドル以上と推定されています。このため、バイオ医薬品業界は、抗癌剤の開発に特にフォーカスしています。2019年、2020年のみでもFDAによっておよそ40の新たな抗癌剤が承認されており、1,300以上の新薬、ワクチンが臨床開発段階にあります。
患者にとって適切な介入方法を選択するためには、オンコロジーの介入の効果を計測することが重要となります。オンコロジーデータ、関係するリアルワールドのエビデンスは、臨床研究、臨床試験のデザイン、規制上の意思決定、安全性の評価、治療計画などに情報を提供するポテンシャルを持っています。残念ながら、オンコロジー治療の特殊性から、病気の評価指標やエンドポイントは多くのケースで構造化されたフォーマットでは利用できず、データサイロに閉じ込められたままとなっており、集約や分析を困難なものにしています。
オンコロジーにおいては、病理学のレポート(多くの場合PDFフォーマットであり、EMRシステムのサイロに格納されています)には、腫瘍のサイズ、グレード、ステージ、組織構造などの重要な情報が含まれています。自然言語処理(NLP)システムによって抽出された変数は、病気のグループを定義し、病気の深刻度を評価し、病状進行のベースラインを作成するために活用することができ、前述した臨床試験のマッチングから治療計画に至るユースケースに適用することができます。しかし、構造化されていない診療テキストデータからの情報の抽出が、データチームにとって非常に大きなペインポイントとなるケースが多くあります。
ヘルスケアNLPのリーダーであるJohn Snow LabsとDatabricksは、この問題に正面から取り組み、構造化されていないオンコロジーのデータをアクション可能なエビデンスに変換するために、ヘルスケアエコシステムにおける多くのお客様とともに協働しています。
DatabricksとJohn Snow Labsによる大規模医療自然言語処理
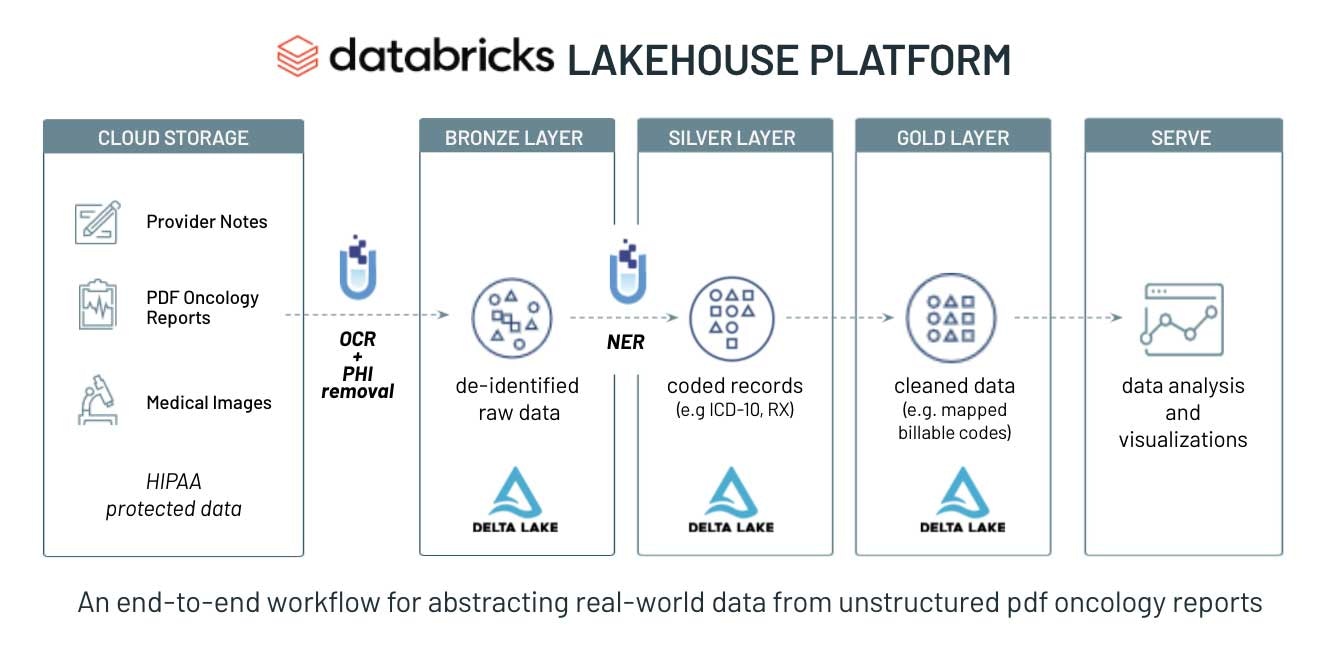
前進するための道のりは、データ管理、パフォーマンスのようなデータウェアハウスの優れた要素と、クラウドデータレイクの低コスト、柔軟性、スケーラビリティを組み合わせたモダンなデータプラットフォームである、Databricksのレイクハウスプラットフォームからスタートします。ヘルスケアシステムを有効化する新たなシンプルなアーキテクチャは、従来の分析とデータサイエンス両方に対応するために、構造化データ(EHRデータベースにおける診断/プロシージャコード)、半構造化データ(HL7、FHIRメッセージ)、非構造化データ(フリーテキストのメモや画像)といった全てのデータを単一の高パフォーマンスに統合します。

Databricksのレイクハウスプラットフォームのコアには、データレイクに(Apache Spark™を通じた)パフォーマンス、信頼性、ガバナンスをもたらすオープンソースストレージレイヤーであるDelta Lakeがあります。ヘルスケア企業は、生のプロバイダーノート、放射線医学レポート、PDFの病理レポートなどお使いの全てのデータをDelta Lakeに格納することができます。これによって、データ変換を行う前のオリジナルの信頼できる情報源を保持することができます。一方、従来型のデータウェアハウスにおいては、データを取り込む前にデータの変換が行われるため、非構造化のテキストから抽出された構造化された変数は、もともとのテキストから分断されることになります。
この基盤の基礎になっているのは、ヘルスケア、ライフサイエンス業界で最も広く使用されているNLPライブラリであるJohn Snow Labsのヘルスケア向けSpark NLPです。Databricks上での動作に最適化されることで、ヘルスケア向けSpark NLPはシームレスかつ大規模、最先端の精度で、医療、生物医学テキストデータを分類し、構造化し、抽出を行います。Python、Java、Scalaに対応している唯一のネイティブ分散オープンソーステキスト処理ライブラリであり、すべてのSpark NLPパイプラインはSpark MLパイプラインなので、統合されたNLP、機械学習パイプラインの構築に特に適しています。Spark NLPは、従来のNLPライブラリ(spaCy、nltk、Stanford CoreNLP、Open NLPなど)の全ての機能に加え、スペルチェック、感情分析、文書分類などの追加機能を備えたPython、Java、Scalaのライブラリを提供します。DatabricksとJohn Snow Labsのジョイントソリューションの詳細に関しては、以前の記事、ヘルスケアにおける大規模テキストデータへの自然言語処理の適用を参照ください。
リアルワールドオンコロジーデータ要約の実践
DatabricksとJohn Snow Labsのパワーをデモンストレーションするために、オンコロジーノートからリアルワールドデータを要約するためのソリューションアクセラレータを作成しました。ソリューションアクセラレータには、後段の分析およびリアルワールドのエビデンスのためのオンコロジーレポートの取り込み、準備に関するステップバイステップの手順書、構築済みのコード、サンプルデータが含まれています。ソリューションはDatabrikcsノートブックとして実行できる様になっており、すぐにスタートできるように、以下のソリューションの簡単なウォークスルーを含めています。
本ソリューションにおいては、MT ONCOLOGY NOTESデータセットを使用しました。これには、主に医療専門家によって書き起こされた医療レポートのサンプルと、医療レポートの一部を構成する特定のセクション、例えば、物理的検査(physical examination)あるいはPE、システムレビュー(review of system)あるいはROSといったセクションにおける医療単語、フレーズの書き起こし、研究データ、精神状態の試験などから構成されています。
ここでは、非構造化テキストのソースとしてMT Oncology notesデータセットから匿名化された50のオンコロジーレポートを選択し、Delta Lakeのブロンズレイヤーに生のテキストデータを取り込みました。デモであるので、サンプル数を50に限定していますが、このソリューションアクセラレータで提供されるフレームワークは、数百万の診断ノート、テキストデータに対応できる様になっています。
このアクセラレータの最初のステップは、固有表現抽出(Named-Entity Recognition:NER)の様々なモデルを用いて変数を抽出するというものです。このために、最初にNLPパイプラインをセットアップします。これには、特にヘルスケア関係のNER向けにトレーニングされたdocumentAssembler、sentenceDetector、tokenizerのようなannotatorsが含まれます。以下の例では、医療NERモデルであるbionlp_nerと医療単語向けにトレーニングされたディープNERモデルであるjsl_nerを組み合わせました。中皮腫(mesothelioma)の患者が咳などの症状を経験していることがわかります。

テキストからの固有表現の抽出は、AIアシストETLの素晴らしい例となります。学習済みのディープラーニング(DL)モデルによって、後段の医療分析で活用できるように非構造化データを構造化フォーマットに変換することができます。
症状を抽出することで、メディケアリスクの調整のためのコーディング精度を改善し、Hierarchical Condition Category(HCC)コーディングを自動化するために使用されるICD-10コードにマッピングすることができます。治療のパターンを分析し、症状と腫瘍学エンティティとの関係性を分析するために、このデータを活用することができます。
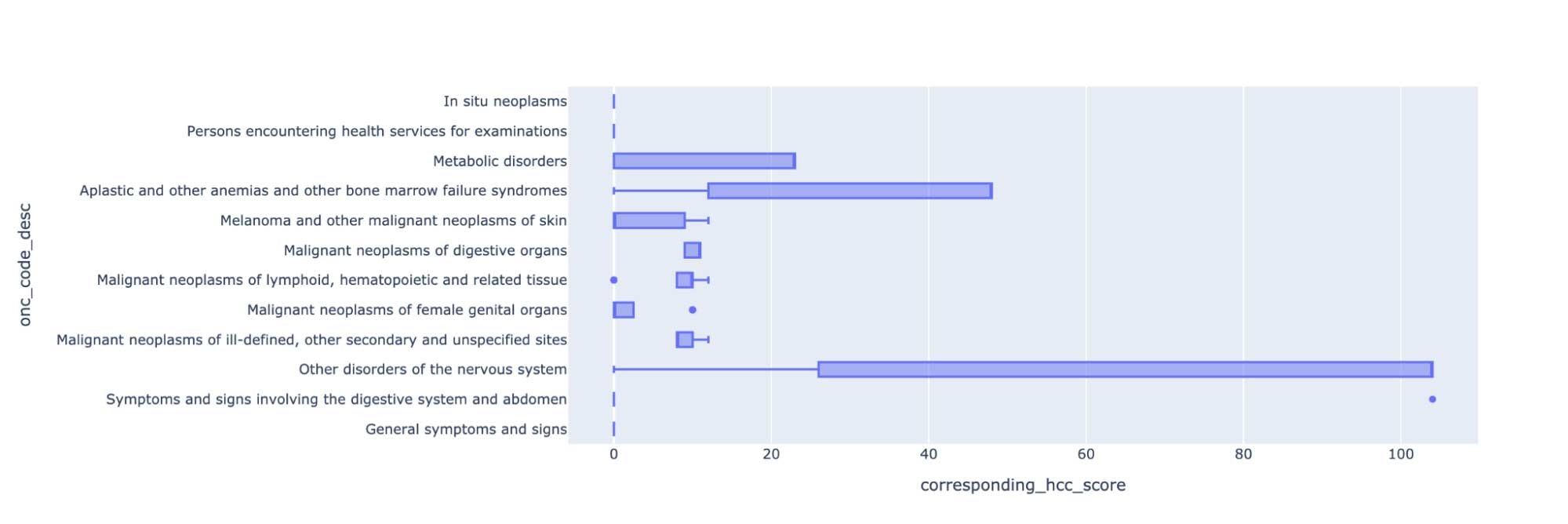
図1. 医療データセットにおいてコード化された症状に対する平均リスク
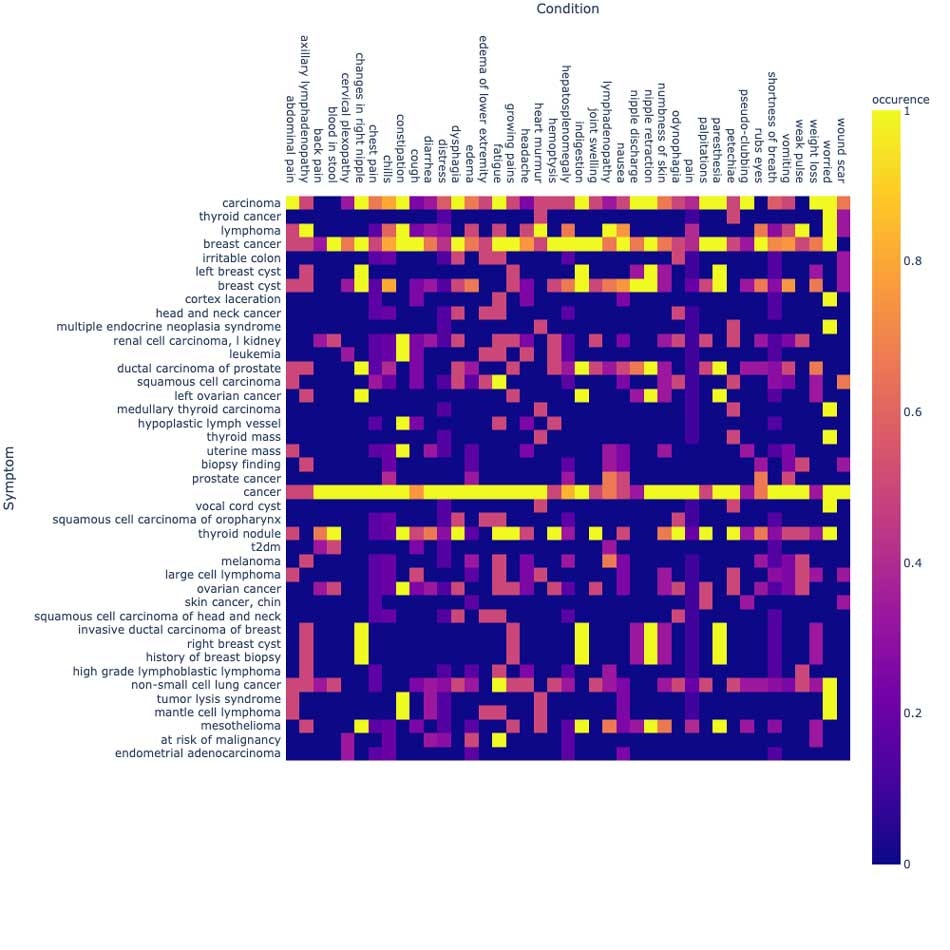
図2. データセットにおいて頻出している条件と病状の可視化
さらに、これらの症状が存在しているか、存在していないか、あるいは他の誰かと関連していないかといった主訴(assertion status)を研究するためのチャートを作成することができます。
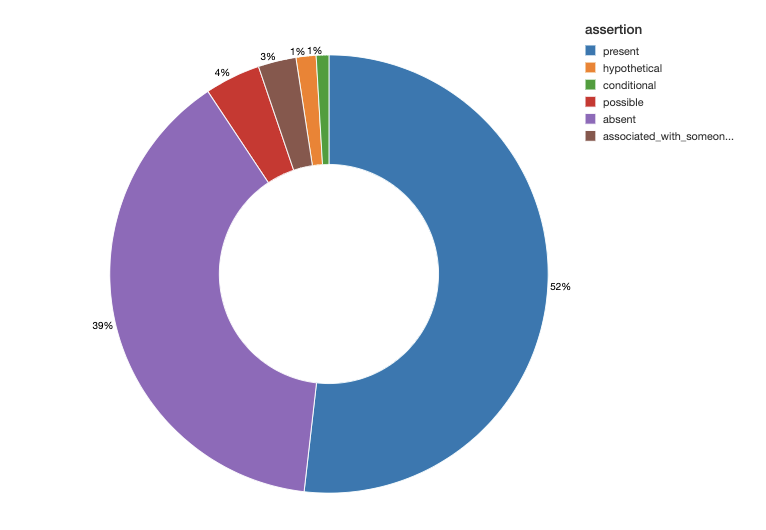
同じノートデータセットに対して、最も一般的なオンコロジーのエンティティと彼らの主訴を重ね合わせることで、解説的かつビジュアルな統計処理を実行することができます。
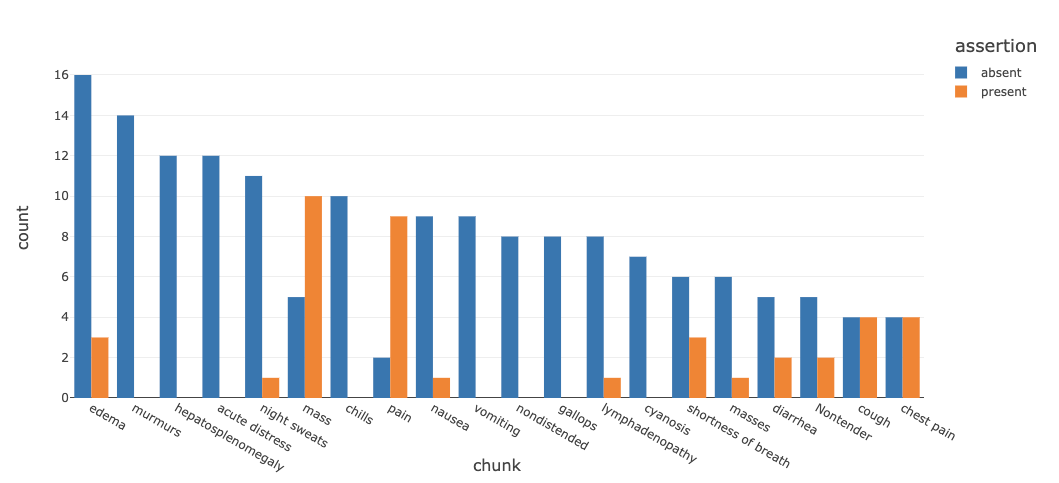
図3. 最も一般的な症状に対する主訴
次に、投薬の頻度、期間を含む治療を見ていきます。これは、オンコロジーの治療の基礎となります。以下は投薬治療と期間に関する情報を抽出するソリューションノートブックに含まれているNLPモデルのスクリーンショットです。

これによって、症状と治療、最初の様な病状を信頼性スコアとともに関連づけることができます。

個々の患者ケアの品質保証と、人工レベルの研究において、データは重要なものであり、リアルワールドにおける介入の効果と安全性を結論づける役に立つものです。
Databricksのレイクハウスプラットフォームを用いることで、状態、症状、治療、そして構造化されていないノートから抽出された他の適切な情報を含むデータベースを容易に構築することができ、後段の分析、医療上の意思決定サポート、研究に活用することができる様になります。
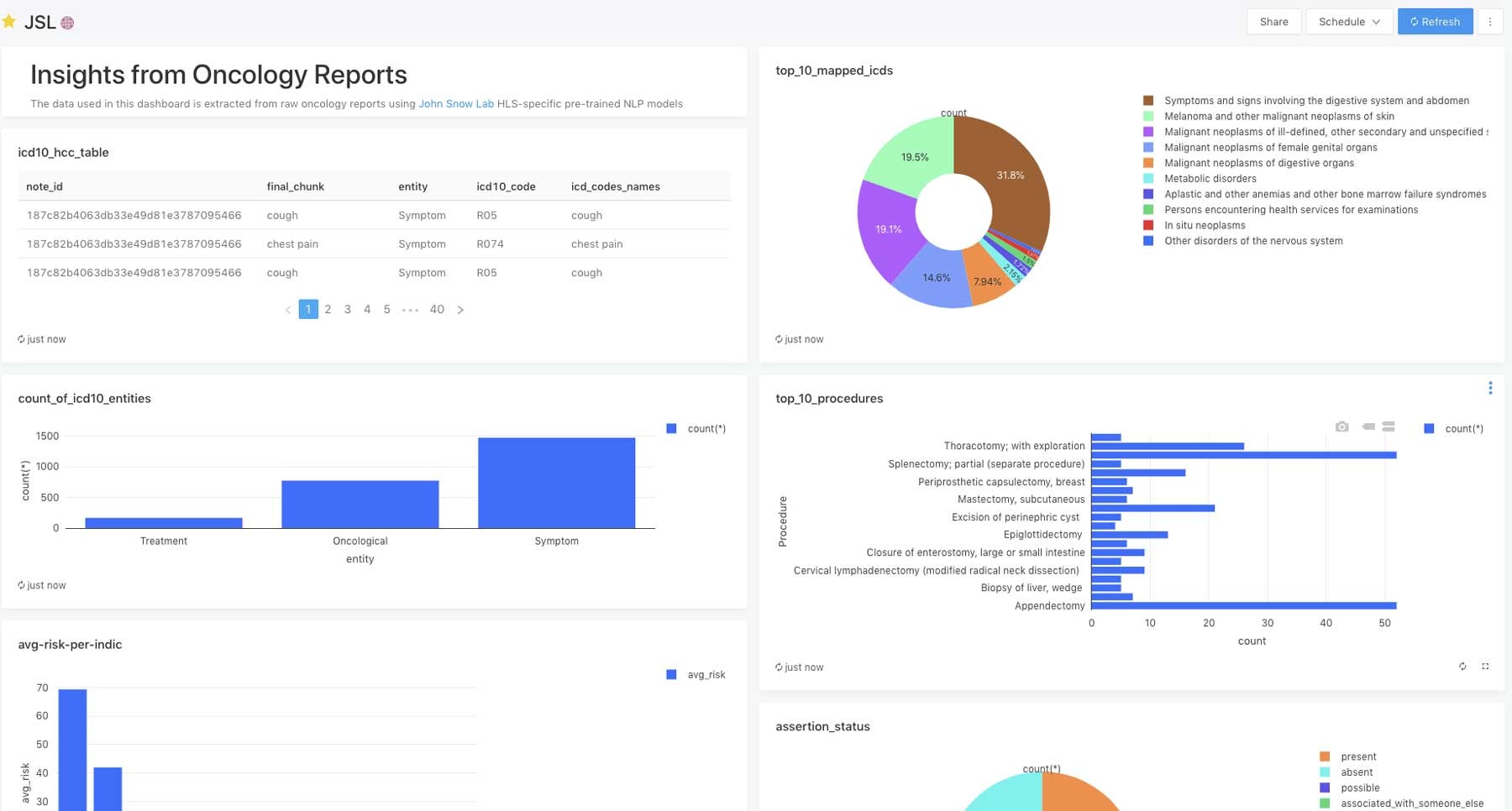
このソリューションアクセラレータを用いることで、DatabricksとJohn Snow Labsは、リアルワールドのエビデンス生成に求められる品質で大規模オンコロジーデータから情報を抽出することができる扉を開きました。
NLPを用いてオンコロジーノートからリアルワールドデータを抽出してみる
このソリューションを活用するには、ノートブックをオンラインで確認するか、ノートブックをダウンロードしてお使いのDatabricksアカウントにインポートして試してみてください。これらのノートブックには、関係するJohn Snow Labs NLPのライブラリやライセンスキーをインストールする手順が含まれています。
ヘルスケア、ライフサイエンスのソリューションについて、業種別ページで詳細を確認することも可能です。