How the Lakehouse Can Unlock the Power of Health Data - The Databricks Blogの翻訳です。
どのようにヘルスケア、ライフサイエンス業界におけるデータウェアハウス、データレイクの課題に打ち勝つのか
一人の患者から毎年およそ80メガバイトの医療データが生まれます。数千の患者の生涯を通じて、価値のある洞察を含むペタバイトオーダーのデータに直面することになります。これらの洞察を導き出すことで、医療オペレーションを円滑にし、創薬研究を加速し、患者の治療結果を改善します。しかし最初に、データは下流の分析、AIで使用できるように準備する必要があります。残念なことに、多くの医療機関、ライフサイエンス期間は、単にデータを収集し、クレンジングし、データを構造化するために膨大な時間を費やしています。
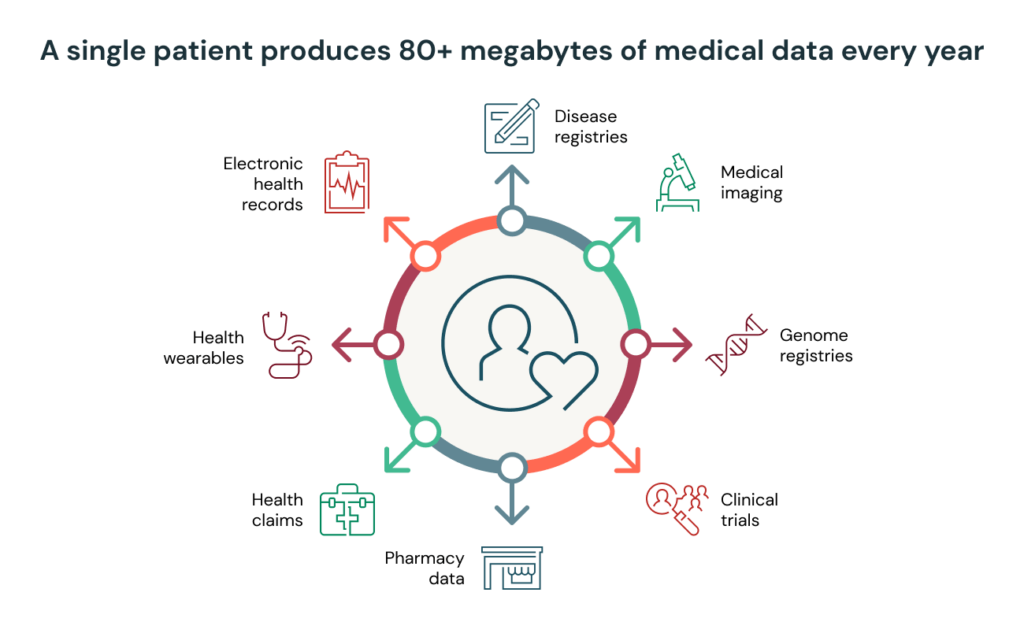
一人の患者が1年あたり80メガバイトのデータを生成することで、医療データは指数関数的に増加しています
ヘルスケア、ライフサイエンスにおけるデータの課題
ヘルスケア業界の企業にとって、データ準備、分析、AIに課題がある理由は数多く存在していますが、そのほとんどはデータウェアハウス上に構築されたレガシーなデータアーキテクチャへの投資に関係するものです。この業界における一般的な4つの課題を見ていきましょう。
課題1(ボリューム): 急速に増加するヘルスデータへの対応
おそらくゲノミクスが、この業界におけるデータの急激な増加を示すベストな例といえるでしょう。当初、ゲノムのシーケンスを行うためには10億ドル以上のコストがかかりました。膨大なコストゆえ、初期は主に(そして今も)、人間の遺伝子の非常に小さい部分、主に0.1%において特定の変異体を見つけ出すプロセスである、ジェノタイピングに注力されていました。そして、これは遺伝子全体の2%以下となるタンパク質のコーディングをカバーする全エクソームシーケンス(Whole Exome Sequencing)へと進化しました。今や企業は全ゲノムシーケンス(WGS)による顧客への直接検査を提供しており、30回のWGSで300ドル以下となっています。人口レベルにおいては、UKのBiobankが今年、20万以上の全ゲノムを公開しています。もはやこれは単なるゲノミクスの話ではありません。画像、ウェアラブル医療機器、電子医療記録もまた劇的に増加しています。
スケールが、人口レベルでの医療分析や創薬のような取り組みへの鍵となります。残念なことに、多くのレガシーなアーキテクチャはオンプレミスに構築されており、ピーク時のキャパシティに合わせて設計されています。このアプローチは、使用率が低い期間における未使用の計算資源(究極的にはお金の無駄)を引き起こし、アップグレードが必要となっても迅速に対応してスケールすることができません。
課題2(種類): 多様性のあるヘルスデータの分析
ヘルスケア、ライフサイエンス企業は、それぞれに意味が異なる膨大な種類のデータを取り扱っています。医療データの80%以上が非構造化データであることは幅広く受け入れられていますが、多くの企業はいまだ構造化データ、SQLベースの分析向けに設計されたデータウェアハウスに大きな注意を払っています。非構造化データには、腫瘍学、免疫学、神経学のような領域(コストが急激に増加している領域)で病気の進行を診断するために重要な画像データ、患者の健康状況、行動履歴を完全に理解するためには重要な医療ノートにおけるナラティブなテキストデータが含まれます。これらのデータタイプを無視したり、脇にのけておくという選択肢はありません。
さらに問題を複雑にしているのは、ヘルスケアのエコシステムは複雑に絡まり合っており、ステークホルダーは新たなデータタイプと格闘する必要に迫られています。例えば、医療従事者がリスク分担のための契約を管理、判断するために請求データを必要とし、患者が事前承認や運転品質計測のようなプロセスを支援するために診療データを必要するといったものです。これらの企業は多くの場合、これらの新しいデータタイプをサポートするデータアーキテクチャはプラットフォームが欠如しています。
いくつかの企業は非構造化データ、先進的分析をサポートするためにデータレイクに投資を行いましたが、これらは新たな課題を引き起こしました。この環境においては、データチームはデータウェアハウスとデータレイクの2つのシステムを管理する必要があり、サイロ化されたツール間でのデータコピーはデータ品質と管理上の問題を引き起こします。
課題3(速度): リアルタイムで患者の洞察を得るためのストリーミングデータ処理
多くのケースにおいて、ヘルスケアは生死に関わる問題です。状況は劇的に変化しうるため、日次ベースのバッチデータ処理であっても十分では無いケースは多く存在します。秒レベルで最新の情報にアクセスできることは、介入性治療を成功させるためには重要なこととなります。敗血症の予測からICU病床のリアルタイム需要予測の実装に至るケースにおいて、病院、国際医療システムでは命を救うためにストリーミングデータが用いられています。
加えて、データの速度が、ヘルスケアにおけるデジタル革命の主要コンポーネントとなっています。個人がこれまで以上により多くのデータにアクセスできるようになっており、リアルタイムで治療に影響を与えられるようになっています。例えばLivongoによって提供される継続的グルコースモニターのようなウェアラブルデバイスは、モバイルアプリにリアルタイムでデータをストリーミングし、パーソナライズされた行動の提案を行っています。
初期のこれらの成功にかかわらず、いまだ多くの組織はストリーミングデータの速度に対応できるようにデータアーキテクチャを設計していません。信頼性の問題と、リアルタイムデータの統合に関する課題がイノベーションを妨げています。
課題4(真実性): ヘルスケアデータ、AIにおける信頼構築
最後となりますが、医療および規制上の基準はヘルスケアにおいて最大限の精度を要求します。ヘルスケア企業は準拠すべき高い公共医療コンプライアンス要件を持っています。組織におけるデータの民主化にはガバナンスが必要となります。
加えて、医療環境に人工知能(AI)、機械学習(ML)を持ち込む際、組織は良いモデルのガバナンスが必要となります。残念なことに、多くの企業はデータウェアハウスと断絶されたデータサイエンスワークフローのための別のプラットフォームを保有しています。このことは、AIを活用したアプリケーションにおける再現性と信頼性を構築する際に深刻な問題を引き起こします。
レイクハウスでヘルスデータを解放する
レイクハウスアーキテクチャは、クラウドデータレイクの低コスト、スケーラビリティ、柔軟性と、データウェアハウスのパフォーマンス、ガバナンスを組み合わせたモダンなデータアーキテクチャであり、ヘルスケア、ライフサイエンス企業がこれらの課題を解決することを支援します。レイクハウスを用いることで、企業は全ての種類のデータを蓄積することができ、オープンな環境で、あらゆるタイプの分析、MLを活用することができます。
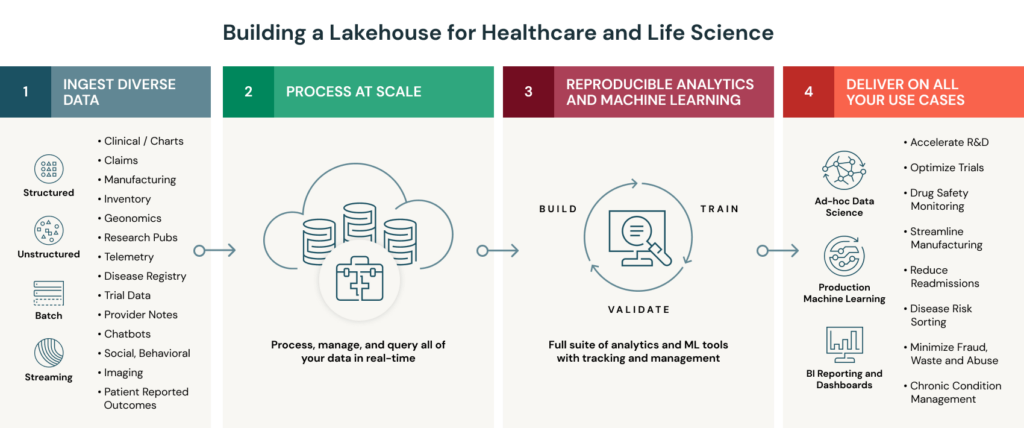
モダンなレイクハウスアーキテクチャにより、ヘルスケア、ライフサイエンスにおける全てのデータ分析のユースケースに対応
特に、レイクハウスはヘルスケア、ライフサイエンス企業に以下のメリットをもたらします。
- 全ての大規模医療データを整理 Databricksのレイクハウスプラットフォームのコアは、お使いのデータレイクに信頼性とパフォーマンスを提供する、オープンソースのデータ管理レイヤーであるDelta Lakeです。従来型のデータウェアハウスとは異なり、Delta Lakeはあらゆる構造化データ、非構造化データをサポートしており、容易に医療データを取り込むために、Databricksでは電子医療記録やゲノミクスといった業界固有のデータタイプに対応したコネクターを開発しました。これらのコネクターは、クイックスタートのためのソリューションアクセラレーターに業界標準のデータモデルとともに同梱されています。加えて、Delta Lakeは、データの処理速度を劇的に改善するためにキャッシュおよびインデックスに対してビルトインの最適化を提供しています。これらの機能により、データチームは全ての生データを一つの場所に取り込むことができ、患者の全体的な健康状況を示すビューを作成するためにデータを整理することができます。
- 全ての患者分析、AIを活用 レイクハウスでで全てのデータが集中管理されることで、データチームは直接データに対して強力な患者分析を実施したり、予測モデルを構築することができます。これらの機能をベースとして、Databricksは、旧スイートの分析、AIツール、そして、SQL、R、Python、Scalaといった幅広いプログラミング言語をサポートするコラボレーティブなワークスペースを提供します。これによって、データサイエンティスト、データエンジニア、医療インフォマティシストなど様々なユーザーグループが一緒になって、医療データの分析、モデル構築、可視化を行うことを支援します。
- 患者に対する洞察をリアルタイムで提供 レイクハウスはストリーミング、バッチデータに対する統合アーキテクチャを提供します。二つの異なるアーキテクチャを管理する必要もなく、信頼性の問題に格闘する必要もありません。加えて、Databricks上でレイクハウスアーキテクチャを運用することで、企業はワークロードに応じて自動でスケールする、クラウドネイティブプラットフォームにアクセスできるようになります。これにより、人口規模でニアリアルタイムの洞察を得るために、ペタバイト規模の履歴データと組み合わせてストリーミングデータを容易に取り込むことができます。
- データ品質とコンプライアンスを提供 データの真実性に対応するために、レイクハウスは従来型のデータレイクハウスには存在しない、スキーマ強制、監査、バージョン管理、きめ細かいアクセスコントロールをサポートしています。レイクハウスによる重要なメリットは、同一かつ信頼できるデータソースに対して、分析とMLの両方を実行できるということです。加えて、DatabricksはMLモデルのトラッキング、管理機能を提供しているので、環境上でチームが結果を容易に再現でき、コンプライアンスの基準への適合をサポートします。これら全ての機能は、HIPAA準拠の分析環境で提供されます。
ヘルスケア、ライフサイエンスデータを管理する際、このレイクハウスはベストなアーキテクチャと言えます。このアーキテクチャとDatabricksが提供する機能を結びつけることで、持病管理を通じた創薬など非常にインパクトのある幅広いユースケースに企業が対応できるようになります。
ヘルスケア、ライフサイエンスのためのレイクハウスを構築する
上で述べたように、ヘルスケア、ライフサイエンス企業がご自身のニーズに対応するためにレイクハウスを構築できるように、一連のソリューションアクセラレーターを発表できることを嬉しく思います。我々のソリューションアクセラレーターには、そして、Databricksノートブック上のサンプルデータ、開発済みのコード、ステップバイステップの指示が含まれています。
- 新たなソリューションアクセラレーター: リアルワールドの証拠のためのレイクハウス リアルワールドのデータは、薬品企業に対して、実験外の患者の健康状況、薬効に関する新たな洞察を提供します。このアクセラレーターは、Databricks上にリアルワールドの証拠のためのレイクハウスを構築する支援を行います。患者グループに対するサンプルのEHRデータの取り込みから、OMOPコモンデータモデルを用いたデータの構造化、そして、薬の処方パターンの調査のような大規模分析を実行します。
Lakehouse for Real-world Evidence notebooksをチェックしてみてください。
- Coming Soon: 人口規模の医療のためのレイクハウス 医者と患者は、より多くの意思決定を行えるように、患者に対するリアルタイムの洞察を必要とします。このアクセラレーターにおいては、Databricks上でHL7ストリーミングデータを容易に取り込み、患者の病気リスクを予測するユースケースに対するMLモデルの構築を行います。
詳細に関しては、Healthcare、Life Sciencesのソリューションを参照ください。