概要
前回の記事はこちらです。
ここで作成した実験コードに追加・改変する形でCNNの実験コードを作成します。
実験では実行時間の問題でscikit-learnのMNISTデータセットを用いています。
通常のMNISTデータセットとの差異は
- 画像サイズが$(8, 8)$
- データセットの総画像数は1797枚
であることですね。おかげで学習時間は(僕の環境では)数十秒で済みます。
一応Kerasのフルデータセットでの実験コードも載せてあります。
こちらは僕の環境だと数時間かかるっぽいので断念しました...
次回記事はこちら
更新履歴
- 2020/9/26
-
Trainerクラスのプログレスバーを変更 -
Trainerクラスのforward関数の実装を変更しました。概算で10MB以上のデータを一度に流そうとすると分割して流すようにしました。 - google colaboratoryへのリンクをgithubのREADME.mdに追加
-
目次
_TypeManagerクラスの変更
まずはLayerManagerクラスでConvLayerとPoolingLayerを扱えるようにするために、_TypeManagerクラスに追加します。
_type_manager.py
class _TypeManager():
"""
層の種類に関するマネージャクラス
"""
N_TYPE = 4 # 層の種類数
BASE = -1
MIDDLE = 0 # 中間層のナンバリング
OUTPUT = 1 # 出力層のナンバリング
CONV = 2 #畳み込み層のナンバリング
POOL = 3 #プーリング層のナンバリング
REGULATED_DIC = {"Middle": MiddleLayer,
"Output": OutputLayer,
"Conv": ConvLayer,
"Pool": PoolingLayer,
"BaseLayer": None}
@property
def reg_keys(self):
return list(self.REGULATED_DIC.keys())
def name_rule(self, name):
name = name.lower()
if "middle" in name or name == "mid" or name == "m":
name = self.reg_keys[self.MIDDLE]
elif "output" in name or name == "out" or name == "o":
name = self.reg_keys[self.OUTPUT]
elif "conv" in name or name == "c":
name = self.reg_keys[self.CONV]
elif "pool" in name or name == "p":
name = self.reg_keys[self.POOL]
else:
raise UndefinedLayerError(name)
return name
定数としてCONVとPOOLを追加、REGULATED_DICでレイヤ名からレイヤオブジェクトを取得できるようにしています。
さらにREGURATED_DICのkeysリストが必要になる場面が多かったのでプロパティ化、ネーミングルールに畳み込み層とプーリング層を追加しました。
Trainerクラスの追加
学習や予測を行う関数群をLayerManagerクラスからTrainerクラスとして独立させました。
trainer.py
import time
import numpy as np
softmax = type(get_act("softmax"))
sigmoid = type(get_act("sigmoid"))
class Trainer():
def __init__(self, x, y):
self.x_train, self.x_test = x
self.y_train, self.y_test = y
self.make_anim = False
def forward(self, x, lim_memory=10):
def propagate(x):
x_in = x
n_batch = x.shape[0]
switch = True
for ll in self.layer_list:
if switch and not self.is_CNN(ll.name):
x_in = x_in.reshape(n_batch, -1)
switch = False
x_in = ll.forward(x_in)
# 順伝播メソッドは誤差計算や未知データの予測にも使用するため
# メモリ容量が大きくなる可能性がある
if np.prod(x.shape)*8/2**20 >= 10:
# 倍精度浮動小数点数(8byte)で10MB(=10*2**20)以上の
# メモリを利用する場合は5MB以下ずつに分割して実行する
n_batch = int(5*2**20/(8*np.prod(x.shape[1:])))
y = np.zeros((x.shape[0], lm[-1].n))
n_loop = int(np.ceil(x.shape[0]/n_batch))
for i in range(n_loop):
propagate(x[i*n_batch : (i+1)*n_batch])
y[i*n_batch : (i+1)*n_batch] = lm[-1].y.copy()
lm[-1].y = y
else:
# そうでなければ普通に実行する
propagate(x)
def backward(self, t):
y_in = t
n_batch = t.shape[0]
switch = True
for ll in self.layer_list[::-1]:
if switch and self.is_CNN(ll.name):
y_in = y_in.reshape(n_batch, *ll.O_shape)
switch = False
y_in = ll.backward(y_in)
def update(self, **kwds):
for ll in self.layer_list:
ll.update(**kwds)
def training(self, epoch, n_batch=16, threshold=1e-8,
show_error=True, show_train_error=False, **kwds):
if show_error:
self.error_list = []
if show_train_error:
self.train_error_list = []
if self.make_anim:
self.images = []
self.n_batch = n_batch
n_train = self.x_train.shape[0]//n_batch
n_test = self.x_test.shape[0]
# 学習開始
start_time = time.time()
lap_time = -1
error = 0
error_prev = 0
rand_index = np.arange(self.x_train.shape[0])
for t in range(1, epoch+1):
#シーン作成
if self.make_anim:
self.make_scene(t, epoch)
# 訓練誤差計算
if show_train_error:
self.forward(self.x_train)
error = lm[-1].get_error(self.y_train)
self.train_error_list.append(error)
# 誤差計算
self.forward(self.x_test)
error = lm[-1].get_error(self.y_test)
if show_error:
self.error_list.append(error)
# 収束判定
if np.isnan(error):
print("fail training...")
break
if abs(error - error_prev) < threshold:
print("end learning...")
break
else:
error_prev = error
t_percent = int(50*t/epoch)
np.random.shuffle(rand_index)
for i in range(n_train):
i_percent = int(50*(i+1)/n_train)
if i_percent <= t_percent:
time_stamp = ("progress:[" + "X"*i_percent
+ "\\"*(t_percent-i_percent)
+ " "*(50-t_percent) + "]")
else:
time_stamp = ("progress:[" + "X"*t_percent
+ "/"*(i_percent-t_percent)
+ " "*(50-i_percent) + "]")
elapsed_time = time.time() - start_time
print("\r" + time_stamp
+ "{}s/{}s".format(
int(elapsed_time),
int(lap_time*epoch) if lap_time > 0 else "?"),
end="")
rand = rand_index[i*n_batch : (i+1)*n_batch]
self.forward(self.x_train[rand])
self.backward(self.y_train[rand])
self.update(**kwds)
if lap_time < 0:
lap_time = time.time() - start_time
print()
if show_error:
# 誤差遷移表示
self.show_errors(show_train_error, **kwds)
def pred_func(self, y, threshold=0.5):
if isinstance(self[-1].act, softmax):
return np.argmax(y, axis=1)
elif isinstance(self[-1].act, sigmoid):
return np.where(y > threshold, 1, 0)
else:
raise NotImplemented
def predict(self, x=None, y=None, threshold=0.5):
if x is None:
x = self.x_test
if y is None:
y = self.y_test
self.forward(x)
self.y_pred = self.pred_func(self[-1].y, threshold=threshold)
y = self.pred_func(y, threshold=threshold)
print("correct:", y[:min(16, int(y.shape[0]*0.1))])
print("predict:", self.y_pred[:min(16, int(y.shape[0]*0.1))])
print("accuracy rate:", np.sum(self.y_pred == y, dtype=int)/y.shape[0]*100, "%",
"({}/{})".format(np.sum(self.y_pred == y, dtype=int), y.shape[0]))
return self.y_pred
def show_errors(self, show_train_error=False, title="error transition",
xlabel="epoch", ylabel="error", fname="error_transition.png",
log_scale=True, **kwds):
fig, ax = plt.subplots(1)
fig.suptitle(title)
if log_scale:
ax.set_yscale("log")
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.grid()
if show_train_error:
ax.plot(self.train_error_list, label="train accuracy")
ax.plot(self.error_list, label="test accuracy")
ax.legend(loc="best")
#fig.show()
if len(fname) != 0:
fig.savefig(fname)
def ready_anim(self, n_image, x, y, title="animation",
xlabel="x", ylabel="y", ex_color="r", color="b",
x_left=0, x_right=0, y_down = 1, y_up = 1):
self.n_image = n_image
self.x = x
self.color = color
self.make_anim = True
self.anim_fig, self.anim_ax = plt.subplots(1)
self.anim_fig.suptitle(title)
self.anim_ax.set_xlabel(xlabel)
self.anim_ax.set_ylabel(ylabel)
self.anim_ax.set_xlim(np.min(x) - x_left, np.max(x) + x_right)
self.anim_ax.set_ylim(np.min(y) - y_down, np.max(y) + y_up)
self.anim_ax.grid()
self.anim_ax.plot(x, y, color=ex_color)
return self.anim_fig, self.anim_ax
def make_scene(self, t, epoch):
# シーン作成
if t % (epoch/self.n_image) == 1:
x_in = self.x.reshape(-1, 1)
for ll in self.layer_list:
x_in = ll.forward(x_in)
im, = self.anim_ax.plot(self.x, ll.y, color=self.color)
self.images.append([im])
forwardやbackward、update関数を関数として分離している理由は、何かオリジナリティある処理をしたい場合はforward関数に順伝播で行って欲しいメソッドを投げるだけでいいようにするためです。もう少し工夫の余地がある気がします...
また、forward関数は誤差計算や予測計算でも使用するため、膨大なデータを流すことになることがあります。そこで、倍精度浮動小数点数(8Byte)のデータが流れてきたことを想定して概算10MBを超える場合は5MB程度ずつに分割して流すように変更しました。
training関数では学習の流れを記述してあります。訓練データの誤差遷移もみたいな〜と思ったので追加してあります。
また、収束判定にNaNの判定も入れており、学習に失敗したらすぐに訓練を終了するようになっています。
また、これまではtqdmモジュールを利用して進捗表示をしていましたが、自前で用意しました。
""でエポックの進捗を、"/"でバッチの消化具合を表示しています。
predict関数では文字通りテストデータに対する予測を行っています。オプション引数を用いており、指定しなければレイヤマネージャに持たせているテストデータを利用します。
テストデータを流した後、pred_funcによってデータ形式を変更し、正答率を計算するようにしています。ここも少し変更する必要がありそうですね...これでは分類問題の正答率しか出せません...
LayerManagerクラスの変更
ConvLayerクラスとPoolingクラスが追加されたことで細かい変更が必要になりました。
layer_manager.py
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import tqdm
class LayerManager(_TypeManager, Trainer):
"""
層を管理するためのマネージャクラス
"""
def __init__(self, x, y):
super().__init__(x, y)
self.__layer_list = [] # レイヤーのリスト
self.__name_list = [] # 各レイヤーの名前リスト
self.__ntype = np.zeros(self.N_TYPE, dtype=int) # 種類別レイヤーの数
def __repr__(self):
layerRepr= "layer_list: " + repr(self.__layer_list)
nameRepr = "name_list: " + repr(self.__name_list)
ntypeRepr = "ntype: " + repr(self.__ntype)
return (layerRepr + "\n"
+ nameRepr + "\n"
+ ntypeRepr)
def __str__(self):
layerStr = "layer_list: " + str(self.__layer_list)
nameStr = "name_list: " + str(self.__name_list)
ntypeStr = "ntype: " + str(self.__ntype)
return (layerStr + "\n"
+ nameStr + "\n"
+ ntypeStr)
def __len__(self):
"""
Pythonのビルドイン関数`len`から呼ばれたときの動作を記述。
種類別レイヤーの数の総和を返します。
"""
return int(np.sum(self.__ntype))
def __getitem__(self, key):
"""
例えば
lm = LayerManager()
+----------------+
| (lmに要素を追加) |
+----------------+
x = lm[3].~~
のように、リストや配列の要素にアクセスされたときに呼ばれるので、
そのときの動作を記述。
sliceやstr, intでのアクセスのみ許可します。
"""
if isinstance(key, slice):
# keyがスライスならレイヤーのリストをsliceで参照する。
# 異常な値(Index out of rangeなど)が入力されたら
# Pythonがエラーを出してくれます。
return self.__layer_list[key]
elif isinstance(key, str):
# keyが文字列なら各レイヤーの名前リストからインデックスを取得して、
# 該当するレイヤーのリストの要素を返す。
if key in self.__name_list:
index = self.__name_list.index(key)
return self.__layer_list[index]
else:
# keyが存在しない場合はKeyErrorを出す。
raise KeyError("{}: No such item".format(key))
elif isinstance(key, int):
# keyが整数ならレイヤーのリストの該当要素を返す。
# 異常な値(Index out of rangeなど)が入力されたら
# Pythonがエラーを出してくれます。
return self.__layer_list[key]
else:
raise KeyError(key, ": Undefined such key type.")
def __setitem__(self, key, value):
"""
例えば
lm = LayerManager()
+----------------+
| (lmに要素を追加) |
+----------------+
lm[1] = x
のように、リストや配列の要素にアクセスされたときに呼ばれるので、
そのときの動作を記述。
要素の上書きのみ認め、新規要素の追加などは禁止します。
"""
value_type = ""
if isinstance(value, list):
# 右辺で指定された'value'が'list'なら
# 全ての要素が'BaseLayer'クラスかそれを継承していなければエラー。
if not np.all(
np.where(isinstance(value, BaseLayer), True, False)):
self.AssignError()
value_type = "list"
elif isinstance(value, BaseLayer):
# 右辺で指定された'value'が'BaseLayer'クラスか
# それを継承していない場合はエラー。
self.AssignError(type(value))
if value_type == "":
value_type = self.reg_keys[self.BASE]
if isinstance(key, slice):
# keyがスライスならレイヤーのリストの要素を上書きする。
# ただし'value_type'が'list'でなければエラー。
# 異常な値(Index out of rangeなど)が入力されたら
# Pythonがエラーを出してくれます。
if value_type != "list":
self.AssignError(value_type)
self.__layer_list[key] = value
elif isinstance(key, str):
# keyが文字列なら各レイヤーの名前リストからインデックスを取得して、
# 該当するレイヤーのリストの要素を上書きする。
# ただし'value_type'が'BaseLayer'でなければエラー。
if value_type != self.reg_keys[self.BASE]:
raise AssignError(value_type)
if key in self.__name_list:
index = self.__name_list.index(key)
self.__layer_list[index] = value
else:
# keyが存在しない場合はKeyErrorを出す。
raise KeyError("{}: No such item".format(key))
elif isinstance(key, int):
# keyが整数ならレイヤーのリストの該当要素を上書きする。
# ただし'value_type'が'BaseLayer'でなければエラー。
# また、異常な値(Index out of rangeなど)が入力されたら
# Pythonがエラーを出してくれます。
if value_type != self.reg_keys[self.BASE]:
raise AssignError(value_type)
self.__layer_list[key] = value
else:
raise KeyError(key, ": Undefined such key type.")
def __delitem__(self, key):
"""
例えば
lm = LayerManager()
+----------------+
| (lmに要素を追加) |
+----------------+
del lm[2]
のように、del文でリストや配列の要素にアクセスされたときに呼ばれるので、
そのときの動作を記述。
指定要素が存在すれば削除、さらにリネームを行います。
"""
if isinstance(key, slice):
# keyがスライスならそのまま指定の要素を削除
# 異常な値(Index out of rangeなど)が入力されたら
# Pythonがエラーを出してくれます。
del self.__layer_list[slice]
del self.__name_list[slice]
elif isinstance(key, str):
# keyが文字列なら各レイヤーの名前リストからインデックスを取得して、
# 該当する要素を削除する。
if key in self.__name_list:
del self.__layer_list[index]
del self.__name_list[index]
else:
# keyが存在しない場合はKeyErrorを出す。
raise KeyError("{}: No such item".format(key))
elif isinstance(key, int):
# keyが整数ならレイヤーのリストの該当要素を削除する。
# 異常な値(Index out of rangeなど)が入力されたら
# Pythonがエラーを出してくれます。
del self.__layer_list[key]
else:
raise KeyError(key, ": Undefined such key type.")
# リネームする
self._rename()
def _rename(self):
"""
リスト操作によってネームリストのネーミングがルールに反するものになった場合に
改めてルールを満たすようにネーミングリストおよび各レイヤーの名前を変更する。
ネーミングルールは[レイヤーの種類][何番目か]とします。
レイヤーの種類はMiddleLayerならMiddle
OutputLayerならOutput
のように略します。
何番目かというのは種類別でカウントします。
また、ここで改めて__ntypeのカウントを行います。
"""
# 種類別レイヤーの数を初期化
self.__ntype = np.zeros(self.N_TYPE)
# 再カウントと各レイヤーのリネーム
for i in range(len(self)):
for j, reg_name in enumerate(self.REGULATED_DIC):
if reg_name in self.__name_list[i]:
self.__ntype[j] += 1
self.__name_list[i] = (self.reg_keys[j]
+ str(self.__ntype[j]))
self.__layer_list[i].name = (self.reg_keys[j]
+ str(self.__ntype[j]))
break
else:
raise UndefinedLayerType(self.__name_list[i])
def append(self, *, name="Middle", **kwds):
"""
リストに要素を追加するメソッドでお馴染みのappendメソッドの実装。
"""
if "prev" in kwds:
# 'prev'がキーワードに含まれている場合、
# 一つ前の層の要素数を指定していることになります。
# 基本的に最初のレイヤーを挿入する時を想定していますので、
# それ以外は基本的に自動で決定するため指定しません。
if len(self) != 0:
if kwds["prev"] != self.__layer_list[-1].n:
# 最後尾のユニット数と一致しなければエラー。
raise UnmatchUnitError(self.__layer_list[-1].n,
kwds["prev"])
elif not self.is_CNN(name):
if len(self) == 0:
# 最初のDNNレイヤは必ず入力ユニットの数を指定する必要があります。
raise UnmatchUnitError("Input units", "Unspecified")
else:
# 最後尾のレイヤのユニット数を'kwds'に追加
kwds["prev"] = self.__layer_list[-1].n
# レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する
name = self.name_rule(name)
# レイヤーを追加する。
for i, reg_name in enumerate(self.REGULATED_DIC):
if name in reg_name:
# 種類別レイヤーをインクリメントして
self.__ntype[i] += 1
# 名前に追加し
name += str(self.__ntype[i])
# ネームリストに追加し
self.__name_list.append(name)
# 最後にレイヤーを生成してリストに追加します。
self.__layer_list.append(self.REGULATED_DIC[reg_name](name=name, **kwds))
def extend(self, lm):
"""
extendメソッドでは既にある別のレイヤーマネージャ'lm'の要素を
全て追加します。
"""
if not isinstance(lm, LayerManager):
# 'lm'のインスタンスがLayerManagerでなければエラー。
raise TypeError(type(lm), ": Unexpected type.")
if len(self) != 0:
if self.__layer_list[-1].n != lm[0].prev:
# 自分の最後尾のレイヤーのユニット数と
# 'lm'の最初のレイヤーの入力数が一致しない場合はエラー。
raise UnmatchUnitError(self.__layer_list[-1].n,
lm[0].prev)
# それぞれ'extend'メソッドで追加
self.__layer_list.extend(lm.layer_list)
self.__name_list.extend(lm.name_list)
# リネームする
self._rename()
def insert(self, prev_name, name="Middle", **kwds):
"""
insertメソッドでは、前のレイヤーの名前を指定しそのレイヤーと結合するように
要素を追加します。
"""
# 'prev_name'が存在しなければエラー。
if not prev_name in self.__name_list:
raise KeyError(prev_name, ": No such key.")
# 'prev'がキーワードに含まれている場合、
# 'prev_name'で指定されているレイヤーのユニット数と一致しなければエラー。
if "prev" in kwds:
if kwds["prev"] \
!= self.__layer_list[self.index(prev_name)].n:
raise UnmatchUnitError(
kwds["prev"],
self.__layer_list[self.index(prev_name)].n)
# 'n'がキーワードに含まれている場合、
if "n" in kwds:
# 'prev_name'が最後尾ではない場合は
if prev_name != self.__name_list[-1]:
# 次のレイヤーのユニット数と一致しなければエラー。
if kwds["n"] != self.__layer_list[
self.index(prev_name)+1].prev:
raise UnmatchUnitError(
kwds["n"],
self.__layer_list[self.index(prev_name)].prev)
# まだ何も要素がない場合は'append'メソッドを用いるようにエラーを出す。
if len(self) == 0:
raise RuntimeError(
"You have to use 'append' method instead.")
# 挿入場所のインデックスを取得
index = self.index(prev_name) + 1
# レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する
name = self.name_rule(name)
# 要素を挿入する
for i, reg_name in enumerate(self.REGULATED_DIC):
if reg_name in name:
self.__layer_list.insert(index,
self.REGULATED_DIC[reg_name](name=name, **kwds))
self.__name_list.insert(index,
self.REGULATED_DIC[reg_name](name=name, **kwds))
# リネームする
self._rename()
def extend_insert(self, prev_name, lm):
"""
こちらはオリジナル関数です。
extendメソッドとinsertメソッドを組み合わせたような動作をします。
簡単に説明すると、別のレイヤーマネージャをinsertする感じです。
"""
if not isinstance(lm, LayerManager):
# 'lm'のインスタンスがLayerManagerでなければエラー。
raise TypeError(type(lm), ": Unexpected type.")
# 'prev_name'が存在しなければエラー。
if not prev_name in self.__name_list:
raise KeyError(prev_name, ": No such key.")
# 指定場所の前後のレイヤーとlmの最初・最後のレイヤーのユニット数が
# それぞれ一致しなければエラー。
if len(self) != 0:
if self.__layer_list[self.index(prev_name)].n \
!= lm.layer_list[0].prev:
# 自分の指定場所のユニット数と'lm'の最初のユニット数が
# 一致しなければエラー。
raise UnmatchUnitError(
self.__layer_list[self.index(prev_name)].n,
lm.layer_list[0].prev)
if prev_name != self.__name_list[-1]:
# 'prev_name'が自分の最後尾のレイヤーでなく
if lm.layer_list[-1].n \
!= self.__layer_list[self.index(prev_name)+1].prev:
# 'lm'の最後尾のユニット数と自分の指定場所の次のレイヤーの
# 'prev'ユニット数と一致しなければエラー。
raise UnmatchUnitError(
lm.layer_list[-1].n,
self.__layer_list[self.index(prev_name)+1].prev)
else:
# 自分に何の要素もない場合は'extend'メソッドを使うようにエラーを出す。
raise RuntimeError(
"You have to use 'extend' method instead.")
# 挿入場所のインデックスを取得
index = self.index(prev_name) + 1
# 挿入場所以降の要素を'buf'に避難させてから一旦取り除き、
# extendメソッドを使って要素を追加
layer_buf = self.__layer_list[index:]
name_buf = self.__name_list[index:]
del self.__layer_list[index:]
del self.__name_list[index:]
self.extend(lm)
# 避難させていた要素を追加する
self.__layer_list.extend(layer_buf)
self.__name_list.extend(name_buf)
# リネームする
self._rename()
def remove(self, key):
"""
removeメソッドでは指定の名前の要素を削除します。
インデックスでの指定も許可します。
"""
# 既に実装している'del'文でOKです。
del self[key]
def index(self, target):
return self.__name_list.index(target)
def name(self, indices):
return self.__name_list[indices]
@property
def layer_list(self):
return self.__layer_list
@property
def name_list(self):
return self.__name_list
@property
def ntype(self):
return self.__ntype
def is_CNN(self, name=None):
if name is None:
if self.__ntype[self.CONV] > 0 \
or self.__ntype[self.POOL] > 0:
return True
else:
return False
else:
name = self.name_rule(name)
if self.reg_keys[self.CONV] in name \
or self.reg_keys[self.POOL] in name:
return True
else:
return False
細かい変更のうち、割とどうでもいい部分は省きます。
省くのは_TypeManagerクラスを充実させたことによる変更の部分ですね。reg_keysプロパティを利用した変更が主です。
大きな変更は、レイヤの種類を増やすごとにいちいち条件分岐を増やしていくのはあまりにも無駄なので、ループで行えるようにしたとこです。
一例としてappendメソッドの該当部分を見てみます。
# レイヤーを追加する。
for i, reg_name in enumerate(self.REGULATED_DIC):
if name in reg_name:
# 種類別レイヤーをインクリメントして
self.__ntype[i] += 1
# 名前に追加し
name += str(self.__ntype[i])
# ネームリストに追加し
self.__name_list.append(name)
# 最後にレイヤーを生成してリストに追加します。
self.__layer_list.append(self.REGULATED_DIC[reg_name](name=name, **kwds))
REGULATED_DICをenumerate関数でループさせ、レイヤ名がreg_nameに含まれている場合に、レイヤ番号iを用いて処理を行っています。
このため、_TypeManagerクラスのレイヤ定数とREGULATED_DICの登録インデックスを揃えておく必要があります。
他の部分も似たような感じです。
最後に、is_CNN関数を用意しました。
これは、引数nameに指定がなければLayerMangerクラスが持っているネットワークがCNNかを返します。
nameにレイヤ名が指定されている場合は、そのレイヤ名がCNNに値するか(つまり畳み込み層かプーリング層かどうか)を返します。
Trainerクラスの順伝播や逆伝播の際に使用しています。
CNN実験コード本体
さて、それではCNNの実験に移ります。
コード全体はこちらに載せています。自由にクローンして/コピーして実験してみてください。
KerasのMNISTデータセットの場合
まずはKerasデータセットの場合から。KerasのMNISTデータセットは訓練データ60000枚、テストデータ10000枚で、画像サイズも$(28, 28)$となっているため、機械学習のデータセットとしては小規模でも、ノートPCなどで学習するには結構大きなデータセットとなっています。
import numpy as np
from keras.datasets import mnist
#from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import tqdm
# データセット取得
n_class=10
(x_train, y_train), (x_test, y_test) = mnist.load_data()
C, B, I_h, I_w = 1, *x_train.shape
B_test = x_test.shape[0]
# 標準化
sc = StandardScaler()
x_train = sc.fit_transform(x_train.reshape(B, -1)).reshape(B, C, I_h, I_w)
x_test = sc.fit_transform(x_test.reshape(B_test, -1)).reshape(B_test, C, I_h, I_w)
# one-hotラベルへの変換
def to_one_hot(data, n_class):
vec = np.zeros((len(data), n_class))
for i in range(len(data)):
vec[i, data[i]] = 1.
return vec
t_train = to_one_hot(y_train, n_class)
t_test = to_one_hot(y_test, n_class)
今回はvalidationデータは作りません。作る場合はscikit-learnのtrain_test_split関数などを利用して訓練データを分割しましょう。
後、scikit-learnのStandardScalerクラスを利用して標準化しています。別に難しい処理をしないので自分で直接コードを書いてもOKです。また、画像認識ですので正規化でもOKです。
scikit-learnのStandardScalerクラスなどは入力が$(B, N)$のデータのみに対応しているので注意しましょう。
最後に正解ラベルが$(60000, )$と$(10000, )$の1次元配列の数値データとなっていますのでone-hot表現と呼ばれるものに変更します。
one-hot表現とは、例えば10クラス分類において、数値ラベルが$3$の正解データを$[0, 0, 0, 1, 0, 0, 0, 0, 0 , 0]$のように、該当部分のみ$1$を取るデータ表現です。
これにより、正解ラベルは$(60000, 10)$と$(10000, 10)$となります。
以上でデータ処理は完了です。
scikit-learnのMNISTデータセットの場合
続いてscikit-learnのMNISTデータセットの場合を紹介します。
こちらは最初に述べたとおりかなり小さなデータセットとなっていますので、気軽に機械学習を試すことができます。
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import tqdm
# データセット取得
n_class=10
C, I_h, I_w = 1, 8, 8
digits = datasets.load_digits()
x = digits.data
t = digits.target
n_data = len(x)
# 標準化
sc = StandardScaler()
x = sc.fit_transform(x).reshape(n_data, I_h, I_w)
x_train, x_test, y_train, y_test = train_test_split(x, t, test_size=0.2, shuffle=True)
# one-hotラベルへの変換
def to_one_hot(data, n_class):
vec = np.zeros((len(data), n_class))
for i in range(len(data)):
vec[i, data[i]] = 1.
return vec
t_train = to_one_hot(y_train, n_class)
t_test = to_one_hot(y_test, n_class)
やっていることはKerasの時とほとんど同じです。違うのはデータセットが$(1797, 64)$の形式で渡される点です。
そのため、データを標準化した後reshapeしてtrain_test_split関数で分割しています。
CNN学習本体
データセットの準備が完了したらいよいよ学習です。
# 畳み込み層と出力層を作成
M, F_h, F_w = 10, 3, 3
lm = LayerManager((x_train, x_test), (t_train, t_test))
lm.append(name="c", I_shape=(C, I_h, I_w), F_shape=(M, F_h, F_w), pad=1,
wb_width=0.1, opt="AdaDelta", opt_dic={"eta": 1e-2})
lm.append(name="p", I_shape=lm[-1].O_shape, pool=2)
lm.append(name="m", n=100, wb_width=0.1,
opt="AdaDelta", opt_dic={"eta": 1e-2})
lm.append(name="o", n=n_class, act="softmax", err_func="Cross", wb_width=0.1,
opt="AdaDelta", opt_dic={"eta": 1e-2})
# 学習させる
epoch = 50
threshold = 1e-8
n_batch = 8
lm.training(epoch, threshold=threshold, n_batch=n_batch, show_train_error=True)
# 予測する
print("training dataset")
lm.predict(x=lm.x_train, y=lm.y_train)
print("test dataset")
lm.predict()
今回は至極簡単なCNNを構築しています。
学習エポック数は50、ミニバッチサイズは8としています。あとはレイヤマネージャにお任せです笑
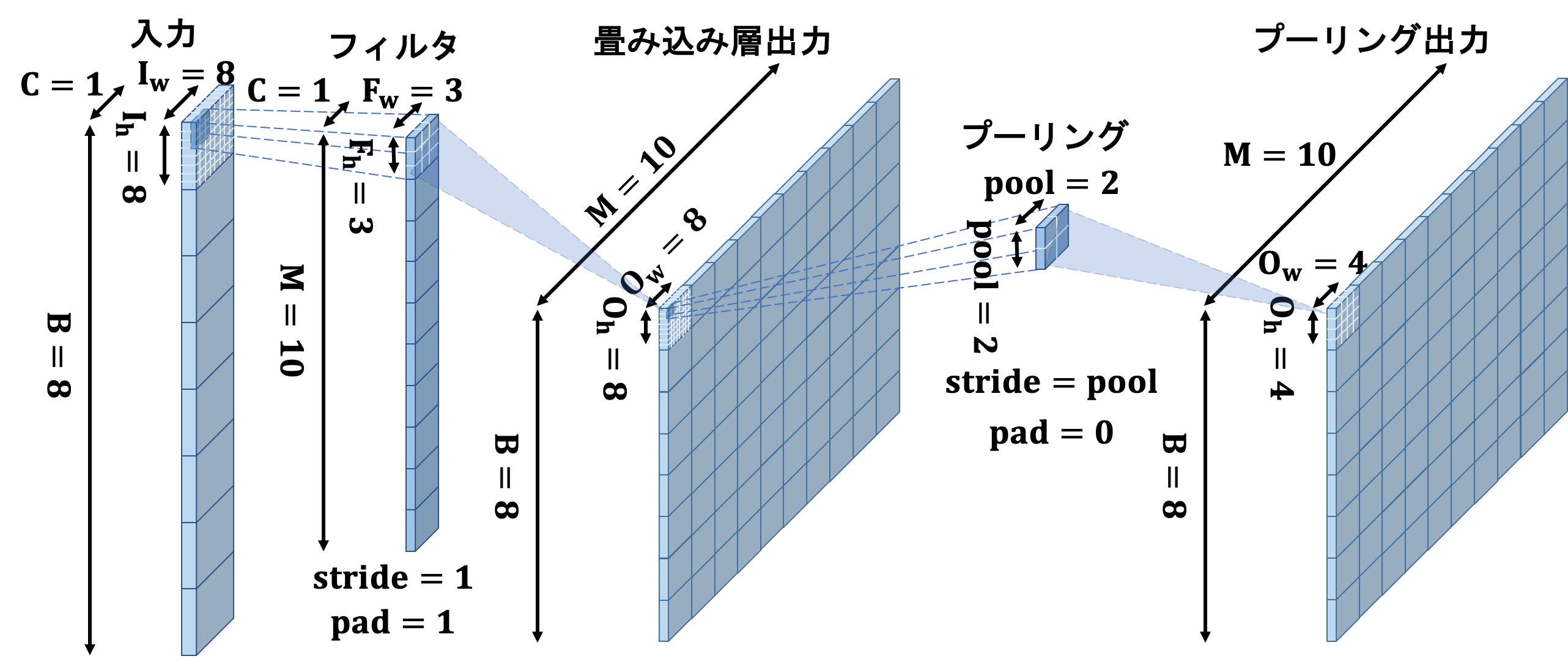
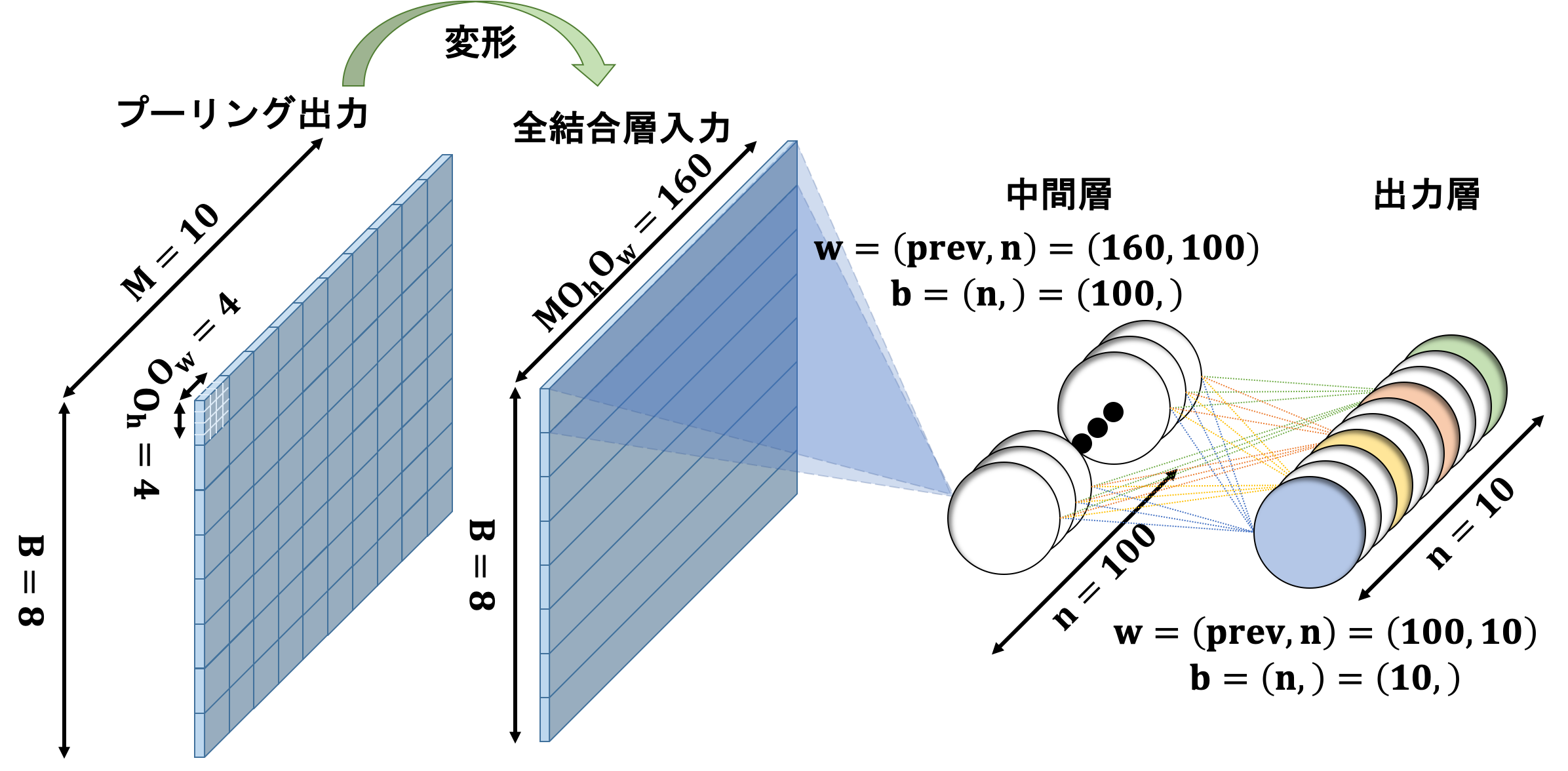
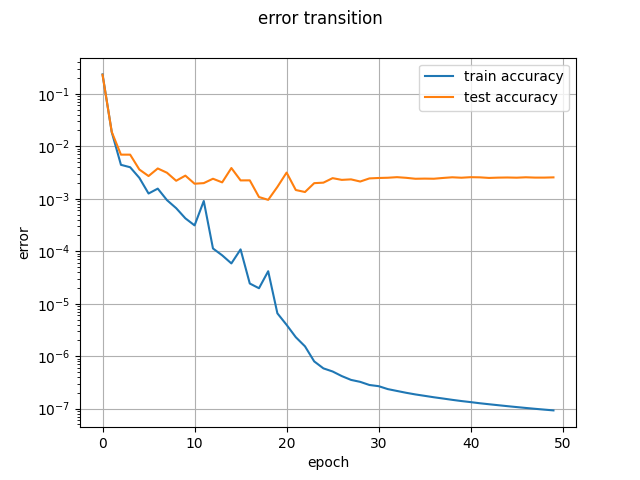
CNNの構造は上図の通りになります。scikit-learnでの実行結果は下図のようになると思います。

誤判断したデータの表示
ついでにどんなデータで間違えたのかを可視化しましょう。
# 間違ったデータを表示する
col=4
dpi=125
y = lm.pred_func(lm.y_test)
fail_index = np.where(y_pred != y)[0]
print("incorrect index:", fail_index)
if fail_index.size:
row = int(np.ceil(fail_index.size/col))
if row * dpi >= 2 ** 16:
row = int(np.ceil((2 ** 16 // dpi - 1)/col))
fig, ax = plt.subplots(row, col, figsize=(col, row + 1), dpi=dpi, facecolor="w")
if row != 1:
for i, f in enumerate(fail_index):
ax[i // col, i % col].imshow(lm.x_test[f], interpolation='nearest', cmap='gray')
ax[i // col, i % col].tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False)
ax[i // col, i % col].set_title(str(y[f]) + " => " + str(y_pred[f]))
if i >= row * col:
break
else:
for i, f in enumerate(fail_index):
ax[i % col].imshow(lm.x_test[f], interpolation='nearest', cmap='gray')
ax[i % col].tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False)
ax[i % col].set_title(str(y[f]) + ' => ' + str(y_pred[f]))
if i >= row * col:
break
fig.tight_layout()
これを実行すると下図のようになります。ちなみに先の実験結果とは別物ですので注意してください。
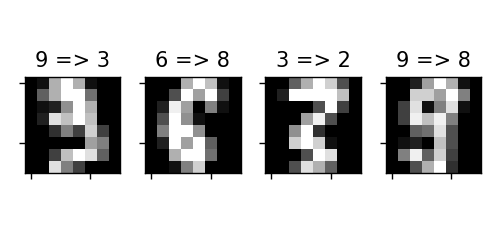
人間が見てもかろうじてって感じですね...これは(このままでは)誤判定しても仕方ないでしょうね。
おわりに
実験中バッチサイズを1より大きくするとうまく学習が進まなくてずっと苦戦してました..
結局、活性化関数がバッチに対応していなかったことが原因でした。普通の活性化関数は放っておいてもnumpyのおかげでバッチに対応してくれますが、softmax関数などの一部の例外的な関数はきちんとバッチに対応しておく必要がありました。
同じように苦しんでいる方がいらっしゃったら気にしてみてください。