こちらのイベントで説明した内容の抜粋です。
自然言語処理(Natural Language Processing: NLP)とは
我々が日常的に使っている自然言語をコンピューターで処理する技術です。
そもそも、なぜ自然言語を処理する必要があるのでしょうか?
世界は自然言語で溢れていますが分析が困難です
2015年、HIMSS(医療情報管理システム協会)は、アメリカのヘルスケア業界において12億の医療ドキュメントが作成されたと推定しました。これ以降、毎年生成される医療テキストデータは増える一方です。電子フォーム、オンラインポータル、PDFレポート、メール、テキストメッセージ、チャットボット、これら全てが現在のヘルスケアコミュニケーションの中心となっていますが、あまりに量が多くて人間による解釈、計測は不可能となっています。
しかし、重要な洞察は自然言語のデータからもたらされます
患者の安全のモニタリングはより多くのデータを収集するにつれて複雑になっています。薬害イベントの5%以下が公式なチャネル経由で報告されており、それ以外の大部分は患者サポートセンターへのメール・電話や、ソーシャルメディアへの投稿、医師と医薬品セールスの会話、オンラインの患者フォーラムなどのフリーテキストのチャネル経由で報告されています。
このような背景から、ここ数年でNLPと機械学習を組み合わせる取り組みが増えています。

機械学習では、コンピューターがタスクを実行する方法自体をデータから学び取ります。
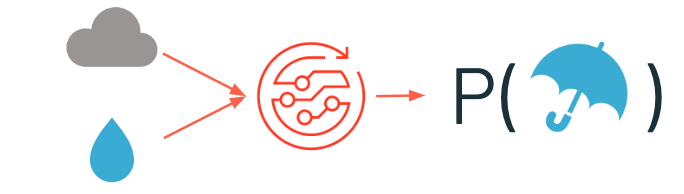
機械学習とNLPを組み合わせることで、テキストに記載されている内容に基づいて特定の事象が発生している確率を導き出すことも可能となっています。
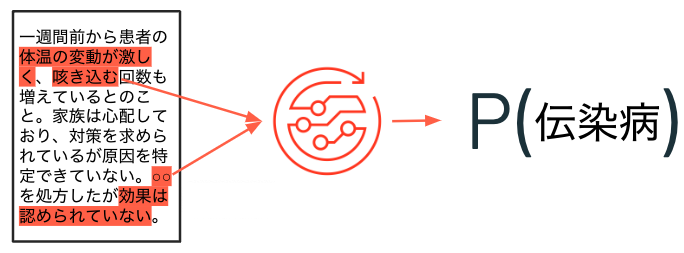
このような技術の進展によって、テキストデータを分析することで様々な価値を生み出すことができるようになっています。
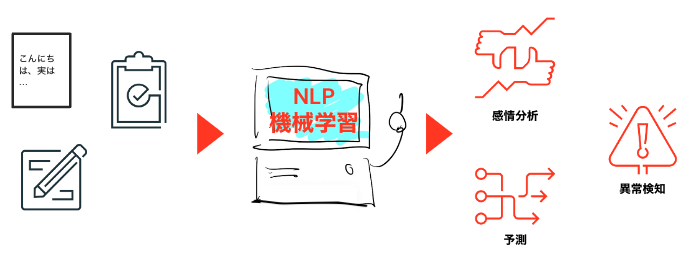
自然言語処理の要素技術
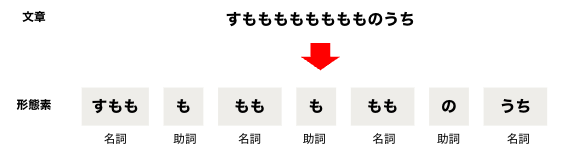
形態素解析
ある文章を入力とし、その文章に含まれる意味をもつ表現要素の最小単位(形態素) を特定します。これにより一連の文章を形態素に分解することができ、単語の数をカウントするなどコンピューターによる処理が容易になります。英語の場合、単語は空白で区切られていますが日本語はそうでないため、日本語の自然言語処理では形態素解析が重要な役割を担います。
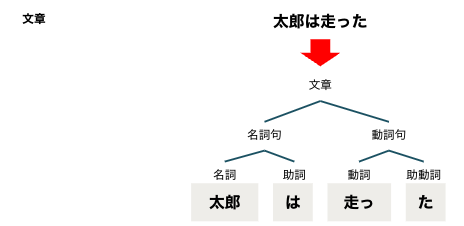
構文解析
ある文章を入力とし、文章に含まれる要素同士の関係性を解析します。係受け解析とも呼ばれます。
その他の技術
-
検索
単語あるいは自然文を入力とし、単語を含む文書や関連する文書を返却します。 -
テキスト分類
文書の類似性に基づいて文書をグルーピングします。 -
トピックモデリング
テキストのグループからトピックを表すキーワードを特定します。 -
文章要約
長い文章を数文に要約します。 -
機械翻訳
ある言語で記述されている文章を別の言語に翻訳します。 -
文章生成
複数の文章を学習するなどして、自動的に文章を生成します。
自然言語処理における課題
自然言語処理には特有の難しさがあります。
曖昧性の取り扱い
自然言語には読み手の解釈によって意味が異なる曖昧性が含まれており、コンピューターでの取り扱いには課題があります。
「絶対値が上がる」は「絶対値が上がる」なのか「絶対(に)値(段) が上がる」なのか?
新語への対応
コンピューターは勝手に新語を学ばないので何かしらの手段で新語を学習させる必要があります。
文脈の理解
同じ単語であっても、文脈によって意味が異なるケースがあります。

しかし、最近の技術の進歩によって、これらの課題にある程度対応できるようになってきています!
自然言語処理の適用事例
適切に自然言語を処理することで様々な価値を生み出すことができます。
アストラゼネカ

- 科学文献と膨大なデータソースに自然言語処理(NLP)を適用することで後段でのデータ分析に活用
- 研究者の意思決定に役立つ推薦モデルを構築
RIOT GAMES

- ゲーム中の不正な言葉をリアルタイムで検出して防止することで、チャット上の誹謗中傷によるコミュニティの悪化を回避
- 特に、同じ単語でも文脈によって意味合いが異なる複数言語の解析が必要であり、このような要件に応えるモデルの精緻化を実現
Medical University of South Carolina

- 患者のCOVID-19のリスクを特定するために600,000以上の遠隔医療レコードにNLPを適用
- 特定した高リスク患者に対して優先度を上げてCOVID-19の検査を実施
その他NLPでできることには、以下のようなものがあります。
検知
テキストの内容に基づいて、例えば、回避すべきイベントを検知し早期の対策を講じることができます。
チャットbot
製品・サービスに対する問い合わせに対する応答を自動化することができます。対象を音声にまで拡大すれば、Siriのような対話システムも構築することができます。
感情分析
製品・サービスに対するポジティブ・ネガティブな感情を分析することでフィードバックに活用することができます。
レコメンデーション
文書の内容に基づいて、関連する別の文書を提示することで、必要とする文書にクイックにアクセスすることができるようになります。
NLPのウォークスルー
ウェビナーで使用したノートブックにはこちらからアクセスできます。
以下では、こちらのノートブックの流れを説明します。
Sparkデータフレームを用いて形態素解析を行い、ワードクラウドで可視化するという内容となっています。
大量テキストデータに対する処理
Amazonの商品レビューのテキストデータを使用します。
https://s3.amazonaws.com/amazon-reviews-pds/tsv/index.txt
データ準備
初回のみ実行します。
file_path = "/FileStore/shared_uploads/takaaki.yayoi@databricks.com/amazon_reviews_multilingual_JP_v1_00.tsv.gz"
sdf = spark.read.format("csv").option("delimiter", "\t") \
.option("header", True) \
.load(file_path)
#display(sdf)
# データフレームをDeltaに保存します
path = f"/tmp/takaaki.yayoi@databricks.com/nlp/amazon_review.delta"
sdf.repartition(288).write.format('delta').mode("overwrite").option("path", path).saveAsTable("20210712_demo_takaakiyayoi.amazon_review")
ライブラリのインポート
import pandas as pd
from janome.tokenizer import Tokenizer
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import string
sdf = spark.table("20210712_demo_takaakiyayoi.amazon_review")
データ前処理
データには英語テキストも含まれているので、日本語のレビューに限定します。
from pyspark.sql.types import ArrayType, StringType, IntegerType, DoubleType
from pyspark.sql.functions import col
from pyspark.sql.functions import pandas_udf
from pyspark.sql.functions import udf
Apache Sparkを用いることで処理を並列分散することができます。Sparkのpandas UDF(User-defined Function:ユーザー定義関数)を活用して大量データに対する形態素解析処理を高速に処理します。
DatabricksにおけるSpark pandasユーザー定義関数 - Qiita
@pandas_udf(IntegerType())
def filter_by_ascii_rate(texts: pd.Series) -> pd.Series:
threshold = 0.9 # テキストの9割が英数字の場合は除外
ascii_letters = set(string.printable)
filtered = []
for text in texts:
if text is None:
filtered.append(0)
else:
rate = sum(c in ascii_letters for c in text) / len(text)
filtered.append(int(rate <= threshold))
return pd.Series(filtered)
# is_jpカラムの追加
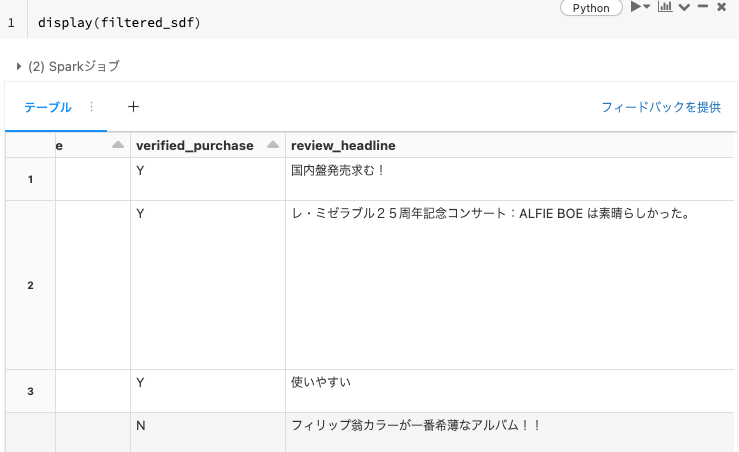
filtered_sdf = sdf.withColumn("is_jp", filter_by_ascii_rate(col("review_body"))).filter("is_jp == 1")
filtered_sdf.write.format("noop").mode("append").save()
display(filtered_sdf)
形態素解析
janomeを使って形態素解析を行い、分かち書きを行います。
@pandas_udf(ArrayType(StringType()))
def tokenize_base_form(texts: pd.Series) -> pd.Series:
from janome.tokenizer import Tokenizer
t = Tokenizer()
tokenized = []
for text in texts:
# 全てのトークンを抽出
#tokens = [token.base_form for token in t.tokenize(text)]
#tokenized.append(tokens)
# 一般名詞のみを抽出
noun_list = []
for token in t.tokenize(text):
split_token = token.part_of_speech.split(',')
#and split_token[1] == '一般'
if split_token[0] == '名詞' and len(token.surface) > 1:
noun_list.append(token.surface)
tokenized.append(noun_list)
return pd.Series(tokenized)
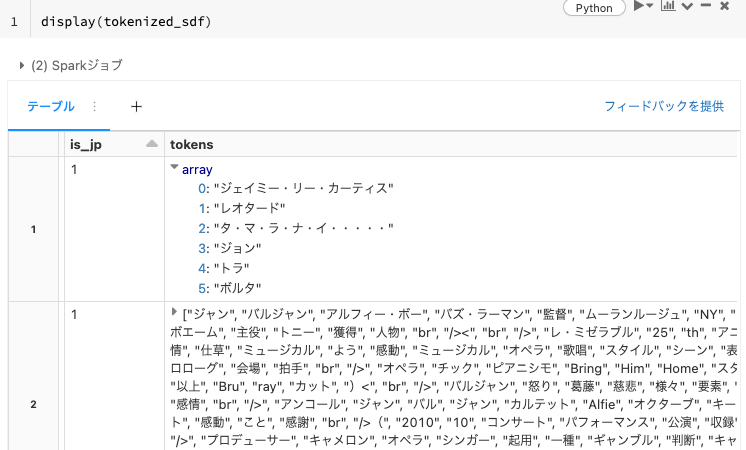
tokenized_sdf = filtered_sdf.withColumn("tokens", tokenize_base_form(col("review_body")))
tokenized_sdf.write.format("noop").mode("append").save()
display(tokenized_sdf)
可視化
ワードクラウドで可視化します。
def depict_word_cloud(noun_list):
## 名詞リストの要素を空白区切りにする(word_cloudの仕様)
noun_space = ' '.join(map(str, noun_list))
## word cloudの設定(フォントの設定)
wc = WordCloud(background_color="white", font_path=r"/usr/share/fonts/truetype/fonts-japanese-gothic.ttf", width=300,height=300)
wc.generate(noun_space)
## 出力画像の大きさの指定
plt.figure(figsize=(5,5))
## 目盛りの削除
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False,
length=0)
## word cloudの表示
plt.imshow(wc)
plt.show()
noun_list = tokenized_sdf.take(10)
display(noun_list)
for i in range(len(noun_list)):
depict_word_cloud(noun_list[i]['tokens'])

NLPの最新技術動向
これは一部ですが日々新たな技術が生まれています。
scikit-learn
最新技術ではないですが、最初に使い始めるのには適していると思います。
Word2vec
Word2vecは、2013年にGoogleの研究者トマス・ミコロフ氏によって提案された手法です。単語の意味ベクトルを得ることで、単語の意味を考慮した処理が可能となります。
BERT(Bidirectional Encoder Representations from Transformers)
2018年にGoogleから発表されたニューラル言語モデルです。事前学習済みモデルをファインチューニングすることで様々な自然言語処理タスクで高い精度を発揮しています。日本語向けのモデルも公開されています。
Spark NLP
Spark向けNLPライブラリです。John Snow Labsによって提供されています。日本語にも対応しています。
BigARTM
新たなトピックモデリングの手法です。
さいごに
ウェビナーで参照した、あるいは関連する記事を以下に示します。DatabricksでのNLPに興味がある方はこちらの記事もご覧になってください。
- Databricks SparkでMeCabを動かしてみる
- 無料のDatabricks Community EditionでSpark NLPを使って自然言語処理をやってみる
- Databricksで日本語ワードクラウドを作成する
- 日本語に対してSpark NLPを使う
- LDAの先へ:BigARTMによる最先端のトピックモデル
- Spark NLPとSpark MLLib(LDA)を用いた分散トピックモデリング
- DatabricksでSparkNLPとMLLibを使って分散トピックモデリングをやってみる
- DatabricksでSparkNLPとMLLibを使って分散トピックモデリングをやってみる(日本語編)
- Apache Spark向け自然言語処理ライブラリのご紹介
- NLPを用いた薬害イベント検知による薬品安全性の改善
- ヘルスケアにおける大規模テキストデータへの自然言語処理の適用
- 自然言語処理によるリアルワールド診療データからのオンコロジー(腫瘍学)に関する洞察の抽出
その他の「今さら聞けない」シリーズ