以前、matplotlibで日本語の表示に苦戦したのと同じような状況になりました。
Databricksのクラスターにはデフォルトで日本語フォントが入っていないので、当然ですが日本語のワードクラウドを表示しようとすると文字化けします。
以下の手順で日本語のワードクラウドを表示することができました。
日本語フォントのインストール
initスクリプトの作成
Databricksクラスターに日本語フォントをインストールするinitスクリプトを準備します。
Python
# init script格納ディレクトリの作成
dbutils.fs.mkdirs("dbfs:/databricks/scripts/")
Python
# init scriptの作成
dbutils.fs.put("/databricks/scripts/japanese-font-install.sh","""
#!/bin/bash
apt-get install fonts-takao-mincho fonts-takao-gothic fonts-takao-pgothic -y""", True)
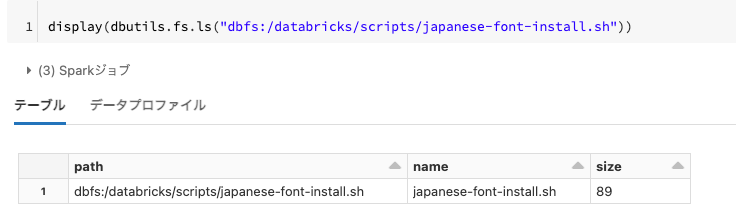
initスクリプトが作成されたことを確認します。
Python
display(dbutils.fs.ls("dbfs:/databricks/scripts/japanese-font-install.sh"))
クラスターのinitスクリプトの設定
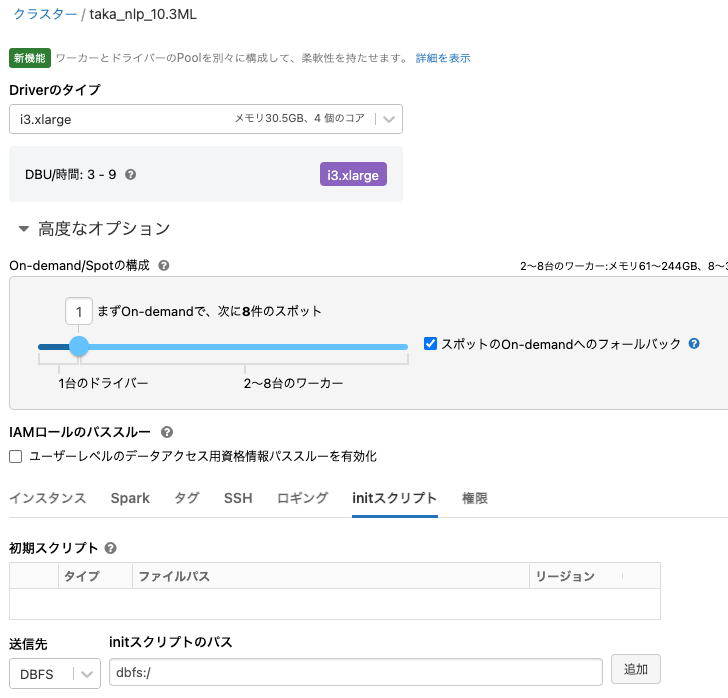
クラスター起動時に、上のステップで作成したinitスクリプトを読み込むように設定します。
- クラスターの詳細画面に移動します。編集ボタンをクリックします。
- 高度なオプションを展開します。
-
initスクリプトタブをクリックします。
- initスクリプトのパスに上で作成したinitスクリプトのパスを入力します。この場合は、
dbfs:/databricks/scripts/japanese-font-install.shと入力し、追加ボタンをクリックします。
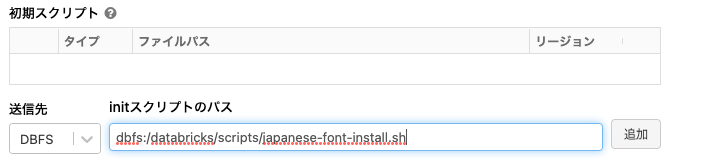
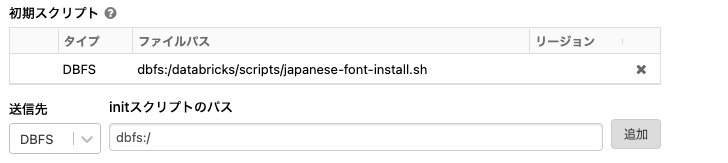
- 画面上部の確認して再起動ボタンをクリックします。
日本語ワードクラウドの作成
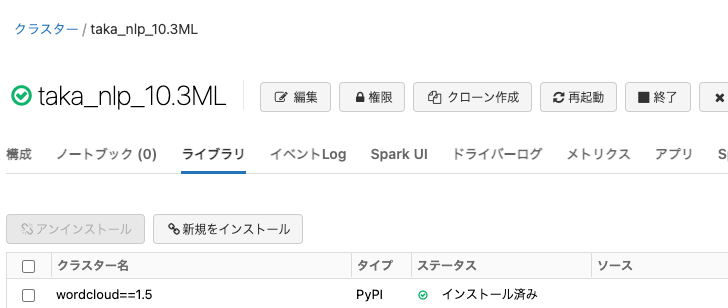
wordcloudのライブラリをインストールします。クラスターライブラリとしてインストールしておけば、クラスターが起動するたびに%pip install wordcloudを実行する必要がないので楽です。
ライブラリをインポートします。
Python
import matplotlib.pyplot as plt
from wordcloud import WordCloud
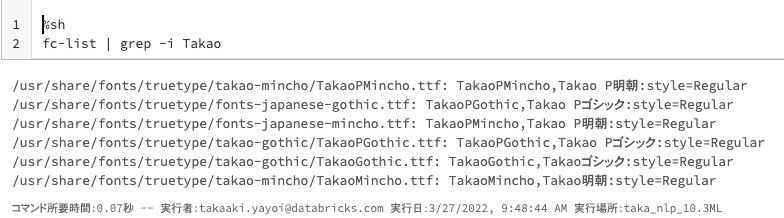
日本語フォントがインストールされていることを確認します。
Shell
%sh
fc-list | grep -i Takao
単語のリストを引数としてワードクラウドを表示する関数を作成します。こちらの記事の関数を引用させていただきました。上のフォントファイルパスをfont_pathに指定します。
Python
def depict_word_cloud(noun_list):
## 名詞リストの要素を空白区切りにする(word_cloudの仕様)
noun_space = ' '.join(map(str, noun_list))
## word cloudの設定(フォントの設定)
wc = WordCloud(background_color="white", font_path=r"/usr/share/fonts/truetype/fonts-japanese-gothic.ttf", width=300,height=300)
wc.generate(noun_space)
## 出力画像の大きさの指定
plt.figure(figsize=(5,5))
## 目盛りの削除
plt.tick_params(labelbottom=False,
labelleft=False,
labelright=False,
labeltop=False,
length=0)
## word cloudの表示
plt.imshow(wc)
plt.show()
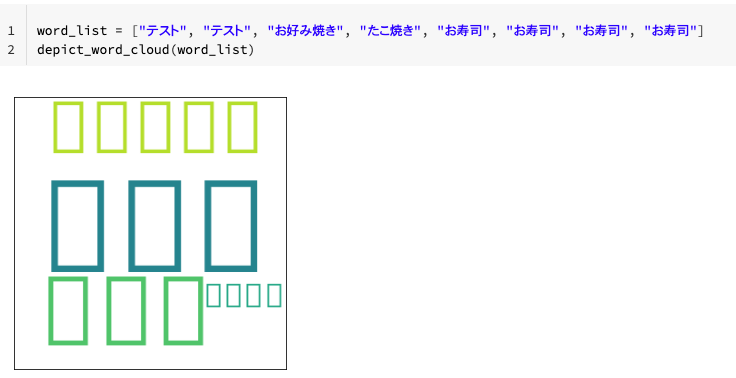
再度ワードクラウドを表示してみます。
Python
word_list = ["テスト", "テスト", "お好み焼き", "たこ焼き", "お寿司", "お寿司", "お寿司", "お寿司"]
depict_word_cloud(word_list)
無事に日本語ワードクラウドが表示されました。テキストデータを対象としたEDA(探索的データ分析)ではワードクラウドは有効だと思います。
