こちらで紹介しているノートブックはこちらです。
絶賛Spark NLPの勉強中なのですが以下の記事が非常にわかりやすかったので、Databricksで試してみました。
クラスターの設定
MLLibを使うので機械学習ランタイムを使用します。また、Spark NLPを使う際には、pypiからのライブラリのインストールとMaven経由でのライブラリのインストールが必要です。pypiからはノートブック上でインストールしているのですが、Maven経由ではクラスターライブラリとしてインストールしています。両方ともクラスターライブラリとしてインストールすることも可能です。
ライブラリのバージョンはクラスターのSparkバージョンに依存するので、こちらで確認してください。
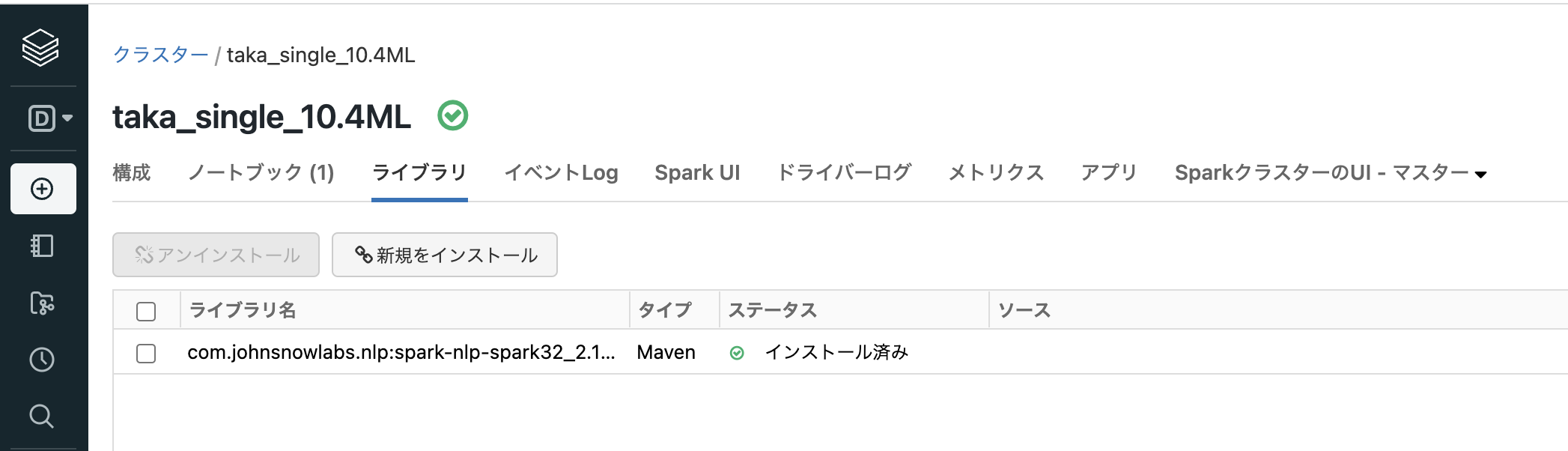
例えば、Sparkのバージョンが3.2.xである場合には、com.johnsnowlabs.nlp:spark-nlp-spark32_2.12:3.4.4をインストールします。
ライブラリをインストール後に、以下のように「インストール済み」になっていることを確認します。
ライブラリのインストール&インポート
# Install PySpark and Spark NLP
%pip install -q pyspark==3.1.2 spark-nlp
# Install Spark NLP Display lib
%pip install --upgrade -q spark-nlp-display
# Spark NLPのインポート
from sparknlp.base import *
from sparknlp.annotator import *
from sparknlp.pretrained import PretrainedPipeline
import sparknlp
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
データのロード
- こちらからCSVファイルをダウンロードします。
- サイドメニューのデータをクリックし、アップロードボタンをクリックします。
- アップロードするパスを選択して、CSVファイルをドラッグ&ドロップします。
以下の例では、下のパスにアップロードしています。
dbfs:/FileStore/shared_uploads/takaaki.yayoi@databricks.com/news/abcnews_date_text.csv
file_location = "dbfs:/FileStore/shared_uploads/takaaki.yayoi@databricks.com/news/abcnews_date_text.csv"
file_type = "csv"
# CSVのオプション
infer_schema = "true"
first_row_is_header = "true"
delimiter = ","
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
# レコード数の確認
df.count()

display(df)
データは記事の発行日とヘッドラインから構成されています。

Spark NLPを用いた前処理パイプライン
Spark NLPでもMLLibと同じように処理のパイプラインを構築することができます。
# Spark NLPはドキュメントに変換する入力データフレームあるいはカラムが必要です
document_assembler = DocumentAssembler() \
.setInputCol("headline_text") \
.setOutputCol("document") \
.setCleanupMode("shrink")
# 文をトークンに分割(array)
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
# 不要な文字やゴミを除外
normalizer = Normalizer() \
.setInputCols(["token"]) \
.setOutputCol("normalized")
# ストップワードの除外
stopwords_cleaner = StopWordsCleaner()\
.setInputCols("normalized")\
.setOutputCol("cleanTokens")\
.setCaseSensitive(False)
# 原型にするための単語のステミング
stemmer = Stemmer() \
.setInputCols(["cleanTokens"]) \
.setOutputCol("stem")
# Finisherは最も重要なアノテーターです。Spark NLPはデータフレームの各行をドキュメントに変換する際に自身の構造を追加します。Finisherは期待される構造、すなわち、トークンの配列に戻す助けをしてくれます。
finisher = Finisher() \
.setInputCols(["stem"]) \
.setOutputCols(["tokens"]) \
.setOutputAsArray(True) \
.setCleanAnnotations(False)
# それぞれのフェーズが順番に実行されるようにパイプラインを構築します。このパイプラインはモデルのテストにも使うことができます。
nlp_pipeline = Pipeline(
stages=[document_assembler,
tokenizer,
normalizer,
stopwords_cleaner,
stemmer,
finisher])
# パイプラインのトレーニング
nlp_model = nlp_pipeline.fit(df)
# データフレームを変換するためにパイプラインを適用します。
processed_df = nlp_model.transform(df)
# NLPパイプラインは我々にとって不要な中間カラムを作成します。なので、必要なカラムのみを選択します。
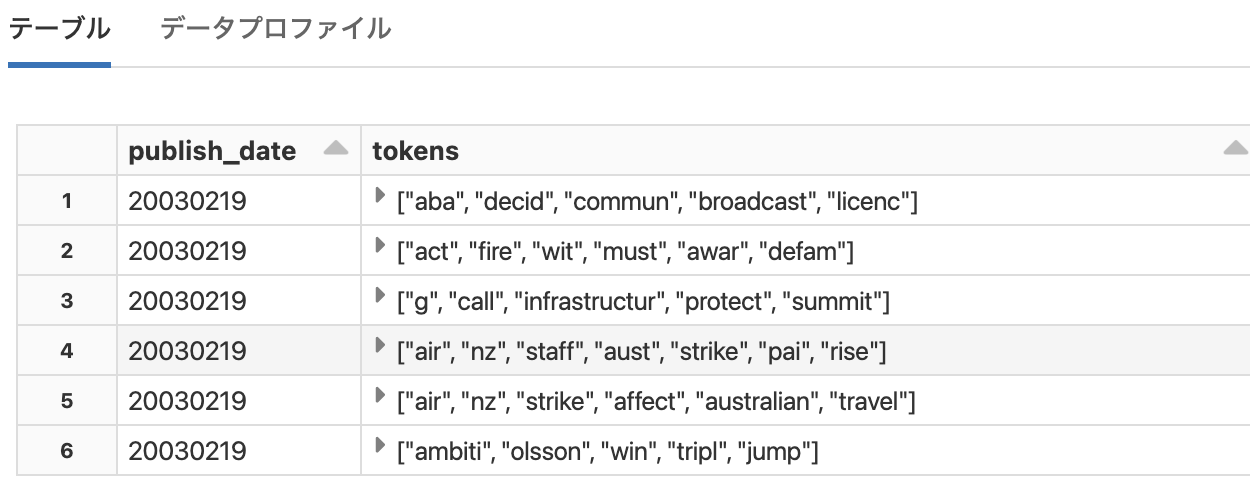
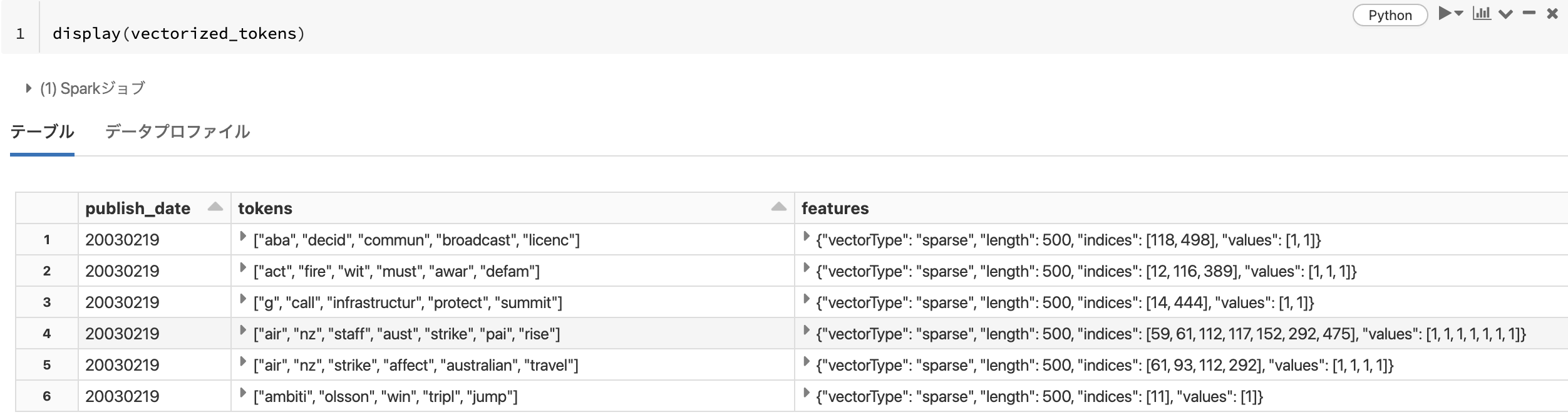
tokens_df = processed_df.select('publish_date','tokens').limit(10000)
display(tokens_df)
これで文がトークンに分割されましたので、特徴量エンジニアリングに進むことができます。
特徴量エンジニアリング
単語の出現頻度を特徴量にするCountVectorizerを使います。要件に応じてTF/IDFなどを使うことも可能です。
from pyspark.ml.feature import CountVectorizer
cv = CountVectorizer(inputCol="tokens", outputCol="features", vocabSize=500, minDF=3.0)
# モデルのトレーニング
cv_model = cv.fit(tokens_df)
# データを変換します。出力カラムが特徴量となります。
vectorized_tokens = cv_model.transform(tokens_df)
LDAモデルの構築
from pyspark.ml.clustering import LDA
num_topics = 3
lda = LDA(k=num_topics, maxIter=10)
model = lda.fit(vectorized_tokens)
ll = model.logLikelihood(vectorized_tokens)
lp = model.logPerplexity(vectorized_tokens)
print("The lower bound on the log likelihood of the entire corpus: " + str(ll))
print("The upper bound on perplexity: " + str(lp))
トピックの可視化
# CountVectorizerからボキャブラリーを抽出
vocab = cv_model.vocabulary
topics = model.describeTopics()
topics_rdd = topics.rdd
topics_words = topics_rdd\
.map(lambda row: row['termIndices'])\
.map(lambda idx_list: [vocab[idx] for idx in idx_list])\
.collect()
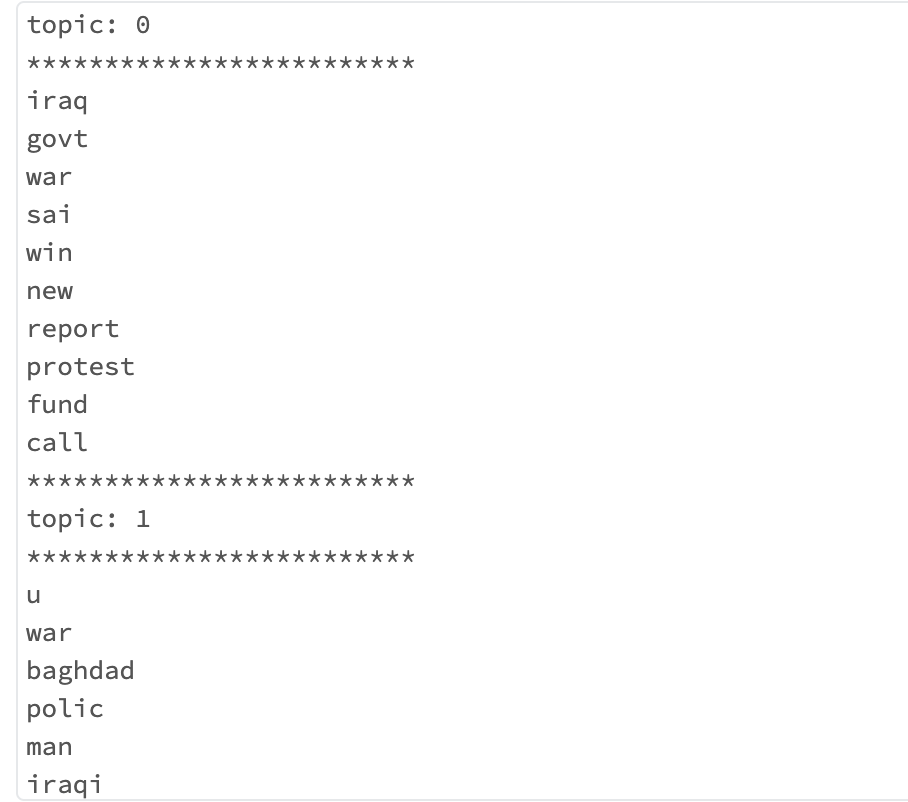
for idx, topic in enumerate(topics_words):
print("topic: {}".format(idx))
print("*"*25)
for word in topic:
print(word)
print("*"*25)
次は日本語にトライしてみます。