Databricksを使い始めて約1年経ちますが、日本語の自然言語処理に手を出していなかったと思い立ちましてトライしました。単にMeCabをインストールするだけではなく、Sparkの並列分散処理を活用できるようにするところまでをまとめました。
MeCabのインストール
まず、DatabricksクラスターにMeCabがインストールされるように、initスクリプトを作成して設定します。
initスクリプトの作成
以下を実行して/dbfs/databricks/scripts/mecab_init_script.shにinitスクリプトを出力します。
import os
file_init="/dbfs/databricks/scripts/mecab_init_script.sh"
with open(file_init,"wt") as f1:
f1.write("""#!/bin/bash
yes | apt-get install mecab
yes | apt-get install libmecab-dev
yes | apt-get install mecab-ipadic-utf8
yes | apt-get install swig
# using neologd
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
echo "dicdir = "`mecab-config --dicdir`"/mecab-ipadic-neologd" > "/usr/local/etc/mecabrc"
""")
initスクリプトの設定
使用するDatabricksクラスターのConfigurationを開き、Advanced optionsのInit Scriptsタブで上で作成したinitスクリプトのパスを設定します。
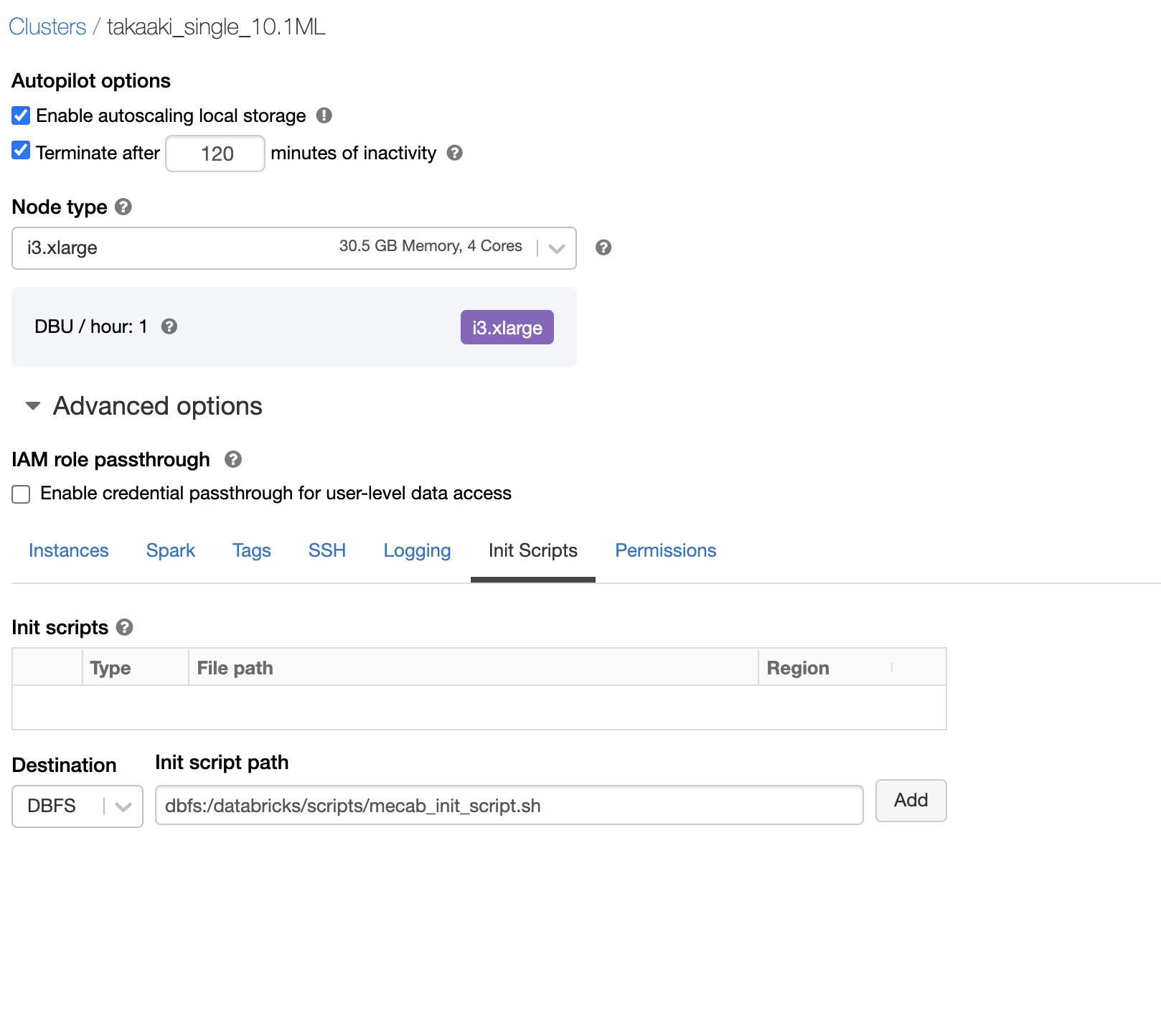
以下のようになります。
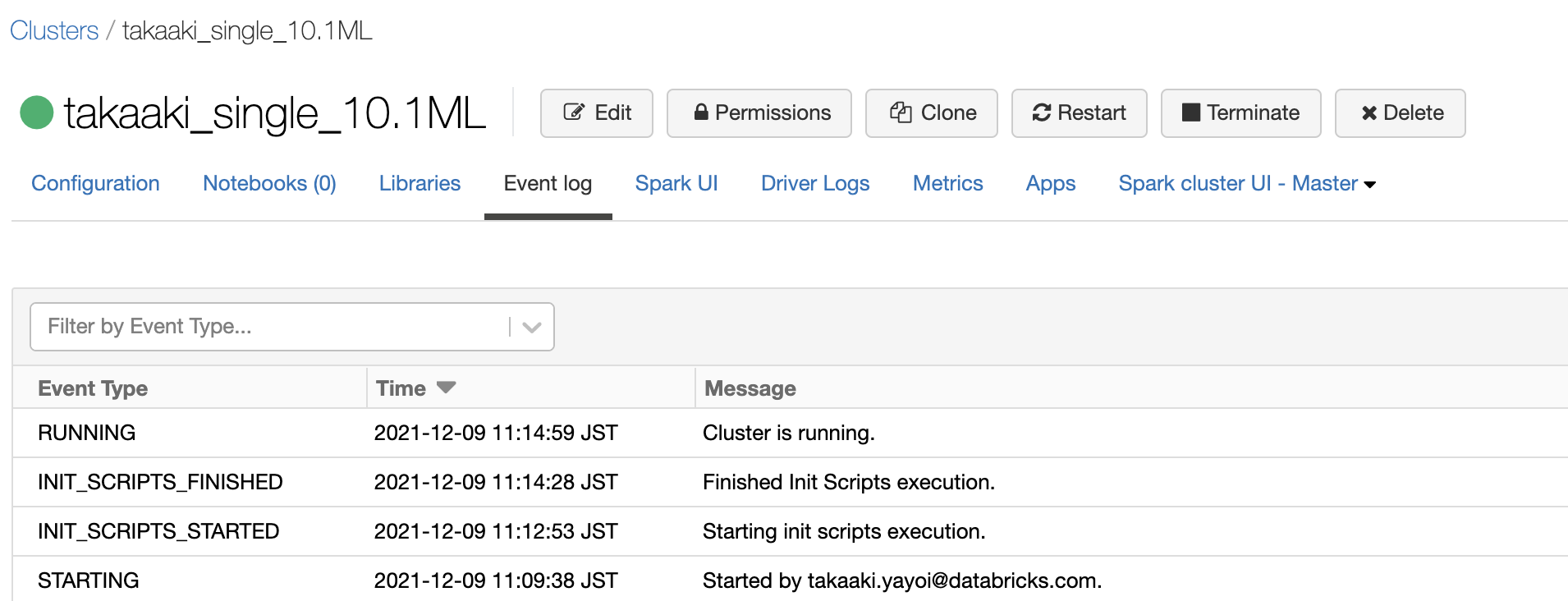
クラスターを起動して、initスクリプトの処理が完了してクラスターが起動することを確認します。
MeCab Pythonラッパーのインストール
クラスターライブラリとして以下のライブラリをインストールします。
- DatabricksクラスターのLibrariesを開き、Install newをクリックします。
- 以下のようにLibrary SourceでPyPIを選択し、Packageに
mecab-python3と入力し、Installをクリックします。

- ライブラリがインストールされたことを確認します。

MeCabの動作確認
Databricksノートブックで、以下のセルを実行して形態素解析が行われることを確認します。
import MeCab
mecab = MeCab.Tagger("-Ochasen")
print(mecab.parse("今日はいい天気ですね。"))
今日 キョウ 今日 名詞-副詞可能
は ハ は 助詞-係助詞
いい イイ いい 形容詞-自立 形容詞・イイ 基本形
天気 テンキ 天気 名詞-一般
です デス です 助動詞 特殊・デス 基本形
ね ネ ね 助詞-終助詞
。 。 。 記号-句点
EOS
追加辞書の利用
追加辞書の動作確認は以下のように行います。
mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
print(mecab.parse("今日はいい天気ですね。"))
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ
天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ
。 記号,句点,*,*,*,*,。,。,。
EOS
ユーザー定義辞書の作成
こちらを参考にさせていただいています。Databricksでは設定の追加、記述方法の変更が必要です。
-
まず、作成するユーザー定義辞書をポイントするようにMecab設定ファイルへのパスを環境変数に定義します。クラスターの高度なオプションを展開し、環境変数に
MECABRC=/etc/mecabrcを追加します。 -
ノートブック上で以下の処理を行います。ドライバーノードでシェルを実行するためにマジックコマンド
%shを追加します。なお、シェルのデフォルトパスは/databricks/driver/となります。%sh echo '"形態素解析は面白い",-1,-1,1,名詞,一般,*,*,*,*,*,*,*,mydic"' > user_dic.csv%sh /usr/lib/mecab/mecab-dict-index -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd -u user_dic.dic -f utf-8 -t utf-8 user_dic.csv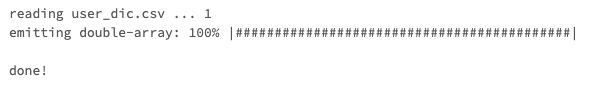
-
ユーザー辞書へのパスをMecab設定ファイルに追記します。
%sh echo "userdic = /databricks/driver/user_dic.dic" >> /etc/mecabrc cat /etc/mecabrc
-
動作確認します。
Pythonimport MeCab text = '形態素解析は面白いのテスト' tagger = MeCab.Tagger("-Ochasen") result = tagger.parse(text) print(result)辞書で定義された単語が抽出できていることが確認できます。

ダミーデータの準備
次に上の形態素解析処理をSparkのUDF(ユーザー定義関数)で実行できるようにします。最初に処理対象のダミーデータを作成します。
# sqlモジュールからPySparkのRowクラスをインポート
from pyspark.sql import *
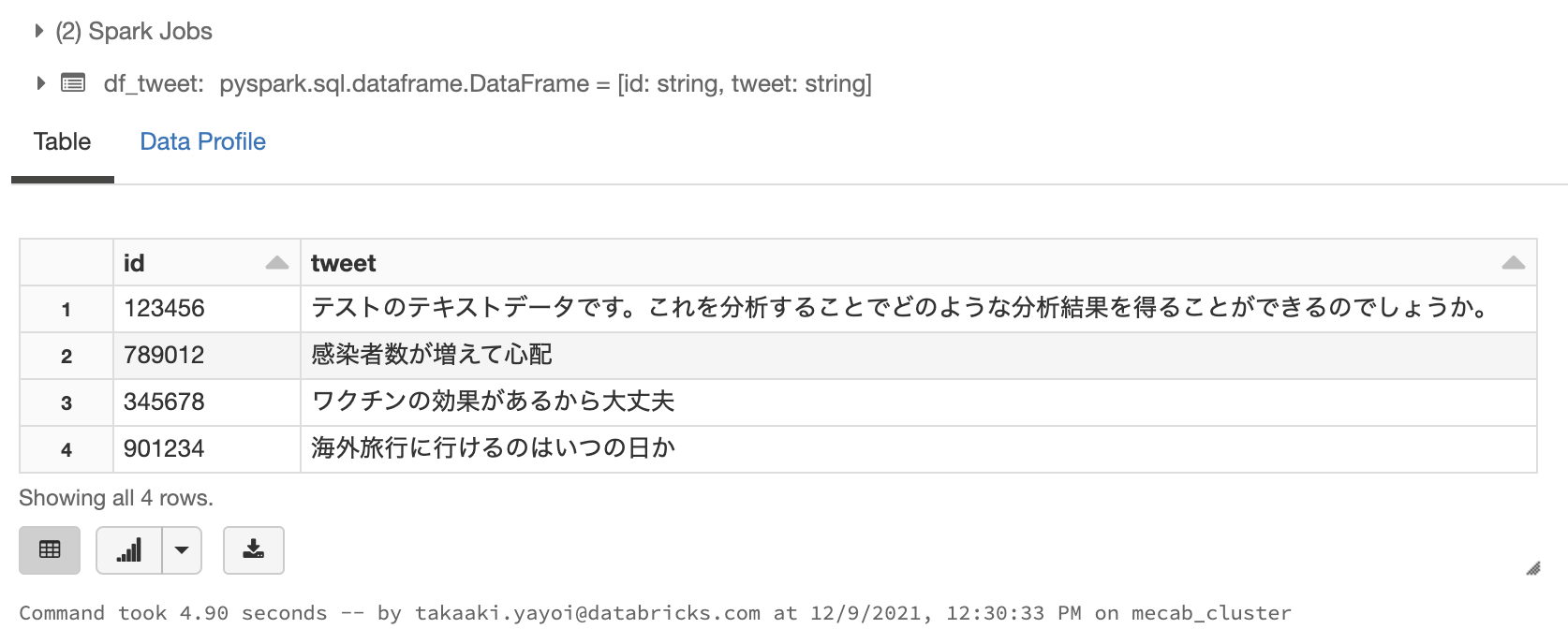
tweet1 = Row(id='123456', tweet='テストのテキストデータです。これを分析することでどのような分析結果を得ることができるのでしょうか。')
tweet2 = Row(id='789012', tweet='感染者数が増えて心配')
tweet3 = Row(id='345678', tweet='ワクチンの効果があるから大丈夫')
tweet4 = Row(id='901234', tweet='海外旅行に行けるのはいつの日か')
tweets = [tweet1, tweet2, tweet3, tweet4]
df_tweet = spark.createDataFrame(tweets)
display(df_tweet)
Spark UDFの定義
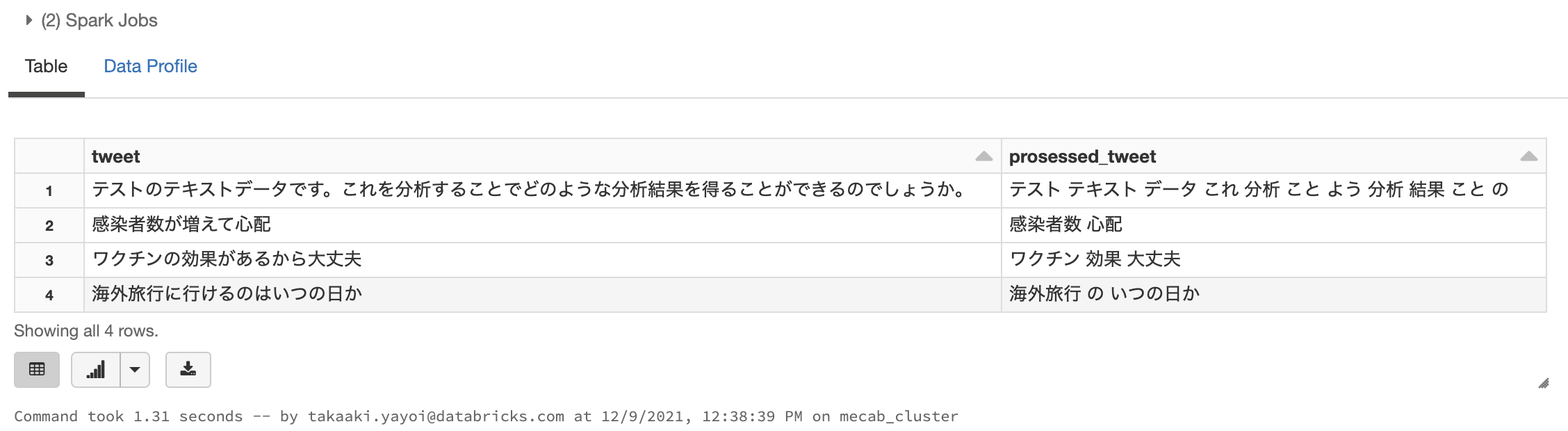
ここでは、MeCabを用いて形態素解析を行い、抽出した名詞を半角スペースで連結した文字列を返却する関数を定義し、Spark UDFとして登録します。
def extract_words(text: str) -> str:
"""
名詞のみを抽出するUDF
:param text: Pyspark/SQLのカラム
:return: 名詞を半角スペースで連結した文字列
"""
word_str = ""
mecab = MeCab.Tagger("-Ochasen")
mecab.parseToNode('')
node = mecab.parseToNode(text)
while node:
# 名詞のみを抽出
if node.feature.split(",")[0] == "名詞":
word = node.surface
word_str = word_str + " " + word
node = node.next
return word_str
# Spark UDFとして関数を登録
spark.udf.register("extract_words", extract_words)
処理の実行
関数をSpark UDFとして登録することで、SQLを用いて容易に形態素解析を行うことが可能となります。
# 上で作成したデータフレームを一時ビューとして登録
df_tweet.createOrReplaceTempView('tweets')
%sql
SELECT tweet, extract_words(tweet) AS prosessed_tweet FROM tweets;
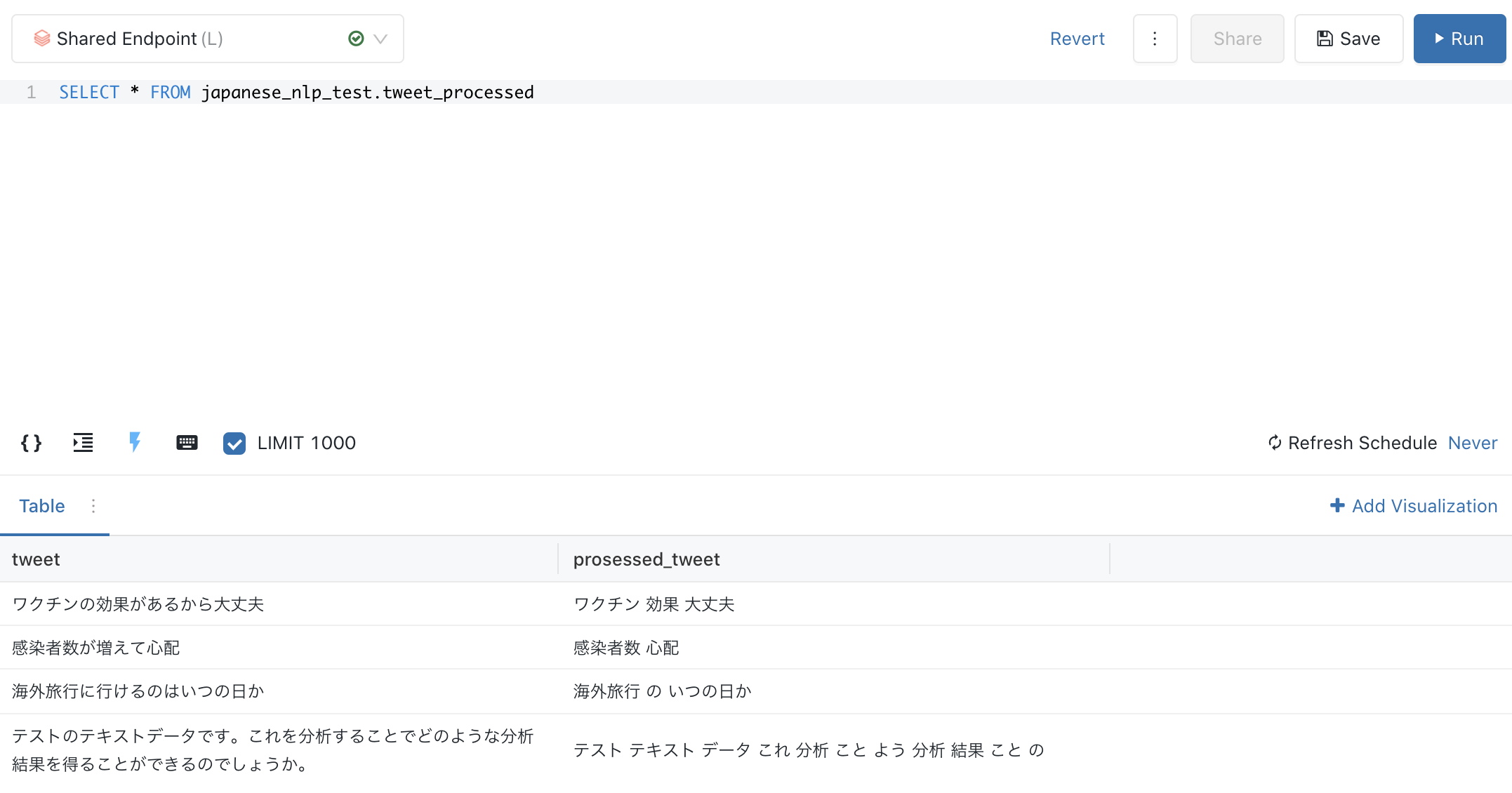
おまけ:ワードクラウドによる可視化
テーブルを永続化することで、Databricks SQLでデータの可視化を行うことができます。先ほど処理した半角スペース区切りの文字列をワードクラウドの入力に指定することで、キーワードの出現頻度に基づくワードクラウドを作成することができます。
%sql
CREATE DATABASE IF NOT EXISTS japanese_nlp_test
CREATE OR REPLACE TABLE japanese_nlp_test.tweet_processed
AS
SELECT tweet, extract_words(tweet) AS prosessed_tweet FROM tweets;

サンプルノートブック
参考資料
- PythonとMeCabで文章を解析する方法【頻出度カウント】 |
- Azure DatabricksでPythonとMeCabを使う - Qiita
- Azure DatabricksでMeCabを使う | Nature Insight ネイチャーインサイト株式会社
- PySparkで日本語形態素解析 | フライウィール