オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
2020年をおさらい!オレオレ深層学習論文ベスト10!
もう2020年も終わりますね。いかがお過ごしでしょうか。私は今年を積極的にアウトプットしていく年にしていたので、深層学習の論文を可能な限り読みました(それでも略読含めて150本程度だと思いますが...)。僭越ながら、今年2020年に読んだ論文たちの中から独断と偏見に基づいて面白かった論文を10個ランキング形式にてまとめます。2020年に読んだ論文なので必ずしも2020年に発表された論文とは限りません。完全なるオレオレランキングなので画像系多めです。簡単な説明に加え論文、解説記事、実装へのリンクをそれぞれに載せましたので興味ある論文があれば是非読んでみてください!それでは第10位から早速見ていきましょう!
【第10位】: "Mish: A Self Regularized Non-Monotonic Activation Function", Misra, D., BMVC2020
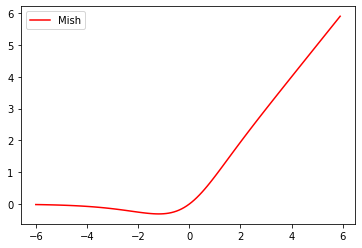
まず第10位は、新たな活性化関数Mishです。Mishは$f(x)=x\text{tanh}(\text{softplus}(x))$で定義されます。ちなみに$\text{softplus}(x)=\log(1+e^x)$です。ReLUやSwishよりも高い性能をしっかりと示しています。余談ですが、著者のDiganta Misraさんが私の記事に関するツイートに返信してきたのが個人的ニュースになっています。
| 項目 | リンク |
|---|---|
| 原論文 | "Mish: A Self Regularized Non-Monotonic Activation Function", Misra, D., (BMVC2020) |
| 解説記事(拙著) | ついに誕生!期待の新しい活性化関数「Mish」解説 |
| 公式実装 | MXNet/TensorFlow/PyTorch |
【第9位】: "AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty", Hendrycks, D., ICLR2020
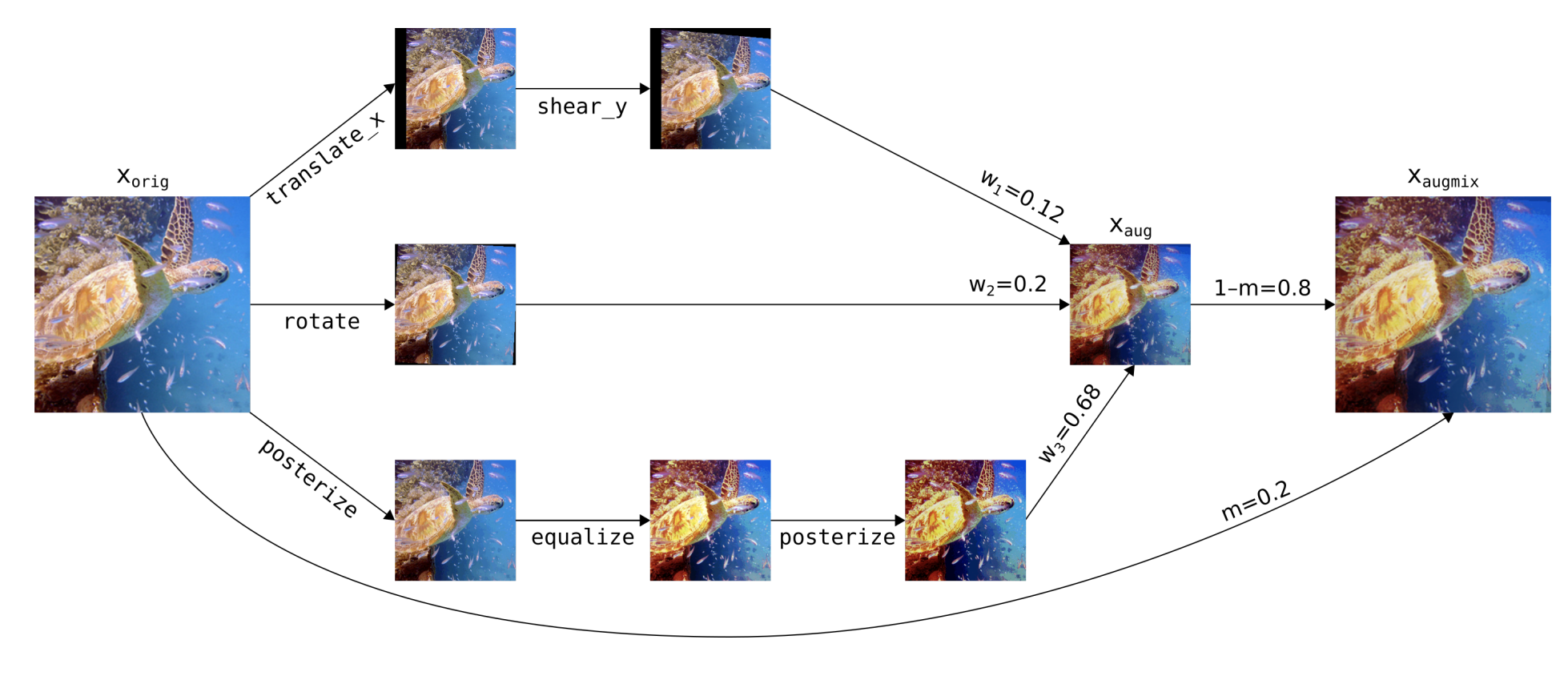
続いて第9位は、モデルのロバスト性を爆発的に向上させるデータオーギュメンテーションAugMixです。複数のデーターギュメンテーションを別々で適用し最後にそれらを凸結合するという手法で性能を向上させています。余談ですが、第一著者のDan Hendrycksさんはロバスト性の論文でよく見かけるすごい人です。
【第8位】: "A Simple Framework for Contrastive Learning of Visual Representations", Chen, T., ICML2020
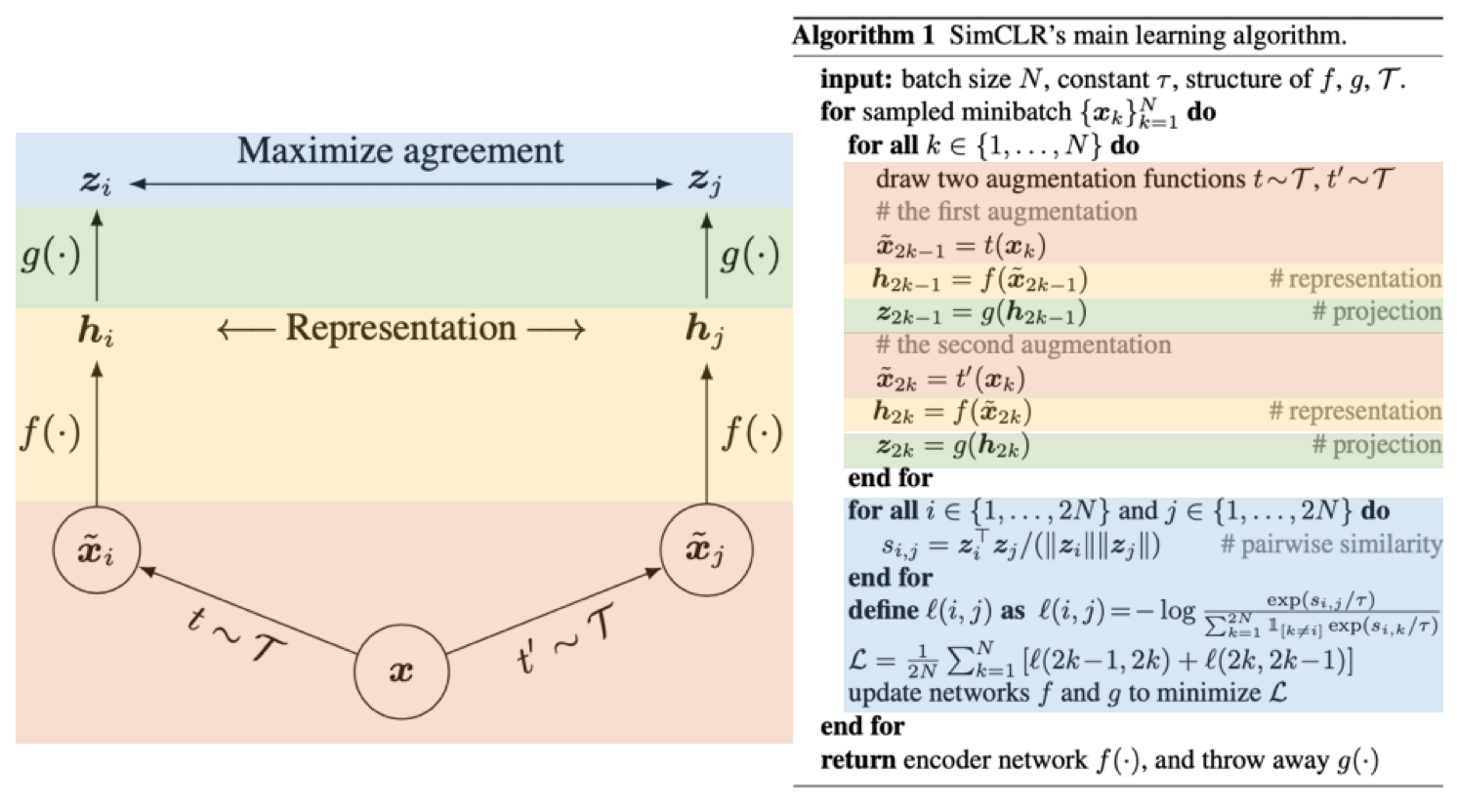
画像: "A Simple Framework for Contrastive Learning of Visual Representations", Chen, T., ICML2020, 改変
第8位に登場するのは、今年の自己教師あり学習(SSL)の立役者の1人であるSimCLRです。End-to-Endなフレームワークで一気にSSLの性能を引き上げました。ImageNetの1%のラベルのみで85.8%Top-5精度を獲得するという驚異的な性能です。余談ですが、共著にあのGeoffrey Hintonさんも名を連ねてます。
【第7位】: "On the Variance of the Adaptive Learning Rate and Beyond", Liu, L., ICLR2020

第7位には、Adamを超えたオプティマイザーとして注目を浴びたRAdamが登場です。Adamではステップサイズが適応的に決まりますが、学習初期では適応的に決まるステップサイズが物凄い大きな値になりうることを指摘しそこを直しています。結果として、幅広いタスクでAdamを超える性能を示しました。余談ですが、この研究はMicrosoftへのインターンシップ中に行ったということでとてもすごいと思いました。
【第6位】: "Funnel Activation for Visual Recognition", Ma, N., ECCV2020
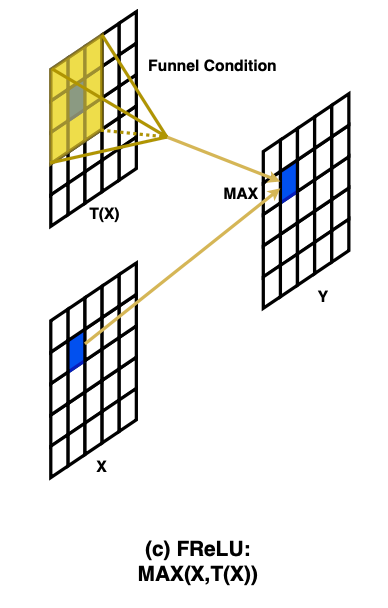
画像: "Funnel Activation for Visual Recognition", Ma, N., ECCV2020
そして第6位は、画像特化の活性化関数としてFReLUです。FReLUは$f(x)=\text{max}(x, \text{DW}(x))$で定義されます。ここで$\text{DW}(\cdot)$はDepthwise畳み込みのことです。Depthwise畳み込みを使っていることからもFReLUは入力がベクトルの活性化関数となっていることがわかりますね。画像特化というのも面白いです。余談ですが、著者の方は質問に即レスしてくれたので印象が良いです。
| 項目 | リンク |
|---|---|
| 原論文 | "Funnel Activation for Visual Recognition", Ma, N., Zhang, X., Sun, J., (ECCV2020) |
| 解説記事(拙著) | 新たな活性化関数「FReLU」誕生&解説! |
| 公式実装 | MegEngine(PyTorchによる再実装は拙著記事に掲載) |
【第5位】: Consistency Regularization for Generative Adversarial Networks", Zhang, H., ICLR2020
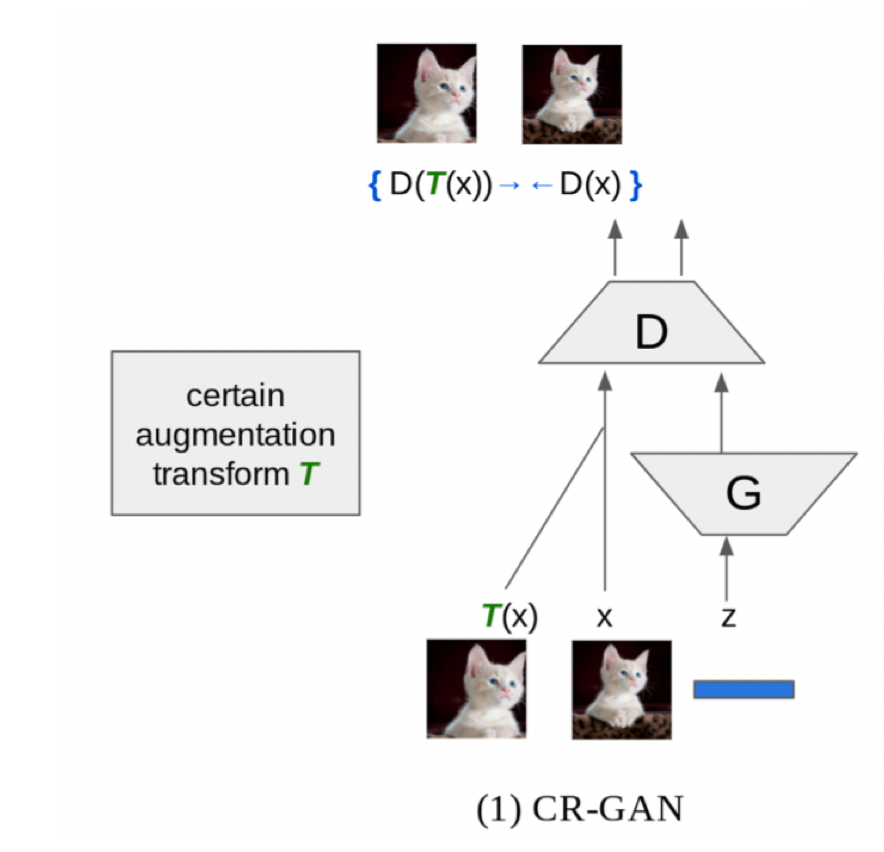
画像: Consistency Regularization for Generative Adversarial Networks", Zhang, H., ICLR2020
第5位は、GANへの新たな正則化としてConsistency Regularizationを追加したCR-GANです。画像にデータオーギュメンテーションが適用されていてもDiscriminatorの出力は元画像と同じであるべき、という制約を損失関数にねじ込んでいます。Discriminatorによる元画像とDA後画像への出力の間で二乗誤差を取るだけです。これをさらに発展させたbCR-GANなども提案されています。この簡単な仕組みによってGANの性能を大きく向上させています。余談ですが、個人的に愛用しています。
| 項目 | リンク |
|---|---|
| 原論文 | "Consistency Regularization for Generative Adversarial Networks", Zhang, H., Zhang, Z., Odena, A., Lee, H., (ICLR2020) |
| 解説記事(拙著) | GANへの新しい正則化「ICR」が期待大な件&解説 |
| 公式実装 | なし (単なる二乗誤差なので実装は簡単) |
【第4位】: "CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features", Yun, S., ICCV2019
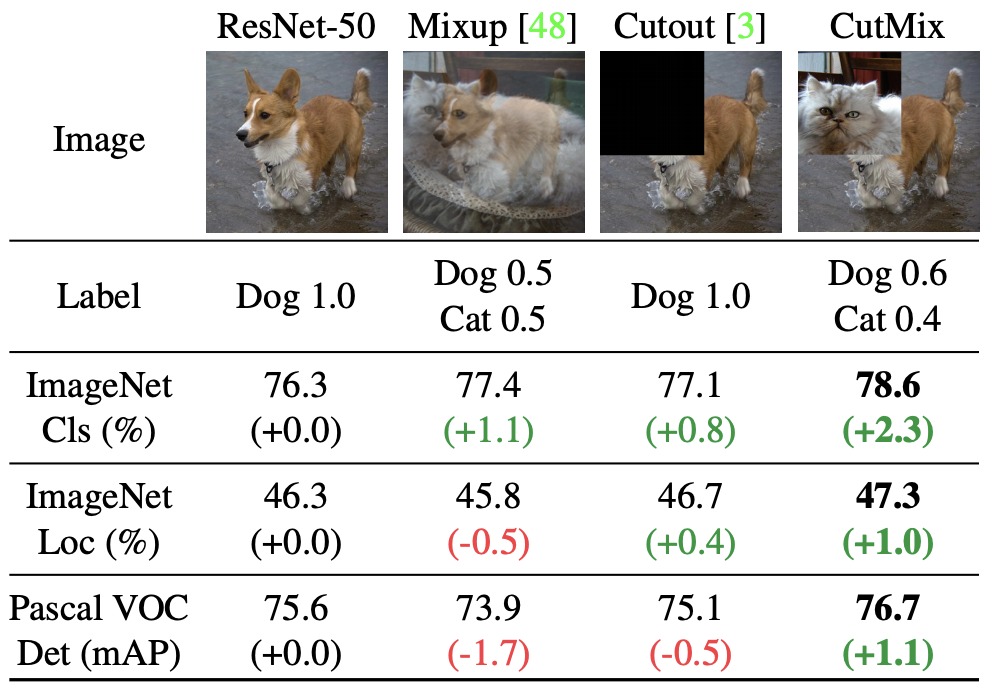
第4位は、新たなデータオーギュメンテーション手法CutMixです。2019年のものですが、今年読んだのでランキングに入れました。手法は、画像の一部を別の画像に貼り付けるだけです。この時のラベルは2枚の画像同士の面積比に従ったソフトラベルになります。とても単純な手法であるにもかかわらず超絶強力です。オススメです。余談ですが、この論文の共著にある韓国のYonsei大学は映画パラサイトの監督やTWICE/NiziUの生みの親の出身大学です。頭がとてもいいです。
【第3位】: "Exploring Self-attention for Image Recognition", Zhao, H., CVPR2020
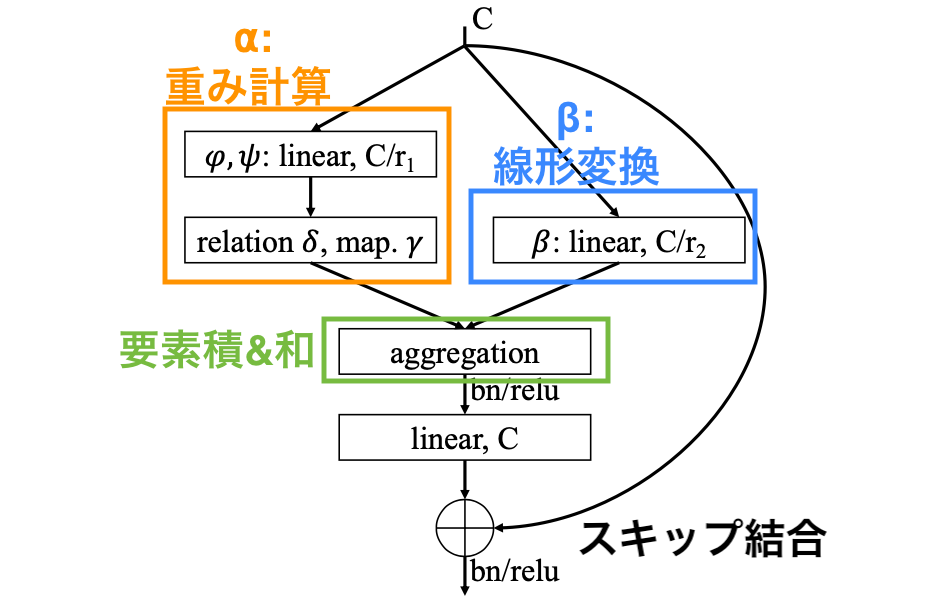
それでは第3位。第3位は、畳み込みをSelf-Attentionに置き換えることで畳み込みよりも高い性能を示した論文です。自然言語でSelf-AttentionがRNNをさようならしたみたいに画像でもSelf-Attentionが畳み込みをさようならしてしまうのではないかと驚きました。その驚きから第3位にランクインです。余談ですが、この論文を読んでSelf-Attentionへの理解が一気に深まりました。
| 項目 | リンク |
|---|---|
| 原論文 | "Exploring Self-attention for Image Recognition", Zhao, H., Jia, J., Koltun, V., (CVPR2020) |
| 解説記事(拙著) | Self-Attentionを全面的に使った新時代の画像認識モデルを解説! |
| 公式実装 | PyTorch |
【第2位】: "Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains", Pinkney, J., NeurIPS2020 Workshop
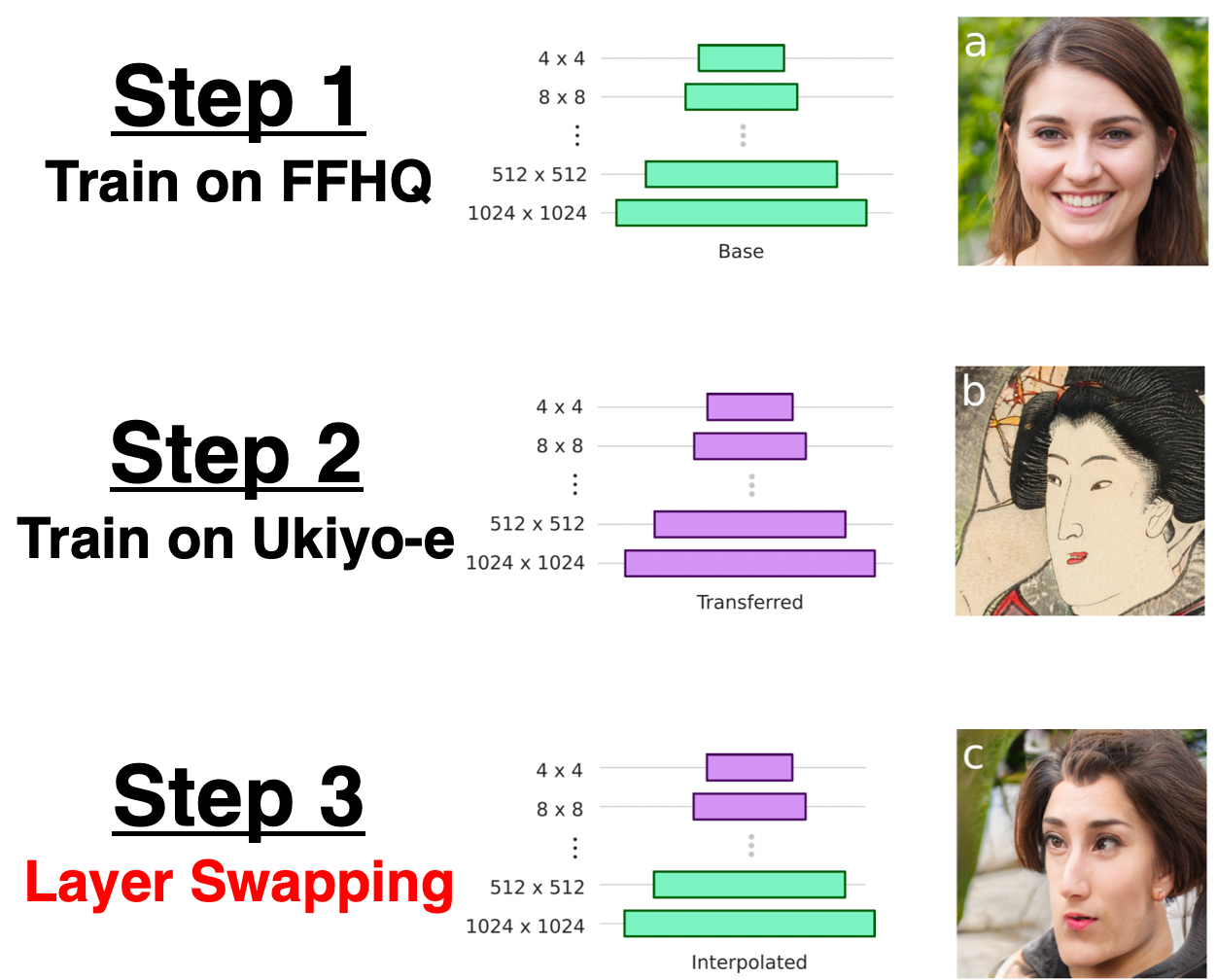
ついに第2位は、顔をディズニー顔に変換するToonify Yourself!の仕組みをその作者が教えてくれている論文です。学習済みStyleGANの層の一部を他の学習済みStyleGANの層と交換するLayer Swappingを行うだけで、面白い画像が生成できます。単純な手法であるにもかかわらず、非常に高クオリティな画像たちが生成されており論文を読んでいても楽しかったです。余談ですが、論文中には安倍前首相のディズニー顔も載っています。
【第1位】: "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale", Dosovitskiy, A., arXiv 2020

そして映えある第1位は、Vision Transformer、通称ViTを提案した論文です。Transformerが遂に画像認識でもSoTAを達成してしまいました。しかも既存のSoTAモデルよりも$\frac{1}{5} \sim \frac{1}{4}$の計算量で。Transformer(Self-Attention)が画像認識にもやってくるのは時間の問題ではありましたが、やっぱり実際に来ると驚きですね。ICLR2021のOpenReviewではReviewerたちからも高い評価を得ておりacceptはほぼ間違いないでしょう。余談ですが、ViT-Hというモデルは計算量が既存モデルよりも少ないと言っても学習にTPU-v3で2,500日かかります。依然ヤバすぎます。
最後に
オレオレランキング2020をまとめてみました。2020年は「自己教師あり学習の台頭」と「畳み込みのSelf-Attentionによる置き換え」の2つが個人的には特に印象的でした。他にもMishやFReLUなどの新しい活性化関数、RAdamやランキングには入りませんでしたがAdaBeliefなどの新しいオプティマイザーが誕生し、面白い論文をたくさん読むことができた2020年でした。来たる2021年は、一体どういったことでワクワクさせてくれるのでしょうか。とても楽しみです。すごく余談ですが、この1年私の記事を読んで反応をくださる皆さんのおかげで稚拙ながらも無事に記事を書き続けることができました。大変感謝しております。そして2021年もよろしくお願いします!良いお年を!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ: