オミータです。ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽に@omiita_atiimoをフォローしてください!
自然言語処理の王様「BERT」の論文を徹底解説
2018年10月に登場して、自然言語処理でもとうとう人間を超える精度を叩き出した ことで大きな話題となったBERT。それ以降、XLNetやALBERT、DistillBERTなどBERTをベースにしたモデルが次々と登場してはSoTAを更新し続けています。その結果、GLUEベンチマークでは人間の能力が12位(2020年5月4日時点)に位置しています。BERTは登場してまだ1年半程度であるにもかかわらず、被引用数は2020年5月4日現在で4809 にも及びます。驚異的です。この記事ではそんなBERTの論文を徹底的に解説していきたいと思います。BERTの理解にはTransformer[Vaswani, A. (2017)]を理解しているととても簡単です。Transformerに関しての記事は拙著の 解説記事 をどうぞ。BERTは公式によるTensorFlowの実装とPyTorchを使用している方にはHuggingFaceによる実装がありますのでそちらも参照してみてください。
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
流れ:
- 忙しい方へ
- 論文解説
- まとめと所感
- 参考
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
0.忙しい方へ
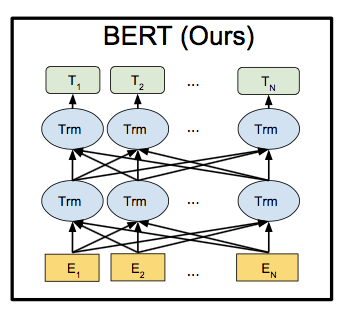
- BERTはTransformerのEncoderを使ったモデルだよ。
- あらゆるNLPタスクにファインチューニング可能なモデルだから話題になったよ。
- 事前学習としてMLM(=Masked Language Modeling)とNSP(Next Sentence Prediction)を学習させることで爆発的に精度向上したよ。
- 事前学習には長い文章を含むデータセットを用いたよ。
- 11個のタスクで圧倒的SoTA を当時叩き出したよ。
1. 論文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding解説
1.0 要約
BERTは Bidirectional Encoder Representations from Transformers の略で、TransformerのEncoderを使っているモデル。BERTはラベルのついていない文章から表現を事前学習するように作られたもので、出力層を付け加えるだけで簡単にファインチューニングが可能。
NLPタスク11個でSoTA を達成し、大幅にスコアを塗り替えた。
1.1 導入
自然言語処理タスクにおいて、精度向上には言語モデルによる事前学習が有効である。この言語モデルによる事前学習には「特徴量ベース」と「ファインチューニング」の2つの方法がある。まず、「特徴量ベース」とは 事前学習で得られた表現ベクトルを特徴量の1つとして用いるもの で、タスクごとにアーキテクチャを定義する。ELMo[Peters, (2018)]がこの例である。また、「ファインチューニング」は 事前学習によって得られたパラメータを重みの初期値として学習させるもの で、タスクごとでパラメータを変える必要があまりない。例として OpenAI GPT[Radford, (2018)]がある。ただし、いずれもある問題がある。それは事前学習に用いる言語モデルの方向が1方向だけということだ。例えば、GPTは左から右の方向にしか学習せず、文章タスクやQ&Aなどの前後の文脈が大事なものでは有効ではない。
そこで、この論文では 「ファインチューニングによる事前学習」に注力 し、精度向上を行なう。具体的には事前学習に以下の2つを用いる。
- Masked Language Model(= MLM)
- Next Sentence Prediction(= NSP)
それぞれ、
- MLM: 複数箇所が穴になっている文章のトークン(単語)予測
- NSP: 2文が渡され、連続した文かどうか判定
この論文のコントリビューションは以下である。
- 両方向の事前学習の重要性を示す
- 事前学習によりタスクごとにアーキテクチャを考える必要が減る
- BERTが11個のNLPタスクにおいてSoTAを達成
1.2 関連研究
ここでは自然言語における事前学習について触れていく。
1.2.1 教師なし特徴量ベースの手法
事前学習である単語の埋め込みによってモデルの精度を大幅に上げることができ、現在のNLPにとっては必要不可欠な存在となっている。
単語の埋め込み表現を獲得するには、主に次の2つがある。
- 文章の左から右の方向での言語モデル
- 左右の文脈から単語が正しいか誤っているかを識別するもの
また、文の埋め込み表現においては次の3つがある。
- 次に続く文をランキング形式で予測するもの
- 次に来る文を生成するもの
- denoisingオートエンコーダー由来のもの
さらに、文脈をしっかりとらえて単語の埋め込み表現を獲得するものにELMoがある。
これは「左から右」および「右から左」の両方向での埋め込みを用いることで精度を大きく上げた。
1.2.2 教師なしファインチューニングの手法
特徴量ベースと同じく、初めは文中の単語の埋め込みを行うことで事前学習の重みを獲得していたが、近年は文脈を考慮した埋め込みを行なったあとに教師ありの下流タスクにファインチューニングしていくものが増えている。これらの例として次のようなものがある。
- 文章の左から右の方向での言語モデル
- オートエンコーダー
1.2.3 教師ありデータによる転移学習
画像認識の分野ではImageNetなどの教師ありデータを用いた事前学習が有効ではあるが、自然言語処理においても有効な例がある。教師あり事前学習として用いられているものに以下のようなものがある。
- 機械翻訳
- 自然言語推論(= 前提と仮説の文のペアが渡され、それらが正しいか矛盾しているか判別するタスク)
1.3 BERT
ここではBERTの概要を述べたのちに深堀りをしていく。
1.3.1 BERTの概要
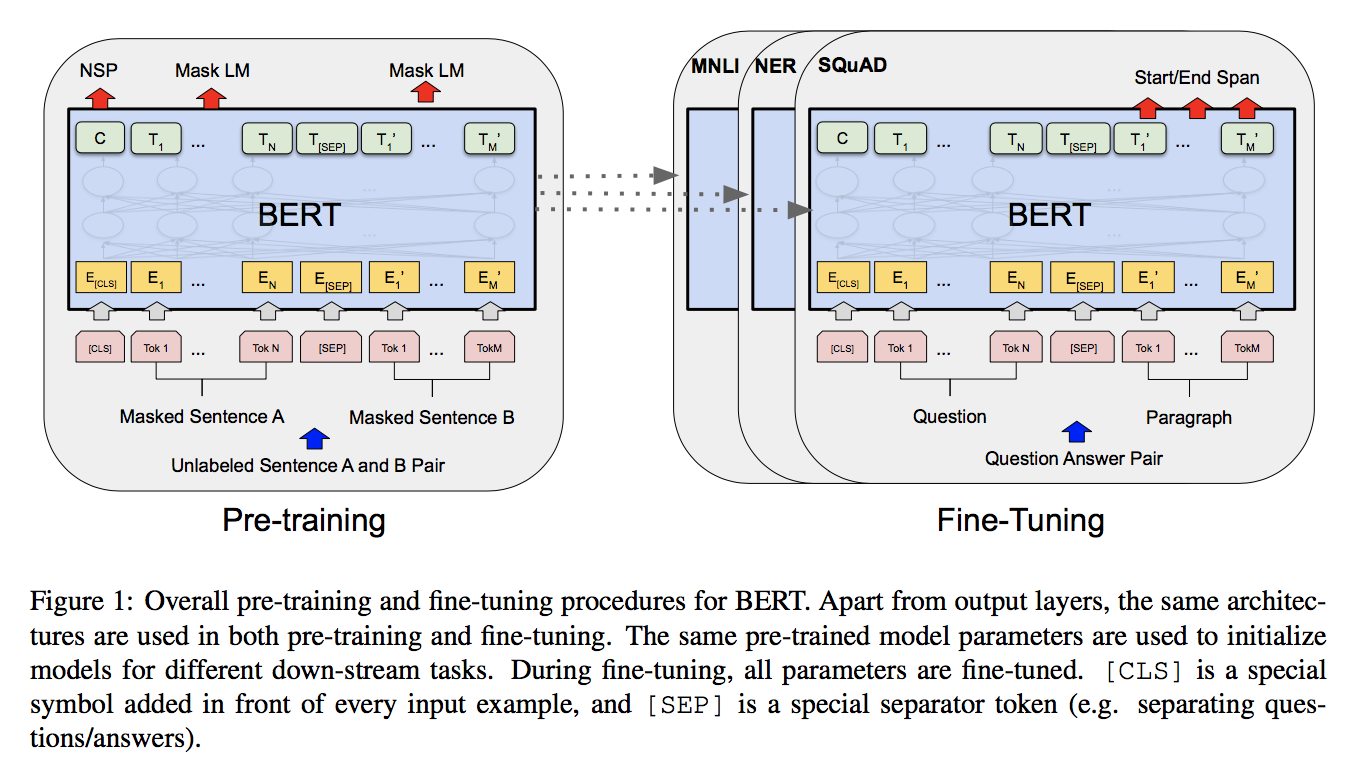
まず、BERTの学習には以下の2段階がある。
- 事前学習: ラベルなしデータを用いて、複数のタスクで事前学習を行う
- ファインチューニング: 事前学習の重みを初期値として、ラベルありデータでファインチューニングを行なう。
例としてQ&Aタスクを図で表すと次のようになる。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
異なるタスクにおいてもアーキテクチャが統一されている というのが、BERTの特徴である。
-
アーキテクチャ: Transformerのエンコーダーのみ。
- $\mathrm{BERT_{BASE}}$ ($L=12, H=768, A=12$, パラメータ数:1.1億)
- $\mathrm{BERT_{LARGE}}$ ($L=24, H=1024, A=16$, パラメータ数:3.4億)
- $L$:Transformerブロックの数, $H$:隠れ層のサイズ, $A$:self-attentionヘッドの数
-
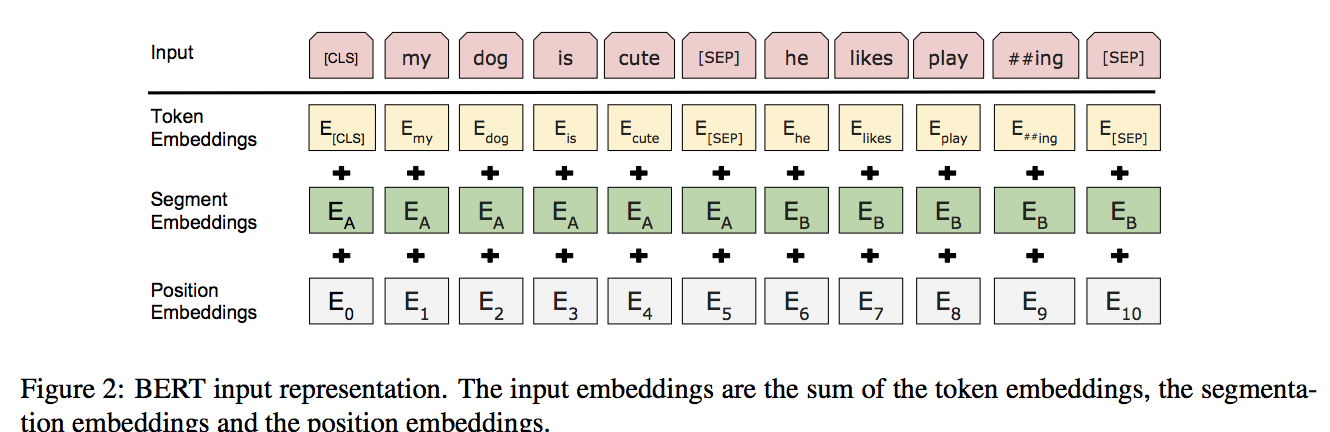
入出力: タスクによって1つの文(Ex.感情分析)、または2つの文をつなげたもの(Ex.Q&A)
- BERTへの入力を以下、sentenceと呼ぶ。
- sentenceの先頭に[CLS]トークンを持たせる。
- 2文をくっつける時は、間に[SEP]トークンを入れ かつ それぞれに1文目か2文目かを表す埋め込み表現を加算 する。
- 最終的に入力文は以下のようになる。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
- $E$:入力の埋め込み表現, $C$:[CLS]トークンの隠れベクトル, $T_i$:sentenceの$i$番目のトークンの隠れベクトル
1.3.2 BERTの事前学習
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
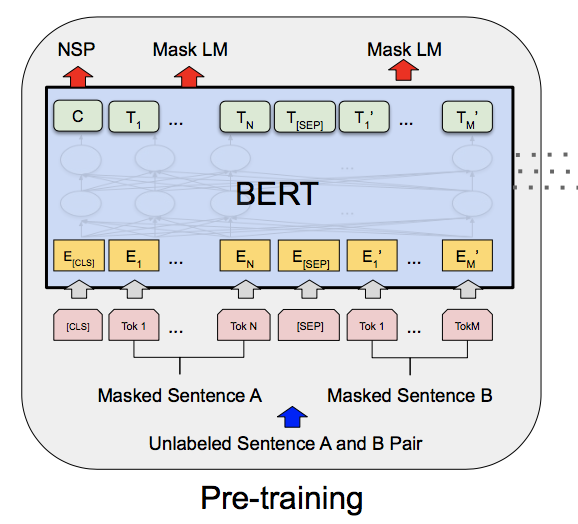
文を両方向(「左から右」および「右から左」)で学ぶためにBERTでは2つの事前学習を行なう。それがMLMとNSPである。データセットにはBooksCorpus(単語数:8億)とEnglish Wikipedia(単語数:25億)
-
Task1: Masked Language Modeling (MLM)
入力の15%のトークンを[Mask]トークンでマスクし、元のトークンを当てるタスク。つまり、穴埋め問題。この時、上図の$T_i$にSoftmaxを適用することでトークンを予測する。
ただし、ファインチューニングでは出てこない[Mask]トークンを事前学習で使用してしまっているために事前学習とファインチューニング間の差異が生じてしまう。そのため、マスクするトークンを常に[Mask]トークンに置き換えるのではなく、マスクするトークンに対して次のようにすることで問題を緩和 した。
| 確率(%) | 処理 |
|---|---|
| 80 | [Mask]トークンで置き換える |
| 10 | ランダムに選んだトークンで置き換える |
| 10 | そのままにする |
-
Task2: Next Sentence Prediction (NSP)
Q&Aや自然言語推論など文同士の関係を考慮する必要がある問題に対して、MLMでは対処できない。そのため、2文選んでそれらが連続した文かどうかを当てるタスク を行なう。
この時、上図の$C$を用いて予測を行なう。
(ここで、$C$はこの時点ではNSPに特化したものなので、文全体を表現したベクトルにはなっていない。)
1.3.3 BERTのファインチューニング
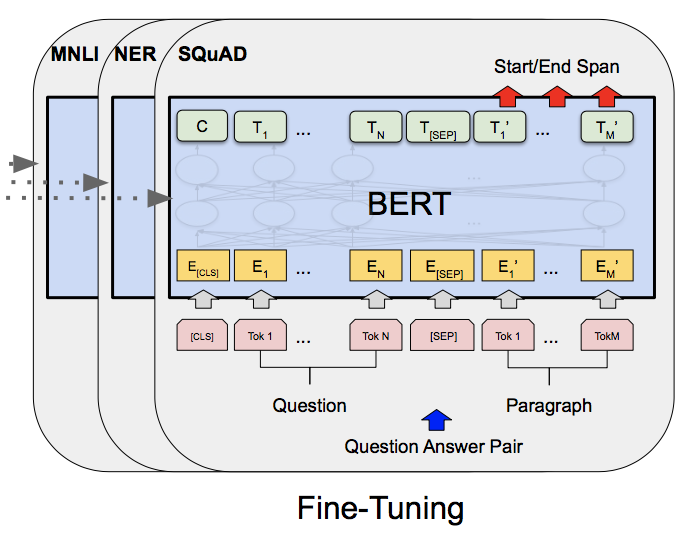
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
単純にタスクごとに入力するだけ。
出力のうち $C$は識別タスク(Ex.感情分析) に使われ、$T_i$はトークンレベルのタスク(Ex.Q&A) に使われる。
ファインチューニングは事前学習よりも学習が軽く、どのタスクもCloud TPUを1個使用すれば1時間以内 で終わった。(GPU1個でも2~3時間程度)
(ただし、事前学習にはTPU4つ使用でも4日もかかる。)
他のファインチューニングの例は以下の図のようになる。
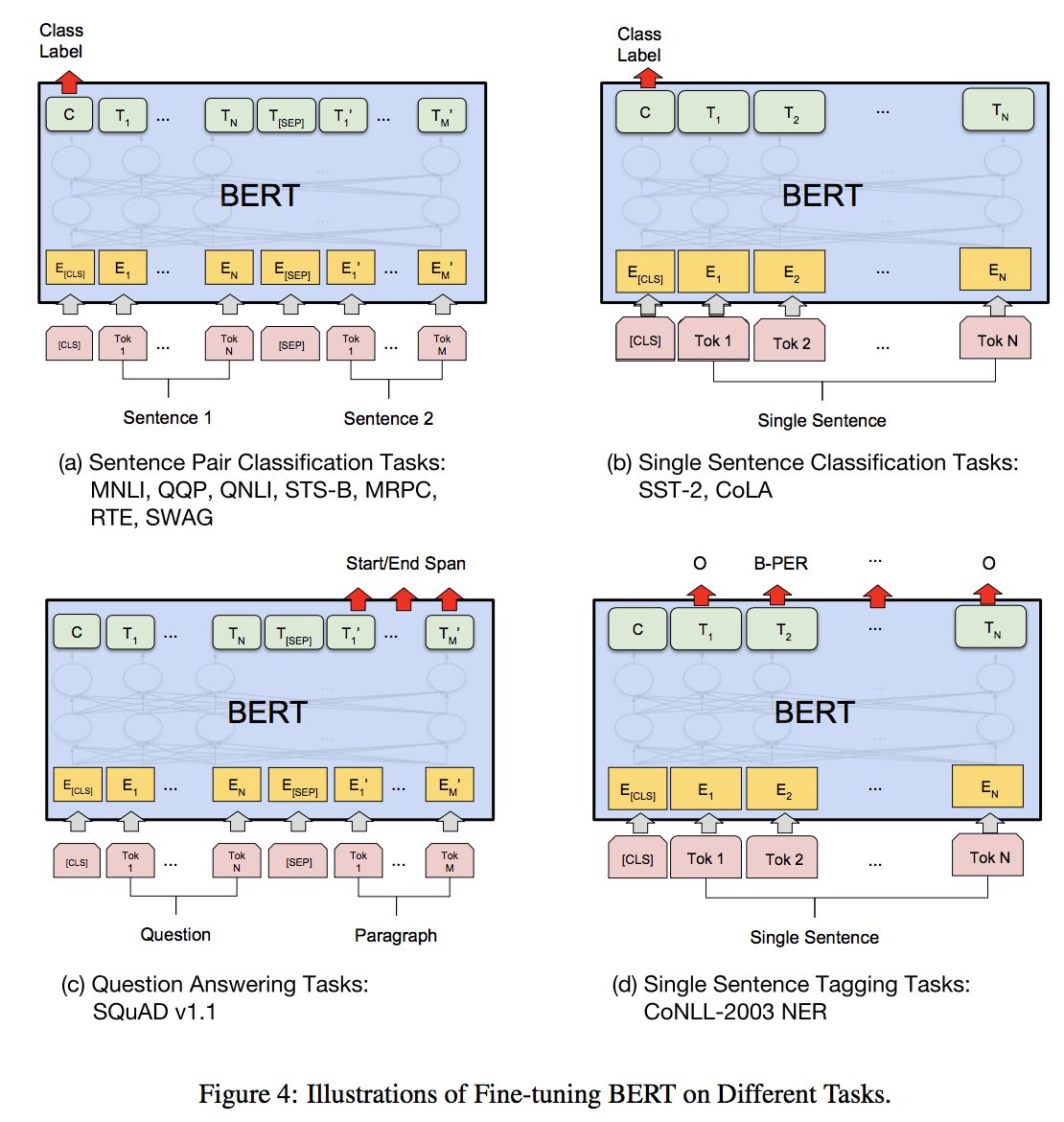
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
1.4 実験
ここからはBERTがSoTAを叩き出した11個のNLPタスクに対しての結果を記す。
1.4.1 GLUE
GLUEベンチマーク(General Language Understanding Evaluation)[Wang, A.(2019)]とは8つの自然言語理解タスクを1つにまとめたものである。最終スコアは8つの平均をとる。こちらで現在のSoTAモデルなどが確認できる。今回用いたデータセットの内訳は以下。
| データセット | タイプ | 概要 |
|---|---|---|
| MNLI | 推論 | 前提文と仮説文が含意/矛盾/中立のいずれか判定 |
| QQP | 類似判定 | 2つの疑問文が意味的に同じか否かを判別 |
| QNLI | 推論 | 文と質問のペアが渡され、文に答えが含まれるか否かを判定 |
| SST-2 | 1文分類 | 文のポジ/ネガの感情分析 |
| CoLA | 1文分類 | 文が文法的に正しいか否かを判別 |
| STS-B | 類似判定 | 2文が意味的にどれだけ類似しているかをスコア1~5で判別 |
| MRPC | 類似判定 | 2文が意味的に同じか否かを判別 |
| RTE | 推論 | 2文が含意しているか否かを判定 |
結果は以下。
$\mathrm{BERT_{BASE}}$および$\mathrm{BERT_{LARGE}}$いずれもそれまでのSoTAモデルであるOpenAI GPTをはるかに凌駕しており、平均で $\mathrm{BERT_{BASE}}$は4.5 %のゲイン、$\mathrm{BERT_{LARGE}}$は7.0%もゲイン が得られた。
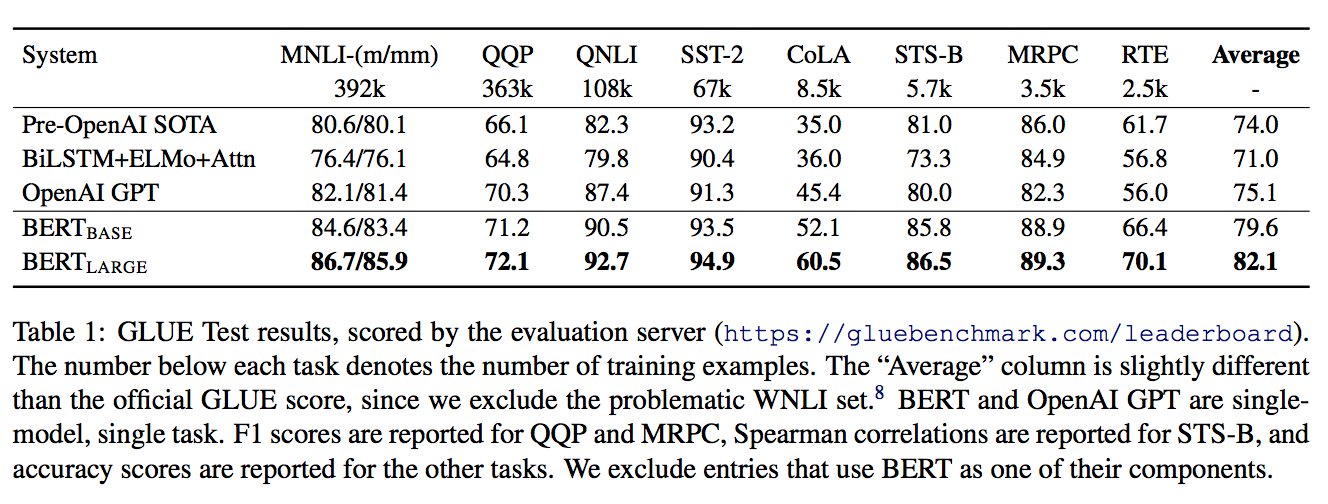
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
1.4.2 SQuAD v1.1
SQuAD(Stanford Question Answering Dataset) v1.1[Rajpurkar (2016)]はQ&Aタスクで、質問文と答えを含む文章が渡され、答えがどこにあるかを予測するもの。
この時、SQuADの前にTriviaQAデータセットでファインチューニングしたのちにSQuADにファインチューニングした。
結果は以下。
アンサンブルでF1スコアにて1.5ポイントのゲイン、シングルモデルでもF1スコアにて1.3ポイントのゲイン が得られた。特筆すべきは BERTのシングルがアンサンブルのSoTAを上回った ということ。
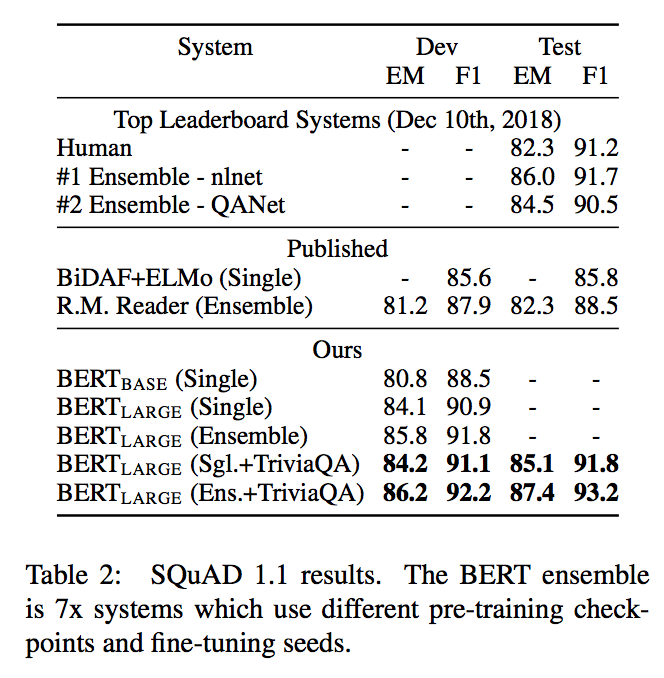
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
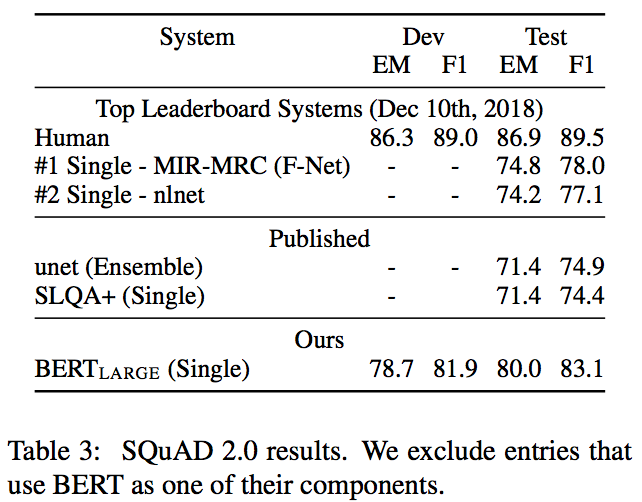
1.4.3 SQuAD v2.0
SQuAD v2.0はSQuAD v1.1に「答えが存在しない」という選択肢を加えたもの。
答えが存在するか否かは[CLS]トークンを用いて判別。
こちらではTriviaQAデータセットは用いなかった。
結果は以下。
F1スコアにてSoTAモデルよりも5.1ポイントのゲイン が得られた。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
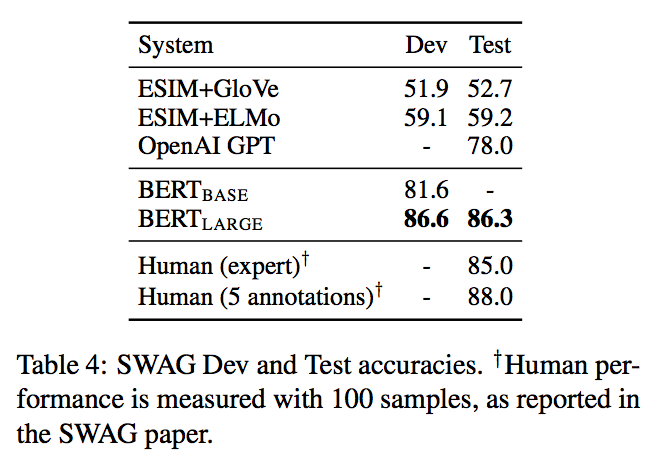
1.4.4 SWAG
SWAG(Situations With Adversarial Generations)[Zellers, R.(2018)]は常識的な推論を行うタスクで、与えられた文に続く文としてもっともらしいものを4つの選択肢から選ぶというもの。
与えられた文と選択肢の文をペアとして、[CLS]トークンを用いてスコアを算出する。
結果は以下。
$\mathrm{BERT_{LARGE}}$がSoTAモデルよりも8.3%も精度が向上した。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
1.5 アブレーションスタディ
BERTを構成するものたちの相関性などをみるためにいくつかアブレーション(部分部分で見ていくような実験のこと。)を行なった。
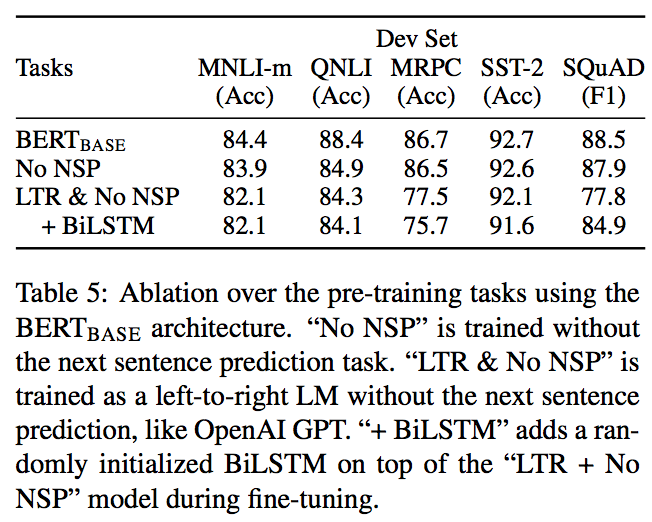
1.5.1 事前学習タスクによる影響
BERTが学んだ文の両方向性がどれだけ重要かを確かめるために、ここでは次のような事前学習タスクについて評価していく。
- NSPなし: MLMのみで事前学習
- LTR & NSPなし: MLMではなく、通常使われるLeft-to-Right(左から右の方向)の言語モデルでのみ事前学習
これらによる結果は以下。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
ここからわかるのは次の3つ。
- NSPが無いとQNLI, MNLIおよびSQuADにてかなり悪化($\mathrm{BERT_{BASE}}$ vs NoNSP)
- MLMの両方向性がない(=通常のLM)だと、MRPCおよびSQuADにてかなり悪化(NoNSP vs LTR&NoNSP)
- BiLSTMによる両方向性があるとSQuADでスコア向上ができるが、GLUEでは伸びない。 (LTR&NoNSP vs LTR&NoNSP+BiLSTM)
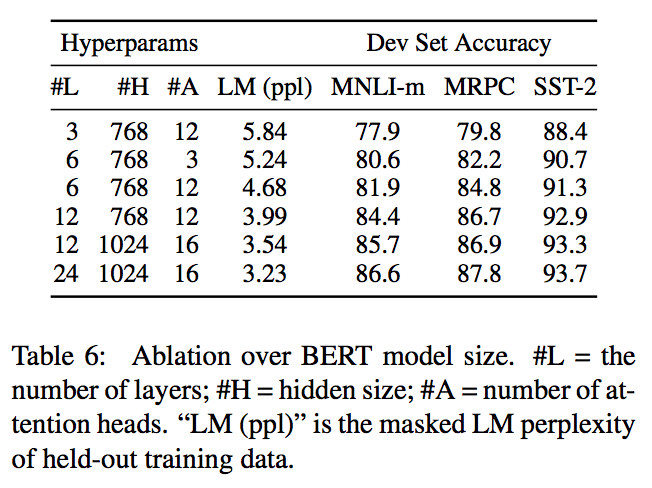
1.5.2 モデルサイズによる影響
BERTモデルの構造のうち次の3つについて考える。
- 層の数 $L$
- 隠れ層のサイズ $H$
- アテンションヘッドの数 $A$
これらの値を変えながら、言語モデルタスクを含む4つのタスクで精度を見ると、以下のようになった。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
この結果から言えることは主に次の2つのことが言える。
- 機械翻訳と比べて小さなタスクにおいても大きいモデルを使うと精度も上がる。
- 下流タスクが小さくてもファインチューニングすることで事前学習が大きいため高い精度 を出せる。
1.5.3 BERTを用いた特徴量ベースの手法
この論文を通して示した結果は、事前学習したモデルに識別器をのせて学習し直すファインチューニングによるものである。ここではファインチューニングの代わりにBERTに特徴量ベースの手法を適用する。
データセットに固有表現抽出タスクであるCoNLL-2003[Sang, T. (2003)]を用いた。
結果は以下。
特徴量ベースの$\mathrm{BERT_{BASE}}$はファインチューニングの$\mathrm{BERT_{BASE}}$と比べF1スコア0.3しか変わらず、このことからBERTはファインチューニングおよび特徴量ベースいずれの手法でも効果を発揮することがわかる。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
1.6 結論
これまでに言語モデルによる転移学習を使うことで層の浅いモデルの精度が向上することがわかっていたが、この論文ではさらに両方向性を持ったより深いモデル(=BERT)においても転移学習が使えることを示した。深いモデルを使えるが故に、さらに多くの自然言語理解タスクに対して応用が可能である。
2. まとめと所感
BERTは基本的に「TransformerのEncoder + MLM&NSP事前学習 + 長文データセット」という風に思えますね。BERTをきっかけに自然言語処理は加速度を増して発展しています。BERTについてさらに理解を深めたい場合はぜひ論文をあたってみてください!
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
ツイッター@omiita_atiimoもぜひ!
3. 参考
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)
原論文。 -
GLUE: A MULTI-TASK BENCHMARK AND ANALYSIS
PLATFORM FOR NATURAL LANGUAGE UNDERSTANDING, Wang, A. (2019)
GLUEベンチマークの論文。 -
The feature of bidirection #83
[GitHub] BERTの両方向性はTransformers由来のもので単純にSelf-Attentionで実現されている、ということを教えてくれているissue。 -
BERT Explained!
[YouTube] BERTの解説動画。簡潔にまとまっていて分かりやすい。 -
[BERT] Pretranied Deep Bidirectional Transformers for Language Understanding (algorithm) | TDLS
[YouTube] BERT論文について詳解してくれている動画。