オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
- 2021/02/28 SimCLRのバッチサイズに関する記述を修正
2020年超盛り上がり!自己教師あり学習の最前線まとめ!
2020年に大きく盛り上がりを見せた分野に自己教師あり学習(=Self-Supervised Learning(SSL))があります。SSLとは名前の通り自分で教師を用意するような手法で、データ自身から独自のラベルを機械的に作り画像の表現を学ばせるようなタスクです。なので、人間によるラベルは用いません。
最近の画像認識では特に大量のデータを必要とし、そのデータをアノテーションするには尋常じゃないほどの労力を要します。この先より高い性能を手に入れるためには、さらなるデータが必要になっていきます。そうなると人間のアノテーションのコストがさらにかかってきてしまいます。このコストを大幅に減らすのに有効なのがまさに機械的にラベリングを行うSSLです。なので、SSLへのモチベーションは「人間によるラベル付けをなるべく減らして、教師あり学習並み(orそれ以上)の性能を手に入れたい」ということになります。
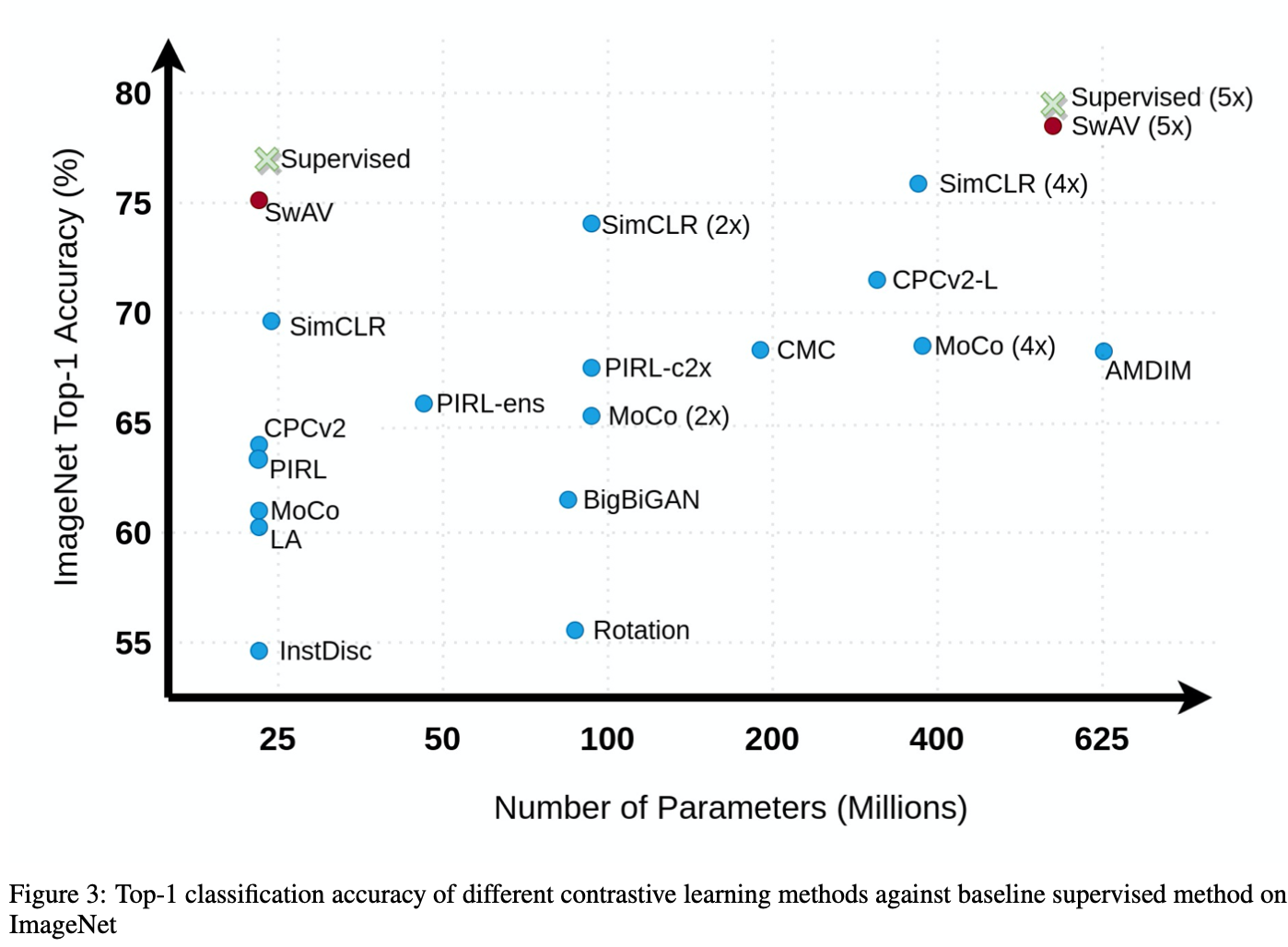
最近のSSLモデルは、Contrastive Learningという手法を用いることで教師あり学習モデルに肩を並べるほどの性能を示しています。
本記事ではこちらの論文[Jaiswal, A.(2020)]をもとに、そんなSSLの手法たちをまとめていきます。画像分野のContrastive Learningを主に取り上げております。それでは、本記事を通してSSLの最前線を見ていきましょう。
本記事の流れ:
- 忙しい方へ
- Contrastive Learningとは
- Pretextタスク
- アーキテクチャ
- 実験結果
- Contrastive Learningのこれから
- まとめと所感
- 参考
0. 忙しい方へ
- 自己教師あり学習の最新トレンドはContrastive Learningだよ
- Contrastive Learningでは、「似ているデータは潜在空間でも似た埋め込みベクトルになり、異なるデータは潜在空間でも異なる埋め込みベクトルになる」ということを学習させるよ
- Contrastive Learningのアーキテクチャは次の4つに分かれるよ
- End-to-End
- メモリーバンク
- モーメンタムエンコーダー
- クラスタリング
- 自己教師あり学習は、画像分類では教師あり学習にほぼ追いつき、物体検出への転移は教師あり学習よりも良いよ
1. Contrastive Learningとは
1.1 Contrastive Learningの概要
SSLでは、ラベルを用いずに画像の特徴量を学習させます。SSLの中でも最近特に性能を発揮しているのがContrastive Learningです。Contrastive Learningでは、「似ているデータは潜在空間でも似た埋め込みベクトルになり、異なるデータは潜在空間でも異なる埋め込みベクトルになる」ようにエンコーダーを学習させます。
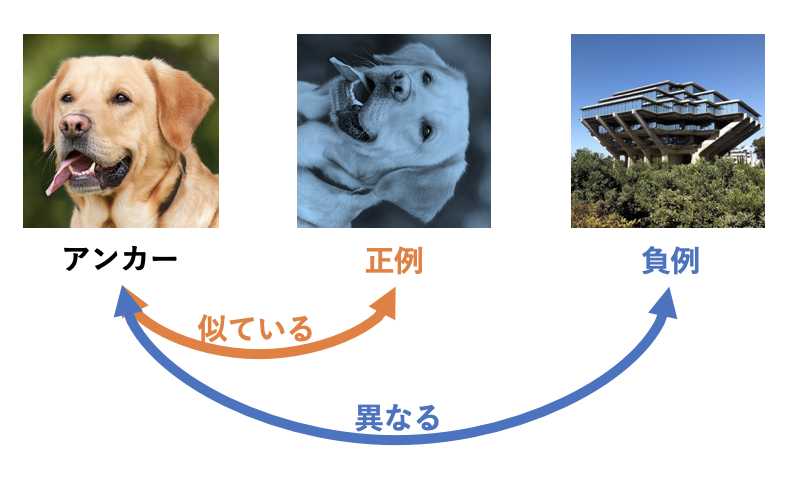
Contrastive Learningではアンカーと正例と負例の3つが登場します。アンカーを軸として正例がアンカーと似ているデータ、負例がアンカーと異なるデータとなります。例としてアンカーをある画像とすると、正例はアンカーをデータオーギュメンテーションしたものが用いられ、負例は全く異なる別画像を用いることがよくあります。画像分野のエンコーダーとしてはよくResNet-50が用いられます(大きさと性能のバランスがちょうど良いためだそうです)。この時、画像の埋め込みとしてResNet-50のGlobal Average Pooling(=GAP)直後の2048次元ベクトルやそれをさらに線形変換した128次元ベクトルを用いたりします。後述しますが、SimCLR[Chen, T.(ICML'20)]ではGAPの出力を2層MLPに通すことで埋め込みベクトルを獲得しています。
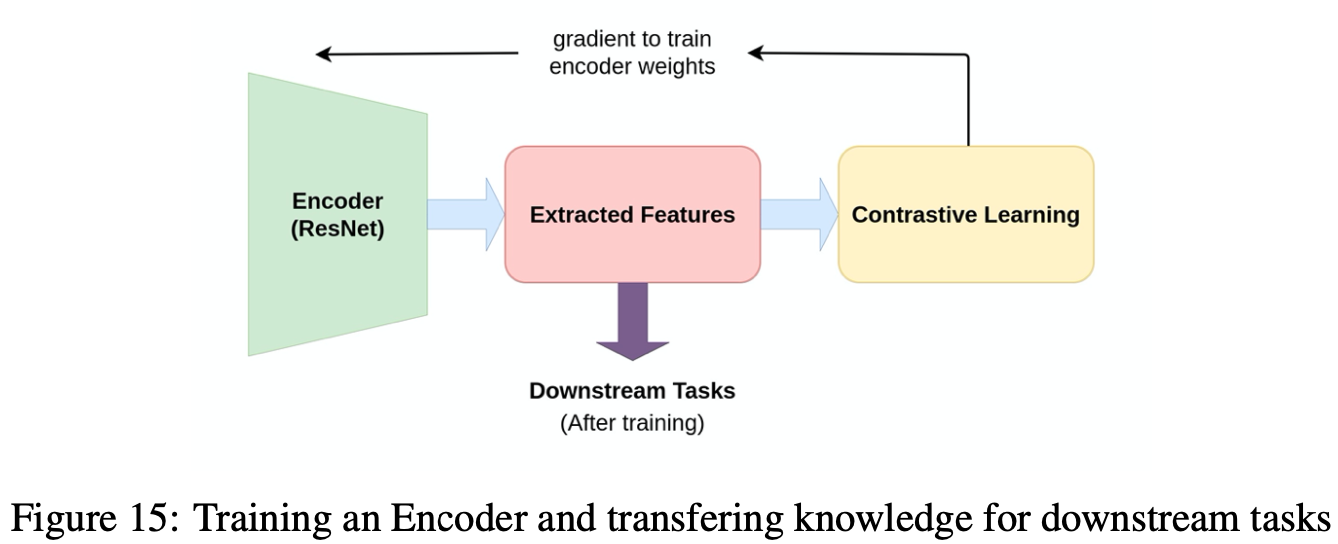
Contrastive Learningで学習させたエンコーダーをそのまま画像分類や物体検出などの下流タスクに用います(私の解釈ですが、Contrastive Learningはラベルを用いない事前学習と見ることができますね。)
1.2 エンコーダーの学習
Contrastive Learningは、似ているものは近く異なるものは遠くという考えなので「似ている」を定義する必要があります。似ている具合のことを類似度と呼びますが、指標としてコサイン類似度がよく用いられます。
\mathrm{cossim}(A, B)=\frac{A\cdot B}{\|A\|\|B\|}
コサイン類似度はベクトル間のなす角度で決定されており、つまりベクトルの向きがどれだけ似ているかを見ています。Contrastive Learningでは、Noise Contrastive Estimation(=NCE)を損失関数とすることで目的を達成します。ちなみにアンカーはクエリ、正例/負例はキーとも呼ばれます。ここでアンカーを$q$、正例を$k_+$、負例を$k_-$とすると、NCEは次のようにかけます。ここで$\tau$はハイパーパラメーターで温度と呼ばれます。
L_{NCE}=-\log{\frac{\exp({\mathrm{sim}(q, k_+)/\tau})}{ \exp({ \mathrm{sim}(q, k_+)/\tau }) + \exp({ \mathrm{sim}(q, k_-)/\tau })} }
アンカーと正例の類似度$\mathrm{sim}(q, k_+)$がアンカーと負例の類似度$\mathrm{sim}(q, k_-)$よりも遥かに大きくなれば、おおよそ$-\log\frac{1}{1}=0$となりますね。$\mathrm{sim}(\cdot, \cdot)$には類似度を測る関数ならいずれでも良いのですが、先ほどのコサイン類似度が用いられることが多いです。
このNCEの負例を増やした場合は特にInfoNCEと呼ばれ次式で表されます。$k_{i}$が負例となります。1つのアンカーと正例ペアに対して、アンカーと負例ペアを大量に用いただけですね。
L_{infoNCE}=-\log{\frac{\exp({\mathrm{sim}(q, k_+)/\tau})}{ \exp({ \mathrm{sim}(q, k_+)/\tau }) + \sum_{i=0}^{K}{\exp({ \mathrm{sim}(q, k_{i})/\tau })}} }
この関数を損失関数として、あとはSGDやらAdamやらで最適化していくのみです。ただ、負例は異なる画像というふうに説明しましたが、後述するEnd-to-Endで学習させるアーキテクチャでは、負例としてバッチ内のアンカー以外の画像を用います。そのため、負例を大量に用いたい時はバッチサイズを大きくしないといけません。このようなバッチサイズが大きい場合には通常のSGDではうまくいかないので、Layer-wise Adaptive Rate Scaling(=LARS)[You, Y(2017)]と呼ばれるアルゴリズムを用いて学習させていきます。LARSでは特に次のような2つの工夫がされています。
- 各層で異なる学習率
- 重みのノルムに基づいて更新する大きさを決定
他にもコサイン学習率スケジューラなども用いることで安定した学習を実現しています。
2. Pretextタスク
繰り返しになりますが、Pretextタスクを用いたCLでは基本的に、アンカー(anchor)、正例、負例の3つを用います。この時、アンカーは元々の画像で、正例にはアンカーに少しトランスフォーメーションを加えたものが、そして負例にはそのバッチ内の他の画像たちが用いられます。
CLにおけるPretextタスクは次の4つに大別されます。
- 色変換(Color Transformation)
- 形状変換(Geometric Transformation)
- 文脈ベースタスク(Context-based Task)
- クロスモーダルベースタスク(Cross-modal based Task)
それでは上から順に見ていきましょう。
2.1 色変換

上図は画像(a)に対する色変換のそれぞれの例を示ししており、ノイズ加算(画像(b))やぼかし(画像(c))、色の歪み(画像(d))などがあります。このほかにもグレースケールへの変換などもあります。これを用いたCLにSimCLR[Chen, T.(ICML'20)]があります。
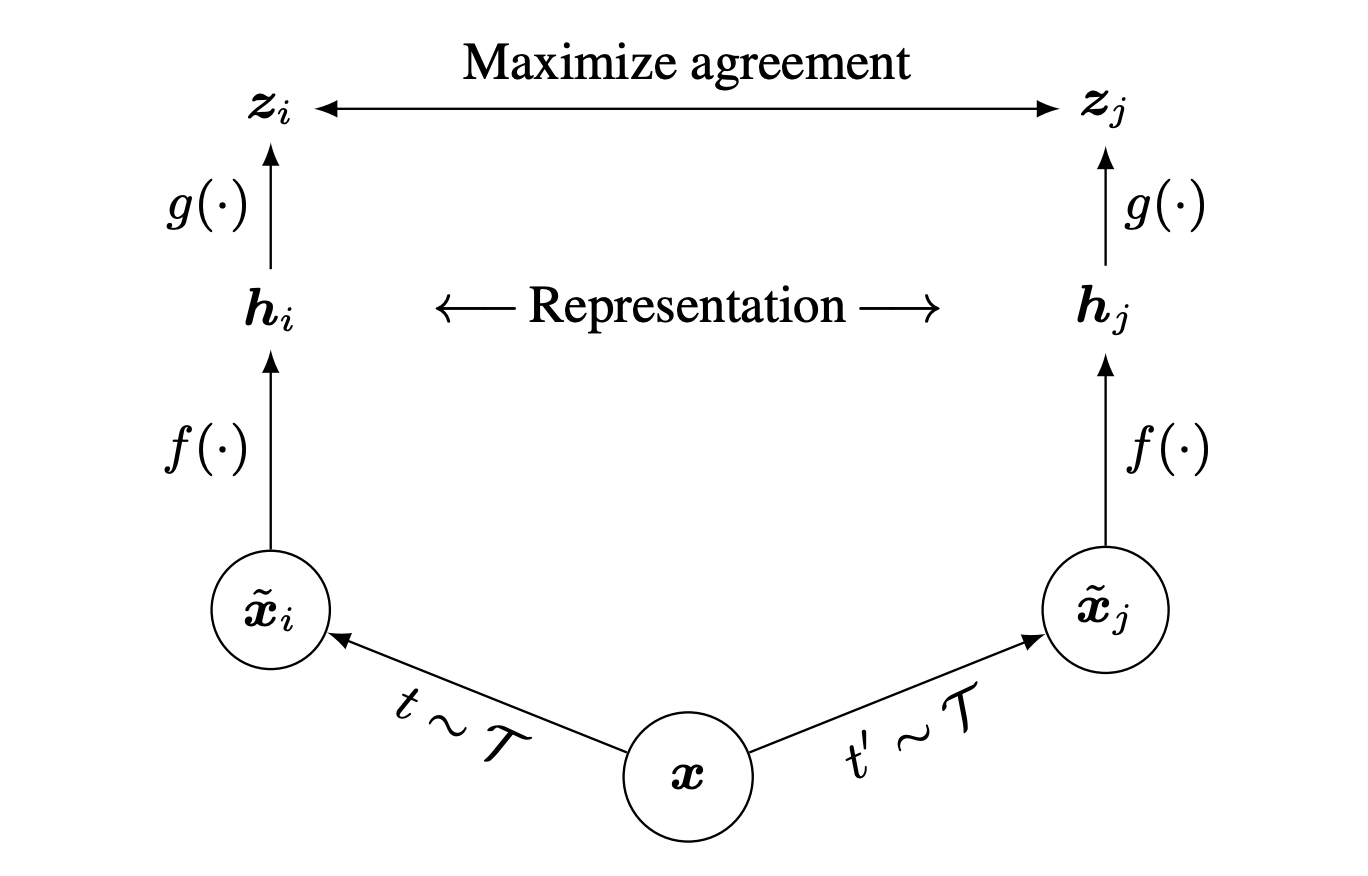
SimCLRでは、色変換に左右されずに似た画像同士を同じであるようにニューラルネットに学ばせていきます。上図でのMaximize agreementというのがそれを表しています。
2.2 形状変換

形状変換とは名の通り、画像の形状を実際に変えるような変換を指します。ピクセル値を実際にいじった色変換に対して、形状変換ではピクセル値に対する変更は行いません。上図が画像(a)に対する変換で、切り抜きやリサイズ(画像(b))、回転(画像(c))、反転(画像(d))などがあります。SimCLR[Chen, T.(ICML'20)]では色変換と同様に、形状変換のPretextタスクにおいても形状変換に左右されずに特徴量を学ばせることを目的として使用されています。
2.3 文脈ベース
2.3.1 ジグソーパズル

名前の通り、ジグソーパズルを用いて画像の特徴量を学んでいくというものです。上図の画像(b)からもとの画像(a)を推測させます。これをCLと組み込んだものがPIRL[Misra, I.(CVPR'20)]です。
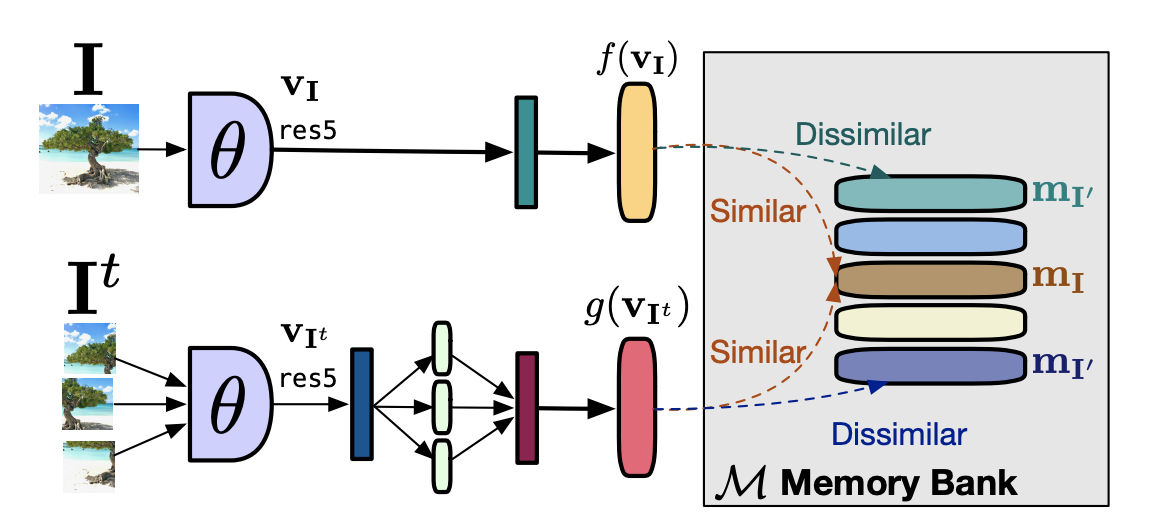
PIRLでは、元画像(上図$I$)をアンカー、シャッフルされた画像(上図$I^t$)を正例としてCLにジグソーパズルを組み込んでいます。ジグソーパズルされていても画像の意味を表す埋め込み表現自体は普遍であるべき、という仮定を学習させている感じですね。$I$の埋め込みベクトルは単にResNet50(上図$\theta$)のステージ5のあとの特徴マップに平均プーリングし線形変換(上図深緑のたてながの長方形)で128次元に落とすだけです。一方で、$I^t$の埋め込みベクトルはパッチそれぞれの特徴マップをとったのちに同様にそれぞれを128次元に落としたら(上図藍色のたてながの長方形)、それらを結合し再び線形変換(上図紫色のたてながの長方形)で128次元に落とすことで得られます。Memory Bankについては「3.2 メモリーバンク」にて後述します。
2.3.2 フレーム順ベース
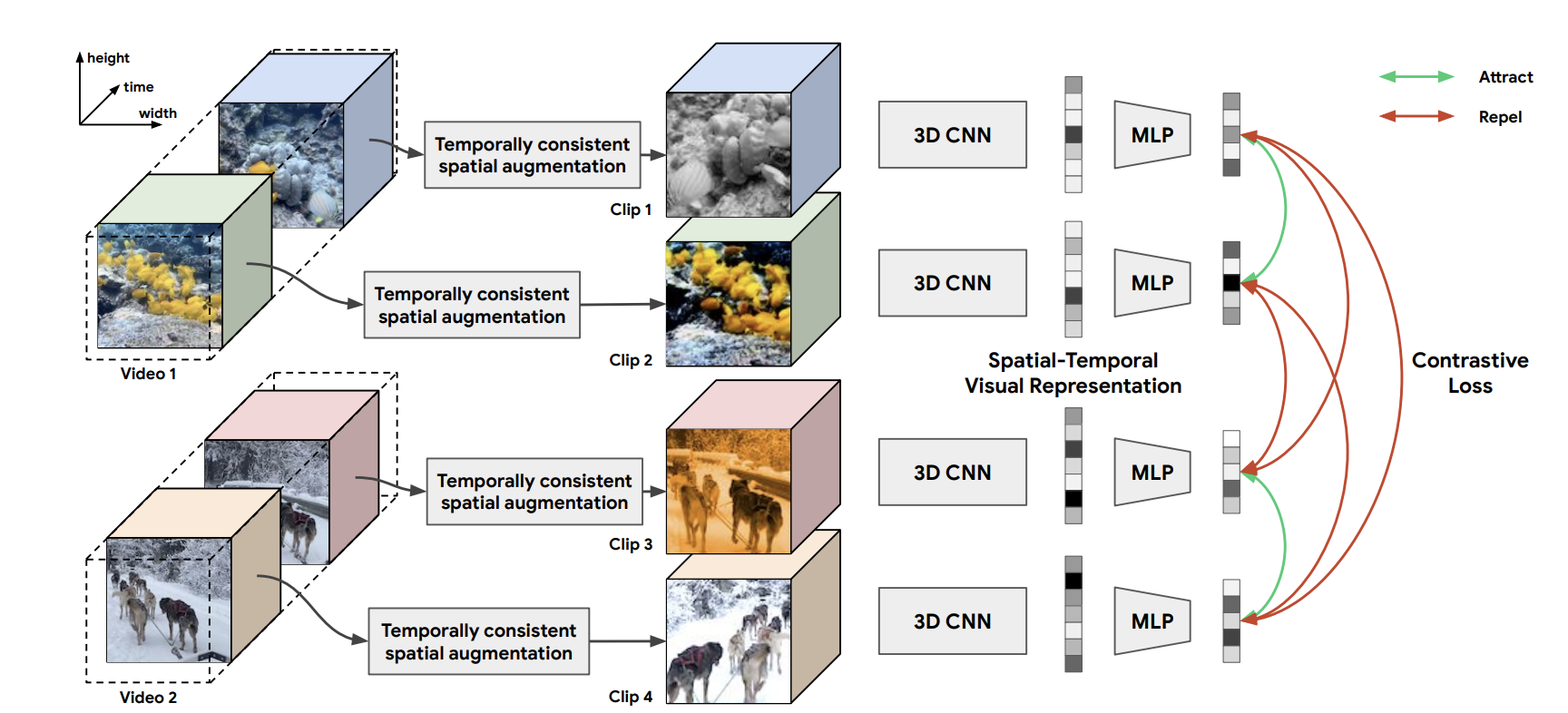
動画に対してもCLは適用できます。この例にCVRL[Qian, R.(2020)]があります。CVRLでは、2つのクリップが同じ動画から取られたもの同士であれば埋め込み表現も似ているべき、という仮定を組み込んでいます。このとき2つのクリップはさらに何かしらの変換も加えられています。
2.3.3 将来予測
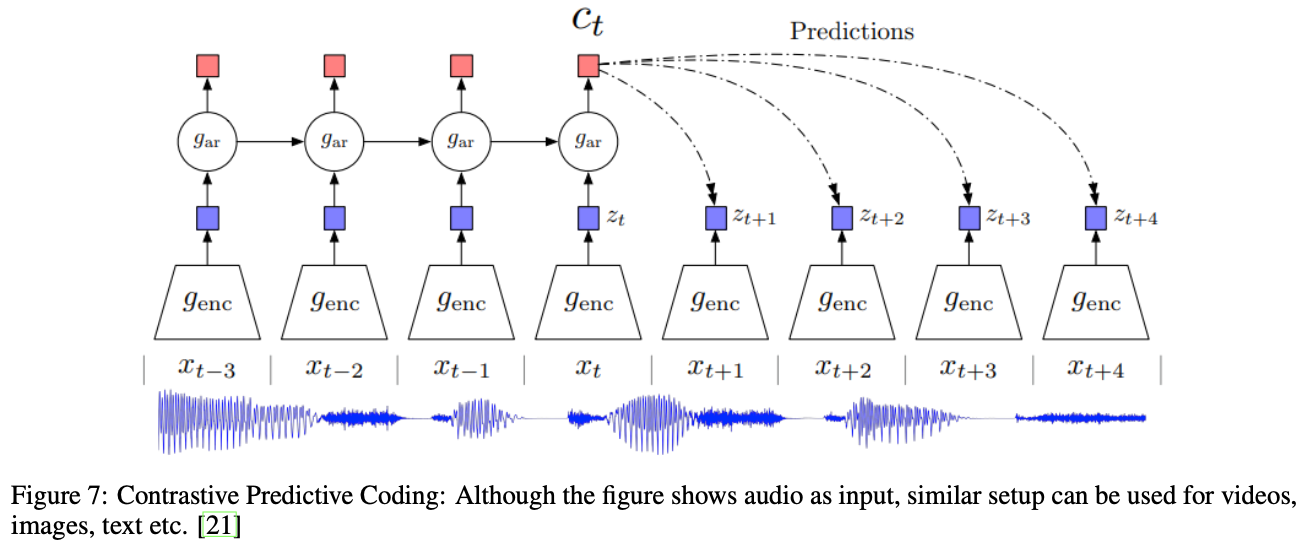
CPCでは、入力との相互情報量を最大化するような埋め込みを学ばせます。上図のようにAutoregressiveに入力を要約していき、潜在表現を予測させます。
2.4 クロスモーダルベース
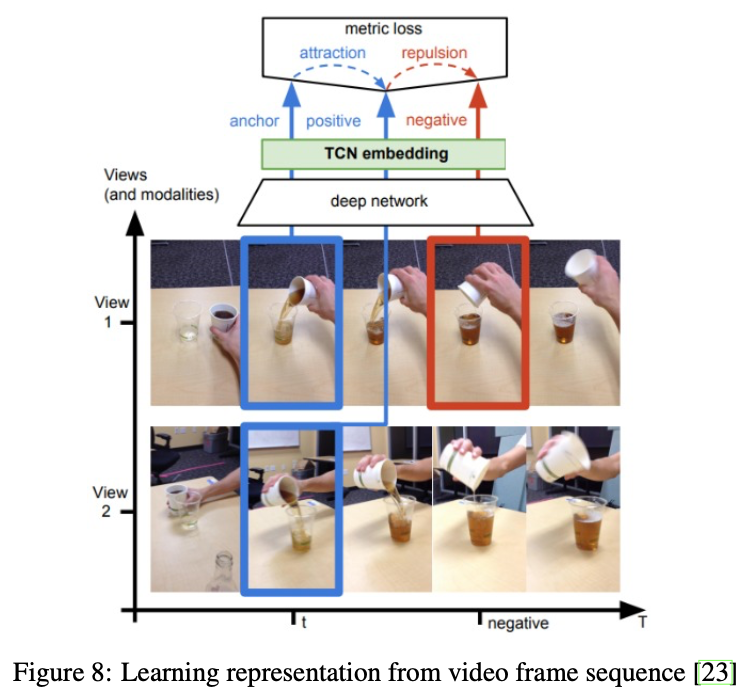
ここでは特に1つの物体をを異なる視点(多視点)から撮影した場合が取り上げられています。上図は動画に対するCLの例[Sermanet, P.(CVPR'17)]で、同時間のフレーム同士は同じところに埋め込まれ異なる時間のフレーム同士は遠くに埋め込まれる、というCLです。
2.5 最適なPretextタスクをどう選ぶか
どのPretextタスクを行うかというのは現在も盛んに研究されていますが、解きたい問題に最適なPretextを選ぶことでCLの良さを最大限に享受できることがわかっています。

実際に、細かい種類の画像分類タスクに対しては色変換などは不適切であることは上図からも分かります。上図で2枚とも同じような見た目ですが、色は大きく異なるので識別ができます。色変換されてしまっては難しいですよね。

他にも、[Yamaguchi, S.(2019)]では、上図のようなテクスチャのデータセットでは回転が意味をなさないことが示されています。また、スケーリングやアスペクト比の変更などの変換を用いたCLはそれほどメリットが無かったようです。どう選ぶかということに関しては、この先さらに研究が進んでもっと具体的な指南が出てくることが望まれます。
3. アーキテクチャ
CLには負例を大量に必要とします。そのため、学習中にどうやって負例を獲得するか、というのがCLにおいてはとても重要になってきます。ここでは、学習中の負例の獲得方法に基づいて、アーキテクチャを4つに分類して説明します。
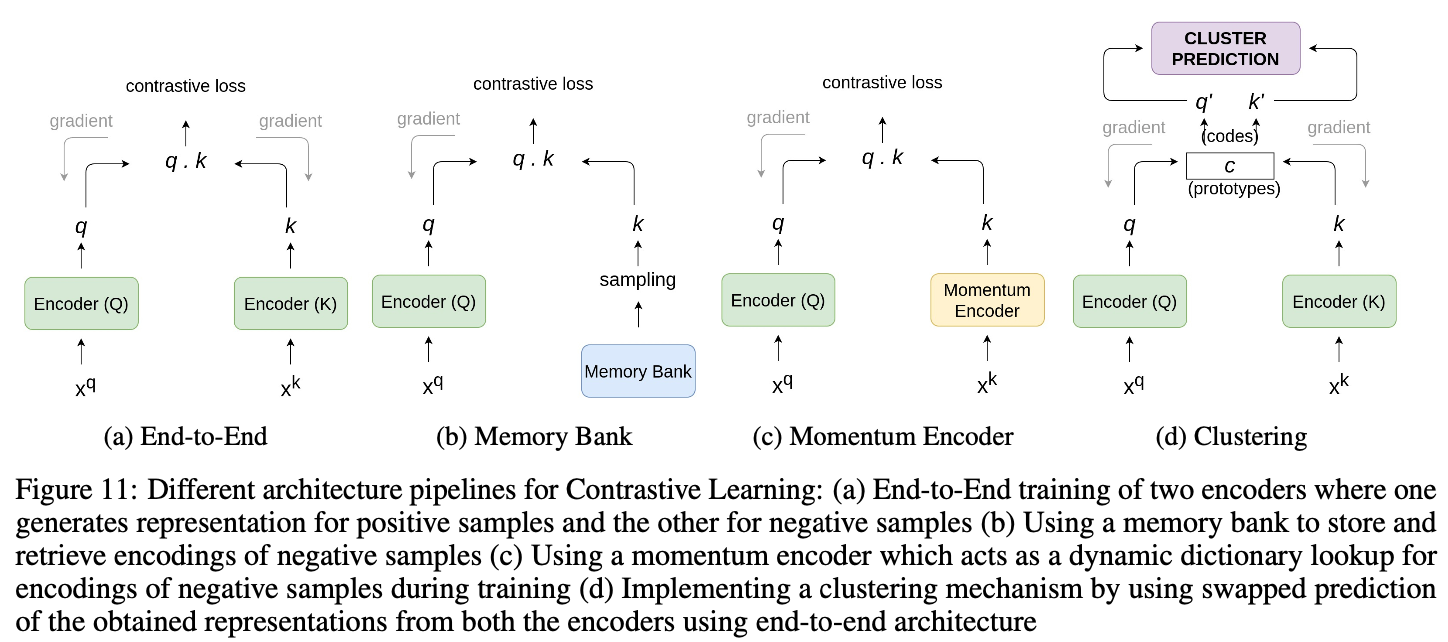
- End-to-End:正例と負例を都度しっかり埋め込む
- メモリーバンク: 負例の埋め込み表現はメモリーバンクに保存しておき、それを用いる
- モーメンタムエンコーダー: 流動的な辞書のような挙動を持つモーメンタムエンコーダーで負例の埋め込み表現を獲得。
- クラスタリング: End-to-Endで得られた表現に、クラスタリングを用いる
3.1 End-to-End
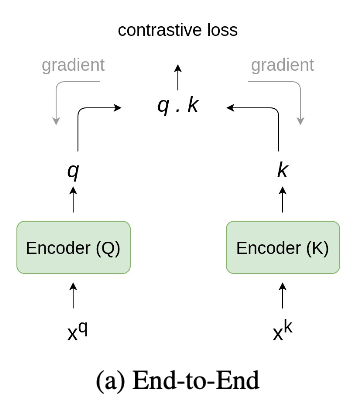
End-to-Endなアーキテクチャでは、2つのエンコーダーQとKを用意します。Qではアンカーを、Kでは正例/負例を埋め込ませます。上図で言いたいことはは、End-to-Endなアーキテクチャは各ステップで負例もしっかりと埋め込む、ということです。このアーキテクチャでは、バッチ内のアンカー画像とそのDA適用後画像(正例)以外を全て負例として扱うため、バッチサイズが大きい方が良いとされています。
2つのエンコーダーによって得られた表現$q$と$k$は類似度を取ってからContrastive損失の計算を行います。あとはその損失で逆伝搬してパラメーターを更新するだけです。
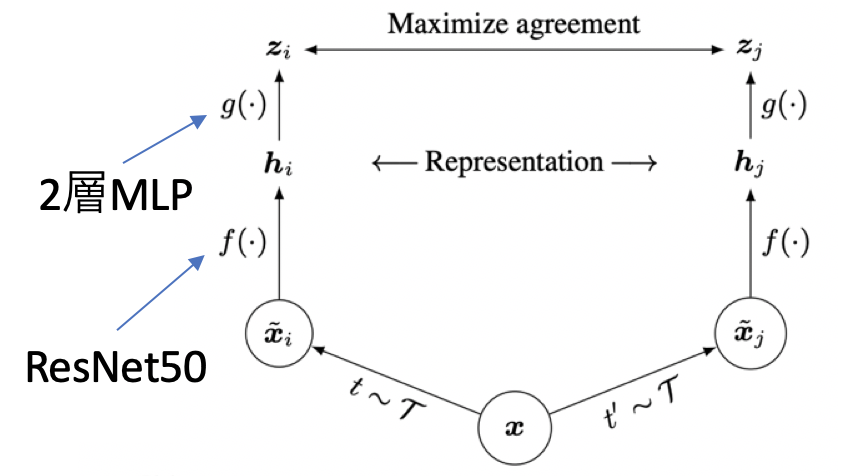
End-to-Endなアーキテクチャの代表例にSimCLR[Chen, T.(ICML'20)]がいます。何度も出てきますね。上図で$\mathcal{T}$はDAの集合を表しています。ランダムにサンプルした$t$と$t'$をバッチ$x$にそれぞれ適用させています。SimCLRにおいては、アンカーもDAが適用されたものになっています。例えば$k$番目の画像$x_k$に注目すると、$t(x_k)$がアンカーの時は正例は$t'(x_k)$で負例はこれら以外の全ての画像です。$t'(x_k)$がアンカーとした場合もちゃんと考慮されておりその時は$t(x_k)$が正例となります。損失関数にはNormalized Temperature CrossEntropy(=NT-Xent)というものが用いられています。式は下の通りですが、(アンカー$z_i$,正例$z_j$)ペアも$\Sigma$に入ったこと以外InfoNCEとほぼ変わりません。$\mathbb{1}_{k\neq i}$は「アンカーとアンカーの類似度は取りませんよ」ということを示しています。より詳しく知りたい方はNT-Xentの実装動画をご覧下さい。理解が深まります。
l_{i,j}=-\log{\frac{\exp({\mathrm{sim}(z_i, z_j)/\tau})}{ \sum_{k=1}^{2N}{\mathbb{1}_{k\neq i}\exp({ \mathrm{sim}(z_i, z_{k})/\tau })}} }
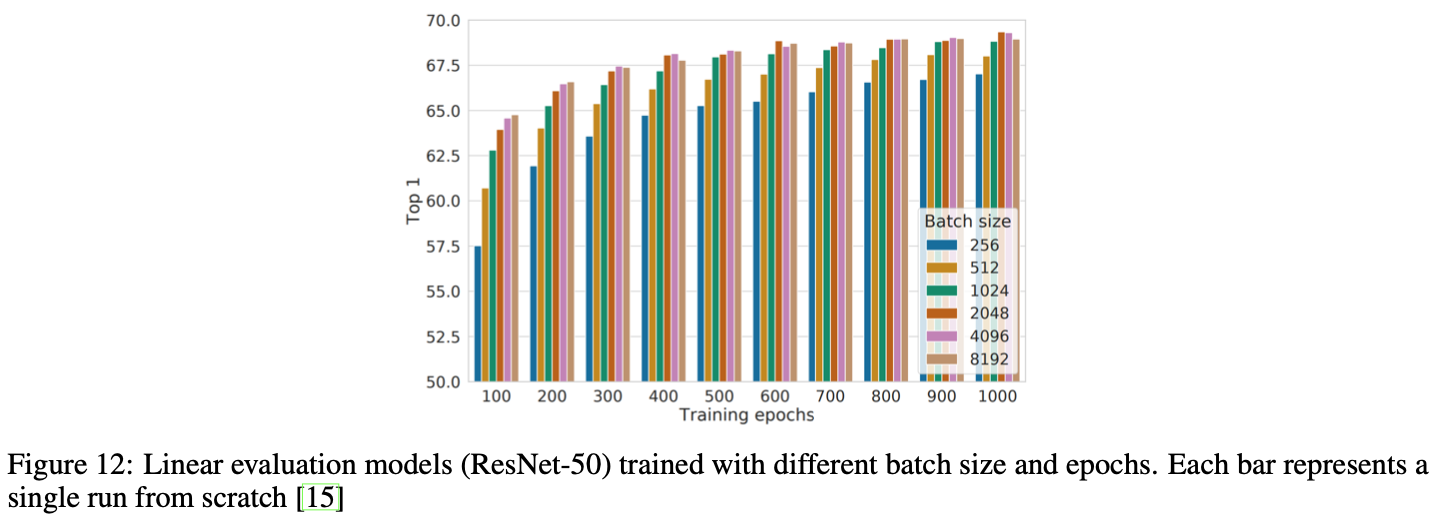
あとはバッチサイズ4096(でかい。)で100エポック回したりしています。SimCLRの論文中では以下の記述があります。
• Contrastive learning benefits from larger batch sizes and longer training compared to its supervised counterpart.
つまり、SimCLRのようなContrastive Learningにおいては教師あり学習と比べてでかいバッチサイズ&長い学習がとても有効なようです。ただ、下図およびSimCLRの論文中の記述からバッチサイズ8,192あたりで性能が飽和してしまうことがわかります。
the performance seems to saturate with a batch size of 8192
End-to-Endなアーキテクチャとして他にはCPC[Oord, A.(2018)]も挙げられます。CPCはAuto-regressiveとContrastive損失を用いることで、時系列データの特徴表現をEnd-to-Endに学んでいます。
End-to-Endなアーキテクチャによってとてもシンプルに学習できますが、欠点としてはやはり大きなバッチサイズを利用する、ということがあります。大きなバッチサイズを要するために、GPUメモリの問題も然り[Goyal, P.(2017)]で述べられているように最適化も難しくなります。この「大きいバッチサイズ問題」を解決する方法の1つにメモリーバンクを用いる方法があります。
3.2 メモリーバンク
End-to-Endなアーキテクチャでの「大きいバッチサイズ問題」を解決する方法の1つに、特徴表現を辞書のようなもので別に保存しておく、というものがあります。この辞書こそがメモリーバンクです。このメモリーバンクを用いた代表的なアーキテクチャが下図のPIRL[Misra, I.(CVPR'20)]です。
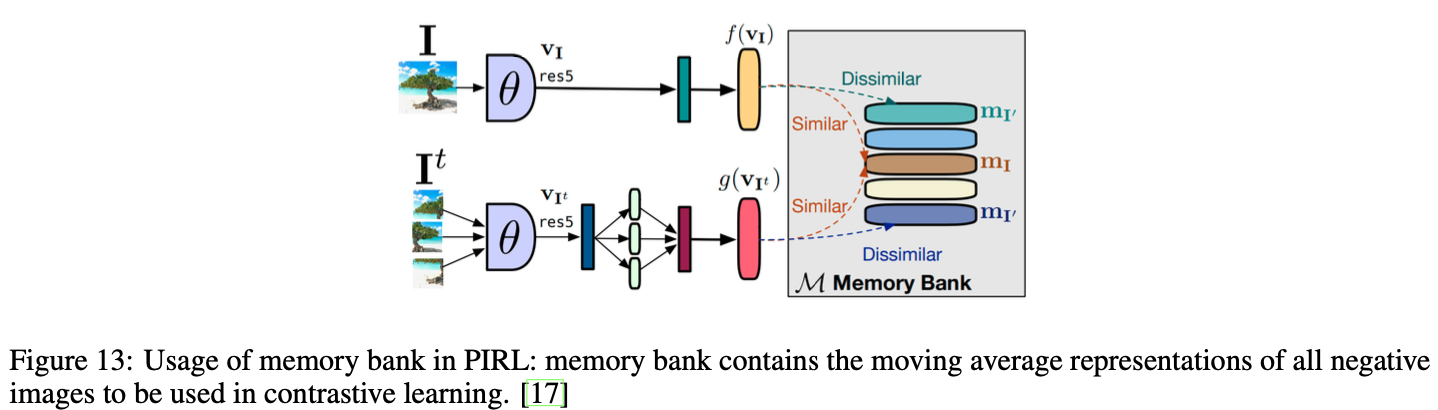
PIRLでは、データセット$D$内の画像$I$全てに対する埋め込み表現$m_I$をメモリーバンクに保存します。この時保存する埋め込み表現は図内の$f(v_I)$です。ただ、学習が進むにつれてメモリーバンク内の埋め込み表現もしっかりと更新したいので、各表現がエポックごとに移動平均で更新されています。
\theta_k \leftarrow \beta m_I+(1-\beta)f(\mathbf{v}_I)
PIRLでは負例がメモリーバンクからランダムサンプルされるため大きなバッチサイズが不要です。なので、SimCLRのような巨大なバッチサイズとはおさらばで嬉しいです。ただし、メモリーバンクの更新に要する計算量が莫大になりうるという問題も孕んでいます。メモリーバンク内の表現を常に最新状態にしようとすると数ステップごとにメモリーバンク内の表現を更新しなければならないためです。これを解決するために、モーメンタムエンコーダーというものを用います。
3.3 モーメンタムエンコーダー
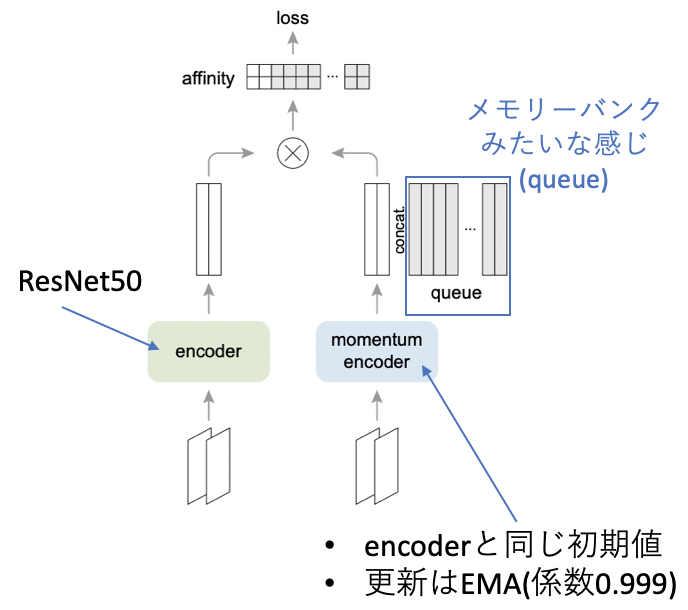
メモリーバンクの「更新が高価になりうる問題」を解決するために、モーメンタムエンコーダーを用います。MoCo[He, K.(CVPR'20)]がその手法になります。モーメンタムエンコーダーでは、正例だけモーメンタムエンコーダーに通し、負例は過去の正例たちの埋め込み表現を用います。この時、過去の正例たちはFirst-In-First-Out(FIFO)な待ち行列(キュー, queue)で保存されています。また、モーメンタムエンコーダーKの重みは上図のエンコーダーQと同じですが、重みの更新はバックプロップではなく移動平均を用います(エンコーダーQはいつも通りバックプロップで更新します)。モーメンタムエンコーダーと呼ばれる所以は移動平均を用いて更新するためですね。
$$
\theta_k \leftarrow m\theta_k+(1-m)\theta_q
$$
メモリーバンクでは埋め込み表現自体を移動平均で更新しましたが、モーメンタムエンコーダーでは重みを移動平均で更新しています。これによって、End-to-Endのように2つのネットワーク学習させる必要がなく、計算量的にもメモリー的にも非効率的なメモリーバンクが不要になったといった利点があります。最後にMoCoの疑似コードを見るとよりわかりやすいと思います。

3.4 クラスタリング
ここまでで見てきたアーキテクチャはいずれもサンプル間の類似度を比較したものになっていました。ただし、サンプル1つ1つで行うContrastive Learningを行う場合ある問題を孕んでしまっています。それは、負例の中にアンカーと同じラベルのものが含まれていても負例として学習してしまう、ということです。これを緩和するためにクラスタリングを用いた手法があります。
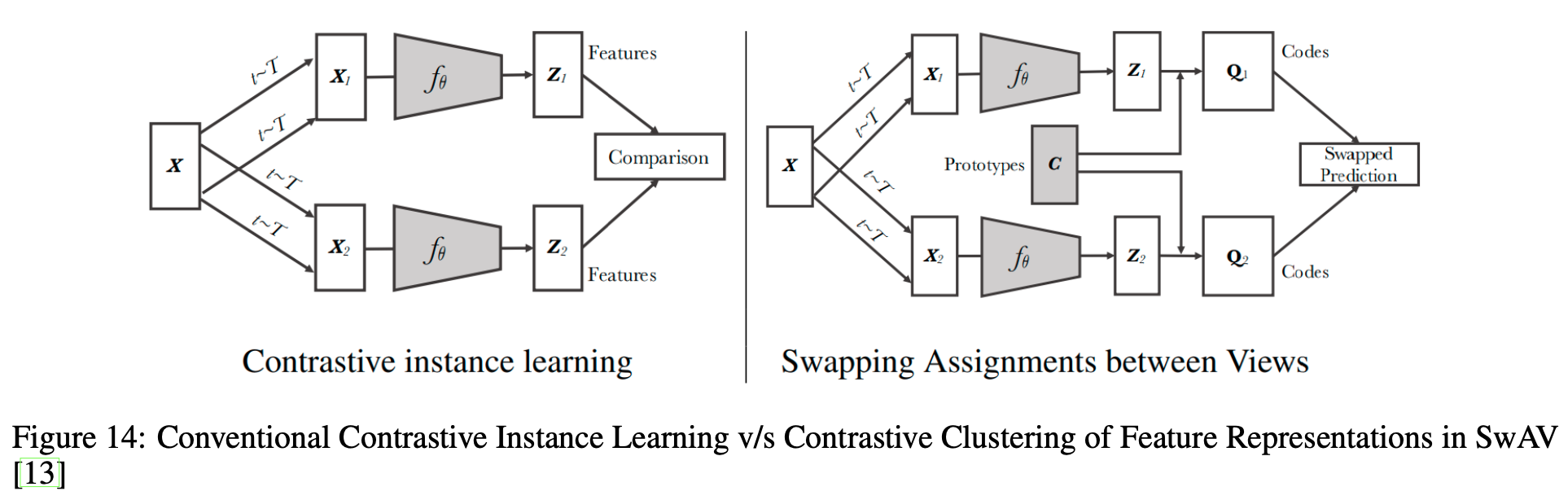
その代表例がSwAV[Caron, M. (NerIPS'20)]です。SwAVは、同じ画像からのクロップ画像たちが属するクラスター(プロトタイプベクトル)は同じ、というのを学習させています(と理解しています)。このクラスターのラベル(ソフトラベル)はSinkhorn-Knoppアルゴリズムと呼ばれるアルゴリズムで各バッチで毎回生成されます。詳しくはこちらの記事が実装も含んでおりとてもわかりやすかったです。以下アルゴリズムの概観です。2つのオーギュメンテーション$x_t$と$x_s$が一貫した予測結果になるように**$x_t$で$x_s$のクラスターを予測し、$x_s$で$x_t$のクラスターを予測**しています(Swap prediction)。

4. 実験結果
SSLで学習させたモデルの性能評価の方法として大きく次の3つを用いたものがあります。
- 線形識別: 学習済みエンコーダーに線形識別器をつけてラベルを用いて再学習。ただし、エンコーダーの重みは固定。
- ファインチューニング: ラベルを用いてエンコーダーの重みも再学習
- 半教師あり学習: ラベルの一部だけを用いて再学習。
4.1 画像分類
まず、エンコーダーの重みを固定し線形識別器だけを再学習させた場合の結果を見てみます。線形識別器とは、ただの1層全結合(アフィン変換)のことです。あまり強くない線形識別器だけを学習させるので、エンコーダーが画像の特徴量をうまく抽出していない限り良い性能は出てきません。
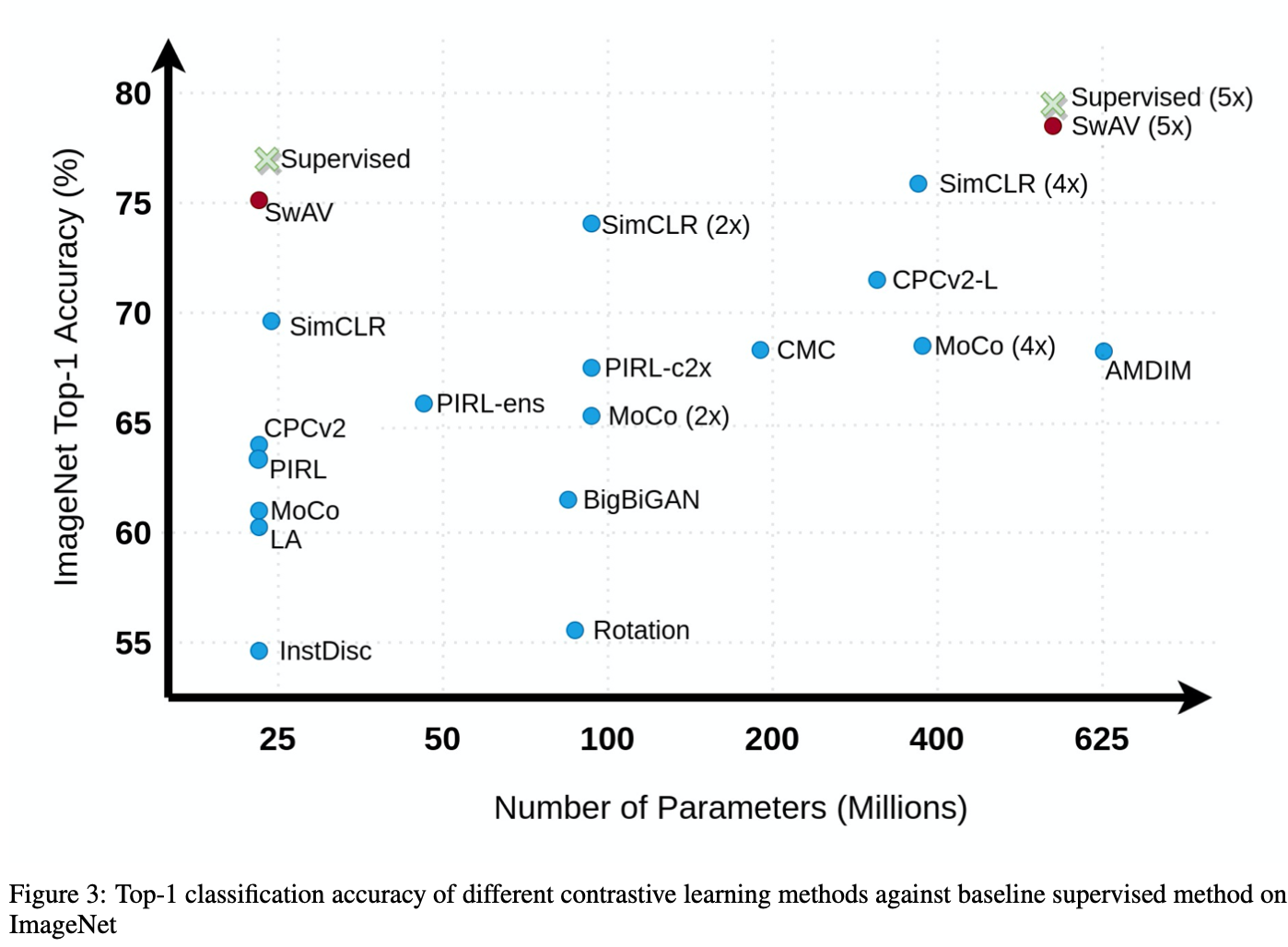
ここではImageNetに対するTop-1精度を示します。ラベルを用いてモデル全体を学習させたSupervisedにあと少しで追いつきそうです。このことから、大量のラベルなし画像だけでモデルを良い感じに学習させることが可能なことがわかりますね。ちなみにSwAVではContrastive Learningの際にInstagramから取った10億枚の画像(ImageNet ILSVRC-2012は100万枚程度)を用いています(もちろんラベルは用いていません)。
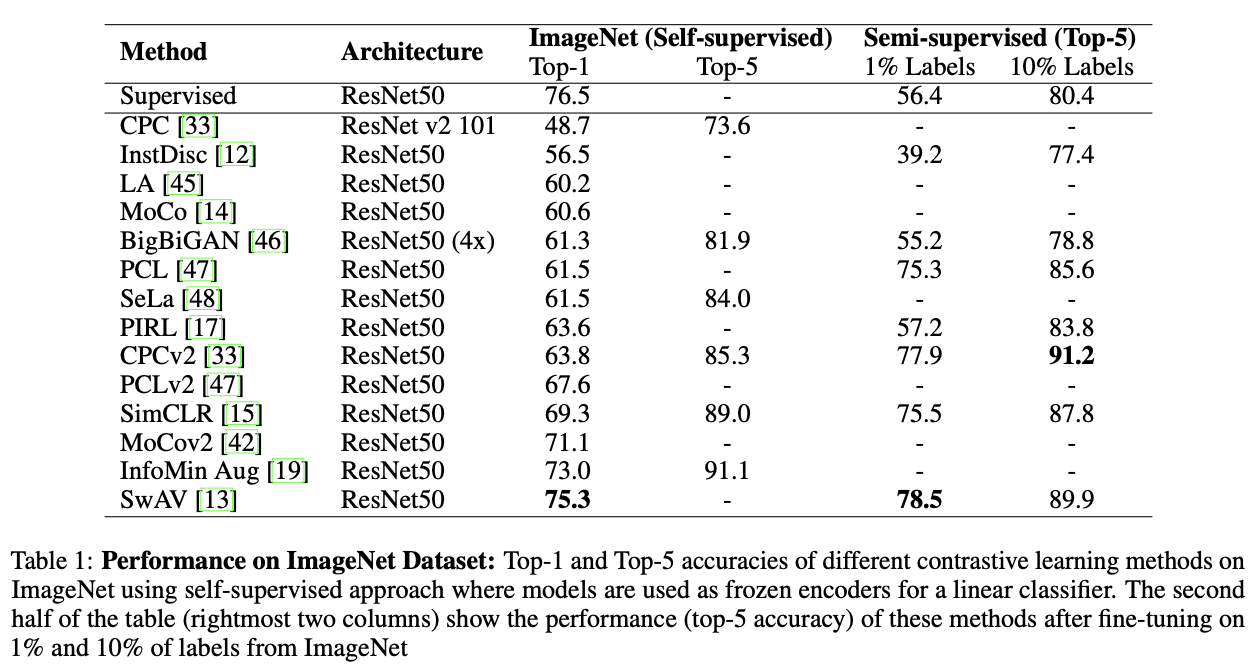
さらに、一部のラベルしか用いない半教師あり学習についても見てみます。ここではエンコーダーも再学習されています(つまり、ファインチューニング)。上表の右側がImageNetに対するTop-5精度です(左側は線形識別器に対する結果がまとめられています)。これを見るとSimCLRやSwAVなどがSupervisedを大きく上回り、Contrastive Learningがラベルが少ない場合にとても有効であることがわかりますね。
4.2 物体検出
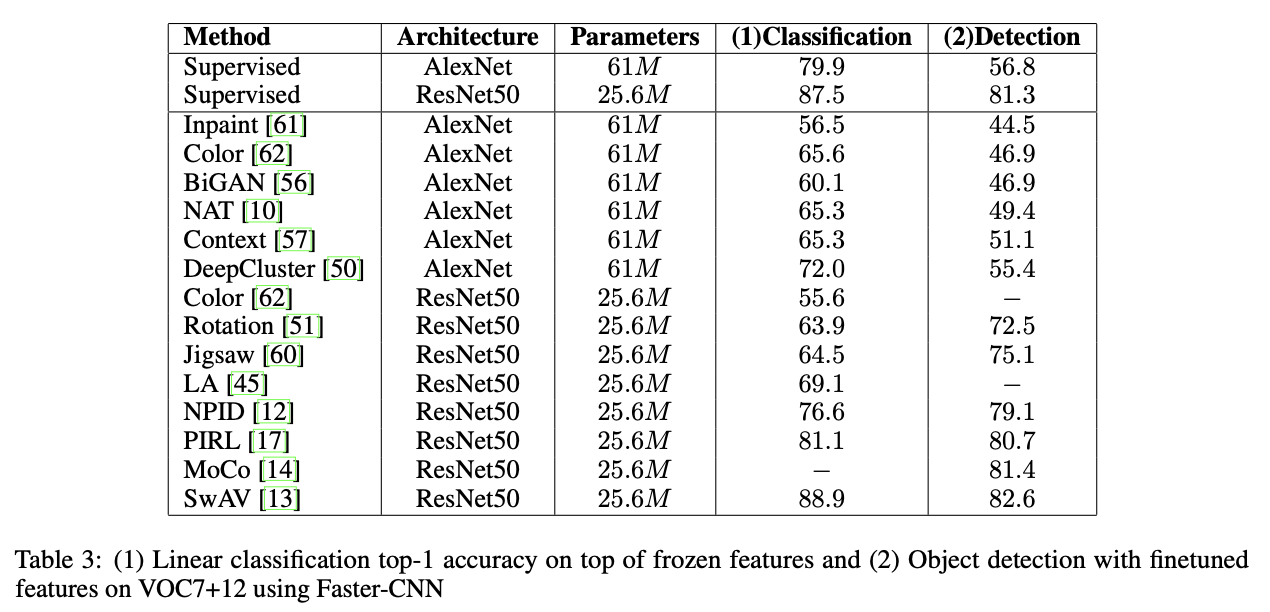
ここではPascal VOC7に対する線形識別による識別精度とPascal VOC7+12に対する物体検出の結果を示します。物体検出でもContrastive Learningによるモデル(MoCoおよびSwAV)がSupervisedを超えていますね。
4.3 動画分類
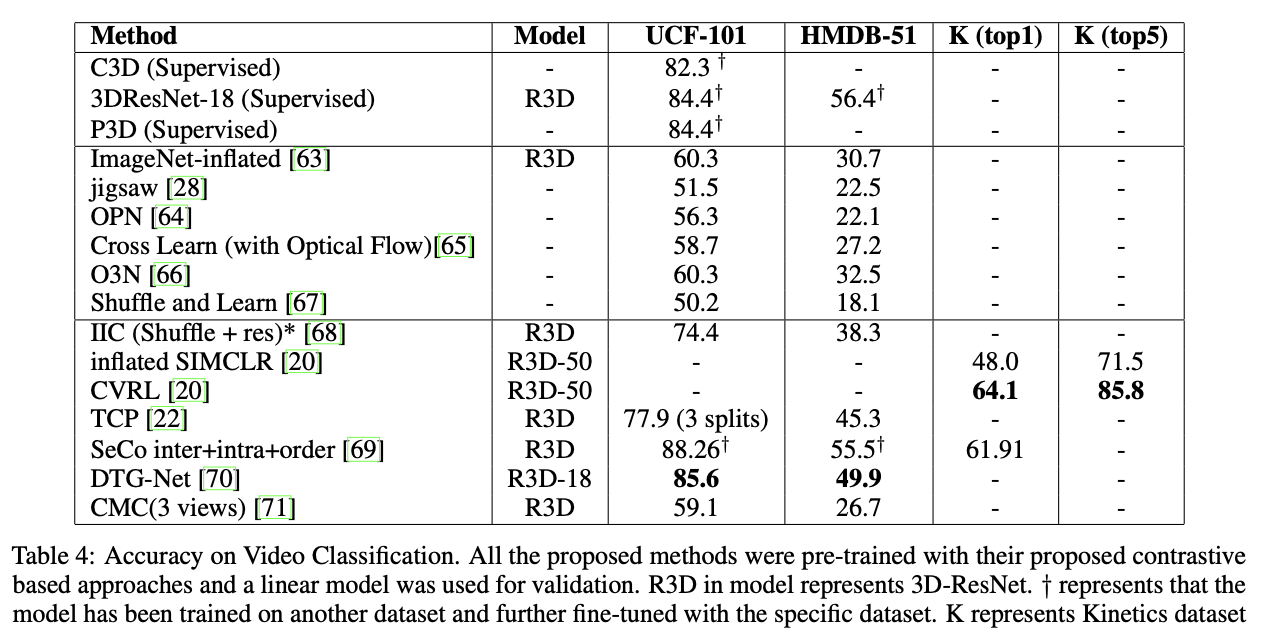
動画分類として、UCF101 / HMDB51 / Kineticsデータセットを用いた場合の結果を示しています。Contrastive Learningで学習させたモデルたちがいい感じの結果を出していることがわかりますね。(太字になっているモデルは、事前学習でも同じデータセットを用いたモデルのうち一番良いモデルのようです。)
5. Contrastive Learningのこれから
本論文では、Contrastive Learningのこの先の方向性として次の4つを上げています。
- 理論面の充実
- データオーギュメンテーションおよびPretextタスクの選択による影響
- 学習中の負例の正しいサンプリング方法
- データセットバイアス
1.の理論面の充実はContrastive Learningに限らずニューラルネット全体で言われていることですね。また、2.はPretextタスクやデータオーギュメンテーションによって性能が大きく変わってくるのでここら辺も必要です。そして3.の負例のサンプリング方法は大きいバッチサイズやメモリーバンクなどのことで、さらなる改善が望まれます。最後4.のデータセットバイアスですが、Contrastive Learningで用いたデータセットが何かに偏っていればモデルもその影響を受ける、ということです。
6. まとめと所感
2020年最高に盛り上がった自己教師あり学習(SSL)についてまとめました。中でも特に注目されているContrastive Learningに焦点を置きメモリーバンクやモーメンタムエンコーダーなどアーキテクチャについても見てきました。SSLは大量のラベルなしデータを有効活用できる手段として注目され、ラベルが少ない状況(=半教師あり学習)ではSSLが真価を発揮することがわかりました。教師あり学習を超えるのも時間の問題のように思えます。さらなる発展が望まれるSSLにこの先も目が離せませんね!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ:
7. 参考
-
"Self-Supervised Learning of Pretext-Invariant Representations", Misra, I., Maaten, L., (CVPR'20)
PIRLの論文 -
Math 574, Lesson 4-5: Mutual Information
相互情報量のわかりやすい解説動画 -
Contrasting contrastive loss functions
Contrastive損失関数の解説記事。初めのMax-marginから最新のNT-Xentまでの説明がスムーズ。 -
Contrastive Loss Explained
「NT-Xentは、Softmaxに温度とコサイン類似度を組み合わせただけ」という説明。 -
The Illustrated PIRL: Pretext-Invariant Representation Learning
PIRLをイラストでわかりやすく解説している記事 -
Unsupervised Visual Representation Learning with SwAV
SwAVの再実装(TensorFlow)を行いながら解説してくれている記事