- 2020/10/24: 公式実装の追加
オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介していますので、人工知能のことをもっと知りたい方などは @omiita_atiimoをご覧ください!
他にも次のような記事を書いていますので興味があればぜひ!
画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説!
遂に訪れてしまいました。今度こそ本当に畳み込みがさよならしてしまうかもしれません。提案モデルの名前はVision Transformer、通称ViTです。ViTは、Transformer[拙著解説]をほぼそのまま画像分類タスクに用いることで、ImageNet/ImageNet-ReaL[拙著解説]/CIFAR-100/VTABでSoTAモデルと同程度またはそれを上回る性能を達成したのです。しかもSoTAモデルたち(BiT[拙著解説]/NoisyStudent[拙著解説])と比べて計算コストは$\frac{1}{15}$程度にまで落としています(SoTAをさらに上回ったモデルでも$\frac{1}{4}$~$\frac{1}{5}$程度にまで落としてる)。今回取り扱う論文はICLR2021のOpenReviewで登場しまだレビュー中ではありますが、NLPでTransformerがRNNを駆逐したように、画像認識でもTransformerがCNNを駆逐するのではないかということでものすごく注目されています。それでは期待の新モデルViTについて見ていきましょう。

本記事の流れ:
- 忙しい方へ
- Vision Transformerの解説
- Vision Transformerによる実験結果
- まとめと所感
- 参考
原論文: "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
公式実装: JAX/FLAX
実装: PyTorch(非公式)
| 略称 | 名称 |
|---|---|
| ViT | Vision Transformer |
| BiT | Big Transfer |
| LN | Layer Normalization |
| SA | Self Attention |
0. 忙しい方へ
- 完全に畳み込みとさようならしてSoTA達成したよ
- Vision Transformerの重要なことは次の3つだよ
- 画像パッチを単語のように扱うよ
- アーキテクチャはTransformerのエンコーダー部分だよ
- 巨大なデータセットJFT-300Mで事前学習するよ
- SoTAを上回る性能を約$\frac{1}{15}$の計算コストで得られたよ
- 事前学習データセットとモデルをさらに大きくすることでまだまだ性能向上する余地があるよ

1. Vision Transformerの解説
Vision Transformer(=ViT)の重要な部分は次の3つです。
- 入力画像
- アーキテクチャ
- 事前学習とファインチューニング
それぞれについて見ていきましょう。
1.1 入力画像
まず入力画像についてです。ViTはTransformerをベースとしたモデル(というより一部を丸々使っている)ですが、そんなViTに画像をどうやって入力するのでしょうか。まず、Transformerでは各単語がベクトル表現となっている文を一気に入力していましたね。

しかし今回はTransformerで画像を扱いたいです。どうすれば良いのでしょうか。
答えは簡単で、下図のように画像をパッチに分けて各パッチを単語のように扱うだけです。

各パッチを単語のように扱うので、実際はパッチをベクトルにFlattenしています。下図では左から2枚目のパッチに対する例のみを示していますが、全てのパッチが同様にベクトルへとFlattenされてからエンコーダーへと入力されています。

最後にこれを記号を用いて表します。元画像が$\mathbf{x}\in\mathbb{R}^{H\times W\times C}$だとすると、FlattenしてからViTに入力するということは $\mathbf{x}_p\in\mathbb{R}^{N\times (P^2\cdot C)}$というベクトルにしてから入力するということです。ここで$N$はパッチ数で、$P$はパッチの大きさになります。ここでパッチは正方形であり、$N$はつまり$N=HW/P^2$とも表せます。上図で元画像のサイズが256だとすると、$N=4, P=128$ということになります。それではアーキテクチャを見てみましょう。
1.2 アーキテクチャ
1.2.1 アーキテクチャの説明
続いてアーキテクチャに入っていきます。と言っても、ほぼTransformerのエンコーダーと同じです(つまり、ほぼBERT[拙著解説]です)。エンコーダーの中身は下図のようになっています。参考までに[Vaswani, A.(NIPS'17)]で提案されたオリジナルのTransformerのエンコーダーも右上に載せました。

"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)改変
ここでNormはLayer Normalization(=LN)[Ba, J.(2016)]を指しています。上図を見るとわかるように、ほぼオリジナルのエンコーダーと同じです。ただオリジナルとの相違点は2つあり、
- Pre-Norm[Wang, Q.(ACL'19)]: NormがMulti-Head Attention / MLPの前に位置する。
- GELU[Hendrycks, D.(2016)]:MLPは2層で活性化関数にGELUを採用(BERTも同様。オリジナルはReLUを使用。)。
くらいです(他にもあればツイッターかコメントで教えて下さい!)。
上図で、ViT Encoderの入力を見ると "Embedded" Patchesとなっています。つまり、第1ブロック目のViT Encoderへの入力は「1.1入力画像」で用意したPatchベクトルたちをさらに埋め込んだものになります。これもオリジナルTransformerと同様です。ここでの埋め込みには、$\mathbf{E}\in\mathbb{R}^{(P^2\cdot C)\times D}$と(ViTはSelf-Attentionのみのためパッチの位置情報がないため、)位置エンコーディング$\mathbf{E}_{pos}\in\mathbb{R}^{(N+1)\times D}$の2つを用います。具体的には次のように用います。
- $\mathbf{E}$で各パッチを長さ$(P^2\cdot C)$から$D$のベクトルに埋め込む
- 各パッチに位置エンコーディング$\mathbf{E}_{pos}$を加算
ここでもしかしたら、位置エンコーディングの$\mathbf{E}_{pos}$が$\mathbf{E}_{pos}\in\mathbb{R}^{(N+1)\times D}$のようにパッチ数の$N$ではなく、$(N+1)$となっていることに気づいた方も居るかもしれません。これは、実は$\mathbf{E}$で埋め込んだ後に実は入力の先頭に[CLS]トークンを連結するからです。これはBERTと全く同じですね。[CLS]トークンにも位置エンコーディングを足すので「パッチ$+$[CLS]$=N+1$」となるわけです。ちなみに位置エンコーディングも学習可能になっています。画像分類では[CLS]トークンの出力を識別器(MLP)に入れることで最終的な予測が出せます。ここまでを全てまとめると下図のようになり、ViTが完成します。
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
1.2.2 式でまとめ
ここまでの流れを式でまとめます。式と言ってもここまで理解していればかなり単純です。
1.2.2.1 パッチの埋め込みと位置エンコーディング
\mathbf{z}_0 = [\mathbf{x}_{\text{class}};\ \mathbf{x}_p^1\mathbf{E};\ \mathbf{x}_p^2\mathbf{E};\ \cdots;\ \mathbf{x}_p^N\mathbf{E}] + \mathbf{E}_{pos}, \qquad \mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times D}, \mathbf{E}_{pos} \in \mathbb{R}^{(N + 1) \times D} \tag{1}
$\mathbf{x}_p^k$は$k$個目のパッチを表しています。上述したとおり、各パッチ$\mathbf{x}_p^k$を$\mathbf{E}$で埋め込み、[cls]トークンを連結したのち、位置エンコーディング$\mathbf{E}_{pos}$を加算しています。ちなみに $\mathbf{E}$の代わりにResNetで各パッチを埋め込んでも良さそうです。この場合、パッチはFlattenさせずにResNetへと入力し、その出力に対してFlattenを行います。論文中ではパッチの最初の埋め込みにResNetを用いる手法のことをハイブリッドと呼んでいます。
1.2.2.2 エンコーダー
\begin{align}
\mathbf{z}'_l &= \text{MSA}(\text{LN}(\mathbf{z}_{l - 1})) + \mathbf{z}_{l - 1}, & l &= 1 \ldots L \tag{2} \\
\mathbf{z}_l &= \text{MLP}(\text{LN}(\mathbf{z}'_l)) + \mathbf{z}'_l, & l &= 1 \ldots L \tag{3}
\end{align}
式(2)はマルチヘッドAttentionを表し、式(3)はMLPを表しています。しっかりとスキップ結合も行われていますね。
1.2.2.3. MLPヘッド
\mathbf{y} = \text{LN}(\mathbf{z}_L^0) \tag{4}
そして最後に式(4)です。$\mathbf{z}_L^0$は最終層の出力における前から0番目のベクトル表現のことなので、つまり[cls]トークンの最終出力ですね。これをLNに入れて、$\mathbf{y}$を得ます。MLPヘッド自体の式は論文中には出てこないのですが、あとはこの$\mathbf{y}$をMLPに入れるだけで最終的な予測まで出せます。これでアーキテクチャの説明は終わりになります。
1.3 事前学習とファインチューニング

ここではViTの重要な部分の3つ目の事前学習とファインチューニングについて説明します。ViTでは、今までの画像認識モデルたちと同様に 「巨大なデータセットで事前学習 + ファインチューニング」 という手順で学習をします。ファインチューニングの際には、ViTのMLPヘッドを取り替えます。このほかに3点ほど工夫を加えています。
- 事前学習時の解像度(e.g 224)よりもファインチューニング時の解像度を大きく(e.g 384)する。[Touvron, H.(NeurIPS'19)]
- パッチの大きさは事前学習とファインチューニングで一定。(つまり、ファインチューニング時は解像度が大きいのでパッチの数が増える。)
- 事前学習で学習した位置エンコーディングはファインチューニング時には足りないところを内挿で補う。
これだけです。それではこのViTがどれだけすごいのかを実験で見てみましょう。
2. Vision Transformerの実験結果
2.1 実験条件
ViTでの実験ではImageNetが小規模データセットとして扱われています。規模がドデカすぎます。
-
データセット:
-
事前学習:
- ILSVRC-2012 ImageNet: 小規模。クラス1,000個の計130万枚。
- ImageNet-21k: 中規模。クラス21,000個の計1,400万枚。
- JFT-300M: 大規模。クラス18,000個の計3億枚。Googleにあるプライベートデータセット。
- ファインチューニング:
-
事前学習:
-
モデル:
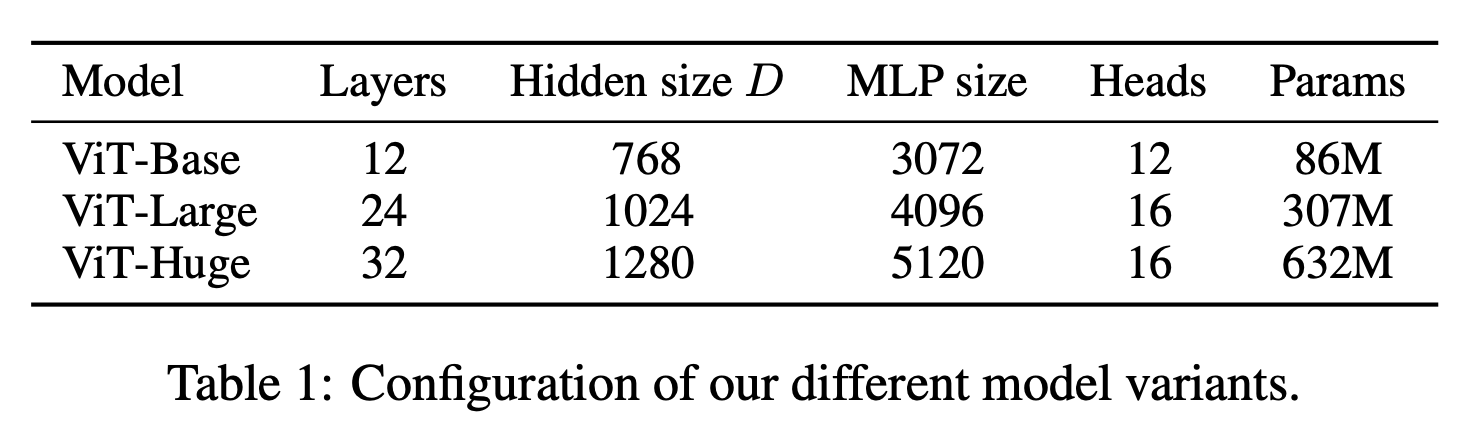
モデルはBase(B)/Large(L)/Huge(H)の3つを用います。層の数などもBERTに倣ってますね。それにしてもHugeのパラメータ数6億は化け物です。
| 事前学習 | ファインチューニング | |
|---|---|---|
| オプティマイザー | Adam | モーメンタム付きSGD |
| バッチサイズ | 4096 | 512 |
| 画像サイズ | 224 | 384(†) |
- (†) ImageNetでのファインチューニングでのみ画像サイズに512や518が用いられています。
- ViT-Hにおいてのみ重みは係数0.9999の移動平均[Polyak, B.(1992)]になっています。(こちらの記事がわかりやすかったです。)
- モデルは「ViT-(1)/(2)」という名前で表され(1)にはモデルサイズB/L/Hが入ります。(2)にはパッチの大きさの16や14などが入ります。ViT-L/16であればViT-Largeで入力画像のパッチの1つの大きさが16であるモデルのことです。
- (余談ですが、ImageNetを小規模と言っているのに驚きました。)
実験は大きく分けて以下の3つです。
- SoTAとの比較
- 事前学習の考察(データサイズや計算コスト)
- ViTの考察
2.2 SoTAとの比較
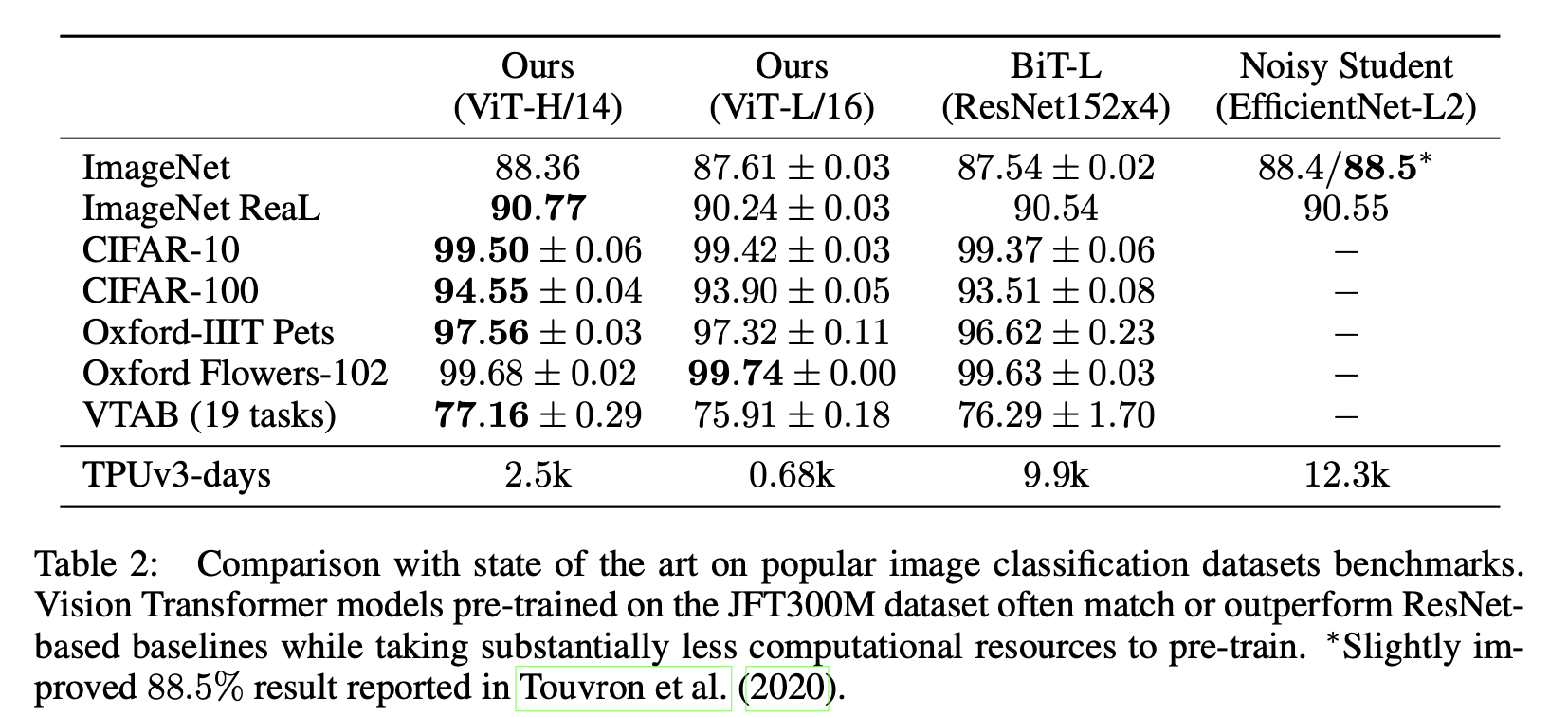
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
まずViT-H/14とViT-L/16をJFT-300Mで事前学習させた場合の結果をSoTAモデルのBiT-LとNoisyStudentと比較します。SoTAモデルたちはもちろんCNNです。上表を見ると一目瞭然で、ほぼ全てでVision TransformerがSoTAを更新してしまっています。CIFAR-100においては1%も更新しています。ただImageNetにおいてNoisy Studentにわずかに及んでいませんが、より正確にアノテーションされたReaLでは上回っているのでViTの方が優れていると言えそうです。
また、ViTは計算時間も大幅に削減しています。上表のTPUv3-daysはJFT-300Mでの事前学習にかかった時間を表しています。BiTとNoisyStudentではおよそ1万TPUv3-日かかっていたものが、ViT-H/14では約$\frac{1}{4}$~$\frac{1}{5}$ほどにまで削減されViT-L/16においてはBiT-Lよりも少し良い性能が約$\frac{1}{15}$程度の日数で得られています。(と言ってもViT-H/14は2,500TPUv3-日もかかるので私のような庶民には再現性皆無です。)
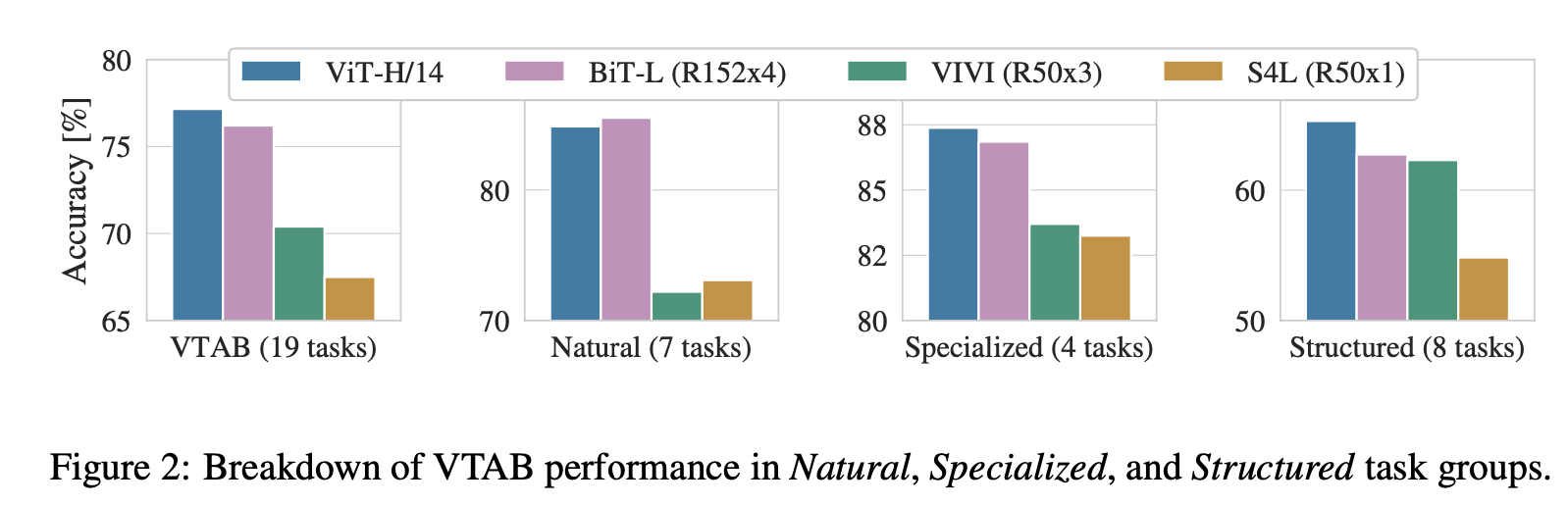
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
さらにVTABのNatural/Specialized/Strucuterdそれぞれでの性能を比較してみます。比較にはViT-H/14とBiT-Lの他にVTABにおいて前までSoTAだったVIVI[Tschannen, M.(CVPR'20)]とS4L[Zhai, X.(ICCV'19)]の4つを用いています。上図を見るとVTAB全体/Specialized/StructuredではViT-H/14が最も良いことがわかります。NaturalにおいてのみBiT-Lに少し劣ってしまっていますが、論文ではこれを誤差の範囲内としています。このようにViTは幅広い転移学習でとても有効であることがわかりますね。
2.3 事前学習の考察
さきほどJFT-300Mという巨大なデータセットで事前学習した結果、見事ViTでSoTAを達成することができました。それでは事前学習で用いるデータセットのサイズはどれほど重要なのでしょうか。また、上述したHybrid(=入力パッチをResNetで埋め込むViT)とのコスパも比較してみます。
2.3.1 事前学習でのデータセットサイズ
まず、事前学習のデータセットとしてImageNet(小)/ImageNet-21k(中)/JFT-300M(大)をそれぞれ用いた場合の、ImageNetへのファインチューニングの性能を見てみます。

"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
比較としてBiTでの結果(BiT-Lともう1つはここを参考にするとResNet50っぽいです。)も示されています。ここから言えるのは、ViTは小さいデータセットでの事前学習ではあまりよくはないが、巨大なデータセットで真価を発揮するということです。ViTの事前学習には巨大なデータセットが必須なようですね。
続いて事前学習のJFT-300Mを小さくした場合でも実験をしています。ここではJFT-300Mのうち9M/30M/90M/300Mを用いた場合の結果は以下図です。

ViT-bとは、ViT-Bの幅(つまり、隠れ層の次元)を半分にしたものだそうです。こちらでも先ほどと同じような傾向が見られ、90M以上でViTが本領発揮してくることがわかります。一方で9MではViTはボロボロですね。ここから言えることは、畳み込みが持つ「局所性」のようなバイアスはデータ数が少ない場合には有効だが、データ数が大きい場合にはむしろ不要となるということです。これはおもしろいですね。
2.3.2 Hybridとのコスパの比較
Hybridとのコスパ比較も見てみましょう。大小様々なResNet(5つ)/ViT(6つ)/Hybrid(4つ)をJFT-300Mで事前学習させます。この時の計算量と転移学習での精度をプロットしたものが下図です。転移学習の結果はAverage-5(左図)とImageNet(右図)のものです。ここで、Average-5がどの5つかという言及は論文中にはありませんでしたが、ImageNet/CIFAR10/CIFAR100/Pets/Flowersの5つのデータセットに対する平均値だと思われます(表2の値からそう思われます)。
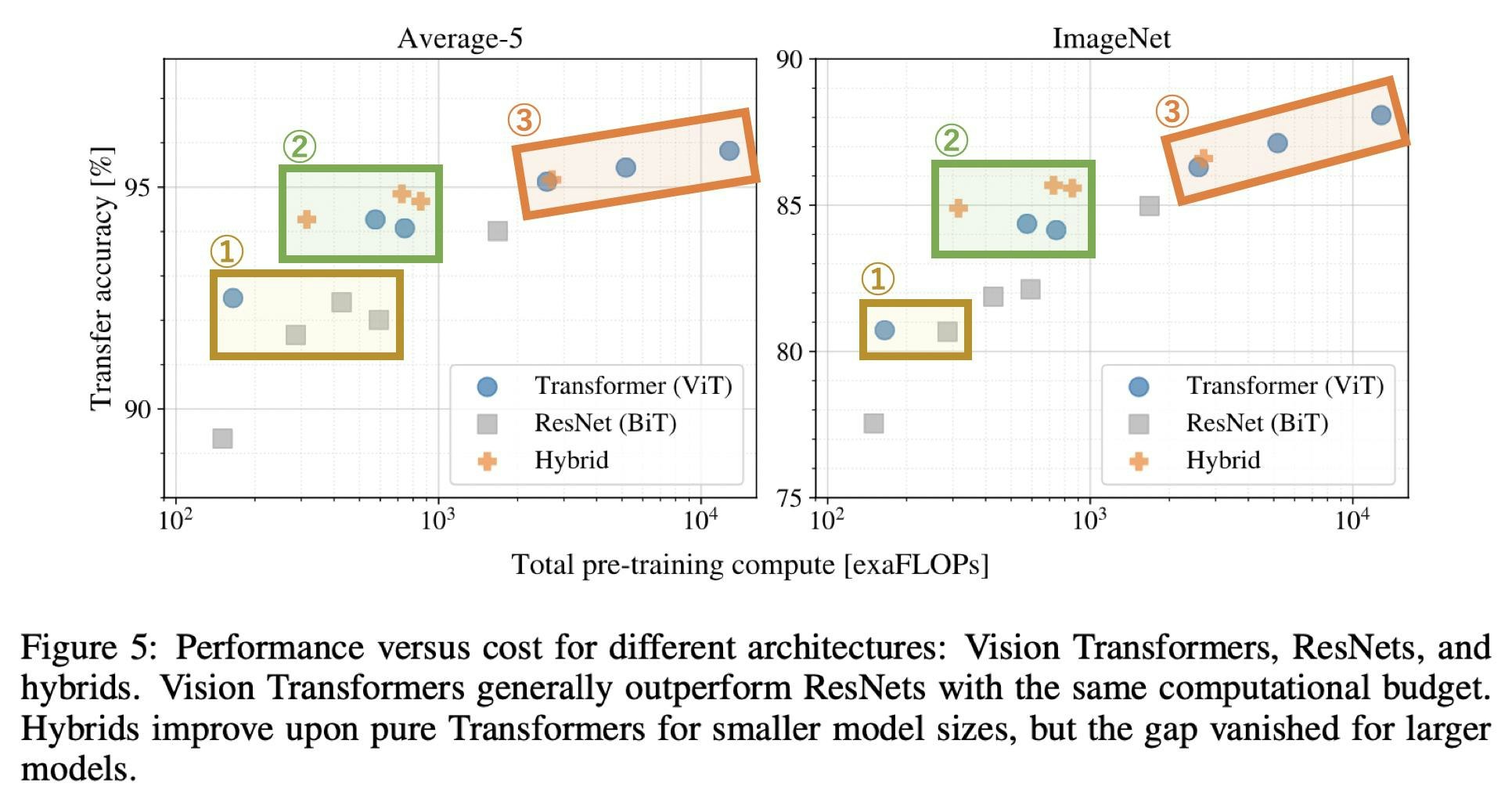
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)改変
この図から言えるのは3つあります。上表の番号が下の3つに対応しています。
- ViTはBiTよりもコスパが良い。(低コストで同じ性能を達成)
- コストが限られている場合はHybridが有効。(高コストではHybridもViTも差がなくなる)
- ViTがまだ飽和しておらず、さらなる性能向上が期待できる
2.4 ViTの考察
ViTについて理解するためにさらなる分析を行っています。ここでは次の4つを行っています。
- ViTの埋め込み層
- ViTの位置エンコーディング
- Attentionの適用範囲
- 自己教師あり学習
2.4.1 ViTの埋め込み層

"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
ViTでは初めに埋め込み層を用いていました。その埋め込み層で学んだものを可視化したものが上図になります。一切畳み込みを用いていないのにもかかわらず、横線や縦線などCNNの低レイヤーで学ぶようなものをしっかりと学習できています。
2.4.2 ViTの位置エンコーディング
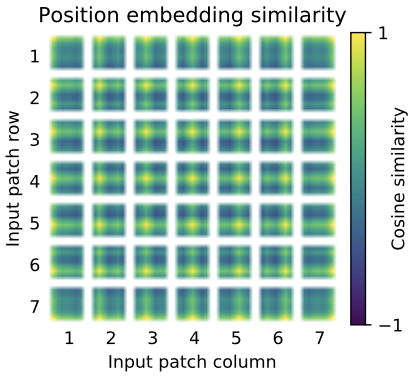
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
ViTでは埋め込んだあとにさらに学習可能な位置エンコーディングを加算していました。位置エンコーディング同士がどれだけ似ているのかを表しているのが上図です。ぱっと見では少しわかりづらいかもしれないので、例を用いてこの図の見方を説明します。
そもそも上図はViT-L/32を用いた時の位置エンコーディングを表しており、上図からも1枚の画像に対するパッチ数が全部で49個(=7x7)あることがわかります(つまり元画像の大きさは32x7=224なので224x224と推測されます)。ここで、上図内の位置(1,1)(つまり一番左の一番上)にある1マスを見てみましょう。そこだけを抜き出すと下図です。

"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
これは、位置(1,1)の位置エンコーディングと他の位置たちの位置エンコーディングたちとの類似度を全部表したものになります。上図を下のように書けばもっとわかりやすいと思います。

"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)改変
これは上述したように位置(1,1)と他の位置たちとのコサイン類似度を表していおり、上図の(1,1)は自分自身ですのでもちろん1(黄色)となっています。一方で位置(7,7)は遠いのでしっかりと類似度が低く(濃い緑色)なっていますね。ここで位置(1,1)と同じ行または列の位置エンコーディングは比較的似ています(黄緑色)。この同じ行/列の位置エンコーディング同士は似るという傾向は、いずれの位置でも見られます。その証に、先ほどの全体像に戻るとどのマスも十字のような模様が出ていますね。これがまさに、同じ行/列の位置エンコーディング同士は似た値になるように学習されていることを表しています。
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
2.4.3 Attentionの適用範囲
ViTはAttentionをフルに使っています。畳み込みと比較してAttentionの良さの1つに全体を俯瞰できることがあります。実際にViTはAttentionを用いて画像全体を俯瞰しているのでしょうか。それを調べるためにまず論文では「Attention距離」というものを定義しています。Attention距離とは、AttentionスコアによるAttention適用位置の加重和になっており、感覚的にはある位置から遠い位置ばかりAttentionスコアが大きい場合にはAttention距離も大きくなり、逆に近い位置たちにばかりAttentionスコアが偏っていたらAttention距離も小さくなります。つまり、Attention距離はCNNで言うと「Receptive Fieldの大きさ」 ということになります。
このAttention距離を各層のヘッドごとに表したものが下図になります。横軸が各層、縦軸がAttention距離で点がヘッドを表しています。
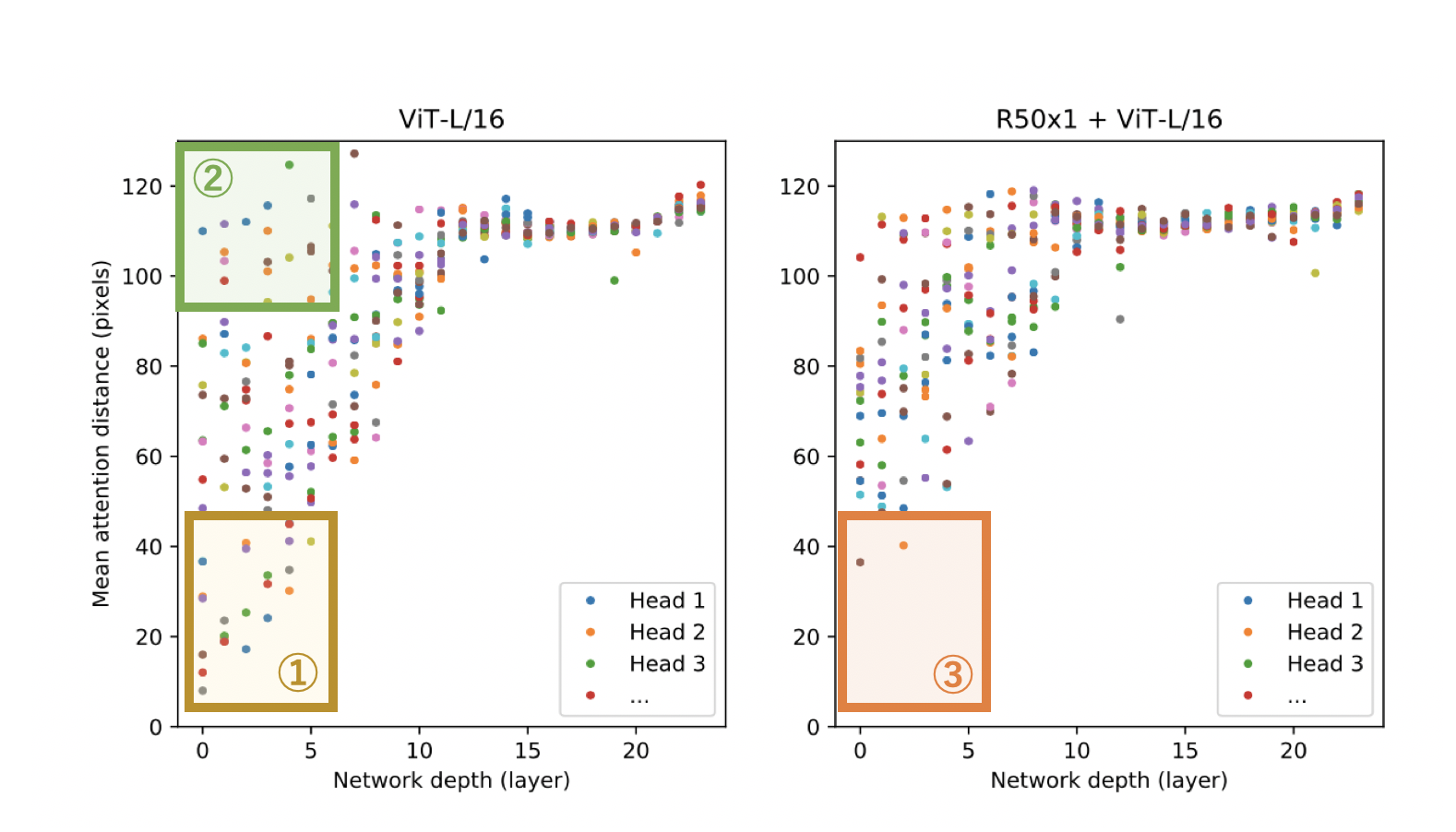
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)改変
左図がViT-L/16で右図がHybridを表しています。この図から言えることは3つです。下の番号は上図内の番号と対応しています。
- 低レイヤーではAttention距離が小さいヘッドが一定数存在する。つまり、低レイヤーではCNNのように局所的な特徴量を抽出している。
- 低レイヤーでもAttention距離が大きいヘッドが一定数存在する。つまり、低レイヤーでは大域的な特徴量も抽出している。
- Hybridの低レイヤーではAttention距離の小さいヘッダーが激減することからも、低レイヤーでのAttention距離が小さいヘッドたちはCNNのような役割を果たしていたことがわかる。
2.4.4 自己教師あり学習
最後に、論文ではJFT-300Mのラベルをフルに用いた事前学習の代わりにBERTにならってMasked Patch Predictionによる事前学習も行っています。これによりMasked Patch Predictionで事前学習したViT-16/BがImageNetをスクラッチから学習させたモデルよりも2%ほど高い性能を示したようですが、JFT-300Mのラベルをフルに用いた事前学習よりは4%低い結果になったようです。ただ、BERTに倣っただけのMasked Patch Predictionで性能向上が認められたので、より最適な自己教師あり学習による事前学習タスクを探すことで、この先JFT-300Mのようなラベル付けにかなりのコストがかかるデータセットを必要とせずにかなり高い性能が得られる可能性があります。
3. まとめと所感
今回こそ文句なしで畳み込みを一切使わないモデルが完成し、しかもSoTAを達成しています。これからは画像認識でもTransformerが猛威をふるってきそうです。次はモデルサイズも事前学習のデータセットサイズもさらに大きくしたBig-ViTなどが出てくるのでしょうか。個人的にはこのViTを小さくしていく方向で研究が行われて欲しいですが、これからの画像認識にも目が離せないことは間違いないですね!転移学習で高い性能を示しているので重みが公開されるのが楽しみです。非公式ではありますが実装(PyTorch)もあるので、そちらもご覧ください!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
こちらもどうぞ:
4. 参考
-
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale",(2021)
原論文 -
The Visual Task Adaptation Benchmark
VTABデータセットについてのGoogleの記事。 -
Polyak Averaging
モデルの重みを移動平均を用いながら決定する手法についての記事。 -
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Paper Explained)
論文解説動画。