オミータです。ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽に@omiita_atiimoをフォローしてください!
画像認識の定番データセットImageNetはもう終わりか
2012年にAlexNet[Krizhevsky, A.(2012)]が登場してから、画像認識分野での発展は著しい。その発展を支えてきたものこそ大規模データセットImageNet[Deng, J.(2009)]である。ImageNetでSoTAを達成すると、そのモデルには最強モデルの称号が与えられると言っても過言ではない。2020年6月にGoogle Brainによって出されたこの論文は、そんな当たり前に使われてきたImageNetデータセットに対して疑問符を叩きつけるものとなっている。現存のImageNetでの性能評価が必ずしも正しいのだろうか。この論文を通してその答えを探しにいく。
本論文で使われているImageNet評価用データセットの新たなラベルReaLはこちらで公開されています。
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
流れ:
- 忙しい方へ
- 論文解説
- まとめと所感
- 用語と補足
- 参考
原論文: Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
0. 忙しい方へ
-
ImageNetのアノテーションの手順には次のような問題があるよ
- 1つの画像にラベル1つしかつけられないよ
- アノテーション時の候補ラベルが1つしかなくて限定的すぎるよ
- 似たようなクラスが複数個存在するよ
-
ImageNetをより正しくアノテーションする手順を次のように提案したよ
- 19個の画像認識モデルの予測ラベルをそれぞれ候補ラベルとするよ
- 候補ラベルが画像に存在するかどうかを各画像につき5人に判断してもらうよ
- 5人の判断結果をもとに最終的なラベル(=ReaL)を決定(複数物体を含む画像は複数ラベル)
- **より正しいラベルReaL**を用いて、今までのモデルたちを再評価したよ
- 最近のモデルたちはImageNetに存在するバイアスに過学習することで精度向上してしまっているよ
- モデルのTop-2/-3予測ラベルも用いることで、ReaLでのより厳しい評価を行なえるよ
-
ImageNetによる学習方法自体を改善させて精度向上したよ
- Softmaxではなく、Sigmoidを用いた二値分類タスクとして捉えるよ
- 最新モデルを用いてImageNetの訓練データからノイズとなりうる画像を予めさよならさせるよ
- タイトルへの回答は「現状のImageNetはもうそろそろ終わりだが、ReaLラベルを用いることでまだしばらくはImageNetによるベンチマークを行なえる」だよ。
1. 論文「Are we done with ImageNet?」解説
1.0 要約
ImageNetはもう用済みなのだろうか。答えはイエスでありかつノーである。
本論文ではImageNetの評価用データセットに対してより正確にアノテーションを再度行ない、最近の画像認識モデルを再評価した。
その結果、以下の3つがわかった。
- 最新モデルたちによる現状のImageNetにおけるゲインは実際はもっと小さい
- 画像認識モデルの性能評価にImageNetを用いるのはそろそろ終わりに近づいている可能性がある
- 新たなImageNetこそが画像認識ベンチマークとして適している
1.1 導入
AlexNetが登場してから約10年もの間、ImageNetは画像認識モデルの性能評価には欠かしてはならないデータセットとなった。その理由の一つに、ImageNetでSoTAを達成したモデルたちは他のタスクでも同様に高い性能を示してきたことがある。
しかし、ImageNetに対して高い性能を示している最近のモデルたちにも同じような汎用性が見られるのだろうか。
そのため、本論文では、様々なモデルによる予測結果も利用した新たなアノテーション方法により、ImageNetに対して改めてラベル付けを行なった。その際に用いたラベルたちをReassessed Labels、略してReaLと呼ぶ。
この新たなラベルReaLを用いて現在までの画像認識モデルたちの性能を再評価したところ、初期モデルではImageNetおよびReaLでのゲインは一致したものの、最新モデルになるにつれて一致しないことがわかった。
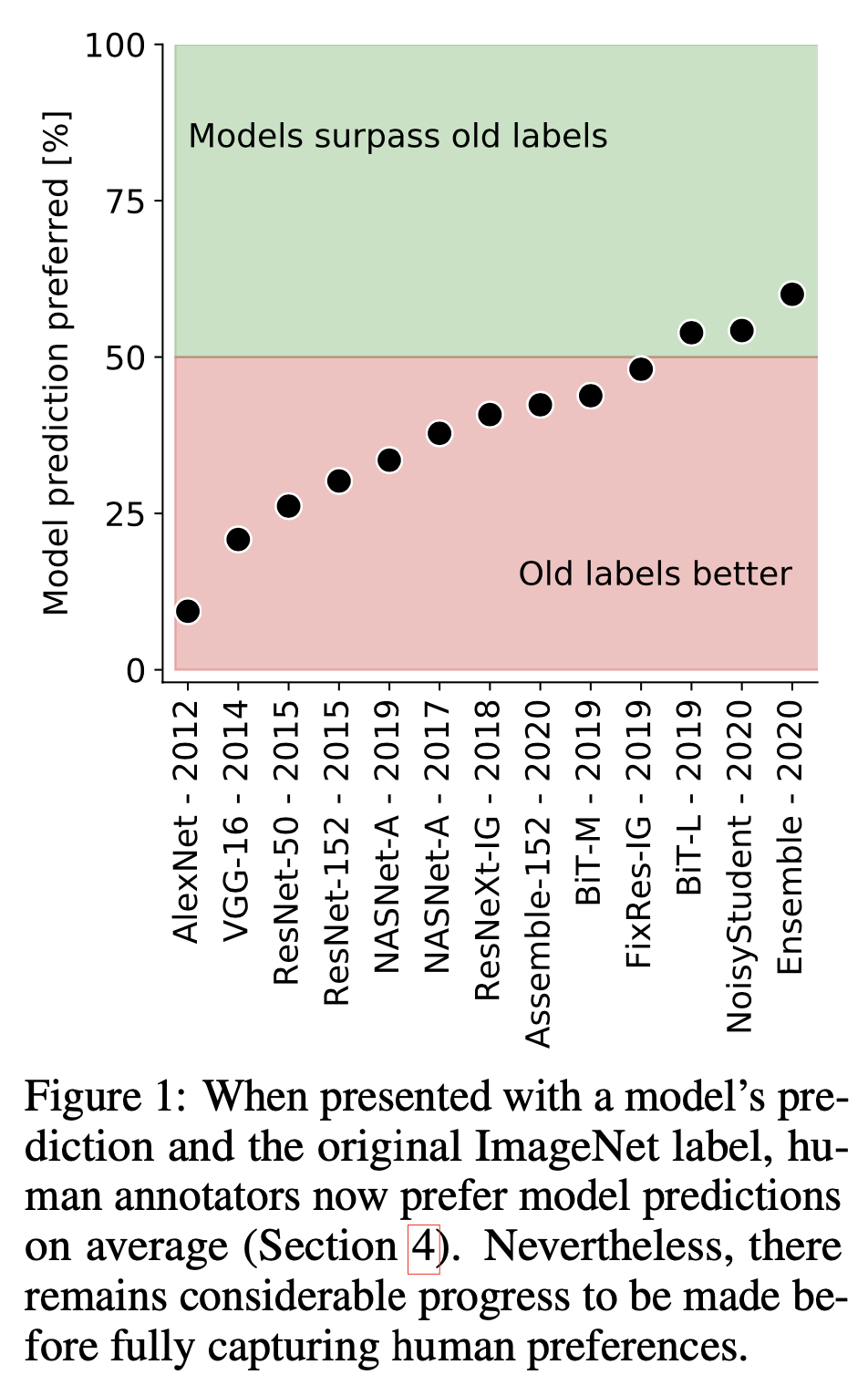
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
また、実際のImageNetのラベルよりも最新モデルによる予測ラベルの方が正確である場合が多くなっていることもわかった。上図の縦軸は、簡単に言うと各モデルによる予測ラベルの方が実際のImageNetラベルよりも正確であると人間が評価した割合を表している。最新モデルであるBiT-L[拙著解説]やNoisyStudent[拙著解説]などはその割合が50%を超えており、モデルの方がより適切なラベルを予測していることがわかる。(ImageNetのアノテーターよりも正確なラベルをモデルが予測している、ということ。すごい。ちなみに、Ensembleは図中のFixRes-IGとBit-LとNoisyStudentでアンサンブルした結果。)
さらに、ImageNetにおける精度とReaLにおける精度の違いを分析することで、今まで"精度向上"したとされるモデルのうちいくつかは、単にImageNetの誤ラベルに対して過学習を起こしたことによる"精度向上" だったことがわかった。
この論文の最後には、ImageNetおよびReaLいずれにおいてもさらなる精度向上が得られる2つの簡単な方法を提案する。
ここまでをまとめると、以下のようになる。
- 新たな方法でImageNetを再度ラベル付けし、そのラベルをReaLと命名。
- 最新なモデルほどReaLにおけるゲインが小さい
- 現状のImageNetラベルよりも最新モデルによる予測ラベルの方が正確なことが多い。
- いくつかのモデルは単にImageNetの誤ラベルへの過学習によって精度向上していた
- ImageNetおよびReaLのいずれでも精度向上が得られる方法を2つ提案
1.2 ImageNetのラベルの欠点
ImageNetはここまでにも述べてきたように、機械学習モデルを評価するためのランドマーク的存在となっている。しかし、そんなImageNetの画像の中には、1つの画像に複数の物体を含むようなものもあり、これにラベルを1つだけ付与するというのは少し違和感がある。そのため、いくつかのクラスはその曖昧さを含んでしまっている。この項では、ラベルに含まれるノイズの原因を探り従来のImageNetとは異なる新たなアノテーション方法を考案する。
1.2.1 1つの画像に1つのラベル

Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
現実の画像には1枚の画像にいくつかの物体を含むことがよくあるが、ImageNetではそういった場合でもラベルは1つだけしか付与していない。そのため、本来は当たっているはずの予測ラベルもたまたまImageNetのラベルと異なるために不正解となり、モデルに悪影響を与えるパターンが生じてしまう(上図)。
Old labelとは異なり、ReaLのように画像の多様性を捉えているラベルに変える必要がある。
1.2.2 限定的なラベル提案

Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
ImageNetのアノテーションは、まず、あるクラスをクエリとしてその画像をインターネットから集める。そして人間のアノテーターがその画像内にクエリのクラスが存在するかどうかを判断する。こうしてラベル付けが行われるが、このようにアノテーターへのラベルの候補が1つだけであるが故に、よりふさわしい他のラベルが見落とされてしまう(上図)。
そのため、アノテーターには複数のラベル候補から適切なものを選んでもらうようにする必要がある。
1.2.3 不明瞭なクラス分類

Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
ImageNetにはよくわからない区別をしているクラスがある。上図がその例だが、例えば"sunglass"と"sunglasses"である。
意味的に同じものを別々にすると当然モデルに悪影響を与えるため、1つの画像に複数のラベルを付与できるようにすることでこうした不明瞭なクラス分類をなくす必要がある。
1.3 ImageNet評価用データの再ラベル付け
上述した問題点を解決するような新たなアノテーション方法を提案する。
特に、アノテーター(人間)が複数の候補ラベルの中から最適なラベルを選ぶことができるようなもの。このとき、当たり前だが候補ラベルはなるべく少ない数に抑えたい。
1.3.1 広範囲の候補ラベル
ここでは画像に対する候補ラベルを生成する。モデルを19個使用するだけで、方法は至って単純。本来のImageNetのラベルと19個のモデルによるTop-1予測ラベルを全て用いるというもの。このとき、モデルの出力値によっては1つのモデルから複数のラベルを候補ラベルとすることができる。
これにより画像ごとに多くの候補ラベルが獲得できるが、少し多すぎる。この候補ラベルの数を減らすためにどのモデルのものを使うかを決める。手法は次。
まず、5人の専門家によってラベル付けされた256枚の画像を用意する。この256枚をゴールドスタンダードとして、これに対して97%以上のRecallでかつ最も高いPrecisionを示すモデルの組み合わせを全通りを試すことで探す。つまり、ゴールドスタンダードを使って19のモデルのうち最適なモデルの組み合わせを見つけるということ。これによって、6つのモデルに絞り各画像ごとの候補ラベルも平均で7.4枚にまで減らした。
1.3.2 人間による候補ラベルの評価
候補ラベルを生成したら、続いてそのうちどの画像を実際に人間のアノテーターに評価させるかを決める。
まず、先ほど絞ったモデルたちが全てオリジナルのImageNetのラベルと同じラベルを予測した場合、その画像は無条件にそのラベルを用いる。これにより、アノテーターに評価してもらう画像を50,000枚から24,889枚にまで減らすことができた。ただし、アノテーターに表示する候補ラベルが多すぎるとアノテーターに負荷がかかるため、候補ラベルを9枚以上持つ画像たちは、WordNetのクラスの階層にしたがって多段階のラベリングタスクにすることで、アノテーターは1回のラベリングにつき高々8個のラベル候補から選べば良い。これによって、ラベリングタスク自体は合計37,988個となった。

Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
それぞれのラベリングタスクにつき、5人のアノテーターが行なう。上図がラベリングタスクの1例で、実際の作業画面である。アノテーターは1枚の画像につき8枚までのラベル候補が表示され、それぞれのラベル候補が画像中に存在するかどうかを選択する。このときアノテーターはYES/NOのいずれかに95%以上の確信があればそれを選び、そうでない場合はMaybeを選ぶ。
1.3.3 アノーテータの評価に基づくラベルづけ
さきほどの5人のアノテータによる評価を用いる。例外的に動物画像のラベルはアノテータにごとに誤差が比較的大きいため、ImageNetのラベル自体を6人目のアノテーターとして用いる。これはImageNetが動物画像に対しては専門家によるアノテーションを間接的に行なっているためである。
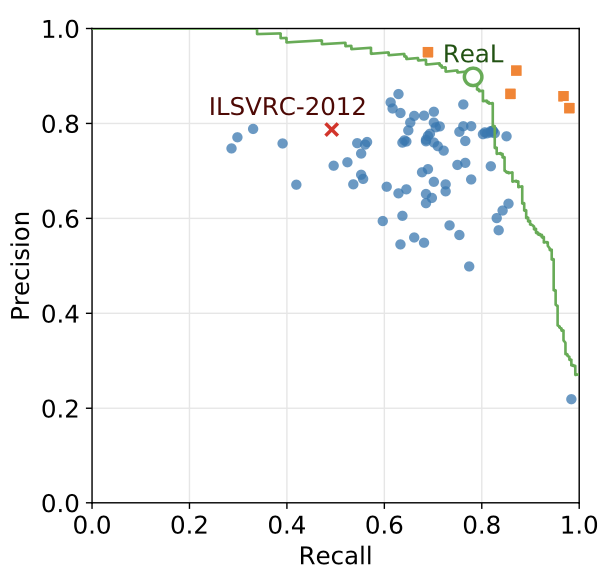
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
上図が最終的なアノテーションによるPrecision-Recallである。青は各アノテーターの結果を示し、オレンジは専門家によるアノテーションの結果を示している。ReaLとオリジナルのILSVRC-2012を比較すると、オリジナルラベルに比べReaLの方がより正確なことがわかる。ReaLは画像によっては複数個ラベルを有しているため、モデルの評価方法をReaL精度としモデルによる予測がReaLに含まれていれば正解とする。
1.4 SoTAモデルの再評価
ReaLを用いて、これまで出てきた代表的なモデルたちの精度を再度測る。その結果が下図。各黒点がモデルのImageNetとReaLそれぞれにおける精度を示し、赤点はImageNetラベルをそのままにした場合のReaL精度を表している。(ReaLで約90%なので、ImageNetのオリジナルラベルは10%ほど間違いを含んでいるということ。)
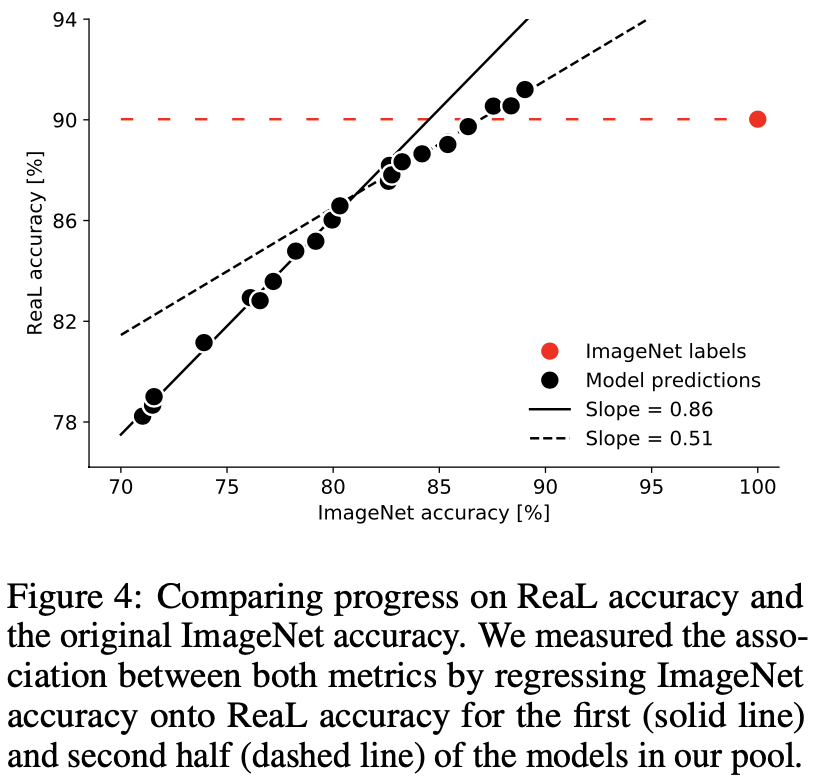
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
この図を見ると、初期モデルたちと最新モデルたちでそれぞれ傾向があることがわかる。初期モデルたちは、ImageNetでの精度とReaL精度との間にかなり強い正の相関を保持している(実線、傾き:0.86)が、最近のモデルたちはそれに比べると弱い正の相関となっている(破線、傾き:0.51)。また、モデルによっては赤破線を超えたReaL精度を出しておりImageNetのオリジナルラベルよりも正確なラベルを予測している。ここまでを踏まえて、最近のモデルたちはImageNetの間違っているラベルたちに過学習し始めてしまっている、と捉えることができる(この過学習については1.4.2で詳しく説明する)。こういったことからもImageNetをベンチマークとして用いるのはそろそろ終わらせたほうがいいのかもしれない。
1.4.1 複数ラベルの予測
ReaL精度というのは、モデルがある画像に対して許容できるラベルを予測しているかどうかを示すもの。さらにReaL精度に対してほぼ完璧な性能を示す時にはモデルによる2番目ないし3番目の予測ラベルの精度も考慮することで、より厳しい性能評価を簡単に行なうことができる。この評価方法が使用できる根拠として以下図を示している。
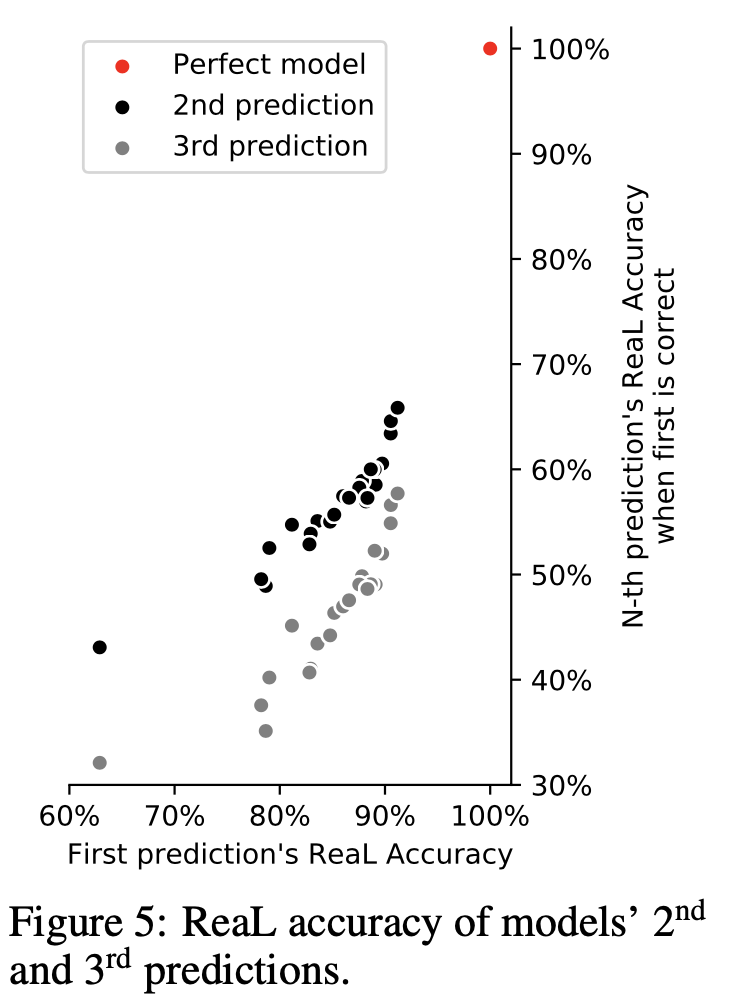
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
横軸はモデルのReaL精度を示しており、縦軸はTop-1予測ラベルが正解の場合にTop-2/Top-3予測ラベルもそれぞれどれだけ正解しているかを示している。Top-1のReaL精度に比べTop-2/-3予測ラベルのReaL精度が低く、モデルによるTop-1のReaL精度が高い場合Top-2やTop-3のReaL精度も高くなる傾向を有していることがわかる。この傾向を根拠に、より厳しい性能評価としてTop-2/-3ReaL精度を用いることを論文では提案している。
1.4.2 共起クラスの分析
ReaLでImageNetを再度ラベル付けした結果、全体の約29%ほどの画像が複数の物体を含む場合かまたは複数の類似ラベルを持つ物体を含む場合に当てはまった。(つまり、1画像に正解ラベルが複数存在するパターンは全体の29%。)
こうした複数ラベルを含む画像に対して、ImageNet学習済みモデルはどう答えるのだろうか。正解となるラベルのうち1つをランダムに答えているのか、それともImageNetのオリジナルのアノテーション手順に存在するバイアスも暗に学習した上でラベルを1つ答えているのか。
クラスごとの精度を計算するためにOracleモデルというのを定義する。このOracleモデルは、ReaLにおいて複数の正解ラベルを持つ画像たちに対してそのうちの1つをランダムに選ぶモデル。つまり、OracleモデルはReaLで決定されたラベルを1つランダムに選び、ImageNetラベルを正解ラベルとして精度を計算する。ImageNetにバイアスが存在しなければ、Oracleのようにランダムに正解ラベルたちから1つ選ぶモデルが一番良いはず。逆にOracleモデルよりも高い性能を示すモデルがあれば、それはImageNetにバイアスが存在することを示しており、そのモデルは不要なバイアスを学習しているだけということになる。より詳しい説明(と独自の解釈)はページ下の用語と補足に記した。以下図を見ると、最近のモデルがこのOracleモデル(黒線)よりも良い精度を出してしまっている。
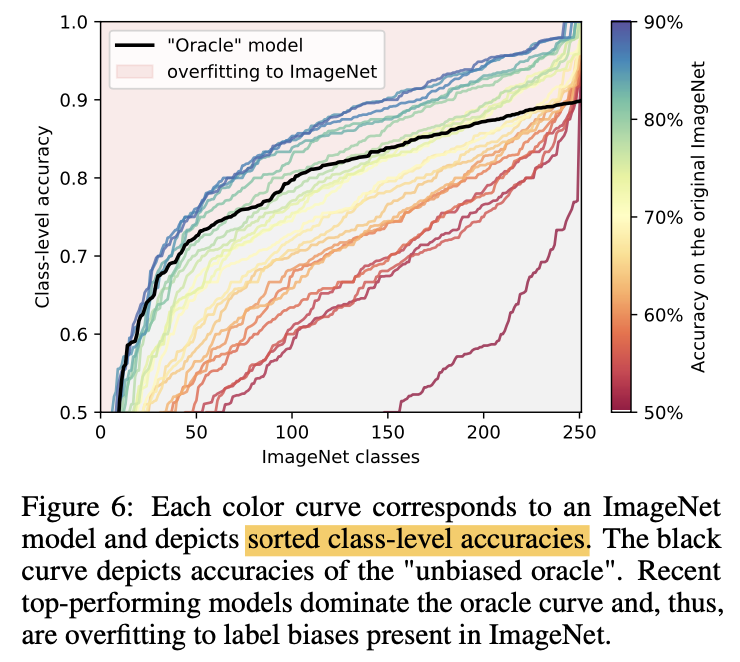
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
上図は各クラスごとの精度を表しており、横軸では精度が低いクラスから順に並べている。この時横軸に並べられているクラスはOracleモデルで精度90%以下のものまでで、動物の細かい種類を問うような画像は除いている(バイアスというより単なるアノテーションの間違いなどによってラベルの違いが出てくるから)。実線がそれぞれモデルのクラスごとの精度を示しており、最近のモデル(=ImageNetにおいて高い精度を示しているモデルたちで青色っぽい線たち)はOracleモデル(黒線)を遥かに上回っており、これこそがImageNetデータセットにバイアスが存在し、最近のモデルはそのバイアスを学ぶことで見かけ上の精度を上げていることを示している。以下表では最新モデル(Noisy Studentなど)がOracleを大きく上回っている具体的な例も示している。
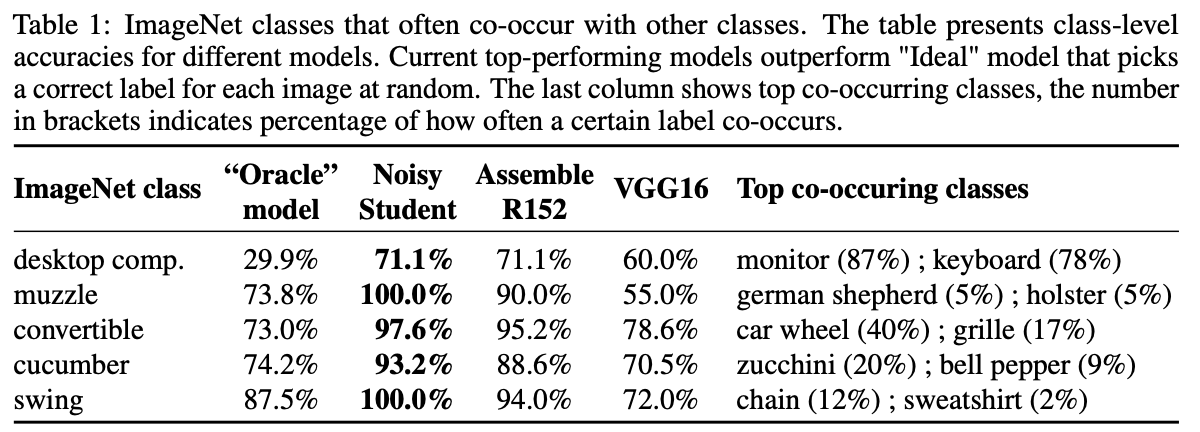
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
1.5 誤分類データの分析
モデルが「ImageNetのオリジナルラベルに対して誤分類したデータたち」と「ReaLに対して誤分類したデータたち」を用いて、ReaLの優位性をさらに確かめる。
誤分類したデータたちと予測ラベルを再び人間に見せて、次の3つに分けてもらった。
- 予測ラベルが間違っている(="Clear mistake")
- 予測ラベルは当たっている(="Not a mistake")
- いずれとも決めがたい(動物の細かい種類を答える画像などの難しいもの)(="Undiceided")
その結果が以下の図。横軸にモデルを精度の低いものから並べている。縦軸は回答数。
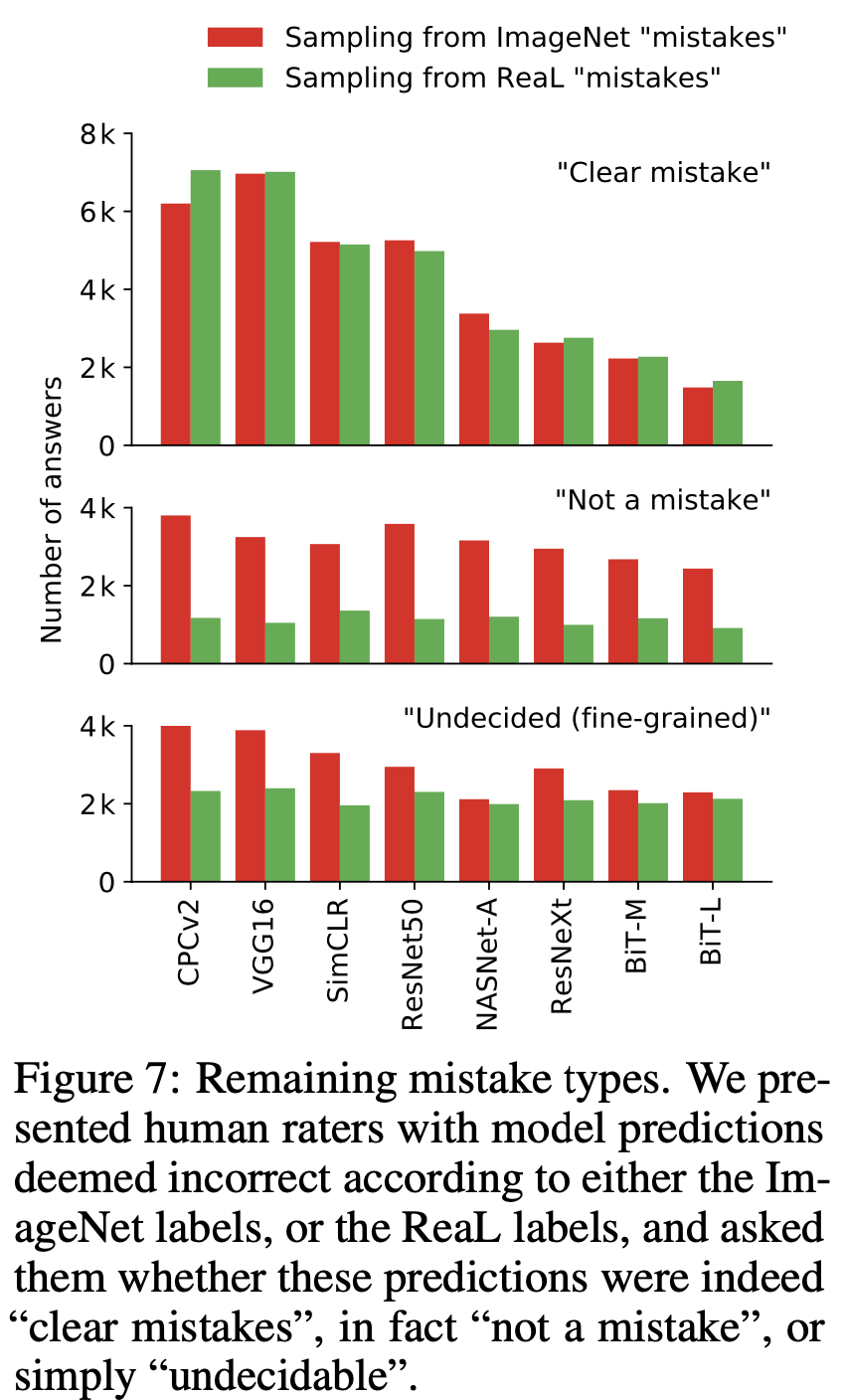
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
ここから言えるのは3つ。
- ReaLでの"Clear mistake"が少なくなっていることから、モデルは着実に改善されている。
- ReaLの"Not a mistake"が少ないことから、ReaLがオリジナルラベルよりも優れている。
- "Undecided"が一定数あることから、難しい画像のラベル付けには専門家を用いる必要がある。
1.6 ImageNetによる学習方法の改善
ImageNetの問題点は、画像が1つのラベルしか持たない、ということに特に由来する。モデルを学習させる際にも各画像にラベルを1つだけしか予測させないため、
同じような問題を含んでいる可能性がある。そのためモデル学習における解決策を2つ提案する。
1つ目は、モデルに複数予測を出力させる、というもの。複数ラベルそれぞれの2値分類としてとらえて、sigmoidを用いたクロスエントロピー誤差を逆伝搬させる。
2つ目は、最新モデルを用いたImageNet内のノイズラベル除去。冒頭で述べたように、最新モデルの予測結果の方がImageNetのオリジナルラベルよりも的確であることが多いため、ここでは、BiT-Lの予測ラベルとオリジナルラベルが異なる訓練画像は除去する。これにより、約90%のよりクリーンな訓練画像データが残った。
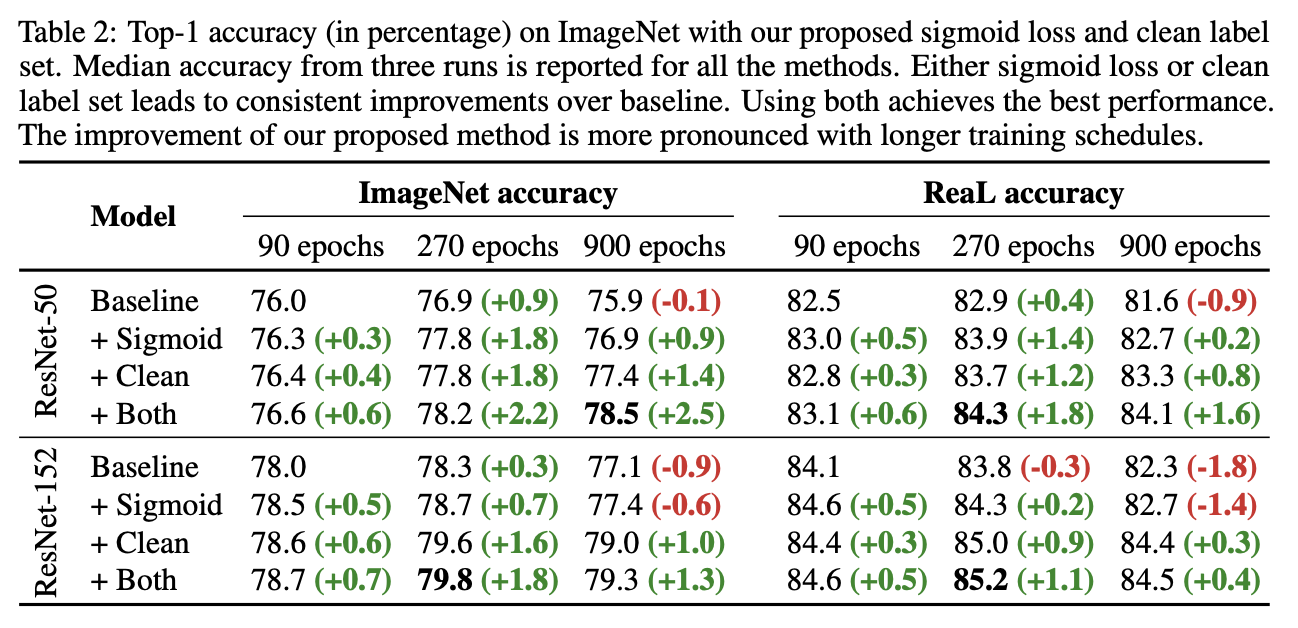
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
上表がこれらによる実験結果。Sigmoidが1つ目の手法、Cleanが2つ目の手法、Bothがどちらも用いた手法である。この表からわかることは次の4つ。
- クリーンな訓練画像データで学習させることで精度向上
- softmaxよりもsigmoidを用いた2値分類のほうが精度が高い
- Sigmoid + Cleanでさらなる精度向上
- 学習が長いと提案手法によるゲインがより大きい
1.7 結論
最近のモデルによる精度向上は、汎化性能の向上だけでなくImageNetへの過学習にも起因していることがわかった。そして、ImageNetの評価用データセットをより正確にラベル付けできるパイプラインを提案し、それによって新たなラベルReaL(=Reassessed Labels)を生成した。ReaLを既存のImageNetのラベルと比較することで、現在のImageNetではもうそろそろ使い物にならなくなることを示した。
また、ImageNetの欠点からモデルの学習自体を改善する方法を2つ提案し、さらなる精度向上を達成した。
タイトルへの答えはつまり、「現状のImageNetはもうそろそろ終わりだが、ReaLラベルを用いることでまだしばらくはImageNetによるベンチマークを行なえる」ということになる。
2. 所感とまとめ
これまでImageNetデータセットのおかげで画像認識モデルは大きな発展を遂げてきたが、今度は最新モデルがそのImageNetデータセットを改善させるというのが面白かった。確かに最近の画像認識モデルの論文を読んでいると精度向上のことだけでなく、もはやデータセットのラベルが曖昧であることを指摘しているものも出てきていたのでこの論文はそういった点でも興味深かった。100万枚以上の訓練画像を含むImageNetに過学習を起こし始めているのなら、訓練画像が50,000枚しかないCIFAR-10/100に対してはもうどうなってしまっているのかが気になる。(現時点(08/2020)ではCIFAR-10のSoTAはBiT-Lの99.37%という過学習ばんばん起こしていそうな値。)
3. 用語と補足
3.1 ImageNetのバイアスの補足説明
ImageNetのバイアスについてもう少しわかりやすく説明する(あくまで私自身の解釈なので間違っていれば指摘いただければありがたいです)。
ImageNetには{sunglass}と{sunglasses}のラベルがあり、ここではこれらを例に使って説明する。サングラスの画像であればいずれのラベルでも正解であるはずで、実際にReaLではサングラス画像には{sunglass, sunglasses}の両方のラベルが割り振られている。ただし、ImageNetにおいては1画像に1ラベルという制約があるため、いずれかしか割り振られていない。この時、どちらを割り振るかというのは完全に「なんとなく」であり、つまり、ImageNetにおいてはいずれか1つがランダムに割り振られているはずである。そのため、ReaLにおいて{sunglass, sunglasses}のラベルとなっているサングラス画像に対してImageNetのオリジナルのラベルを予測する場合、ランダムに{sunglass}か{sunglasses}のいずれか1つを選ぶようなOracleモデルは最適なモデルと言える。
Are we done with ImageNet?, Beyer, L., Hénaff, O., Kolesnikov, A., Zhai, X. and Oord, V. (2020)
それでは、もしもImageNetのラベリングにおいて例えば「サングラス単体の画像であればsunglassとなり、人が掛けている画像であればsunglassesとなっている傾向」が存在してしまっている場合はどうだろうか。このような傾向というのは全く本質的なものではなく、ImageNetに存在する不要なバイアスと言える。このようなバイアス(傾向)がImageNetに存在する場合に初めて、Oracleモデルを超えるモデルが誕生する余地が出てきてしまう。言い換えると、Oracleモデルよりも優秀なモデルが存在すれば、ImageNetにはバイアスが存在し、その優秀なモデルも実は優秀なのではなく単にImageNetのバイアスに過学習しているだけ、ということになるのである。実際にFigure6を見ると、最近のモデルはOracleよりも高い精度を示しているため、ImageNetにはバイアスが存在しかつ最近のモデルもImageNetに過学習を起こしているということができるのである。
Twitterで人工知能のことや他媒体で書いている記事などを紹介していますのでぜひフォロー@omiita_atiimoしてください!