オミータです。ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽に@omiita_atiimoをフォローしてください!
パラメータ数10億!最新の巨大画像認識モデル「BiT」爆誕 & 解説
2019年12月24日のクリスマスイブにarxiv上でGoogle Brainから新たな画像認識モデルが発表されました。その名も BiT(=Big Transfer)。その性能は2019年にGoogleが出したEfficientNet(拙著解説記事)を様々なデータセットで超えるほどで現在のState-of-The-Art になっています。驚くべきはそれだけでなく、なんとこのモデル、パラメータ数が10億にもおよぶ巨大なモンスターモデル になっています。そんなBiTについて早速この記事で解説していきたいと思います。バッチノームやドロップアウト、Weight Decayなどを使用していないという、 今までの画像認識モデルではデファクトで使っていた技術たちを使わずにSoTAを達成したのがおもしろい です。BiT-Mモデルが公開される ようです。
読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
流れ:
- 忙しい方へ
- 論文解説
- まとめと所感
- 用語と補足
- 参考
原論文: Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
0. 忙しい方へ
- 300万枚の画像を含む巨大なデータセットでResNetv2-151の幅を4倍にしたパラメータ数10億の巨大なモデルを事前学習してから、各タスクにファインチューニングしたらSoTA叩き出しまくったよ。
- 使用したデータセットの大きさによってBiT-S, BiT-M, BiT-Lのモデルがあるよ。SoTAはBiT-Lだよ。BiT-Mは公開 されるよ。
- ResNet-151ではバッチノーマライゼーションではなく、**「グループノーマライゼーション + 重み標準化」**を使っているよ。
- ついでにドロップアウトとWeight Decay使っていないよ。
- ファインチューニングの時に調整するハイパーパラメータはたったの3つだけに絞ったよ。
- 入力画像の大きさ
- MixUpの使用の有無
- 学習率スケジュール
- 上の3つを BiTハイパーパラメータ と呼んでいるよ。
1. 論文Large Scale Learning of General Visual Representations for Transfer解説
1.0 要約
大規模データで事前学習させてから、各タスクでファインチューニングさせるという従来の方法を使っている。このうち、事前学習のスケールアップ と Big Transfer(BiT)ハイパーパラメータの使用 により、大小様々な画像データでSoTAを達成。この論文では事前学習のスケールアップとBiTハイパーパラメータについて詳細に調査していく。
1.1 導入
ディープラーニングは画像分野で大きい成果を出しているが、そのためには大量のデータによる学習が必要で計算量が莫大である。そのため、各タスクでの計算量が極端に大きくなってしまう。これを解決しているのが転移学習(Transfer Learning)である。転移学習とは大規模データによって事前学習させ、その重みを初期値として各タスクで再度学習(Fine Tuning)させていく というものである。ここではそれぞれ上流(Upstream)と下流(Downstream)と呼ぶことにする。この事前学習+ファインチューニングという戦略には大きく2つ利点がある。
- 下流タスクにおいて少ないデータで高い成果が得られる
- ディープラーニングの莫大な計算量を上流タスクにだけ集中させられる
この論文では、事前学習+ファインチューニング の戦略に注目していく。
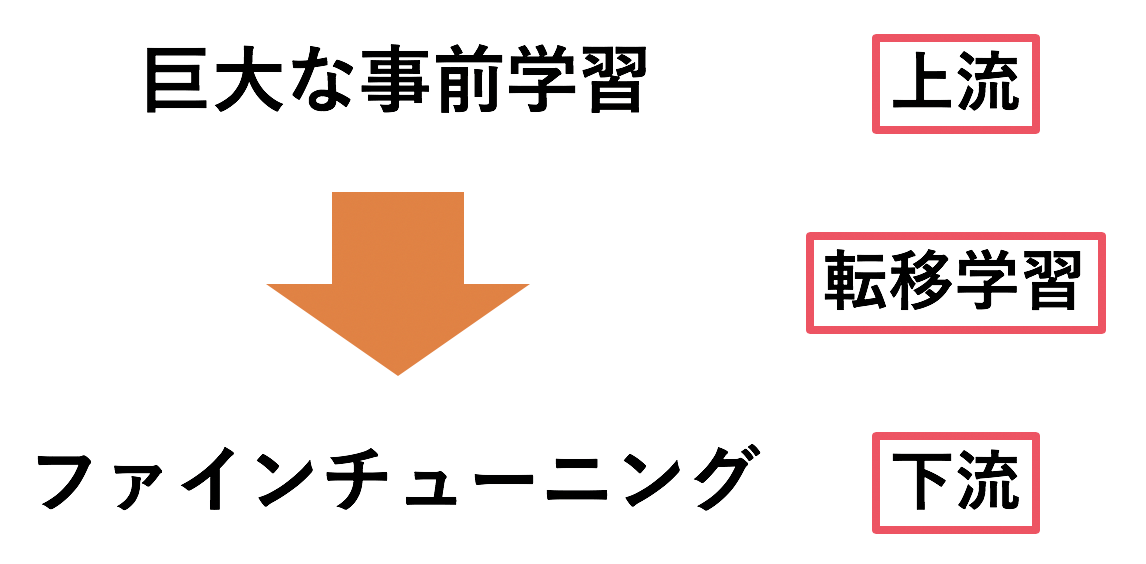
現在のディープラーニングには、EfficientNetのようなアーキテクチャやAdamやらMixUp、バッチノーマライゼーションなど有用なテクニックが多くある。そのため、今回はこのテクニックのうちより有効なものだけに絞って使用した。こうして有効なテクニックだけを絞って使用したモデルのことをBig Transfer(BiT) と呼ぶ。
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
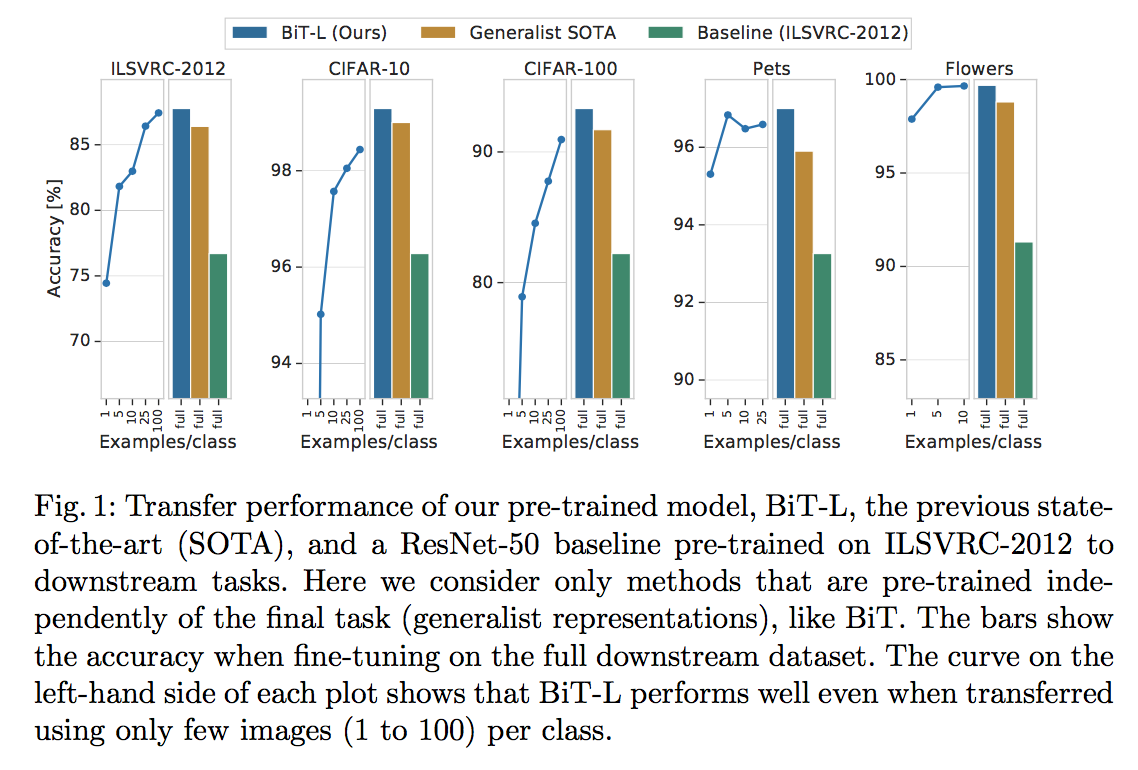
JFT-300Mデータセットで事前学習したモデルのことをBiT-Lと呼ぶ。このBiT-LがSoTAを叩き出しまくった(上図)。データセット5つの結果を示す。それぞれ棒グラフを見ると3つのモデル(BiT-L, SoTA, ResNet-50(ベースライン))を比較しており、いずれもBiT-LがSoTAモデルよりもいい。線グラフはFew-shot Learningのように各クラスあたりの画像数を減らした時のBiT-Lの結果で横軸は1クラスあたりの画像数を表している。1クラスあたり少ない画像数で高い精度を出している ことがわかる。もう少し小さいImageNet-21kデータセットで事前学習したモデルをBiT-Mと呼ぶ。
ここで重要なことは、BiT-Lは事前学習が1度だけで良い ということ。ファインチューニングする下流タスクは計算量が小さくて良い。
また、転移学習のためのハイパーパラメータを設定するヒューリスティックもこの論文で紹介 する。
この論文の目的は SoTAモデルに新しい要素などを追加することではなく、最小限のコツで「事前学習+ファインチューニング」による性能を最大限に引き出すこと にある。
そのために注目したのは以下の3つだけ。
- 学習の規模
- どのモデルか
- 学習時のハイパーパラメータ
1.2 BiTの構成
1.2.1 上流の事前学習
注目することは2つ。学習の規模 とバッチノーマライゼーションの仲間である グループノーマライゼーションの使用。
大きいデータセットにおいては長期間で学習率を調整する必要があることがわかった。データの統計情報を使うバッチノームは、異なるデータを使う転移学習に向かない。代わりに「グループノーム+重み標準化(Weight Standardization)」を使ったことで精度が向上した。

1.2.2 下流タスクへの転移
時間のかかるハイパーパラメータサーチはもうやめて、次の3つだけを使用しヒューリスティックな値を提案。
- 入力画像サイズ
- MixUpの使用の有無
- 学習ステップ数
タスクを大中小で定義し、それぞれに合った値を使うだけ。詳細は1.3.3.2にて説明。
画像の前処理は、「リサイズ」、「クロップ」、「フリップ」の3つだけ。(画像の方向が意味を持つタスクではフリップをしていない。)
また、Weight Decayおよびドロップアウトは使わないほうが精度がよかった。
1.3 実験
1.3.1 上流の事前学習におけるデータセット
事前学習に用いたデータの大きさの違いでモデルを3種類に分けた。
以下の表にまとめた。
| モデル | データセット | 画像数 | クラス数 |
|---|---|---|---|
| BiT-S | ILSVRC-2012 | 1.28 M | 1 k |
| BiT-M | ImageNet-21k | 14.2 M | 21 k |
| BiT-L | JFT-300M | 300 M | 18 k |
1.3.2 下流タスク用のデータセット
ILSVRC-2012, CIFAR-10/100, OxfordIIIT Pet, Oxford Flowers-102などのデータセットと、19個のタスクを含むVTABベンチマークを使ってBiTの性能を測った。
1.3.3 ハイパーパラメータの詳細
1.3.3.1 上流の事前学習
モデルはいずれも バッチノームをグループノームおよびWeight Standardizationに変更したResNet-v2 を使った。バッチサイズは4096。(でかすぎ。)
| モデル | アーキテクチャ |
|---|---|
| BiT-S | ResNet101x3 |
| BiT-M | ResNet101x3 |
| BiT-L | ResNet152x4 |
ここでx3やx4というのは元々のモデルの幅(各レイヤーのサイズ)をそのまま3倍や4倍したということ。BiT-Lは9.3億個のパラメータ数を持つ。
1.3.3.2 下流タスクへのファインチューニング
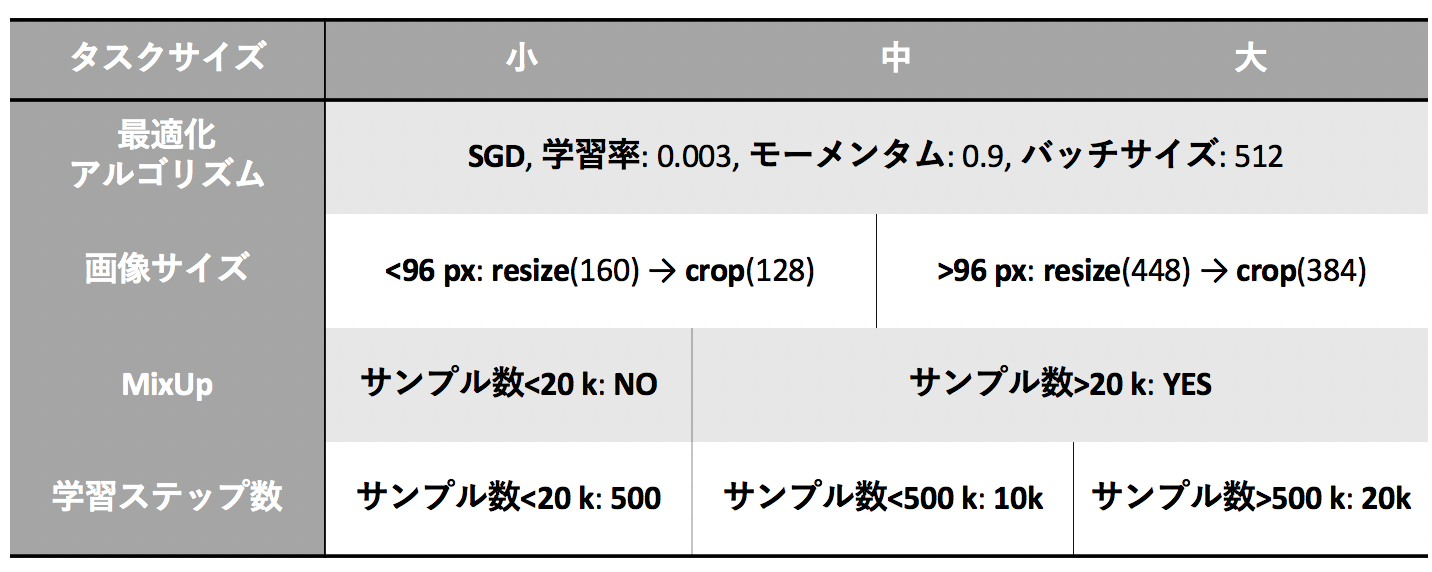
タスクごとのハイパーパラメータなどの調整は最小限に抑えたいものの、タスクによって入力画像サイズやデータセットの大きさが異なるため全タスクに同じハイパーパラメータを使うのはあまり賢くない。そこで冒頭でも述べたように、調整するハイパーパラメータを3つに絞った 。また、それぞれの値は入力画像サイズとデータセットの大きさによって決定 することにした。これを BiTハイパーパラメータ と呼ぶ。BiTハイパーパラメータのテーブルは以下。
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)をもとに作成
-
画像サイズ:
下流タスクにおいて入力画像サイズが96px以下であれば、160pxに画像をリサイズしたのち128pxの大きさでクロップするという意味である。96px以上においても同様に書いてある処理を行う。 -
MixUp:
データセットの大きさによってMixUpを行うか行わないかを決める。MixUpの係数 $\alpha=0.1$ とした。 -
学習ステップ数:
データセットの大きさによってファインチューニングでのステップ数を決める。ここで学習率は学習ステップの30 %, 60 %, 90 %で $\frac{1}{10}$ となる。
1.3.4 画像認識ベンチマークでのモデル評価
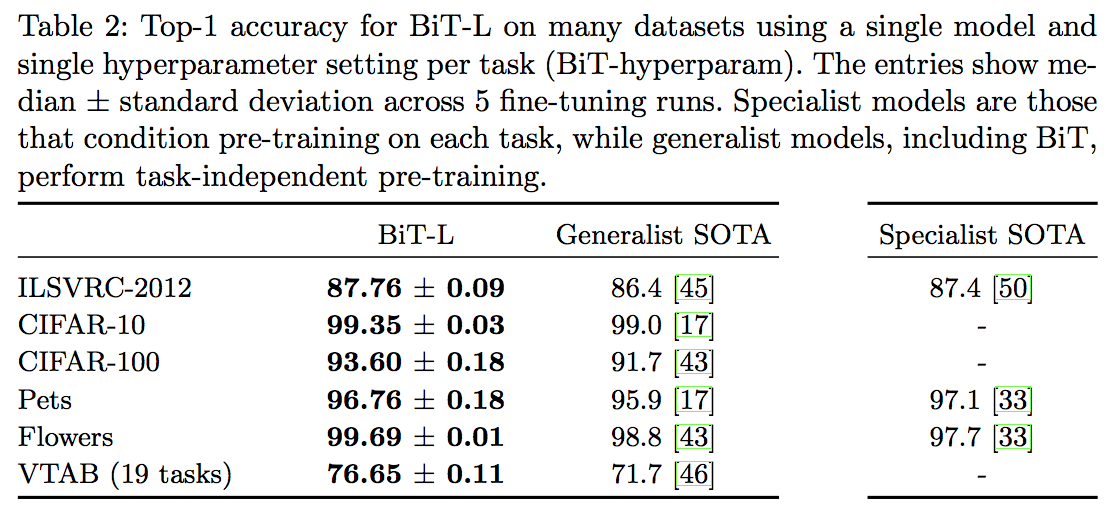
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
BiT-LをジェネラリストモデルのSoTAとスペシャリストモデルのSoTA両方と比較する。
ここでジェネラリストモデルとはEfficientNetのような様々なデータセットで高い精度を出すことを目的に作られたモデルのことで、一方スペシャリストモデルとは1つのデータセットで高い精度を出すことを目的に作られたモデルのこと。
上の表を見るとわかるように、BiT-Lはジェネラリストモデルたちよりはもちろんスペシャリストモデルたちと比べてもより良い精度を叩き出している。しかも、特別なハイパーパラメータチューニングなし(つまり BiTハイパーパラメータだけ)で達成している。
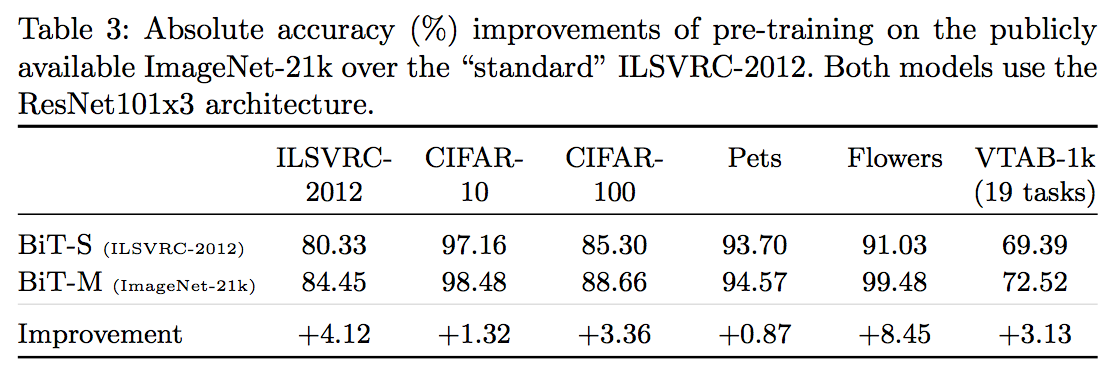
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
また、アーキテクチャは同じで事前学習のデータセットが異なるだけのBiT-SとBiT-Mを比較して見ると、事前学習のデータセット(の大きさ)の違いによってファインチューニングタスクの精度が大きく変わる ことがわかる。
1.3.5 データ数が少ない場合のモデル評価
人工知能をやる研究者が持つ目標として 「1クラスあたりのデータ数が少なくても高精度をたたきだしたい。」 というものがある。ここでは 1クラスあたりのデータ数が変わることでどれだけBiT-Lモデルの精度が変わるか を見る。
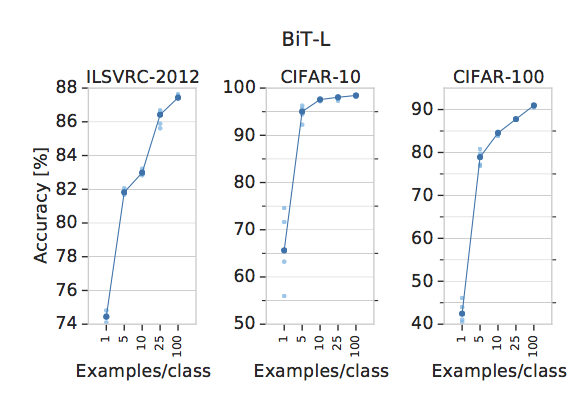
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
上図からわかるように、BiT-Lは1クラスあたりのデータ数が少なくても高い精度を叩き出している。特筆すべきは、ILSVRC-2012データセット(一番左)においては1クラスあたり1枚しか画像がない場合でも精度74.1 % を叩き出していることだ。
1.4 詳しい分析
ここでは特に以下の5つのことについてより詳しく調査していく。
- モデルとデータセットの大きさ
- 大きいデータセットに対する最適化アルゴリズム
- グループノーマライゼーションおよび重み標準化
- 転移学習におけるハイパーパラメータチューニング
- 事前学習と下流タスク間での画像の重複による影響
1.4.1 モデルとデータセットの大きさ
ここではモデルサイズと事前学習データセットサイズによる精度の変化を見る。
4つのデータセットに対して調査した。
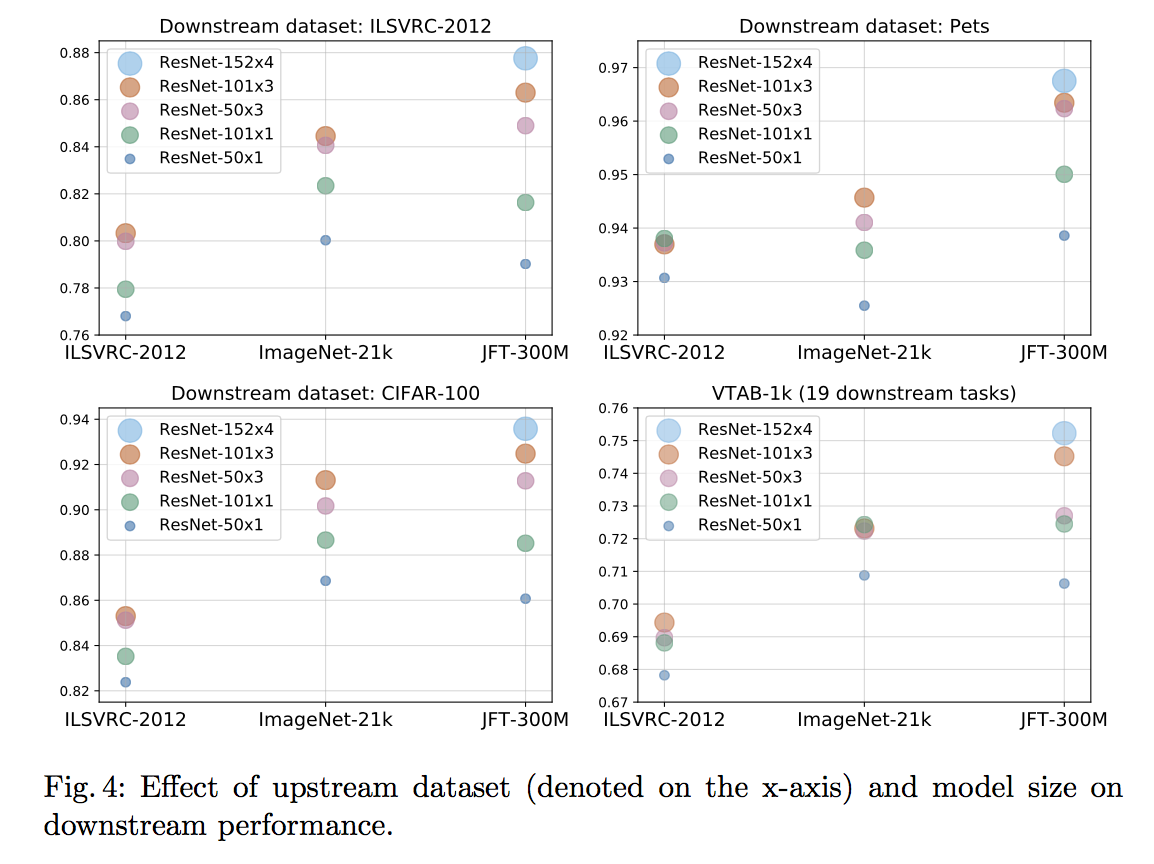
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
各グラフが下流タスクに対応した精度になっており、横軸が事前学習データセット縦軸がその精度である。それぞれのプロットは使用したモデルに対応する。
全体として言えるのは、大きいデータセットで大きいモデルを事前学習すると精度が上がる ということである。また、このグラフから分かるおもしろいことは主に2つ。
- 必ずしもデータが多くてもモデルが小さいと精度が上がらない
- 大きいモデルは小さい下流タスクでも高い精度を叩き出す
1つ目に関しては、大きい事前学習データで高い精度を出すにはそのデータサイズに応じたサイズのモデルが必要 ということである。(例えば上の図でResNet-50x1(小さい青色)を3つのデータセット各々で事前学習させた時、大サイズのデータセットで学習させた時よりも中サイズのデータセットで事前学習させた方が高い精度を出している。)
2つ目に関しては、大きいモデルがVTAB-1kという小さいタスクで高い精度を出している ことから言える。VTAB-1kとは19個の小さいタスク(各タスク画像1000枚のみ)を含むベンチマークで、各タスクに対する精度の平均値をとったものが最終的なスコアとなる。
1.4.2 大きいデータセットに対する最適化アルゴリズム
ILSVRC-2012のようなスタンダードなデータセットに対する学習は広く行われているため学習方法へのベストプラクティスがあるが、BiT-Lに用いているような巨大な事前学習データセットに対するベストプラクティスはまだ確立していない。そのためここでは巨大なデータセットに対する学習方法のベストプラクティスについて調査する。
その結果巨大な事前学習データセットに対するベストプラクティスとしてわかったことは以下。
- かなり長い学習を要する(数週間精度向上が見えなくても数ヶ月単位で見ると精度が上がり続けていた)
- Weight Decayが小さい方( $1e^{-5}$ )が収束が早いが、最終的な精度はWeight Decayが大きい方( $1e^{-4}$ )がよかった。
- 最適化アルゴリズムはシンプルなモーメンタムSGDが一番よかった。
1.4.3 グループノーマライゼーションおよび重み標準化
今回は バッチサイズが4096であり巨大 。TPUのAccelerator chipを128個使用。この場合「バッチノーマライゼーション(BN)」よりも 「グループノーマライゼーション(GN)+重み標準化(WS)」の方がよかった。バッチサイズが大きい方がBNがうまくいくはずだが、GN+WSを採用した流れは以下。
巨大モデルの使用 → それのせいでチップに膨大なメモリが必要 → チップあたりのバッチサイズを小さくして緩和 → デバイス毎にBN使ったらサイズが小さいため実力発揮できない → 全デバイスに包括的なBN → 欠点2つ: 1.バッチサイズが大きすぎると逆によくない 2.BNを計算する遅延がすごい → 代替案のGN+WSが制度よかった。
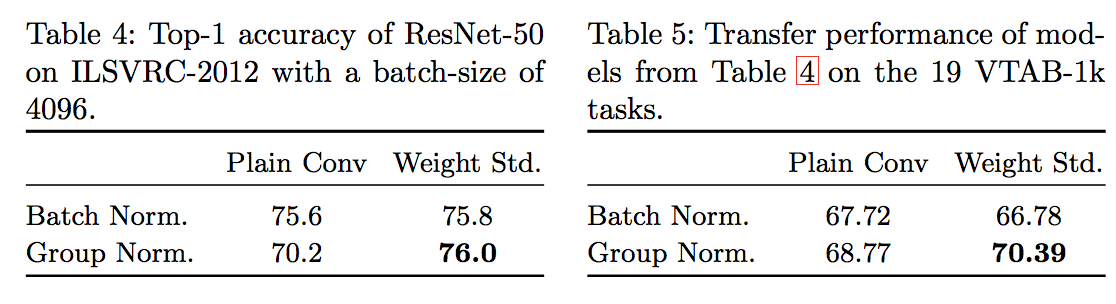
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
GN+WSが事前学習(Table 4)および下流タスク(Table 5)いずれにおいても一番良い精度を出している のがわかる。
1.4.4 転移学習におけるハイパーパラメータチューニング
この論文では ハイパラチューニングをなるべく避けたいという理由からBiTハイパーパラメータを一貫して使っていた。しかし、計算リソースに余裕があるのであれば 各タスク毎にハイパラチューニングをするに越したことはない。そのためここではランダムサーチを使ってハイパラチューニングを行ってみる。モデルはBiT-Lを用い、下流タスクとしてVTAB-1kを使った。その結果は以下図。
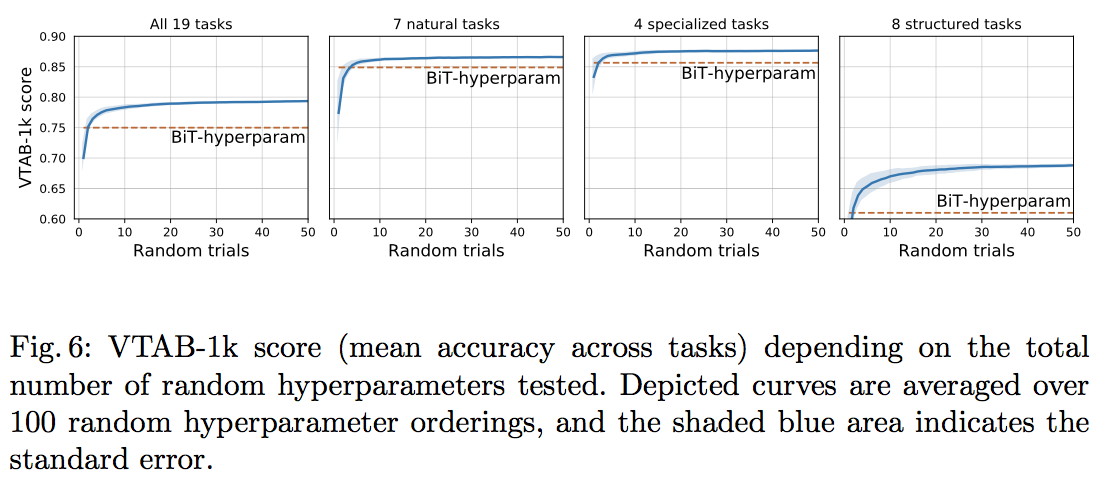
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
ランダムサーチによってハイパラチューニングをした方がBiTハイパーパラメータよりも良い結果になっていることがわかる。特筆すべきは、ハイパラの探索回数は10~20回程度で良い こと。
1.4.5 事前学習と下流タスク間での画像の重複による影響
事前学習で使ったデータセットと下流のタスクで使ったデータセットとで画像が重複していたとしても、精度にほぼ影響しない ことがわかった。データセット全体を使った場合の結果とデータセットから似た画像を除いた場合の結果は下表。ここでFullが全体を使った結果、Dedupが重複を除いた結果、Dupsというのが"重複"と判断された画像数。
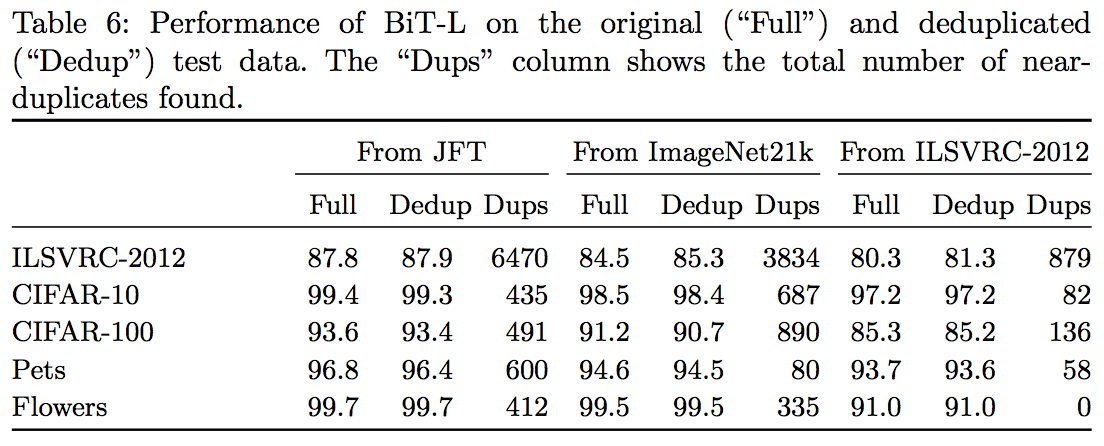
Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
それぞれFullとDedupを比較するとわかるが、結果にほぼ影響していないことがわかった。
1.5 関連研究
ここでは4分野の関連研究が紹介されている。それぞれの論点だけを列挙する。
-
大規模弱教師あり表現学習:
転移学習においては事前学習で大きなデータセットおよびモデルを使うことで精度があがることがこの論文を通してわかった。ただJFT-300Mよりも大きいデータセット3.5B InstagramデータセットをResNeXtモデルに対して使っている関連研究があるが、それよりも今回の「ResNet + JFT-300M + BiTハイパラ」 が最強。 -
スペシャリストモデル:
下流のタスクに合うようなデータセットを使って事前学習するスペシャリストモデルは高い精度がでるものの、以下の2つ欠点があるため、BiTのようなジェネラリストモデルが良い。- 前もって下流のタスクを知っていないといけない。
- 下流の各タスクにそれぞれ事前学習が必要なため計算量が大きい。
-
教師なし表現学習と半教師あり表現学習
教師なし学習、半教師あり学習、自己教師あり学習、教師あり学習など色々な手法の表現学習を研究した関連研究があり、それでは「教師あり学習+自己教師あり表現学習」が一番とされていたが、今回の論文では「大規模データに対しての教師あり事前学習」が有効であることがわかった 。 -
Few-shot Learning:
今回の論文ではFew-shot Learningにはフォーカスせず、あくまでも ジェネラリストモデルを作ることに注力した。
1.6 考察
BiT-Lが間違えた結果を考察する。ここではCIFAR-10の間違いを全部とILSVRC-2012の間違いを一部を示す。

Large Scale Learning of General Visual Representations for Transfer, Kolesnikov, A. et al.(2019)
左がCIFAR-10データセットにおいて間違えた画像全部で、右がILSVRC-2012データセットにおいて間違えた画像の一部である。1つ1つ見るとわかるが、ミスがもはやミスでない ことがわかる。間違えている原因がモデルにあるのではなく、画像の曖昧さやラベルノイズによるものである。このように、CIFAR-10などの現在スタンダードで使われているデータセットはもはや攻略済み と言える。
2. まとめと所感
今回の論文は特に新しいモデルや要素を取り入れているのではなく、「転移学習」にフォーカスして精度をあげているのがおもしろい。このように「巨大な事前学習+タスク毎のファインチューニング」というのでSoTAを狙う流れはNLPの方でも見て取れるので、画像認識もNLPもそうなっていくのだろうか。個人的には新しいモデルとか要素が入ってくれた方がわくわくする。
ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽にフォローしてください! いいねやコメントもお待ちしております!
3. 用語と補足
3.1 MixUp
本論文中では下流タスクへのファインチューニングの際のハイパーパラメータ「BiTハイパーパラメータ」にてMixUpが使用されている。
MixUpとはZhang, H. et al.(2017)で提案された新たなData Augmentation手法。モデルの汎化性能やGANの性能の安定性を向上 させる効果がある。Kaggleでもよく使われている(らしい。) (ソース)
一言で言えば、「2つのデータを線形補間し新たなデータを生成する」ということ。
例えば、あるラベルを持つ画像データが2つあるとする。ここでそれぞれ $(x_1, y_1)$, $(x_2, y_2)$ とする。ここで $y$ はone-hot表現。その時 MixUpとは新たなデータ $(\lambda x_1 + (1-\lambda)x_2, \lambda y_1 + (1-\lambda)y_2)$ を作る こと。ここで $\lambda$ はベータ分布からサンプリングされる[0,1]の範囲内の値で、FacebookによるPyTorchの実装では分布は $\mathrm{Beta}(1.0, 1.0)$ をデフォルトとしている。
3.2 重み標準化(Weight Standardization)
本論文中ではBiTモデル(巨大なResNet)にてバッチノームの代わりにグループノームと共に重み標準化(WS)使われている。
重み標準化とはQiao, S. et al.(2019)で提案された新たなNormalization手法。単純にCNNにおける重み(Filter)を入力チャネル方向で標準化するだけ。以下論文からの引用。 $C_{in}, C_{out}$ はそれぞれConv層における入力チャネル数と出力チャネル数を示す。
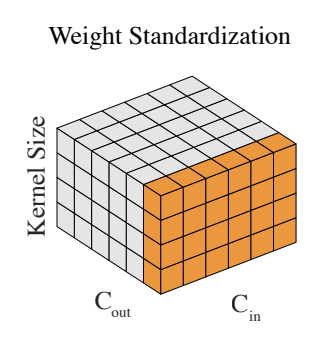
Weight Standardization, Qiao, S. et al. (2019)
3.3 ランダムサーチ
本論文中では転移学習におけるBiTハイパーパラメータではなく実際にハイパーパラメータを探索した場合の精度変化を見た際に、ランダムサーチがその探索方法として用いられている。
ランダムサーチとはBergstra, J. et al.(2012)にて有用性が説かれたハイパーパラメータの探索方法。ブルートフォースなグリッドサーチよりも低い計算コストで、高精度なハイパラを獲得できる。
ある程度学習率やレイヤー層などのハイパラの値をそれぞれ(例えば5個ずつ)決め、全通りの組み合わせでモデルの精度を見てみるグリッドサーチとはことなり、ランダムサーチとは各ハイパラの取りうる範囲だけを指定してあとはランダムで組み合わせを任意の数試しモデル精度を見る探索方法 のこと。
4. 参考
-
Large Scale Learning of General Visual Representations for Transfer
(論文) 原論文。 -
A Newbie’s Guide to Stochastic Gradient Descent With Restarts
(英語) 学習率アニーリングについての説明。 -
Mixup data augmentation
(英語) fast.aiのスレッド。MixUpについて具体例を使いながらわかりやすく議論されている。 -
mixup: Data-Dependent Data Augmentation
(英語) MixUpの概要と数式的な説明。 -
Random Search for Hyper-parameter Optimization
(YouTube) ランダムサーチの説明。インド英語。 -
In a CNN, does each new filter have different weights for each input channel, or are the same weights of each filter used across input channels?
(英語) StackExchangeの質問。CNNのフィルターは出力チャネル数用意するのはもちろん入力チャネル毎にも別々のフィルターを用意する。