はじめに
この記事では、Keras(Tensorflow)のOptimizerを単独実行させた実験結果を示すことにより、各種最適化アルゴリズムでのパラメーターの効果や、アルゴリズム間の比較を行う。
ここでは、これまで他の記事で扱ってきたアルゴリズム間での動作の違いを、同一グラフ上のアニメーションとして視覚化する。
ただし、AdadeltaとFtrlは特殊なので同時比較の対象としない。AMSgradはAdamとの違いが出なかったので省略した。
SGD編
Adagrad/RMSprop/Adadelta編
Adam/Adamax/Nadam編
FTRL編
実験方法
最適化のクラスを直接実行して、最適値に向かう様子をグラフにプロットして比較する。
具体的には、下記の内容。
- TensorFlow(2.3.0)/tf.keras(2.4.0)使用。
- 初期値1.0、最適値0.0として、Optimiserのminimize()を直接実行し、ステップ毎に最適値に近づく様子を観察する。
- Google Colabで実行可な実験コードを最後に記載。
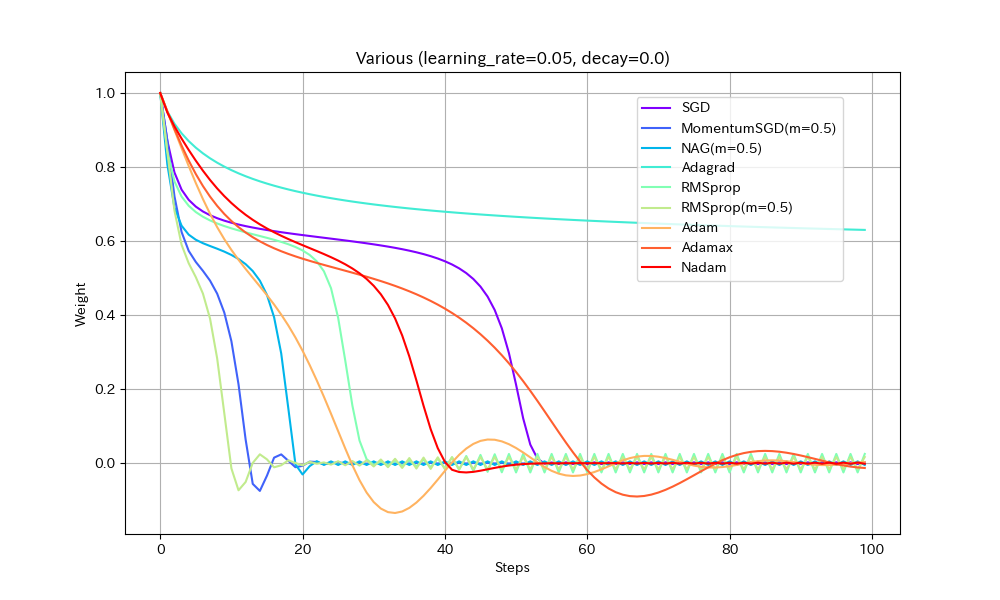
実験1. 途中に緩やかな区間がある場合
損失関数を「いったん下ったあと、途中平坦になり、再度急降下する」形にして動作を比べた。すべて同一の学習率にしてある。
| Weight/Steps | Loss/Weight |
|---|---|
 |
 |
- 単純に最適値に到達するまでの早さで比べると、RMSprop(Momentum有)、MomentumSGD、NAGの順番で早く到達する。Momentumの加速効果が見て取れる。
- NAGは単純なMomentumSGDよりも遅い。Nesterovでは減速も早くなるので、平坦な場所がくると急ブレーキがかかるようだ。NadamとAdamの比較でも同様の現象が見られる。
- Adamでは他のアルゴリズムより、最適値を通り過ぎた後に最も遠い地点まで進んでしまうようだ。この条件では勢いがつきすぎているようにも見えるが100step経過後には最適値にほぼ停止しているので、大きく問題視すべきことでは無いかもしれない。
- Adamとは違いNadamでは最適値で急ブレーキがかかるが、平坦区間で減速してしまっているので、この条件ではAdamに比べると学習の進みがかなり遅い。
- Adagradはこの条件では他のアルゴリズムより大幅に遅くなる。学習率を大きくとらないと最適値に到達できないだろう。
- Adagradを除くとAdamaxが最適値への到達が最も遅い。最適値を通り過ぎてからの振幅も大きく、あまりいいところが見られない。
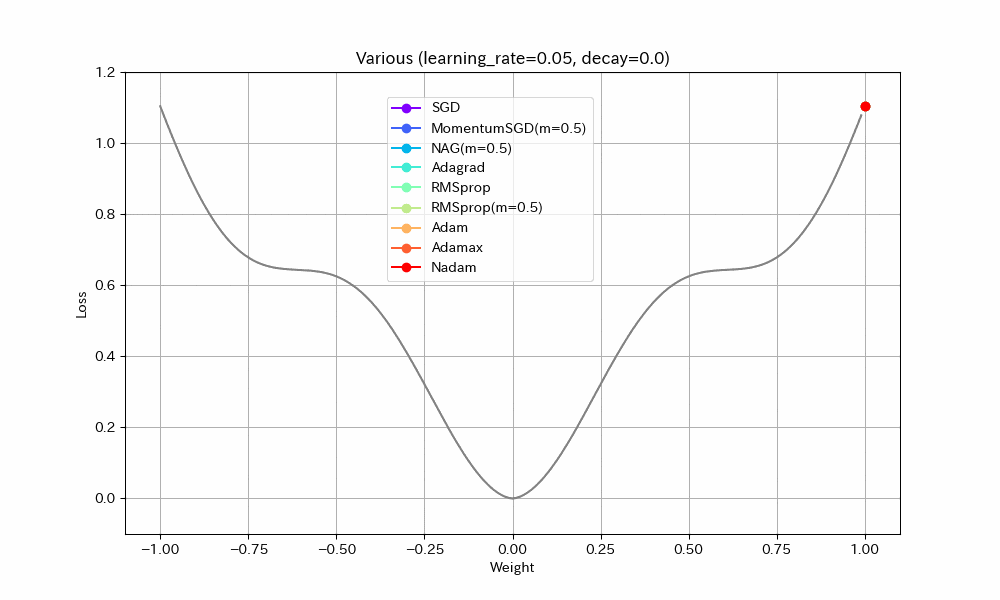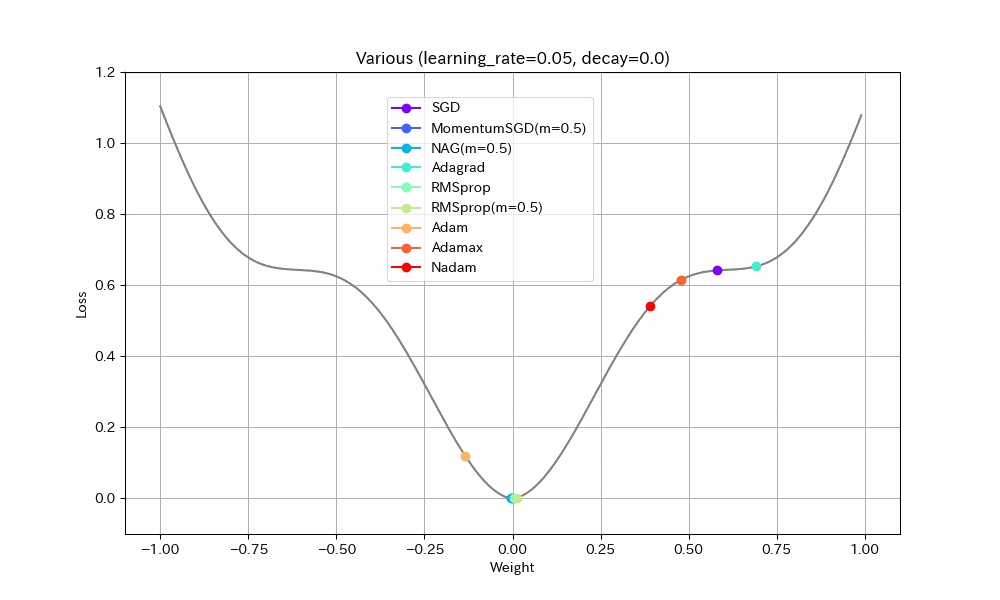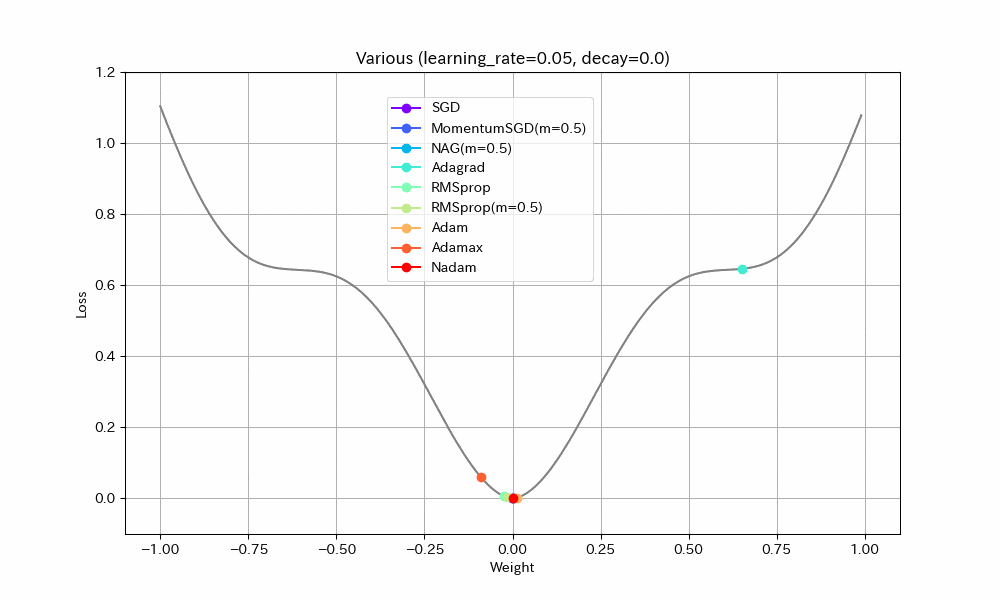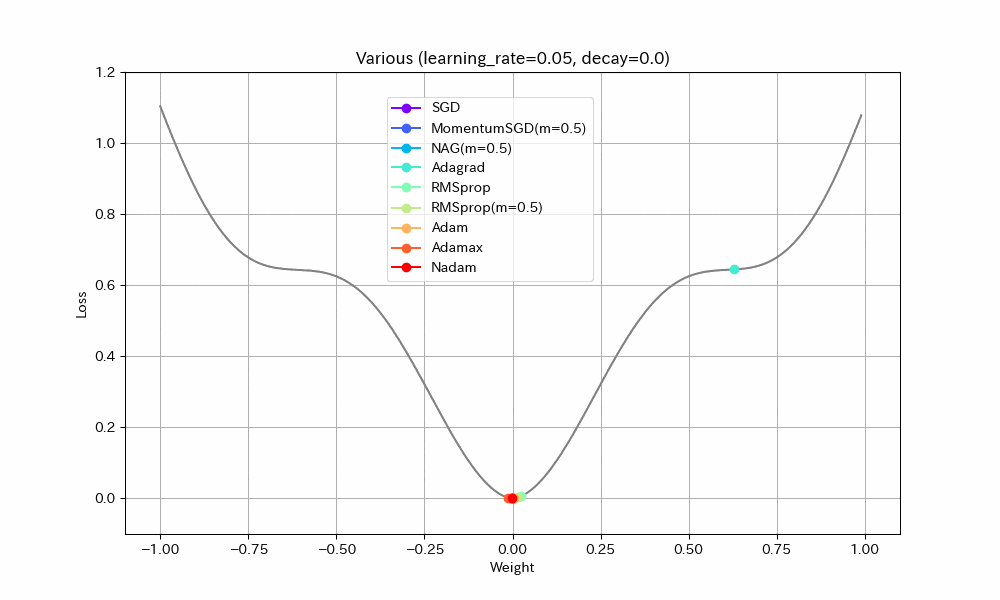
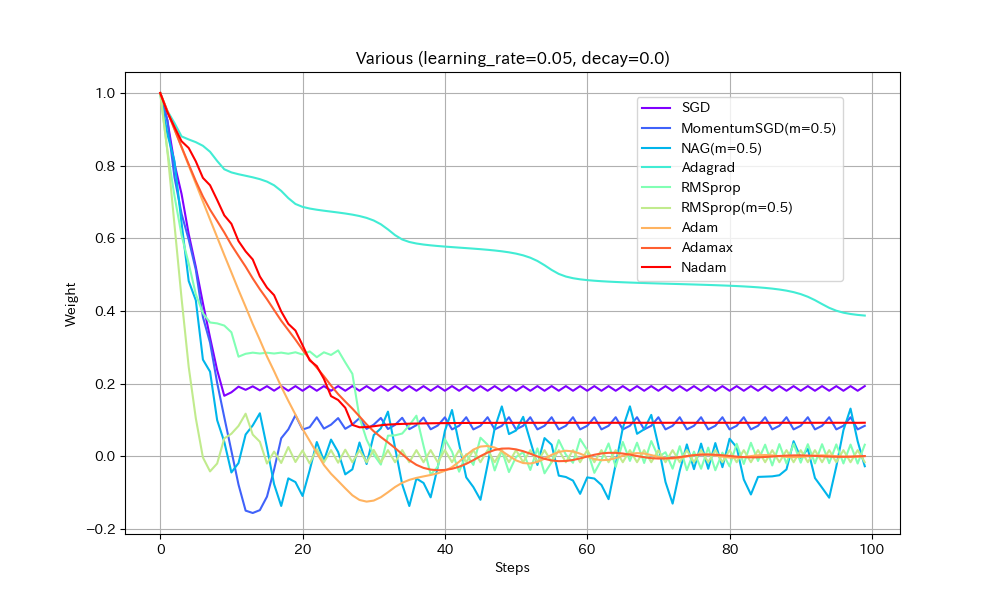
実験2. 局所最適解が複数存在する場合
損失関数を「局所最適解が複数存在する」形にして動作を比べた。損失関数以外は実験1と同じ。
| Weight/Steps | Loss/Weight |
|---|---|
 |
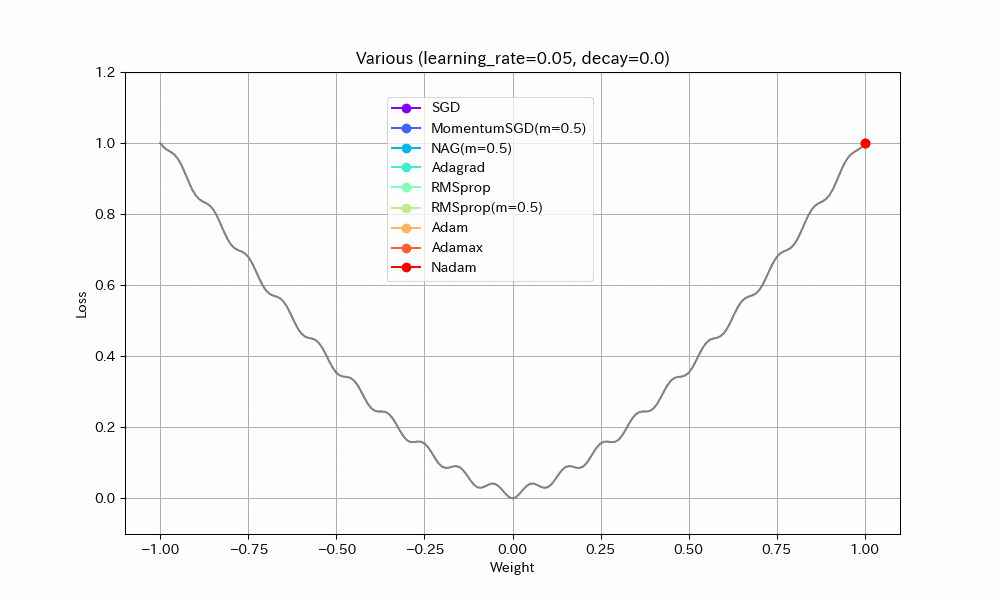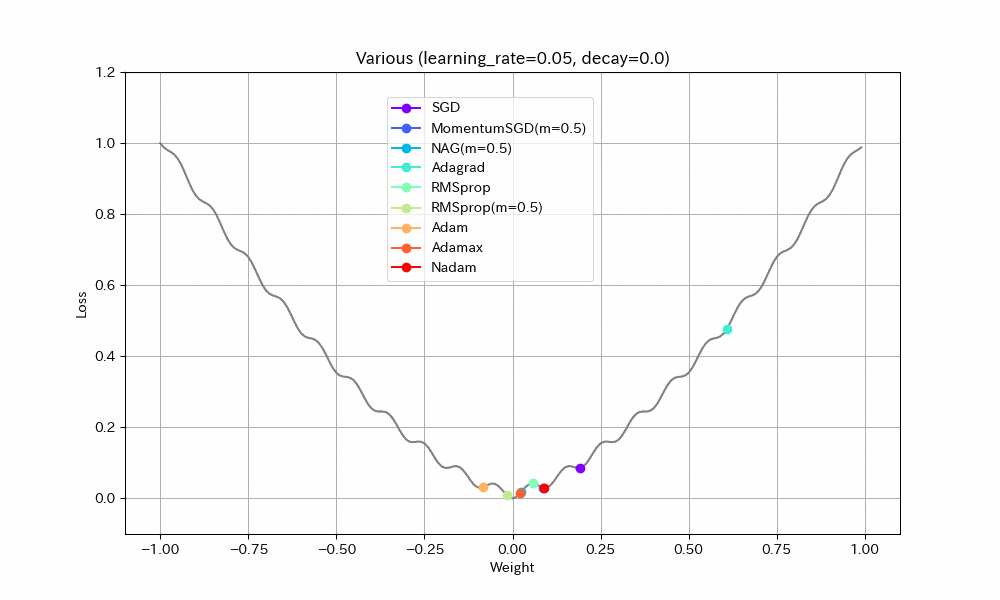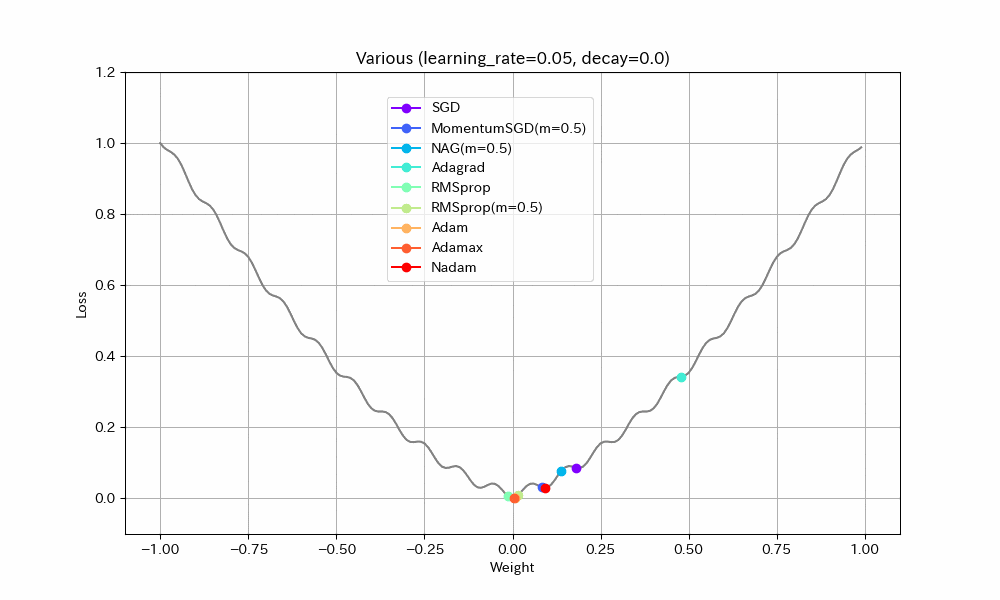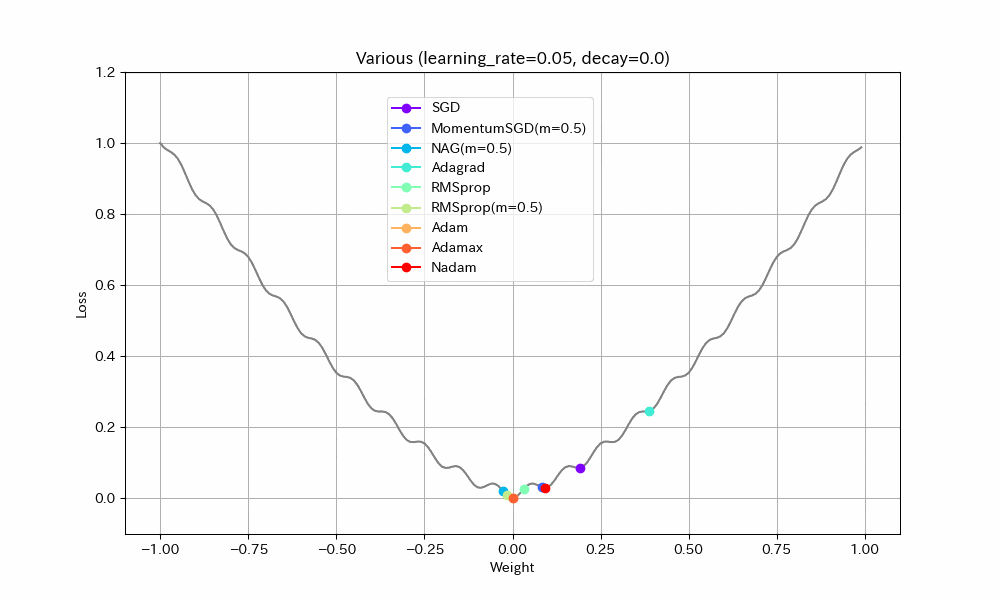 |
- SGD/Nadam/Adagradは途中で局所最適解にはまって、最適解までたどり着けていない。SGDとAdagradがはまるのは学習率が小さすぎたのだろう。Nadamは急減速できる特性が悪く作用したと考えられる。
- MomentumSGDは一度最適解を通り過ぎた後、反動で戻ってきた先で局所最適解にはまっている。
- RMSprop(Momentum有)が実験1同様、最速で最適解にたどり着き、正しく収束もできているが、RMSprop系の特性で振動が止まらない。
- NAGが最適値付近で大きく変動している。他の実験ではNesterov法は振動抑制効果がみられたが、場合によってはむしろ不安定になることがわかる。
- AdamとAdamaxは若干遅いが、きれいに最適解に収束している。
以下、学習率を2倍にした結果。
| Weight/Steps | Loss/Weight |
|---|---|
 |
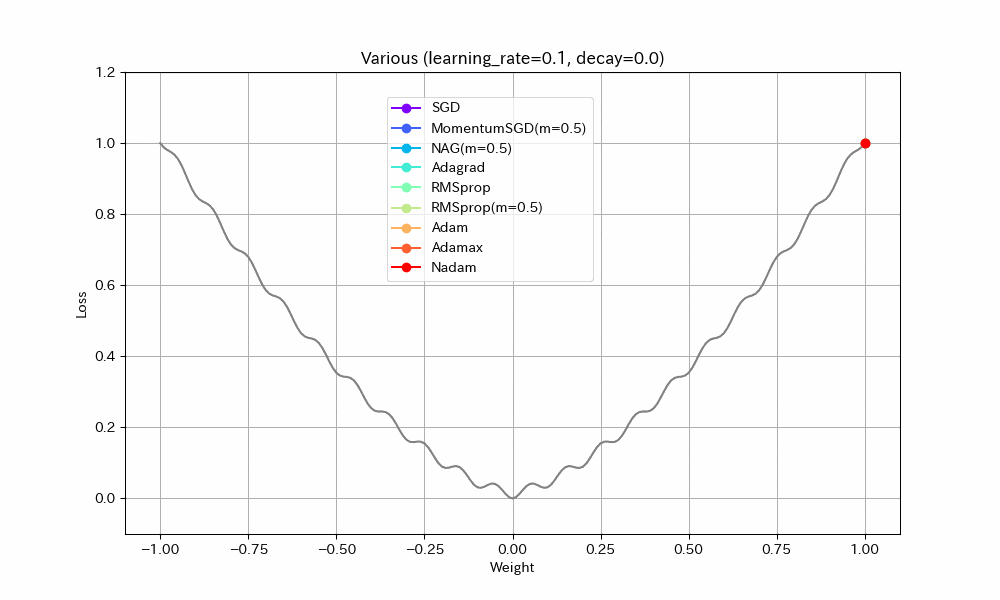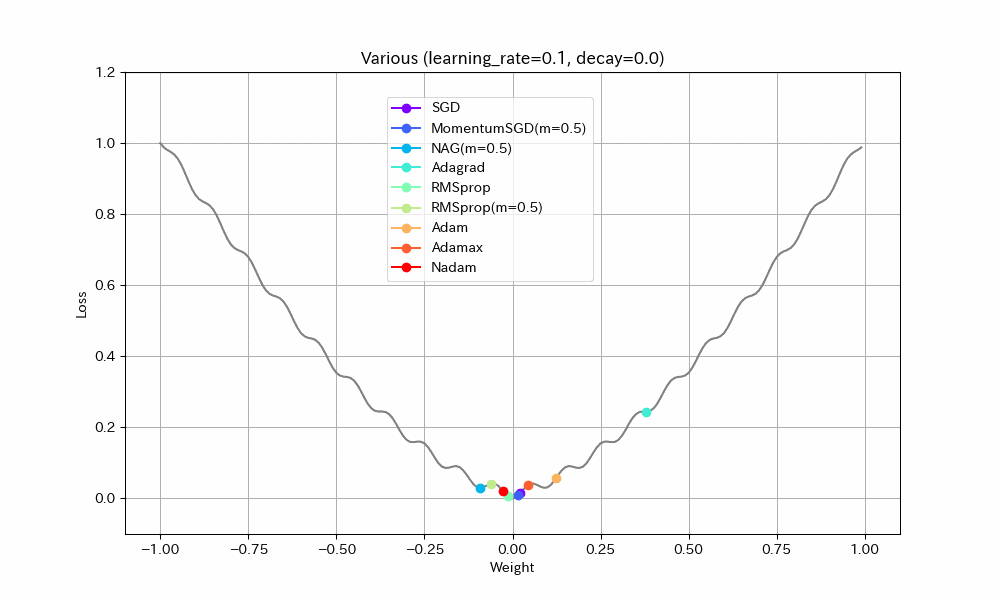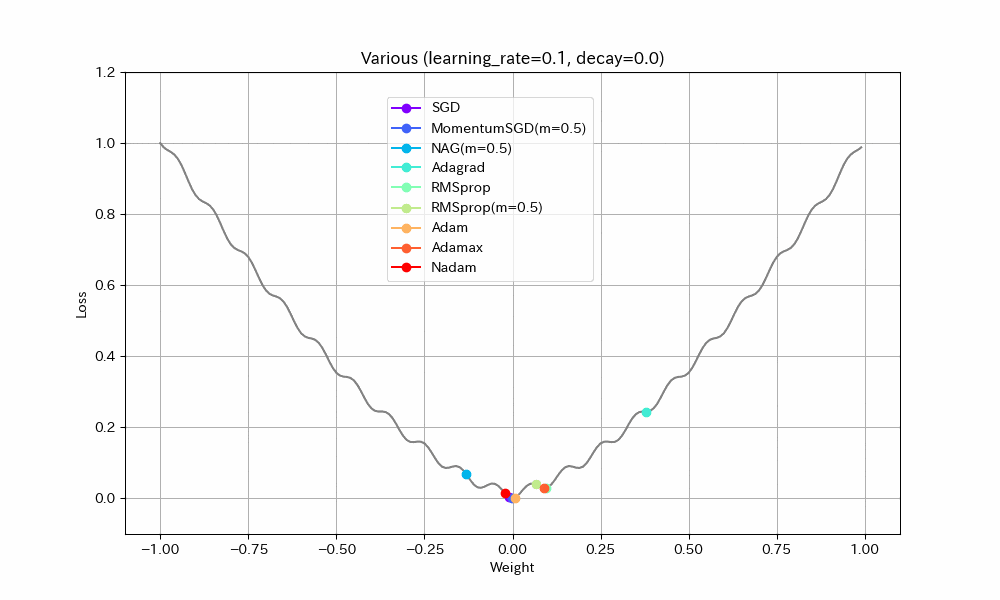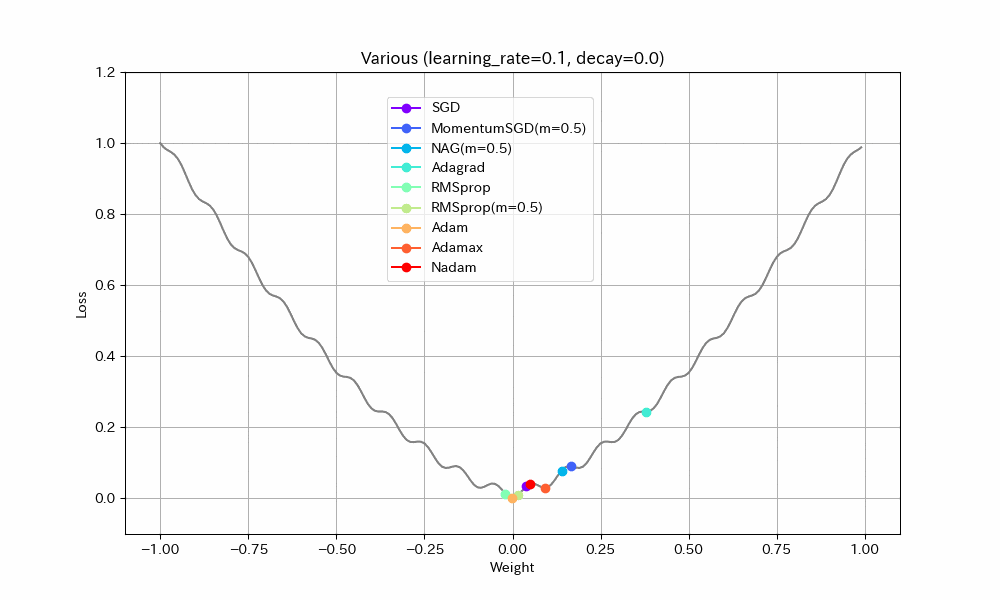 |
- Adagrad以外は最適解まで到達している
- ほとんどのアルゴリズムで最適解付近の振動が激しくなっているが、Adamはうまく停止している。ただし、ある程度振動したほうが局所最適解から抜け出せる可能性が高くなるはずなので、Adamのように停止してしまったほうが本当に良いのかは、場合によると思われる。
実際の機械学習では、途中でOptimizerの学習率を一気に1/10下げることが良く行われる。学習率が小さすぎると最適解に到達できないが、大きすぎても収束しないことへの対応と考えられる。
同様のことはDecayパラメータを使ってもできる(あまり使われることが無いようではあるが)。初期学習率0.1、Decay=0.04(100ステップで学習率0.05になるはず)という設定で実験する。
| Weight/Steps | Loss/Weight |
|---|---|
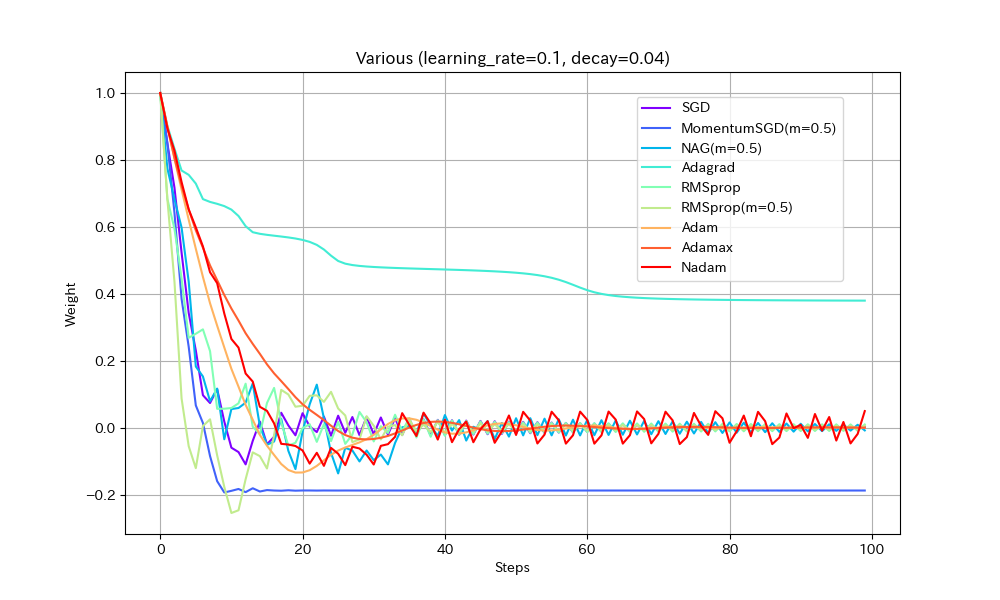 |
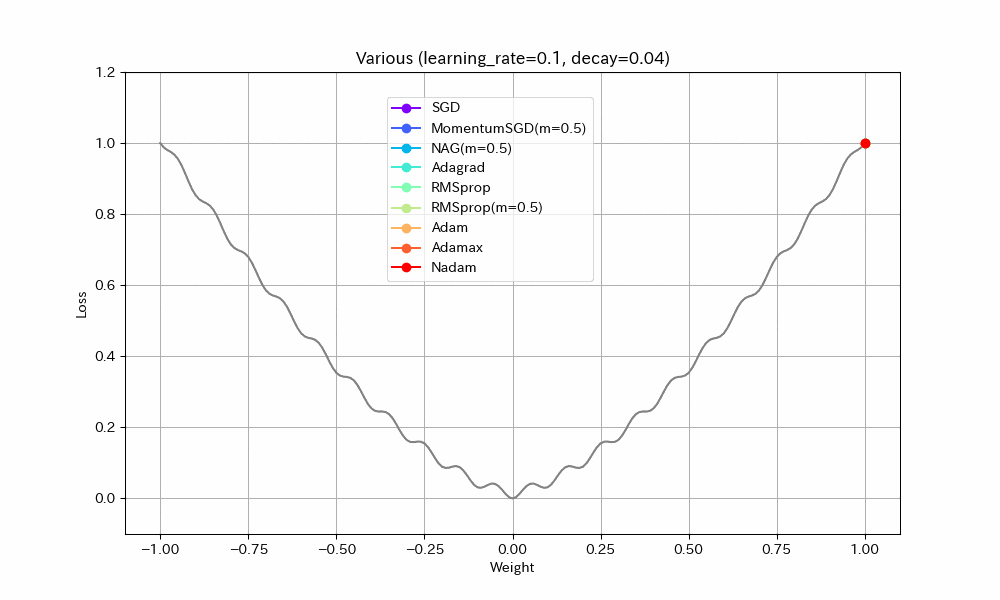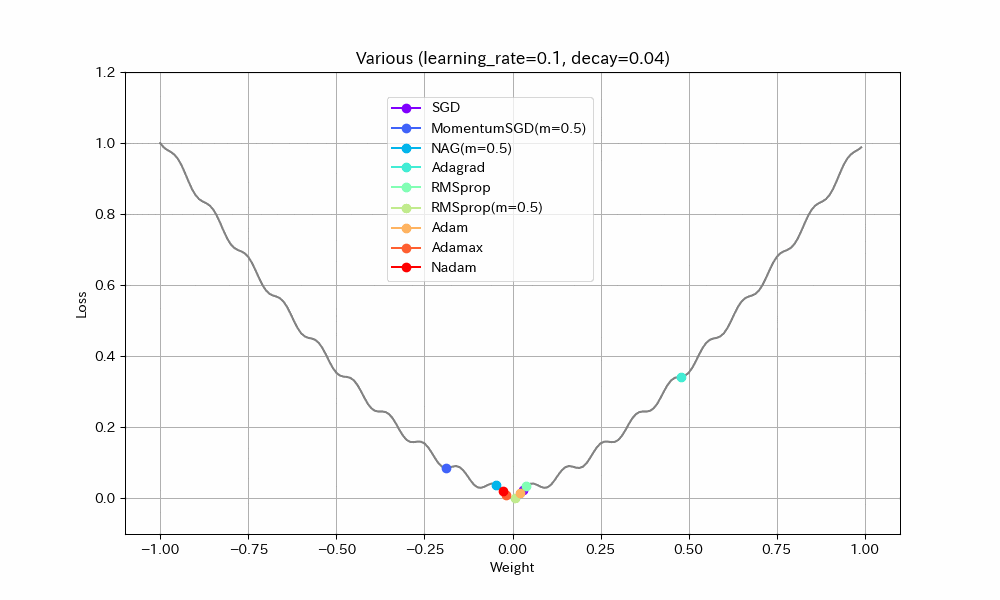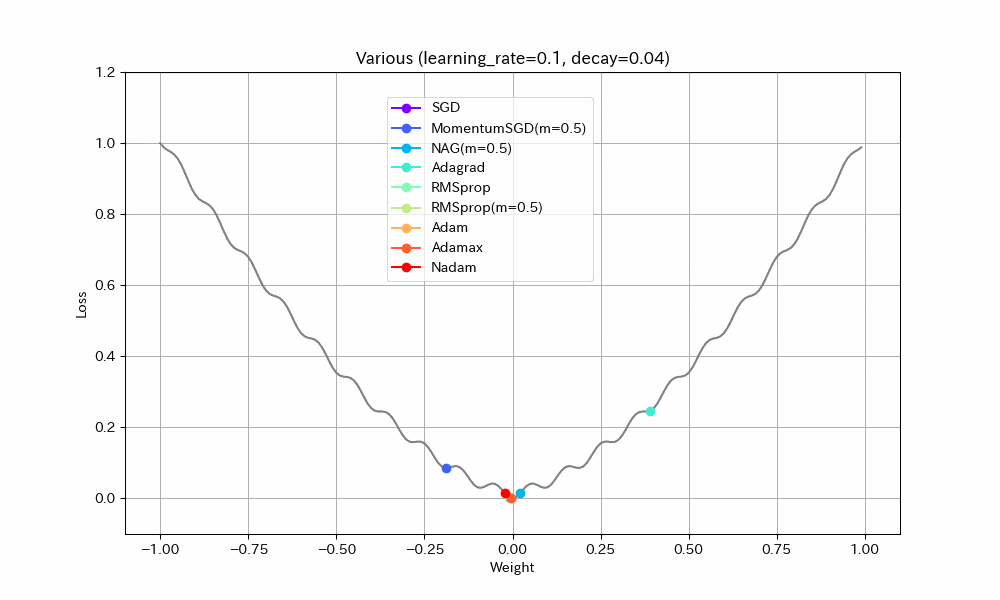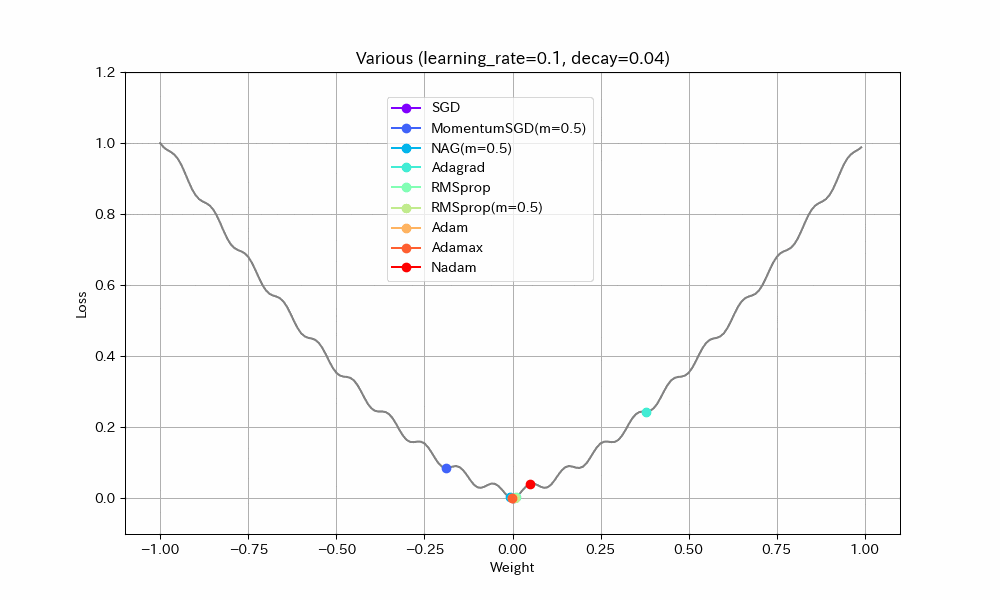 |
- MomentumSGDとAdagrad以外は最適解で収束しているので、学習率を減らすことの良い効果が見えた。
- Nadamの振動が激しいが、これはNadamがDecayパラメータに対応していないためと思われる。
- MomentumSGDは最適解を行き過ぎた後で局所最適解につかまり戻れなくなっている。Decayの数値も気を付けて設定しなければならないことがわかる。この辺もDecayがあまり使われない原因かもしれない。
まとめ
各種アルゴリズムを同一条件で比較した。
学習率を同じ設定で比較するのが本当にフェアなのか、条件が単純すぎるのではないか、という疑問はあるが、それぞれの特色がある程度でたように思う。
以下、「非常に単純な条件下での実験」という前提での感想。
- MomentumSGD/RMSprop(Momentum有)/Adamが比較的良好な結果を出しているように思われる。
- 上記以外のアルゴリズムはあまり積極的に使用する理由が見つからないように思う。特に、NAG/NadamといったNesterov系は今一つ信頼できないような結果になったのは意外。
下記の実験コードを使えば、本記事に載せた以外の比較や、学習率等のパラメータを変更して実験を行えるので、興味のある方は各自実験してもらいたい。
実験コード
import math
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.optimizers import SGD,RMSprop,Adagrad,Adadelta,Adam,Nadam,Adamax,Ftrl
from IPython.display import HTML
import matplotlib.pyplot as plt
from matplotlib import animation
from matplotlib import rc
from matplotlib.animation import PillowWriter
class LoopingPillowWriter(PillowWriter):
def finish(self):
self._frames[0].save(
self._outfile, save_all=True, append_images=self._frames[1:],
duration=int(1000 / self.fps), loop=0)
def testOptims2(optims, lossFn='mae', total_steps=150, title=None):
if lossFn == 'Abs':
def loss(): return tf.abs(var1)
elif lossFn == 'Square':
def loss(): return var1**2
elif lossFn == 'Special':
def loss(): return var1*(1010 if (i % 101) == 1 else -10)
elif lossFn == 'Bumpy1':
def loss(): return (tf.abs(var1)**1.5)+0.15*(tf.sin(var1*1.2*math.pi*2 - math.pi/2.0)+1.0)
elif lossFn == 'Bumpy2':
def loss(): return (tf.abs(var1)**1.5)+0.015*(tf.sin(var1*10*math.pi*2 - math.pi/2.0)+1.0)
else:
return
w_list = []
loss_list = []
for label, optim in optims.items():
var1 = tf.Variable(1.0)
w_buf = []
loss_buf = []
w_buf.append(var1.numpy())
loss_buf.append(loss())
for i in range(total_steps-1):
optim.minimize(loss, [var1]).numpy()
w_buf.append(var1.numpy())
loss_buf.append(loss())
w_list.append(w_buf)
loss_list.append(loss_buf)
loss_x_buf = []
loss_y_buf = []
for i in range(-100, 100):
var1 = tf.Variable(i*0.01)
loss_y_buf.append(loss())
loss_x_buf.append(i*0.01)
cmap = plt.get_cmap("rainbow")
coloring = [cmap(i) for i in np.linspace(0, 1, len(optims))]
print('plotting history...')
fig = plt.figure(figsize=(10, 6), facecolor="white",)
ax = fig.add_subplot(111)
steps = range(total_steps)
for i, label in enumerate(optims.keys()):
ax.plot(steps, w_list[i], color=coloring[i], label=label)
fig.legend(bbox_to_anchor=(0.85, 0.85))
ax.set_xlabel('Steps')
ax.set_ylabel('Weight')
if title != None:
ax.set_title(title)
ax.grid()
fig.savefig(lossFn+'_'+title+'.png')
plt.show()
print('making animation...')
fig = plt.figure(figsize=(10, 6), facecolor="white",)
ax = fig.add_subplot(111)
ax.set_xlim((-1.1, 1.1))
ax.set_ylim((-0.1, 1.2))
if title != None:
ax.set_title(title)
images = []
loss_line, = ax.plot([], [], color='gray')
images = []
for i, label in enumerate(optims.keys()):
im, = ax.plot([], [], marker="o", color=coloring[i], label=label)
images.append(im)
def anim_ini():
loss_line.set_data(loss_x_buf, loss_y_buf)
return (loss_line,)
def anim_animate(i):
for j, label in enumerate(optims.keys()):
images[j].set_data(w_list[j][i], loss_list[j][i])
return images
fig.legend(bbox_to_anchor=(0.6, 0.85))
ax.set_xlabel('Weight')
ax.set_ylabel('Loss')
ax.grid()
interval = 100
anim = animation.FuncAnimation(fig, anim_animate, init_func=anim_ini, frames=total_steps, interval=interval, blit=False)
anim.save(lossFn+'_'+title+'.gif', writer=LoopingPillowWriter(fps=1000.0/interval))
if 'COLAB_GPU' in os.environ.keys():
plt.close()
rc('animation', html='jshtml')
else:
plt.show()
return anim
steps = 100 #@param {type: "number"}
loss_type = "Bumpy1" #@param ["Abs", "Square", "Bumpy1","Bumpy2"]
test_type = "Various" #@param ["SGD", "MomentumSGD", "NAG", "RMSprop", "RMSprop(2)","Adam", "Adamax", "Nadam","Adam vs AMSGrad vs Adamax vs Nadam","Adadelta","Various" ]
learning_rate = 0.05 #@param {type: "number"}
decay = 0.0 #@param {type: "number"}
test_dict = {}
test_dict['SGD'] = {
'SGD(lr/4, m=0.0)': SGD(learning_rate/4, momentum=0.0, decay=decay),
'SGD(lr/2, m=0.0)': SGD(learning_rate/2, momentum=0.0, decay=decay),
'SGD(lr, m=0.0)': SGD(learning_rate, momentum=0.0, decay=decay),
'SGD(lr*2, m=0.0)': SGD(learning_rate*2, momentum=0.0, decay=decay),
'SGD(lr*4, m=0.0)': SGD(learning_rate*4, momentum=0.0, decay=decay),
}
test_dict['MomentumSGD'] = {
'MomentumSGD(lr/4, m=0.5)': SGD(learning_rate/4, momentum=0.5, decay=decay),
'MomentumSGD(lr/2, m=0.5)': SGD(learning_rate/2, momentum=0.5, decay=decay),
'MomentumSGD(lr, m=0.5)': SGD(learning_rate, momentum=0.5, decay=decay),
'MomentumSGD(lr*2, m=0.5)': SGD(learning_rate*2, momentum=0.5, decay=decay),
'MomentumSGD(lr*4, m=0.5)': SGD(learning_rate*4, momentum=0.5, decay=decay),
}
test_dict['NAG'] = {
'NAG(lr/4, m=0.5)': SGD(learning_rate/4, momentum=0.5, decay=decay, nesterov=True),
'NAG(lr/2, m=0.5)': SGD(learning_rate/2, momentum=0.5, decay=decay, nesterov=True),
'NAG(lr, m=0.5)': SGD(learning_rate, momentum=0.5, decay=decay, nesterov=True),
'NAG(lr*2, m=0.5)': SGD(learning_rate*2, momentum=0.5, decay=decay, nesterov=True),
'NAG(lr*4, m=0.5)': SGD(learning_rate*4, momentum=0.5, decay=decay, nesterov=True),
}
test_dict['Adam'] = {
'Adam(lr/4)': Adam(learning_rate/4, decay=decay),
'Adam(lr/2)': Adam(learning_rate/2, decay=decay),
'Adam(lr)': Adam(learning_rate, decay=decay),
'Adam(lr*2)': Adam(learning_rate*2, decay=decay),
'Adam(lr*4)': Adam(learning_rate*4, decay=decay),
}
test_dict['Adamax'] = {
'Adamax(lr/4)': Adamax(learning_rate/4, decay=decay),
'Adamax(lr/2)': Adamax(learning_rate/2, decay=decay),
'Adamax(lr)': Adamax(learning_rate, decay=decay),
'Adamax(lr*2)': Adamax(learning_rate*2, decay=decay),
'Adamax(lr*4)': Adamax(learning_rate*4, decay=decay),
}
test_dict['Nadam'] = {
'Nadam(lr/4)': Nadam(learning_rate/4, decay=decay),
'Nadam(lr/2)': Nadam(learning_rate/2, decay=decay),
'Nadam(lr)': Nadam(learning_rate, decay=decay),
'Nadam(lr*2)': Nadam(learning_rate*2, decay=decay),
'Nadam(lr*4)': Nadam(learning_rate*4, decay=decay),
}
test_dict['Adam vs AMSGrad vs Adamax vs Nadam'] = {
'Adam': Adam(lr=learning_rate, decay=decay),
'AMSGrad': Adam(lr=learning_rate, amsgrad=True, decay=decay),
'Adamax': Adamax(lr=learning_rate, decay=decay),
'Nadam': Nadam(lr=learning_rate, decay=decay),
}
test_dict['RMSprop'] = {
'RMSprop(lr/4)': RMSprop(learning_rate/4, decay=decay),
'RMSprop(lr/2)': RMSprop(learning_rate/2, decay=decay),
'RMSprop(lr)': RMSprop(learning_rate, decay=decay),
'RMSprop(lr*2)': RMSprop(learning_rate*2, decay=decay),
'RMSprop(lr*4)': RMSprop(learning_rate*4, decay=decay),
}
test_dict['RMSprop(2)'] = {
'RMSprop(m=0.0)': RMSprop(learning_rate, decay=decay),
'RMSprop(m=0.5)': RMSprop(learning_rate, momentum=0.5, decay=decay),
'RMSprop(m=0.0,centered)': RMSprop(learning_rate, centered=True, decay=decay),
'RMSprop(m=0.5,centered)': RMSprop(learning_rate, momentum=0.5, centered=True, decay=decay),
}
test_dict['Adadelta'] = {
'Adadelta(lr/4)': Adadelta(learning_rate/4, decay=decay),
'Adadelta(lr/2)': Adadelta(learning_rate/2, decay=decay),
'Adadelta(lr)': Adadelta(learning_rate, decay=decay),
'Adadelta(lr*2)': Adadelta(learning_rate*2, decay=decay),
'Adadelta(lr*4)': Adadelta(learning_rate*4, decay=decay),
}
test_dict['Various'] = {
'SGD': SGD(learning_rate, momentum=0.0, decay=decay),
'MomentumSGD(m=0.5)': SGD(learning_rate, momentum=0.5, decay=decay),
'NAG(m=0.5)': SGD(learning_rate, momentum=0.5, nesterov=True, decay=decay),
'Adagrad': Adagrad(learning_rate, decay=decay),
'RMSprop': RMSprop(learning_rate, momentum=0.0, decay=decay),
'RMSprop(m=0.5)': RMSprop(learning_rate, momentum=0.5, decay=decay),
'Adam': Adam(learning_rate, decay=decay),
'Adamax': Adamax(learning_rate, decay=decay),
'Nadam': Nadam(learning_rate, decay=decay),
}
testOptims2(
test_dict[test_type],
total_steps=steps,
lossFn=loss_type,
title='{0} (learning_rate={1}, decay={2})'.format(test_type, learning_rate, decay)
)