今回コンペに参加しての取組みをまとめました。
RAGに関することはすべて初めての取り組みだったので関係各社様のツールがほとんど使えなかったのが心残りですが、RAG周りの技術に触れたのは良い経験になりました。
他の方も同じコンペで様々な観点で投稿されているかと思いますが、どういったものかを共有できれば幸いです。
他コンペ参加者 投稿ページ(2025年2月17日時点まとめ)
- 【dataiku】非エンジニアがGUIツールでRAGを実装してみた
- Dataikuで実施するRAG構築 1 - セットアップ使用感 -
- よくわからないうちにDataikuでRAG構築できたようです
- 第3回 金融データ活用チャレンジ RAGシステムを作らずに質問に回答しよう!
- Dataiku社営業マン(文系ノーコーダー)が金融データ活用チャレンジに挑む!vol.2 (RAG編)
- 第3回金融データ活用チャレンジ 感想戦
- 第3回 金融データ活用チャレンジ 振り返り (Azure OpenAIの感想)
- #11 コンペ初参加、RAG初心者、非エンジニアによる金融データ活用チャレンジ体験レポート
- 第3回金融データ活用チャレンジへの取組み
- Azure OpenAIのRAGナレッジ検索をエクセルに実装しました
- DataikuでRAG構築!
- FDUA 第3回金融データ活用チャレンジに参加してみた! #1 データの準備
- 【dataiku】未経験転職して7か月のエンジニアは『第3回金融データチャレンジ』に散った
- FDUA 第3回金融データ活用 ”ドタバタ” チャレンジ ~初めてRAGに挑戦 with HITACHI~
- 【SIGNATE】第3回金融データ活用チャレンジ 41th Solution
- 【SIGNATE】第3回金融データ活用チャレンジ (DataRobot)
- DataRobotで構築したベクターDBの中身を確認する
- 第3回金融データ活用チャレンジ で DataRobotを使ってみた
- 第3回金融データ活用チャレンジ参加記
- FAISSとAzure OpenAIを組み合わせたRAGシステム
- 【SIGNATE】第3回金融データ活用チャレンジ LlamaIndexチュートリアルを参照して
- 【SIGNATE】第3回金融データ活用チャレンジ(振り返り):Dataiku 13.4新機能のドキュメント埋め込み(Vision LLMs)を試してみた
- 第3回 金融データ活用チャレンジ GPT vs Gemini vs DeepSeek、最適なAIは?
- RAGにおける表やグラフの処理 第3回金融データ活用チャレンジ
- 第3回金融データ活用チャレンジに参加しました。
- Dataikuを活用したマルチモーダルRAG構築(第3回金融データ活用チャレンジ)
- (FDUA✖️金融庁共催) 第3回金融データ活用チャレンジ(RAGコンペ)への挑戦
- 第3回金融データ活用チャレンジの参加体験記(Azure Open AI)
- 【SIGNATE】(金融庁共催)第3回金融データ活用チャレンジ: Hybirid RAG system
- 【SIGNATE】(金融庁共催)第3回金融データ活用チャレンジ:LLMモデルの比較
- 第3回金融データ活用チャレンジに参加 コードをまとめてみる
- LLMの実験管理 Langfuse & Ragas - 金融コンペと供に -
- 第3回金融データ活用チャレンジ奮闘記 〜PDFの読み取りが得意なLLM探しとローカルOpenSearchによるハイブリッド検索〜
- RAGを知って、一ヵ月で「第3回金融データ活用チャレンジ」ゴールドメダル(暫定)取得まで
- 第3回金融データ活用チャレンジ参加記 ~仲間とともに参加し,Dataikuを活用~
- 第3回金融データ活用チャレンジに参加してみた感想
自身の取り組み結果

- 順位: 231位(/635人(投稿), /1544人(コンペ参加))
- 最終スコア: 0.14
0. 環境
- 実行環境: Google Colab
- GUI: DataRobot, Dataiku
- インプットデータ: PDF(ページ数は2桁-3桁ページ)
- 出力: 回答テキスト
- 利用可能LLM: MicroSft(GPT-4o-mini), 日立製作所(Llama3.3-70b, qwen2.5-72b), その他(各自の判断で)
0.X DataRobot
DataRobotは、専門的なプログラミング知識がなくても、ドラッグ&ドロップなどの直感的な操作で機械学習モデルの作成、評価、運用までを自動化できるAIプラットフォームです。豊富なアルゴリズムと自動化機能により、膨大なデータから最適な予測モデルを短時間で構築し、ビジネスの意思決定をサポートします。GUIベースの操作により、データの前処理やモデルのチューニングも容易に行えるため、データサイエンティストだけでなく、ビジネスユーザーにも使いやすいツールです。
0.X Dataiku

Dataikuは、データの取得、前処理、可視化、機械学習モデルの構築・評価、さらにはレポート作成や運用までを一貫してサポートする統合プラットフォームです。GUIを中心とした直感的なインターフェースにより、ノーコード・ローコードでのデータ分析が可能となり、技術的な専門知識がなくても誰でもデータ活用に取り組むことができます。チーム内でのコラボレーション機能も充実しており、部署横断的にデータ分析プロセスを共有・改善できる点が大きな特徴です。
1. 背景
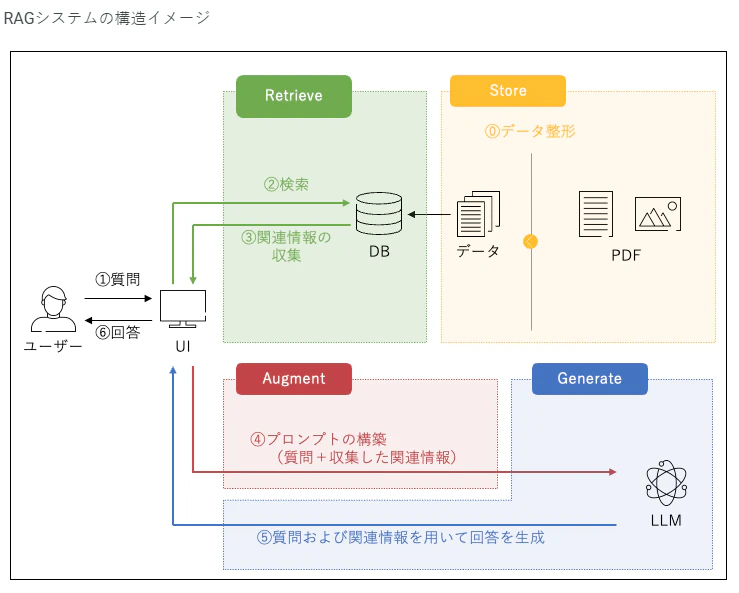
近年、企業の持続可能性や社会的責任への関心が急速に高まる中、ESG(環境・社会・ガバナンス)レポートや統合報告書は、企業の透明性や信頼性を示す重要な情報源として位置付けられています。しかし、これらの報告書は膨大なデータや詳細な情報を含んでおり、関係者が必要な情報を迅速かつ的確に把握することは容易ではありません。そこで、今回のコンペティションでは、企業のESGレポートや統合報告書に関連する質問に対し、引用を行いながら自動かつ正確に回答できるRAG(Retrieval Augmented Generation)システムの構築を目指しました。
2. 課題
本コンペティションでは、J-LAKEの情報(パートナー企業DATAZORAが提供するKIJIサービスのデータを含む)を活用し、どのようにして大量の文書データから必要な情報を抽出し、回答に反映するかが大きな課題となりました。限られた時間の中で、正確性と効率性の両立が求められたのです。
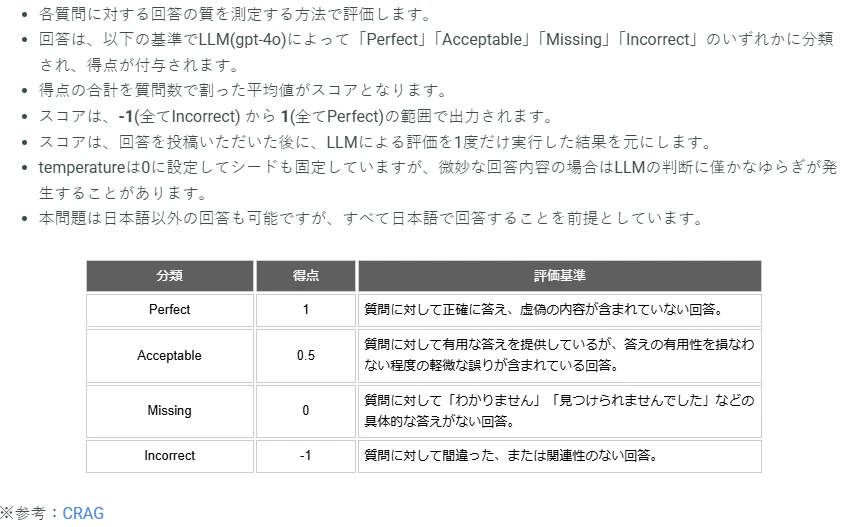
2.1 評価方法
3. 作業内容と検討事項
3.1 個人的な目的
以前、Difyを用いてAPI経由でLLM(大規模言語モデル)を利用していたものの、RAGの実践経験はほとんどありませんでした。今回のコンペティションは、現状のRAG技術のレベルや実運用での可能性を体感する絶好の機会となりました。
3.2 初手とデータ処理
- 初手:document.zipをDataRobotに投入し、文書データのベクトル化を実施。DataRobotは非常に優秀で、初期設定のままでも引用を伴う回答作成が可能であることを確認しました。
- DBの分割:回答前に引用するドキュメントを会社ごとに切り分けることで、誤った引用を防ぐ工夫を実施しました。これはDataRobotの画面で操作することで直感的に登録ができ、ノーコードで作成することができるのでとても楽でした。
-
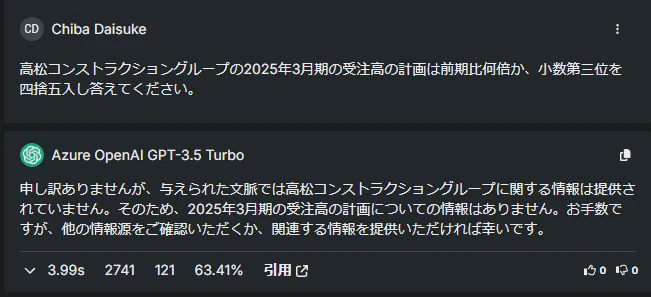
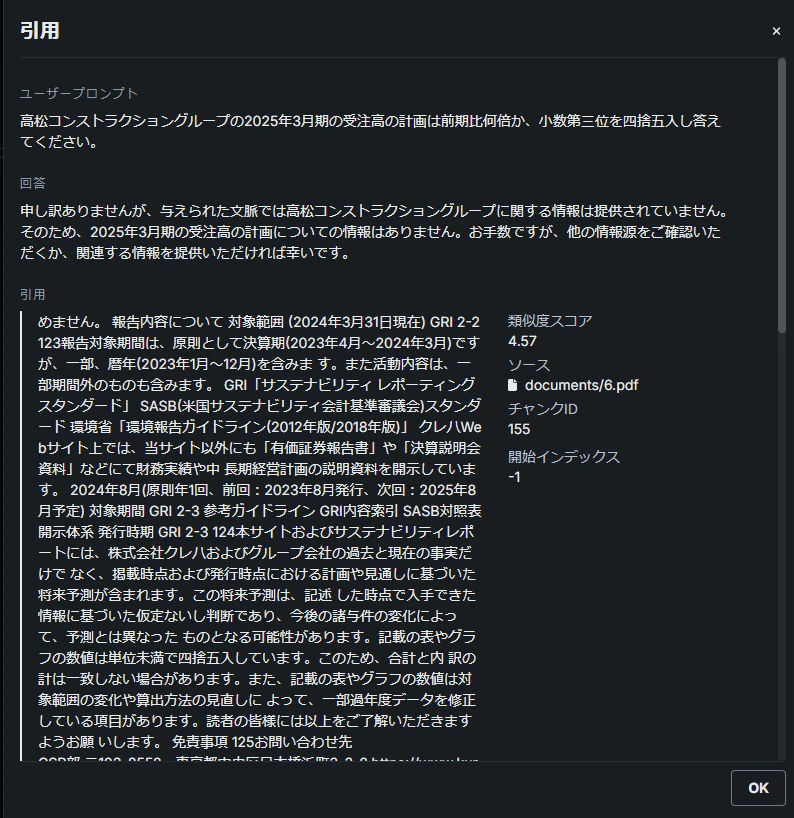
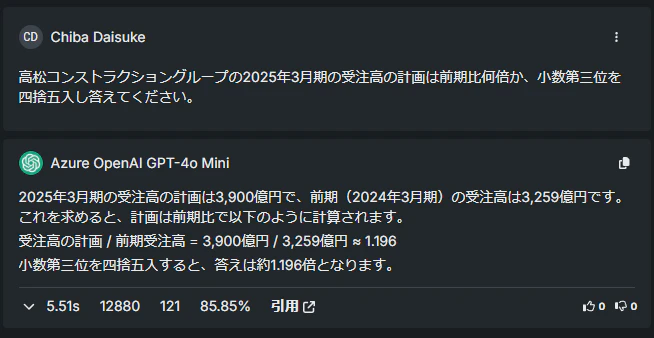
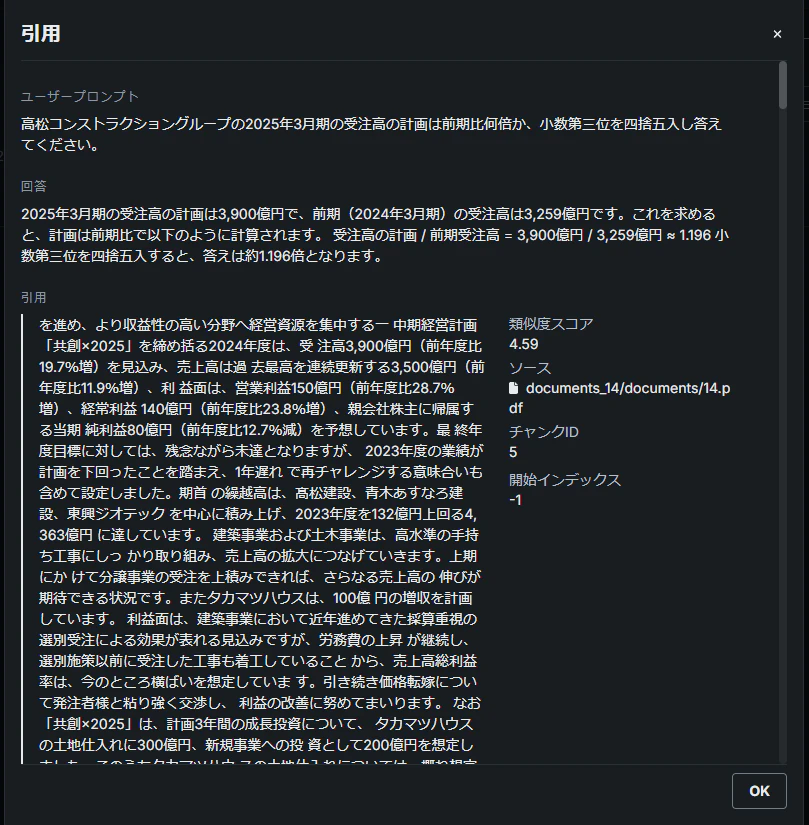
回答の作成: 上記の環境でDataRobot上で回答させた結果は以下となりました。特に、当たり前ですが、引用ドキュメントを切り分けることができれば引用精度も上がることが確認できます。
-
PDF引用(全体(63.41%)):
↓
-
PDF引用(特定した場合(85.85%)):
↓
-
3.3 Dataikuの活用とロジック作成
Dataikuを利用し、OCRを含む各種ロジックを組み立てました。オブジェクト指向でのロジック作成に挑戦し、どの部分を自動化できるか、また手動での対応が必要な部分はどこかを検討しました。なお、Dataiku上で共通関数の書き方が把握できなかったため、すべて個別に作成する形となりました。

↓拡大
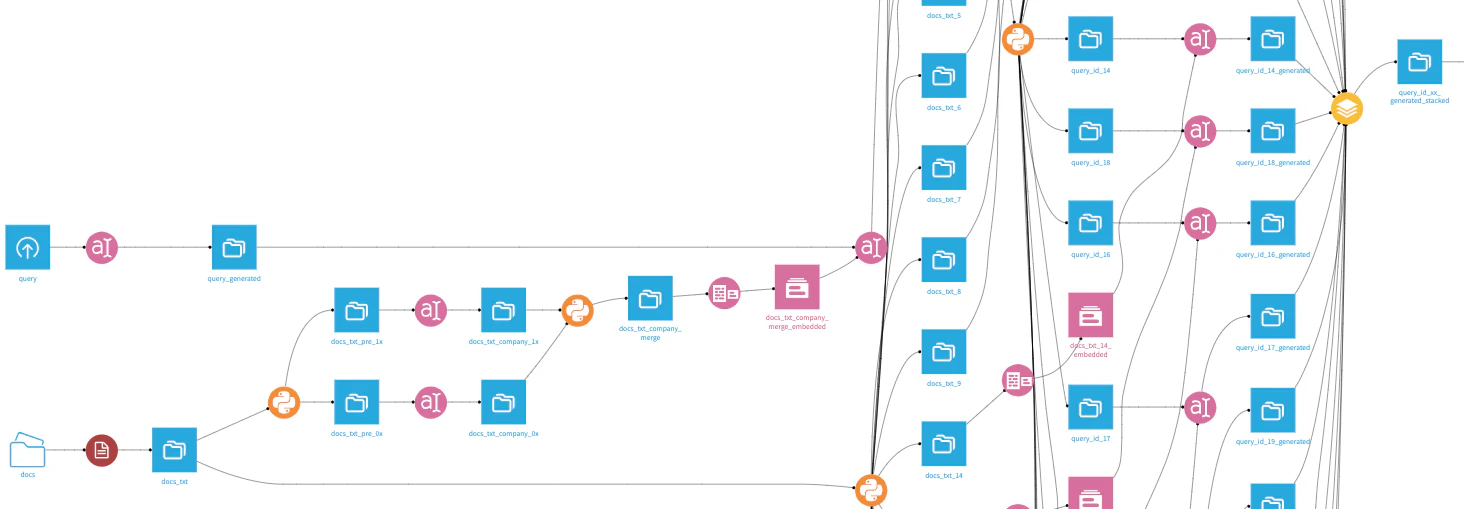
3.4 回答作成のアプローチ
- GPT-4o-miniの利用:初期段階では、GPT-4o-miniを用いてどの程度回答が生成できるかを検証しました。
- 回答のスコアリング:最初の投稿では-0.20のスコアを記録。全くわからない場合は0.00になるため、回答の質向上に努めました。
- プロンプトの改善:より良い回答を得るため、具体的なプロンプト例を提示するなど、プロンプト設計に工夫を凝らしました。
- プロンプト例
# 命令文 あなたは、企業の統合報告書を解析し、ユーザーの質問に回答する専門家AIエージェントです。以下の手順に従い、ユーザーからの質問に対して、最も適切で詳細な回答を生成してください。 **手順:** 1. **質問の理解:** ユーザーの質問を注意深く読み、その質問の**意図**と**必要な情報**を特定します。質問のキーワードを抽出し、質問が何について尋ねているのかを正確に理解してください。 * 例:質問が「2023年度の売上高は?」の場合、意図は「2023年度の売上高に関する情報を知りたい」であり、必要な情報は「2023年度」「売上高」となります。 2. **思考の連鎖(CoT)による分析:** 質問を理解した後、以下の思考プロセス(CoT)を実行し、回答を導き出してください。 * **ステップ1:質問の再構成と拡張:** 質問をより詳細な形に再構成し、必要な情報を特定するための具体的な質問に展開します。5W1Hを意識し、関連指標やデータの所在を特定する質問を含めます。 * 例:「2023年度の売上高は?」 → * 「2023年度の連結売上高はいくらか?」(When, Whatを明確化) * 「2023年度の連結売上高は、統合報告書のどのページに記載されているか?」(Whereを明確化) * 「2023年度の連結売上高の増減率は前年度比でどの程度か?」(計算の必要性を明示) * 「セグメント別の売上高はいくらか?」(関連情報を考慮) * 「主要なセグメントとその売上高構成比は?」(詳細な情報を要求) * 「売上高の増減要因は何か?」(Whyを考慮) * **ステップ2:関連情報の特定:** 再構成された質問に基づいて、統合報告書から関連する情報を特定します。財務諸表、経営成績、事業等のリスクなど、関連するセクションを特定し、必要な情報が含まれているページ番号やセクション名を記録します。 * 例:「2023年度の売上高は、連結損益計算書の『売上高』の項目に記載されている。また、セグメント別売上高は、注記情報の『セグメント情報』に記載されている可能性がある。」 * **ステップ3:情報の抽出と整理:** 特定した情報から、質問に答えるために必要なデータを抽出します。数値データ、テキストデータなどを整理し、回答の根拠となる情報を明確にします。 * 例:「2023年度の連結売上高は1兆円、前年度比で5%増加。主要セグメントであるA事業の売上高は6,000億円で、全体の60%を占めている。」 * 例:「ページ2から、2023年度の連結売上高は1兆円、前年度比で5%増加していることがわかる。ページ4から、主要セグメントであるA事業の売上高は6,000億円で、全体の60%を占めていることがわかる。」 3. **メタデータの出力:** 上記の思考プロセス(CoT)を以下のフォーマットで出力してください。これは、AIエージェントが思考プロセスを追跡し、ユーザーに説明する際に役立ちます。 ```json { "質問": "ユーザーの元の質問", "意図": "質問の背後にあるユーザーの意図", "再構成された質問": [ "質問を詳細化した質問1", "質問を詳細化した質問2", "..." ], "関連情報": [ { "セクション": "関連情報のセクション名", "内容": "関連情報の概要" }, "..." ], "抽出データ": [ { "項目": "抽出したデータの項目", "値": "抽出したデータの値", "単位": "抽出したデータの単位" } }4. **回答の出力:** 最後に、ステップ2で構成した最終的な回答をユーザーに提示してください。ただし、回答ができない場合は「回答なし」としてください。 **制約条件:** * 回答は、添付された統合報告書の情報のみに基づいて生成してください。 * 不明確な点がある場合は、「より具体的な情報が必要」と返答しつつ、現段階で分かる範囲で回答を提示してください。 * 常に丁寧な口調で回答してください。 * CoTのメタデータを出力してください。 **統合報告書(チャンク化データ):** [チャンク化データ] **ユーザーの質問:** [ユーザーの質問を入力]
3.5 引用ドキュメントとチャンク化の工夫
PDFデータのテキスト化をNotebookLMを用いて先に作成し、DataRobotで作成したチャンクデータをベクトル化し、類似度上位10個を抽出するロジックを用いることで、回答の精度向上に寄与しました。また、PDFデータのテキスト化に関しては、既存の変換データをチャンク分割して回答に利用する方針に変更し、最大のスコアを獲得できた点は大きな成果でした。
3.6 課題と気づき
-
テキスト化の課題:PDFのテキスト変換では、文章部分は十分に前後関係が保たれている一方、表やグラフ、画像からの情報抽出には課題が残りました。このため、構造化データとしての抽出方法を検討する必要があると認識しました。
- テキスト化と構造化: たとえば、「2023年度 売上10,000百万円」のようなデータは構造化することで有効な情報となりますが、コンテキスト情報が欠落する恐れもあるため、並行して利用するアプローチが望ましいと感じました。
- 回答の簡略化:質問内容が既に存在するため、LLMにそのまま回答例を作成させる方法を試みたところ、回答が簡潔になり、全体の品質が向上する結果となりました。
3.7 自身の最終結果スコア
- 順位: 231位(/635人(投稿), /1544人(コンペ参加))
- スコア: 0.14
4. まとめ
今回の金融データチャレンジを通じて、ESGレポートや統合報告書という膨大かつ複雑な情報源から、必要な情報を迅速かつ正確に抽出するRAGシステムの可能性と課題を実感しました。データの前処理、プロンプトの最適化、そして引用ロジックの整理といった多方面での工夫が必要であることが分かり、今後の改善点や新たなアプローチのヒントを得ることができました。
結局のところ、LLMそのものの問題ではなく、LLMに渡す情報の整備(お膳立て)が極めて重要であり、データの前処理が必要不可欠であると再認識しました。いわゆる「データ分析は前処理が8割」と言われるように、RAGシステムの構築においても「インプットデータ >>> インプットデータの構造化・蓄積 > データ検索環境の構築 >>> LLM(プロンプト含む)」という流れが大切だと感じました。
この経験をもとに、さらなる技術の向上と実運用でのシステム精度の向上を目指していきたいと考えています。
X. ChatGPTに今後の展望と課題を考えさせてみた
5. 今後の展望と課題
5.1. 異種データの統合と前処理の標準化
現在は会社ごとのPDFデータを個別に処理していますが、将来的には複数企業の文書を横断的に比較するため、フォーマットや内容、表現方法が大きく異なるデータを統合・標準化する必要があります。
-
課題点:
- 企業ごとにフォーマットが異なるため、統一的な前処理パイプラインを構築する難しさ
- テキスト、画像、表、グラフなど多様な情報を一元管理する仕組みの整備
-
必要な知見:
- 高性能なOCRや多モーダルデータ処理の技術
- 共通のデータフォーマット設計と、柔軟に対応可能な前処理アルゴリズムの開発
5.2. スケーラビリティの向上
データ量が増大すると、ベクトル化や検索、回答生成のプロセス全体の処理速度とストレージコストが重要な問題となります。
-
課題点:
- 膨大なデータセットに対する高速かつ正確な検索の実現
- クラウド環境や分散処理技術を利用した効率的なシステム運用
-
必要な知見:
- クラウドベースの分散処理技術(例:Spark、BigQuery)の統合方法
- 最新の埋め込みモデルやベクトル検索アルゴリズムの採用とチューニング
5.3. セキュリティとプライバシーの強化
複数企業のデータを横断的に扱う場合、情報の機密性や権限管理がより複雑になります。
-
課題点:
- 各企業の機密情報や個人情報を安全に扱うためのアクセス制御や暗号化対策
- 異なる企業間でのデータ共有に伴うプライバシーリスクの管理
-
必要な知見:
- データ匿名化やマスキング技術
- セキュリティポリシーの策定と、厳格なアクセス管理システムの構築
5.4. 評価基準とフィードバックループの確立
企業間比較を行う際、各社のデータ特性に合わせた評価基準が必要です。
-
課題点:
- 参照ドキュメント選択と回答生成のプロセスを個別に評価する仕組みの構築
- 自動評価(NonLLM評価、LLMによるメタ評価)と実際のユーザーフィードバックの統合
-
必要な知見:
- 最新の評価指標(例:RAGBench、TRACe評価フレームワーク)の活用
- 継続的な改善を可能にするCI/CDパイプラインの構築
5.5. 柔軟なカスタマイズと汎用性の両立
企業ごとに異なる業務ニーズに対応するため、RAGシステムはカスタマイズ性と汎用性のバランスをとる必要があります。
-
課題点:
- 特定業界に特化した調整と、複数企業間での共通評価との両立
- ファインチューニングとRAGの組み合わせによる最適化戦略の策定
-
必要な知見:
- アジャイル開発手法を活用した迅速なプロトタイピングと改善
- LLMおよび埋め込みモデルの最新動向を踏まえた柔軟なシステム設計
6. 総括
今後、RAGシステムは「会社ごとのPDFデータ」を対象とした初期実装から、異なる企業間や業種横断的なデータ統合・比較を行うシステムへと進化していくと予想されます。そのためには、データ統合・前処理、スケーラビリティ、セキュリティ、評価、そして柔軟なカスタマイズの各領域で、最新技術と実践的なノウハウを組み合わせた総合的なアプローチが不可欠です。これにより、より正確で迅速な回答生成と、ユーザーが信頼できるシステムの実現が期待されます。
今後の展開では、RAGシステムの実装・評価方法に関する研究や、業界横断的な共通データセットの整備、さらに自動評価システム(LLMOpsなど)の構築が、より高度な運用と改善の鍵となるでしょう。
このような知見を活かし、企業間の比較や大規模データへの対応を実現することで、RAGシステムはさらに業務効率化や意思決定の精度向上に寄与していくと考えられます。
参考)LLMOpsについて
今回ツール提供いただいたDataRobotには生成モデルの監視が実装されていますので、興味がある方はこちらをご参考ください。