1. はじめに
FDUA主催の「第3回金融データ活用チャレンジ」に参加し、初めて RAG構築に挑戦 しました。
この記事では Dataiku を使って私が取り組んできた内容を記載しています。
今までブログを書いたことはなかったのですが、 初心者 である自分の取り組みを発信することで、これから RAG構築する方の参考 になったら嬉しいです。
2. 自己紹介
金融業界でデータ分析を担当する部署に所属しています。
社会人になってからプログラミングを学び始め、 データ分析歴は4年 です。
RAGについては素人ですが、「初心者がどこまでできるのか 」 挑戦する気持ちで参加しました。
3. 参加したデータコンペについて
「第3回金融データ活用チャレンジ」はFDUAと金融庁の共催で行われました。
以下は本コンペの概要です。(サイトより引用)
課題
本コンペティションでは、J-LAKE(*パートナー企業であるDATAZORAのKIJIサービス提供データを含む)の情報を用いてRAGシステムを構築していただきます。提供されたデータを元に、質問(query.csv)に対する回答を生成し、その回答の精度を競います。 生成した回答は、指定のフォーマットに従い、投稿してください。
統合報告書等を参照元としてRAGを構築し、与えられた問題に対する回答精度を競います。
手厚いサポート(↓)があり、 初心者でも参加しやすい コンペになっていました。
- 各種ツールやAPIキーの無償提供
- ハンズオン
- SlackでのQA対応
精度向上 はもちろん、 Dataikuを使い倒す ことも目標の一つとして取り組みました。
4. 分析環境について
Dataikuのクラウド版と、Microsoftから無償提供されたMicrosoft Azure OpenAI(AOAI)を使用しました。
Dataikuの初期設定はこちらのサイトを参考に実施しています。
インストール版とクラウド版では、画面のレイアウト等が異なる点に注意してください。
5. Dataikuでやってみたこと
Dataikuで取り組んだ内容を5つご紹介します。
試行錯誤しながら取り組んできたので、読みづらい部分もあるかと思いますがご容赦ください。
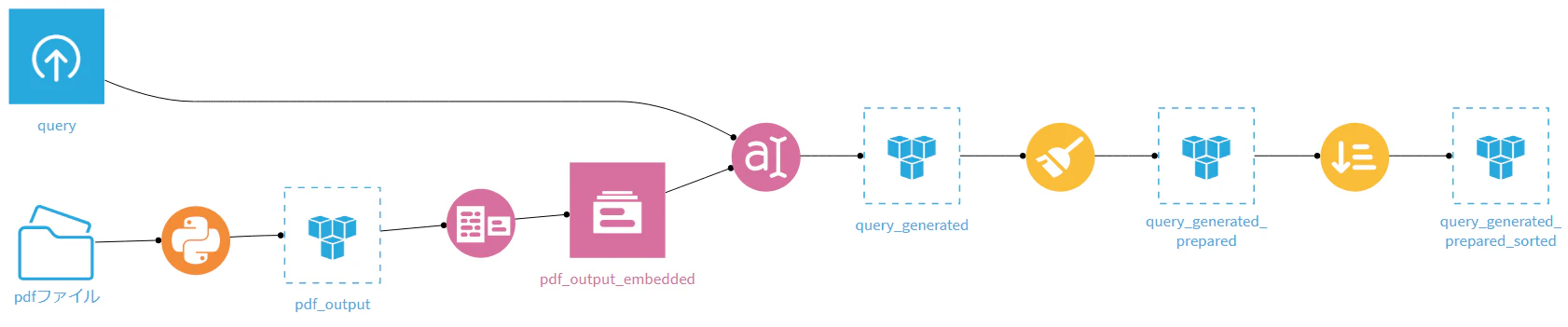
5.1. まず作ってみる
最初は 提出する ことを目標に、先ほどのサイトを見ながらRAGを構築しました。
作成したフローはこんな感じです。

どんなことをやっているのか、処理ごとに簡単に記載します。
-
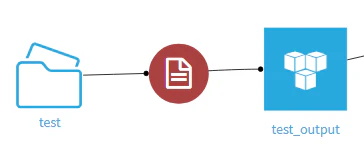
参照元となるPDFファイルをアップロード(test)し、
プライグインレシピのText extractionを実行
⇒ テキスト化されたデータ(test_output)が作成される
-
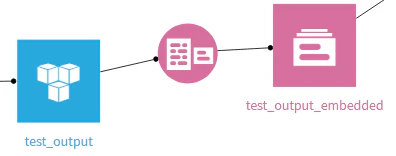
テキスト化したデータ(test_output)に
LLMレシピの埋め込みを実行
⇒Knowledge Bankが作成される
-
アップロードした質問データ(query)に
LLMレシピのプロンプトを実行
※先ほど作成したKnowledge Bankを選択する
⇒ 作成したRAGを用いて回答(query_generated)が生成される

-
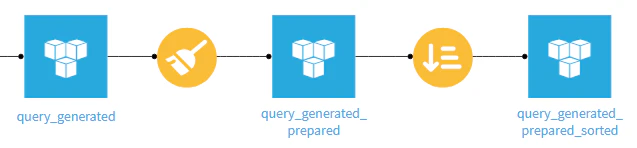
ビジュアルレシピの準備(不要項目の除外、補正、等)や並べ替えを使い、データを加工する
⇒ 投稿用データ(query_generated_prepared_sorted)が作成できる
実行してきた事がフローで見られるため、RAG構築の流れを理解しながら進めることができました。
試しに、エクスポートしたデータを投稿した結果...スコアは 0.04(暫定評価※) でした!
リーダーボードを見るとマイナス評価も多いようで、深く考えずに作ったものとしてはまずまずの精度かと思います。Dataikuへの期待が高まってきました![]()
さらに、ここまで特に悩むこともなく、 初心者 でも 約1時間でRAGを構築 することができました。
※暫定評価
評価用データセット全体の50%で評価されるため、最終的なスコア(全体の100%で評価)とは異なります。
続いて、PDFファイルを事前にPythonでテキスト化たデータを使い、RAGを構築しました。
フローは先ほどと同じです。
テキスト化したデータから構築したフロー
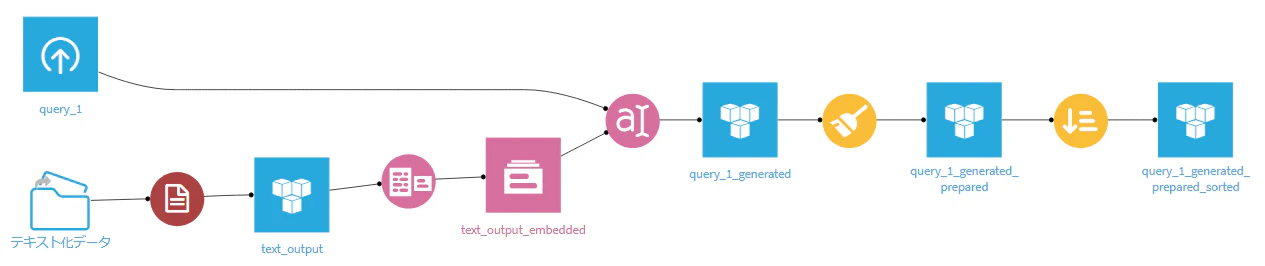
スコアは... 0.09(暫定評価) に上がりました!
(ちなみに、同じデータを再度投稿するとスコア 0.12(暫定評価) でした。ブレが大きいようなので、あくまでも暫定評価であるという点は注意が必要だと思いました。)
5.2. データの前処理
次のステップとして Dataikuで処理を完結させる ことを目標に、 コードレシピ の Python を使ってみました。
これにより Dataiku上 で Pythonを使う ことができます。
左から2番目↓の部分が コードレシピ の Python です。

Pythonのコードも載せておきます。私はフォルダの設定に手間取ってしまいました...。
参考)Pythonコード
import fitz
import tempfile
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
# Read recipe inputs
pdfhuairu = dataiku.Folder(" フォルダ名 ")
pdfhuairu_info = pdfhuairu.get_info()
path = pdfhuairu.list_paths_in_partition()
# 空のリストを作成する
pdf_texts = []
# PDFごとに繰り返し処理を行う
for pdf_file in path:
with pdfhuairu.get_download_stream(pdf_file) as f:
# 一時ファイルに保存
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as temp_file:
temp_file.write(f.read())
temp_file_path = temp_file.name
# 一時ファイルを開いてテキストを抽出
doc = fitz.open(temp_file_path)
output_text = ''
for page in range(len(doc)):
text = doc[page].get_text() # ページからテキストを抽出
output_text += text + '\n' #ファイル単位に1レコード(ページ単位でも良いかも)
# 抽出したテキストをリストに追加
pdf_texts.append({'file': pdf_file, 'text': output_text})
# 一時ファイルを削除
os.remove(temp_file_path)
# データフレームを作成
pdf_output_df = pd.DataFrame(pdf_texts)
# 結果を確認
pdf_output_df
目検で見た限りですが、精度は微妙そうです...。
(投稿回数には制限がある為、こちらのデータは投稿できず![]() )
)
考えられる要因として プラグインレシピ の Text extraction の実施有無、 metadata の設定内容の違いといった事が影響しているのではないかと思いました。
( metadata については後ほど記述します)
5.3. Dataikuの各種機能を実践
マニュアル無しでも一通り構築できるようになってきたので、 Dataikuの機能を色々と試してみる ことにしました。
具体的には以下の4つです。
-
スタック:データを縦結合する機能(ビジュアルレシピで設定)
⇒5.1.と5.2.の回答結果を比較すると、正答できる問題に得意不得意がありそうだったので、データを縦結合すれば正答率があがるのでは?と考えました。 -
Chunk size:各チャンクの最大文字数を調整(LLMレシピの埋め込みで設定) -
Chunk overlap:チャンク間の重複の長さを調整(LLMレシピの埋め込みで設定) -
Improve diversity of documents:選択するドキュメントの多様性を調整(LLMレシピの埋め込み内にあるKnowledge bank settingsで設定) -
topP:確率上位の単語から合計がPになるまで絞り込む機能(LLMレシピのプロンプトで設定)
参考)試行錯誤したフロー
こんな感じで分岐を作りながら試行錯誤していました。ご参考までに。
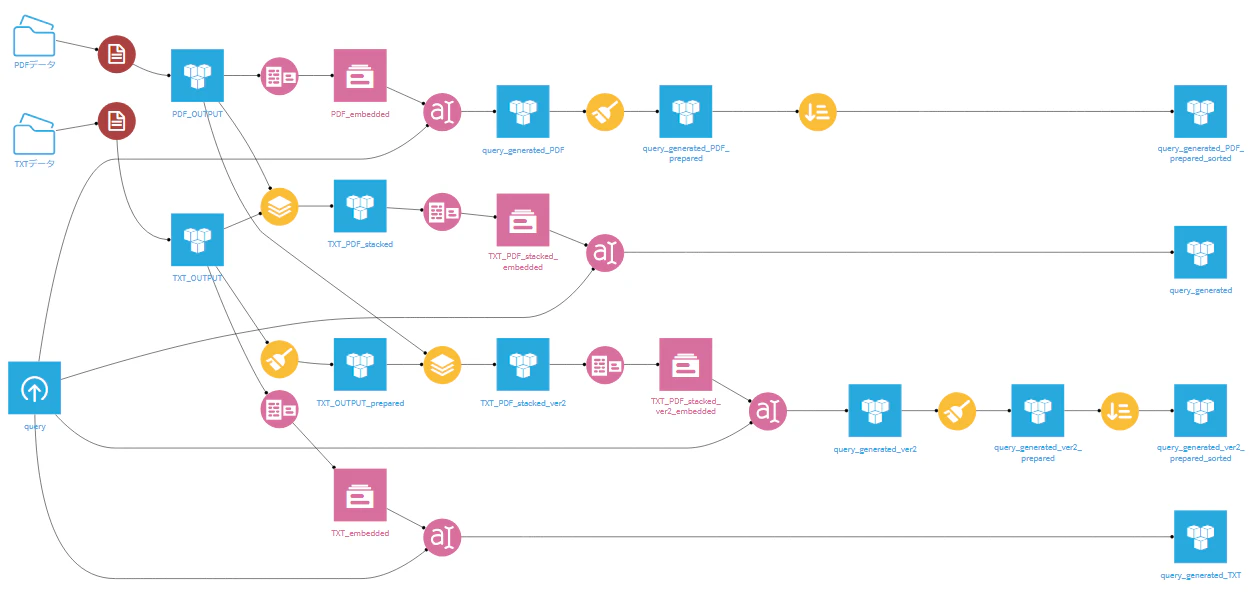
投稿数制限の関係で、選りすぐりのものを投稿してスコアを確認しました。
結果がこちらです↓
| Data pattern | Chunk size | Chunk overlap | Improve diversity of documents | topP | スコア(暫定評価) |
|---|---|---|---|---|---|
| a | 3000 | 120 | なし | 0.7 | 0.09 |
| aとbのスタック | 3000 | 120 | なし | 0.7 | 0.1 |
| a | 3000 | 300 | あり | 0.7 | 0.01 |
| a | 3000 | 500 | なし | 0.7 | 0.12 |
※Data pattern
a:Pythonでテキスト化したデータをアップロードし、OCRで読み取ったデータ
b:Dataiku上でPDFファイルをテキスト化したデータ
これ以外にも様々なパターンを実施し、それぞれの回答を目で見て比較しました。
あくまで個人的な意見になりますが、感じた事を記載します。
-
スタック:回答できるようになった問題もあるが、精度に大きな影響なし -
Chunk size:あまり検証できず(デフォルトの設定は3000) -
Chunk overlap:増やした方が良さそう(デフォルトの設定は120) -
Improve diversity of documents:設定しない方が良さそう -
topP:設定した方が良さそう(0.7くらい?)
増やす/減らす、設定する/しないは一概にどちらが良いと判断できず、扱うデータや組み合わせによっても違ってきそうです。
次やるときにはもっと深堀ってみようと思います![]()
5.4. metadataの設定
このあたりで各種パラメーターの調整に疲れてきてしまい、 何か新しいこと がやりたくなってきました。
そんなとき、 回答を探す手掛かり となるような項目を metadata に設定すると良いと知り、実践してみることにしました。

metadata の組み込みは コードレシピ の Python で実装しています。
参照元のファイル(提供された統合報告書等の19ファイル)に相対する企業名を metadata に組み込みました。
参考)Pythonコード
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
import ast
# Read recipe inputs
PDF_OUT = dataiku.Dataset("PDF_OUT")
PDF_OUT_df = PDF_OUT.get_dataframe()
# 相対表を辞書として定義(株式会社A~Sは具体的な企業名を入れる)
company_mapping = {
'/1.pdf': '株式会社A',
'/2.pdf': '株式会社B',
'/3.pdf': '株式会社C',
'/4.pdf': '株式会社D',
'/5.pdf': '株式会社E',
'/6.pdf': '株式会社F',
'/7.pdf': '株式会社G',
'/8.pdf': '株式会社H',
'/9.pdf': '株式会社I',
'/10.pdf': '株式会社J',
'/11.pdf': '株式会社K',
'/12.pdf': '株式会社L',
'/13.pdf': '株式会社M',
'/14.pdf': '株式会社N',
'/15.pdf': '株式会社O',
'/16.pdf': '株式会社P',
'/17.pdf': '株式会社Q',
'/18.pdf': '株式会社R',
'/19.pdf': '株式会社S'
}
# 新しい列「test」を追加し、fileに対応する社名を入力
PDF_OUT_df['test'] = PDF_OUT_df['file'].map(company_mapping)
# metadataがNaNの場合は空の辞書に置き換え
PDF_OUT_df['metadata'] = PDF_OUT_df['metadata'].replace({None: '{}', pd.NA: '{}', 'nan': '{}', '': '{}'}).astype(str)
# 文字列を辞書に変換
PDF_OUT_df['metadata'] = PDF_OUT_df['metadata'].apply(ast.literal_eval)
# testの値をmetadataに追加
PDF_OUT_df['metadata'] = PDF_OUT_df.apply(lambda row: {**row['metadata'], 'company_name': row['test']}, axis=1)
PDF_OUT_KAKOU_df = PDF_OUT_df # For this sample code, simply copy input to output
# Write recipe outputs
PDF_OUT_KAKOU = dataiku.Dataset("PDF_OUT_KAKOU")
PDF_OUT_KAKOU.write_with_schema(PDF_OUT_KAKOU_df)
投稿すると、スコアは... 0.19(暫定評価) と久しぶりに大きく上がりました!
嬉しい...![]()
metadata の重要性を実感しました。
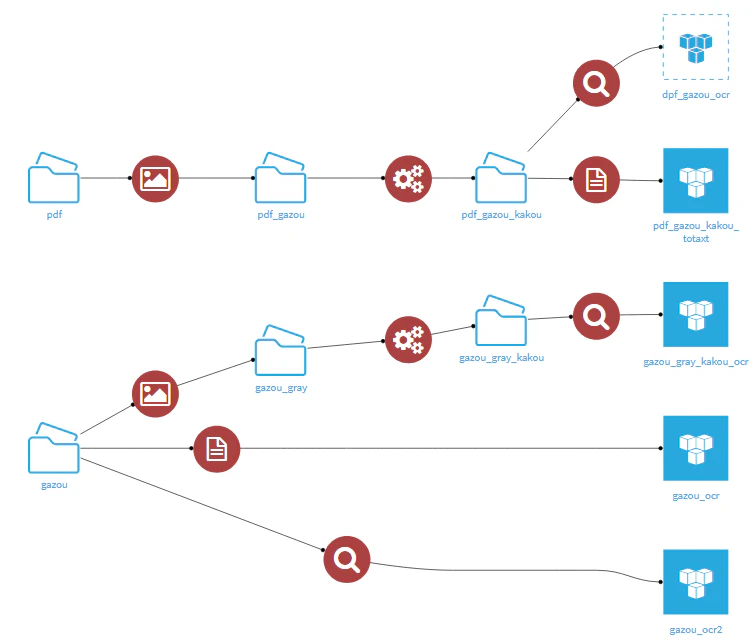
5.5. (+α)画像処理の機能
コンペの残り期間が少なくなってきたので、 まだ使っていない機能を使おう! と考え、 プラグインレシピ に着目しました。
プラグインレシピ には4つの機能が備わっています。
-
Text extraction:PDF / Docx / HTML / 等で保存したドキュメントからテキストを抽出する -
Optical Character Recognition (OCR):PDF / JPG / JPEG / PNG / TIFF として保存された画像からテキストを抽出する -
Greyscale:PDF / JPG / JPEG / PNG / TIFF として保存された画像をグレースケールJPG画像に変換する -
Image processing:上級ユーザー向けの画像処理機能(入力はグレースケールJPG画像にする必要あり)
今までは Text extraction を使っていましたが、せっかくなので他の機能も試してみよう!という感じです。
こちらのサイトを参考に実施しました。
参考)実際に作成したフロー
こちらも試行錯誤しながらだったので、あくまでもご参考までに。
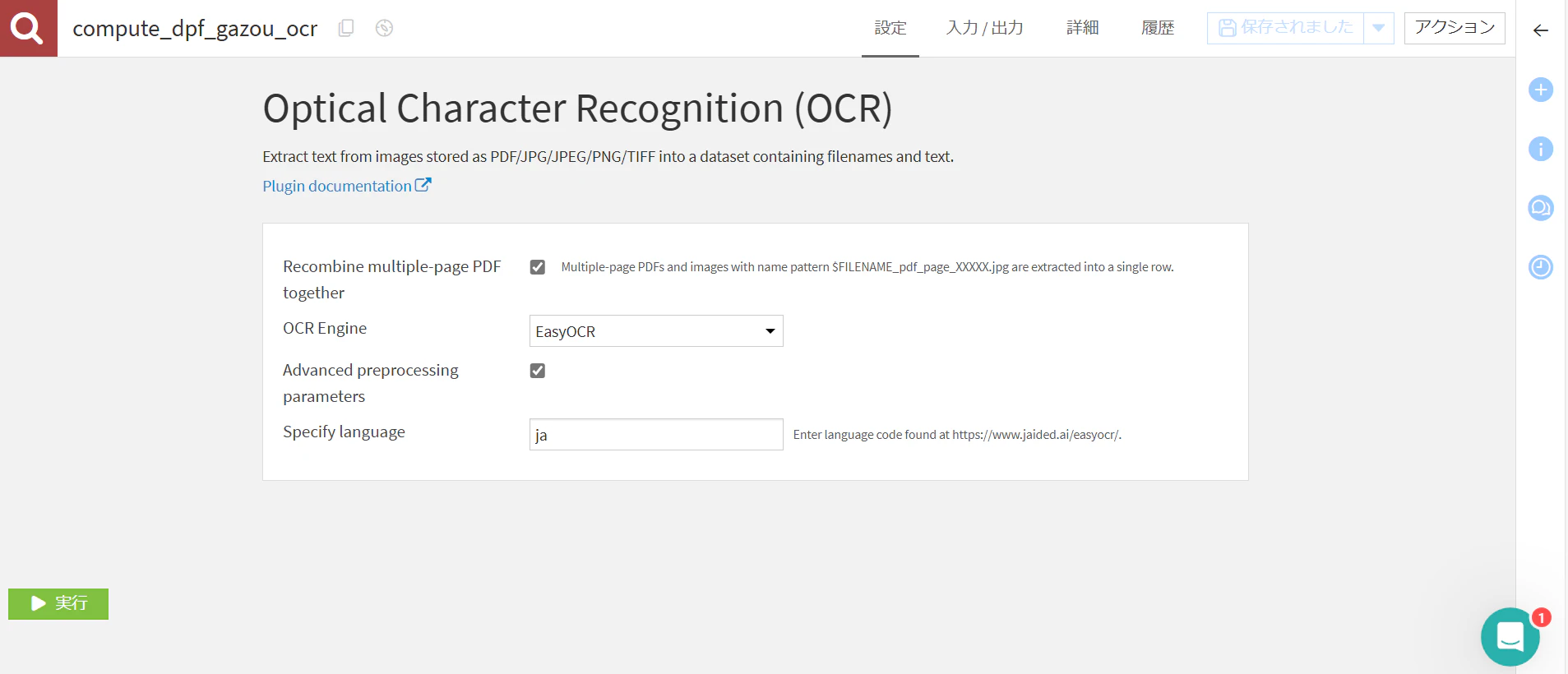
参考)日本語の設定方法
Optical Character Recognition (OCR) は、デフォルトのままだと英語で処理されます。
私はこの設定にすると日本語が読み取れるようになりました。
-
OCR Engine:EasyOCRを選択 -
Advanced preprocessing parameters:チェックを入れる -
Specify language:jaと入力
やってみた結果...日本語の読み取りは非常に難しいようで、単純にこの機能を使っただけでは文章がグチャグチャになってしまいました![]()
また、実行にも時間がかかり、コンペ期間内に全てのPDFファイルをテキスト化することはできませんでした。(コンペ終了間際だった影響もあるのでしょうか...PDF1ファイルあたり数時間かかりました。)
アウトプットまではいきませんでしたが、Dataikuの機能を一つでも多く実践してみることができたので、やって良かったなと思っています!
6. 最終結果
今回は Dataiku で RAG構築 に挑戦しました。
最終評価は 0.19 (暫定評価は0.12)、 上位30%程 の順位となりました!
まだまだやりたかったこともありますが、最後までやり遂げることができたかなと思っています。
余談ですが...
今回私はチームで参加し、最終評価は他のメンバーが作成したデータを提出しました。(0.19より良い精度でした。)
データの前処理に使用していたAPIが自社のセキュリティの関係でDataiku上に実装できず...これもDataikuに実装したかったです。
7. さいごに
Dataiku は目で見て 使い方が分かりやすく 、 初心者 でも 気軽にRAGを構築 することができました。
精度を上げるためには、もっと機能を使いこなしたり、Pythonで高度な処理をしたりする必要があるのかなと感じています。
また機会があったらぜひ 挑戦![]() してみたいです!
してみたいです!
コンペに参加したことで、新しいことを楽しく学ぶことができました![]()
ありがとうございました!