はじめに
Dataikuは"Everyday AI, Extraordinary People"というテーマを掲げ、データ分析やAI活用を広げ、皆様の可能性を開放していく事を目標にしております。
そんな中、FDUA主催の「第3回金融データ活用チャレンジ」に、昨年に引き続き今年もツール提供させて頂く運びとなりました。
本記事は、こちらの素晴らしい取り組みにご参加頂くための手順を分かりやすくご案内する目的で記述しております。
この記事でわかる・できること
- コンペ参加の手順
- Dataikuご利用の準備
- コンペ推進・サブミットまでの流れ(例として解法に触れない範囲で)
この記事の対象者
- 本コンペに参加する全ての方(初めての方を含む)
- Dataikuにご興味のある方
- 生成AIをご活用されたい方
目次
1.コンペ参加の手順
1.1 SIGNATEのコンペページから参加登録
上記ページのリンクから、参加ボタンを押下する事でコンペへの参加が可能です。
- SIGNATEへのユーザー登録が必要ですので、案内に沿って登録・ログインを実施して下さい
- その後コンペへの参加登録に再度ユーザー情報の登録が必要となります
1.2 コンペ情報の把握とデータダウンロード
コンペ登録後の画面にて、説明タブからコンペの概要を把握した上で、「データ」タブから各種データをダウンロードします

- slack_invitation_link.txt を開きいずれかのリンクURLを利用してSlackチャネルへ参加
- 今回は参加者向けのコミュニティとしてSlackチャネルも用意されてます - readme.mdファイルにてその他ファイルの内容や利用用途を確認
- 後ほど推進手順をご案内しますので、概要把握で問題ございません
1.3 Slack内容の確認
今回は各社様より分析ツールや生成AIのAPIが提供されております。
それらの申請はSlackチャネルから実施頂きますので、こちらのSlackの情報を確認して下さい
是非「24-qa_dataiku」のチャネルに遠慮なく投稿して下さいね!
コミュニティとして皆様と一緒に盛り上げていくチャネルにしたいと思っております。
2.Dataiku利用の準備
2.1 利用申請フォームの記入
Dataikuをご利用頂く事で"コンペの推進がより簡単かつスムーズに"実施頂けます。
ご利用に当たっての情報登録をお願いしておりますので、以下のフォーム登録をお願いします。
2.2 製品インストール or クラウド登録
Dataikuでは本コンペ向けにインストール形式の「無料版」とクラウド形式の「無料トライアル版(14日限定)」をご案内しております。
以下のページよりインストールもしくはクラウド登録して下さい
例として無料版のインストール手順を簡単に記載します。
※無料版をお試し頂き、環境設定で躓く場合はクラウド版もご検討下さいませ。
(期限に関してはSlackの問い合わせベースで延長対応を考えております)
-
無料版の「いますぐインストール」をクリック

-
ご利用の環境に適したインストラクションをクリック

-
手順に沿ってインストールして下さい
-
私の環境はMacですが、DataScienceStudioのアプリケーションを起動するとWebブラウザにてDataikuのログイン画面が表示されます

-
初期ログイン情報は変更していなければ下記の通りです
user:admin
pass:admin
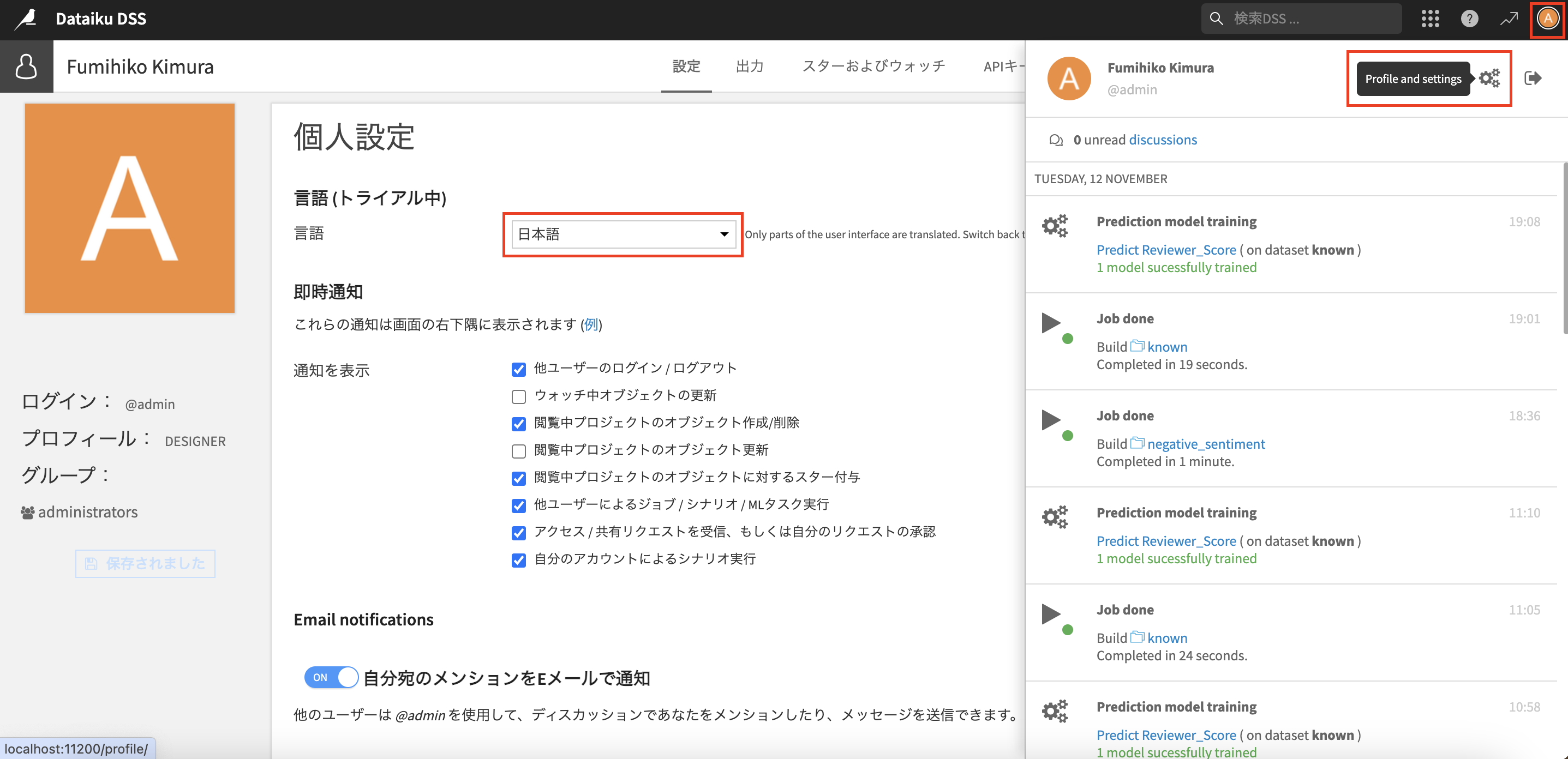
ログイン後に、右上のプロファイルの設定から言語を日本語に変更しておきましょう。
こちらでDataikuの利用が可能になりました!
3.Dataiku分析(RAG)環境準備
3.1 RAG構築に向けたPythonコード環境の準備
Dataikuでは必要なパッケージを事前にリスト化して、簡単にGUI上でpipインストールできる様にしております
-
右上の「ナインドット」から「アドミニストレーション」をクリック

-
「Code Envs」タブをクリックし「NEW PYTHON ENV」ボタンを選択し、名前(Name)を入力してCREATEをクリック
※Python3.9以降が"Not available"の場合はお手持ちの環境(OS)にPythonのインストールか、PATHの確認が必要です。
インストールをお試し頂き、難しい場合は先にご案内のクラウド版の「無料トライアル」もご検討下さい

-
作成したPythonのコード環境が一覧に表示されます。
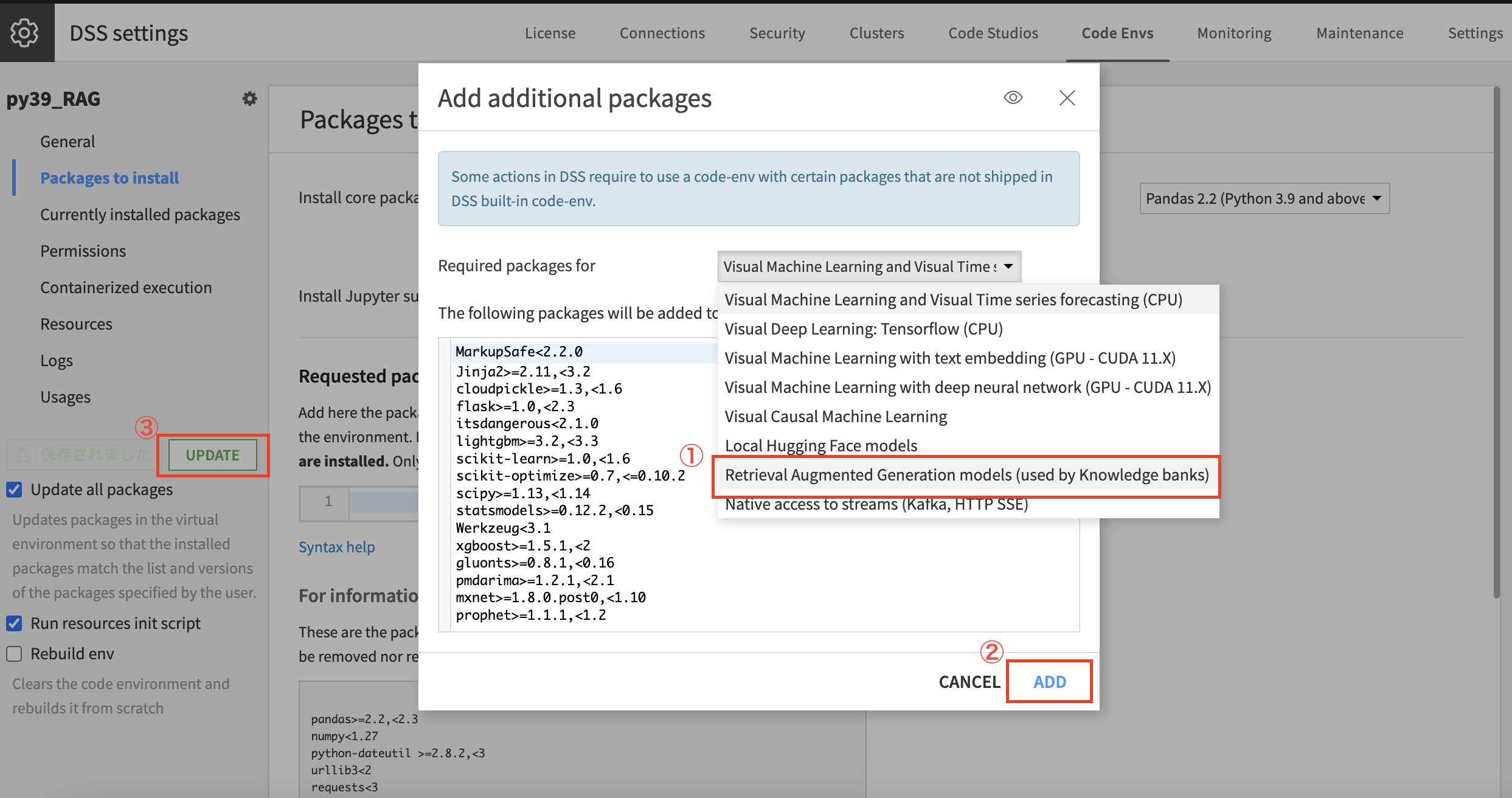
名前がリンクになってますので、そちらを押下して以下の画面を開き、「Packages to install」→「ADD SETS OF PACKAGES」をクリック

-
Required packages forの一覧に「Retrieval Augmented Generation models」がございますので、こちらを選択して「ADD」、その後画面が元の画面に戻りますので、左のパネルから「保存と更新」をクリック
※DataikuではRAG用のパッケージを事前にリスト化しており、GUIですぐに環境準備も完了します。
これでコード環境の準備も完了です!
3.2 PDFをデータをテキスト化(OCR)するプラグインのインストール
今回はPDFのデータを利用してRAGを作成します。
その上でPDFデータのテキスト化に利用するOCR機能のプラグインをインストールします。
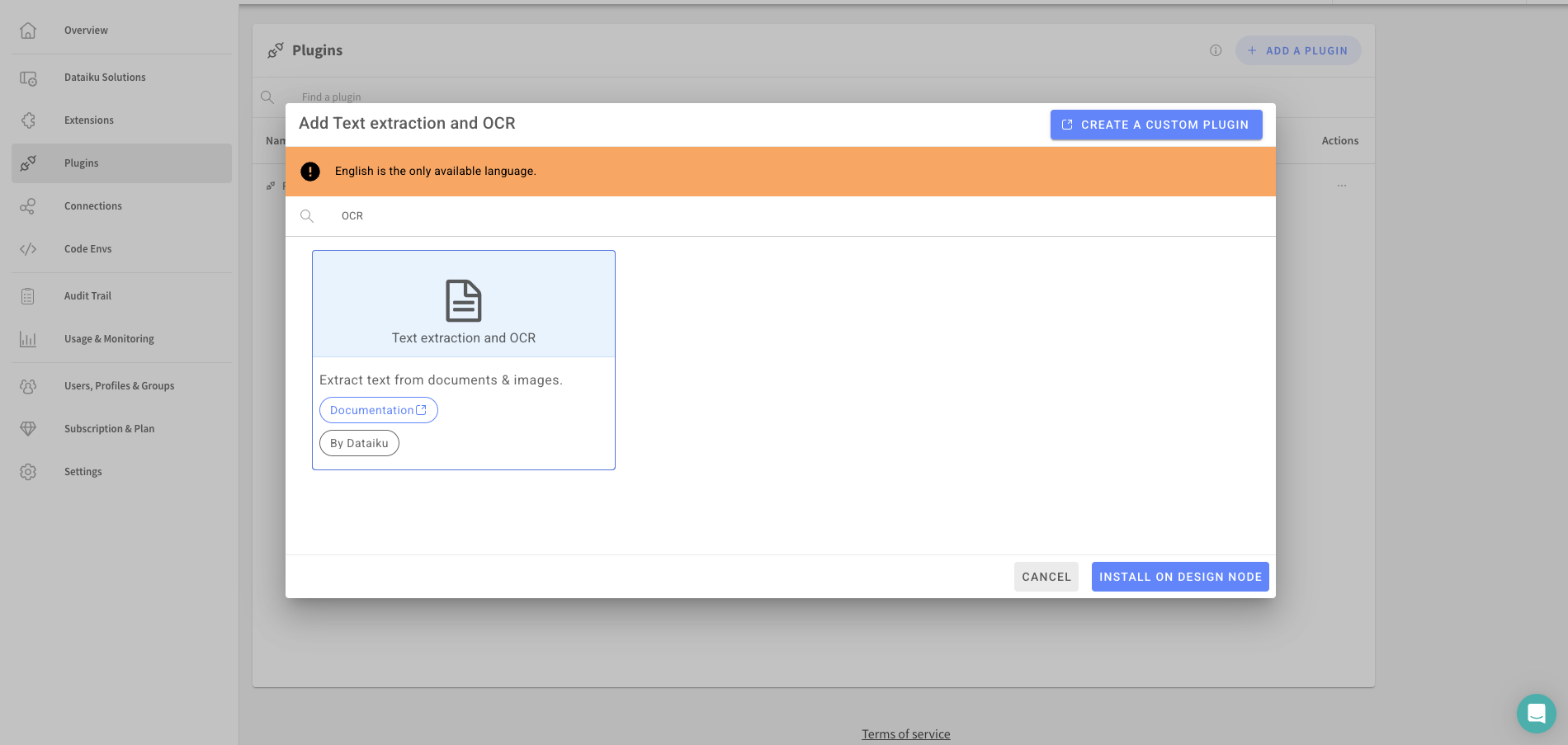
- 右上の「ナインドット」→「プラグイン」をクリック

- 検索窓に"OCR"と入力し、"Text extraction and OCR"をインストール

- 手順に従ってBUILD NEW ENVIRONMENTを実施して進む事でインストール完了です!

(以下追記):クラウド版の場合 Launchpadから「Plugins」→「ADD A PLUGIN」→ OCRと検索して、選択の上「INSTALL ON DESIGN NODE」でインストール完了です! 反映までに少しお時間が掛かります
3.3 生成AIのAPI接続設定
生成AIのAPIは今回Microsoft様と日立様から提供されております。
先にご案内したSlack上で各社様の申請ページからフォームを記載頂くとAPIの情報がメールで送られます。
上記の申請が完了している前提で、Azure OpenAIを例として接続設定の手順を記載します。
-
右上の「ナインドット」→「アドミニストレーション」をクリック→「Connections」タブを選択し→「NEW CONNECTOIN」→「Azure OpenAI」をクリック
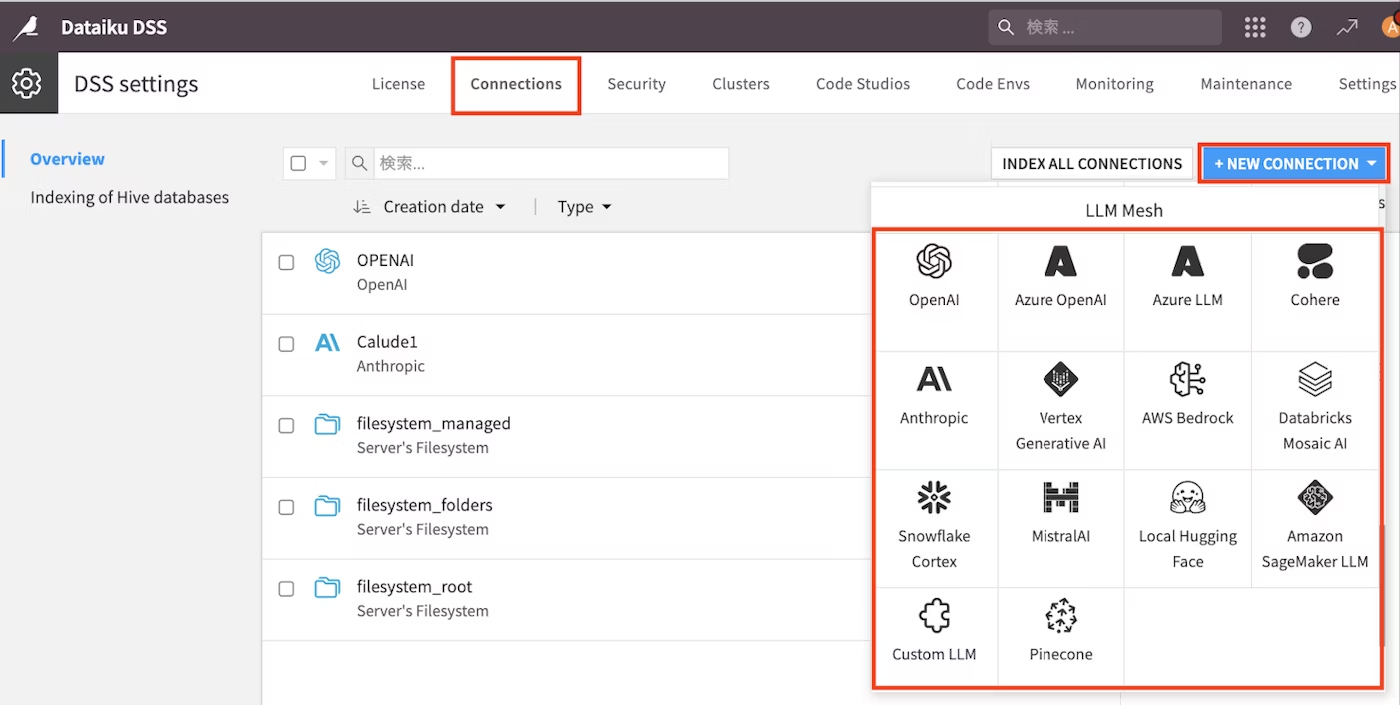
-
入力する情報は、Slackで申請後"「第3回 金融データ活用チャレンジ」コンペティション用 Azure OpenAI APIキー発行完了のご連絡"としてメールで受領します
- 以下を参考にご自身の情報で入力して下さい
- New connection name:任意の名前
- Resource name / URL:エンドポイントURLの末尾にopenai/を加えたURL
例:[https://xxx.net/model/openai/] ※こちら躓きやすいので注意して下さい
- Deployment name:4omini
- Deployment type:chat completion
embeddingモデルについても「+ADD DEPLOYMENT」をクリックして頂き以下を入力して下さい
- Deployment name:embedding
- Deployment type:Embedding
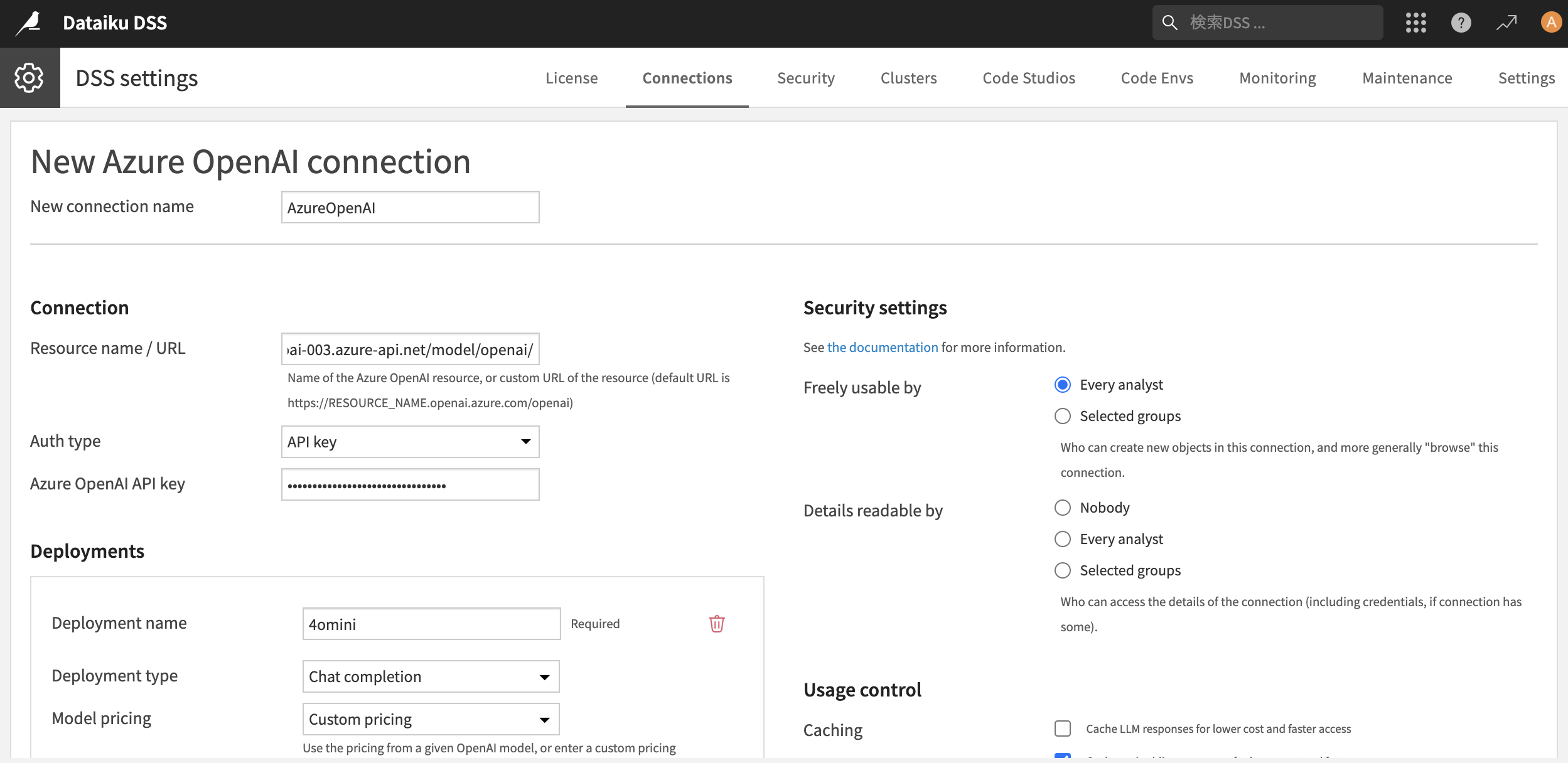
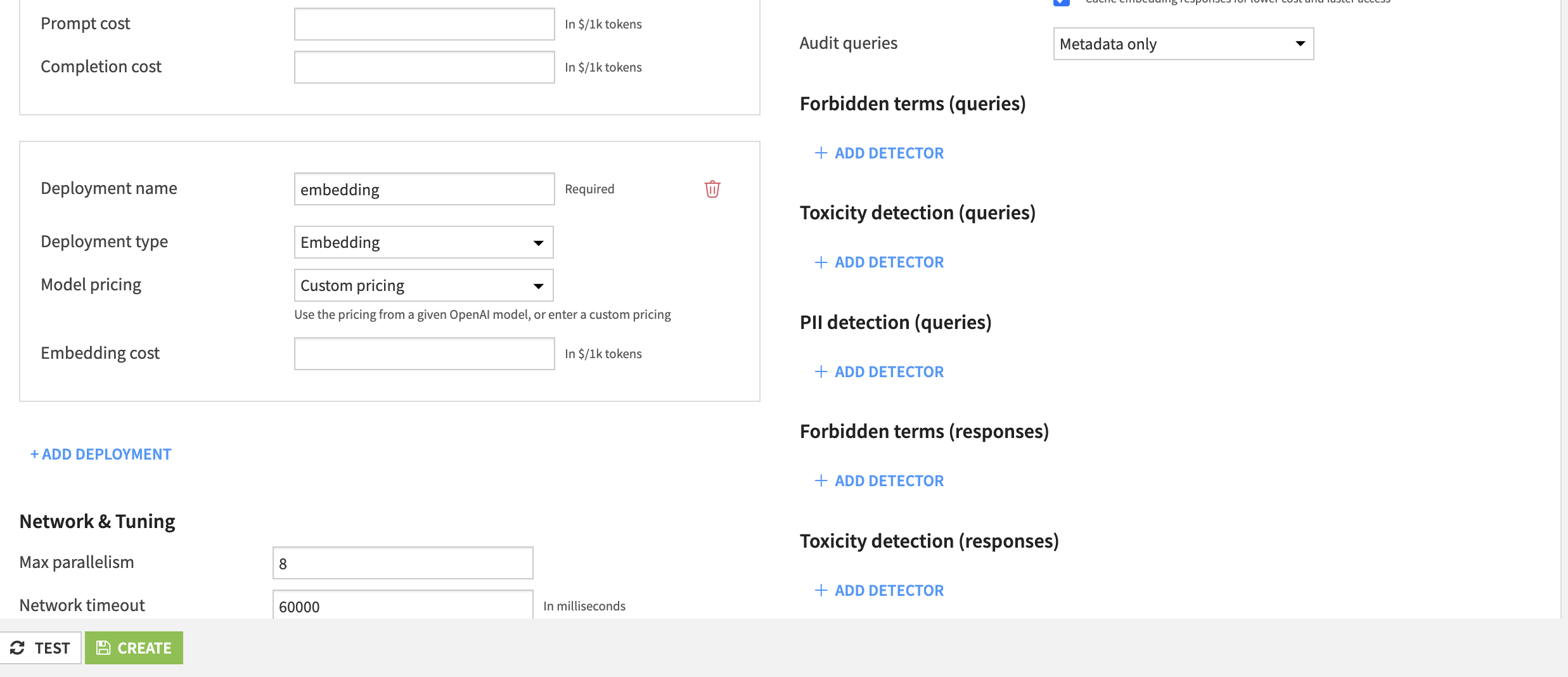
(追記)今回のAPI側の制約や取り扱うデータサイズで以下のパラメータもご調整頂いた方が後続でエラーを回避できそうです
- Max parallelism:4
- Network timeout:300000

こちらでページ下部の「TEST」でOKであれば「CREATE」でAPI接続も完了です!
後はDataiku上で自由に生成AIを含めたあらゆる機能を利用できますので、開発を進めるだけです!
(以下追記):クラウド版の場合
-
Launchpadの「Connections」→「+ ADD A CONNECTION」→「Azure OpenAI」を選択

-
入力内容はほぼインストール版と同じですが、チャット用とEmbedding用の二種類のコネクションを用意して下さい
※入力内容はMicrosoft社へ申請の上、受領した各自の内容を利用下さい。
以下サンプルです。
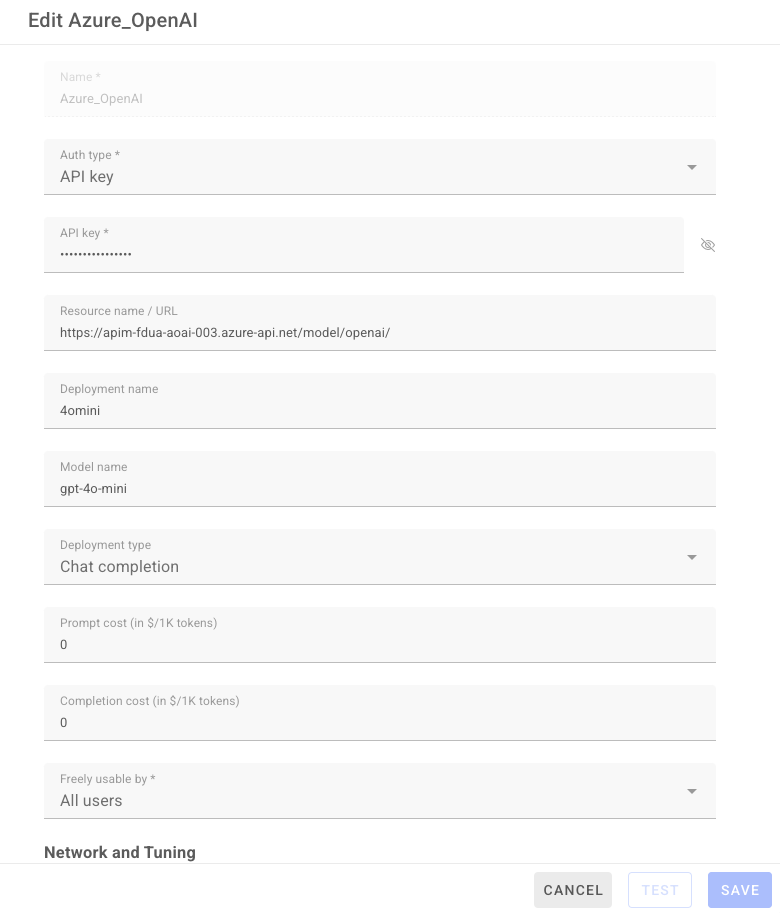

(追記)こちらもEmbeddingのモデルはNetwork and Tuningのパラメータ調整をお勧めします。
- Max parallelism:4
- Network timeout 300000

こちらでクラウド版の設定も完了です!
4.コンペ推進・サブミットまでの流れ(解法に触れない範囲で)
4.1 Dataikuプロジェクトの作成
Dataikuではプロジェクトという単位であらゆる分析を管理します
※クラウド版では、Launchpadから「Overview」→「OPEN INSTANCE」のボタンを押して頂くと同じTOP画面に遷移します。以降は全く同じです。
- ページ中段の「新しいプロジェクト」→「空白のプロジェクト」をクリック(画面左上の鳥のマークを押すとトップ画面に遷移できます)
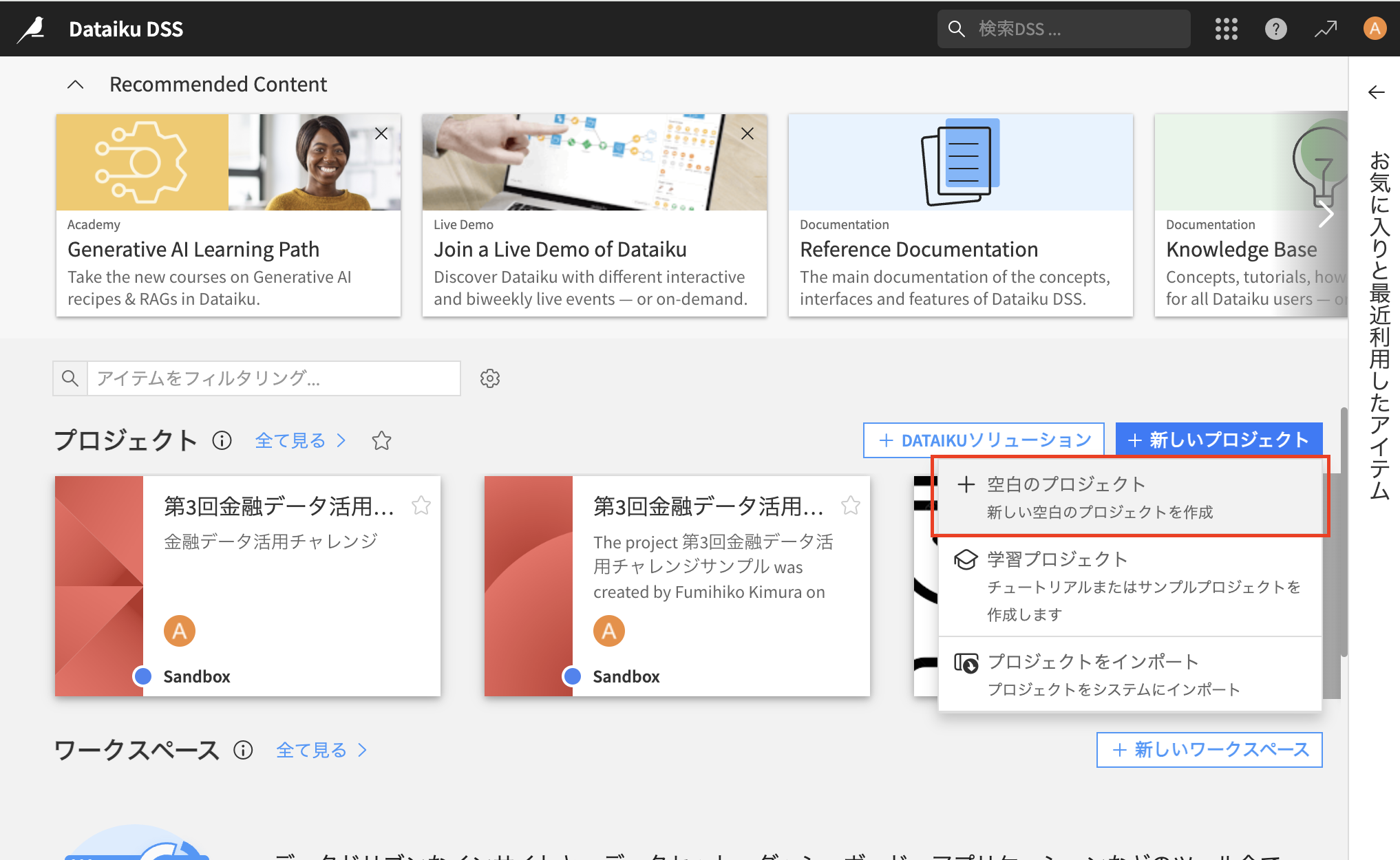
- プロジェクト名を入力し「CREATE」

4.2 利用データの取り込み
- PFDデータ取り込みに向けて、「+IMPORT YOUR FIRST DATASET」をクリックし、「フォルダー」を選択

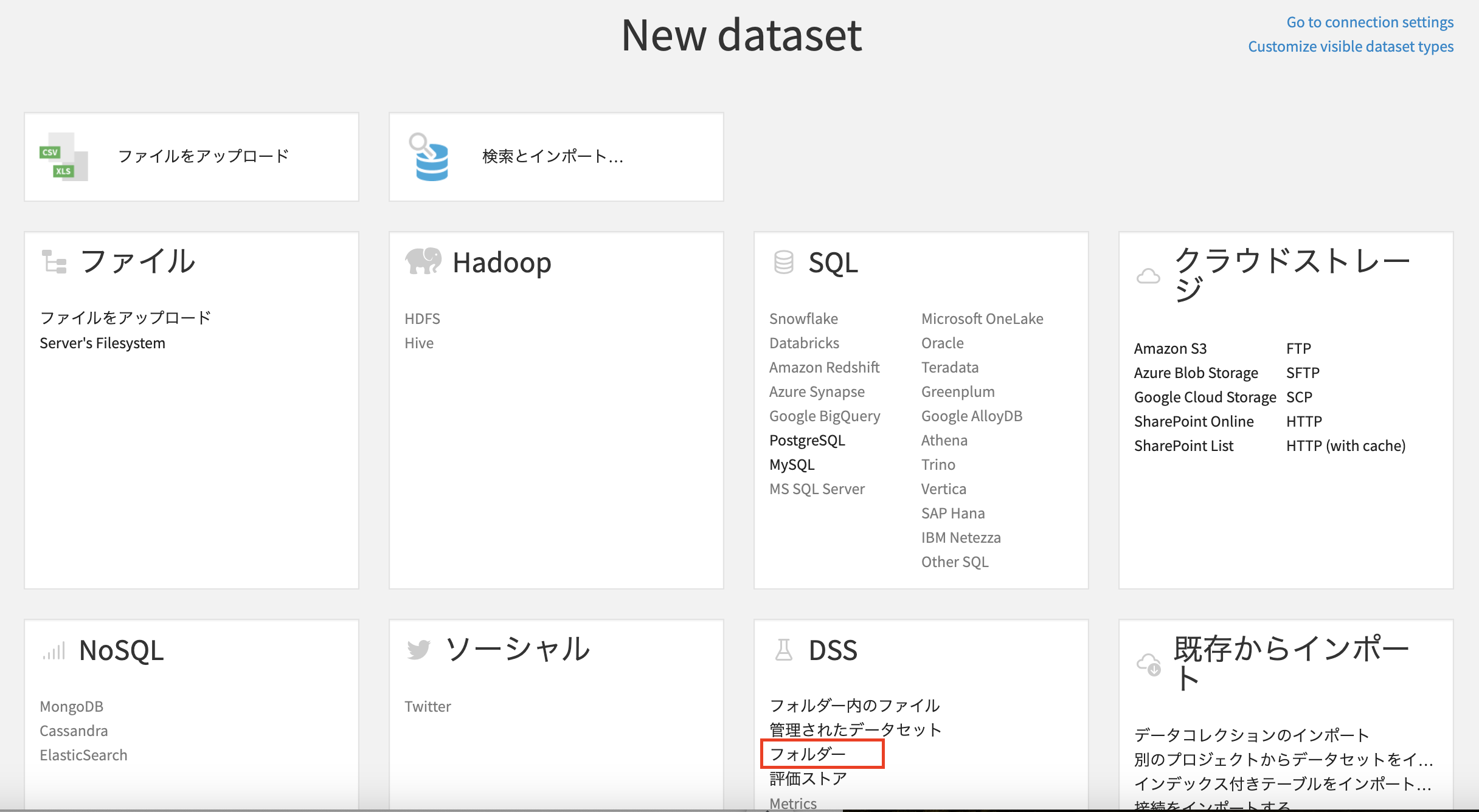
- フォルダ名を入力して「CREATE」をクリック

- 事前にSIGNATEのデータからダウンロードした「documents」内のPFD19種類をドラッグ&ドロップかエクスプローラーから左の枠にインポート

こちらでデータ取り込みが完了です!
4.3 データのテキスト化(OCR)
事前にプラグインインストールした"Text extraction and OCR"レシピを利用してテキストデータ化します
- 「フロー」タブからビジュアルフローの画面に遷移し、documentsフォルダーを選択
右のパネルからプラグインレシピ内の"Text extraction and OCR"をクリック

- 一番上部の「Text extraction」をクリックして、PDFの内容を展開していきます

- Inputs/Outputsのデータを選択します。Inputsは自動で入るため、アウトプットのデータの名前を入力し、「CREATE DATASET」をクリックします
今後もこの構造は同じですので、是非覚えて下さい

- そのまま「CREATE」をクリック

- Text extracitonの設定項目は僅かです。Use PDF bookmarksのチェックボックスも付けて左下の「実行」ボタンをクリック

- 処理が終わればデータセット(青背景)が生成され、内容がtext列に展開されます
- データの中身はデータセットをダブルクリックすると確認できます
- 本画面はよく利用する"ビジュアルフロー"の画面であり、ページ上部のフローマークから遷移できます

こちらのステップでPDFデータの展開が完了です!
4.3 展開したデータを利用したRAG構築
documentsから展開したテキストデータを利用してRAGを構築します
-
右のパネルからLLMレシピの「埋め込み」を選択します

-
先ほどと同様にIn/Outを指定しますが、先ほどembeddingのモデルを登録しているのでそちらが表示されるのと、Vector storeもデフォルトで選択されているのでそのまま「CREATE RECIPE」をクリック

-
Embedding columnに「text」を指定します
その他の項目も必要に応じて設定して下さい。今回はスキップします。

-
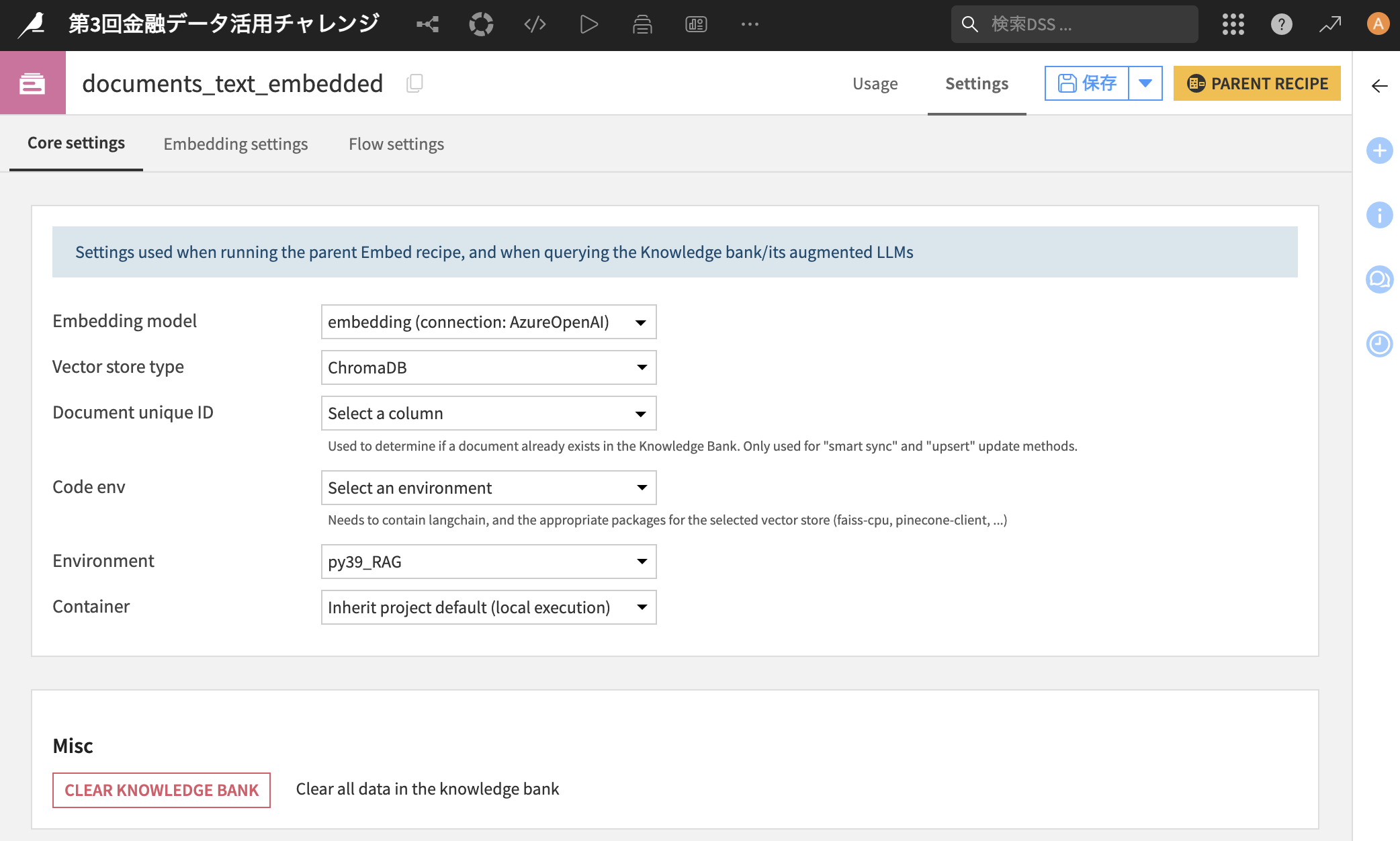
Knowledge bankとしてテキストをベクトル化する時の設定を行いますので、ページ下部の「EDIT SETTINGS」をクリック

-
「Code env」を"Select an environment"に変更し、「Environment」に事前に作成したコード環境を指定して下さい(私の場合はpy39_RAG)
-
右上の「保存」→「PARENT RECIPE」をクリックし、元の画面に遷移した後、左下の「実行」ボタンをクリックして下さい
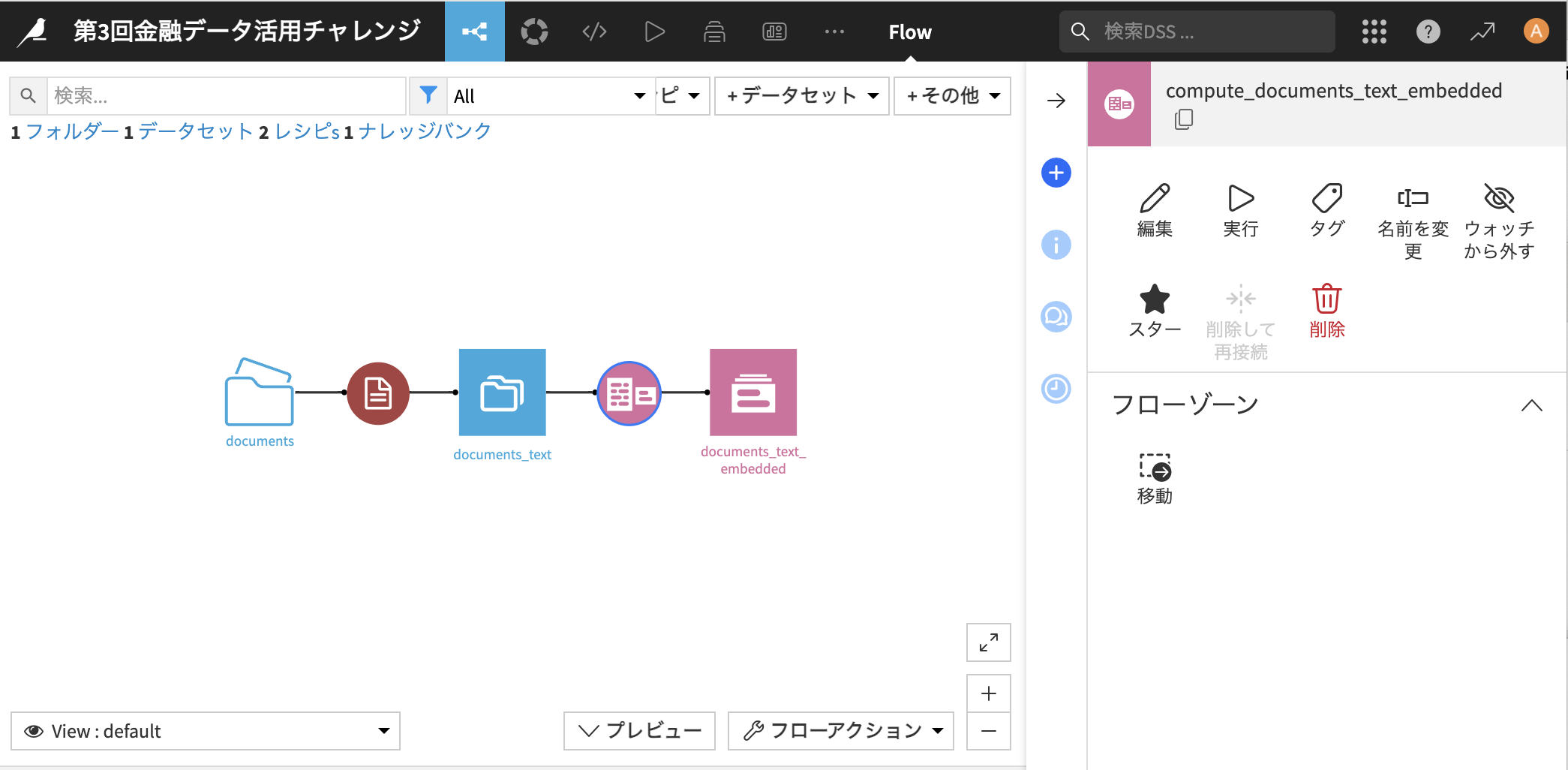
-
フロー画面に戻るとこの様な形で、テキストデータをベクトル化して格納したKnowledge Bankが作られます!
注)実行でエラーが出た場合はAPI設定の制約に引っかかっている可能性があります。
再実行するか、事前に実施したConnections設定内のAzure OpenAIの「Network & Tuning」内でタイムアウト値などを調整して下さい
-
作成したフローから終点のピンク背景のKnowledge Bankをダブルクリックして下さい(私の例だとdocuments_text_embedded)
-
クリックすると以下の画面になりますので、「+ADD AUGMENTED LLM」(+拡張LLMを追加)を押して下さい
※私のキャプチャはGoogleのブラウザ翻訳で日本語にしています
※日本語対応しているのですが、一部英語の内容も残存しているので、必要に応じてブラウザ翻訳も活用下さい
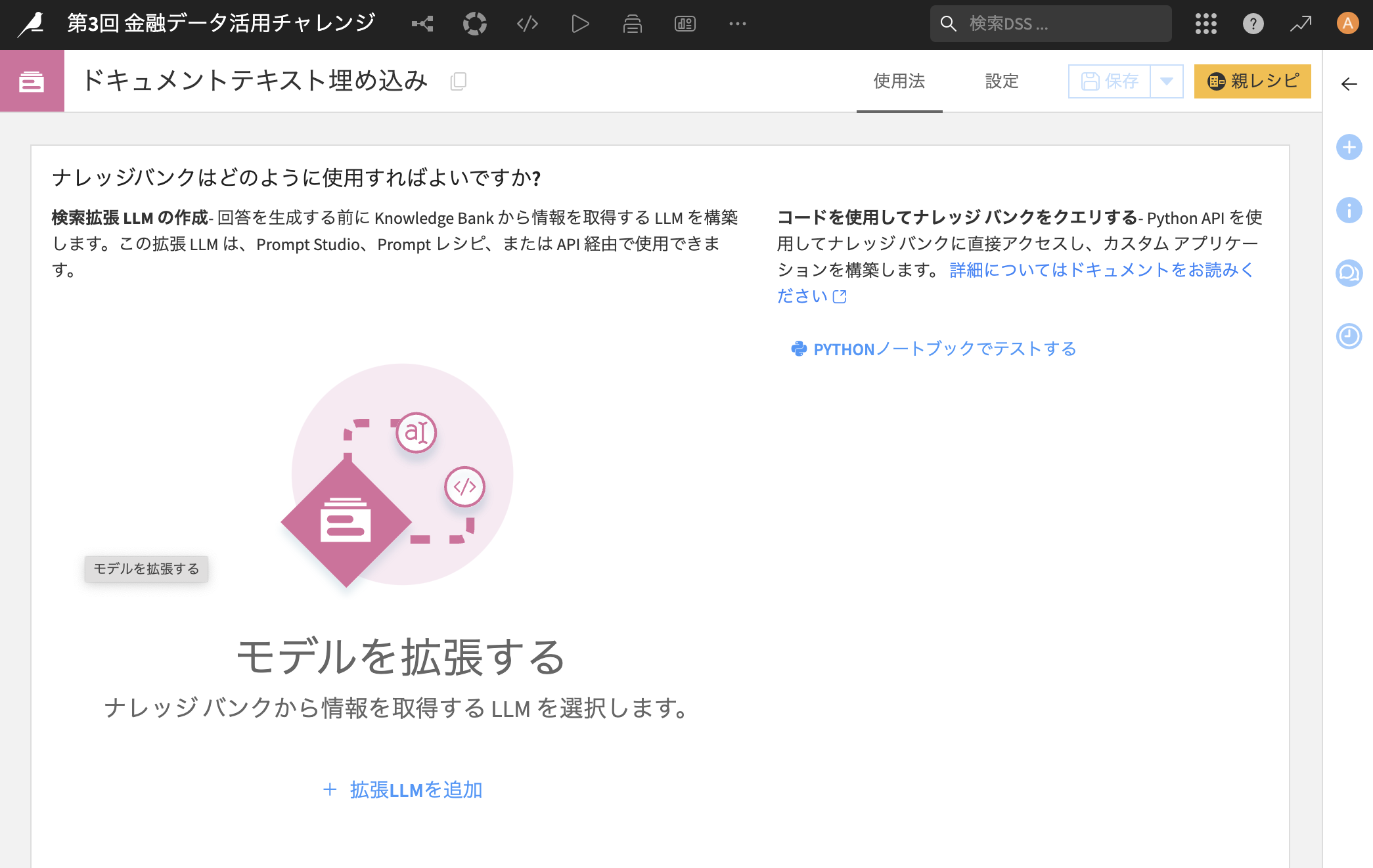
-
「LLM」の項目に事前にチャットとして接続設定している「4omini」を選択して下さい
-
右上の「保存」ボタンを押して完了です

これでRAGの構築や問い合わせ時に利用するGPTの指定等も完了しました!
4.4 質問を利用した回答作成(プロンプトエンジニアリング)
作成したRAGを利用して、プロンプトで回答を取得してみましょう
-
今回のお題である質問が記載されている「query.csv」をアップロードします。「+データセット」→「ファイルをアップロード」をクリック
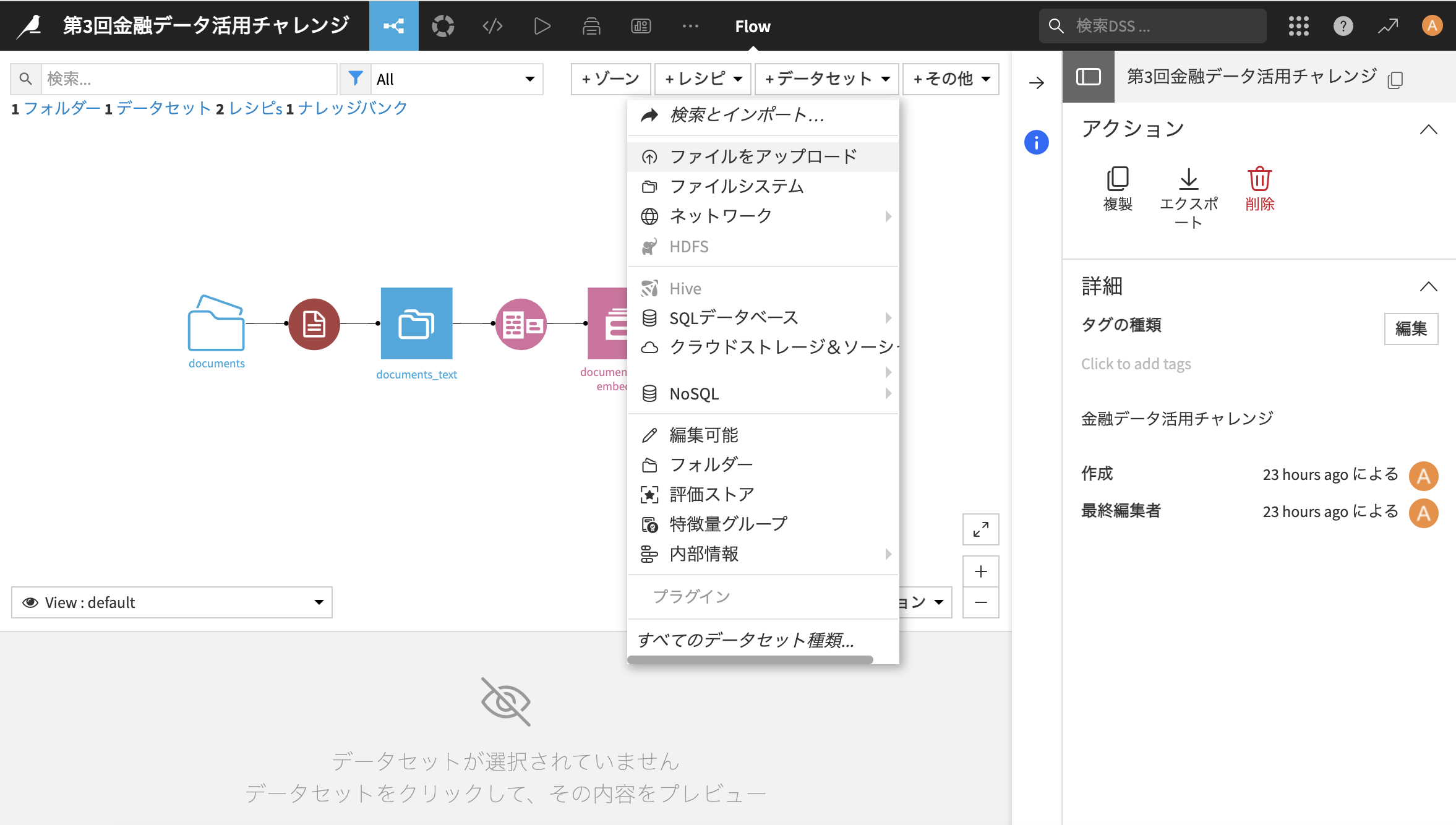
-
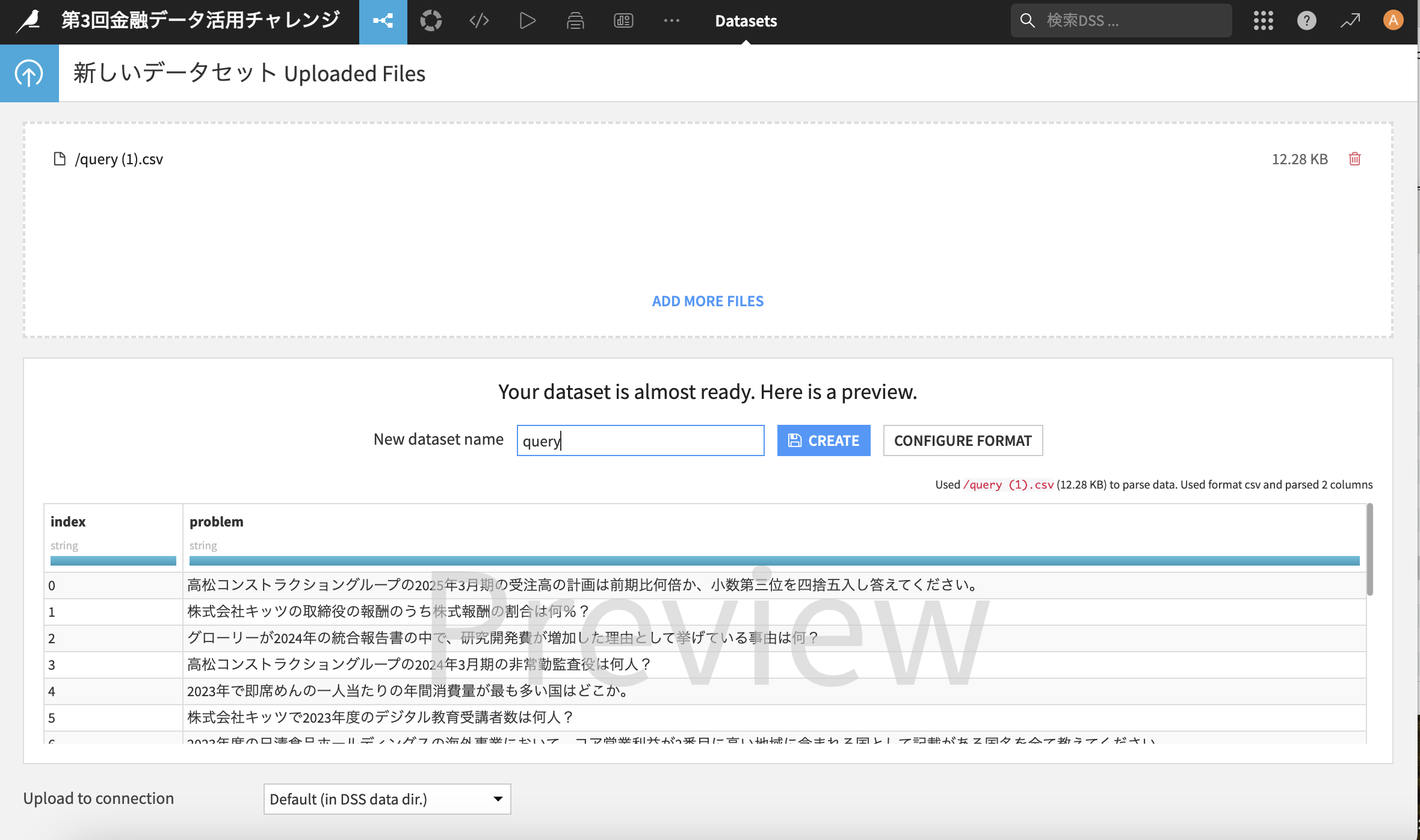
「Drag and drop files here or」のエリアにquery.csvをドラッグ&ドロップします
-
問題なく取り込みが完了したら「CREATE」をクリック
-
プロンプト作成のために右側のパネル内のLLMレシピから「プロンプト」レシピをクリック
-
既にご説明済みのため割愛しますが、遷移後の画面で「レシピを作成」をクリック

-
この画面からプロンプトを書くことも可能ですが、より使いやすい"プロンプトスタジオ"を利用するため、「EDIT IN PROMPT STUDIO」をクリック

-
"Create a new Prompt studio"をクリックし、名前を埋めて「CREATE」をクリック

-
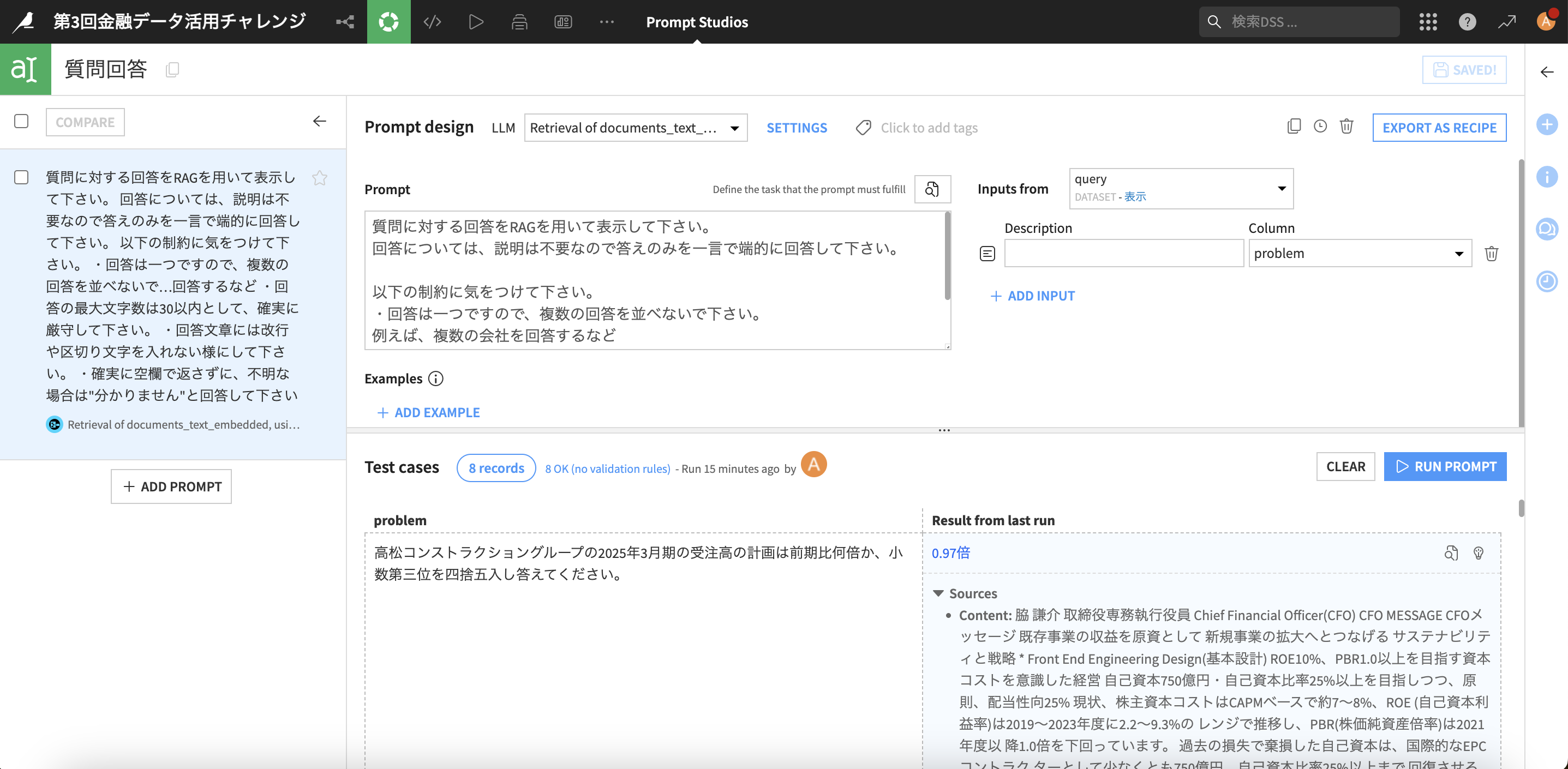
各種項目を設定し、質問に対する回答用のプロンプトを作成
- LLM:先ほど作成したRAG(この例だとRetrieval of documents_text_embedded...")
- 「+ADD INPUT」→Column:problem
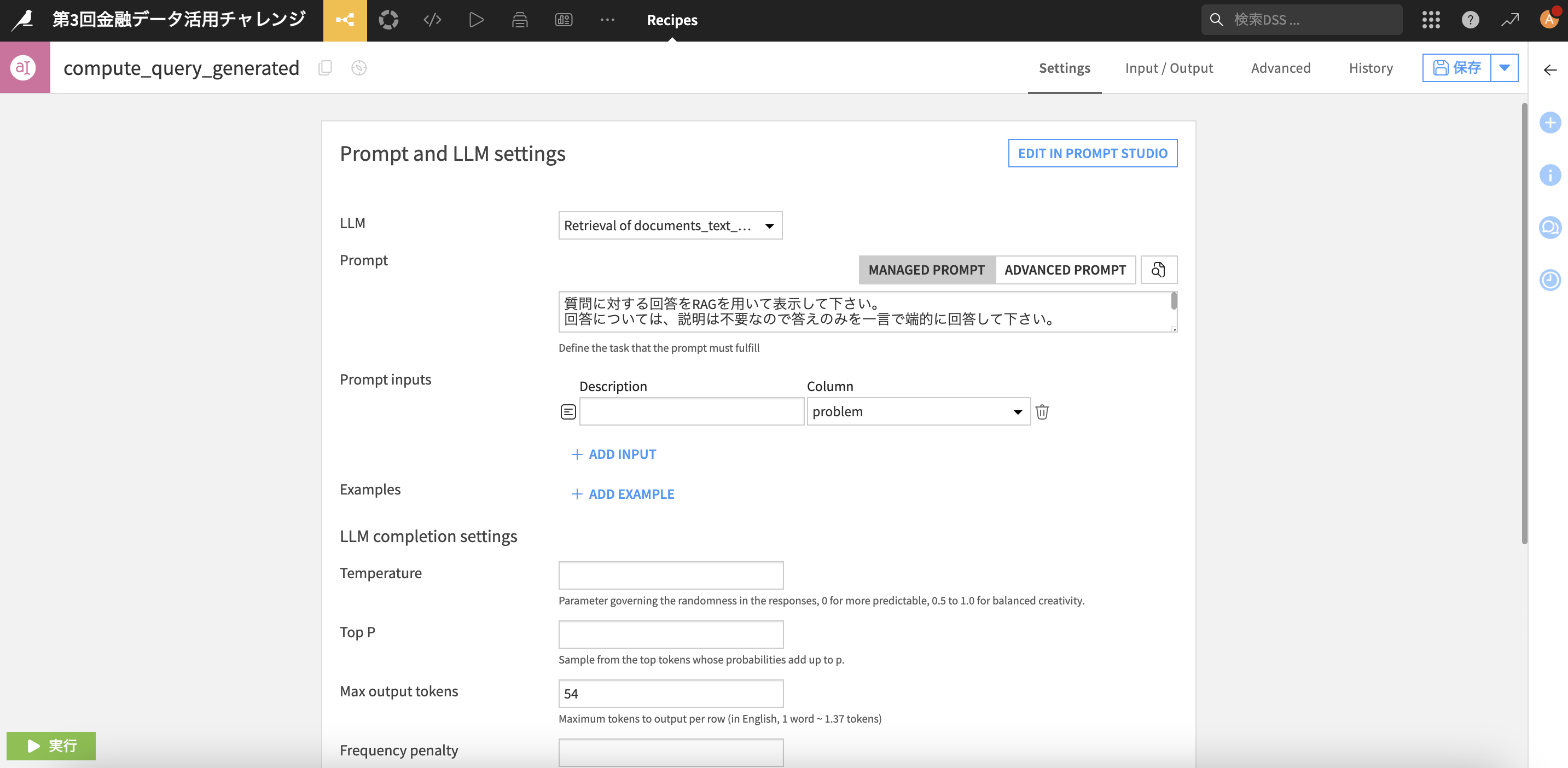
- Prompt:任意のプロンプトを記載して下さい -
プロンプトの改善に非常に便利で、「RUN PROMPT」を押すことでこの例だと8 recordsで回答を生成してくれます
※解法に触れ過ぎない様に割愛しますが、「+ADD EXAMPLE」から回答例の記載もできるので所謂精度改善に必要なfew shotでのサンプル追加も可能です。
※また、実際のサブミット時に回答の文字数が多かったり空欄があるとエラーとなりますので、その場合はプロンプトで制約を記載して下さい。
-
内容をFIXしたら「EXPORT AS RECIPE」をクリックし、"Select a recipe"でレシピを指定して、「OVERRITE」をクリック

-
レシピに内容が反映されるので、左下の「実行」ボタンをクリック

(後日追記)今回回答の長さが54トークンを超えるとサブミット時にエラーになる仕様なので、「Max output tokens」に54を指定しておくと長さも制約を掛けれます
-
質問一つずつに対して、先ほどのプロンプトが適用され、llm_output列で結果が確認できました!
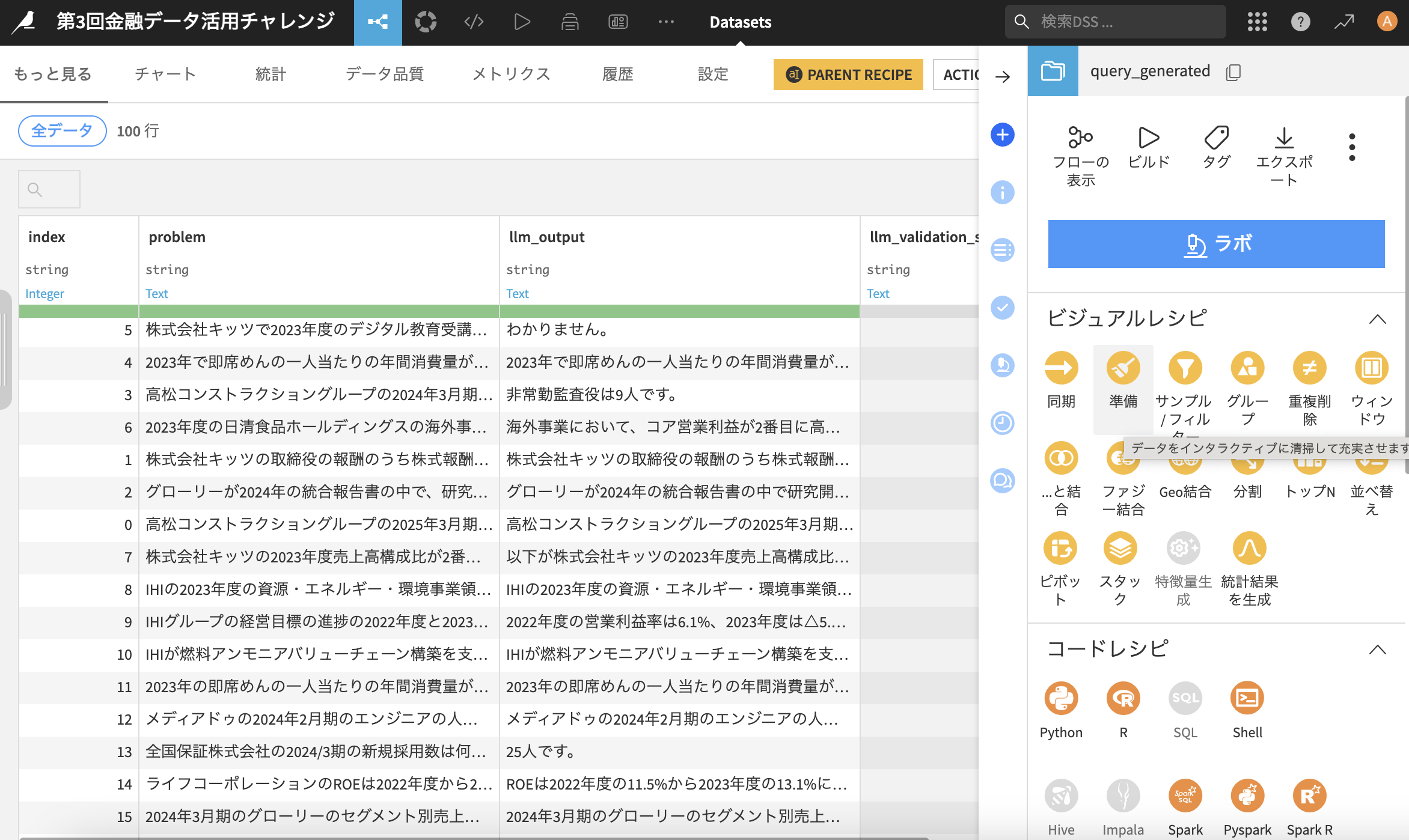
今回は手順案内のみに留めておりますが、Dataikuではこちらのシンプルな手順で、加工したデータをフローで可視化しながら分析を進めていけます。
ご紹介内容はDataikuの多くの機能のほんの一部ですので、是非ここから取り込みや前処理、RAG、プロンプトなど各所で色々と精度改善に取り組んで下さい!
4.5 投稿(submit)に向けた準備
最後に投稿までの流れをご案内します
- 先ほどのキャプチャの回答データの右側のパネル内、ビジュアルレシピから黄色アイコンの「準備」レシピをクリック
- ポップアップから「レシピを作成」をクリック
今回の配布データの中から「sample_submit」のpredictions.csvの中身を確認すると、列ヘッダーなしでIndexと回答の2列が必要そうなのでそのデータフォーマットに直します
※こういう時にDataikuのノーコードのレシピが便利です!
- problem列名をクリックし、出てきたリストの一番上の「削除」をクリック

- 左にステップが表示されるので「複数」→不要な列を指定していけば必要なデータだけ残せます
もしくは、右の列から最初の操作と同じようにクリックしていっても構いませんし、列の保持も選べます

- この様な形にして実行します!

実行後はこの様なフローになりました!
-
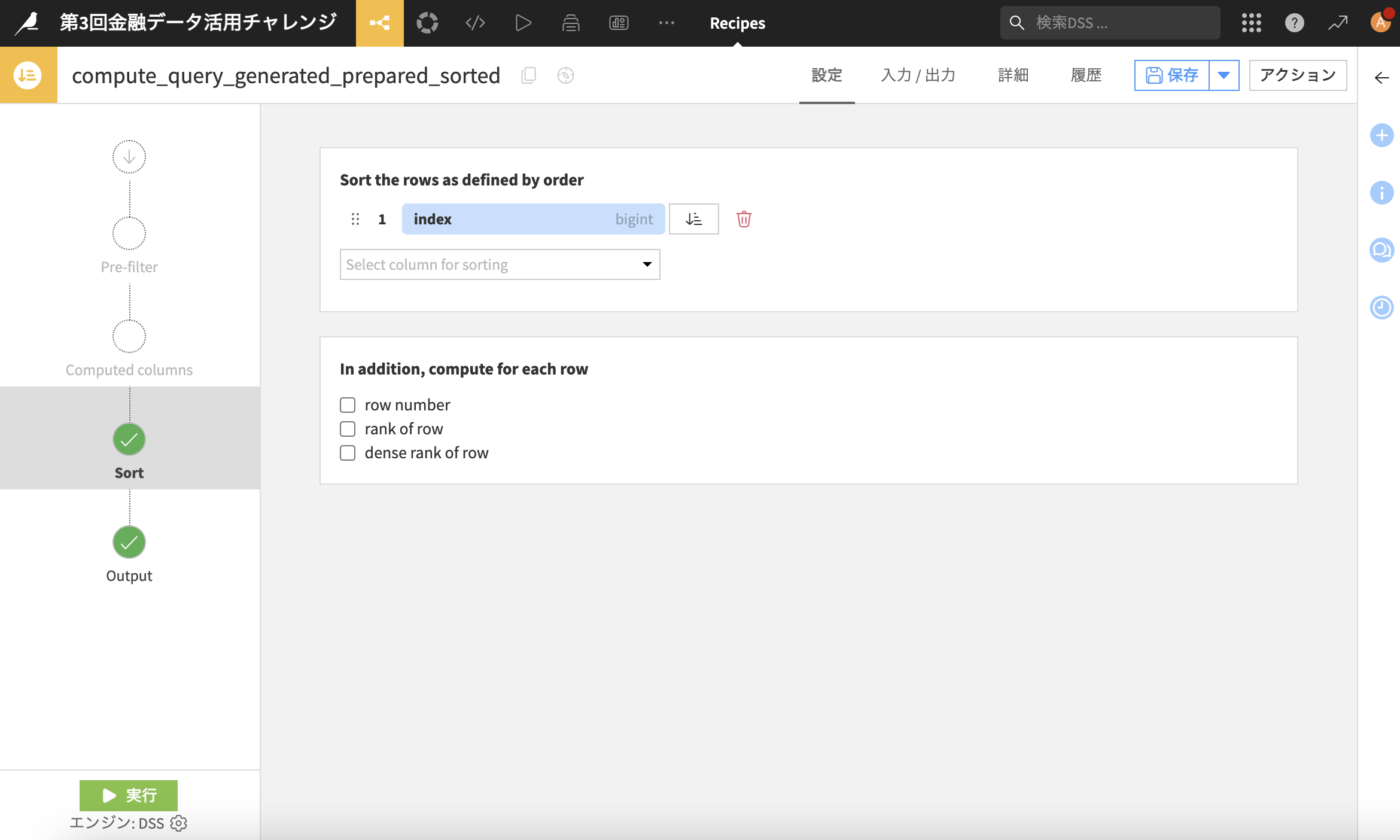
最後、私のデータはindexが降順じゃなくなっていたので、右側のパネルから「並べ替え」のレシピをクリック
-
レシピの作成をクリック

-
"Select column for sorting"に「index」を指定して左下の「実行」をクリック
-
結果のデータセットの右側のパネルから「エクスポート」をクリック

-
"with header"のチェックを外して「DOWNLOAD」をクリック

これで提出用のcsvファイルが手元にダウンロードできました!
注1)csvファイル名が「predictions.csv」である必要がありますので、ファイル名は書き換えて下さい
注2)今回の提出形式はzipですので、お手元でcsvをzipに圧縮して下さい -
後はSIGNATEの「投稿」ボタンから、ダウンロードしたファイルをアップロードして投稿したら完了です
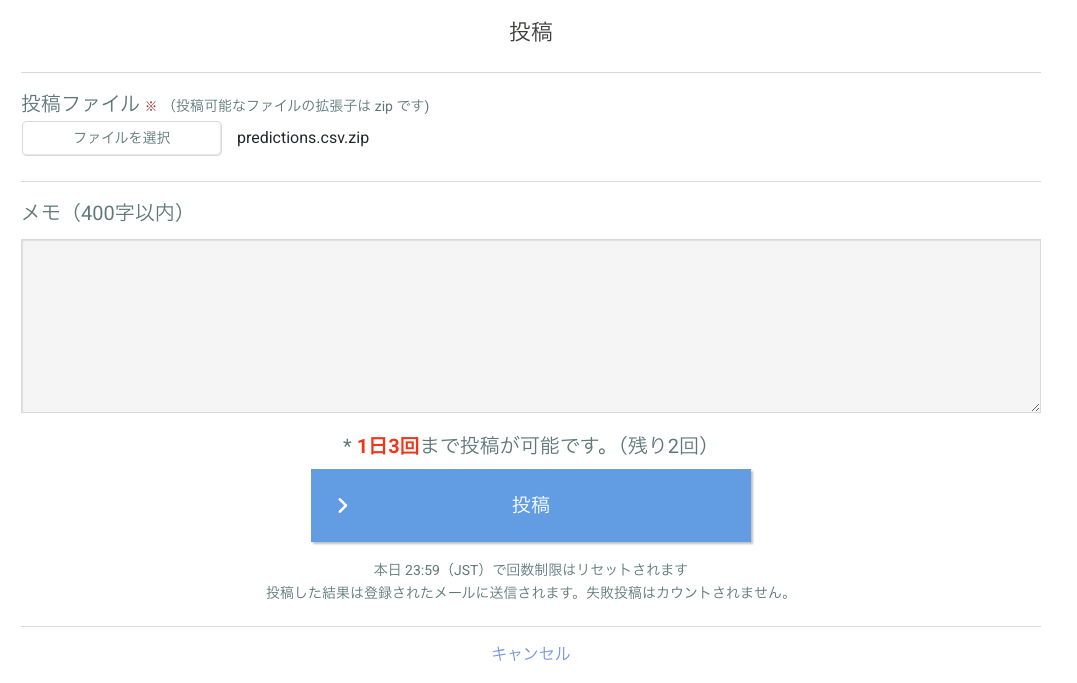
後はリーダーズボードから評価を確認して下さい!
- 恐らく空欄があったり、回答が長すぎるとエラーで登録できない場合があります。
その場合はプロンプトを見直して、制約を記載する(例えば何文字以内で回答して下さい、とか空白では返さず不明な場合は"分かりません"と回答して下さいなど)
今回はステップ毎に見える化しながら全てノーコードのGUIで完結しました。Dataikuの便利さが伝われば幸いです!
参考情報
- Twitterで日々データ分析やDataikuに関わる内容を発信してます。是非参考としてフォローして頂けると嬉しいです
https://x.com/Fumihiko__K - ハンズオン開催
1月24日(金)18:00-にハンズオンを開催しますので、是非ご参加ください!
※詳細はSlackチャネルをご確認下さい
https://us02web.zoom.us/j/83481405518?pwd=c1JgBBw1f3p7FqiD19nF6HaJykuQxe.1
ミーティング ID: 834 8140 5518
パスコード: 595476 - 環境について
今回はインストール版を利用しておりますが、皆様のPCやOSによって環境は変わります(私はMacOSです)
環境設定やパフォーマンスに手こずる場合は弊社のクラウド版もお試し下さい。14日限定ですが、お問い合わせベースでコンペ終了までお使い頂ける様に尽力します。
おわりに
- Dataikuは「データ接続〜前処理〜RAG構築・プロンプトエンジニアリング〜後処理」までの全てのプロセスを完結できる素晴らしいプラットフォームです
- 各手順のステップがビジュアルフローで見える化され、後からイタレーションが容易ですし、今後に向けては勿論コードレシピでコードを書いていただくことも可能です
- 生成AIもご案内の通りDataiku上で活用できますし、改善要素がどんどん出てくると思うので是非ご活用下さい!
ぜひ皆様と一緒に盛り上げていきたいと思いますので、Slackチャネルにも遠慮なく投稿して下さいね!最後までご拝読を有難うございました。