金融データ活用推進協会(FUDA)と金融庁共催の第3回金融データ活用チャレンジ
最初に
今回、生成AIのAPIを無料で提供いただいた日本マイクロソフトさん、日立製作所さん、本当にありがとうございます。今回、両者のAPIを使用させていただきました。ただ、私のRAGをそもそも理解できていなかったのか、コンテキストサイズが大きすぎたのかは、わかりませんでしたが、llama3.3:70b-instruct-fp16とQwen 2.5:72bは思った様な回答が返ってこず、早々に諦めてしまいました。本来であれば、いろいろと考察ができれば良かったのですが、次回にこの様な機会があれば、もっと前処理をしっかりとして、いろいろな評価ができればなと思っています。
貴重な機会をいただき、大変ありがとうございます。
コンペ概略
-
企業の統合報告書・サステナビリティレポートのPDFファイルが存在し、その情報をコンテキストとして、質問の回答を得るものとなっています。日本マイクロソフトさんよりAzure Open AIで提供されたGPT 4o-mini version 2024-10-24なので、これを調べてみると「ナレッジカットオフは2023年10月に設定されている」となっています。一方、今回の出題元となっている統合報告書・サステナビリティレポートは、2024年度の後のもとなっている様子です
-
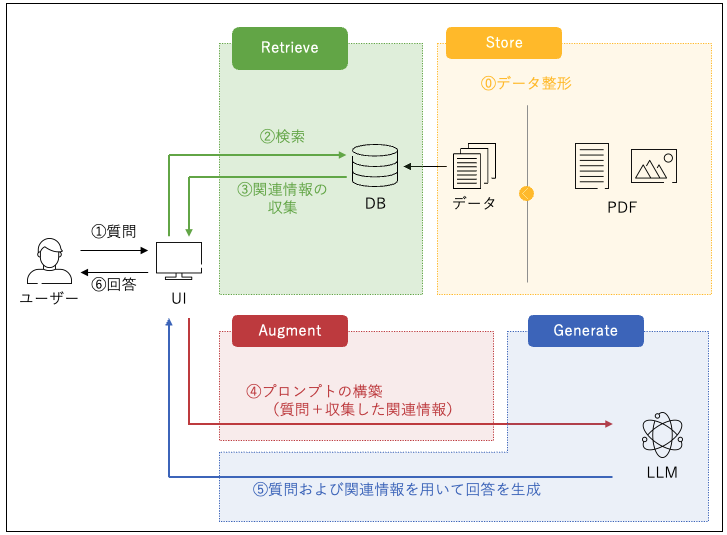
1.の情報に対して、Retrieval Augmented Generation(RAG)システムを構築し、用意された質問(query.csv)に対する回答を生成し、その回答を作成する。
https://signate.jp/competitions/1515#abstractより引用 -
回答の精度は、Comprehensive RAG Benchmark (CRAG)という次で示されるスコアの平均値を競うというものとなっています
分類 得点 評価基準 Perfect 1 質問に対して正確に答え、虚偽の内容が含まれていない回答。 Acceptable 0.5 質問に対して有用な答えを提供しているが、答えの有用性を損なわない程度の軽微な誤りが含まれている回答。 Missing 0 質問に対して「わかりません」「見つけられませんでした」などの具体的な答えがない回答。 Incorrect -1 質問に対して間違った、または関連性のない回答。
https://signate.jp/competitions/1515#evaluationより引用
ということは、正解があっても間違えが多いとスコアは、大きく減点されるということですね。
試しに、ChatGPT 4oを使って、お題のquery.csvの質問をしてみると、Webを検索して、次の様な結果となっています。

こうやってみると、結構近いしいところWebから取得できそうですが、やはり適切なコンテキストを与えないと、質問の解釈に誤りが生じたり、ハルシネーションを引き起こすのは想像に難しくなく、今回のコンペの目的がここにあることは容易に理解できました。
1. 前処理
お題として提供されたデータは、PDFとなっていました。一部のPDFは、暗号化がされており、オープンソースのPDF解析ライブラリが機能しないなどの問題がありました。このため、まず最初にCairoを使用して、pdftocairoでPDFのバージョンを1.5にするということを行いました。マルチモーダルに対応した多くの生成AI APIは、ダイレクトにPDFを読み込ませることができなかったことから、各ページをPNGの画像として、用意しました。
for pdffile in *.pdf
do
pdftopng $pdffile
done
また、Azure Document Intelligenceを使用して、PDFの内容をmarkdownにしてみました。
RAGシステム構築への挑戦:PDFドキュメントを活用したQ&Aシステムの開発記録
はじめに
近年、生成AIを活用した情報検索や質問応答システムが注目を集めています。その中でも、外部知識を組み込むRAG(Retrieval-Augmented Generation)技術は、特定領域の文書に基づいた高精度な回答を提供できるため、非常に有用です。
今回、私たちは企業の統合報告書や有価証券報告書をコンテキストとして、指定された100問の質問に回答するRAGシステムの開発に挑戦しました。本記事では、PDFドキュメントの前処理から質問応答システムの設計、そして発生した課題とその解決策までを詳しく記録します。
1. PDFドキュメントの前処理
今回のRAGシステムでは、19種類のPDFドキュメントをコンテキストとして利用しました。しかし、PDF形式には様々な課題が伴います。特に、次のような問題に直面しました。
- PDFの暗号化:一部のPDFが暗号化されており、オープンソースのPDF解析ライブラリが機能しない。
- PDFバージョンの違い:生成AI APIが一部のPDFフォーマットをサポートしていない。
- マルチモーダルAPIの制限:PDFを直接読み込めないAPIが多い。
これらの課題を解決するため、次のアプローチを取りました。
1.1 PDFバージョンの変更
暗号化の問題に対処するため、pdftocairoコマンドを用いてPDFのバージョンを1.5に統一しました。これにより、PDF解析ライブラリの互換性が向上しました。
for pdf in *.pdf
do
pdftocairo -png $pdf
done
このスクリプトにより、各PDFをページごとのPNG画像に変換し、マルチモーダルAPIでも処理可能な形式にしました。
2. テキストデータの抽出
画像化されたPDFページからテキストを抽出するため、Azure Document Intelligenceを活用しました。このサービスはOCR機能を備えており、構造化されたMarkdown形式でテキストを出力できるため、後の検索・回答処理が容易になりました。
2.1 OCR処理フロー
- PDFをそのままBlobでアップロード。
- Azure Document IntelligenceでOCR処理を実施。この際、以下のPythonスクリプトを使用しました。
#!/usr/bin/env python3 # import libraries import os from azure.core.credentials import AzureKeyCredential from azure.ai.documentintelligence import DocumentIntelligenceClient from azure.ai.documentintelligence.models import AnalyzeResult from azure.ai.documentintelligence.models import AnalyzeDocumentRequest # set `<your-endpoint>` and `<your-key>` variables with the values from the Azure portal endpoint = "<my-endpoint>" key = "<my-key>" # PDFをBase64形式に変換する関数 def convert_pdf_to_base64(pdf_file_path): with open(pdf_file_path, "rb") as pdf_file: return base64.b64encode(pdf_file.read()).decode('utf-8') # レイアウト解析を実行する関数 def analyze_layout(pdf_path): base64_pdf = convert_pdf_to_base64(pdf_path) client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key)) poller = client.begin_analyze_document( "prebuilt-layout", AnalyzeDocumentRequest(bytes_source=base64_pdf), output_content_format="markdown" ) result = poller.result() with open(f'{pdf_path.replace(".pdf", ".md")}', 'w') as f: f.write(result.content) # 実行 if __name__ == "__main__": pdf_files = [f'./documents/{i}_out.pdf' for i in range(1, 20)] for file in pdf_files: analyze_layout(file) - 出力結果をMarkdown形式で保存
このステップで、表やセクション構造などの文書情報が失われることなく取得できましたが、Figの情報が微妙だったり、一部複雑な表が崩れていました。表については、チャンキングを行う際に、一旦pandasのpd.read_html()を使用して、Markdownで出力しなおすという処理を噛ませました。
また、図の一部は、必要なテキスト情報が抽出されていますが、順序性などが読み取れないものであったことから、一部の画像ページは、Claude 3.5 Sonnet(無料の5USD分)を使って、置き換える試みをしました。おそらく、図については、もっと適切な処理が必要だった様に思いました。
3. キーワード抽出と埋め込み生成
質問に適した文書部分を特定するため、BERT埋め込みを活用しました。当初、KeyBERTを使用してキーワードを抽出しようとしましたが、出力の品質が期待に満たなかったため、断念しました。その後、以下のチャンキング処理を実装しました。
#!/usr/bin/env python3.12
import os
import re
import io
import glob
import tiktoken
import numpy as np
import pandas as pd
from sentence_transformers import SentenceTransformer
document_dir = './markdown'
encoding = tiktoken.get_encoding("o200k_base")
bert_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
def strip_tags(md_content):
md_content = re.sub(r'<!--[\s\S]*?-->', '', md_content)
md_content = re.sub(r'\n{3,}', '\n\n', md_content)
md_content = re.sub(r'#\s+', '# ', md_content)
md_content = re.sub(r'^[●・]\s*', '- ', md_content, flags=re.MULTILINE)
return md_content
def split_markdown_with_headers(markdown_text, max_tokens=512):
chunks = []
current_chunk = []
current_headers = []
lines = markdown_text.split("\n")
for line in lines:
match = re.match(r'^(#{1,4})\s+(.*)', line)
if match:
level = len(match.group(1))
title = match.group(2)
if level == 1:
current_headers = [title]
else:
current_headers = current_headers[:level - 1] + [title]
if current_chunk:
chunks.append((" / ".join(current_headers), "\n".join(current_chunk)))
current_chunk = []
else:
current_chunk.append(line)
if current_chunk:
chunks.append((" / ".join(current_headers), "\n".join(current_chunk)))
processed_chunks = []
for title, content in chunks:
words = content.split()
if len(words) > max_tokens:
for i in range(0, len(words), max_tokens):
processed_chunks.append((title, " ".join(words[i:i+max_tokens])))
else:
processed_chunks.append((title, content))
return processed_chunks
md_paths = glob.glob('markdown/*.md')
chuncks_array = []
for path in md_paths:
doc_id = int(re.sub(r'markdown/(\d{1,2})\.md', r'\1', path))
with open(path, 'r') as f:
md_doc = f.read()
chunks = split_markdown_with_headers(strip_tags(md_doc))
for chunk_id, (title, chunk) in enumerate(chunks, 1):
chuncks_array.append({
'doc': doc_id,
'chunk_id': chunk_id,
'title': title,
'text': chunk,
'text_size': len(chunk),
'estimate_tokens': len(encoding.encode(chunk))
})
pd.DataFrame(chuncks_array).to_feather('chunked_text.ftr')
4. ベクター情報の作成
埋め込み生成には、日本マイクロソフトから提供されたtext-embedding-3-largeを使用しました。次のPythonスクリプトで実装しました。
#!/usr/bin/env python3.12
import os
import re
import io
import sys
import glob
import pandas as pd
import numpy as np
from openai import AzureOpenAI
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
API_VERSION = os.getenv("API_VERSION")
DEPLOYMENT_ID_FOR_CHAT_COMPLETION = "4omini"
DEPLOYMENT_ID_FOR_EMBEDDING = "embedding"
DOCUMENT_DIR = './markdown'
TARGET_PATH = './chunked_text.ftr'
df_text = pd.read_feather(TARGET_PATH)
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version=API_VERSION
)
embeddings = []
for row in df_text.iterrows():
doc = row[1]['doc']
page = row[1]['page']
text = row[1]['text']
try:
response = client.embeddings.create(
input=text,
model=DEPLOYMENT_ID_FOR_EMBEDDING
)
embedding_vector = response.data[0].embedding
# embeddings リストに追加
embeddings.append(embedding_vector)
except Exception as e:
print(doc, page)
print(f'エラー: {e}', file=sys.stderr)
df_text['vector'] = embeddings
df_text.to_feather('chunked_emb.ftr')
DOCUMENT_DIR = './markdown'
QUERY_PATH = './query.csv'
VECTOR_PATH = 'text_vectors_20250129.ftr'
df_query = pd.read_csv(QUERY_PATH)
output = []
for row in df_query.iterrows():
index, question = row[1]['index'], row[1]['problem']
# Embedding API を使って質問をベクトル化
response = client.embeddings.create(
input=question,
model=DEPLOYMENT_ID_FOR_EMBEDDING
)
question_vector = response.data[0].embedding
output.append([
index,
question,
question_vector
])
df_out = pd.DataFrame(output, columns=['index', 'problem', 'vector'])
df_out.to_feather('query.ftr')
最終的に、質問応答タスクにはBERTベースの言語モデルを採用し、埋め込み空間で最も関連性の高い文書をコンテキストとして提示しました。
さらに、Cosine類似度を計算する前に、次のような質問文から固有名詞を抜き出すプロンプトを用意しました。(トークン数もそれほど多くなく、Gの前段として問題がないと判断しました)
with open(QUERY_PATH, 'r') as f:
query = f.read()
query = query.replace('index,problem','')
sys_content = (
'文章から企業や商品名等の固有名詞を抽出を行います。
'
'回答は先頭の番号ごとに記載し、固有名詞がなければ空欄にします。
'
'書式は項番,固有名詞とします。'
)
usr_content = (
'次の文章から固有名詞を抽出してください。
'
f'{query}'
)
try:
response = client.chat.completions.create(
model=DEPLOYMENT_ID_FOR_CHAT_COMPLETION,
messages=[
{"role": "system", "content": sys_content},
{"role": "user", "content": usr_content}
]
)
print(response)
answer = response.choices[0].message.content.strip()
except Exception as e:
print(e, file=sys.stderr)
with open('output_tmp.csv', 'w') as f:
f.write(answer)
本来、DBを構築すべきですが、諸般の事情で、事前に準備したFeatherフォーマットのファイルを使って、質問とコンテキストを用意することにし、質問とチャンク化されたテキスト情報の類似度は、次の様にしました。
チャンク化されたテキストは、おおよそ一つが500文字程度であったことから、ここでは、一つの質問に対して、類似度が高い9個の内容を単純に結合し、それをプロンプトにくべる内容としました。これにより、一つの質問に対する入力トークンがテキスト情報については、4000〜6000程度になっていたと思います。表や図は大きくなるため、小さくならないものもあった。
#!/usr/bin/env python3
import os
import re
import sys
import glob
import pandas as pd
import numpy as np
DOCUMENT_DIR = './markdown'
QUERY_PATH = './query.ftr'
VECTOR_PATH = './chunked_emb.ftr'
SIM_DOC_INFO = 'output_tmp.csv'
def cosine_similarity(vec_a, vec_b):
'''
'''
a = np.array(vec_a)
b = np.array(vec_b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
df_sim_doc = pd.read_csv(SIM_DOC_INFO)
df_query = pd.read_feather(QUERY_PATH)
vector_rec = pd.read_feather(VECTOR_PATH)
output = []
docids = vector_rec['doc'].to_list()
page_number_list = vector_rec['page'].to_list()
texts = vector_rec['text'].to_list()
embeddings = vector_rec['vector'].to_list()
doc_pages = vector_rec.groupby('doc')['page'].max()
output = []
for row in df_query.iterrows():
index, question, q_vector = row[1]['index'], row[1]['problem'], row[1]['vector']
target_doc = df_sim_doc[df_sim_doc['index'] == index]['doc'].to_list()
print(f"{index:02d}(doc = {target_doc[0] if len(target_doc) > 0 else None})問い合わせ: {question}")
# 【4-3】先ほどのテキストに対して、コサイン類似度を計算
similarities = []
for i, embedding_vector in enumerate(embeddings):
score = cosine_similarity(embedding_vector, q_vector)
similarities.append((docids[i], page_number_list[i], texts[i], score))
# df_outと比較して、固有名詞が含まれている場合は、その企業情報のみにする。
# どの会社か特定できている場合
if len(target_doc) > 0:
similarities = [row for row in similarities if row[0] == target_doc[0]]
# 類似度スコアが高い順にソート
similarities.sort(key=lambda r: r[3], reverse=True)
# 上位5件のみとして、ページ順にソーティング
similarities = similarities[:9]
# 固有名詞が見つからず、複数のドキュメントが混在しているものがあるため
max_docs = np.amax([s[0] for s in similarities])
similarities = [s for s in similarities if s[0] == max_docs]
pages = [sim[1] for sim in similarities]
pages = sorted(set(pages), key=pages.index)
scores = [sim[3] for sim in similarities]
similarities.sort(key=lambda r: r[1], reverse=False)
output.append([
index,
question,
similarities[0][0], # doc
pages, # pages
scores,
'\n\n'.join([sim[2] for sim in similarities]),
])
df_sim_doc = pd.DataFrame(output,
columns=['index', 'problem', 'doc',
'pages',
'scores',
'text'])
df_sim_doc.to_feather('problem_a9.ftr')
5. GPT-4o-miniでの試行結果
EmbeddingとCosine Similarityの後に、次のG部分を作成しました。先ほどの類似度検索したFeatherを読み込み、それに類似度が上位4位以内のページの画像を合わせて、プロンプトするものとしました。画像は、1ページあたり1000程度のコンテキストと処理されていた様であり、今回チャンキングした情報に比べるとそれほど大きくなく、使い勝手が良さそうでした。
#!/usr/bin/env python3
import re
import os
import io
import sys
import glob
import datetime as dt
import pandas as pd
import warnings
import base64
import time
import tiktoken
from openai import AzureOpenAI, OpenAI
from PIL import Image
warnings.filterwarnings('ignore')
DEPLOYMENT_ID_FOR_CHAT_COMPLETION = "4omini"
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
API_VERSION = os.getenv("API_VERSION")
PNG_DIR = './png'
SYS_CONTENT = '''
# Role
あなたは統合報告書・ESGレポートを分析する優秀なアナリストです。
ユーザーはこれら報告書等を活用にするにあたり、あなたに質問をするので、それに回答することでサポートします。
# Your Task
## **Input**
---コンテキスト---: <Markdown形式で記述された統合報告書の一部分>
---質問---: <コンテキストに対する質問>
## **Output**
markdown形式で回答します。
```markdown
# 回答
<回答内容>
## 根拠
<回答の理由>
## **Process**
1. 質問の内容から想定される回答について、回答内容に対する正規表現を用意します。
2. 質問内容の解釈とその思考過程がわかる様に段階的に回答の根拠を<回答の理由>を記述します。可能な限り記載してください。また計算が伴う場合は、計算式も詳細に記してください。
3. <回答の理由>と<回答内容>が整合しているか、矛盾がなく無関係となっていないか確認します。
4. <回答内容>が1.の正規表現に合致するか確認します。合致していなければ、1.から3.を繰り返します。
## Policy
* <回答内容>は54文字以内とします。
* 統合報告書・ESGレポートの画像が提供される場合があります。その場合は、コンテキストは画像情報の補助的なものとなります。
* 計算は精度が高いものを使用し、四捨五入等の丸め処理は最後に行ってください。
* <回答内容>は可能な限り短くし、「YYYY年度の〜は、〇〇〇〇名です」となる場合は「〇〇〇〇名」の様にしてください。
* 計算が伴う回答を行う際は、**できる限り精度の高い手法**を用います。
* 質問に単位が含まれている場合、その単位の通りに回答します。例: 822,391円に対して何万円であれば82万円、3,000千円に対して、何円であれば3,000,000円
* 質問に「小数第一位を四捨五入して答えてください。」という場合があります。計算した結果の数値が81.912%の場合、回答の数値は「82%」となります。
* 質問が「カタカナで答えてください」や「ひらがな・カタカナ・漢字を全て含む」という質問などに注意してください。
* コンテキストから見つからない場合、回答: わからない(根拠: <回答の理由>)とします。
'''
amendment = '''
### Example
質問と回答の例を示す。
index,質問,回答
1,大成温調が積極的に資源配分を行うとしている高付加価値セグメントを全てあげてください。,改修セグメント、医療用・産業用セグメント、官公庁セグメント
2,花王の生産拠点数は何拠点ですか?,36拠点
3,電通グループPurposeは何ですか?,an invitation to the never before.
4,2023年度の大成温調の連結純資産配当率(DOE)は何%でしたか?,3.0%
5,ダイドーグループの従業員数において、2012年から2023年までの12年間で、医薬品関連が食品を下回った年を全てあげてください。,2013年、2015年、2016年、2017年
6,東洋紡の取締役の在籍期間において、0~3年と4~9年ではどちらの方が取締役の人数が多いか,0~3年
7,東洋紡グループのコア技術を4つ答えてください。,高分子技術、バイオ・メディカル技術、環境技術、分析・シミュレーション技術
8,ダイドーグループが2012年に立ち上げたチャネルの国内飲料事業の中での売上は何%か,3%
9,ウエルシアホールディングスが掲げる2030のありたい姿はなんですか?,地域No.1の健康ステーション
10,日本化薬グループが「TCFD提言」に賛同したのは何年何月ですか?,2022年3月
11,花王の製品ライフサイクル全体のCO2 排出量において2019年度と2020年度ではどちらの数値が大きいか,2019年度
12,電通グループの電力使用に伴うCO2排出量ゼロを達成した撮影スタジオの名称を答えよ。,FACTORY ANZEN STUDIO
13,ダイドーグループの国内飲料事業では保有している自販機台数は約何台ですか?,約27万台
14,2024年2月29日現在、ウエルシアホールディングスの子会社は全部で何社ですか?,14社
'''
def conv_img_to_base64(image_path):
"""
PDFファイルを読み込み、Base64形式に変換する。
Args:
pdf_file_path (str): PDFファイルのパス。
Returns:
Base64形式の文字列。
"""
try:
# PDFファイルを読み込む
with open(image_path, "rb") as im_file:
image = im_file.read()
# Base64形式に変換
return base64.b64encode(image).decode('utf-8')
except Exception as e:
print(f"エラーが発生しました: {e}")
return None
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version=API_VERSION
)
# 質問をOpenAI APIに送信し回答を取得
def get_answer(question, context, doc_id:int, pages:list[int]):
'''
'''
usr_content = f'''次のコンテキストを参照して回答してください:
{context}
---質問---
{question}
'''
message = [
{"role": "system", "content": SYS_CONTENT},
{"role": "user", "content": [
{"type": "text", "text": usr_content},
]}
]
for page in pages:
png_path = f'./png/{doc_id}-' + (f'{page:003d}.png' if doc_id in (3, 6, 8, 10, 16) else f'{page:02d}.png')
message[1]['content'].append({
"type": "image_url",
"image_url": {"url": 'data:image/jpeg;base64,' + conv_img_to_base64(png_path)}
})
try:
response = client.chat.completions.create(
model=DEPLOYMENT_ID_FOR_CHAT_COMPLETION,
# max_tokens=54,
temperature=0.0,
messages=message
)
answer = response.choices[0].message.content.strip()
total_tokens = response.usage.total_tokens,
prompt_tokens = response.usage.prompt_tokens
return answer, total_tokens, prompt_tokens
except Exception as e:
print(e, file=sys.stderr)
return "EXCEPTION", None, None
# return f"エラー: {e}"
# 回答を保存するリスト
results = []
df_query = pd.read_feather('problem_a9.ftr')
print(df_query.head(5))
# df_query = df_query.head(5)
encoding = tiktoken.get_encoding("o200k_base")
# 各質問に対して回答を取得し保存
for row in df_query.iterrows():
index = row[1]['index']
doc_id = row[1]['doc']
# page = row[1]['page']
pages = list(row[1]['pages'])
question = row[1]['problem']
context = row[1]['text']
target_pages = sorted(set(pages), key=pages.index)[:5]
target_pages = sorted(target_pages)
print(f'{index:02d}: {question} (est_context_tokens = {len(encoding.encode(context)):,})')
print(pages)
answer, total_tokens, prompt_tokens = get_answer(question, context,
doc_id=doc_id,
pages=target_pages
)
if answer == 'EXCEPTION':
answer = 'わかりません。。。'
print(f'{answer}(total_tokens = {total_tokens[0]})')
time.sleep(5)
results.append([index, question, doc_id, pages, context,
answer, total_tokens[0], prompt_tokens])
if (index + 1) % 10 == 0 and index != 99:
df_ans = pd.DataFrame(results,
columns=['index', 'question', 'doc_id',
'pages', 'context', 'answer_detail',
'total_tokens', 'prompt_tokens'])
df_ans.drop(columns=['context'], inplace=True)
df_ans['answer'] = df_ans['answer_detail'].str.extract(r'# 回答\n(.*)\n')
df_ans.to_feather('predictions_checkpoint.ftr')
df_ans = pd.DataFrame(results,
columns=['index', 'question', 'doc_id',
'pages', 'context', 'answer_detail',
'total_tokens', 'prompt_tokens'])
df_ans['answer'] = df_ans['answer_detail'].str.extract(r'# 回答\n(.*)\n')
now = dt.datetime.now().strftime('%Y%m%dT%H%M%S')
print(f'### {now}')
output_path = f"pred_4omini_{now}.csv"
print(f"結果がCSVに保存されました: {output_path}")
df_ans.to_feather(f'pred_4omini_{now}.ftr')
df_ans[['index', 'answer']].to_csv(output_path, index=False, header=None, encoding="utf-8-sig")
当初は、このプロンプトを日本マイクロソフトさん提供のGPT-4o-miniで試行しましたが、回答が冗長で、暫定スコアが0.42(最終スコアは0.35で、この時は最も近似の4ページまでを送信)と、期待した結果が得られませんでした。
例:
1,株式会社キッツの取締役の報酬のうち株式報酬の割合は何%?
# 回答
取締役の報酬における株式報酬の割合は20%です。
## 根拠
取締役の報酬等構成比の表において、株式報酬が20%と記載されているため。
回答が詳細すぎることが、AcceptableやIncorrectになってしまい、適切にコンテキストを捉えているものの、スコアに影響した可能性が大いにある様に見えました。
7. Gemini 2.0 flash-thinking-exp-01-21 の試行結果
GPT-4o-miniでうまくいかなかったため、gemini-2.0-flashとgemini-2.0-flash-thinking-exp-01-21を代わりに利用したところ、冗長な回答はなくなり、スコアはやや上昇しました。
gemini-2.0-flashは、回答と根拠で矛盾が見られるものが増加しました。おいおい、回答の根拠を考えてる間に何が起きたんだい?と言わんばかりに...
そのため、gemini-2.0-flash-thinking-exp-01-21に切り替えると、矛盾は少なくなりましたが、それでも少し見られました。
また、画像を前後追加し、一つの4ページ分から12ページ分としました。入力コンテキストを長くしても特段問題がなく、他のモデルは長くすると、やはり回答が矛盾したり、必要な情報を見つけることができていなかった様子です。このことからすると、本来のRAGの趣旨からはズレていたのかもしれません。
import re
import os
import io
import sys
import glob
import datetime as dt
import pandas as pd
import warnings
import base64
import time
import tiktoken
from PIL import Image
from google import genai
from google.genai import types
warnings.filterwarnings('ignore')
PNG_DIR = './png'
SYS_CONTENT = '''
# Role
あなたは統合報告書・ESGレポートを分析する優秀なアナリストです。
ユーザーはこれら報告書等を活用にするにあたり、あなたに質問をするので、それに回答することでサポートします。
# Your Task
## **Input**
---コンテキスト---: <Markdown形式で記述された統合報告書の一部分>
---質問---: <コンテキストに対する質問>
## **Output**
markdown形式で回答します。
```markdown
# 回答
<回答内容>
## 根拠
<回答の理由>
## **Process**
1. 質問の内容から想定される回答について、回答内容に対する正規表現を用意します。
2. 質問内容の解釈とその思考過程がわかる様に段階的に回答の根拠を<回答の理由>を記述します。可能な限り記載してください。また計算が伴う場合は、計算式も詳細に記してください。
3. <回答の理由>と<回答内容>が整合しているか、矛盾がなく無関係となっていないか確認します。
4. <回答内容>が1.の正規表現に合致するか確認します。合致していなければ、1.から3.を繰り返します。
## Policy
* <回答内容>は54文字以内とします。
* 統合報告書・ESGレポートの画像が提供される場合があります。その場合は、コンテキストは画像情報の補助的なものとなります。
* 計算は精度が高いものを使用し、四捨五入等の丸め処理は最後に行ってください。
* <回答内容>は可能な限り短くし、「YYYY年度の〜は、〇〇〇〇名です」となる場合は「〇〇〇〇名」の様にしてください。
* 計算が伴う回答を行う際は、**できる限り精度の高い手法**を用います。
* 質問に単位が含まれている場合、その単位の通りに回答します。例: 822,391円に対して何万円であれば82万円、3,000千円に対して、何円であれば3,000,000円
* 質問に「小数第一位を四捨五入して答えてください。」という場合があります。計算した結果の数値が81.912%の場合、回答の数値は「82%」となります。
* 質問が「カタカナで答えてください」や「ひらがな・カタカナ・漢字を全て含む」という質問などに注意してください。
* コンテキストから見つからない場合、回答: わからない(根拠: <回答の理由>)とします。
### Example
質問と回答の例を示す。
index,質問,回答
1,大成温調が積極的に資源配分を行うとしている高付加価値セグメントを全てあげてください。,改修セグメント、医療用・産業用セグメント、官公庁セグメント
2,花王の生産拠点数は何拠点ですか?,36拠点
3,電通グループPurposeは何ですか?,an invitation to the never before.
4,2023年度の大成温調の連結純資産配当率(DOE)は何%でしたか?,3.0%
5,ダイドーグループの従業員数において、2012年から2023年までの12年間で、医薬品関連が食品を下回った年を全てあげてください。,2013年、2015年、2016年、2017年
6,東洋紡の取締役の在籍期間において、0~3年と4~9年ではどちらの方が取締役の人数が多いか,0~3年
7,東洋紡グループのコア技術を4つ答えてください。,高分子技術、バイオ・メディカル技術、環境技術、分析・シミュレーション技術
'''
amendment = '''
### Example
質問と回答の例を示す。
index,質問,回答
1,大成温調が積極的に資源配分を行うとしている高付加価値セグメントを全てあげてください。,改修セグメント、医療用・産業用セグメント、官公庁セグメント
2,花王の生産拠点数は何拠点ですか?,36拠点
3,電通グループPurposeは何ですか?,an invitation to the never before.
4,2023年度の大成温調の連結純資産配当率(DOE)は何%でしたか?,3.0%
5,ダイドーグループの従業員数において、2012年から2023年までの12年間で、医薬品関連が食品を下回った年を全てあげてください。,2013年、2015年、2016年、2017年
6,東洋紡の取締役の在籍期間において、0~3年と4~9年ではどちらの方が取締役の人数が多いか,0~3年
7,東洋紡グループのコア技術を4つ答えてください。,高分子技術、バイオ・メディカル技術、環境技術、分析・シミュレーション技術
8,ダイドーグループが2012年に立ち上げたチャネルの国内飲料事業の中での売上は何%か,3%
9,ウエルシアホールディングスが掲げる2030のありたい姿はなんですか?,地域No.1の健康ステーション
10,日本化薬グループが「TCFD提言」に賛同したのは何年何月ですか?,2022年3月
11,花王の製品ライフサイクル全体のCO2 排出量において2019年度と2020年度ではどちらの数値が大きいか,2019年度
12,電通グループの電力使用に伴うCO2排出量ゼロを達成した撮影スタジオの名称を答えよ。,FACTORY ANZEN STUDIO
13,ダイドーグループの国内飲料事業では保有している自販機台数は約何台ですか?,約27万台
14,2024年2月29日現在、ウエルシアホールディングスの子会社は全部で何社ですか?,14社
'''
# usr_content = f'''---コンテキスト---
# {context}
# ---質問---
# {question}
# '''
def conv_img_to_base64(image_path):
"""
PDFファイルを読み込み、Base64形式に変換する。
Args:
pdf_file_path (str): PDFファイルのパス。
Returns:
Base64形式の文字列。
"""
try:
# PDFファイルを読み込む
with open(image_path, "rb") as im_file:
image = im_file.read()
# Base64形式に変換
return base64.b64encode(image).decode('utf-8')
except Exception as e:
print(f"エラーが発生しました: {e}")
return None
def merge_images_vertically(doc_id=1, page=2):
# フォルダ内のPNGファイルを取得し、ソート
png_path = f'{PNG_DIR}/{doc_id}-' + (f'{page:003d}.png' if doc_id in (3, 6, 8, 10, 16) else f'{page:02d}.png')
if page == 1:
png_path_prev = f'{PNG_DIR}/{doc_id}-' + (f'{page+2:003d}.png' if doc_id in (3, 6, 8, 10, 16) else f'{page+2:02d}.png')
else:
png_path_prev = f'{PNG_DIR}/{doc_id}-' + (f'{page-1:003d}.png' if doc_id in (3, 6, 8, 10, 16) else f'{page-1:02d}.png')
png_path_next = f'{PNG_DIR}/{doc_id}-' + (f'{page+1:003d}.png' if doc_id in (3, 6, 8, 10, 16) else f'{page+1:02d}.png')
if not os.path.isfile(png_path_next):
png_path_next = f'{PNG_DIR}/{doc_id}-' + (f'{page-2:003d}.png' if doc_id in (3, 6, 8, 10, 16) else f'{page-2:02d}.png')
paths = [png_path_prev, png_path, png_path_next]
# 画像を読み込む
images = [Image.open(file) for file in sorted(paths)]
# 結合後の画像サイズを計算(幅は最大値、高さは合計)
max_width = max(img.width for img in images)
total_height = sum(img.height for img in images)
# 新しいキャンバスを作成
merged_image = Image.new("RGB", (max_width, total_height), "white")
# 各画像を結合
y_offset = 0
for img in images:
merged_image.paste(img, (0, y_offset))
y_offset += img.height # 高さを加算
return merged_image
api_key = os.getenv('GEMINI_API_KEY')
client = genai.Client(api_key=api_key)
def get_answer(question, context, doc_id:int, pages:list[int], model_name="gemini-2.0-flash-thinking-exp-01-21"):
'''
'''
usr_content = f'''次のコンテキストを参照して回答してください:
{context}
---質問---
{question}
'''
message = [SYS_CONTENT + '\n' + usr_content]
images = [merge_images_vertically(doc_id=doc_id, page=page) for page in pages]
message.extend(images)
try:
response = client.models.generate_content(
# model="gemini-2.0-flash",
model=model_name,
# temperature=0.0,
contents=message,
)
return response.text
except Exception as e:
print(e, file=sys.stderr)
return "EXCEPTION"
# 回答を保存するリスト
results = []
df_query = pd.read_feather('problem_a9.ftr')
print(df_query.head(5))
# df_query = df_query.head(5)
encoding = tiktoken.get_encoding("o200k_base")
target_indexes = []
if len(target_indexes) > 0:
df_query = df_query[df_query['index'].isin(target_indexes)] #.sort_values(['doc', 'index'], ascending=True)
# 各質問に対して回答を取得し保存
for row in df_query.iterrows():
index = row[1]['index']
doc_id = row[1]['doc']
pages = list(row[1]['pages'])
question = row[1]['problem']
context = row[1]['text']
target_pages = sorted(set(pages), key=pages.index)[:5]
target_pages = sorted(target_pages)
print(f'{index:02d}: {question} (est_context_tokens = {len(encoding.encode(context)):,})')
print(pages)
answer = get_answer(question, context,
doc_id=doc_id,
pages=target_pages)
if answer == 'EXCEPTION':
answer = 'わかりません。。。'
answer = get_answer(question, context,
doc_id=doc_id,
pages=target_pages,
model_name="gemini-2.0-flash")
if answer == 'EXCEPTION':
answer = 'わかりません。。。'
print(f'{answer}')
time.sleep(14)
results.append([index, question, doc_id, pages, context,
answer,
])
df_ans = pd.DataFrame(results,
columns=['index', 'question', 'doc_id',
'pages', 'context', 'answer_detail',
# 'total_tokens', 'prompt_tokens'
])
now = dt.datetime.now().strftime('%Y%m%dT%H%M%S')
output_path = f"predictions_{now}.csv"
print(f"結果がCSVに保存されました: {output_path}")
if len(target_indexes) == 0:
df_ans.to_feather(f'predictions_detail_{now}.ftr')
df_ans['answer'] = df_ans['answer_detail'].str.extract(r'# 回答\n(.*)\n')
print(f'### {now}')
if len(target_indexes) == 0:
df_ans[['index', 'answer']].to_csv(output_path, index=False, header=None, encoding="utf-8-sig")
8. 回答整合性の確認と修正
そこで、次の様に、一旦回答した内容結果を改めて確認し、内容がおかしければ修正するという処理を追加しました。
SYS_CONTENT = '''
# Role
あなたは統合報告書・ESGレポートを分析する優秀なアナリストです。
ユーザーはこれら報告書等を活用にするにあたり、あなたに質問をするので、それに回答することでサポートします。
# Your Task
統合報告書の質問に対して、回答とその根拠が記載されたものがありますが、その内容が整合していないものがあります。
このため、整合していないものについて修正を行って、最終的な回答とすることをサポートします。
## **Input**
---前回の回答---: <以前の回答と根拠>
---質問---: <質問>
## **Output**
修正した回答と根拠をmarkdown形式で回答します。
```markdown
# 回答
<回答内容>
## 根拠
<回答の理由>
## **Process**
1. 前回の回答について、<回答内容>と<回答の理由>が整合しているか確認します。まず、<回答の理由>を分析し、<回答内容>と整合していない場合は、<回答内容>を更新します。
2. 1.で<回答内容>と<回答の理由>が整合していれば、<回答内容>と<回答の理由>はそのままとします。
3. <回答内容>と<質問>の単位や求める書式に合致するか確認し、異なっている場合は、単位や数量を変更します。
## Policy
* <回答内容>は54文字以内とします。
* <回答内容>は可能な限り短くし、「YYYY年度の〜は、〇〇〇〇名です」となる場合は「〇〇〇〇名」の様にしてください。さらに質問と比較して、冗長と思われる表現を除いてください。
* コンテキストは<回答の理由>であるため、<回答の理由>と<回答内容>のみで整合性を確認し、外部の情報を用いません。
* 計算が伴う回答を行う際は、**できる限り精度の高い手法**を用い、四捨五入等の丸め処理は最後に行ってください。
* 質問に単位が含まれている場合、その単位の通りに回答します。
* 質問が「カタカナで答えてください」や「ひらがな・カタカナ・漢字を全て含む」という質問などに注意してください。
* 必ず、回答: わからない(根拠: <回答の理由>)とします。
### Example
質問と回答の例を示す。
index,質問,回答
1,大成温調が積極的に資源配分を行うとしている高付加価値セグメントを全てあげてください。,改修セグメント、医療用・産業用セグメント、官公庁セグメント
2,花王の生産拠点数は何拠点ですか?,36拠点
3,電通グループPurposeは何ですか?,an invitation to the never before.
4,2023年度の大成温調の連結純資産配当率(DOE)は何%でしたか?,3.0%
5,ダイドーグループの従業員数において、2012年から2023年までの12年間で、医薬品関連が食品を下回った年を全てあげてください。,2013年、2015年、2016年、2017年
6,東洋紡の取締役の在籍期間において、0~3年と4~9年ではどちらの方が取締役の人数が多いか,0~3年
7,東洋紡グループのコア技術を4つ答えてください。,高分子技術、バイオ・メディカル技術、環境技術、分析・シミュレーション技術
'''
api_key = os.getenv('GEMINI_API_KEY')
client = genai.Client(api_key=api_key)
# 質問をOpenAI APIに送信し回答を取得
def get_answer(question, prev_ans):
'''
'''
usr_content = f'''「前回の回答」の<回答>と<根拠>が整合しているか確認し、回答を修正してください。
また、「質問」が求める数量や単位などに合致しているか確認してください。
---前回の回答---
{prev_ans}
---質問---
{question}
'''
message = [SYS_CONTENT + '
' + usr_content]
try:
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=message,
)
return response.text
except Exception as e:
print(e, file=sys.stderr)
return "EXCEPTION", None, None
この様に二段階としたところ、暫定スコアが0.73(最終スコアが0.71)まで上がりました。なお、回答を見直す処理は、gemini-2.0-flash-thinking-exp-01-21よりgemini-2.0-flashの方が良かった様でした。gemini-2.0-flash-thinking-exp-01-21は余計なことをする様な印象がありました。
おわりに
今回、初めてRAGに関するコンペに参加し、試行錯誤することができました。生成AIは、ChatGPT 4oを利用しているのですが、APIを使ったことはなく、大変学びになりました。また、Azureを使ってこなかったのですが、さまざまなサービス・機能があるので、いろいろと活用してみたいなと感じました。(コードをベタベタと貼った内容になってしまいましたが、何か使える部分があれば幸いです。)
運営の皆様、誠にありがとうございました。
なお、こちらは、ChatGPT 4oを使って作成・編集しました。