はじめに
【SIGNATE】(金融庁共催)第3回金融データ活用チャレンジに参加し、最終結果5位となりました。※まだ速報値であり、失格になる可能性もあり
最終的に出来上がったシステムがなかなかユニークなものになったのでその概要をまとめます。
失格になったとしても考え方や発想は色々なところに応用できる可能性があると考えています。少しでもどなたかの役に立てばという思いで執筆いたしました。拙い文章ですが、ご覧いただければ幸いです。
コンペ概要
J-LAKE(*パートナー企業であるDATAZORAのKIJIサービス提供データを含む)の情報を用いてRAGシステムを構築しその回答の精度を競うコンペでした。(詳しくはサイトを参照ください。)
スコア
暫定スコア0.95/最終スコア0.89(速報値)でした。
参加経緯
参加理由は主に以下の2つです。
-
RAG-1グランプリのリベンジ
実は昨年開催された似たようなコンペであるRAG-1グランプリに参加しており、8位という結果でくやしい思いをしました。今回はそのリベンジマッチとして優勝を目指して参加しました。 -
RAGや生成AI周りのスキルアップ
RAGや生成AIの最新の技術をキャッチアップして実装する力を身につけたいというのも参加の理由の一つです。
解法全体像
タイトルにもある通り、質問毎に使用するコレクション(ベクターストアのこと)とsystem(① サブ質問を用いたRAG ② Long-context LLM ③ Multimodal RAG)を使い分けるハイブリッドシステムを作成しました。
全体像と処理の流れは以下のイラストの通りです。
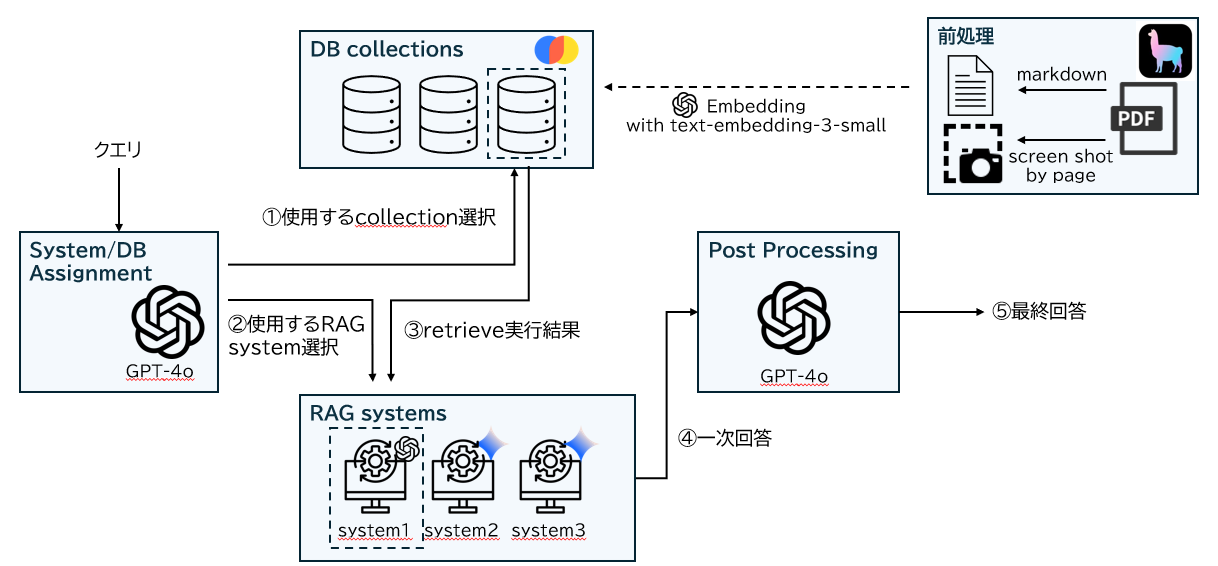
各コンポーネントについて概要をこのようなシステム構成にいたるまでの背景も含めて以下に紹介します。
※具体的のコードは現在検収中のため、掲載していません。無事検収が通れば、一部コードを追記予定です。
※検収が通らなかったとしても、考え方自体は色々な場面で応用できるかと思いますので是非一読いただければと思います。
1.前処理パート
今回のコンペのキーポイントがこの前処理パートだったと感じています。
理由は単純で正確にPDFをテキストやmarkdownに変換できるかどうかが正しい回答の獲得に直結するからです。
私がためしたPDFtをTEXTに変換するライブラリはunstructuredとllamaparseの2つです。
結論はllama parseを使用し、PDFをMarkdown形式のテキストに変換しました。
理由は単純でllama parseのpremium modeの精度(特に表データの検出精度)がかなり高かったからです。(※APIコストも高い)
実際に公式サイトでもState-of-the-art table extractionと記載されています。
私は上位を狙うために、コスパよりタイパを重視しすぐにこのライブラリを使用することを決意しました。
llamaparseの優れた点はテキスト化の精度の他にもchart extractやimg extract、page screen shot等のオプション機能が豊富な点です。
私はpage screen shot機能で得た画像を用いて後続のmultimodal RAGを実装しました。
(※chart extractでpdfのチャート部分のみを画像抽出しその画像をインプットにllmでチャートの内容を説明させて、それをもとにRAGを構築するパターンも試しましたが、あまりいい結果がえられませんでした。)
llamaparseをコンペの早い段階で試せたことで、早い段階でPDFのテキスト化を高精度で実行できたました。そのアーキテクチャの試行錯誤に大きく時間を割くことができ、今回の結果につながったと感じています。
2.System/DB Assignmentパート
llm(gpt-4o)を使用して、各質問に対して後述するSystem群やDB群の選択に必要な以下の情報を取得するコンポーネントです。
a. 質問対象の企業名
b. 全文検索が必要な問題か
c. 10年間以上の財務データが掲載された情報を必要とする問題か
それぞれの情報を取得する意味とその使われ方は以下の通りです。
a. 質問対象の企業名
今回の質問群の大半は質問文中に質問対象となる企業が記述されています。
よって各質問文に対して、その対象となる企業名が何かをLLM(GPT-4o)を使用して特定します。この情報をもとに後述するDBコレクションでどの企業のコレクションを使用するかを決定します。
※企業名が判断できない場合は"unknown"と返すようにしています。
b.全文検索が必要な問題か
質問文の回答根拠となる文章を詳しく調べていくうちに、回答根拠がPDF中の様々なページに散在している質問がいくつか存在することに気づきました。このような質問に対して通常のRAGのアーキテクチャでは必要なすべての情報を漏れなくretrieveするのは非常に難しく、その結果正しい回答が得られないという問題点にも気づきました。
そこで、全文検索を行う必要性が高い質問(特定の情報を数え上げる必要がある問題等)をLLMに判定させています。この結果全文検索が必要と判断した質問は後述のsystem2(Long-context LLM)におくるという選択をしています。
c.10年間以上の財務データが掲載された情報が必要な問題か
こちらについても質問を注意深く観察すると、いくつかの質問は10年分以上の財務データを回答根拠としなければいけない問題がありますが、また10年分以上の財務情報が記述されているページはもれなく財務諸表の表データでした。しかし、①この表データはretriveの結果されにくいという問題がありました。
この課題に対して、LLMが以下2点の判断がつくのであれば、
- 質問文から10年分以上の情報を必要としているかどうか
- 参照元のテキストで10年分以上の財務データが掲載されているか
「質問文が10年分以上の財務データを必要としている場合にのみ、10年分以上の財務データが掲載されたページだけをembeddingしたDBに送る」というのsystemを実装できるなと考え、試したところ実行可能でした。
よって上記のプロセスを組み込んだsystem3を作成し、LLMが10年分以上の財務データが必要と判断したものをsystem3に送ることにしています。
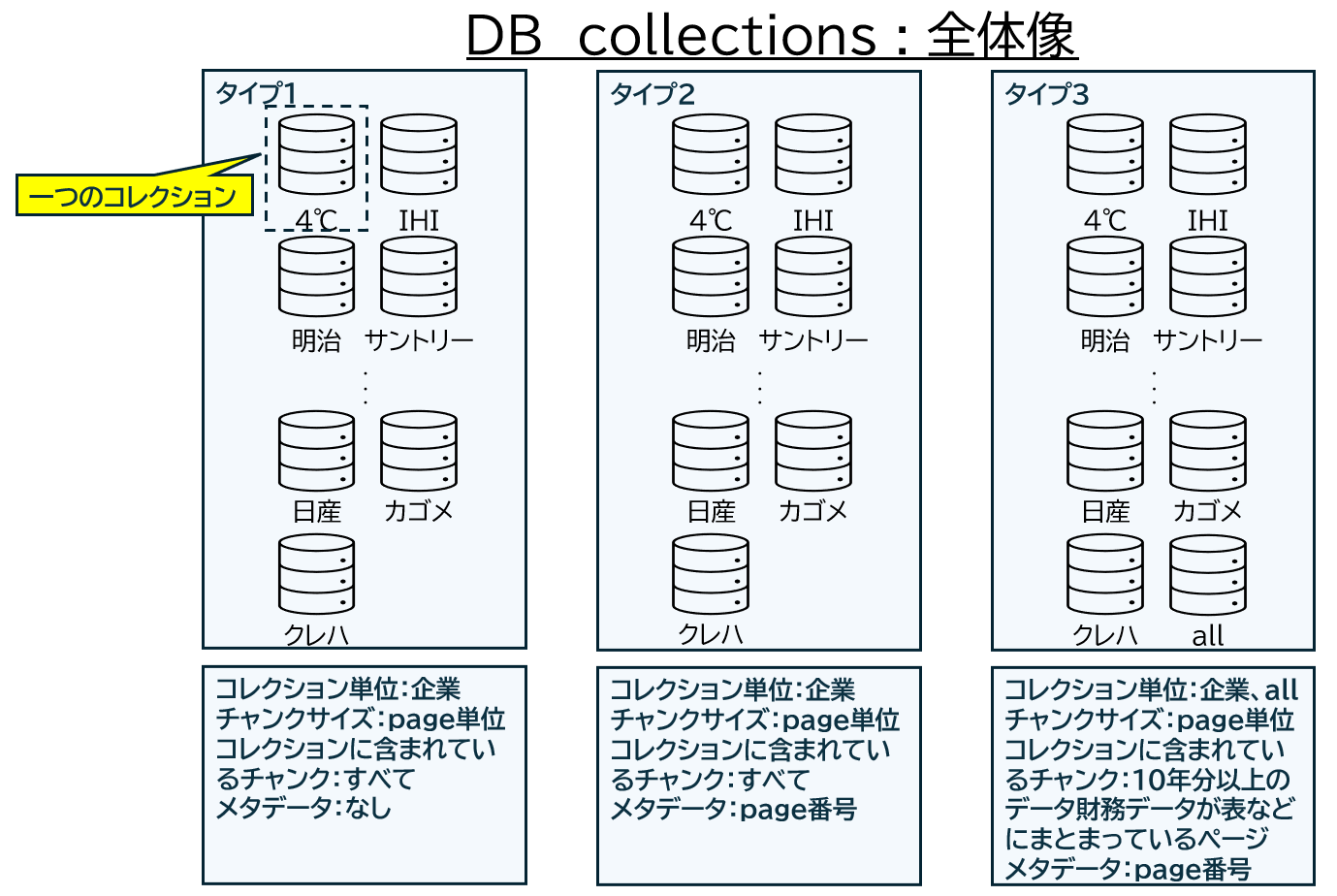
3.DB コレクション
systemごとにDBを使い分けるため、コレクションも以下の3タイプ作成しました。
-
タイプ1. 企業単位でコレクションを作成し、チャンキングはpage単位で行い、それらをベクトル化、メタデータなし
-
タイプ2. 企業単位でコレクションを作成し、チャンキングはpage単位で行い、それらをベクトル化、メタデータページ番号(page screenshotに紐づけるための情報)
-
タイプ3. llmを使用し10年以上のデータが表やチャートで掲載されているページのみを抽出し、それらを企業単位にまとめたコレクションと全企業でまとめたコレクションを作成。チャンキングはpage単位で行い、そこから、それらをベクトル化、メタデータページ番号(page screenshotの参照)
4.RAG systems
いよいよ本題のRAG systemsについてです。作成した3システムそれぞれ順に説明をいたします
system1. サブ質問を用いたRAG
このsystem1が本解法のメインシステムです。ほとんどの質問(2-b,2-cのどちらも必要なしとなった質問)に対する回答を本システムで回答しています。
まずはこのメインシステムにサブ質問を用いたRAGを使用した背景から説明します。
背景
query.csvの中には多段階推論や比較推論を必要とする質問が多数存在しました。そのようなタイプの問題では必ずといってよいほど以下の課題に直面します。
- 回答根拠となる文章をretrieveできない
- できたとしてもLLMが正しい回答を出力しない
1の課題について.
この根本的な要因は質問文に対する回答が本文中に直接的に記述されていないことにあります。
例えば、
A社とB社の売上高はどちらが高いですか?
という比較質問がなされた場合を考えましょう。
直接的な回答というのは
「A社とB社の売上高はA社のほうが高いです。」
というように質問に対する回答が本文中に直接的に記載されている場合のことです。
一方で、実際はこのように直接的な回答は存在せず、
「A社の売上高は1億」
「B社の売上高は1億2千万円」
というように、回答の根拠となる情報が文章中にバラバラに存在し、これらの情報を組み合わせて推論しなければいけない場合も非常に多く存在します。
元々の質問文のままでベクターストアから関連情報を検索した場合に後者のパターンでは文章類似度が低くなってしまい、その結果として検索結果の上位に上がってこないという問題がしばしば生じます。
2.の課題について
2の課題については、世間で言われているとおりLLMは一度たくさんのタスクを遂行するのが非常に苦手です。(計算が絡むと特に・・・)
そのため、多段階推論や比較推論等になると回答精度が下がる傾向にあります。
(※o1等推論力の高いモデルを使えば問題なさそうですが、コストを考慮するとなるべく4oもしくは4o-miniを使用したかったです。)
解決策
よって上記のような課題を解決するためにサブ質問を用いたRAGを構築いたしました。
サブ質問を用いたRAGでは、まず最初にLLMを用いて質問をサブ質問に分解します。そうして得られたそれぞれのサブ質問に対する回答をRAGから取得します。最後にそのサブ質問とその回答のペアの集合をもとに元の質問の回答を得るというものです。
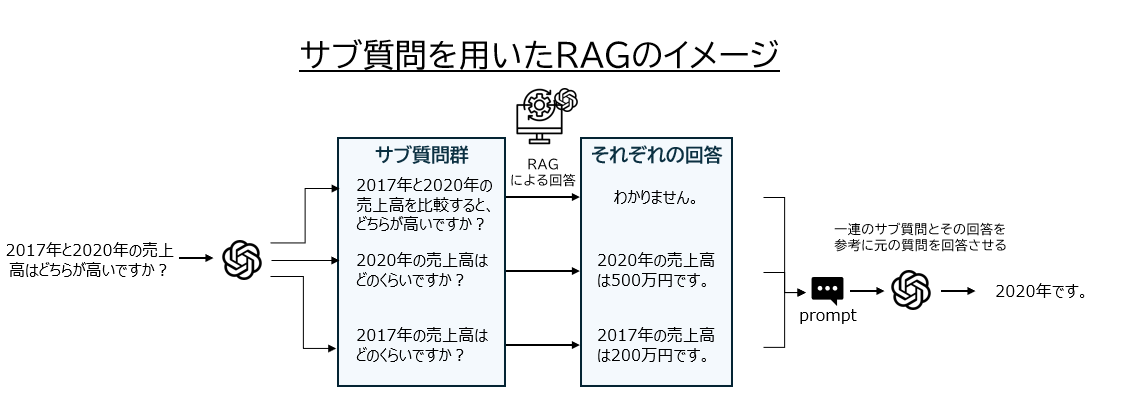
gpt-4oを使用した場合、このシステムのみで暫定スコア0.7以上を記録しました。
system1ではこの後さらに、質問文と回答を照らし合わせた際にあきらかな誤りがある場合は後述するmultimodal RAGの機構で再度回答を取得し回答の修正を行う処理を行っています。
system2:Long-context LLMについて
このシステムを作成した背景2-bで言及した通り以下となります。
背景
- RAGは回答根拠となる情報が散在している質問に対して精度が悪くなる傾向がある。
- 質問の中には回答根拠が散在している質問もあり、それらの質問にたいして、system1では正しい回答が導けない
解決策
- 2-bで回答情報が散在している可能性があるとLLMが判断した質問に対して質問対象企業の統合報告書全文をcontextとして与える、Long context LLMを実装
- 使用したLLM: gemini-1.5-pro
system3:multimodal RAG
このシステムを作成した背景2-cで言及した通り以下となります。
背景
- 10年分以上の財務情報を回答根拠に必要とする問題を解く際に以下2つの課題に直面
- 財務情報がまとまっている表やチャートがretrieveで上位にヒットしない
- pdfをmarkdownにparseする際、マルチカラムの表や複雑なチャートの情報を正確にmarkdown化するのが難しい
解決策
- タイプ3のDBでRetrieveを実行
- retrieveの検索結果で上がってきたdocumentのメタデータに含まれているpage番号から当該pageのスクリーンショット(画像データ)をインプットとして与えるmultimodal ragの実装
使用LLm: gemini-2.0-flash-exp
これらの3systemを質問ごとに使い分けることで一次回答を取得します。
5. 後処理
後処理として、得られた一次回答を望ましいフォーマットに整形する処理をLLM(gpt-4o)で実行し最終回答を獲得します。ここではひたすらFew shot プロンプトの例を積み上げていき、自分が望む回答のフォーマットで出力されるようします。この作業をしっかりやらないと、本質的には正解の回答もINCOREECTと判定してしまう可能性があります。上位のスコアを狙うにはかなり重要な作業となります。
以下後処理のプロンプト例です。
"""あなたは文章校正のエキスパートです。
以下は質問とその回答のペアです。
- 例を参考に質問に対する回答として成立する範囲で端的な回答に校正してください。
- 「わかりません。」という回答はそのまま「わかりません。」と出力してください。
例1:
質問: 2020年の売上高はいくらですか?
回答: 2020年の売上高は1億円です。
校正後の回答: 1億円
例2:
質問: 私と弟の体重はどちらが軽い?
回答: 私の方が軽いです。
校正後の回答: 私
例3:
質問: 2024年度の売上高は2023年度対比で何%向上したか?小数第2位で四捨五入してください。
回答: 9.40%です。
校正後の回答: 9.4%
例4:
質問:評価基準をいくつクリアする必要がありますか?
回答:5項目以上
校正後の回答:5つ
例5:
質問:A社の経営理念はなんですか?
回答:A社の経営理念は「お客様の未来を支える」です。
校正後の回答:お客様の未来を支える
例6:
質問:A社の強みはなんですか?
回答:「日本全国に拠点をおいた安定した供給網が強みです」。
校正後の回答:日本全国に拠点をおいた安定した供給網
例7:
質問:A社の平均月収は約何万円ですか?
回答:A社の平均月収は約30万円です
校正後の回答:約30万円
質問: {question}
回答: {answer}
校正後の回答:
"""
以上が私の解法の簡単な説明となります。このシステムを通した結果、暫定評価0.95/最終評価0.89となるスコアを達成しすることができました。
最後に
参加経緯にも挙げた、リベンジこそ果たませんでしたが、色々なモデルやアーキテクチャを試すことができ、スキルアップにつながるコンペとなりました。この場を借りて機会を与えてくださった運営の皆様、協賛企業の皆様、そして最後まで切磋琢磨しあったすべての参加者の皆様に感謝いたします。
また、これをコンペで終わらせるのではなく、社会実装に向けて積極的な行動をとっていきたいなと強く感じました。このコンペにかかわった皆様が各々の組織で活躍され、日本企業全体の成長に大きく貢献する。そんな素敵な未来が実現すればいいなと思った次第です。
参考文献
https://arxiv.org/abs/2312.10997v5
https://www.arxiv.org/abs/2407.16833
https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb
https://github.com/langchain-ai/rag-from-scratch