こんにちは。
SIGNATEの「第3回金融データ活用チャレンジ」に参加して取組んだ内容について、その結果と手法を解説します。
取組みや記事作成は @SY122095 氏を含むチームメンバーと取組みました。
取組結果概要
| チーム名 | FXD |
| 暫定評価 | 0.52 |
| 最終評価(順位) | 0.28(161/1,544) |
RAGシステム構築方針
私たちのチームでは、社員のRAGに関する知見を実践で蓄積すること目的として、本コンペティションに参加しました。
これにあたり、以前開催されていた「RAG-1グランプリ」の知見共有会で共有された知見をもとにRAG構築の方針を決定しました。
| タスク | アプローチ |
|---|---|
| Store | テキスト抽出、要約処理、チャンキング、ベクトル化 |
| Retrieve | 参照ファイル特定、ベクトル検索 |
| Augment | プロンプト構築(マークダウン記法)、質問の分類と質問カテゴリ別プロンプト構築、生成結果のアンサンブル |
| Generate | パラメータチューニング、ハルシネーション対策 |
上記の方針に基づき、目標スコアを「0.5」として取組みを実施しました。
実際に構築したRAGシステム
イメージ図
(図1)RAGシステムイメージ図

Azure OpenAI ServiceとAPI連携し、データの取得から生成結果の出力まで行えるPyhtonコードを構築しました。
(図2)タスク別イメージ図

今回の取組みでは、各工程において複数パターンに分岐させて生成を行いその結果をアンサンブルすることが有力ではないかと考え、上図のようなパターン分岐により生成を行いました。
設定・API連携
RAGシステムの構築のベースは、Azure OpenAIとしました。
(使用したAPI)
- コンペ提供
- endpoint :'https://apim-fdua-aoai-002.azure-api.net/model/'
- llm_deployment :'4omini'
- embed_deployment : 'embedding'
- api_version : '2024-10-21'
- api_key : '6bc29179dbd7808aee7d3e1ef50145a4'
- 社内契約
- 4o, o1-mini
テキスト抽出・並び替え
今回の検索対象とするデータは上場企業の統合報告書ですべてPDFファイルです。そのため、PDFファイルからテキスト情報の抽出が必要となります。考えられるアプローチは大きく2つです。
- AI-OCR : 「Azure Computer Vision」を使用します。
- PDF解析 : Pythonライブラリの「PyMuPDF」や「pdfplumber」などを使用し、テキスト抽出、表のhtml出力などを行います。
AI-OCR
AzurePortalにおいて画像認識可能なサービス(Azure Computer Vision)を用いてPDFファイルの文字起こしを行います。
-
使用サービス: Azure Computer Vision
-
インプット
- 統合報告書のPDFをそのまま入力します。
例: 株式会社4℃ホールディングス
- 統合報告書のPDFをそのまま入力します。
-
アウトプット
- ACVからは以下のようにJSONでページごとにテキストと記載位置(boundingBox)が格納されている辞書のリストが返されるため、Pythonで加工していきます。
ACV返り値
{'boundingBox': [3.7416, 10.5305, 3.9616, 10.5305, 3.9616, 10.7541, 3.7416, 10.7541], 'text': '笑', 'confidence': 1}, {'boundingBox': [3.9791, 10.5312, 4.2046, 10.5312, 4.2046, 10.7538, 3.9791, 10.7538], 'text': '顔', 'confidence': 1}, {'boundingBox': [4.223, 10.5394, 6.6824, 10.5394, 6.6824, 10.7444, 4.223, 10.7444], 'text': '”や“ときめき”のために', 'confidence': 1}]} -
テキスト作成
-
返されたJSONを順に結合していくと以下のようにPDFの段組みが考慮されず文章として成り立たない箇所が多数出てきます。
4℃ holdings group 統合レポート 4℃レポート2024 すべては、お客様の“笑顔”や“ときめき”のために 経営理念・ブランドコンセプト 4℃ホールディングスグループの At a Glance CorporatePhilosophy経営理念 業績(2024年2月期) 株主情報(2024年2月29日現在) 私達は、お客様に信頼される企業を目指します。 売上高 394.5億円 私達は、社員に夢を与える企業を目指します。
-
ルールベースで折り返し地点を設定し、返り値を結合していくことで以下のように改善されました。
株式会社4℃ホールディングス CorporatePhilosophy経営理念 私達は、お客様に信頼される企業を目指します。 私達は、社員に夢を与える企業を目指します。 私達は、社会に貢献できる企業を目指します。 私達は、株主に期待される企業を目指します。 CorporateMessage コーポレートメッセージ 当グループは、4℃ブランドを中心とした グローバルファッション創造企業として、お客様の一歩先のニーズに 応える、お客様の生活文化を向上させる企業であり続けます。
-
また、図表部については以下のように表としての情報を保てていないためさらに改善が必要となります。
4℃ 2℃未満 シナリオ シナリオ 大 中 炭素税の導入によるコストの増大 脱炭素・低炭素エネルギーの利用促進 開示業務の効率化 小 中 情報開示義務拡大への対応による業務負荷、コストの増大 商品のLCA(ライフサイクルアセスメント)評価義務化によ 新たな業務範囲の精査および業務の効率化・ - 中 るトレーサビリティの確保等必要な措置による業務負荷と RJCの継続 コストの増大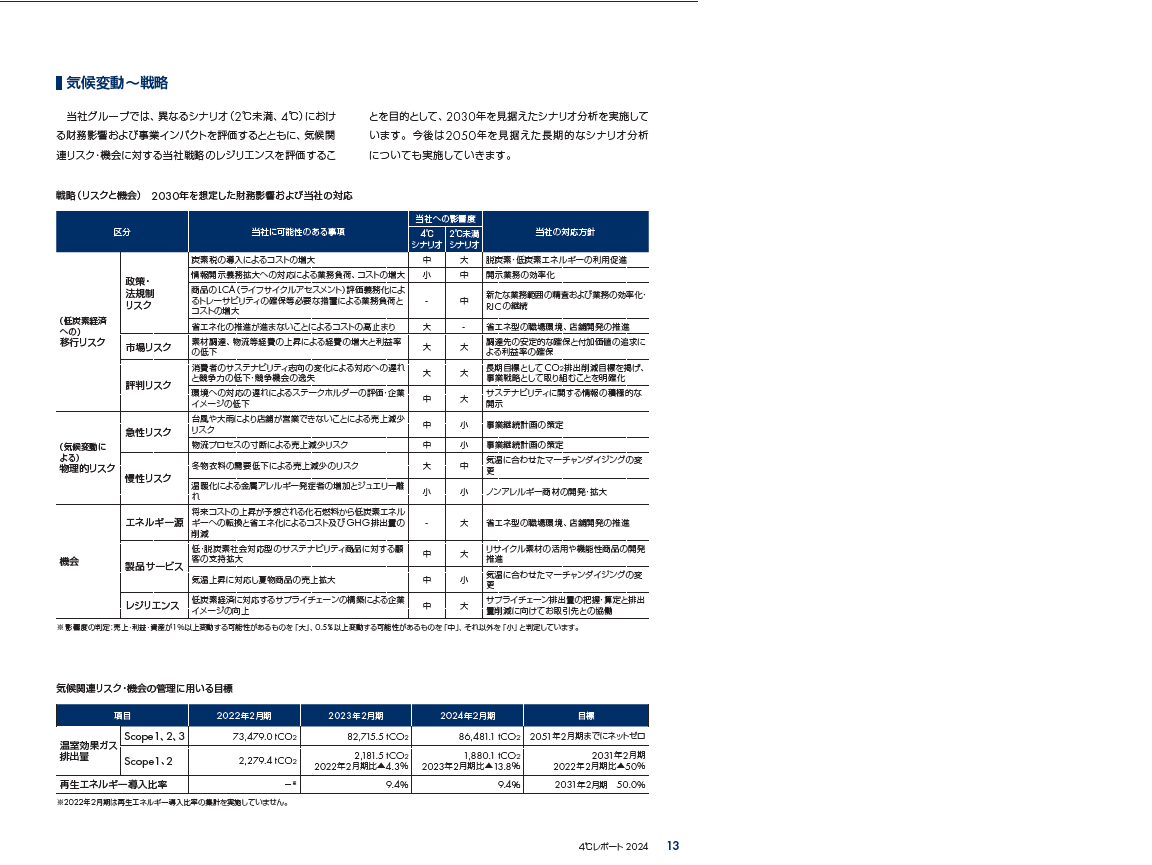
AI-OCRコード
# エンドポイントとAPIキーを設定
endpoint = 'https://xxxx/'
api_key = 'xxxxxxxxxx'
# PDFファイルが格納されているディレクトリを指定
pdf_dir = './xxx/documents'
# PDFをひとつずつ文字起こししていく
for f in os.listdir(pdf_dir):
# PDFファイルのパスを指定
pdf_path = os.path.join(pdf_dir, f)
# エンドポイントからOCRのURLを指定
ocr_url = f'{endpoint}vision/v3.2/read/analyze'
# PDFデータの読み込み
pdf_data = open(pdf_path, 'rb').read()
# パラメータの設定
headers = {
'Ocp-Apim-Subscription-Key': api_key,
'Content-Type': 'application/octet-stream'
}
# APIを呼び出す
response = requests.post(ocr_url, headers=headers, data=pdf_data)
# 結果取得
operation_location = response.headers['Operation-Location']
analysis = {}
while not 'analyzeResult' in analysis:
response_final = requests.get(operation_location, headers={'Ocp-Apim-Subscription-Key': api_key})
analysis = response_final.json()
# テキスト化(テキストとboundingBoxが返されるため、boundingBoxを参照して並び替える)
text = ''
# ページ数を取得してページごとに並び替え
length = len(response['analyzeResult']['readResults'])
for page in range(0, length):
# 対象ページのboundingBoxとテキストのみ抽出
content = response['analyzeResult']['readResults'][page]['lines']
content = [{'boundingBox': d['boundingBox'], 'text':d['text']} for d in content]
# 左端x座標で並び替え
l = [[i, c['boundingBox'][-2]] for i, c in enumerate(content)]
tmp = pd.DataFrame(data=l, columns=['index', 'x'])
tmp.sort_values('x', inplace=True)
content_xsorted = [content[int(v[0])] for v in tmp.values]
# どのくらいずれていれば違う段とみなすかの閾値を設定
x_threshold = 0.4
tmp['x_pre'] = tmp['x'].shift(1)
tmp['x_diff'] = np.abs(tmp['x']-tmp['x_pre'])
tmp['changepoint'] = tmp['x_diff'].apply(lambda x: x>x_threshold)
tmp['x_group'] = tmp['changepoint'].cumsum()
# 左端y座標で並び替え
l2 = [[i, c['boundingBox'][-1]] for i, c in enumerate(content)]
tmp2 = pd.DataFrame(data=l2, columns=['index', 'y'])
tmp2.sort_values('y', inplace=True, ascending=True)
content_xsorted = [content[int(v[0])] for v in tmp2.values]
# どのくらいずれていれば違う段とみなすかの閾値を設定
y_threshold = 0.2
tmp2['y_pre'] = tmp2['y'].shift(1)
tmp2['y_diff'] = np.abs(tmp2['y']-tmp2['y_pre'])
tmp2['changepoint'] = tmp2['y_diff'].apply(lambda y: y>y_threshold)
tmp2['y_group'] = tmp2['changepoint'].cumsum()
# ボックス作成
box_dict = {}
cnt = 1
for x in np.sort(tmp['x_group'].unique()):
tmp_x = tmp.loc[tmp['x_group']==x]
tmp_x = pd.merge(tmp_x, tmp2, on='index', how='left')
tmp_x.sort_values('y', inplace=True, ascending=True)
tmp_x['y_pre'] = tmp_x['y'].shift(1)
tmp_x['y_diff'] = np.abs(tmp_x['y']-tmp_x['y_pre'])
tmp_x['changepoint'] = tmp_x['y_diff'].apply(lambda y: y>y_threshold)
tmp_x['y_group'] = tmp_x['changepoint'].cumsum()
for y in np.sort(tmp_x['y_group'].unique()):
tmp_xy = tmp_x.loc[tmp_x['y_group']==y]
tmp_xy.sort_values('y', inplace=True, ascending=True)
box_dict[cnt] = {}
box_dict[cnt]['x_group'] = x
box_dict[cnt]['y_group'] = y
box_dict[cnt]['indice'] = list(tmp_xy['index'].values)
box_dict[cnt]['df'] = tmp_xy
cnt+=1
# テキスト作成
text += f'{page}ページ目\n'
for k, v in box_dict.items():
for idx in v['indice']:
tmp_txt = content[idx]['text']
text += tmp_txt
text += '\n'
text += '\n'
# 保存
with open('保存先指定', 'w', encoding='utf-8') as f:
f.write(text)
PDF解析
ページごとにPythonライブラリのPyMuPDFで文字起こしを実行後、PDFplumberで当該ページに記載されている表をpandas.DataFrame形式で取得してHTML形式に変換して文字起こし結果に結合します。
-
使用ツール
-
PyMuPDF
- PDFドキュメントからデータ抽出、解析、変換、操作を行うためのPythonライブラリです。
- 今回は統合報告書中のテキスト抽出に用います。
-
PDFplumber
- PDFドキュメントからテキストや画像を抽出するPythonライブラリです。
- PyMuPDFと比較して画像抽出の精度が高く、pandas.DataFrame型への変換が容易にできます。
- 今回は統合報告書中の図表抽出に用います。
-
PyMuPDF
- インプット
- ACVのときと同様、PDFファイルをそのまま入力します。
- アウトプット
-
PyMuPDFによるテキスト抽出では以下のようになり、文章としては成立していますが、順序がバラバラになっている箇所が見受けられます。
水は自由奔放に、その姿を変えていきます。 時には繊細な光を放つ雪の結晶のように、また時には大きなうねりとなって大海原へ。 そして、岩や大地をも削り取る強い結束力さえもあります。 水は平凡どころか、すこぶる非凡であり、シンプルにしてきわめて強固。 それは、地球上のあらゆる生命に潤いをもたらせています。 「水のようでありたい」それが私たちのモノづくりの原点になっています。 「4℃」それは氷が張った水面の底の温度をあらわします。 唯一魚が生息できるいわば「安息の場」であり、 きびしい環境にあっての潤いそのものを意味します。 私たちは既存の価値に捉われることなく常に新しさと潤いをもたらす 商品の提案を続けています 1 4℃ホールディングスグループの At a Glance 2 トップメッセージ 価値創造ストーリー
-
PDFplumberによる図表抽出は以下のようになります。
「当社の対応方針」が抽出できていないなどの課題はありますが、表としての意味を保つため、これをHTMLコードに変換してテキストデータに埋め込みます。0 1 2 3 4 5 区分 当社に可能性のある事項 当社への影響度 当社の対応方針 4℃ 2℃未満 シナリオ シナリオ 政策・ 炭素税の導入によるコストの増大 中 大 法規制 リスク 情報開示義務拡大への対応による業務負荷、コストの増大 小 中 商品のLCA(ライフサイクルアセスメント)評価義務化によ - 中 るトレーサビリティの確保等必要な措置による業務負荷と コストの増大 省エネ化の推進が進まないことによるコストの高止まり 大 - 市場リスク 素材調達、物流等経費の上昇による経費の増大と利益率 大 大 の低下 評判リスク 消費者のサステナビリティ志向の変化による対応への遅れ 大 大 と競争力の低下・競争機会の逸失 環境への対応の遅れによるステークホルダーの評価・企業 中 大 イメージの低下 急性リスク 台風や大雨により店舗が営業できないことによる売上減少 中 小 リスク 物流プロセスの寸断による売上減少リスク 中 小 慢性リスク 冬物衣料の需要低下による売上減少のリスク 大 中 温暖化による金属アレルギー発症者の増加とジュエリー離 小 小 れ エネルギー源 将来コストの上昇が予想される化石燃料から低炭素エネル - 大 ギーへの転換と省エネ化によるコスト及びGHG排出量の 削減 製品サービス 低・脱炭素社会対応型のサステナビリティ商品に対する顧 中 大 客の支持拡大 気温上昇に対応し夏物商品の売上拡大 中 小 レジリエンス 低炭素経済に対応するサプライチェーンの構築による企業 中 大 イメージの向上 HTMLコード
<table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th>0</th> <th>1</th> <th>2</th> <th>3</th> <th>4</th> <th>5</th> </tr> </thead> <tbody> <tr> <td>区分</td> <td>None</td> <td>当社に可能性のある事項</td> <td>当社への影響度</td> <td>None</td> <td>当社の対応方針</td> </tr> <tr> <td>None</td> <td>None</td> <td>None</td> <td>4℃\nシナリオ</td> <td>2℃未満\nシナリオ</td> <td>None</td> </tr> <tr> <td>None</td> <td>政策・\n法規制\nリスク</td> <td>炭素税の導入によるコストの増大</td> <td>中</td> <td>大</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>情報開示義務拡大への対応による業務負荷、コストの増大</td> <td>小</td> <td>中</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>商品のLCA(ライフサイクルアセスメント)評価義務化によ\nるトレーサビリティの確保等必要な措置による業務負荷と\nコストの増大</td> <td>-</td> <td>中</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>省エネ化の推進が進まないことによるコストの高止まり</td> <td>大</td> <td>-</td> <td>None</td> </tr> <tr> <td>None</td> <td>市場リスク</td> <td>素材調達、物流等経費の上昇による経費の増大と利益率\nの低下</td> <td>大</td> <td>大</td> <td>None</td> </tr> <tr> <td>None</td> <td>評判リスク</td> <td>消費者のサステナビリティ志向の変化による対応への遅れ\nと競争力の低下・競争機会の逸失</td> <td>大</td> <td>大</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>環境への対応の遅れによるステークホルダーの評価・企業\nイメージの低下</td> <td>中</td> <td>大</td> <td>None</td> </tr> <tr> <td>None</td> <td>急性リスク</td> <td>台風や大雨により店舗が営業できないことによる売上減少\nリスク</td> <td>中</td> <td>小</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>物流プロセスの寸断による売上減少リスク</td> <td>中</td> <td>小</td> <td>None</td> </tr> <tr> <td>None</td> <td>慢性リスク</td> <td>冬物衣料の需要低下による売上減少のリスク</td> <td>大</td> <td>中</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>温暖化による金属アレルギー発症者の増加とジュエリー離\nれ</td> <td>小</td> <td>小</td> <td>None</td> </tr> <tr> <td>None</td> <td>エネルギー源</td> <td>将来コストの上昇が予想される化石燃料から低炭素エネル\nギーへの転換と省エネ化によるコスト及びGHG排出量の\n削減</td> <td>-</td> <td>大</td> <td>None</td> </tr> <tr> <td>None</td> <td>製品サービス</td> <td>低・脱炭素社会対応型のサステナビリティ商品に対する顧\n客の支持拡大</td> <td>中</td> <td>大</td> <td>None</td> </tr> <tr> <td>None</td> <td>None</td> <td>気温上昇に対応し夏物商品の売上拡大</td> <td>中</td> <td>小</td> <td>None</td> </tr> <tr> <td>None</td> <td>レジリエンス</td> <td>低炭素経済に対応するサプライチェーンの構築による企業\nイメージの向上</td> <td>中</td> <td>大</td> <td>None</td> </tr> </tbody> </table>
# PDFファイルが格納されているディレクトリを指定
pdf_dir = './xxx/documents'
# PDFをひとつずつ文字起こししていく
for f in os.listdir(pdf_dir):
# PDFファイルのパスを指定
pdf_path = os.path.join(pdf_dir, f)
# テキストを格納する変数
text = ''
# ページごとに表を取得する
table_dict = {}
with pdfplumber.open(pdf_path) as pdf:
for i, page in enumerate(pdf.pages):
# データフレーム格納用リスト
table_dict[i] = []
# 表取得&追加
data = page.extract_table()
if data:
df_tmp = pd.DataFrame(data)
table_dict[i].append(df_tmp)
# テキストを取得し、表があるページには上記で取得したDataFrameをHTMLに変換して埋め込む
doc = fitz.open(pdf_path)
for page in range(len(doc)):
tmp = doc[page].get_text()
text += f'統合報告書{page}ページ目\n'
text += f'{tmp}\n'
if len(table_dict[page]):
for table in table_dict[page]:
table_html = table.to_html(index=False)
text += f'{table_html}\n\n'
# 保存
with open('保存先パス', 'w', encoding='utf-8') as f:
f.write(text)
テキストの要約
アンサンブルを想定し、テキストの要約パターンを考えました。
| 加工No. | 加工パターン | 文字数指定 |
|---|---|---|
| 1 | 原文のまま | なし |
| 2 | 全文要約 | 5万文字 |
| 3 | 単元ごと要約 | 項目ごとに1万文字 |
| 4 | 1ページずつ要約 | ページごとに5000文字 |
| 5 | 事業活動に着目した要約 | 事業ごとに3万文字 |
| 6 | 財務情報に着目した要約 | 財務情報ごとに2万文字 |
| 7 | 企業理念に着目した要約 | 3万文字 |
| 8 | 人名に着目した要約 | 3万文字 |
| 9 | 実績に着目した要約 | 3万文字 |
| 10 | 計画に着目した要約 | 3万文字 |
| 11 | ESGに着目した要約 | 3万文字 |
| 12 | 時期に着目した要約 | 3万文字 |
| 13 | 地域に着目した要約 | 3万文字 |
| 14 | 数値情報に着目した要約 | 3万文字 |
| 15 | 前年度からの変化に着目した要約 | 3万文字 |
文字数については、統合報告書1つあたりの文字数が平均で約10万文字だったので、全文に対する要約はその3分の1である3万文字としました。
チャンキング・ベクトル化
-
パラメータ
- テキスト分割に必要な以下のパラメータを設定します。
- chunk_size: テキストをどのくらいのサイズごとに分けるか。
- overlap: 隣接するチャンク間にどの程度共通の部分を持たせるか。
- テキスト分割に必要な以下のパラメータを設定します。
-
チャンキング
-
LangchainのTextSplitterを使用してテキストを分割します。
例: 株式会社4℃ホールディングスチャンキング結果
['統合報告書0ページ目\n統合レポート\n4℃ レポート 2024\nすべては、お客様の“笑顔”や“ときめき”のために\n統合報告書1ページ目\n水は自由奔放に、その姿を変えていきます。 \n時には繊細な光を放つ雪の結晶のように、また時には大きなう....., '.....', '.....', ....., '.....', '.....', '<td>19,727</td>\n </tr>\n <tr>\n <td>販売費及び一般管理費( 百万円)</td>\n <td>22,171</td>\n <td>21,804</td>\n <td>18,527</td>\n <td>17,884</td>\n <td>17,748</td>\n </tr>\n <tr>\n <td>営業利益( 百万円)</td>\n <td>4,984</td>\n <td>3,975</td>\n <td>2,767</td>\n <td>1,788</td>\n <td>1,979</td>\n </tr>\n <tr>\n <td>経常利益( 百万円)</td>\n <td>6,804</td>\n <td>4,312</td>\n <td>3,195</td>\n <td>2,293</td>\n <td>2,342</td>\n </tr>\n <tr>\n <td>親会社株主に帰属する当期純利益( 百万円)</td>\n <td>2,440</td>\n <td>2,475</td>\n <td>1,622</td>\n <td>1,490</td>\n <td>1,149</td>\n </tr>\n </tbody>\n</table>\n統合報告書13ページ目\n株式会社4℃ホールディングス\n〒141-0021 東京都品川区上大崎2-19-10\nTEL:03-5719-3429 FAX:03-5719-4462\nhttps://yondoshi.co.jp/']
-
-
ベクトル化
- AzureOpenAIのEmbeddingモデルを使用します。
設定
RAGに使用する各テキストをベクトル化するための設定をします。
ここでは、例としてチャンクサイズ2,000、オーバーラップ500としています。
# チャンク設定
chunk_size = 1000
overlap = 200
chunk_type = 'standard'
source = 'python-lib'
# テキスト分割インスタンス
text_splitter = CharacterTextSplitter(
separator='\n',
chunk_size=chunk_size,
chunk_overlap=overlap
)
# AOAI設定
endpoint = 'https://xxxxx/'
api_key = 'xxxxxyyyyyyzzzzzzz'
api_version = '2024-03-01'
embed_deployment = 'embeddings'
client = AzureOpenAI(
api_key = api_key,
api_version = api_version,
azure_endpoint = endpoint
)
# 統合報告書のテキストファイルが格納されているディレクトリ
text_dir = ''
# ベクトル化したファイルを保存するディレクトリ
save_dir = ''
参照ファイル(統合報告書)
# テキストファイルを一つずつベクトル化
for text_file in os.listdir(text_dir):
# テキストの読み込み
text_file = os.path.join(text_dir, text_file)
with open(text_file, 'r', encoding='utf-8') as f:
text = f.read()
# 指定したチャンクサイズやオーバーラップをもとにテキストを分割
text_splitted = text_splitter.split_text(text)
# Embedding(ベクトル化)
res = client.embeddings.create(
input=text_splitted,
model=embed_deployment
)
# numpy.arrayに変換
vec = np.array([data.embedding for data in res.data], dtype=np.float32)
# 分割したテキストとベクトルを保存(ベクトルの列番号をテキストの保存ファイル名とする)
np.save(os.path.join(save_dir, 'vector'), vec)
for j, tmp_txt in enumerate(text_splitted):
with open(os.path.join(save_dir, f'{j}.txt'), 'w', encoding='utf-8') as f:
f.write(tmp_txt)
クエリ
参照ファイルの特定を類似度算出で行うため、クエリもベクトル化しておきます。
# クエリのcsvパスをpandasで読み込む
query_path = 'xxx.csv'
query_df = pd.read_csv(query_path)
# 100問分のクエリをnumpy.ndarrayに変換
query_list = query_df['problem'].values.tolist()
# Embedding(ベクトル化)
res = client.embeddings.create(
input=query_list,
model=embed_deployment
)
# numpy.ndarrayに変換して保存
queryvec = np.array([data.embedding for data in res.data], dtype=np.float32)
np.save(os.path.join(save_dir, 'query'), queryvec)
クエリの分類・プロンプト構築
知見共有会の総括で共有された質問分類にクエリを分類し、基本のプロンプトに加えて質問カテゴリ別にプロンプトを用意しました。
基本プロンプト
# 指示
[# 質問]に対して[# 参照元]の情報のみで[# 出力項目]の内容を[# 出力形式]に沿って回答してください。
このとき、[# 注意事項]と[# 特記事項]にもしっかりと従ってください。
# 出力項目
・質問に対する回答を単語レベルで回答
・回答の根拠となる本文の抜粋
・回答に対する確信度(100点満点としたときの自己評価)
・確信度に対する根拠
# 出力形式
回答:
根拠となる本文:
確信度:
確信根拠:
# 質問
{question}
# 参照元
{context}
# 注意事項
・出力結果は改行しないでください。
・出力項目の回答は各30文字以内としてください。
・回答が見つからない場合は「わかりません」と回答してください。
・Let’s think step by step.
質問カテゴリ別プロンプト
| カテゴリNo. | 質問カテゴリ | 分類別プロンプト |
|---|---|---|
| 1 | 単純質問 | # 特記事項 この[# 質問]は「単純質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題 トヨタ自動車の社長は誰ですか。 ## 例題の回答 佐藤 恒治 |
| 2 | 比較質問 | # 特記事項 この[# 質問]は「比較質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題 東都銀行の預金量は2021年と2022年でどちらが大きいですか。 ## 例題の回答例 2021年 |
| 3 | 条件付き質問 | # 特記事項 この[# 質問]は「条件付き質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題 ヤマトの2023年2月期の従業員数は何名ですか。 ## 例題の回答例 3043名 |
| 4 | 集計質問 | # 特記事項 この[# 質問]は「集計質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題 大阪不動産の2022年と2024年の不動産売買部門の売り上げ合計はいくらですか。 ## 例題の回答例 171億5721万円 |
| 5 | 誤った前提の質問 | # 特記事項 この[# 質問]は「誤った前提の質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題 マイクロソフトが提供するAIサービス「Gemini」は何年からサービスが開始されましたか。 ## 例題の回答例 質問誤り |
| 6 | 多段階質問 | # 特記事項 この[# 質問]は「多段階質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題1 アメイジングコンピューターの社員数は2020年度から2022年度にかけて何%増加しましたか。 ## 例題1の回答例 17% ## 例題2 2000年以降立川重工の退職者数が最大だった年は何年ですか。 ## 例題2の回答例 2020年 |
| 7 | 後処理が必要な質問 | # 特記事項 この[# 質問]は「後処理が必要な質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題1 東京自動社のアメリカ支社について、2021年から2024年までの3年間のガソリンの使用料はいくらになりますか。 ## 例題1の回答例 3兆2000億円 ## 例題2 フルーツデリバリーの飲食部門の売上高は全体の何%ですか。小数点第一位以下を四捨五入して答えてください。 ## 例題2の回答例 38% ## 例題3 ハートシステムの2024年の営業部門の従業員数と経営企画部門の従業員数の差は何人ですか。 ## 例題3の回答例 197人 |
| 8 | 集合質問 | # 特記事項 この[# 質問]は「集合質問」です。[## 例題]および[## 例題の回答例]の回答方法に倣って回答してください。 ## 例題1 昭和株式会社の社長が挙げている強みを全て挙げてください。 ## 例題1の回答例 豊富な人材育成プログラム、グローバル展開によるリスクヘッジ、独自技術の特許を多数保有している ## 例題2 益子ラーメンの海外拠点を全てあげてください。 ## 例題2の回答例 上海支社、カリフォルニアブランチ、マダガスカル研究センター、ジャカルタセントラルキッチン ## 例題3 2023年度に立川マンション建設が増益となった要因の上位3点を挙げてください。 ## 例題3の回答例 海外投資家からの売上が増加、資材不足の終息、Z世代におけるマンション需要の増加 |
質問カテゴリの分類は本来であれば、クエリを生成AIに与えることで分類させたかったのですが、RAGシステムの基本的な仕組みの構築やデータ加工にリソースを割きたかったので、クエリを目視で確認して分類しました。
回答生成
回答生成に使用する関数を定義します。
関数定義
def get_response(prompt:str, api_key:str, deployment_id:str, endpoint:str,
api_version:str='2024-02-15-preview',
temperature:float=0.7,
top_p:float=0.9,
max_tokens:int=800):
'''Azureから直接生成結果を得る'''
# Configuration
headers = {
'Content-Type': 'application/json',
'api-key': api_key,
}
# Payload for the request
payload = {
'messages': [
{
'role': 'system',
'content': [
{
'type': 'text',
'text': prompt
}
]
}
],
'temperature': temperature,
'top_p': top_p,
'max_tokens': max_tokens
}
ENDPOINT = f'{endpoint}/openai/deployments/{deployment_id}/chat/completions?api-version={api_version}'
# Send request
try:
response = requests.post(ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f'Failed to make the request. Error: {e}')
return response
def cos_sim(a, b):
'''ベクトル間の類似度を測る'''
return np.dot(a, b)/(np.sqrt(np.dot(a, a))*np.sqrt(np.dot(b, b)))
100問それぞれのクエリに対して回答を生成していきます。
-
プロンプトテンプレート作成
- カテゴリ別のプロンプトを共通部分に結合します。
プロンプトテンプレート作成
# 各種ベクトル格納先 query_vec_path = '' text_vec_dir = '' queryvec = np.load(query_vec_path) # プロンプト作成に必要な情報を読み込み query_dir = '' query_type = pd.read_csv(os.path.join(query_dir, 'query_分類.csv')) query_category = pd.read_csv(os.path.join(query_dir, '質問カテゴリ.csv')) query_category_val = pd.read_csv(os.path.join(query_dir, '質問カテゴリ.csv')) template_path = os.path.join(query_dir, 'プロンプト_共通部分.txt') with open(template_path, 'r', encoding='utf-8') as f: template = f.read() # クエリ情報読み込み query_array = query_type.values[num] q = query_array[0] #クエリテキスト category_num = int(query_array[1]) #クエリタイプ query_vector = queryvec[num] #クエリベクトル # 該当するクエリタイプのプロンプトを読み込んでテンプレートに結合 prompt_type = query_category.loc[query_category['カテゴリNo.']==category_num].values[0][-1] prompt_template = template + '/n' + prompt_type
-
使用する統合報告書の特定
- あらかじめ参照する統合報告書が特定できているものについては、特定済みの統合報告書を使用します。
- 参照する統合報告書が特定できていない場合はすべての統合報告書についてクエリとの類似度を算出し、もっともクエリとの類似度が高かった統合報告書を使用します。
統合報告書特定
# データソースの指定(あらかじめ特定できていないクエリについては類似度の高いドキュメントを使用) try: doc_num = int(query_array[2]) except: doc_num = [j for j in range(1,20)] if type(doc_num)==list: # 最も類似度の高いドキュメントを特定する idx = 0 #インデックス(ドキュメント番号) score = 0 #類似度 for j in doc_num: # 統合報告書のベクトルパス tmp_folder = os.path.join(text_vec_dir, f'{j}/') # 類似度上位k個のチャンクの平均類似度をスコアとする data = [] for j, tmp_vec in enumerate(chunk_vector): # チャンクごとにクエリとの類似度を算出(コサイン類似度) sim = cos_sim(tmp_vec, query_vector) data.append([j, sim]) # DataFrameにして類似度順に並び替え、上からk行を抽出 df_sim = pd.DataFrame(data=data, columns=['idx','sim']) df_sim = df_sim.sort_values('sim', ascending=False) df_sim.reset_index(drop=True, inplace=True) df_sim = df_sim.iloc[:k,:] sim = np.mean(df_sim['sim'].values) # 最大値より大きければ更新 if sim > score: idx, score = j, sim doc_num = idx # 使用する統合報告書のベクトルが格納されているパス report_folder = os.path.join(text_vec_dir, f'{doc_num}/')
-
類似度の高いチャンクを抽出
- ベクトル化したチャンクごとにクエリとの類似度を算出します。
- 指定した数だけ類似度上位のチャンクを抽出し、クエリとともにプロンプトに埋め込みます。
チャンク抽出
# 作成したチャンクのうちクエリとの関連性上位何個まで採用するか k = 10 # チャンクごとにベクトルを読み込む chunk_vector = np.load(os.path.join(report_folder, 'vector.npy')) # クエリとの類似度を算出して上位k個だけ残す data = [] for j, tmp_vec in enumerate(chunk_vector): # チャンクごとにクエリとの類似度を算出(コサイン類似度) sim = cos_sim(tmp_vec, query_vector) data.append([j, sim]) # DataFrameにして類似度順に並び替え、上からk行を抽出 df_sim = pd.DataFrame(data=data, columns=['idx','sim']) df_sim = df_sim.sort_values('sim', ascending=False) df_sim.reset_index(drop=True, inplace=True) df_sim = df_sim.iloc[:k,:] # 類似度上位として残ったチャンクを結合 text = '' for _, row in df_sim.iterrows(): chunk_idx = int(row['idx']) with open(os.path.join(report_folder, f'{chunk_idx}.txt'), 'r', encoding='utf-8') as f: chunk_text = f.read() text += f'{chunk_text}\n\n' # プロンプトテンプレートにクエリと参照チャンクを埋め込む prompt = prompt_template.format(question=q,context=text)
-
回答生成
- 上記で作成したプロンプトを生成AIに与えて回答を生成します。
回答生成
# 生成結果を格納する辞書 ans_dict = {} # 回答を生成して結果を辞書型変数に格納 res = get_response(prompt=prompt, api_key=api_key, deployment_id=llm_deployment, max_tokens=4*1000, api_version=api_version, endpoint=endpoint) ans_txt = json.loads(res.json())['choices'][0]['message']['content'] ans_dict[num] = ans_txt
-
回答整形
- それぞれの回答は以下の形式で出力されるため、「回答」部分を抽出します。
''' 回答: xxxxx 根拠となる本文: yyyyy 確信度: oo 確信根拠: zzzzz '''
回答整形
ans_data = [] for query_idx, ans in ans_dict.items(): a = 'わかりません' # 回答抽出 ans = ans if '回答' in ans: if '\n' in ans: tmp_ans = ans.split('\n')[0].split(':')[-1] else: tmp_ans = ans.split(' ')[0].split(':')[-1] if 'わかりません' not in tmp_ans: a = tmp_ans else: continue ans_data.append([query_idx, a]) # データフレームに変換してcsv出力 df_ans = pd.DataFrame(ans_data) df_ans.to_csv('xxx.csv', index=False, header=False, encoding='utf-8') - それぞれの回答は以下の形式で出力されるため、「回答」部分を抽出します。
取組みから得られた知見
評価結果の分析
アンサンブルを想定してRAG構築パターンを検証した結果のスコアは以下の通りです。
| LLM | テキスト抽出方法 | 参照chunk数 | chunk size-over lap | クエリ | score(評価プログラム) | score(提出暫定評価) | |
|---|---|---|---|---|---|---|---|
| 提出1回目 | GPT-4o | AI-OCR | - | 2000-500 | simple | - | 0.28 |
| 提出2回目 | GPT-4o mini | AI-OCR | - | 2000-500 | simple | 0.065 | 0.08 |
| 提出3回目 | GPT-4o mini | AI-OCR | - | 128-40 | ensemble | -0.03 | -0.06 |
| 提出4回目 | GPT-4o mini | python-lib | - | 128-40 | simple | 0.12 | 0.07 |
| 提出5回目 | GPT-4o mini | python-lib | - | 5000-500 | simple | -0.175 | -0.19 |
| 提出6回目 | GPT-4o mini | python-lib | - | 5000-500 | simple | 0.02 | -0.04 |
| 提出7回目 | GPT-4o mini | python-lib | - | 5000-500 | simple | 0.145 | 0.05 |
| 提出8回目 | GPT-4o | python-lib | 10 | 2000-500 | simple | 0.34 | 0.46 |
| 提出9回目 | o1-mini | python-lib | 10 | 2000-500 | simple | 0.395 | 0.52 |
(評価結果の比較)
- テキスト抽出方法:AI-OCRよりもPythonライブラリ(pdf解析)を利用した方がよい。
- Chunking:今回のデータに関してはチャンクサイズ2,000、オーバーラップ500がベター。チャンクサイズ5,000は数回試したが、API制限がかかりやすく試行回数をあまり回せなかった。
- クエリ:類似質問での生成結果アンサンブルを試行したが、1週の生成に時間がかかりすぎる割には大して精度改善しなかった。
- LLM:o1-miniが最も正答率が高い。次いでGPT-4o。今回の検証段階ではLLMの影響が最も大きい。
(質問カテゴリ別の正答率)
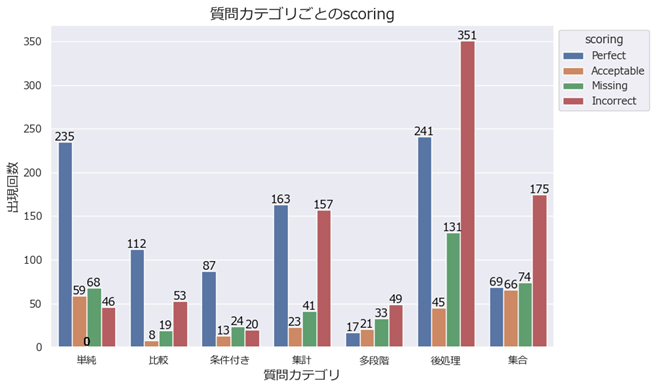
評価用プログラムで採点した結果を質問カテゴリ別で集計したところ、知見共有会での共有でもあったように、難易度の低いとされる質問カテゴリ(左側ほど難易度低)ほど正答率は高い傾向となりました。
今回の問題は単純質問の問題が多い構成となっていたようなので、難しい加工やシステム構築をしなくてもある程度の正解は出せるのではないかと考えられます。
また、集計質問や後処理が必要な質問は不正解が多いですがそれだけ正解も多いです。これについては原因の確認が必要です。
(企業別の正答率)
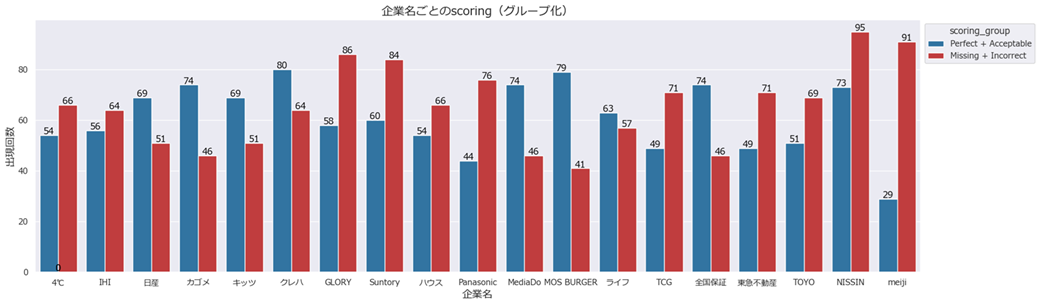
同様に、質問の参照元となる企業別に集計したところ、「Perfect」「Acceptable」が「Missing」「Incorrect」を上回る企業と下回る企業に2分される結果となりました。
単に、企業によって質問難易度が異なっているという見方もできますが、それ以外の観点としては、統合報告書の構成によってRAGとの相性が異なることを示唆すると考えられます。
正解が多かった問題
正解が多かった問題の中で「集計質問」と「後処理が必要な質問」についていくつか確認してみます。
Q2
| 参照ファイル | 株式会社キッツ |
| 質問分類 | 後処理が必要な質問 |
| 参照ページ | pdf 28ページ |
| Perfect率 | 91.7% |
この問題は、参照ページに表で答えが記載されているため、計算の必要がなく「後処理が必要な質問」ではなく「単純質問」だったので、正答率が高かったようです。
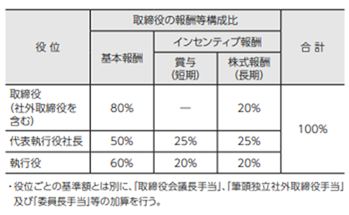
Q10
| 参照ファイル | IHIグループ |
| 質問分類 | 後処理が必要な質問 |
| 参照ページ | pdf 30ページ |
| Perfect率 | 91.7% |
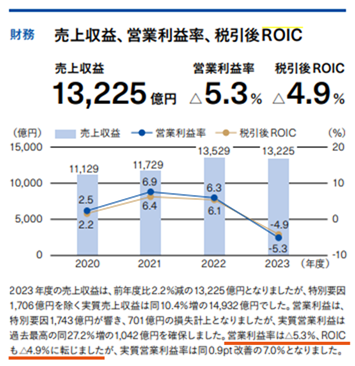
この問題も、グラフの説明として文章で答えが記載されているため、計算の必要がなく「後処理が必要な質問」ではなく「単純質問」だったので、正答率が高かったようです。
Q46
| 参照ファイル | 株式会社モスフードサービス |
| 質問分類 | 集計質問 |
| 参照ページ | pdf 6ページ、26ページ |
| Perfect率 | 79.2% |
この問題は、グラフの読み取りだと難しそうなものの、マップ内の国名との位置関係を正しく取得できれば、計算の必要がなく「後処理が必要な質問」ではなく「単純質問」だったので、正答率が高かったようです。

以上の例から、「集計質問」や「後処理が必要な質問」で正答率が高かった問題は、一見「集計質問」や「後処理が必要な質問」のような問題文でありながら、参照元に直接答えが載っている「単純質問」であったために正解が多かったのではないかと考えられます。
不正解が多かった問題
次に不正解が多かった問題の中で「集計質問」と「後処理が必要な質問」についていくつか確認してみます。
Q5
| 参照ファイル | 日清食品ホールディングス |
| 質問分類 | 後処理が必要な質問 |
| 参照ページ | pdf 69ページ |
| Perfect率 | 0.0% |
この問題は、大半のパターンが「中国」と回答しました。参照すべき表の序盤行でセル結合があるためにうまく取得できなかったものと思料しています。
また、この問題も「一人当たりの年間消費量」の記載はあるため、「後処理が必要な質問」ではなく「多段階質問」だったことがわかります。

Q29
| 参照ファイル | パナソニックグループ |
| 質問分類 | 集計質問 |
| 参照ページ | pdf 42ページ |
| Perfect率 | 12.5% |
この問題は、大半のパターンが「39工場」と回答しました。文章で答えの記載がある「単純質問」であったものの直前単語に注釈があるせいで数値を誤認していることが不正解が多かった要因と考えられます。

Q43
| 参照ファイル | 日産自動車 |
| 質問分類 | 後処理が必要な質問 |
| 参照ページ | pdf 56ページ |
| Perfect率 | 0.0% |
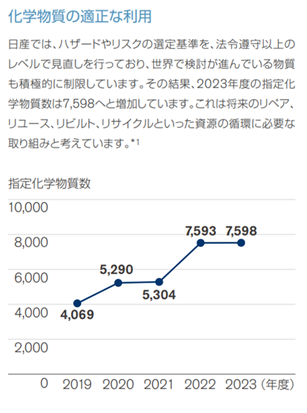
この問題は、グラフ内の情報のみで読み取りから計算までが必要な「後処理が必要な質問」でした。このような問題を正答するには画像解析等のデータ加工段階でのさらなるアプローチが必要と考えられます。
Q91
| 参照ファイル | カゴメ株式会社 |
| 質問分類 | 集計質問 |
| 参照ページ | pdf 45ページ |
| Perfect率 | 0.0% |
この問題は、大半のパターンが「17拠点」と回答しました。拠点名と拠点数を混ぜた記載のされ方を理解できなかったものと思料しています。

ここからは、不正解が多かったものの、LLMをo1-miniを採用した暫定評価最高のものでは正答していた問題を確認しておきます。
Q1
| 参照ファイル | 高松コンストラクショングループ |
| 質問分類 | 後処理が必要な質問 |
| 参照ページ | pdf 9ページ |
| Perfect率 | 37.5% |
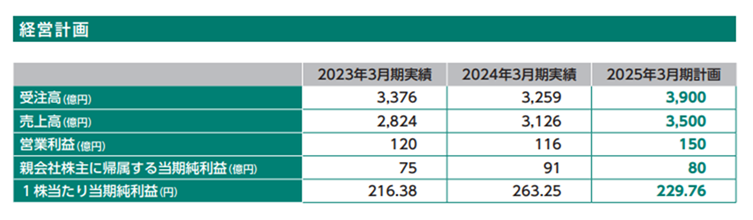
この問題は、表の読み取りから計算が必要な「後処理が必要な質問」ですが、不正解の大半は「1.19倍」と計算までは4o-miniでもできている可能性があります。チャンクサイズの調整や性能の良いLLMを使用することで四捨五入も含めて正答率をあげられていることが確認できました。
Q20
| 参照ファイル | ハウス食品グループ |
| 質問分類 | 後処理が必要な質問 |
| 参照ページ | pdf 11ページ |
| Perfect率 | 9.1% |
この問題は、グラフの読み取りから比較が必要な「後処理が必要な質問」です。先ほどと異なりこちらについては、GPT-4oでも正答することができなかった問題でしたが、o1-miniでは正答できていました。つまり、グラフ内の数値情報でもLLMの性能によっては理解できる可能性はあるものの、Q43のようにそこから計算までは難しいかもしれないようです。
図からの情報取得が正しくできたのであれば、比較と計算はさして難易度が変わらない認識だったので、これについては今後のRAG検証で深堀したいところです。
個別に問題を確認してわかったこと
質問分類
個別に問題を確認したところ、質問分類が間違っている問題が割とあることがわかりました。実際にRAGシステムを運用するのであれば、与えられた質問文で分類するのではなく、関連するデータに検索したときにどのような情報の記載のされ方がされているかを把握し、それに基づいて質問分類する仕組みを作る必要がありそうです。
プロンプト
また、質問カテゴリ別のプロンプトについても、単に例題を場合分けしただけでしたが、質問に解答するためにどんな処理が必要かやプロンプトを分割して再考処理するようにすべきだったと考えられます。
難易度の高い質問
上記で取り上げた例だと、特にグラフとそれに記載されたテキストを読み解いて答える問題に対するアプローチが取れていないことがわかりました。これに対しては今後のRAG検証で画像解析などの調査・検証を実施したいところです。
その他RAGシステム構築でうまくいかなかったこと
アンサンブル
今回はアンサンブルを想定して取組みを行いましたが、結局のところアンサンブルしていない生成結果を採用する結果となりました。その理由としては、
- 要約:要約によって検索したい詳細な情報が失われてしまい、回答が生成できない(Missing)。
- Embedding:アンサンブルにすると1週に必要な使用量が飛躍的に増加しすぐにAPI制限となる。
- クエリ:類似質問での生成結果アンサンブルを試行したが、1週の生成に時間がかかりすぎる割には大して精度改善しなかった。
などがありました。
まとめ
目標スコアは「0.5」でしたが、暫定評価「0.52」、最終評価「0.28」と悔しい結果になった印象です。ただ、100問中の「Perfect」数は60問、「Acceptable」数は3問と過半数を正答しており、評価プログラムでのスコアが「0.395」であったことから、難易度の高くないデータに対しては一定の性能を認めても良いと考えています。
ただ、統合報告書のような画像や図などを多く含むレイアウトが幅広いデータでも高い精度のシステムを構築している方々がいるわけなので、私たちも調査・検証を続けてよりよいRAGシステムの構築を目指したいと思います。