この記事で伝えたいこと
・OCR(API)で読み込んだ表やグラフは読み込んだ文字と画像を一緒にLLMへ渡して説明してもらうと良かった(これが一番精度向上に役立った力技)
・段階的に解く問題もあったので事前情報を集めさせるプロンプトを用意した
・LLMが毎回異なる結果を返してくるものは複数回実行して同じ回答になるものを回答として固定する。異なる回答になるものは再度条件を変えて回答させる
自己紹介
仕事ではレガシーな基幹系システムの関係の仕事がメインの社内SEです。基本的にはプログラムに触れることはほとんどないのですが、趣味でPythonのプログラムを使って色々作って遊んでいるなんちゃってエンジニアです。
第1回、第2回の金融データ活用チャレンジにも参加していますが今回が最も良い成績となりました。
コンペ概要
企業の統合報告書(PDF)が19社分用意されており、その19社に対して用意されている100問の質問に正しく答えるというものです。100問の中には質問自体にひっかけがあり、正しく答えることができない問題もありました。
主なルールとしては
・使用できるLLMに制限はなし(ただしコンペで無料配布されたAzureの4o-miniのAPIは最終回答のみに利用できる ※今回は最終的に無料配布のものを利用しない仕組みとなりました)
・LLMに直接学習させるのも可(制限時間あり)
・使用できるGUIはDataRobot、Dataikuのみ。Azure AI Document IntelligenceなどPythonからAPIで呼び出せるものなどは検収できるため利用可能
・特定の質問を狙い撃ちするようなタグ付けは禁止、ただし質問内に企業名が含まれている場合、その企業名を手動でタグ付けするなどは可能。(slackにて公式から回答あり)
LLMの利用制限は特になかったので今回はOPEN AIのgpt-4oを中心に利用していきました。
コンペ結果
暫定評価0.67 最終評価0.81

引用:https://signate.jp/competitions/1515
(金融庁共催)第3回金融データ活用チャレンジ
運にも助けられましたが過去最高評価でした。
まt会社名の特定LLMや、キーワード検索と組み合わせたハイブリッド検索、サブクエリ、全角を半角に直したりする処理などはありきたりですが全処理過程にちりばめて活用していました。
特に工夫したこと① 表やグラフの前処理
↓の⓪データ整形の部分
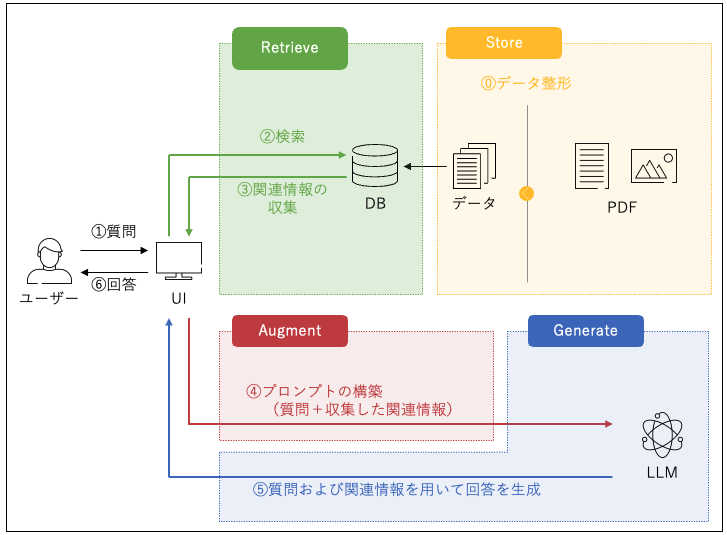
基本は上記の図と同じ流れを実装しました。
PDF読み込みの部分はAzure AI Document Intelligenceを利用していました。
質問:2023年で即席めんの一人当たりの年間消費量が最も多い国はどこか。
対応するPDFの箇所は日清の以下のページになり、回答は「ベトナム」になります。
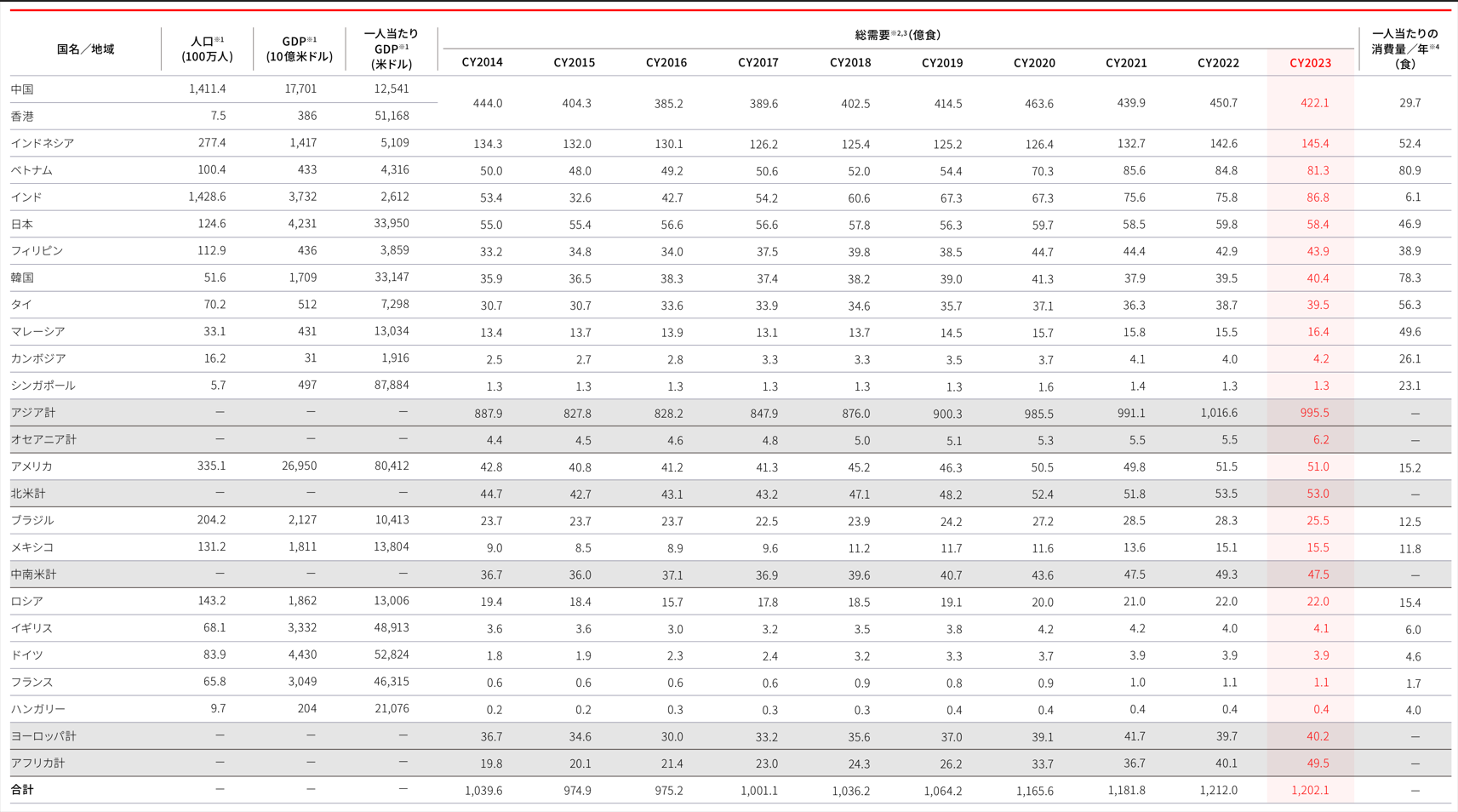
引用:https://www.nissin.com/jp/company/ir/integrated/assets/static/pdf/2024_all_index.pdf
(日清食品ホールディングス 統合報告書 2024 P69)
ここをAzure AI Document IntelligenceのOCR機能に任せて読み取った後に文章だけ抽出するとこうなってしまいました。
国名/地域
人口※1 (100万人)
GDP#1 (10億米ドル)
一人当たり GDP#1 (米ドル)
総需要※2,3(億食)
一人当たりの 消費量/年※4 (食)
CY2014
CY2015
CY2016
CY2017
CY2018
CY2019
CY2020
CY2021
CY2022
CY2023
中国
1,411.4
17,701
12,541
444.0
404.3
385.2
389.6
402.5
414.5
463.6
439.9
450.7
422.1
29.7
香港
7.5
386
51,168
インドネシア
277.4
1,417
5,109
134.3
132.0
130.1
126.2
125.4
125.2
126.4
132.7
142.6
145.4
52.4
ベトナム
100.4
433
4,316
50.0
48.0
49.2
50.6
52.0
54.4
70.3
85.6
84.8
81.3
80.9
~(中略)~
ハンガリー
9.7
204
21,076
0.2
0.2
0.3
0.3
0.3
0.4
0.4
0.4
0.4
0.4
4.0
ヨーロッパ計
-
-
-
36.7
34.6
30.0
33.2
35.6
37.0
39.1
41.7
39.7
40.2
-
アフリカ計
-
-
-
19.8
20.1
21.4
23.0
24.3
26.2
33.7
36.7
40.1
49.5
-
合計
-
-
-
1,039.6
974.9
975.2
1,001.1
1,036.2
1,064.2
1,165.6
1,181.8
1,212.0
1,202.1
-
これでLLMに投げると質問にうまく答えてくれませんでした。中国とか韓国とか答えてしまいます。
Azure AI Document Intelligenceはそもそもこれが何行何列かの表データとして返してくれるのでその形式にして渡すのもありかと思いました。
しかし綺麗な行列のテーブルデータでないものも一部テーブルになっていることもあり、少し悩みました。
そこで思いついた力技がLLMに対して読み取れた文字列と共に画像データ渡せば綺麗に解説させてみよう。
ということで以下のようなプロンプトで画像を説明させるようにしました。
画像データはAzure AI Document Intelligenceで座標を教えてくれるのでそれを使ってプログラムで画像を取得しました。
#画像ファイルをbase64エンコードする
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def open_ai_explanation(image_path,text):
base64_image = encode_image(image_path)
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
chat = ChatOpenAI(temperature=0, model_name="gpt-4o")
system = (
"あなたは有能なアシスタントです。ユーザーの問いに回答してください"
)
human_prompt = '''\
この画像は統合報告書から抜粋した内容です。この画像の内容を画像を見ていない人にすべての内容の事実のみを説明してください。
また以下の内容は画像に含まれる文字を抽出したものです。画像の内容を読み取る場合の参考にしてください。以下のルールを守ってください。
ルール:"""情報は必ずすべて説明し、含まれる文字や数字を省略してはいけません。"""
画像に含まれる文字: """{text}"""
'''
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat | StrOutputParser()
result_image = chain.invoke({"text": text})
return result_image
この関数にimage_pathに画像のパス、textにOCRで読み取った文字を引数として渡してあげることで以下のように帰ってきます。
この画像は、日清食品ホールディングス株式会社の2024年度の統合報告書からの抜粋で、各国・地域の人口、GDP、一人当たりGDP、総需要、一人当たりの消費量を示しています。以下に詳細を説明します。
### 各国・地域のデータ
- **中国**
- 人口: 1,411.4百万人
- GDP: 17,701十億米ドル
- 一人当たりGDP: 12,541米ドル
- 総需要 (CY2023): 422.1億食
- 一人当たりの消費量/年: 29.7食
- **香港**
- 人口: 7.5百万人
- GDP: 386十億米ドル
- 一人当たりGDP: 51,168米ドル
- **インドネシア**
- 人口: 277.4百万人
- GDP: 1,417十億米ドル
- 一人当たりGDP: 5,109米ドル
- 総需要 (CY2023): 145.4億食
- 一人当たりの消費量/年: 52.4食
- **ベトナム**
- 人口: 100.4百万人
- GDP: 433十億米ドル
- 一人当たりGDP: 4,316米ドル
- 総需要 (CY2023): 80.9億食
- 一人当たりの消費量/年: 80.9食
~(中略)~
- **ハンガリー**
- 人口: 9.7百万人
- GDP: 204十億米ドル
- 一人当たりGDP: 21,076米ドル
- 総需要 (CY2023): 0.4億食
- 一人当たりの消費量/年: 4.0食
- **ヨーロッパ計**
- 総需要 (CY2023): 40.2億食
- **アフリカ計**
- 総需要 (CY2023): 49.5億食
- **合計**
- 総需要 (CY2023): 1,202.1億食
このデータは、各国・地域の人口、経済規模、即席麺の消費量を示しており、地域ごとの消費動向を把握するのに役立ちます。
これを元の文章に差し込んでベクターDBに入力し、検索させ、最終的な回答を生み出すLLMに渡してやることができたので精度向上ができたのかと思っています。(しかし出力内容が安定しないところもあり、CY2022以前のデータが省略されていたりしています。ちゃんと出力してくれることもあったんですが、最後に実行したデータでは出力できておらず必要な部分が抜けてないのは運が良かったみたいです。)
他にもグラフで言うと
「株式会社キッツで2023年度のデジタル教育受講者数は何人?」
という質問があり、下記のようなグラフから取得する必要がありました。
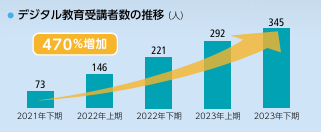
引用:https://www.kitz.co.jp/cms/wp-content/uploads/2024/08/Kitz_Corporate_Report_2024_J_A3_all.pdf
(株式会社キッツ 2024年統合報告書)
これも上記の手順を踏んで得た画像の説明文は
この画像は、デジタル教育受講者数の推移を示しています。以下のデータが含まれています。
- 2021年下期: 73人
- 2022年上期: 146人
- 2022年下期: 221人
- 2023年上期: 292人
- 2023年下期: 345人
全体として、2021年下期から2023年下期にかけて受講者数が470%増加しています。グラフは各期間の受講者数の増加を視覚的に示しています。
こんな感じに出力してくれます。
このように前処理ではかなりうまくいっていたのかと思います。
特に工夫したこと② 事前情報収集プロンプト
↓の④と⑤の部分
引用:https://signate.jp/competitions/1515
(金融庁共催)第3回金融データ活用チャレンジ
問題の中には段階的に情報を収集する必要がありました。
質問:株式会社キッツの2023年度売上高構成比が2番目に高い事業の製造・販売会社を全て上げよ。(回答には株式会社も含めること)
この問題では①売上高構成比が2番目に高い事業の特定②製造・販売会社を全て上げるという2STEPが必要でした。(それぞれ違うページ、文脈に登場する内容です)
そのために考えたのは事前情報に問題を解くためのステップを考えさせて事前情報を取得させる方法でした。
プロンプトはこんな感じです。
("""\
あなたは優秀な企業分析家です。以下の質問に答えるために企業の統合報告書の内容を事前に確認できます。
質問の内容に回答するために必要な手順をステップバイステップで考え、1つ目の質問を出力してください。
質問:{question}
""")
("""\
あなたは優秀な企業分析家です。以下の質問に答えるために企業の統合報告書の内容を事前に確認できます。
事前情報として以下の通り、事前質問に対して事前回答を得ています。
この情報は事前に知っている前提で最終的な質問に答えるために必要な統合報告書に対する質問文を1つ考えてください。
ただし事前回答がわからないと回答している場合は出力する質問文を事前質問よりも抽象的な質問にしてください。
事前質問:{pre_question_0}
事前回答:{pre_answer_0}
最終的な質問:{question}
質問:{question}""")
("""\
あなたは優秀な企業分析家です。以下の最終的な質問に答えるために企業の統合報告書の内容を事前に確認できます。
事前情報として以下の通り、事前質問に対して事前回答を2通り得ています。
この情報は事前に知っている前提で最終的な質問に答えるために必要な統合報告書に対する質問文を1つ考えてください。
ただし事前回答2がわからないと回答している場合は出力する質問文を事前質問2よりも抽象的な質問にしてください。
事前質問1:{pre_question_0}
事前回答1:{pre_answer_0}
事前質問2:{pre_question_1}
事前回答2:{pre_answer_1}
最終的な質問:{question}
""")
このような感じで情報を収集しつつ、また質問を得るために必要だった元文書で検索したものはため込んでいきます。
で、最終的にはこれまででえられた回答と検索してきた元文書を一緒に渡してあげました。
(f'''\
あなたは優秀な企業分析の専門家です。以下の文脈は{company}の2024年の統合報告書の抜粋です。文脈だけを踏まえて質問に回答してください。
質問に答えるために統合報告書の内容について以下の通り、事前質問1~事前質問3を行い、事前回答1~事前回答3を確認しているので参考にしてください。
ただし以下のルールを必ず守って回答してください。
ルール:
"""
ルール1:数値を回答する場合は計算過程や根拠は記載せず、値と単位のみで回答すること。
ルール2:事前回答よりも文脈を優先してください。文脈のみでわからない場合は事前回答の内容も参考にしてください。
ルール3.文脈から取得した単語はなるべくそのまま使用して回答すること。事実に基づいた計算は許可されているが、記載事項にない考察や推測することは厳禁とする。
ルール4:質問に含まれる内容は回答で繰り返さず端的に回答すること。
ルール5:「です」や「ます」などの言葉は不要とし、50文字以内で回答すること。
ルール6:回答内容と相反する内容が文脈に含まれている場合や、正確に回答てきないものはわかりませんと回答すること。
"""
質問: """{query}"""
事前質問1:"""{pre_question_0}"""
事前回答1:"""{pre_answer_0}"""
事前質問2:"""{pre_question_1}"""
事前回答2:"""{pre_answer_1}"""
事前質問3:"""{pre_question_2}"""
事前回答3:"""{pre_answer_2}"""
文脈: """{contexts}"""
''')
これを「株式会社キッツの2023年度売上高構成比が2番目に高い事業の製造・販売会社を全て上げよ。」で試してあげると
pre_question_0
2023年度の売上高構成比が2番目に高い事業は何か?
pre_answer_0
2023年度の売上高構成比が2番目に高い事業は「伸銅品事業」であり、その売上高構成比は17.0%です。
pre_question_1
2023年度の伸銅品事業の製造・販売会社を全て教えてください。
pre_answer_1
2023年度の伸銅品事業の製造・販売会社は、以下の2社です。
1. 株式会社キッツメタルワークス
2. 北東技研工業株式会社
pre_question_2
2023年度の売上高構成比が2番目に高い事業の製造・販売会社を全て教えてください。
pre_answer_2
2023年度の売上高構成比が2番目に高い事業は「伸銅品事業」です。この事業の製造・販売会社は以下の通りです。
- 株式会社キッツメタルワークス
- 北東技研工業株式会社
以上が文脈から得られる情報です。
こんな結果になります。事前情報の段階で答えちゃってますが、2023年度の売上高構成比が2番目に高い事業は何か?という事前質問から伸銅品事業と答えを得られており、最終質問に正しく情報を渡せています。
特に工夫したこと③ 出力が毎回異なることへの対策・後処理
↓の⑥の後処理部分
引用:https://signate.jp/competitions/1515
(金融庁共催)第3回金融データ活用チャレンジ
ここはあまり語ることもないのですが、LLMは毎回微妙に違う回答を返してきます。また上記のように事前質問の内容を参考にさせると事前質問のちょっとしたズレが回答に影響を及ぼして全く違う回答になることもありました。
今回それを対策できたとは言えなかったのですが、微妙に処理やプロンプトを変えてあえて違う条件で複数回回答をさせました。80時間制限的には余裕でしたが、金銭面ではつらい作戦です。
そして複数回の回答を比較し、同じ回答になっている場合は回答として確定。異なる回答だった場合にはちょっと条件を変えて実行しました。
それで最終的な回答は少し安定しました。それでも何回やっても合わないものはあきらめました。
プロンプトはこんな感じで、これもLLMに回答させました。
f'''
あなたは優秀は採点者です。
質問に対して回答1と回答2が存在しています。
回答1と回答2が完全に同じ回答である場合は「同じです」と出力し、違う回答である場合は「異なります」と回答してください。
質問: """{question}"""
回答1: """{answer}"""
回答2: """{answer2}"""
'''
さいごに
今回のコンペでRAGを実装してみて非常に勉強になりました。
LLMに期待できる部分とできない部分の輪郭が参加前よりはずっとわかるようになった気がします。
最後になりましたが、
・コンペの運営者の皆様
・切磋琢磨しながら競いあうことができた参加者の皆様
・日ごろから一緒に勉強している同僚の皆様
・コンペに取り組む時間を作ってくれた家族
大変感謝しております。ありがとうございました。
第4回の金融データ活用チャレンジがあればまた頑張りたいと思います。