はじめに
第3回金融データ活用チャレンジというコンペに参加しました.参加の経緯とコンペで実施したことなどを書いていきます.Qiitaで記事を書くのは初めてですので,温かく見守っていただけるとありがたいです.第3回金融データ活用チャレンジの詳細は,以下を参考にしてください.
そもそも,「RAGって何?」 という状況にも関わらず,このコンペに参加しました.
参加の経緯とチームの結成
2023年度と2024年度に,マナビDX Questに参加しました.そこでは,一歩踏み出して経験することで多くので学びが得られることを経験することができました.そういったことも後押しになり,最近になってコンペに参加して,経験をしながら学びを得ようと考えています.ただ今回の第3回金融データ活用チャレンジは,なんとなく楽しそうという軽い気持ちで参加しました.
コンペに参加して,Slackの自己紹介のチャンネルを眺めてみると,マナビDX Questで知り合い,何度か連絡を取り合っている方を発見しました.直接連絡をして,マナビDX Questの知り合い3名でチームを結成することになりました.私自身,コンペにチームで出場するのは初めてだったのですが,これこそ私が望んでいるチャンスと思って,チームで参加することを選びました.
Dataikuで挑戦することを決める
私は,Pythonは仕事ではあまり使うことがなく,すべてをPythonのコードで書くのは難しいと思っていました.またじっくりコンペに時間をかけることはできないと考えていました.そんな中チームのメンバーから,Dataikuを使おうと考えていると聞いて,私もDataikuでチャレンジすることにしました.結局メンバー3名とも,Dataikuを使うことなりました.Dataikuは2023年度のマナビDX Questに参加していた際に,ある受講者からDataikuを紹介いただいことがありました.知ってはいたものの本格的に使ってみることは今回が初めてでした.2023年当時は,生成AIに関する部分は,まだ十分に使える状況ではなかったと思います.今回のRAG構築で,Dataikuがパワフルなツールでかなりの機能が使えることを知り,大変驚きました.
Dataikuは,操作が直感的で分かりやすい上,以下の手引書のお陰で,無事初回の投稿を行うことができました.
Dataikuの皆様には,休日にもSlackで素早い回答やフォローなどをしていただき,本当にありがたいかぎりでした.
チュートリアルの次に何を実施するか
チュートリアルを実施した後,次に何を実施するか非常に悩みました.チャンクという言葉など専門用語をSlackで目にしたのですが,意味がきちんと理解できていないということもありました.RAGに触れるのが初めてという部分もあったように思います.
PyMuPDFを用いたPDFの読み取り
チームメンバーより,(またSlack上でも話題になっていたと思いますが,) OCRのプラグインでは,8.pdf,10.pdf,12.pdf,19.pdfがきちんと読み込めていないと教えていただきました.確認すると次のようになっていました.

そこで,OCRのプラグインではない方法で,PDFを読み込むことができないかと考えるようになりました.それでメンバーから教えてもらったのは,PyMuPDFを使ったPDFの読み込みです.実際に実施してみたことを書いていきます.
DataikuのCode Envsから,PyMuPDFのパッケージのインストールします.
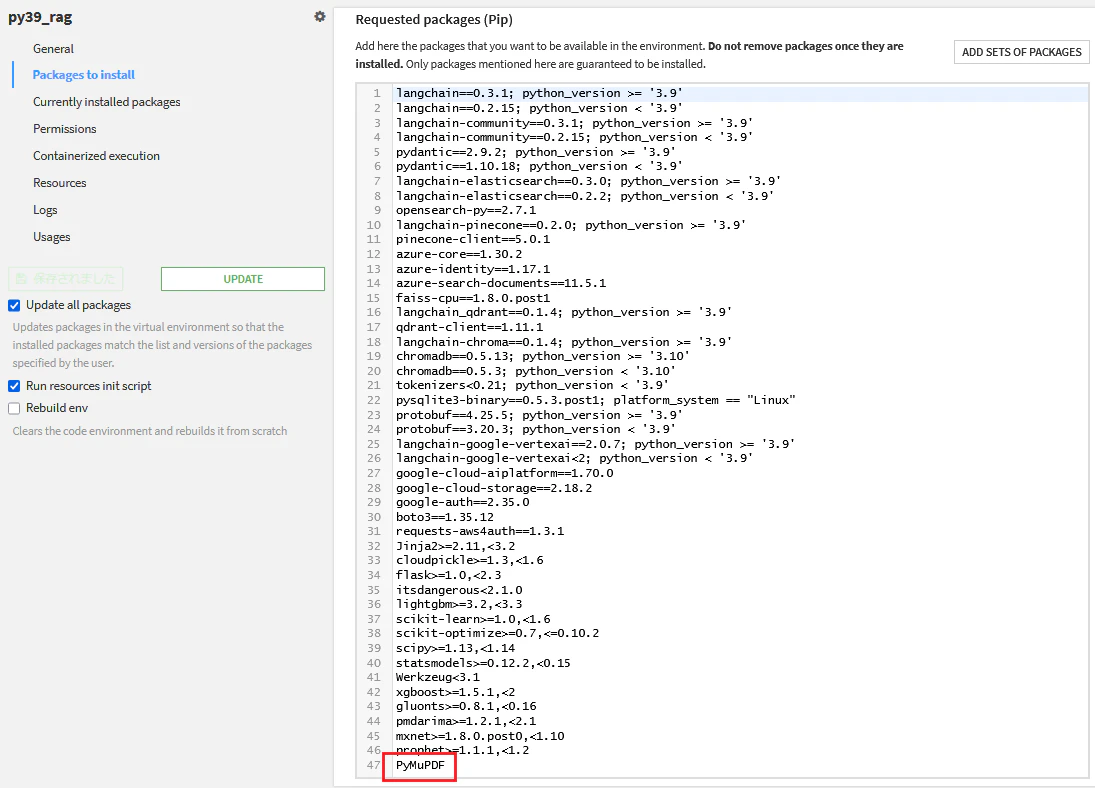
ここでは,バージョンを選択しなくても自動的に適切なものを選んでくれるようでした.
この後,Pythonレシピのコードを示しますが,レシピの中でインポートしているのは,fitzです.Code Envsでもfitzのインストールだけで良いと勘違いをして,最初ここにはfitzと書いていました.するとfitzの中で別のライブラリのfrontendを呼んでいるようで,モジュールがないというエラーが発生します.ここで躓き,かなりの時間を使ってしまいました.
さて,PyMuPDFを使うためのPythonレシピについてです.Pythonレシピを選んで,以下のコードを書きます.このコードはチームメンバーが試行錯誤されて作成したものです.
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd
import os
import fitz
# Input: Managed Folderに接続
input_folder_name = "documents" # 読み込むPDFファイルが格納されているManaged Folderの名前
input_folder = dataiku.Folder(input_folder_name)
input_folder_paths = input_folder.list_paths_in_partition()
# Output: Datasetに接続
output_dataset_name = "python_documets_text" # 結果を書き込むDatasetの名前
output_dataset = dataiku.Dataset(output_dataset_name)
# 抽出したテキストを格納するリスト
texts = []
file_names = []
# Managed Folder内のPDFファイルを処理
for file_path in input_folder_paths:
lstrip_file_path = file_path.lstrip("/")
with input_folder.get_download_stream(lstrip_file_path) as f:
# バイト列として読み込み、PyMuPDFで開く
doc = fitz.open(stream = f.read(), filetype="pdf")
text = ""
for page in doc:
text += page.get_text()
texts.append(text)
file_names.append(lstrip_file_path)
# リストをPandas DataFrameに変換
df = pd.DataFrame({"file_name": file_names, "texts": texts})
# DataFrameをOutput Datasetに書き込む
output_dataset.write_with_schema(df)
input_folder_nameとoutput_dataset_nameをそれぞれの環境に合わせて設定すれば,同じように動くと思います.Dataikuはコードを書かなくても,様々な処理を行うことができる一方で,こうやってPythonのコードも用いることができるのは大変ありがたいと感じました.
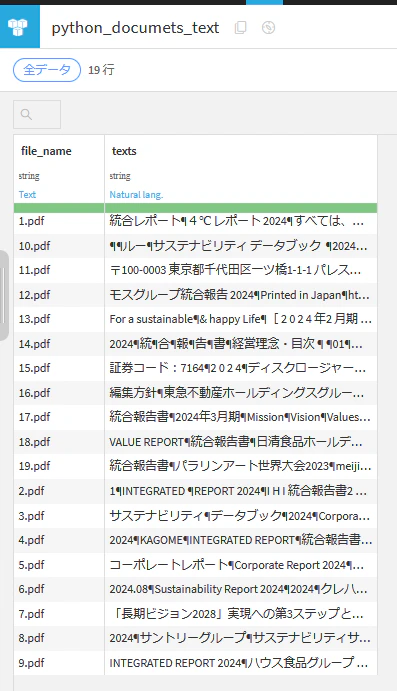
実行した結果は次のようになりました.きちんと8.pdf,10.pdf,12.pdf,19.pdfが読み込めていることがわかります.
こうやってメンバーから教えてもらって,自分で理解しながら進めて行けるというのは本当にすばらしいことだと感じました.自分だけでは,絶対にこんなことをしようとは考えないはずです.このPythonレシピを動かしながら,多くの学びを得ることができたと感じました.
さて,このPythonレシピでPyMuPDFを使って,その他はチュートリアルと同じで回答を投稿するとどうなるのか.実際に投稿してみました.結果はチュートリアルより低いスコアでした.なかなか難しいですね.
改行の削除
読み取ったテキストでは改行が含まれているため,この影響もあるのではないかと考え,改行を削除しました.上記のコードの一部分で,replaceを使った1行分を追加しただけです.
for page in doc:
text += page.get_text()
text = text.replace("\n", "")
texts.append(text)
しかし,回答を提出してみても,結果はチュートリアルには及ばないものでした.この後,似たような前処理をいろいろ試してみましたが,スコアは良くならず.さて一体どうすれば良いのだろうと思ってしまいました.
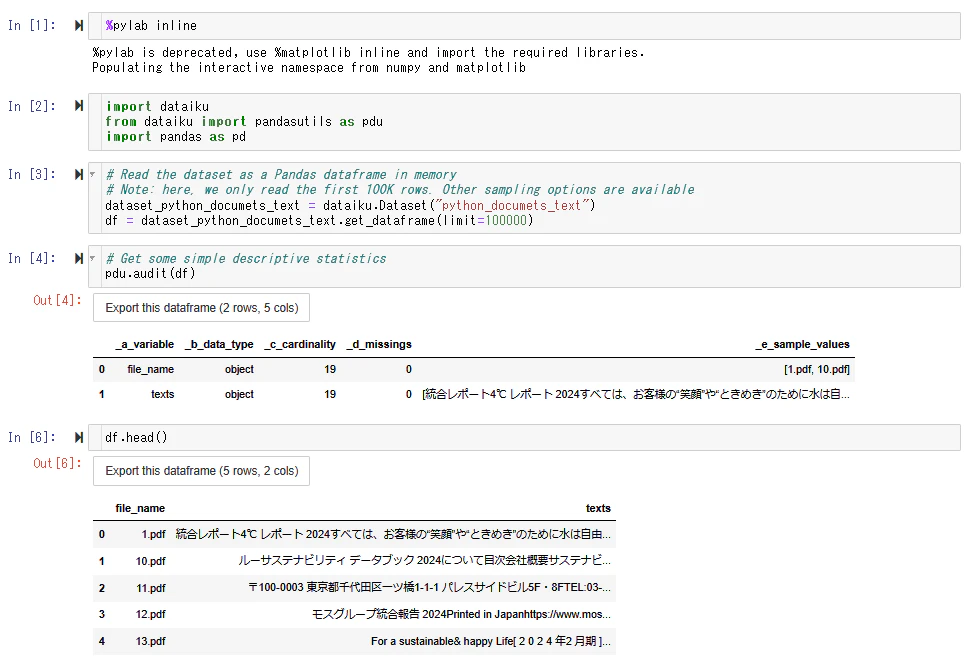
なお,Pythonのノートブックで変数の中身を確認したいこともあると思います.私はラボの機能を使って,ノートブックを開いて確認などもしていました.
この後,プロンプトエンジニアリングなども行ってみたのですが,こちらも上手く行きませんでした.そしてこの辺りで時間切れになってしまいました.
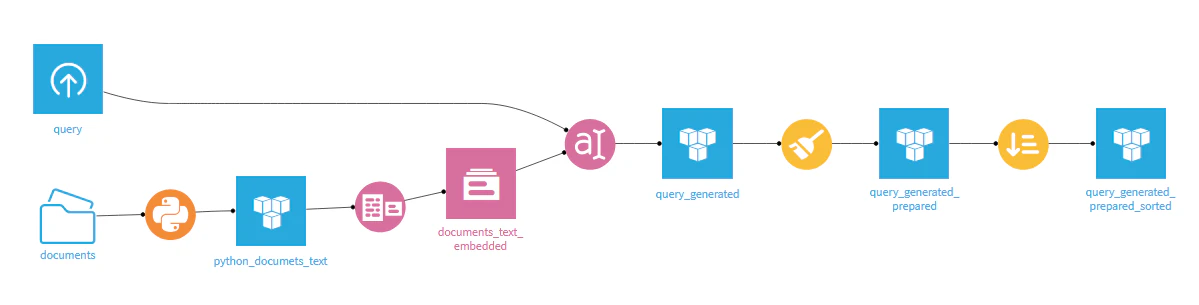
今回作成したフローを以下に記載しておきます.
Dataiku Academy
DataikuではAcademyというコンテンツが用意されていて,これを使ってDataikuを習得できるようになっているようです.
今回,Dataikuがかなり便利なツールだと分かりましたので,これから少しずつAcademyを使って,引き続き学んで行きたいと考えています.ただし,Academyは英語のコンテンツを日本語化している都合なのかもしれませんが,Pythonレシピにあたる部分を学ぶData Scientist Quick Start (Tutorial) がDSS Tutorialsの中にないのが大変残念です.この部分が修正され,さらにDataikuが学びやすくなることを期待しています.
最後に
ここまで読んでいただきどうもありがとうございます.時間がない中でこの文章を書いていることもあり,整理されておらず,読みにくいかもしれません.
第3回金融データチャレンジに参加させていただき,本当にありがとうございました.Slackでは多くの議論が交わされ,確認するだけでも得るものが大きいものでした.またDataikuの可能性を感じることができました.手軽にRAGの構築ができるのは非常に魅力的な一方で,Pythonを使いたい部分には使えるようになっていることもすばらしいポイントの一つであると考えています.これで終わらず,Dataikuを引き続き使って行きたいと思っています.
また,今回初めてチームでコンペに参加させていただきました.やはり,チームのメンバーから様々な学びを得ることができるのはチームで参加するメリットですね.メンバー間でやり取りをする中で,一人では気づかない新しい発見をすることがあります.ぜひ同じメンバーでまたコンペに参加したいと思います.